论文阅读-Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting
可解释多水平时间序列预测的时间融合Transformer
Temporal Fusion Transformers 时间融合Transformers(TFT),一种基于注意力机制的架构。它将高性能多水平预测(多层面预测)与对时间动态的可解释见解相结合。
多水平预测:在多个未来时间步长预测感兴趣的变量。 与提前一步预测相比,多水平预测能在未来多个步骤中优化其行动。(零售商优化整个即将到来的季节的库存,临床医生为患者优化治疗计划等)。

模型需要的数据包括关于未来的已知信息(如日期)、其他外生时间序列(如历史流量数据)和静态数据。
目前研究的不足
- 不考虑常见的多水平预测的输入的异质性
目前常用方法是循环神经网络(RNN)架构与其变体用于时间序列预测,或者增加基于注意力机制来增强过去相关时间步长的选择等方法。这些方法通常没有考虑多水平预测中常见的不同类型的输入,也没有假设所有外源输入都是已知的或忽略静态协变量。
- DNN常用的可解释性方法不太适合应用于时间序列
在DNN传统形式中,事后解释的方式不考虑输入特征的时间顺序。例如,对于 LIME(Rubeiro),为每个数据点独立构建代理模型,而对于 SHAP(Lundberg&Lee),对于相邻时间步长独立考虑特征。这种事后解释的方式会导致较差的解释质量,因为时间步长之间的依赖性在时间序列中通常很重要。
Ribeiro M., et al. “Why should I trust you?” Explaining the Predictions of any classifier KDD (2016)
Lundberg S., Lee S.-I. A unified approach to interpreting model predictions NIPS (2017)
- 一些基于注意力机制的模型,针对语言或语音这类顺序数据有固有的可解释性。但多水平预测包括许多不同类型的输入特征。
在传统形式中,这些架构可以深入了解多水平预测的相关时间步长,但其无法区分给定时间步长不同特征的重要性。
创新点
时间融合Transformer(TFT),一种基于注意力机制的DNN架构,用于多水平预测,在实现高性能的同时实现一种新的可解释性。
- 静态协变量编码器,用于网络其他部分的上下文向量
- 整个门控机制和样本相关变量选择以最小化无关输入的贡献
- 序列到序列层以局部处理已知和观测的输入
- 时间自注意力解码器,用于学习数据集中存在的任何长期依赖关系
三种可解释性用例
帮助用户识别1)预测问题的全局重要变量;2)持续时间模式;3)重要事件
相关工作
基于DNNs的多水平预测
类似于传统的多水平预测方法(Marcellino,Taieb),可分类为使用自回归模型的迭代方法(Li,Rangapuram,Salinas)和基于序列到序列模型的直接方法(Fan,Wen)。
.Marcellino M., Stock J., Watson M. A comparison of direct and iterated multistep AR methods for forecasting macroeconomic time series Journal of Econometrics, 135 (2006), pp. 499-526
.Taieb S.B., Sorjamaa A., Bontempi G. Multiple-output modeling for multi-step-ahead time series forecasting Neurocomputing, 73 (10) (2010), pp. 1950-1957
.Li S., et al. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting NeurIPS (2019)
.Rangapuram S.S., et al. Deep state space models for time series forecasting NIPS (2018)
.Salinas D., Flunkert V., Gasthaus J., Januschowski T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks International Journal of Forecasting (2019)
.Fan C., et al. Multi-horizon time series forecasting with temporal attention learning KDD (2019)
.Wen, R., et al. (2017). A multi-horizon quantile recurrent forecaster. In NIPS 2017 time series workshop.
使用自回归模型的迭代方法
迭代方法利用一步超前预测模型,通过将预测递归地提供给未来输入来获得多步预测。
DeepAR就是使用具有长短时记忆网络(LSTM)的方法,其使用堆叠的LSTM层来生成前一步高斯预测的参数分布。
深度状态空间模型(DSSM)利用LSTM生成预定义线性状态空间模型的参数,其中预测分布通过卡尔曼滤波生成,并扩展了多变量时间序列数据。
基于Transformer的架构,建议使用卷积层进行局部处理和稀疏注意力机制,以在预测过程中增加感受野大小。
.Salinas D., Flunkert V., Gasthaus J., Januschowski T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks International Journal of Forecasting (2019)
.Rangapuram S.S., et al. Deep state space models for time series forecasting NIPS (2018)
.Li S., et al. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting NeurIPS (2019)
但是迭代方法依赖一个假设:除目标之外的所有变量的值在预测时都是已知的。这样只有目标需要递归的输入到未来的输入中。但是在实际应用场景,存在许多有用的时变输入,其中有许多是事先未知的。
感受野
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。
感受野计算时有下面几个知识点需要知道:
. 最后一层(卷积层或池化层)输出特征图感受野的大小等于卷积核的大小。
. 第i层卷积层的感受野大小和第i层的卷积核大小和步长有关系,同时也与第(i+1)层感受野大小有关。
. 计算感受野的大小时忽略了图像边缘的影响,即不考虑padding的大小。
关于感受野大小的计算方式是采用从最后一层往下计算的方法,即先计算最深层在前一层上的感受野,然后逐层传递到第一层,使用的公式可以表示如下:
R F i = ( R F i + 1 − 1 ) × R F_{i}=\left(R F_{i+1}-1\right) \times RFi=(RFi+1−1)× s t r i d e stride stride i + _{i}+ i+ K s i z e Ksize Ksize i _{i} i
其中, R F i RF_i RFi是第i层卷积层的感受野, R F ( i + 1 ) RF_{(i+1)} RF(i+1)是 ( i + 1 ) (i+1) (i+1)层上的感受野, s t r i d e stride stride是卷积的步长, K s i z e Ksize Ksize是本层卷积核的大小。
感受野有什么用呢?
. 一般task要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好
. 密集预测task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好
. 目标检测task中设置anchor要严格对应感受野,anchor太大或偏离感受野都会严重影响检测性能
基于序列到序列模型的直接方法
可以在每个时间步为多个预定义的范围显式生成预测。其架构通常依赖于序列到序列模型。尽管性能优于基于LSTM的迭代方法,但是其在可解释性方面还有不足。
MQRNN使用LSTM或卷积编码器来生成上下文向量,这些向量被输入到每个层的多层感知器MLP中。
多模态注意力机制与LSTM编码器一起使用,为双向LSTM解码器构建上下文向量。
Wen, R., et al. (2017). A multi-horizon quantile recurrent forecaster. In NIPS 2017 time series workshop.
Fan C., et al. Multi-horizon time series forecasting with temporal attention learning KDD (2019)
相比以上两种方法,TFT既能保证输入的多样性,又能提供关于时间动态的有意义的解释,同时在各种数据集上保持最好的性能。
带有注意力的时间序列可解释性
TFT通过在自注意力之上的每个时间步对静态特征使用单独的编码-解码器注意力来确定随时间变化的输入的权重,从而避免没有考虑静态协变量的情况。
DNN的实例变量重要性:
LIME、SHAP和RL-LIM应用于预训练的黑盒模型,基于提炼成可替代的可解释模型或分解为特征属性。在模型设计中,未考虑输入的时间顺序,从而限制使用。
Ribeiro M., et al. “Why should I trust you?” Explaining the Predictions of any classifier KDD (2016)
Lundberg S., Lee S.-I. A unified approach to interpreting model predictions NIPS (2017)
Yoon J., Arik S.O., Pfister T. RL-LIM: Reinforcement learning-based locally interpretable modeling (2019)
可解释的多变量 LSTM 对隐藏状态进行分区,使得每个变量对其自己的内存段有唯一的贡献,并对内存段进行加权以确定变量的贡献。Choi 等人也考虑了结合时间重要性和变量选择的方法,该方法根据各自的注意力权重计算出一个贡献系数。然而,除了只对一步超前预测进行建模的缺点外,现有的方法还侧重于对注意力权重的特定实例(即特定样本)的解释–没有提供对全局时间动态的洞察力。
Guo T., Lin T., Antulov-Fantulin N. Exploring interpretable LSTM neural networks over multi-variable data ICML (2019)
Choi E., et al. RETAIN: An interpretable predictive model for healthcare using reverse time attention mechanism NIPS (2016)
TFT 能够分析全局时间关系并允许用户解释模型在整个数据集上的全局行为——特别是在识别任何持续模式(例如季节性或滞后效应)和存在的制度方面。
模型架构
TFT 使用规范组件来有效地为每种输入类型(即静态、已知、观察到的输入)构建特征表示,从而在广泛的问题上实现高预测性能。TFT的主要成分是:
- 门控机制门控线性单元(GLU)允许TFT控制门控残差网络(GRN),如有必要,跳过架构中任何未使用的组件,提供自适应深度和网络复杂性以适应广泛的数据集和场景。
- 变量选择网络在每个时间步选择相关的输入变量,允许 TFT 去除可能对性能产生负面影响的任何不必要的噪声输入。
- 静态协变量编码器将静态特征集成到网络中,通过对上下文向量的编码来调节时间动态。
- 从观察到的和已知的时变输入中学习长期和短期时间关系的时间处理。序列到序列层用于本地处理,而长期依赖关系使用新颖的可解释多头注意力块捕获。
- 采用自我注意机制学习不同时间步长的长期关系,增强可解释性。多头注意力机制提高了标准注意力机制的学习能力。
Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A.N., et al. Attention is all you need NIPS (2017)
- 通过分位数预测的预测区间以确定每个预测范围内可能的目标值的范围。
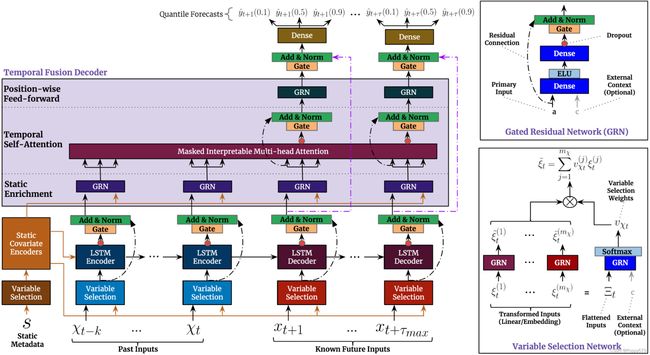 (图片来自论文)TFT架构
(图片来自论文)TFT架构
输入:静态元数据、随时间变化的过去输入和随时间变化的先验已知未来输入。变量选择:根据输入选择最显着的特征。
门控残差网络块:通过跳过连接和门控层实现高效的信息流。
时间相关处理:基于 LSTM 进行局部处理,多头注意力用于整合来自任何时间步的信息。
时间融合解码器
Seq2Seq局部性增强
输入 ε ~ t − k : t \tilde{\boldsymbol{\varepsilon}} _{t-k: t} ε~t−k:t和 ε ~ t + 1 : t + τ max \tilde{\boldsymbol{\varepsilon}} _{t+1: t+\tau_{\max }} ε~t+1:t+τmax进入解码器,然后生成一组统一的时间特征,作为时间融合解码器本身的输入。
静态富集层(Static enrichment layer)
由于静态协变量通常对时间动态有显著影响(如疾病风险的遗传信息),引入一个静态富集层通过静态元数据增强时间特征。
时间自注意力层
所有在上一层丰富过的时间特征分组到一个矩阵中,通过多头注意力机制应用于每一个预测时间。通过解码器掩码((Li et al., 2019, Vaswani et al., 2017))确保每个时间维度只能关注它之前的特征。除了通过掩码保留因果信息流外,自注意力层还允许TFT获取长期依赖关系(这可能对于基于RNN架构的学习具有挑战性)
(Li S., et al. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting NeurIPS (2019))
位置前馈层(Position-wise feed-forward layer)
对自注意力层的输出做额外的非线性处理,与Static enrichment层类似利用了GRN,其中权重在整个层中共享。
分为数输出
TFT通过在每个时间步(如第10、50、90)同时预测各种百分位数实现在点预测之上生成预测区间。分位数预测是使用时间融合解码器的输出的线性变换生成的。
损失函数
联合最小化分位数损失
本文仅对论文和模型结构进行简单的了解,没有深究其中的计算公式。