机器学习入门三
- 多功能
- 多元梯度下降法
-
- 多元梯度下降法
- 多元梯度算法求偏导
- 特征缩放
-
- 使用最大值处理
- 均一化
- 学习率
- 特征和多项式回归
-
- 多项式回归
- 正规方程
-
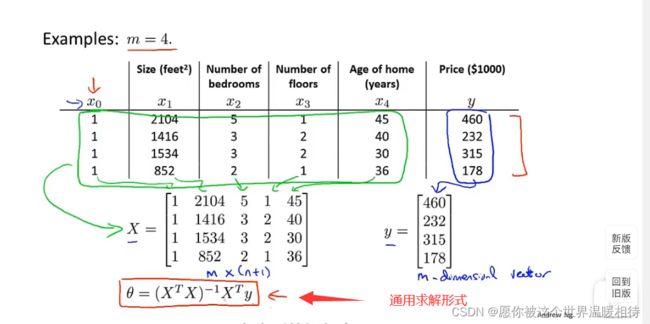
- 通用求解形式
- 设计矩阵
- 什么时候用正规方程法
- 正规方程在矩阵不可逆情况下的解法
多功能
新线性回归的版本,适用于多个变量或者多特征的情况
图一是一般的线性回归方程,图二是涉及到多个输入特征量,也就是多特征的情况
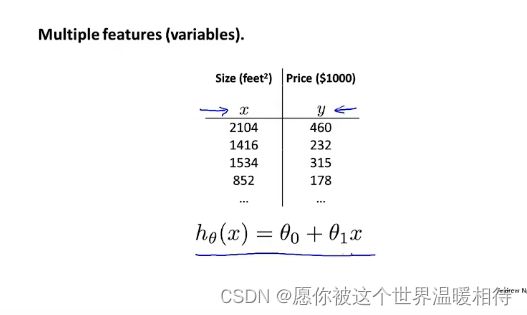

对于多元线性回归的描述,类似于一般的线性回归
n:表示记录数
x i x^i xi:表示输入的第i行特征值
xij:表示第i行特征值的第j个特征值

多元线性回归具体的方程如下

对于多元回归方程可以转换成如下更为紧凑的形式

多元梯度下降法
多元梯度下降法
- 参数θ0…θn,可以使用一个Θ向量表示
- 多元梯度下降法类似于一元的梯度下降法
- 在一般惯例中,x0设置为1

多元梯度算法求偏导
,如下是多元梯度下降算法的公式求偏导后对应的公式
在一般惯例中x0=1,因而推导出来的θ0的公式也是适用的

特征缩放
使用最大值处理
确保不同的特征值在相近的范围内,这样的梯度下降法就能更快地收敛
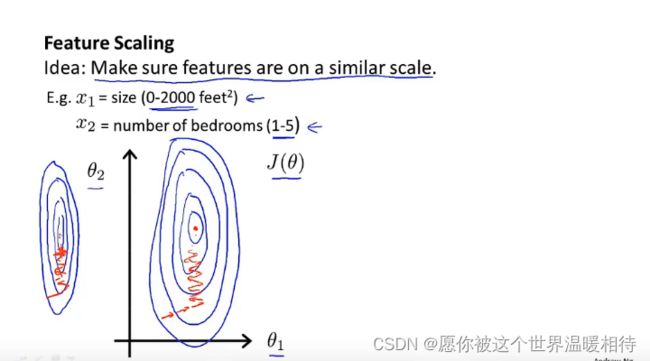
θ1和θ2表示两个不同的特征值(这里不考虑θ0这个常数项),那么就相当于h(x) = θ1x1+θ2x2,其中θ1表示的是房屋的面子,θ2表示房屋对应的房间数,并且x1的取值范围为0-2000,而x2的取值范围为0-5,这个时候两个特征值的取值范围相差非常大,这个时候就如果画出其中J(θ)对应的高线图,这个时候就很可能会出现椭圆相当扁长的情况,那么从椭圆的顶端到中心,这个时间就会越长,使得下降过程相当缓慢,反复来回震荡,从而使的梯度下降算法的效率下降
不同特征值在相近的范围内,高线图中椭圆会更倾向于圆
解决上述问题可以使用特征缩放,如下对于房屋面积,可以对具体的房屋面积除以2000,对于具体房间数,可以除以5,最终使得二者范围在0~1之间,从而是不同的特征值在相近的范围内
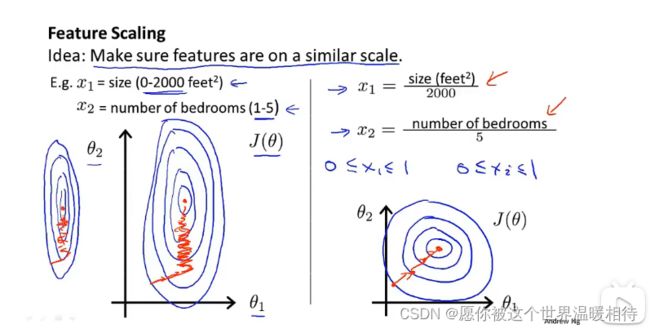
更一般而言,我们在执行特征缩放的时候,会将对应的特征值约束在-1到+1的范围内,对于比较小的数就进行放大,对于比较大的数就进行增大

上述中限定特征特征值在-1到1之间的范围,但是并不需要过分担心数据经过特征缩放后是否在该范围i内,只要特征值比较相近,那么梯度下降算法就能正常工作
均一化
上述过程中都是将特征值除以最大值,从而约束特征值在-1到1之间的范围,除了这种形式以外,在特征缩放,有时候我们也会进行均一化的工作
如果你有一个特征值是xi那么就用xi-ui来替换,让你的特征值具有为0的平均值,如下图
这一步不用应用到x0中,因为x0被设定为恒等于1

u1事实上是训练集中特征j集x1的平均值,如上述房屋售卖例子中,房屋的面积平均值是1000,所以u1=1000,训练集中房屋的房间数的平均是2,那么u1=2,这样就可以特征值的范围保持在-0.5到0.5之间的范围(也可能超过,但是总体是相近就可以了)
学习率
当梯度函数正常运作的时候,如下图,横轴表示的是迭代的次数,纵轴表示的是经过迭代后得到的代价函数的最小值。因而正常工作的梯度下降函数应该是随着迭代次数增加而不断下降直到最后去向平整
不同的使用场景中,梯度下降函数可能会在不同的迭代次数后就已经趋向平整,也就是代数函数基本得到最小值

如下表示梯度下降函数并没有正常工作,并且下边两个图中表示可能是因为设置的学习率比较大,导致代数函数的值在来回振荡的情况,从而导致出现类似二次函数的图像。解决这个问题只需要设置较小的学习率就行了

梯度下降函数中,只要学习率足够小,那么每次迭代后代价函数都会下降。但是因为学习率比较小,那么迭代的次数就会比较多,也就是收敛比较慢的问题,才能达到最低点
特征和多项式回归
多项式回归
不使用原来的特征,而是根据原来的特征得到一个新的特征,然后得到一个更好的模型,与选择特征相关的概念被称为多项式回归
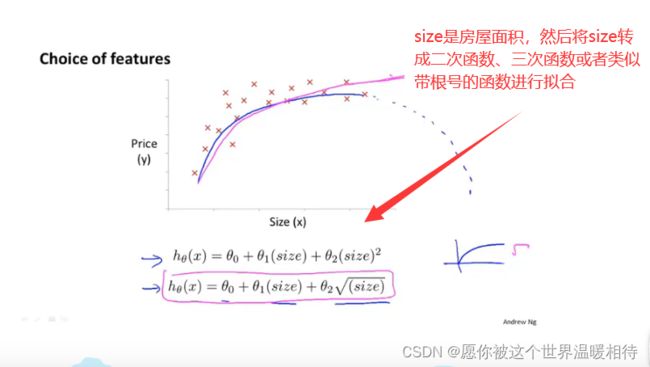
如下假设函数是跟房屋占地的宽高进行配置的,而这个时候可以进行考虑与宽高两个特征量有关的面积作为特征量,并使用新特征配置成相应的二次函数或者三次函数拟合到数据上
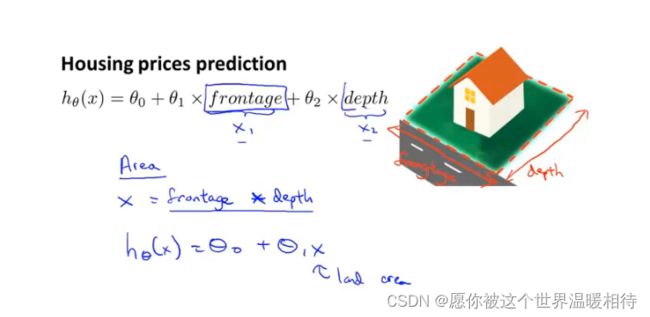
这里解决的是使用新的特征,如何将多元线性回归将一个二次函数或者三次函数拟合到你的数据上。如下,经过多元回归后,将相应的假设函数转成二次函数或三次函数对数据进行拟合,但是在这种情况下,例如设置 s i z e 2 size^2 size2,以 s i z e 2 size^2 size2为新的特征量时候,他的特征值的范围都会变大,这个时候需要进行特征值的放缩使得各个特征值特征值相近
正规方程
- 对于某些线性回归方程,正规方程可以提供更好的方法来求得参数θ最优值
- 正规方程提供一种求θ的解析解法,而不需要运行迭代算法
通用求解形式
如一个二元一次方程,求他的最小值,就是对他进行求导以后,找到导数值为0的点,这就是他的最小值,对于线性回归方程也有类似的过程,但是对应的不是一个变量,而是一个向量

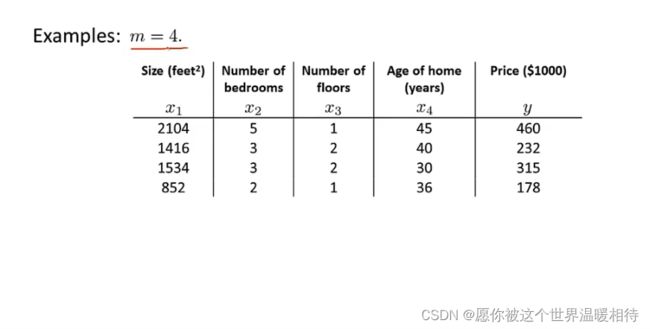
对于上述将代价函数转成导数形式,然后导数为0的情况下还需要针对每个θ进行得到相应的导数,例如θ0…θj,如果每个都求出相应的导数,并不具备一般性。如下例子中给出了更为一般的解析式,得到使得代价函数最小的θ的值
在上图左边添加一列特征变量,并设置为恒等于1并组成对应的矩阵,并得到如下图的通用求解形式
设计矩阵
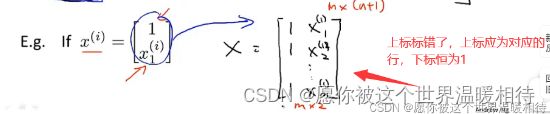
将上述例子更一般化,就涉及到设计矩阵,如下,m个例子,其中 x i x^i xi他是一个向量,其中包括n个特征值,如下图,在特征值头部添加x0特征,将 x i x^i xi变成n+1维向量,然后是设计矩阵
设计矩阵如下图2,就是将 x i x^i xi的n+1维向量转置后放到对应的行,例如第一个样品对应的 x 1 x^1 x1向量转置后放到第一行,第二个样品的 x 1 x^1 x1向量转置后放到第二行,如此类推,如下图3例子


使用正规方程法,不需要特征缩放
什么时候用正规方程法
正规方程法可以直接解析出θ值,但是其中计算的时候涉及到矩阵的乘法,复杂度将达到O( n 3 n^3 n3),如果数据量比较大,例如上万,那么使用正规方程法是负担比较大的,所以正规方程法的使用一般是在特征量比较小的情况,如小于一万
梯度下降法执行效率跟学习率有关,需要不断尝试,最终选择一个比较好的学习率,并且过程寻找需要多次迭代,需要额外的消耗,这是他的缺点,但是梯度下降法适用于任何数据量
正规方程在矩阵不可逆情况下的解法
正规方程中涉及到矩阵的逆,但是 X T X X^TX XTX可以是不可逆的,这个时候就可以进一步处理

- 运算的结果是一个奇异矩阵或者是不可逆矩阵,这个时候可以找到多余的特征并将它删除来解决不可逆问题
- 在没有多余特征的情况下,如果特征数量太多,例如m