Hadoop大数据技术详解
一、大数据概述
1、大数据简介
大数据(Big Data)∶指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决:海量数据的存储和海量数据的分析计算问题。
按顺序给出数据存储单位∶bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
1Byte=8bit、1K=1024Byte、1MB=1024K、1G=1024M、1T=1024G、1P=1024T
2、大数据特点
1. Volume(大量)
截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。
2. Velocity(高速)
这是大数据区分于传统数据挖掘的最显著特征。根据IDC的“数字宇宙”的报告,预计到2025年,全球数据使用量将达到163ZB。在如此海量的数据面前,处理数据的效率就是企业的生命。
天猫双十一∶
2017年3分01秒,天猫交易额超过100亿
2019年1分36秒,天猫交易额超过100亿
3. Variety(多样)
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求。
4. Value(低价值密度)
价值密度的高低与数据总量的大小成反比,如何快速对有价值数据“提纯”成为目前大数据背景下待解决的难题。
3、大数据应用场景
1. 物流仓储
大数据分析系统助力商家精细化运营、提升销量、节约成本。
京东物流∶上午下单下午送达、下午下单次日上午送达
2. 零售
分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。
经典案例,纸尿布+啤酒。
3. 旅游
深度结合大数据能力与旅游行业需求,共建旅游产业智慧管理、智慧服务和智慧营销的未来。
4. 商品广告推荐
给用户推荐可能喜欢的商品。
5. 保险
海量数据挖掘及风险预测,助力保险行业精准营销,提升精细化定价能力。
6. 金融
多维度体现用户特征,帮助金融机构推荐优质客户,防范欺诈风险。
7. 房产
大数据全面助力房地产行业,打造精准投策与营销,选出更合适的地,建造更合适的楼,卖给更合适的人。
4、大数据发展前景
1. 党的十八大提出“实施国家大数据战略”,国务院印发《促进大数据发展行动纲要》,大数据技术和应用处于创新突破期,国内市场需求处于爆发期,我国大数据产业面临重要的发展机遇。
2. 党的十九大提出"推动互联网、大数据、人工智能和实体经济深度融合"。
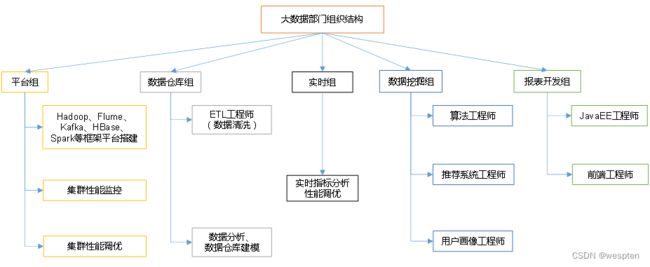
大数据业务:

大数据部门组织结构:
二、Hadoop生态圈
1、Hadoop简介
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
2、Hadoop发展历史
1)Lucene框架是Doug Cutting开创的开源软件,用Java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎。
2)2001年年底Lucene成为Apache基金会的一个子项目。
3)对于海量数据的场景,Lucene面对与Google同样的困难,存储数据困难,检索速度慢。4)学习和模仿Google解决这些问题的办法∶微型版Nutch。
5)可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
GFS-->HDFS
Map-Reduce--->MR
BigTable--->HBase
6)2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和MapReduce机制,使Nutch性能期升。
7)2005年Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
8)2006年3月份,Map-Reduce和Nuteh Distributed File System (NDFS)分别被纳入到Hadoop 项目中,Hadoop就此正式诞生,标志着大数据时代来临。
9)名字来源于Doug Cutting儿子的玩具大象。

3、Hadoop的优势(4高)
1)高可靠性∶Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性∶在集群间分配任务数据,可方便的扩展数以干计的节点。
3)高效性∶在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性∶能够自动将失败的任务重新分配。
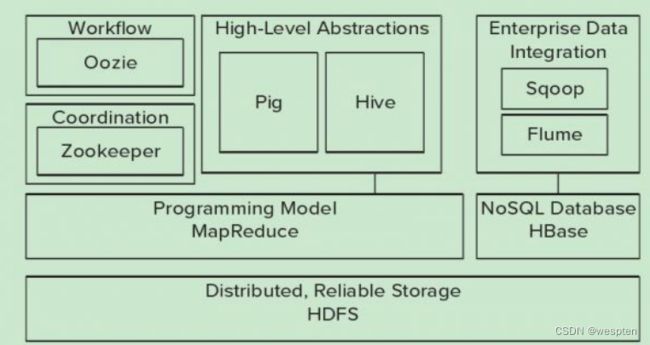
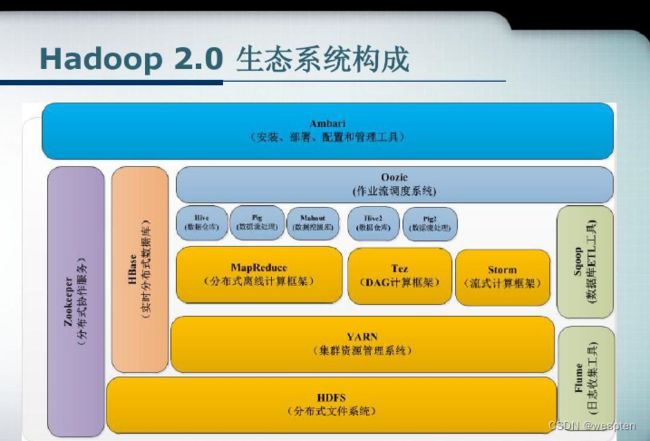
4、大数据技术生态体系
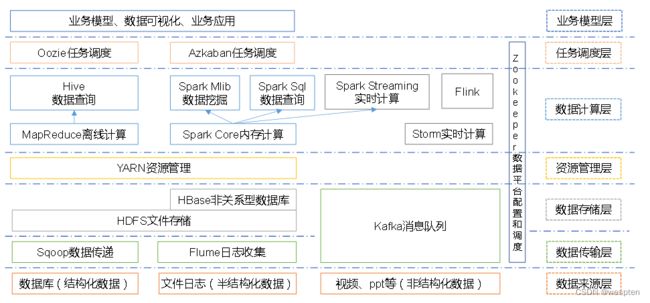
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
5)Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
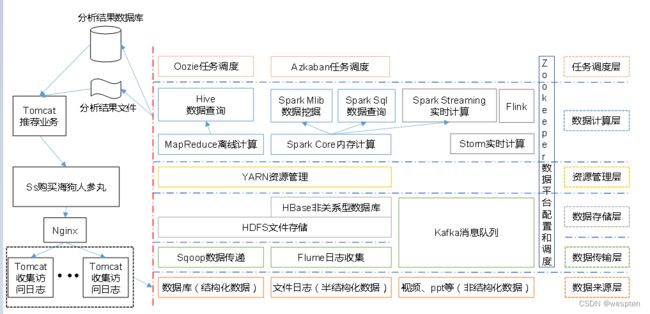
推荐系统架构图:
5、Hadoop生态圈
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。具有可靠、高效、可伸缩的特点。
Hadoop的核心是YARN、HDFS和Mapreduce。
官方网站: Apache Hadoop
常用模块架构:
1)HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。 HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
2)Mapreduce(分布式计算框架)离线计算
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。MapReduce是一种分布式计算模型,用以进行大数据量的计算。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
3)HBASE(分布式列存数据库)
源自Google的Bigtable论文,发表于2006年11月,HBase是Google Bigtable克隆版。
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。在Hbase中,列簇相当于关系型数据库的表。而Key-Value这样的键值对,相当于数据库里面的一行。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
4)Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版,解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
官方网站:Apache ZooKeeper
5)HIVE(数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行,通常用于离线分析。HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
官方网站:Apache Hive
6)Pig(ad-hoc脚本)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具。
Pig定义了一种数据流语言—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
其编译器将Pig Latin翻译成MapReduce程序序列将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
官方网站:Welcome to Apache Pig!
7)Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
官方网站: Sqoop -
8)Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。当然也可以用于收集其他类型数据
官方网站: Welcome to Apache Flume — Apache Flume
9)Oozie(工作流调度器)
Oozie是一个基于工作流引擎的服务器,可以在上面运行Hadoop的Map Reduce和Pig任务。它其实就是一个运行在Java Servlet容器(比如Tomcat)中的Javas Web应用。
对于Oozie来说,工作流就是一系列的操作(比如Hadoop的MR,以及Pig的任务),这些操作通过有向无环图的机制控制。这种控制依赖是说,一个操作的输入依赖于前一个任务的输出,只有前一个操作完全完成后,才能开始第二个。
Oozie工作流通过HPDL定义(hPDL是一种XML的流程定义语言)。工作流操作通过远程系统启动任务。当任务完成后,远程系统会进行回调来通知任务已经结束,然后再开始下一个操作。
Oozie工作流包含控制流节点以及操作节点:
控制流节点定义了工作流的开始和结束(start,end以及fail的节点),并控制工作流执行路径(decision,fork,join节点)。
操作节点是工作流触发计算\处理任务的执行,Oozie支持不同的任务类型——hadoop map reduce任务,hdfs,Pig,SSH,eMail,Oozie子工作流等等。Oozie可以自定义扩展任务类型。
官方网站: Oozie - Apache Oozie Workflow Scheduler for Hadoop
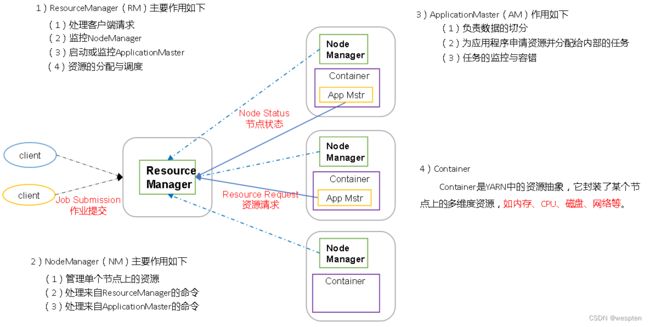
10)Yarn(分布式资源管理器)
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
yarn是下一代 Hadoop 计算平台,yarn是一个通用的运行框架,用户可以编写自己的计算框架,在该运行环境中运行。
用于自己编写的框架作为客户端的一个lib,在运用提交作业时打包即可。
该框架提供了以下几个组件:
① 资源管理:包括应用程序管理和机器资源管理。
② 资源双层调度。
③ 容错性:各个组件均有考虑容错性。
④ 扩展性:可扩展到上万个节点。
Yarn架构:
11)Spark(内存DAG计算模型)
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。
Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。和Hadoop相比,Spark可以让程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
官方网站: Apache Spark™ - Unified Engine for large-scale data analytics
12)Kafka(分布式消息队列)
Kafka是一种高吞吐量的分布式发布/订阅消息系统,这是官方对kafka的定义,kafka是Apache组织下的一个开源系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop平台的数据分析、低时延的实时系统、storm/spark流式处理引擎等。kafka现在它已被多家大型公司作为多种类型的数据管道和消息系统使用。
官方网站: Apache Kafka
6、Hadoop2.x体系结构
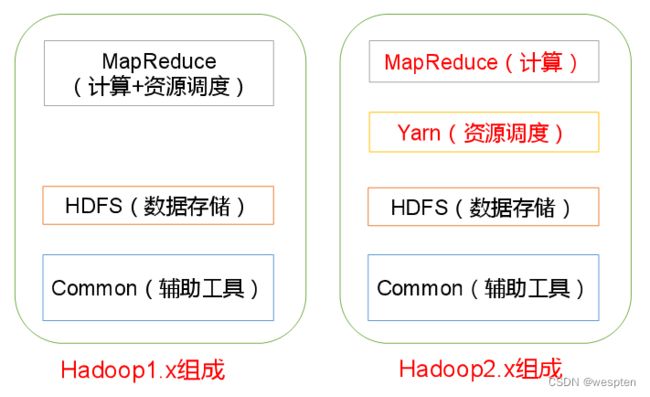
hadoop1.x的核心组成是两部分,即HDFS和MapReduce。

Hadoop1.x HDFS架构:
在Hadoopl.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时代,增加了Yarn,Yarn只负责资源的调度,MapReduce只负责运算。
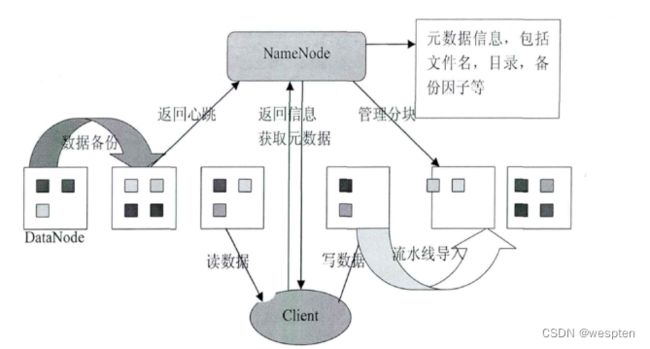
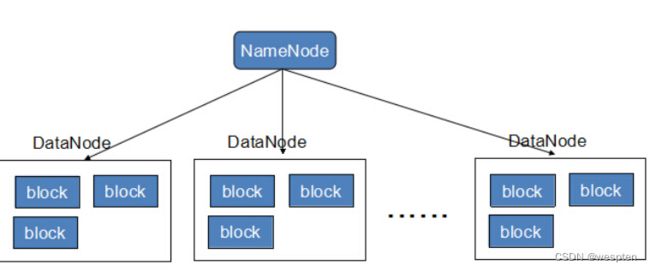
HDFS架构概述:
1)NameNode(mm)∶存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn)∶在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn)∶每隔一段时间对NameNode元数据备份。
YARN架构:
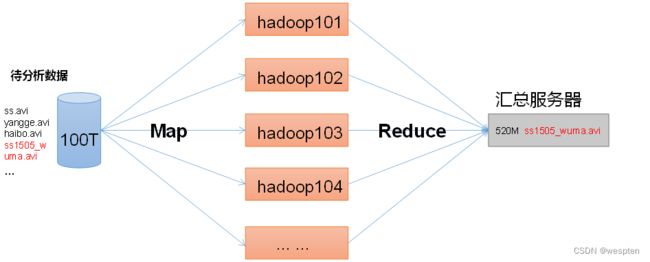
MapReduce架构:
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
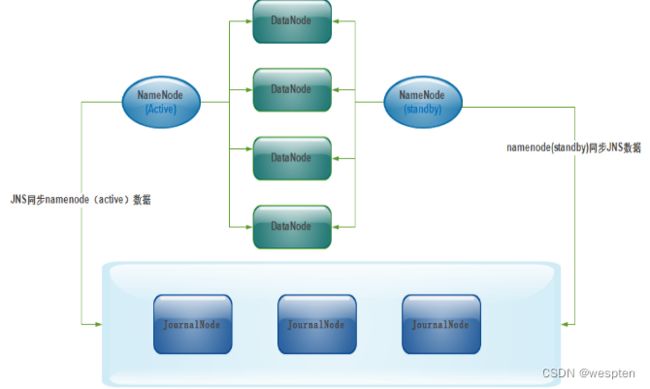
在Hadoop2中新的HDFS中的NameNode不再是只有一个了,可以有多个,每一个都有相同的职能。
1. 两个NameNode的地位如何
一个是active状态的,一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,standby状态的NameNode就可以转变为active状态的,就可以继续工作了,这就是高可靠。
2. 当NameNode发生故障时,数据如何保持一致
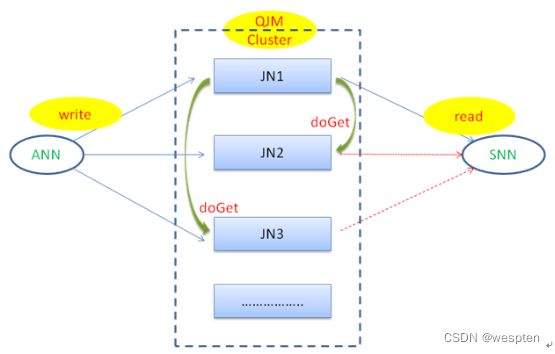
在Hadoop2.0中,新HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者network File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享。
JournalNode集群架构:
3. 如何实现NameNode的自动切换
这就需要使用ZooKeeper集群进行选择了。HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
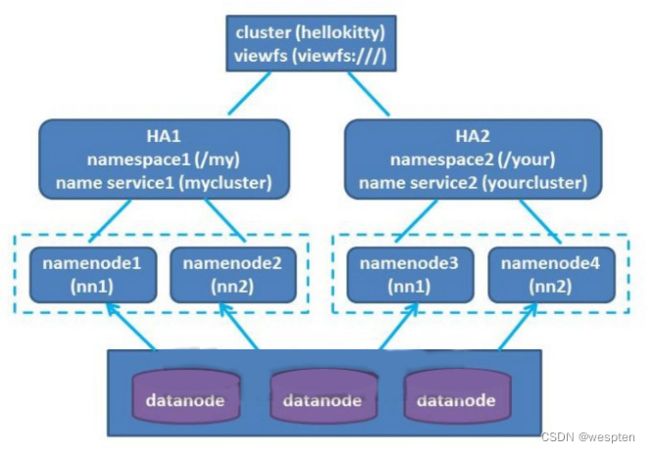
4. HDFS Federation(HDFS联盟)是怎么回事
HDFS联盟的出现是有原因的。我们知道NameNode是核心节点,维护着整个HDFS中的元数据信息,那么其容量是有限的,受制于服务器的内存空间。当NameNode服务器的内存装不下数据后,那么HDFS集群就装不下数据了,寿命也就到头了。因此其扩展性是受限的。HDFS联盟指的是有多个HDFS集群同时工作,那么其容量理论上就不受限了,夸张点说就是无限扩展。
HDFS Federation:
5. 高可用hadoop集群架构
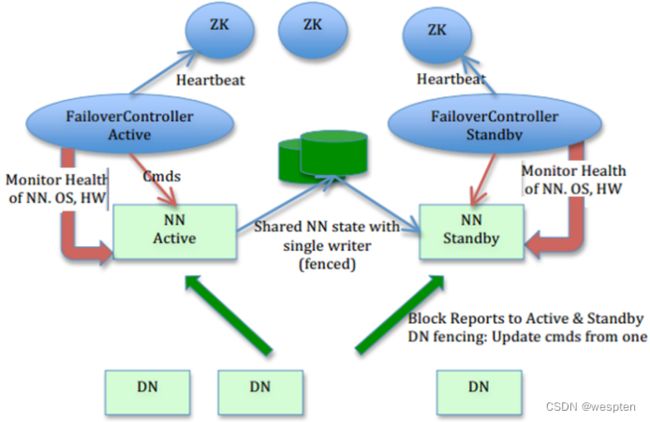
6. JournalNode集群
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
QJM(Qurom Journal Manager)的基本原理就是用2N+1台JournalNode存储EditLog,每次写数据操作有N/2+1个节点返回成功,本次写操作才算成功,保证数据高可用。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效。
7. ZooKeeper集群
ZooKeeper(ZK)集群作为一个高可靠系统,能够为集群协同数据提供监控,将数据的更改随时反应给客户端。HDFS的HA依赖zk提供的两个特性:一个是错误监测,一个是活动节点选举。
1)Failure detection
每个NN都会在ZK中注册并且持久化一个session。一旦一个NN失效了,那么这个session也将过期,那么zk将会通知其他的NN应该发起一个Failover。
2)Active NameNode election
ZK提供了一个简单的机制来保证只有一个NN是活动的。如果当前的活动NN失效了,那么另一个NN将获取ZK中的独占锁,表名自己是活动的节点。
3)ZKFailoverController(ZKFC)
ZKFailoverController 是ZK集群的客户端,用来监控NN的状态信息。每个运行NN的节点必须要运行一个zkfc。
zkfc提供以下功能:
① Health monitoring
zkfc定期对本地的NN发起health-check的命令,如果NN正确返回,那么这个NN被认为是OK的。否则被认为是失效节点。
② ZooKeeper session management
当本地NN是健康的时候,zkfc将会在zk中持有一个session。如果本地NN又正好是active的,那么zkfc将持有一个"ephemeral"的节点作为锁,一旦本地NN失效了,那么这个节点将会被自动删除。
③ ZooKeeper-based election
如果本地NN是健康的,并且zkfc发现没有其他的NN持有那个独占锁。那么他将试图去获取该锁,一旦成功,那么它就需要执行Failover,然后成为active的NN节点。
Failover的过程是:第一步,对之前的NN执行fence,如果需要的话。第二步,将本地NN转换到active状态。
三、Hadoop部署
1、Hadoop发行版
目前Hadoop发行版非常多,有Intel发行版,华为发行版、Cloudera发行版(CDH)、Hortonworks版本等,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,是由于Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并作为开源或商业产品发布/销售。
目前而言,不收费的Hadoop版本主要有三个,都是国外厂商,分别是:
Apache(最原始的版本,所有发行版均基于这个版本进行改进)
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称CDH)
Hortonworks版本(Hortonworks Data Platform,简称“HDP”)
1)Apache Hadoop
官网地址:Apache Hadoop
下载地址:Index of /dist/hadoop/common
2)Cloudera Hadoop
官网地址:CDH Product Download
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。
3)Hortonworks Hadoop
官网地址:Enterprise Data Management Platforms & Products | Cloudera
下载地址:Product Downloads | Cloudera
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(4)Hortonworks目前已经被Cloudera公司收购。
对于国内用户而言,绝大多数选择CDH版本,Cloudera的CDH和Apache的Hadoop的区别如下:
(1) CDH对Hadoop版本的划分非常清晰,截止目前为止,CDH共有5个版本,其中,前三个已经不再更新,最近的两个,分别是CDH4和CDH5,CDH4基于Hadoop2.0,CDH5基于hadoop2.2/2.3/2.5/2.6.相比而言,Apache版本则混乱得多;同时,CDH发行版比Apache hadoop在兼容性,安全性,稳定性上有很大增强。
(2) CDH3是CDH第三个版本,基于Apache hadoop0.20.2改进而来,并融入了最新的patch,CDH4版本是基于Apache hadoop2.0.0改进的,CDH总是并应用了最新Bug修复或者Feature的Patch,并比Apache hadoop同功能版本提早发布,更新速度比Apache官方快。
(3) CDH支持Kerberos安全认证,apache hadoop则使用简陋的用户名匹配认证。
(4) CDH文档完善清晰,很多采用Apache版本的用户都会阅读CDH提供的文档,包括安装文档、升级文档等。
(5) CDH支持yum/apt包,RPM包,tar包,Cloudera Manager三种方式安装,Apache hadoop只支持Tar包安装。
2、CDH发行版本
CDH首先是100%开源,基于Apache协议。基于Apache Hadoop和相关projiect开发。可以做批量处理,交互式sql查询和及时查询,基于角色的权限控制。在企业中使用最广的Hadoop分发版本。
Cloudera完善了CDH的版本,并提供了对hadoop的发布、配置和管理,监控,诊断工具,在官网提供了多种集成发行版。单纯CDH版本下载,目前最新版本为CDH5.15.1,可自由下载并免费无限制使用。
CDH下载地址
官方网站下载页面:Product Downloads | Cloudera
也可以知道到下面地址下载不同版本:
http://archive.cloudera.com/cdh/
http://archive.cloudera.com/cdh4/
CDH与操作系统的依赖
操作系统与JDK版本支持:CDH 5 and Cloudera Manager 5 Requirements and Supported Versions | 5.x | Cloudera Documentation
3、Hadoop编译源码
1. 前期准备工作
1)CentOS联网
配置CentOS能连接外网。Linux虚拟机ping www.baidu.com 是畅通的。
注意:采用root角色编译,减少文件夹权限出现问题。
2)jar包准备(hadoop源码、JDK8、maven、ant 、protobuf)
(1)hadoop-3.1.3-src.tar.gz
(2)jdk-8u212-linux-x64.tar.gz
(3)apache-maven-3.6.3-bin.tar.gz
(4)protobuf-2.5.0.tar.gz(序列化的框架)
(5)cmake-3.13.1.tar.gz
2. Jar包安装
注意:所有操作必须在root用户下完成。
1)上传软件包到指定的目录 ,例如 /opt/software/hadoop_source
[root@hadoop101 hadoop_source]$ pwd
/opt/software/hadoop_source
[root@hadoop101 hadoop_source]$ ll
总用量 55868
-rw-rw-r--. 1 yyds yyds 9506321 3月 28 13:23 apache-maven-3.6.3-bin.tar.gz
-rw-rw-r--. 1 yyds yyds 8614663 3月 28 13:23 cmake-3.13.1.tar.gz
-rw-rw-r--. 1 yyds yyds 29800905 3月 28 13:23 hadoop-3.1.3-src.tar.gz
-rw-rw-r--. 1 yyds yyds 2401901 3月 28 13:23 protobuf-2.5.0.tar.gz2)解压软件包指定的目录,例如: /opt/module/Hadoop_source
[yyds@hadoop101 hadoop_source]$ tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module/hadoop_source/
[yyds@hadoop101 hadoop_source]$ tar -zxvf cmake-3.13.1.tar.gz -C /opt/module/hadoop_source/
[yyds@hadoop101 hadoop_source]$ tar -zxvf hadoop-3.1.3-src.tar.gz -C /opt/module/hadoop_source/
[yyds@hadoop101 hadoop_source]$ tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/hadoop_source/
[yyds@hadoop101 hadoop_source]$ pwd
/opt/module/hadoop_source
[yyds@hadoop101 hadoop_source]$ ll
总用量 20
drwxrwxr-x. 6 yyds yyds 4096 3月 28 13:25 apache-maven-3.6.3
drwxr-xr-x. 15 root root 4096 3月 28 13:43 cmake-3.13.1
drwxr-xr-x. 18 yyds yyds 4096 9月 12 2019 hadoop-3.1.3-src
drwxr-xr-x. 10 yyds yyds 4096 3月 28 13:44 protobuf-2.5.03)确认Java已安装且配置好环境变量,安装完后验证
[yyds@hadoop101 hadoop_source]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)4)配置maven环境变量,maven镜像, 并验证
#配置maven的环境变量
[root@hadoop101 hadoop_source]# vim /etc/profile
#MAVEN_HOME
MAVEN_HOME=/opt/module/hadoop_source/apache-maven-3.6.3
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin
[root@hadoop101 hadoop_source]# source /etc/profile
#修改maven的镜像
[root@hadoop101 apache-maven-3.6.3]# vi conf/settings.xml
# 在 mirrors节点中添加阿里云镜像
nexus-aliyun
central
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
[root@hadoop101 hadoop_source]# mvn -version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /opt/module/hadoop_source/apache-maven-3.6.3
Java version: 1.8.0_212, vendor: Oracle Corporation, runtime: /opt/module/jdk1.8.0_212/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-862.el7.x86_64", arch: "amd64", family: "unix"5)安装相关的依赖(注意安装顺序不可乱,可能会出现依赖找不到问题)
# 安装gcc make
[root@hadoop101 hadoop_source]# yum install -y gcc* make
#安装压缩工具
[root@hadoop101 hadoop_source]# yum -y install snappy* bzip2* lzo* zlib* lz4* gzip*
#安装一些基本工具
[root@hadoop101 hadoop_source]# yum -y install openssl* svn ncurses* autoconf automake libtool
#安装扩展源,才可安装zstd
[root@hadoop101 hadoop_source]# yum -y install epel-release
#安装zstd
[root@hadoop101 hadoop_source]# yum -y install *zstd*6)手动安装cmake
① 在解压好的cmake目录下,执行 ./bootstrap 进行编译,此过程需一小会时间耐心等待。
[yyds@hadoop101 cmake-3.13.1]$ pwd
/opt/module/hadoop_source/cmake-3.13.1
[yyds@hadoop101 cmake-3.13.1]$ ./bootstrap② 执行安装
[yyds@hadoop101 cmake-3.13.1]$ make && make install③ 验证安装是否成功
[yyds@hadoop101 cmake-3.13.1]$ cmake -version
cmake version 3.13.1
CMake suite maintained and supported by Kitware (kitware.com/cmake).7)安装protobuf ,进入到解压后的protobuf目录
[yyds@hadoop101 protobuf-2.5.0]$ pwd
/opt/module/hadoop_source/protobuf-2.5.0
#依次执行下列命令 --prefix 指定安装到当前目录
[yyds@hadoop101 protobuf-2.5.0]$ ./configure --prefix=/opt/module/hadoop_source/protobuf-2.5.0
[yyds@hadoop101 protobuf-2.5.0]$ make && make install
#配置环境变量
[yyds@hadoop101 protobuf-2.5.0]$ vim /etc/profile
PROTOC_HOME=/opt/module/hadoop_source/protobuf-2.5.0
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$PROTOC_HOME/bin
#验证
[yyds@hadoop101 protobuf-2.5.0]$ source /etc/profile
[yyds@hadoop101 protobuf-2.5.0]$ protoc --version
libprotoc 2.5.0到此,软件包安装配置工作完成。
3. 编译源码
1)进入解压后的hadoop源码目录下
[yyds@hadoop101 hadoop-3.1.3-src]$ pwd
/opt/module/hadoop_source/hadoop-3.1.3-src
#开始编译
[yyds@hadoop101 hadoop-3.1.3-src]$ mvn clean package -DskipTests -Pdist,native -Dtar等等等…..等待,第一次编译需要下载很多依赖jar包,编译时间会很久,预计1小时 左右,最终成功是全部SUCCESS,爽!!!
如图:
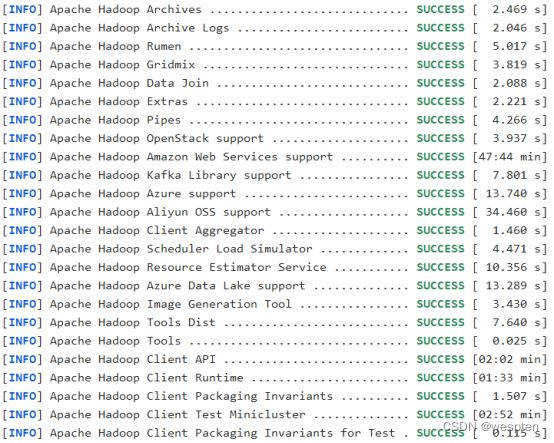
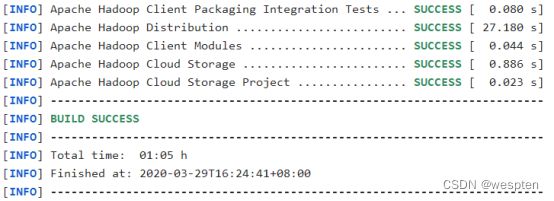
编译成功。
2)成功的64位hadoop包在/opt/hadoop-3.1.3-src/hadoop-dist/target下
[root@hadoop101 target]# pwd
/opt/hadoop-3.1.3-src/hadoop-dist/target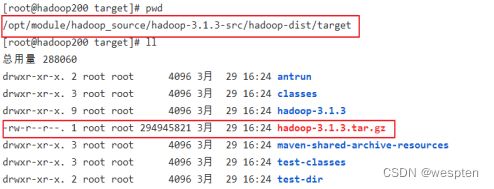
4、常见错误及解决方案
1)防火墙没关闭、或者没有启动YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:80322)主机名称配置错误
3)IP地址配置错误
4)ssh没有配置好
5)root用户和yyds两个用户启动集群不统一
6)配置文件修改不细心
7)未编译源码
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:80328)不识别主机名称
java.net.UnknownHostException: hadoop102: hadoop102
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)解决办法:
(1)在/etc/hosts文件中添加192.168.1.102 hadoop102
(2)主机名称不要起hadoop hadoop000等特殊名称
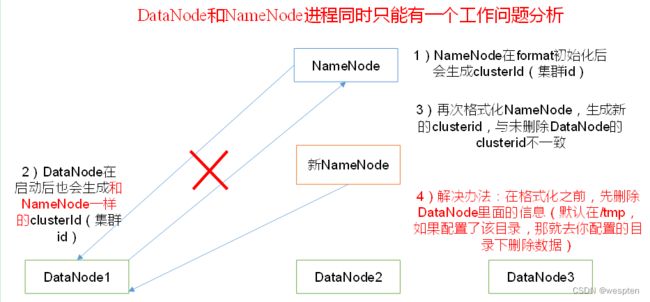
9)DataNode和NameNode进程同时只能工作一个。
10)执行命令不生效,粘贴word中命令时,遇到-和长–没区分开。导致命令失效
解决办法:尽量不要粘贴word中代码。
11)jps发现进程已经没有,但是重新启动集群,提示进程已经开启。原因是在linux的根目录下/tmp目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
12)jps不生效。
原因:全局变量hadoop java没有生效。解决办法:需要source /etc/profile文件。
13)8088端口连接不上
[yyds@hadoop102 桌面]$ cat /etc/hosts
//注释掉如下代码
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 hadoop1025、Hadoop运行环境搭建
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:Apache Hadoop
1. 模板虚拟机环境准备
1)准备一台模板虚拟机hadoop100
虚拟机配置要求如下:
模板虚拟机:内存4G,硬盘50G,安装必要环境,为安装hadoop做准备。
[root@hadoop100 ~]# yum install -y epel-release
[root@hadoop100 ~]# yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git使用yum安装需要虚拟机可以正常上网,yum安装前可以先测试下虚拟机联网情况。
[root@hadoop100 ~]# ping www.baidu.com
PING www.baidu.com (14.215.177.39) 56(84) bytes of data.
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=1 ttl=128 time=8.60 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=2 ttl=128 time=7.72 ms2)关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld3)创建yyds用户,并修改yyds用户的密码
[root@hadoop100 ~]# useradd yyds
[root@hadoop100 ~]# passwd yyds4)配置yyds用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
// 修改/etc/sudoers文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
yyds ALL=(ALL) NOPASSWD:ALL5)在/opt目录下创建文件夹,并修改所属主和所属组
(1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software(2)修改module、software文件夹的所有者和所属组均为yyds用户
[root@hadoop100 ~]# chown yyds:yyds /opt/module
[root@hadoop100 ~]# chown yyds:yyds /opt/software(3)查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
总用量 12
drwxr-xr-x. 2 yyds yyds 4096 5月 28 17:18 module
drwxr-xr-x. 2 root root 4096 9月 7 2017 rh
drwxr-xr-x. 2 yyds yyds 4096 5月 28 17:18 software6)卸载虚拟机自带的open JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps7)重启虚拟机
[root@hadoop100 ~]# reboot2. 克隆虚拟机
1)利用模板机hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
2)修改克隆机IP,以下以hadoop102举例说明
(1)修改克隆虚拟机的静态IP
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33改成:
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.1.102
PREFIX=24
GATEWAY=192.168.1.2
DNS1=192.168.1.2(2)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
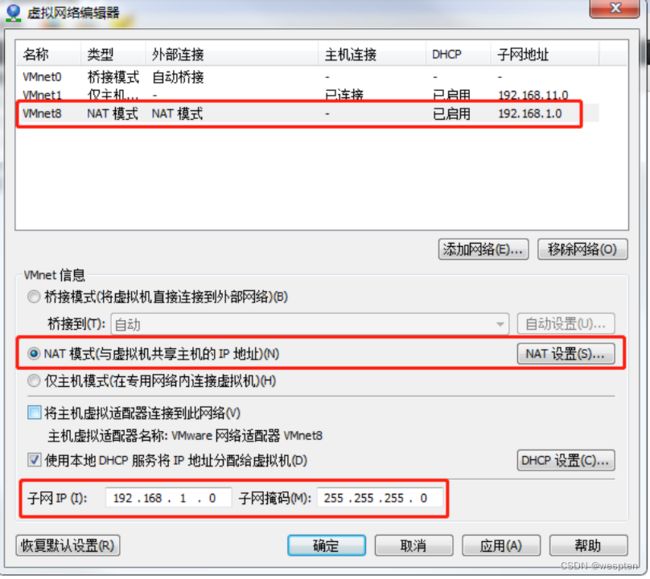
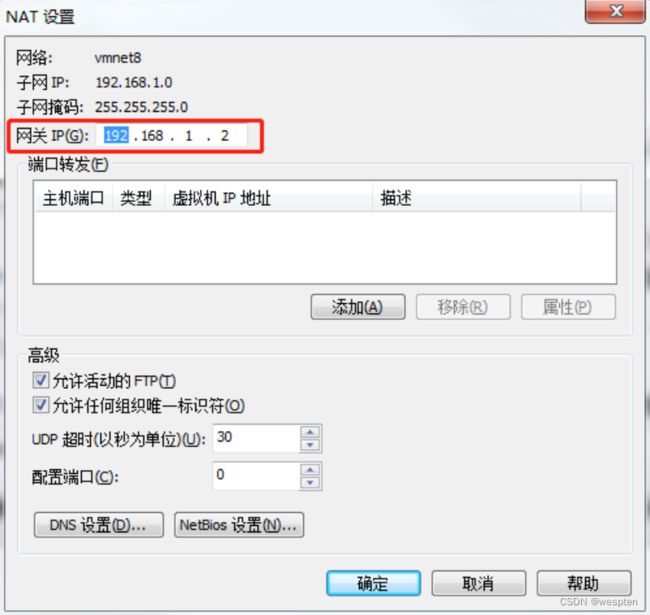
(3)查看Windows系统适配器VMware Network Adapter VMnet8的IP地址
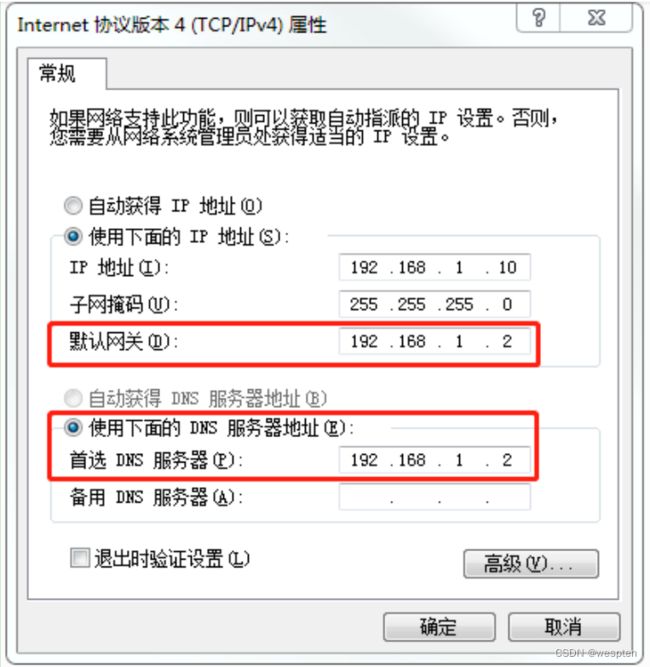
(4)保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
3)修改克隆机主机名,以下以hadoop102举例说明
(1)修改主机名称,两种方法二选一
[root@hadoop100 ~]# hostnamectl --static set-hostname hadoop102或者修改/etc/hostname文件:
[root@hadoop100 ~]# vim /etc/hostname
hadoop102(2)配置linux克隆机主机名称映射hosts文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts添加如下内容:
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop1084)重启克隆机hadoop102
[root@hadoop100 ~]# reboot5)修改windows的主机映射文件(hosts文件)
(1)如果操作系统是window7,可以直接修改
(a)进入C:\Windows\System32\drivers\etc路径
(b)打开hosts文件并添加如下内容,然后保存
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108(2)如果操作系统是window10,先拷贝出来,修改保存以后,再覆盖即可
(a)进入C:\Windows\System32\drivers\etc路径
(b)拷贝hosts文件到桌面
(c)打开桌面hosts文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108(d)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
3. 在hadoop102安装JDK
1)卸载现有JDK
[yyds@hadoop102 ~]$ rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps2)用SecureCRT工具将JDK导入到opt目录下面的software文件夹下面
3) “alt+p”进入sftp模式
4)选择jdk1.8拖入工具
5)在Linux系统下的opt目录中查看软件包是否导入成功
[yyds@hadoop102 ~]$ ls /opt/software/看到如下结果:
hadoop-3.1.3.tar.gz jdk-8u212-linux-x64.tar.gz6)解压JDK到/opt/module目录下
[yyds@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/7)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[yyds@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh添加如下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin(2)保存后退出
:wq(3)source一下/etc/profile文件,让新的环境变量PATH生效
[yyds@hadoop102 ~]$ source /etc/profile8)测试JDK是否安装成功
[yyds@hadoop102 ~]$ java -version如果能看到以下结果,则代表Java安装成功。
java version "1.8.0_212"注意:重启(如果java -version可以用就不用重启)
[yyds@hadoop102 ~]$ sudo reboot4. Hadoop目录结构
1)查看Hadoop目录结构
[yyds@hadoop102 hadoop-3.1.3]$ ll
总用量 52
drwxr-xr-x. 2 yyds yyds 4096 5月 22 2017 bin
drwxr-xr-x. 3 yyds yyds 4096 5月 22 2017 etc
drwxr-xr-x. 2 yyds yyds 4096 5月 22 2017 include
drwxr-xr-x. 3 yyds yyds 4096 5月 22 2017 lib
drwxr-xr-x. 2 yyds yyds 4096 5月 22 2017 libexec
-rw-r--r--. 1 yyds yyds 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 yyds yyds 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 yyds yyds 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 yyds yyds 4096 5月 22 2017 sbin
drwxr-xr-x. 4 yyds yyds 4096 5月 22 2017 share2)重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
5. 在hadoop102安装Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
1)用SecureCRT工具将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
切换到sftp连接页面,选择Linux下编译的hadoop jar包拖入,如图所示:
拖入Hadoop的tar包成功:
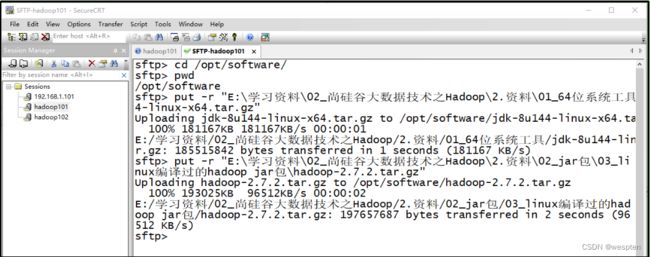
2)进入到Hadoop安装包路径下
[yyds@hadoop102 ~]$ cd /opt/software/3)解压安装文件到/opt/module下面
[yyds@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/4)查看是否解压成功
[yyds@hadoop102 software]$ ls /opt/module/
hadoop-3.1.35)将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[yyds@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3(2)打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin(3)保存后退出
:wq(4)让修改后的文件生效
[yyds@hadoop102 hadoop-3.1.3]$ source /etc/profile6)测试是否安装成功
[yyds@hadoop102 hadoop-3.1.3]$ hadoop version
Hadoop 3.1.37)重启(如果Hadoop命令不能用再重启)
[yyds@hadoop102 hadoop-3.1.3]$ sync
[yyds@hadoop102 hadoop-3.1.3]$ sudo reboot6、Hadoop本地运行模式
1)创建在hadoop-3.1.3文件下面创建一个wcinput文件夹
[yyds@hadoop102 hadoop-3.1.3]$ mkdir wcinput2)在wcinput文件下创建一个word.txt文件
[yyds@hadoop102 hadoop-3.1.3]$ cd wcinput3)编辑word.txt文件
[yyds@hadoop102 wcinput]$ vim word.txt在文件中输入如下内容:
hadoop yarn
hadoop mapreduce
yyds
yyds保存退出:
:wq4)回到Hadoop目录/opt/module/hadoop-3.1.3
5)执行程序
[yyds@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput6)查看结果
[yyds@hadoop102 hadoop-3.1.3]$ cat wcoutput/part-r-00000看到如下结果:
yyds 2
hadoop 2
mapreduce 1
yarn 17、伪分布式安装Hadoop
我们通过伪分布式来迅速安装一个hadoop集群,完全分布式hadoop集群后面介绍。
CDH支持yum/apt包,RPM包,tarball包多种安装方式,根据hadoop运维需要,我们选择tarball的安装方式。
(1)安装规划
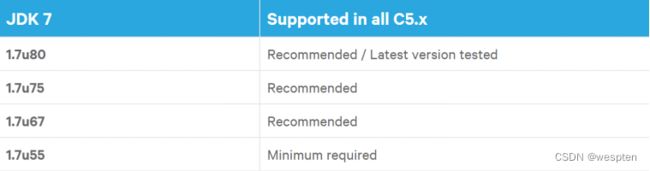
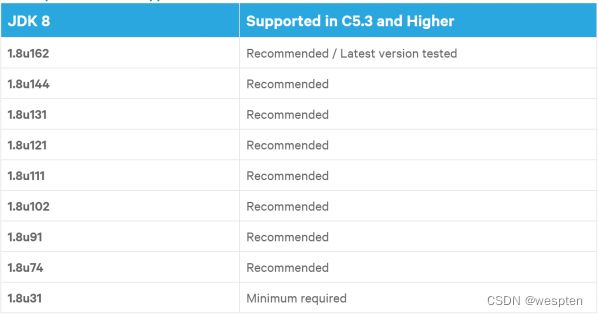
jdk需要oracle JDK1.7.0_55以上,或者JDK1.8.0_31以上。这里将hadoop程序安装到/opt/hadoop目录下,hadoop配置文件放到/etc/hadoop目录下。
(2)安装过程
这里使用的是jdk-8u162-linux-x64 ,将jdk-8u162-linux-x64.tar.gz安装到/usr/java目录下。接着,需要创建一个hadoop用户,然后设置hadoop用户的环境变量,配置如下:
[root@cdh5namenode hadoop]#useradd hadoop
[root@cdh5namenode hadoop]# more /home/hadoop/.bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions
export JAVA_HOME=/usr/java/default
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_PREFIX=/opt/hadoop/current
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HTTPFS_CATALINA_HOME=${HADOOP_PREFIX}/share/hadoop/httpfs/tomcat
export CATALINA_BASE=${HTTPFS_CATALINA_HOME}
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
export HTTPFS_CONFIG=/etc/hadoop/conf
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbintarball方式安装很简单,只需解压文件即可完成安装,然后将解压后的目录放到/opt目录下,进行授权即可:
[root@cdh5namenode opt]#chown -R hadoop:hadoop /opt/hadoop
(3)本地库文件(native-hadoop)支持
Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通过本地库,Hadoop可以更加高效地执行某一些操作。
目前在Hadoop中,本地库应用在文件的压缩上面,主要有gzip和zlib方面,在使用这两种压缩方式的时候,Hadoop默认会从$HADOOP_HOME/lib/native/Linux-*目录中加载本地库。
如果加载失败,输出为:
INFO util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicableCDH4版本之后,hadoop的本地库文件已经不放到CDH的安装包里面了,所以需要另行下载。
一种方式是直接下载源码,自己编译本地库文件,此方法比较麻烦,不推荐,另一种方式是下载apache的hadoop发行版本,这个发行版本中包含有本地库文件。
apache的hadoop发行版本下载地址:
http://archive.apache.org/dist/hadoop/core/从这里下载跟CDH对应的apache发行版本,例如上面下载的是hadoop-2.6.0-cdh5.15.1.tar.gz,这里就从apache发行版本中下载hadoop-2.6.0.tar.gz版本,将下载的此版本解压,找到里面的lib/native本地库文件,复制到CDH5版本对应的路径下就可以了。
如果成功加载native-hadoop本地库,日志会有如下输出:
DEBUG util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
INFO util.NativeCodeLoader - Loaded the native-hadoop library(4)启动Hadoop服务
CDH5新版本的hadoop启动服务脚本位于$HADOOP_HOME/sbin目录下,hadoop的服务启动包含下面几个服务:
1. namenode
2. secondarynamenode
3. datanode
4. resourcemanager
5. nodemanager
这里以hadoop用户来进行管理和启动hadoop的各种服务。
1)启动namenode服务
这里需要修改hadoop配置文件core-site.xml,增加如下内容:
fs.defaultFS
hdfs://cdh5namenode
这里的cdh5namenode是服务器的主机名,需要将此主机名在/etc/hosts进行解析,内容如下:
172.16.213.232 cdh5namenode
接着,就可以启动namenode服务了,要启动namenode服务,首先需要对namenode进行格式化,命令如下:
[hadoop@cdh5namenode ~]$ cd /opt/hadoop/current/bin
[hadoop@cdh5namenode bin]$ hdfs namenode -format格式化完成,就可以启动namenode服务了。
[hadoop@cdh5namenode conf]$ cd /opt/hadoop/current/sbin/
[hadoop@cdh5namenode sbin]$ ./hadoop-daemon.sh start namenode要查看namenode启动日志,可以查看
/opt/hadoop/current/logs/hadoop-hadoop-namenode-cdh5namenode.lognamenode启动完成后,就可以通过web页面查看状态了,默认namenode启动后,会启动50070端口,访问地址为:
http://172.16.213.232:50070
2) 启动datanode服务
启动datanode服务很简单,直接执行如下命令:
[hadoop@cdh5namenode sbin]$ ./hadoop-daemon.sh start datanode可通过/opt/hadoop/current/logs/hadoop-hadoop-datanode-cdh5namenode.log查看datanode启动日志。
3)启动resourcemanager
resourcemanager是yarn框架的服务,用于任务调度和分配,启动方式如下:
[hadoop@cdh5namenode sbin]$ ./yarn-daemon.sh start resourcemanager可通过/opt/hadoop/current/logs/yarn-hadoop-resourcemanager-cdh5namenode.log查看resourcemanager启动日志。
4)启动nodemanager
nodemanager是计算节点,主要用于分布式运算,启动方式如下:
[hadoop@cdh5namenode sbin]$ ./yarn-daemon.sh start nodemanager可通过/opt/hadoop/current/logs/yarn-hadoop-nodemanager-cdh5namenode.log查看nodemanager启动日志。
至此,hadoop伪分布式已经运行起来了。
可通过jps命令查看各个进程的启动信息:
[hadoop@cdh5namenode logs]$ jps
16843 NameNode
16051 DataNode
16382 NodeManager
28851 Jps
16147 ResourceManager(5)运用HADOOP HDFS命令进行分布式存储
[hadoop@cdh5namenode logs]$ hadoop fs -ls /
[hadoop@cdh5namenode logs]$ hadoop fs -mkdir /logs
[hadoop@cdh5namenode logs]$ hadoop fs -put test.txt /logs
[hadoop@cdh5namenode logs]$ hadoop fs -cat /logs/test.txt
(6)在HADOOP中运行Mapreduce程序
hadoop安装包中附带了一个mapreduce的demo程序,我们做个简单的mr计算。在/opt/hadoop/current/share/hadoop/mapreduce路径下找到
hadoop-mapreduce-examples-2.6.0-cdh5.4.1.jar包,我们执行一个wordcount程序,统计一批文件中,相同文件的行数。
[hadoop@cdh5namenode logs]$ hadoop fs -put test.txt /input
[hadoop@cdh5namenode mapreduce]$hadoop jar \
/opt/hadoop/current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.1.jar wordcount /input/ /output/test90其中,/output/test90是输出文件夹,必须不存在,它由程序自动创建,如果预先存在output文件夹,则会报错。
[hadoop@cdh5namenode mapreduce]$ hadoop fs -ls /output/test90
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2016-10-21 17:46 /output/test90/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 225 2016-10-21 17:46 /output/test90/part-r-00000
[hadoop@cdh5namenode mapreduce]$ hadoop fs -cat /output/test90/part-r-00000
GLIBC_2.10 11
GLIBC_2.11 11
8、完全分布式模式
分析:
1)准备3台客户机(关闭防火墙、静态ip、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
1. 编写集群分发脚本xsync
1)scp(secure copy)安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)。
(2)基本语法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称(3)案例实操
前提:在 hadoop102 hadoop103 hadoop104 都已经创建好的 /opt/module
/opt/software 两个目录, 并且已经把这两个目录修改为yyds:yyds
sudo chown yyds:yyds -R /opt/module(a)在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上。
[yyds@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212
yyds@hadoop103:/opt/module(b)在hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上。
[yyds@hadoop103 ~]$ scp -r yyds@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/(c)在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上。
[yyds@hadoop103 opt]$ scp -r yyds@hadoop102:/opt/module/*
yyds@hadoop104:/opt/module2)rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更
新。scp是把所有文件都复制过去。
(1)基本语法
rsync -av $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称选项参数说明:
| 选项 |
功能 |
| -a |
归档拷贝 |
| -v |
显示复制过程 |
(2)案例实操
(a)把hadoop102机器上的/opt/software目录同步到hadoop103服务器的/opt/software目录下
[yyds@hadoop102 opt]$ rsync -av /opt/software/*
yyds@hadoop103:/opt/software3)xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module root@hadoop103:/opt/(b)期望脚本:
xsync要同步的文件名称。
(c)说明:在/home/yyds/bin这个目录下存放的脚本,yyds用户可以在系统任何地方直接执行。
(3)脚本实现
(a)在/home/yyds/bin目录下创建xsync文件
[yyds@hadoop102 opt]$ cd /home/yyds
[yyds@hadoop102 ~]$ mkdir bin
[yyds@hadoop102 ~]$ cd bin
[yyds@hadoop102 bin]$ vim xsync在该文件中编写如下代码:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done(b)修改脚本 xsync 具有执行权限
[yyds@hadoop102 bin]$ chmod +x xsync(c)将脚本复制到/bin中,以便全局调用
[yyds@hadoop102 bin]$ sudo cp xsync /bin/(d)测试脚本
[yyds@hadoop102 ~]$ xsync /home/yyds/bin
[yyds@hadoop102 bin]$ sudo xsync /bin/xsync2. SSH无密登录配置
1)配置ssh
(1)基本语法
ssh另一台电脑的ip地址
(2)ssh连接时出现Host key verification failed的解决方法
[yyds@hadoop102 ~]$ ssh hadoop103出现:
The authenticity of host '192.168.1.103 (192.168.1.103)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)? (3)解决方案如下:直接输入yes
2)无密钥配置
(1)免密登录原理
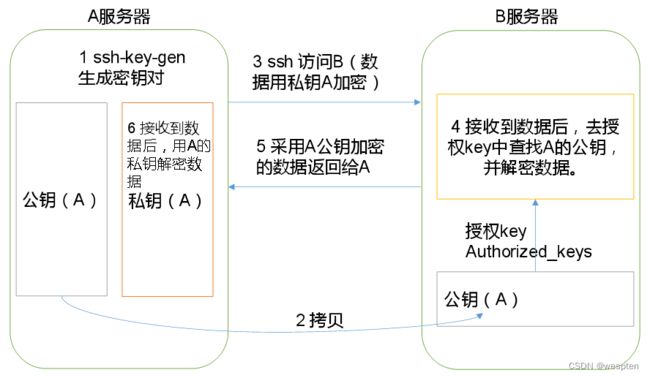
(2)生成公钥和私钥
[yyds@hadoop102 .ssh]$ ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[yyds@hadoop102 .ssh]$ ssh-copy-id hadoop102
[yyds@hadoop102 .ssh]$ ssh-copy-id hadoop103
[yyds@hadoop102 .ssh]$ ssh-copy-id hadoop104注意:
还需要在hadoop103上采用yyds账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop104上采用yyds账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
3).ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts |
记录ssh访问过计算机的公钥(public key) |
| id_rsa |
生成的私钥 |
| id_rsa.pub |
生成的公钥 |
| authorized_keys |
存放授权过的无密登录服务器公钥 |
3. 集群配置
1)集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop102 |
hadoop103 |
hadoop104 |
|
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2)配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件
| 要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
| [core-default.xml] |
hadoop-common-3.1.3.jar/ core-default.xml |
| [hdfs-default.xml] |
hadoop-hdfs-3.1.3.jar/ hdfs-default.xml |
| [yarn-default.xml] |
hadoop-yarn-common-3.1.3.jar/ yarn-default.xml |
| [mapred-default.xml] |
hadoop-mapreduce-client-core-3.1.3.jar/ mapred-default.xml |
(1)默认配置文件:
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
(3)常用端口号说明
| Daemon |
App |
Hadoop2 |
Hadoop3 |
| NameNode Port |
Hadoop HDFS NameNode |
8020 / 9000 |
9820 |
| Hadoop HDFS NameNode HTTP UI |
50070 |
9870 |
|
| Secondary NameNode Port |
Secondary NameNode |
50091 |
9869 |
| Secondary NameNode HTTP UI |
50090 |
9868 |
|
| DataNode Port |
Hadoop HDFS DataNode IPC |
50020 |
9867 |
| Hadoop HDFS DataNode |
50010 |
9866 |
|
| Hadoop HDFS DataNode HTTP UI |
50075 |
9864 |
3)配置集群
(1)核心配置文件
配置core-site.xml
[yyds@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[yyds@hadoop102 hadoop]$ vim core-site.xml文件内容如下:
fs.defaultFS
hdfs://hadoop102:9820
hadoop.tmp.dir
/opt/module/hadoop-3.1.3/data
hadoop.http.staticuser.user
yyds
hadoop.proxyuser.yyds.hosts
*
hadoop.proxyuser.yyds.groups
*
hadoop.proxyuser.yyds.groups
*
(2)HDFS配置文件
配置hdfs-site.xml
[yyds@hadoop102 hadoop]$ vim hdfs-site.xml文件内容如下:
dfs.namenode.http-address
hadoop102:9870
dfs.namenode.secondary.http-address
hadoop104:9868
(3)YARN配置文件
配置yarn-site.xml
[yyds@hadoop102 hadoop]$ vim yarn-site.xml文件内容如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop103
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
4096
yarn.nodemanager.resource.memory-mb
4096
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
(4)MapReduce配置文件
配置mapred-site.xml
[yyds@hadoop102 hadoop]$ vim mapred-site.xml文件内容如下:
mapreduce.framework.name
yarn
4)在集群上分发配置好的Hadoop配置文件
[yyds@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/5)去103和104上查看文件分发情况
[yyds@hadoop103 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[yyds@hadoop104 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml4. 群起集群
1)配置workers
[yyds@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件:
[yyds@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc2)启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[yyds@hadoop102 ~]$ hdfs namenode -format(2)启动HDFS
[yyds@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh(3)在配置了ResourceManager的节点(hadoop103)启动YARN
[yyds@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh(4)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
(5)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
3)集群基本测试
(1)上传文件到集群
上传小文件:
[yyds@hadoop102 ~]$ hadoop fs -mkdir /input
[yyds@hadoop102 ~]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input上传大文件:
[yyds@hadoop102 ~]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /(2)上传文件后查看文件存放在什么位置
(a)查看HDFS文件存储路径
[yyds@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-938951106-192.168.10.107-1495462844069/current/finalized/subdir0/subdir0(b)查看HDFS在磁盘存储文件内容
[yyds@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
yyds
yyds(3)拼接
-rw-rw-r--. 1 yyds yyds 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 yyds yyds 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 yyds yyds 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 yyds yyds 495635 5月 23 16:01 blk_1073741837_1013.meta
[yyds@hadoop102 subdir0]$ cat blk_1073741836>>tmp.tar.gz
[yyds@hadoop102 subdir0]$ cat blk_1073741837>>tmp.tar.gz
[yyds@hadoop102 subdir0]$ tar -zxvf tmp.tar.gz(4)下载
[yyds@hadoop104 software]$ hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./(5)执行wordcount程序
[yyds@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output5. 集群启动/停止方式总结
1)各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode(2)启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager2)各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh6. 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1)配置mapred-site.xml
[yyds@hadoop102 hadoop]$ vim mapred-site.xml在该文件里面增加如下配置。
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
2)分发配置
[yyds@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml3)在hadoop102启动历史服务器
[yyds@hadoop102 hadoop]$ mapred --daemon start historyserver4)查看历史服务器是否启动
[yyds@hadoop102 hadoop]$ jps5)查看JobHistory
http://hadoop102:19888/jobhistory
7. 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
1)配置yarn-site.xml
[yyds@hadoop102 hadoop]$ vim yarn-site.xml在该文件里面增加如下配置:
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
2)分发配置
[yyds@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml3)关闭NodeManager 、ResourceManager和HistoryServer
[yyds@hadoop103 ~]$ stop-yarn.sh
[yyds@hadoop102 ~]$ mapred --daemon stop historyserver4)启动NodeManager 、ResourceManage和HistoryServer
[yyds@hadoop103 ~]$ start-yarn.sh
[yyds@hadoop102 ~]$ mapred --daemon start historyserver5)删除HDFS上已经存在的输出文件
[yyds@hadoop102 ~]$ hadoop fs -rm -r /output6)执行WordCount程序
[yyds@hadoop102 ~]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output7)查看日志
http://hadoop102:19888/jobhistory
Job History:
job运行情况:
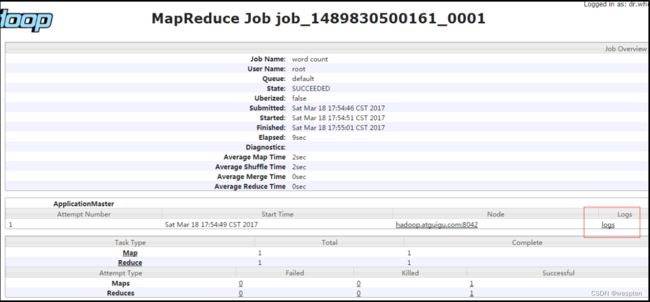
查看日志:
8. 编写hadoop集群常用脚本
1)查看三台服务器java进程脚本:jpsall
[yyds@hadoop102 ~]$ cd /home/yyds/bin
[yyds@hadoop102 ~]$ vim jpsall然后输入:
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps $@ | grep -v Jps
done保存后退出,然后赋予脚本执行权限:
[yyds@hadoop102 bin]$ chmod +x jpsall2)hadoop集群启停脚本(包含hdfs,yarn,historyserver):myhadoop.sh
[yyds@hadoop102 ~]$ cd /home/yyds/bin
[yyds@hadoop102 ~]$ vim myhadoop.sh然后输入:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac保存后退出,然后赋予脚本执行权限:
[yyds@hadoop102 bin]$ chmod +x myhadoop.sh3)分发/home/yyds/bin目录,保证自定义脚本在三台机器上都可以使用
[yyds@hadoop102 ~]$ xsync /home/yyds/bin/9. 集群时间同步
间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。

配置时间同步具体实操:
1)时间服务器配置(必须root用户)
(0)查看所有节点ntpd服务状态和开机自启动状态
[yyds@hadoop102 ~]$ sudo systemctl status ntpd
[yyds@hadoop102 ~]$ sudo systemctl is-enabled ntpd(1)在所有节点关闭ntpd服务和自启动
[yyds@hadoop102 ~]$ sudo systemctl stop ntpd
[yyds@hadoop102 ~]$ sudo systemctl disable ntpd(2)修改hadoop102的ntp.conf配置文件(要将hadoop102作为时间服务器)
[yyds@hadoop102 ~]$ sudo vim /etc/ntp.conf修改内容如下:
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为:
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrapb)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburstc)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10(3)修改hadoop102的/etc/sysconfig/ntpd 文件
[yyds@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes(4)重新启动ntpd服务
[yyds@hadoop102 ~]$ sudo systemctl start ntpd(5)设置ntpd服务开机启动
[yyds@hadoop102 ~]$ sudo systemctl enable ntpd2)其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[yyds@hadoop103 ~]$ sudo crontab -e编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102(2)修改任意机器时间
[yyds@hadoop103 ~]$ sudo date -s "2017-9-11 11:11:11"(3)十分钟后查看机器是否与时间服务器同步
[yyds@hadoop103 ~]$ sudo date说明:测试的时候可以将10分钟调整为1分钟,节省时间。
四、HDFS存储架构
1、HDFS简介
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景∶适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
2、HDFS优缺点
1. 优点
1)高容错性
(1)数据自动保存多份副本,它通增加副本的形式,提高容错性。
![]()
(2)某一个副本丢失以后,它可以自动恢复。

2)适合处理大数据
(1)数据规模∶能够处理数据规模达到GB、TB、甚至PB级别的数据。
(2)文件规模∶能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性。
2. 缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
(1)存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
(2)小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改。
(1)一个文件只能有一个写,不允许多个线程同时写;
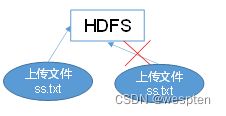
(2)仅支持数据append(追加),不支持文件的随机修改。
3、HDFS结构与架构
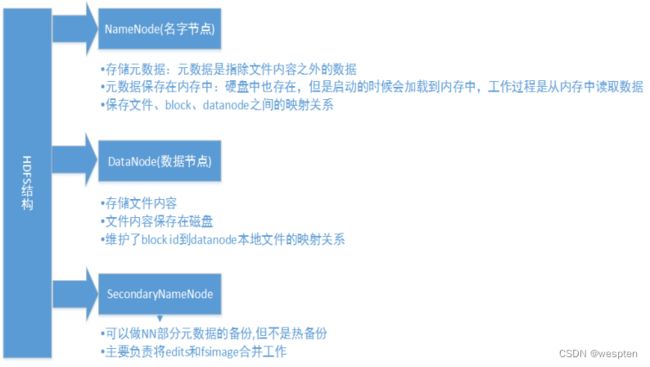
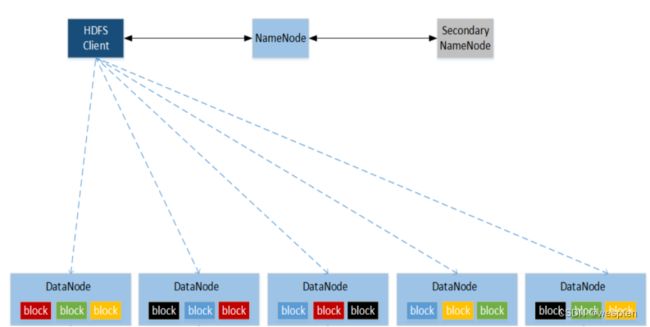
HDFS组成架构:
1)NameNode(nn)∶就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端读写请求;
2)DataNode ∶就是Slave。NameNode 下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作;
3)Client∶就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如NameNode格式化;
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
4)Secondary NameNode∶并非NameNode的热备,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
(2)在紧急情况下,可辅助恢复NameNode。
HDFS分布式文件系统架构:
4、 NameNode与SecondaryNameNode
1)NameNode工作机制
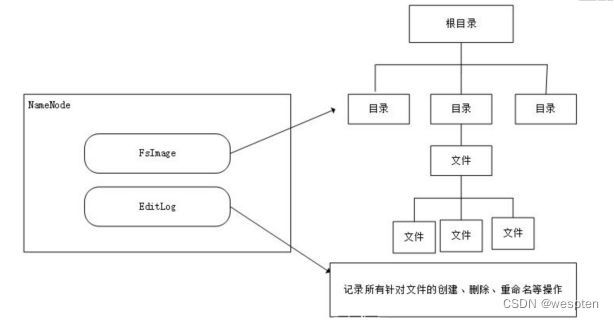
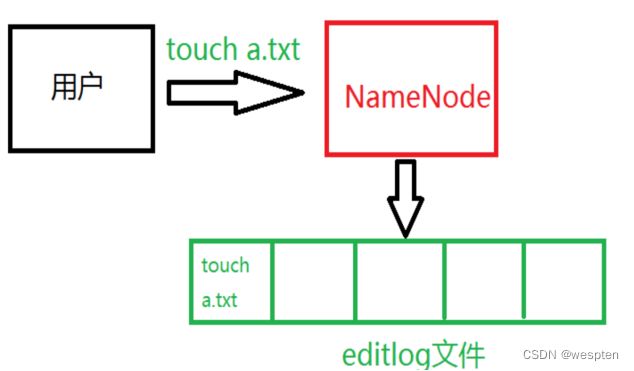
Namenode上保存着 HDFS 的名字空间。对于任何对文件系统元数据产生修改的操作, Namenode 都会使用一种称为 EditLog 的事务日志记录下来。例如,在 HDFS 中创建一个文件, Namenode 就会在 Editlog 中插入一条记录来表示。
同样地,修改文件的副本系数也将往 Editlog 插入一条记录。 Namenode 在本地操作系统的文件系统中存储这个 Editlog 。整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等,都存储在一个称为FsImage的文件中,这个文件也是放在 Namenode 所在的本地文件系统上。
FsImage和Editlog是HDFS的核心数据结构,它们组成了Namenode元数据信息(metadata),这些元数据信息的损坏会导致整个集群的失效。因此,名字节点可以配置成支持多个FsImage和EditLog的副本。任何FsImage和EditLog的更新都会同步到每一份副本中。
当 Namenode 启动时,它从硬盘中读取 Editlog 和 FsImage ,将所有 Editlog 中的事务作 用在内存中的 FsImage 上,并将这个新版本的 FsImage 从内存中保存到本地磁盘上,然后删除 旧的 Editlog ,因为这个旧的 Editlog 的事务都已经作用在 FsImage 上了。这个过程称为一个检查 点 (checkpoint) 。在当前实现中,检查点只发生在 Namenode 启动时,在不久的将来将实现支持 周期性的检查点。
元数据管理机制:
(1)元数据有3中存储形式:内存、edits日志、fsimage
(2)最完整最新的元数据一定是内存中的这一部分
Namenode元数据文件解析:
version :是一个properties文件,保存了HDFS的版本号
editlog :任何对文件系统数据产生的操作,都会被保存!
fsimage /.md5:文件系统元数据的一个永久性的检查点,包括数据块到文件的映射、文件的属性等
seen_txid :非常重要,是存放事务相关信息的文件
Namenode 的目录结构:
${ dfs.name.dir}/current /VERSION
/edits
/fsimage
/fstimedfs.name.dir 是 hdfs-site.xml 里配置的若干个目录组成的列表。
EditLog文件不断变大的问题:
在名称节点运行期间,HDFS的所有更新操作都是直接到EditLog,一段时间之后,EditLog文件会变得很大,虽然这对名称节点运行时候没有什么明显影响,但是,当名称节点重启时候,名称节点需要先将FsImage里面的所有内容映象到内存,然后一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作会非常的慢。
此时就需要另一个功能模块:secondaryNameNode。
2)secondaryNameNode工作机制
secondaryNameNode 作用:
(1)Namenode的一个快照,周期性的备份Namenode。
(2)记录Namenode中的metadata及其它数据。
(3)可以用来恢复Namenode,并不能替代NameNode。
SecondaryNameNode执行流程:
(1)SecondaryNameNode节点会定期和NameNode通信,请求其停止使用EditLog,暂时将新的写操作到一个新的文件edit.new上来,这个操作是瞬间完成的。
(2)SecondaryNameNode 通过HTTP Get方式从NameNode上获取到FsImage和EditLog文件并下载到本地目录。
(3)将下载下来的FsImage和EditLog加载到内存中这个过程就是FsImage和EditLog的合并(checkpoint)。
(4)合并成功之后,会通过post方式将新的FsImage文件发送NameNode上。
(5)Namenode 会将新接收到的FsImage替换掉旧的,同时将edit.new替换EditLog,这样EditLog就会变小。
3)NN和2NN工作机制
思考:NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
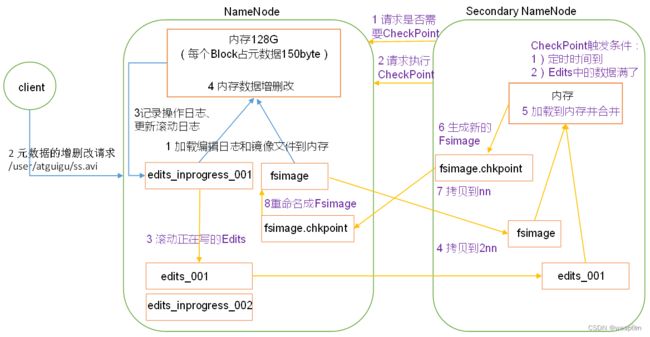
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
NN和2NN工作机制详解:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
4)Fsimage和Edits解析
NameNode被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current目录中产生如下文件:
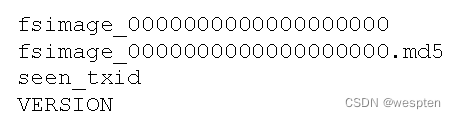
(1)Fsimage文件∶HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
(2)Edits文件∶存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
(3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字
(4)每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
① oiv查看Fsimage文件
(1)查看oiv和oev命令
[yyds@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[yyds@hadoop102 current]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
[yyds@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
[yyds@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/fsimage.xml将显示的xml文件内容拷贝到IDEA中创建的xml文件中,并格式化。
部分显示结果如下:
16386
DIRECTORY
user
1512722284477
yyds:supergroup:rwxr-xr-x
-1
-1
16387
DIRECTORY
yyds
1512790549080
yyds:supergroup:rwxr-xr-x
-1
-1
16389
FILE
wc.input
3
1512722322219
1512722321610
134217728
yyds:supergroup:rw-r--r--
1073741825
1001
59
可以看出,Fsimage中没有记录块所对应DataNode,为什么?
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
② oev查看Edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径(2)案例实操
[yyds@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
[yyds@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/edits.xml将显示的xml文件内容拷贝到Eclipse中创建的xml文件中,并格式化。
显示结果如下:
-63
OP_START_LOG_SEGMENT
129
OP_ADD
130
0
16407
/hello7.txt
2
1512943607866
1512943607866
134217728
DFSClient_NONMAPREDUCE_-1544295051_1
192.168.1.5
true
yyds
supergroup
420
908eafd4-9aec-4288-96f1-e8011d181561
0
OP_ALLOCATE_BLOCK_ID
131
1073741839
OP_SET_GENSTAMP_V2
132
1016
OP_ADD_BLOCK
133
/hello7.txt
1073741839
0
1016
-2
OP_CLOSE
134
0
0
/hello7.txt
2
1512943608761
1512943607866
134217728
false
1073741839
25
1016
yyds
supergroup
420
思考:NameNode如何确定下次开机启动的时候合并哪些Edits?
③ CheckPoint时间设置
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
hdfs-default.xml:
dfs.namenode.checkpoint.period
3600s
2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次:
dfs.namenode.checkpoint.txns
1000000
操作动作次数
dfs.namenode.checkpoint.check.period
60s
1分钟检查一次操作次数
④ NameNode故障处理(扩展)
NameNode故障后,可以采用如下两种方法恢复数据。
1)将SecondaryNameNode中数据拷贝到NameNode存储数据的目录
(1)kill -9 NameNode进程
(2)删除NameNode存储的数据(/opt/module/hadoop-3.1.3/data/tmp/dfs/name)
[yyds@hadoop102 hadoop-3.1.3]$ rm -rf /opt/module/hadoop-3.1.3/data/dfs/name/*(3)拷贝SecondaryNameNode中数据到原NameNode存储数据目录
[yyds@hadoop102 dfs]$ scp -r yyds@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary/* ./name/(4)重新启动NameNode
[yyds@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode2)使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中
(1)修改hdfs-site.xml中的
dfs.namenode.checkpoint.period
120
dfs.namenode.name.dir
/opt/module/hadoop-3.1.3/data/dfs/name
(2)kill -9 NameNode进程
(3)删除NameNode存储的数据(/opt/module/hadoop-3.1.3/data/dfs/name)
[yyds@hadoop102 hadoop-3.1.3]$ rm -rf /opt/module/hadoop-3.1.3/data/dfs/name/*(4)如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
[yyds@hadoop102 dfs]$ scp -r yyds@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary ./
[yyds@hadoop102 namesecondary]$ rm -rf in_use.lock
[yyds@hadoop102 dfs]$ pwd
/opt/module/hadoop-3.1.3/data/dfs
[yyds@hadoop102 dfs]$ ls
data name namesecondary(5)导入检查点数据(等待一会ctrl+c结束掉)
[yyds@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode -importCheckpoint(6)启动NameNode
[yyds@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode5)集群安全模式
(1)NameNode启动
NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个空的编辑日志。此时,NameNode开始监听DataNode请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
(2)DataNode启动
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
(3)安全模式退出判断
如果满足"最小副本条件",NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值∶dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
(4)基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)(5)模拟等待安全模式
查看当前模式:
[yyds@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -safemode get
Safe mode is OFF先进入安全模式:
[yyds@hadoop102 hadoop-3.1.3]$ bin/hdfs dfsadmin -safemode enter(6)创建并执行下面的脚本
在/opt/module/hadoop-3.1.3路径上,编辑一个脚本safemode.sh:
[yyds@hadoop102 hadoop-3.1.3]$ touch safemode.sh
[yyds@hadoop102 hadoop-3.1.3]$ vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-3.1.3/README.txt /
[yyds@hadoop102 hadoop-3.1.3]$ chmod 777 safemode.sh
[yyds@hadoop102 hadoop-3.1.3]$ ./safemode.sh 再打开一个窗口,执行:
[yyds@hadoop102 hadoop-3.1.3]$ bin/hdfs dfsadmin -safemode leave观察上一个窗口:
Safe mode is OFFHDFS集群上已经有上传的数据了。
6)NameNode多目录配置
NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
具体配置如下:
(1)在hdfs-site.xml文件中添加如下内容
dfs.namenode.name.dir
file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2
(2)停止集群,删除三台节点的data和logs中所有数据
[yyds@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[yyds@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[yyds@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/(3)格式化集群并启动
[yyds@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode –format
[yyds@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh(4)查看结果
[yyds@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 yyds yyds 4096 12月 11 08:03 data
drwxrwxr-x. 3 yyds yyds 4096 12月 11 08:03 name1
drwxrwxr-x. 3 yyds yyds 4096 12月 11 08:03 name2
5、DataNode
1)DataNode工作机制
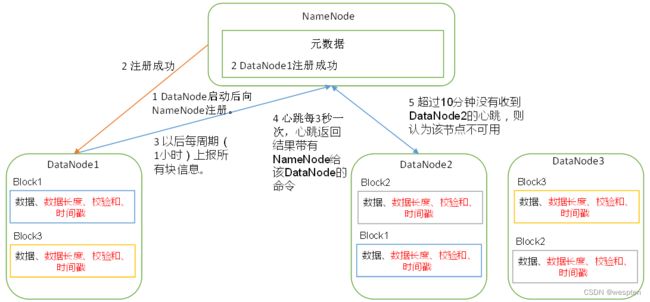
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
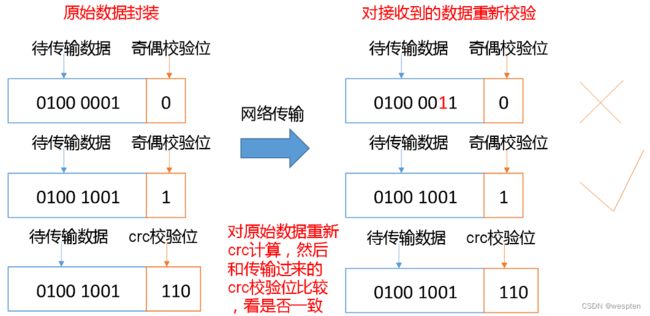
2)数据完整性
思考:如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是DataNode节点保证数据完整性的方法:
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)常见的校验算法 crc(32),md5(128),sha1(160)
(5)DataNode在其文件创建后周期验证CheckSum。
3)掉线时限参数设置
DataNode掉线时限参数设置:
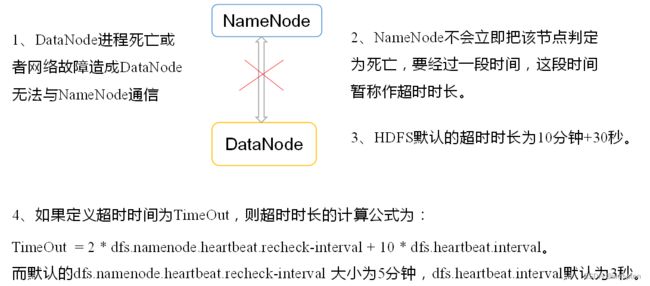
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
dfs.namenode.heartbeat.recheck-interval
300000
dfs.heartbeat.interval
3
4)服役新数据节点
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
1. 环境准备
(1)在hadoop104主机上再克隆一台hadoop105主机
(2)修改IP地址和主机名称
(3)删除原来HDFS文件系统留存的文件(/opt/module/hadoop-3.1.3/data和logs)
(4)source一下配置文件
[yyds@hadoop105 hadoop-3.1.3]$ source /etc/profile2. 服役新节点具体步骤
(1)直接启动DataNode,即可关联到集群
[yyds@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[yyds@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager
(2)在hadoop105上上传文件
[yyds@hadoop105 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /(3)如果数据不均衡,可以用命令实现集群的再平衡
[yyds@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-yyds-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved5)退役旧数据节点
1. 添加白名单和黑名单
白名单和黑名单是hadoop管理集群主机的一种机制。
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。添加到黑名单的主机节点,不允许访问NameNode,会在数据迁移后退出。
实际情况下,白名单用于确定允许访问NameNode的DataNode节点,内容配置一般与workers文件内容一致。 黑名单用于在集群运行过程中退役DataNode节点。
配置白名单和黑名单的具体步骤如下:
1)在NameNode节点的/opt/module/hadoop-3.1.3/etc/hadoop目录下分别创建whitelist 和blacklist文件
[yyds@hadoop102 hadoop]$ pwd
/opt/module/hadoop-3.1.3/etc/hadoop
[yyds@hadoop102 hadoop]$ touch whitelist
[yyds@hadoop102 hadoop]$ touch blacklist在whitelist中添加如下主机名称,假如集群正常工作的节点为102 103 104 105:
hadoop102
hadoop103
hadoop104
hadoop105黑名单暂时为空。
2)在hdfs-site.xml配置文件中增加dfs.hosts和 dfs.hosts.exclude配置参数
dfs.hosts
/opt/module/hadoop-3.1.3/etc/hadoop/whitelist
dfs.hosts.exclude
/opt/module/hadoop-3.1.3/etc/hadoop/blacklist
3)分发配置文件whitelist,blacklist,hdfs-site.xml (注意:105节点也要发一份)
[yyds@hadoop102 etc]$ xsync hadoop/
[yyds@hadoop102 etc]$ rsync -av hadoop/ yyds@hadoop105:/opt/module/hadoop-3.1.3/etc/hadoop/4)重新启动集群(注意:105节点没有添加到workers,因此要单独起停)
[yyds@hadoop102 hadoop-3.1.3]$ stop-dfs.sh
[yyds@hadoop102 hadoop-3.1.3]$ start-dfs.sh
[yyds@hadoop105 hadoop-3.1.3]$ hdfs –daemon start datanode5)在web浏览器上查看目前正常工作的DN节点
2. 黑名单退役
1)编辑/opt/module/hadoop-3.1.3/etc/hadoop目录下的blacklist文件
[yyds@hadoop102 hadoop] vim blacklist添加如下主机名称(要退役的节点):
hadoop1052)分发blacklist到所有节点
[yyds@hadoop102 etc]$ xsync hadoop/
[yyds@hadoop102 etc]$ rsync -av hadoop/ yyds@hadoop105:/opt/module/hadoop-3.1.3/etc/hadoop/3)刷新NameNode、刷新ResourceManager
[yyds@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[yyds@hadoop102 hadoop-3.1.3]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:80334)检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点

5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役

[yyds@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanodestopping datanode
[yyds@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanagerstopping nodemanager
6)如果数据不均衡,可以用命令实现集群的再平衡
[yyds@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-yyds-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved注意:不允许白名单和黑名单中同时出现同一个主机名称,既然使用了黑名单blacklist成功退役了hadoop105节点,因此要将白名单whitelist里面的hadoop105去掉。
3. DataNode多目录配置
1)DataNode可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
2)具体配置如下
(1)在hdfs-site.xml文件中添加如下内容
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2
(2)停止集群,删除三台节点的data和logs中所有数据。
[yyds@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[yyds@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[yyds@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/(3)格式化集群并启动。
[yyds@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode –format
[yyds@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh(4)查看结果
[yyds@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 yyds yyds 4096 4月 4 14:22 data1
drwx------. 3 yyds yyds 4096 4月 4 14:22 data2
drwxrwxr-x. 3 yyds yyds 4096 12月 11 08:03 name1
drwxrwxr-x. 3 yyds yyds 4096 12月 11 08:03 name26、HDFS运行机制以及数据存储单元(block)
HDFS文件块大小:
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2x版本中是128M,老版本中是64M。
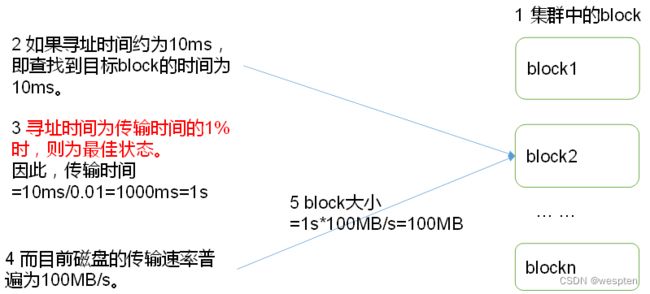
为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结∶HDFS块的大小设置主要取决于磁盘传输速率。
HDFS数据存储机制:
1. 一次写入,多次读取(不可修改)。
2. 文件由数据块组成,Hadoop2.x的块大小默认是128MB,若文件大小不足128M,则也会单独存成一个block,一个块只能存一个文件的数据,及时一个文件不足128M,也会占用一个block,块是一个逻辑空间,并不会占磁盘空间。
3. 默认情况下每个block都有三个副本,三个副本会存储到不同的节点上。副本越多,磁盘利用率越低,但是数据的安全性越高。可以通过修改hdfs-site.xml的dfs.replication属性设置产生副本的个数。
4. 文件按大小被切分成若干个block,存储到不同的节点上,hadoop1.x的默认数据块大小64M ,hadoop2.x的默认数据块大小128M,block块大小可配置。
HDFS文件名组成格式为:
blk_:HDFS的数据块,保存具体的二进制数据
blk_.meta:数据块的属性信息:版本信息、类型信息 7、HDFS写入数据流程解析
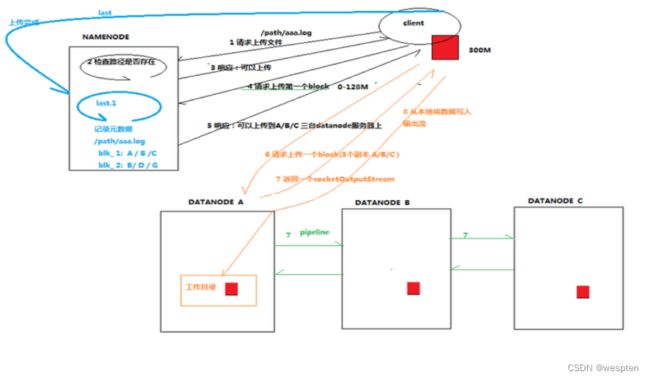
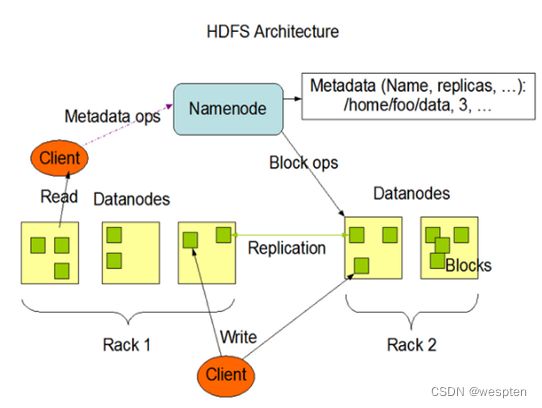
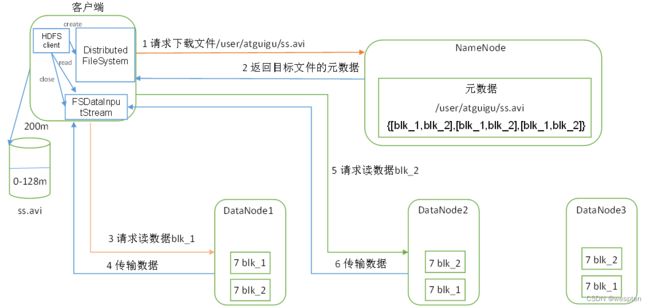
1)HDFS写数据流
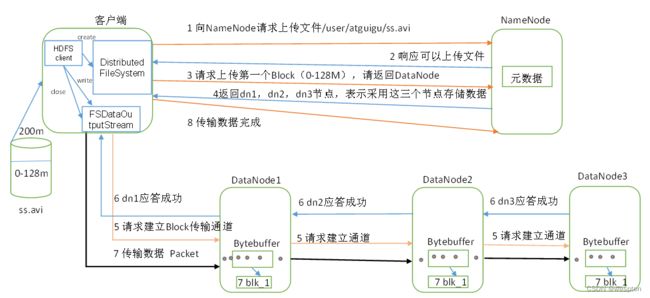
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
源码解析:org.apache.hadoop.hdfs.DFSOutputStream
2)网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
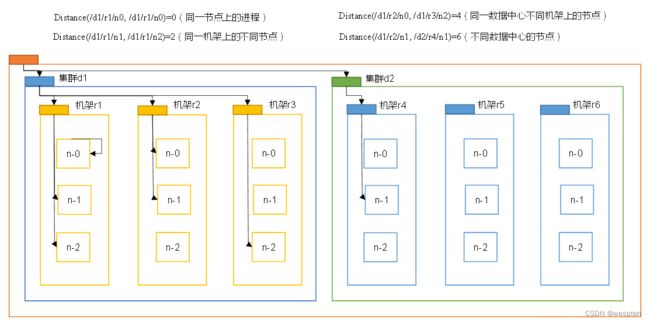
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
大家算一算每两个节点之间的距离。
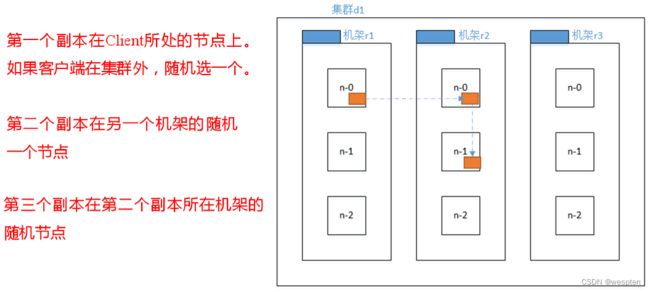
3) 机架感知(副本存储节点选择)
① 官方IP地址
机架感知说明:
http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.② Hadoop3.1.3副本节点选择
8、HDFS读取数据流程解析
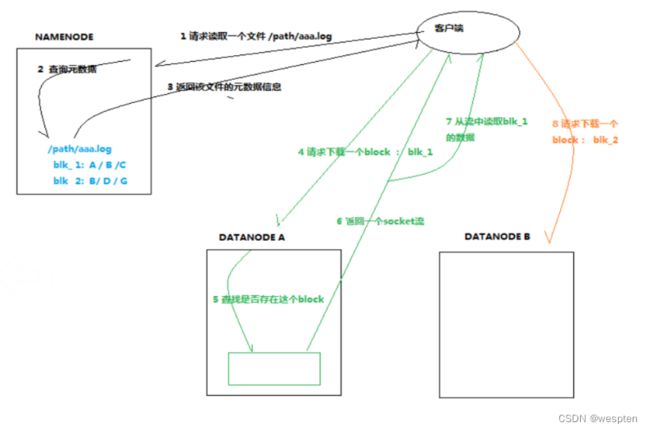
1)HDFS的读数据流程
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
9、HDFS的Shell操作
1. 基本语法
hadoop fs 具体命令 OR hdfs dfs 具体命令,两个是完全相同的。
2. 命令大全
[yyds@hadoop102 hadoop-3.1.3]$ bin/hadoop fs
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] ... ]
[-copyToLocal [-p] [-ignoreCrc] [-crc] ... ]
[-count [-q] ...]
[-cp [-f] [-p] ... ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [ ...]]
[-du [-s] [-h] ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] ... ]
[-getfacl [-R] ]
[-getmerge [-nl] ]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [ ...]]
[-mkdir [-p] ...]
[-moveFromLocal ... ]
[-moveToLocal ]
[-mv ... ]
[-put [-f] [-p] ... ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] ...]
[-rmdir [--ignore-fail-on-non-empty] ...]
[-setfacl [-R] [{-b|-k} {-m|-x } ]|[--set ]]
[-setrep [-R] [-w] ...]
[-stat [format] ...]
[-tail [-f] ]
[-test -[defsz] ]
[-text [-ignoreCrc] ...]
[-touchz ...]
[-usage [cmd ...]] 3. 常用命令实操
(1)准备工作
1)启动Hadoop集群(方便后续的测试)
[yyds@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[yyds@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh2)-help:输出这个命令参数
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm(2)上传
1)-moveFromLocal:从本地剪切粘贴到HDFS
[yyds@hadoop102 hadoop-3.1.3]$ touch kongming.txt
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal README.txt /3)-appendToFile:追加一个文件到已经存在的文件末尾
[yyds@hadoop102 hadoop-3.1.3]$ touch liubei.txt
[yyds@hadoop102 hadoop-3.1.3]$ vi liubei.txt
输入
san gu mao lu
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt4)-put:等同于copyFromLocal
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./liubei.txt /user/yyds/test/(3)下载
1)-copyToLocal:从HDFS拷贝到本地
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./2)-get:等同于copyToLocal,就是从HDFS下载文件到本地
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo/kongming.txt ./3)-getmerge:合并下载多个文件,比如HDFS的目录 /user/yyds/test下有多个文件:log.1, log.2,log.3,...
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -getmerge /user/yyds/test/* ./zaiyiqi.txt(4)HDFS直接操作
1)-ls: 显示目录信息
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /2)-mkdir:在HDFS上创建目录
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir -p /sanguo/shuguo3)-cat:显示文件内容
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo/kongming.txt4)-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -chown yyds:yyds /sanguo/shuguo/kongming.txt5)-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt6)-mv:在HDFS目录中移动文件
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/7)-tail:显示一个文件的末尾1kb的数据
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /sanguo/shuguo/kongming.txt8)-rm:删除文件或文件夹
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /user/yyds/test/jinlian2.txt9)-rmdir:删除空目录
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /test
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -rmdir /test10)-du统计文件夹的大小信息
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /user/yyds/test
2.7 K /user/yyds/test
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /user/yyds/test
1.3 K /user/yyds/test/README.txt
15 /user/yyds/test/jinlian.txt
1.4 K /user/yyds/test/zaiyiqi.txt11)-setrep:设置HDFS中文件的副本数量
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
10、HDFS客户端操作
1. 准备Windows关于Hadoop的开发环境
1)找到资料目录下的Windows依赖目录,打开:

选择Hadoop-3.1.0,拷贝到其他地方(比如d:\)。
2)配置HADOOP_HOME环境变量
3)配置Path环境变量。然后重启电脑
4)创建一个Maven工程HdfsClientDemo,并导入相应的依赖坐标+日志添加
junit
junit
4.12
org.apache.logging.log4j
log4j-slf4j-impl
2.12.0
org.apache.hadoop
hadoop-client
3.1.3
在项目的src/main/resources目录下,新建一个文件,命名为“log4j2.xml”,在文件中填入:
5)创建包名:com.yyds.hdfs
6)创建HdfsClient类
public class HdfsClient{
@Test
public void testMkdirs() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
// configuration.set("fs.defaultFS", "hdfs://hadoop102:9820");
// FileSystem fs = FileSystem.get(configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9820"), configuration, "yyds");
// 2 创建目录
fs.mkdirs(new Path("/1108/daxian/banzhang"));
// 3 关闭资源
fs.close();
}
}7)执行程序
运行时需要配置用户名称:
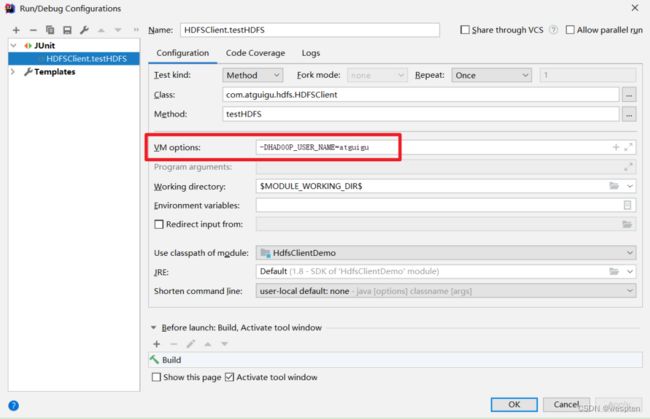
客户端去操作HDFS时,是有一个用户身份的。默认情况下,HDFS客户端API会从JVM中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=yyds,yyds为用户名称。
2. HDFS的API操作
① HDFS文件上传(测试参数优先级)
1)编写源代码
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "yyds");
// 2 上传文件
fs.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));
// 3 关闭资源
fs.close();
System.out.println("over");
}2)将hdfs-site.xml拷贝到项目的根目录下
dfs.replication
1
3)参数优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
② HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9820"), configuration, "yyds");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/banzhang.txt"), new Path("e:/banhua.txt"), true);
// 3 关闭资源
fs.close();
}③ HDFS删除文件和目录
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9820"), configuration, "yyds");
// 2 执行删除
fs.delete(new Path("/0508/"), true);
// 3 关闭资源
fs.close();
}④ HDFS文件更名和移动
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9820"), configuration, "yyds");
// 2 修改文件名称
fs.rename(new Path("/banzhang.txt"), new Path("/banhua.txt"));
// 3 关闭资源
fs.close();
}⑤ HDFS文件详情查看
查看文件名称、权限、长度、块信息:
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException{
// 1获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9820"), configuration, "yyds");
// 2 获取文件详情
RemoteIterator listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
// 输出详情
// 文件名称
System.out.println(status.getPath().getName());
// 长度
System.out.println(status.getLen());
// 权限
System.out.println(status.getPermission());
// 分组
System.out.println(status.getGroup());
// 获取存储的块信息
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 获取块存储的主机节点
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("-----------班长的分割线----------");
}
// 3 关闭资源
fs.close();
} ⑥ HDFS文件和文件夹判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件配置信息
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9820"), configuration, "yyds");
// 2 判断是文件还是文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// 如果是文件
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 关闭资源
fs.close();
}11、HDFS坏块处理
hdfs dfsadmin-safemode leave
hdfs fsck -delete /五、MapReduce&yarn
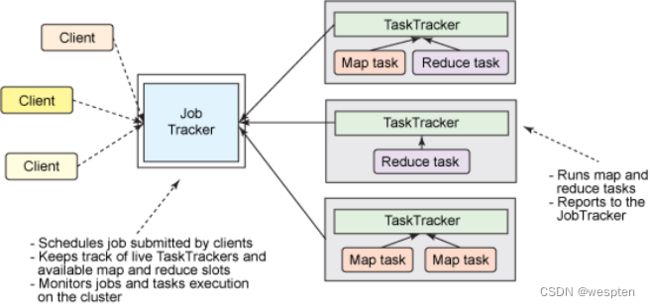
1、第一代hadoop组成与结构
第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为Hadoop 1.x和0.21.X,0.22.x。
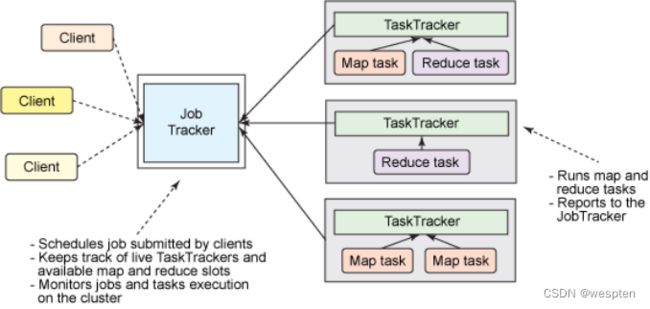
1)MapReduce角色分配
1. Client :作业提交发起者。
2. JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业。
3. TaskTracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。
2)MapReduce执行流程
(1)提交作业
1. 在作业提交之前,需要对作业进行配置
2. 程序代码,主要是自己书写的MapReduce程序。
3. 输入输出路径
4. 其他配置,如输出压缩等。
5. 配置完成后,通过JobClinet来提交
(2)作业的初始化
1. 客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
(3)任务的分配
1. TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
2. TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。
(4)任务的执行
1. 申请到任务后,TaskTracker会做如下事情:
2. 拷贝代码到本地
3. 拷贝任务的信息到本地
4. 启动JVM运行任务
(5)状态与任务的更新
1. 任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
2. 任务进度是通过计数器来实现的。
(6)作业的完成
1. JobTracker是在接受到最后一个任务运行完成后,才会将任务标志为成功。
2. 此时会做删除中间结果等善后处理工作。
2、第二代hadoop组成与结构
第二代Hadoop,为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的。针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展;
针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN(Yet Another Resource Negotiator),它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。对应Hadoop版本为Hadoop 0.23.x和2.x。
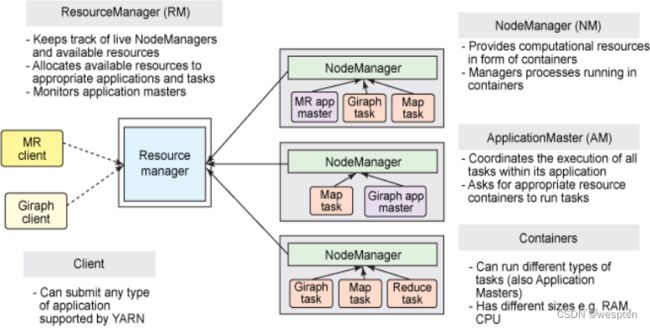
1)yarn运行架构
YARN 是下一代Hadoop计算平台,如下所示:
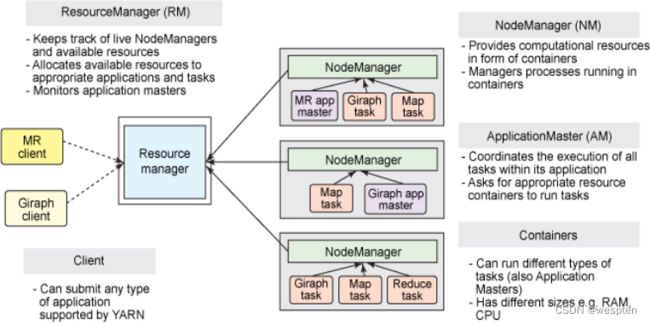
在 YARN 架构中,一个全局ResourceManager 以主要后台进程的形式运行,它通常在一台独立机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。
ResourceManager会追踪集群中有多少可用的活动节点和资源,协调用户提交的哪些应用程序应该在何时获取这些资源。ResourceManager是唯一拥有此信息的进程,所以它可通过某种共享的、安全的、多租户的方式制定分配(或者调度)决策(例如,依据应用程序优先级、队列容量、ACLs、数据位置等)。
在用户提交一个应用程序时,一个称为ApplicationMaster的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。这些职责以前是分配给单个 JobTracker来完成的。
ApplicationMaster和属于它的应用程序的任务,在受NodeManager控制的资源容器中运行。
NodeManager是TaskTracker的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。容器的大小取决于它所包含的资源量,比如内存、CPU、磁盘和网络 IO。目前,仅支持内存和 CPU (YARN-3)。一个节点上的容器数量,由节点资源总量(比如总CPU数和总内存)共同决定。
需要说明的是:ApplicationMaster可在容器内运行任何类型的任务。例如,MapReduce ApplicationMaster请求一个容器来启动map或reduce 任务,而 Giraph ApplicationMaster请求一个容器来运行Giraph任务。
2)YARN可运行任何分布式应用程序
ResourceManager、NodeManager 和容器都不关心应用程序或任务的类型。所有特定于应用程序框架的代码都会转移到ApplicationMaster,以便任何分布式框架都可以受 YARN 支持。
得益于这个一般性的方法,Hadoop YARN集群可以运行许多不同分布式计算模型,例如:MapReduce、Giraph、Storm、Spark、Tez/Impala、MPI等。
3)YARN中提交应用程序
下面讨论在应用程序提交到YARN集群时,ResourceManager、ApplicationMaster、NodeManagers和容器如何相互交互。
下图显示了一个例子:
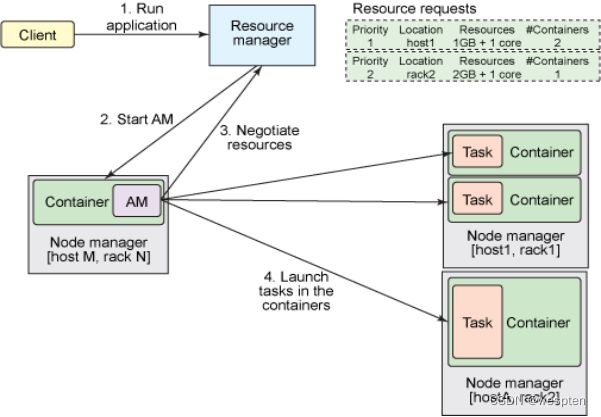
(1)在 ResourceManager接受一个新应用程序提交时,Scheduler制定的第一个决策是选择将用来运行ApplicationMaster的容器。在 ApplicationMaster启动后,它将负责此应用程序的整个生命周期。首先也是最重要的是,它将资源请求发送到 ResourceManager,请求运行应用程序的任务所需的容器。
(2)如果可能的话,ResourceManager 会分配一个满足ApplicationMaster在资源请求中所请求的容器(表达为容器 ID和主机名)。该容器允许应用程序使用特定主机上给定的资源量。分配一个容器后,ApplicationMaster会要求NodeManager(管理分配容器的主机)使用这些资源来启动一个特定于应用程序的任务。此任务可以是在任何框架中编写的任何进程(比如一个 MapReduce 任务或一个Giraph任务)。
(3)NodeManager 不会监视任务;它仅监视容器中的资源使用情况,例如,如果一个容器消耗的内存比最初分配的更多,它会结束该容器。ApplicationMaster会竭尽全力协调容器,启动所有需要的任务来完成它的应用程序。它还监视应用程序及其任务的进度,在新请求的容器中重新启动失败的任务,以及向提交应用程序的客户端报告进度。应用程序完成后,ApplicationMaster 会关闭自己并释放自己的容器。
(4)尽管ResourceManager不会对应用程序内的任务执行任何监视,但它会检查 ApplicationMaster的健康状况。如果 ApplicationMaster失败,ResourceManager 可在一个新容器中重新启动它。可以认为ResourceManager负责管理ApplicationMaster,而 ApplicationMasters负责管理任务。
3、MapReduce概述
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并行运行在一个Hadoop集群上。
MapReduce核心思想:
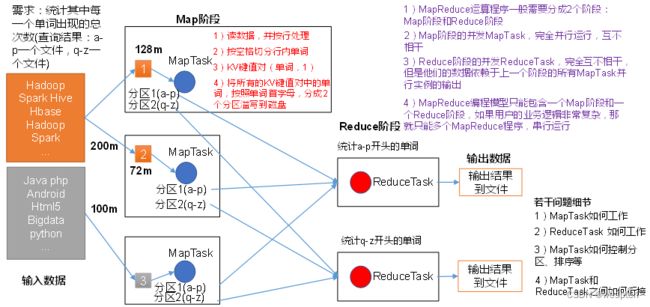
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
MapReduce进程:
一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
官方WordCount源码:
采用反编译工具反编译源码,发现WordCount案例有Map类、Reduce类和驱动类。且数据的类型是Hadoop自身封装的序列化类型。
分析WordCount数据流走向深入理解MapReduce核心思想。
① MapReduce优点
1)MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
② MapReduce缺点
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
4、MapReduce编程规范
1. 常用数据序列化类型
| Java类型 |
Hadoop Writable类型 |
| Boolean |
BooleanWritable |
| Byte |
ByteWritable |
| Int |
IntWritable |
| Float |
FloatWritable |
| Long |
LongWritable |
| Double |
DoubleWritable |
| String |
Text |
| Map |
MapWritable |
| Array |
ArrayWritable |
| Null |
NullWritable |
用户编写的程序分成三个部分:Mapper、Reducer和Driver:
1)Mapper阶段
(1)用户自定义的Mapper要继承自己的父类。
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)。
(3)Mapper中的业务逻辑写在map()方法中。
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)(5)map)方法(MapTask进程)对每一个
2)Reducer阶段
(1)用户自定义的Reducer要继承自己的父类。
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV 。
(3)Reducer的业务逻辑写在reduce()方法中。
(4)ReduceTask进程对每一组相同k的
3)Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象。
2. WordCount案例实操
1)需求
在给定的文本文件中统计输出每一个单词出现的总次数
(1)输入数据
yyds yyds
ss ss
cls cls
jiao
banzhang
xue
hadoop(2)期望输出数据
yyds 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 12)需求分析
按照MapReduce编程规范,分别编写Mapper,Reducer,Driver。
Mapper将MapTask传给我们的文本内容转换成String,根据空格将这一行切分成单词,将单词输出为<单词,1>。
Reducer汇总各个key的个数,输出该key的总次数。
Driver获取配置信息,获取job对象实例,指定本程序的jar包所在的本地路径,关联Mapper/Reducer业务类。指定Mapper输出数据的kv类型,指定最终输出的数据的kv类型,指定job的输入原始文件所在目录,指定job的输出结果所在目录,提交作业。
3)环境准备
(1)创建maven工程
(2)在pom.xml文件中添加如下依赖
junit
junit
4.12
org.apache.logging.log4j
log4j-slf4j-impl
2.12.0
org.apache.hadoop
hadoop-client
3.1.3
(3)在项目的src/main/resources目录下,新建一个文件,命名为“log4j2.xml”,在文件中填入。
4)编写程序
(1)编写Mapper类
package com.yyds.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
} (2)编写Reducer类
package com.yyds.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
} (3)编写Driver驱动类
package com.yyds.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及获取job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 关联本Driver程序的jar
job.setJarByClass(WordcountDriver.class);
// 3 关联Mapper和Reducer的jar
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}5)本地测试
(1)需要首先配置好HADOOP_HOME变量以及Windows运行依赖
(2)在IDEA/Eclipse上运行程序
6)集群上测试
(0)用maven打jar包,需要添加的打包插件依赖
maven-compiler-plugin
3.6.1
1.8
1.8
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
single
注意:如果工程上显示红叉。在项目上右键->maven->Reimport即可。
(1)将程序打成jar包,然后拷贝到Hadoop集群中
步骤详情:右键->Run as->maven install。等待编译完成就会在项目的target文件夹中生成jar包。如果看不到。在项目上右键->Refresh,即可看到。修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群。
(2)启动Hadoop集群
(3)执行WordCount程序
[yyds@hadoop102 software]$ hadoop jar wc.jar
com.yyds.wordcount.WordcountDriver /user/yyds/input /user/yyds/output7)在Windows上向集群提交任务
(1)添加必要配置信息
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
//设置HDFS NameNode的地址
configuration.set("fs.defaultFS", "hdfs://hadoop102:9820");
// 指定MapReduce运行在Yarn上
configuration.set("mapreduce.framework.name","yarn");
// 指定mapreduce可以在远程集群运行
configuration.set("mapreduce.app-submission.cross-platform","true");
//指定Yarn resourcemanager的位置
configuration.set("yarn.resourcemanager.hostname","hadoop103");
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJar("F:\\idea_project\\main\\bigdata1214\\MapReduce\\target\\MapReduce-1.0-SNAPSHOT.jar");
// 3 设置map和reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}(2)编辑任务配置
1)检查第一个参数Main class是不是我们要运行的类的全类名,如果不是的话一定要修改!
2)在VM options后面加上
-DHADOOP_USER_NAME=yyds3)在Program arguments后面加上两个参数分别代表输入输出路径,两个参数之间用空格隔开。如:
hdfs://hadoop102:9820/input hdfs://hadoop102:9820/output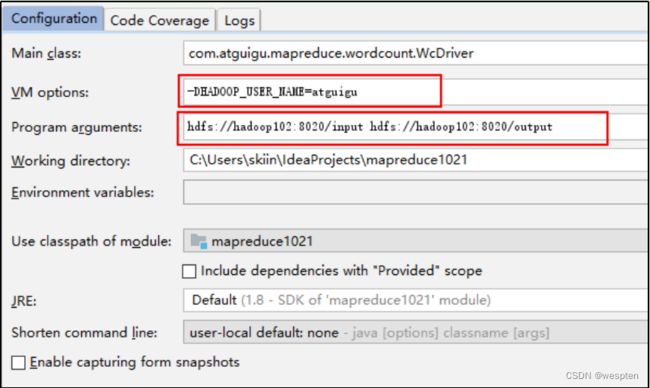
(3)打包,并将Jar包设置到Driver中
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hadoop102:9820");
configuration.set("mapreduce.framework.name","yarn");
configuration.set("mapreduce.app-submission.cross-platform","true");
configuration.set("yarn.resourcemanager.hostname","hadoop103");
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
//job.setJarByClass(WordCountDriver.class);
job.setJar("D:\IdeaProjects\mapreduce\target\mapreduce-1.0-SNAPSHOT.jar");
// 3 设置map和reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}(4)提交并查看结果
5、Hadoop序列化
1. 序列化概述
1)什么是序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
2)为什么要序列化
一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。然而序列化可以存储"活的"对象,可以将"活的"对象发送到远程计算机。
3)为什么不用Java的序列化
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以,Hadoop自己开发了一套序列化机制(Writable)。
Hadoop序列化特点:
(1)紧凑高效使用存储空间。
(2)快速读写数据的额外开销小。
(3)可扩展随着通信协议的升级而可升级。
(4)互操作支持多语言的交互。
2. 自定义bean对象实现序列化接口(Writable)
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下7步。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean() {
super();
}(3)重写序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}(4)重写反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用”\t”分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。详见后面排序案例。
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}3. 序列化案例实操
1)需求
统计每一个手机号耗费的总上行流量、总下行流量、总流量
(1)输入数据
1 13736230513 192.196.100.1 www.baidu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.baidu.com 1527 2106 200
6 84188413 192.168.100.3 www.baidu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.baidu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200(2)输入数据格式
7 13560436666 120.196.100.99 1116 954 200
id 手机号码 网络ip 上行流量 下行流量 网络状态码(3)期望输出数据格式
13560436666 1116 954 2070
手机号码 上行流量 下行流量 总流量2)需求分析

3)编写MapReduce程序
(1)编写流量统计的Bean对象
package com.yyds.mapreduce.flowsum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
// 1 实现writable接口
public class FlowBean implements Writable{
private long upFlow;
private long downFlow;
private long sumFlow;
//2 反序列化时,需要反射调用空参构造函数,所以必须有
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
//3 写序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//4 反序列化方法
//5 反序列化方法读顺序必须和写序列化方法的写顺序必须一致
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
// 6 编写toString方法,方便后续打印到文本
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
}(2)编写Mapper类
package com.yyds.mapreduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowCountMapper extends Mapper{
FlowBean v = new FlowBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割字段
String[] fields = line.split("\t");
// 3 封装对象
// 取出手机号码
String phoneNum = fields[1];
// 取出上行流量和下行流量
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]);
k.set(phoneNum);
v.set(downFlow, upFlow);
// 4 写出
context.write(k, v);
}
} (3)编写Reducer类
package com.yyds.mapreduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context)throws IOException, InterruptedException {
long sum_upFlow = 0;
long sum_downFlow = 0;
// 1 遍历所用bean,将其中的上行流量,下行流量分别累加
for (FlowBean flowBean : values) {
sum_upFlow += flowBean.getUpFlow();
sum_downFlow += flowBean.getDownFlow();
}
// 2 封装对象
FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow);
// 3 写出
context.write(key, resultBean);
}
} (4)编写Driver驱动类
package com.yyds.mapreduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowsumDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/inputflow", "e:/output1" };
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(FlowsumDriver.class);
// 3 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 4 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}6、MapReduce框架原理
1. InputFormat数据输入
MapReduce的数据流:
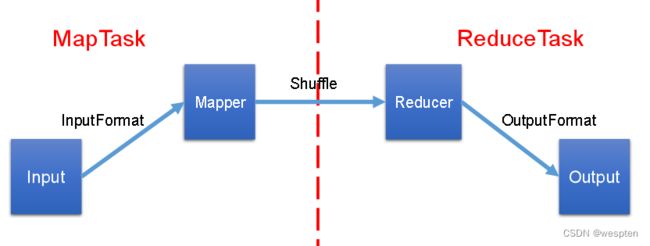
① 切片与MapTask并行度决定机制
1)问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
2)MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
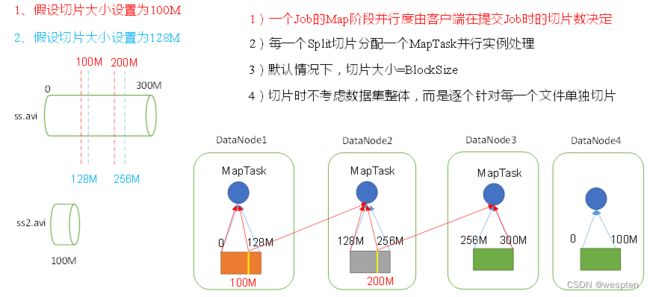
② Job提交流程源码和切片源码详解
1)Job提交流程源码详解
waitForCompletion()
submit();
// 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地运行环境还是yarn集群运行环境
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());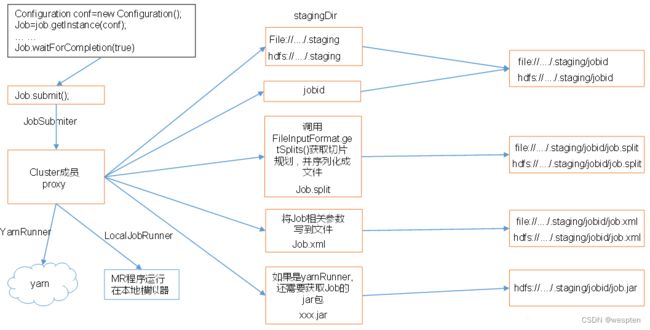
2)FileInputFormat切片源码解析(input.getSplits(job))

③ FileInputFormat切片机制

FileInputFormat切片大小的参数配置:

④ TextInputFormat
FileInputFormat实现类:
在运行MapReduce程序时,输入的文件格式包括∶基于行的日志文件、二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce是如何读取这些数据的呢?
FileInputFormat 常见的接口实现类包括∶TextInputFormat、Key ValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
TextInputFormat:

⑤ CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1)应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。

(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
⑥ CombineTextInputFormat案例实操
1)需求
将输入的大量小文件合并成一个切片统一处理。
(1)输入数据
准备4个小文件:
a.txt b.txt c.txt d.txt
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop
yyds yiqi
yyds
hadoop(2)期望
期望一个切片处理4个文件。
2)实现过程
(1)不做任何处理,运行1.6节的WordCount案例程序,观察切片个数为4。
![]()
(2)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为3。
(a)驱动类中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);(b)运行如果为3个切片。
![]()
(3)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为1。
(a)驱动中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);(b)运行如果为1个切片。
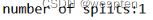
2. MapReduce工作流程
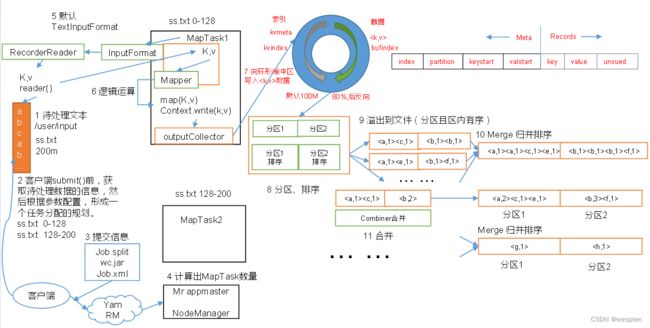
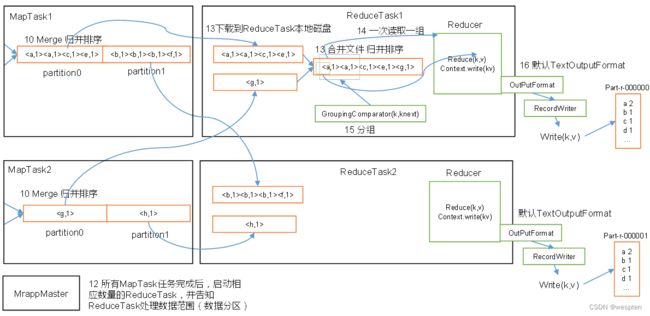
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
(5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
(6)ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
注意:
(1)Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
(2)缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb默认100M。
(3)源码解析流程
MapTask:
context.write(k, NullWritable.get()); //自定义的map方法的写出,进入
output.write(key, value);
//MapTask727行,收集方法,进入两次
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner(); //默认分区器
collect() //MapTask1082行 map端所有的kv全部写出后会走下面的close方法
close() //MapTask732行
collector.flush() // 溢出刷写方法,MapTask735行,提前打个断点,进入
sortAndSpill() //溢写排序,MapTask1505行,进入
sorter.sort() QuickSort //溢写排序方法,MapTask1625行,进入
mergeParts(); //合并文件,MapTask1527行,进入file.out和file.out.index
collector.close();ReduceTask:
if (isMapOrReduce()) //reduceTask324行,提前打断点
initialize() // reduceTask333行,进入
init(shuffleContext); // reduceTask375行,走到这需要先给下面的打断点
totalMaps = job.getNumMapTasks(); // ShuffleSchedulerImpl第120行,提前打断点
merger = createMergeManager(context); //合并方法,Shuffle第80行
// MergeManagerImpl第232 235行,提前打断点
this.inMemoryMerger = createInMemoryMerger(); //内存合并
this.onDiskMerger = new OnDiskMerger(this); //磁盘合并
eventFetcher.start(); //开始抓取数据,Shuffle第107行,提前打断点
eventFetcher.shutDown(); //抓取结束,Shuffle第141行,提前打断点
copyPhase.complete(); //copy阶段完成,Shuffle第151行
taskStatus.setPhase(TaskStatus.Phase.SORT); //开始排序阶段,Shuffle第152行
sortPhase.complete(); //排序阶段完成,即将进入reduce阶段 reduceTask382行
reduce(); //reduce阶段调用的就是我们自定义的reduce方法,会被调用多次
cleanup(context); //reduce完成之前,会最后调用一次Reducer里面的cleanup方法7、Shuffle机制
1. Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
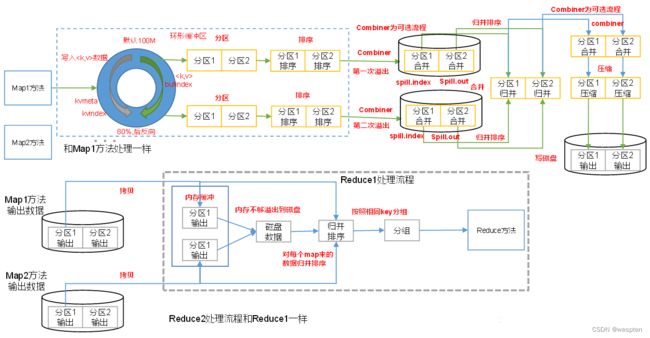
2. Partition分区



3. Partition分区案例实操
1)需求
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
(1)输入数据
1 13736230513 192.196.100.1 www.baidu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.baidu.com 1527 2106 200
6 84188413 192.168.100.3 www.baidu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.baidu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200(2)期望输出数据
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。
2)需求分析
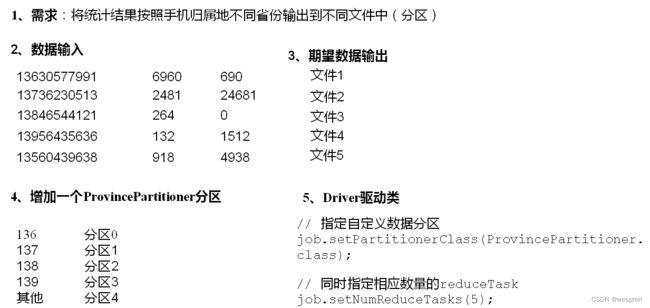
3)增加一个分区类
package com.yyds.mapreduce.flowsum;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 1 获取电话号码的前三位
String preNum = key.toString().substring(0, 3);
int partition = 4;
// 2 判断是哪个省
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
} 4)在驱动函数中增加自定义数据分区设置和ReduceTask设置
package com.yyds.mapreduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowsumDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[]{"e:/output1","e:/output2"};
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(FlowsumDriver.class);
// 3 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 4 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 8 指定自定义数据分区
job.setPartitionerClass(ProvincePartitioner.class);
// 9 同时指定相应数量的reduce task
job.setNumReduceTasks(5);
// 6 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}4. WritableComparable排序
排序是MapReduce框架中最重要的操作之一。MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
排序分类:
(1)部分排序
MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部有序。
(2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
(3)辅助排序∶(GroupingComparator分组)
在Reduce端对key进行分组。应用于∶在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
(4)二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
自定义排序WritableComparable原理分析
bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
@Override
public int compareTo(FlowBean bean) {
int result;
// 按照总流量大小,倒序排列
if (this.sumFlow > bean.getSumFlow()) {
result = -1;
}else if (this.sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}5. WritableComparable排序案例实操(全排序)
1)需求
根据案例2.3序列化案例产生的结果再次对总流量进行倒序排序。
(1)输入数据
原始数据 第一次处理后的数据
phone_data.txt part-r-00000
phone_data.txt:
1 13736230513 192.196.100.1 www.baidu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.baidu.com 1527 2106 200
6 84188413 192.168.100.3 www.baidu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.baidu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200(2)期望输出数据
13509468723 7335 110349 117684
13736230513 2481 24681 27162
13956435636 132 1512 1644
13846544121 264 0 264
。。。 。。。2)需求分析

3)代码实现
(1)FlowBean对象在在需求1基础上增加了比较功能
package com.yyds.mapreduce.sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable {
private long upFlow;
private long downFlow;
private long sumFlow;
// 反序列化时,需要反射调用空参构造函数,所以必须有
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
/**
* 序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化方法 注意反序列化的顺序和序列化的顺序完全一致
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
@Override
public int compareTo(FlowBean bean) {
int result;
// 按照总流量大小,倒序排列
if (sumFlow > bean.getSumFlow()) {
result = -1;
}else if (sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
} (2)编写Mapper类
package com.yyds.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowCountSortMapper extends Mapper{
FlowBean bean = new FlowBean();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split("\t");
// 3 封装对象
String phoneNbr = fields[0];
long upFlow = Long.parseLong(fields[1]);
long downFlow = Long.parseLong(fields[2]);
bean.set(upFlow, downFlow);
v.set(phoneNbr);
// 4 输出
context.write(bean, v);
}
} (3)编写Reducer类
package com.yyds.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowCountSortReducer extends Reducer{
@Override
protected void reduce(FlowBean key, Iterable values, Context context) throws IOException, InterruptedException {
// 循环输出,避免总流量相同情况
for (Text text : values) {
context.write(text, key);
}
}
} (4)编写Driver类
package com.yyds.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowCountSortDriver {
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[]{"e:/output1","e:/output2"};
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(FlowCountSortDriver.class);
// 3 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountSortMapper.class);
job.setReducerClass(FlowCountSortReducer.class);
// 4 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}6. WritableComparable排序案例实操(区内排序)
1)需求
要求每个省份手机号输出的文件中按照总流量内部排序。
2)需求分析
基于前一个需求,增加自定义分区类,分区按照省份手机号设置。

3)案例实操
(1)增加自定义分区类
package com.yyds.mapreduce.sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner {
@Override
public int getPartition(FlowBean key, Text value, int numPartitions) {
// 1 获取手机号码前三位
String preNum = value.toString().substring(0, 3);
int partition = 4;
// 2 根据手机号归属地设置分区
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
} (2)在驱动类中添加分区类
// 加载自定义分区类
job.setPartitionerClass(ProvincePartitioner.class);
// 设置Reducetask个数
job.setNumReduceTasks(5);7. Combiner合并

自定义Combiner实现步骤:
(a)自定义一个Combiner继承Reducer,重写Reduce方法
public class WordcountCombiner extends Reducer{
@Override
protected void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException {
// 1 汇总操作
int count = 0;
for(IntWritable v :values){
count += v.get();
}
// 2 写出
context.write(key, new IntWritable(count));
}
} (b)在Job驱动类中设置
job.setCombinerClass(WordcountCombiner.class);8. Combiner合并案例实操
1)需求
统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量即采用Combiner功能。
(1)数据输入
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang(2)期望输出数据
期望:Combine输入数据多,输出时经过合并,输出数据降低。
2)需求分析

3)案例实操-方案一
(1)增加一个WordcountCombiner类继承Reducer
package com.yyds.mr.combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
// 1 汇总
int sum = 0;
for(IntWritable value :values){
sum += value.get();
}
v.set(sum);
// 2 写出
context.write(key, v);
}
} (2)在WordcountDriver驱动类中指定Combiner
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountCombiner.class);4)案例实操-方案二
(1)将WordcountReducer作为Combiner在WordcountDriver驱动类中指定
// 指定需要使用Combiner,以及用哪个类作为Combiner的逻辑
job.setCombinerClass(WordcountReducer.class);运行程序,如下图所示:
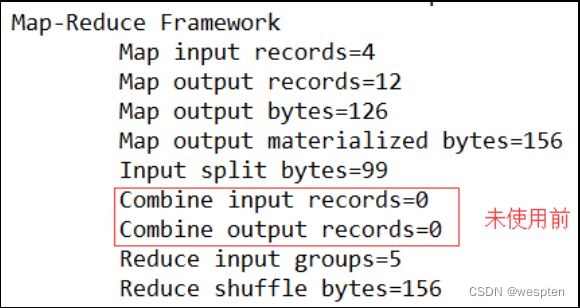
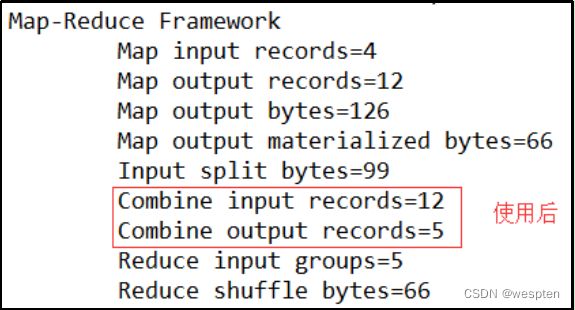
8、MapTask工作机制
MapTask工作机制:
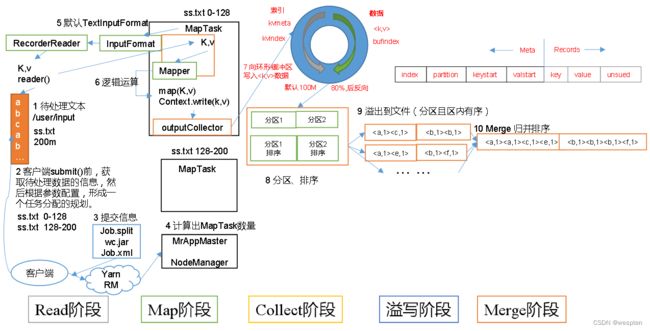
(1)Read阶段:MapTask通过InputFormat获得的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
(5)Merge阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并mapreduce.task.io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
9、ReduceTask工作机制
ReduceTask工作机制:
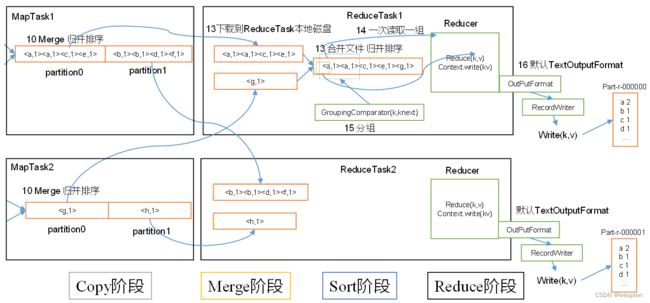
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
1)设置ReduceTask并行度(个数)
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的决定是可以直接手动设置:
// 默认值是1,手动设置为4
job.setNumReduceTasks(4);2)实验:测试ReduceTask多少合适
(1)实验环境:1个Master节点,16个Slave节点:CPU:8GHZ,内存: 2G
(2)实验结论:
改变ReduceTask (数据量为1GB):
| MapTask =16 |
||||||||||
| ReduceTask |
1 |
5 |
10 |
15 |
16 |
20 |
25 |
30 |
45 |
60 |
| 总时间 |
892 |
146 |
110 |
92 |
88 |
100 |
128 |
101 |
145 |
104 |
3)注意事项
(1)ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
(2)ReduceTask默认值就是1,所以输出文件个数为一个。
(3)如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜
(4)ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
(5)具体多少个ReduceTask,需要根据集群性能而定。
(6)如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是∶不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
10、OutputFormat数据输出
1. OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat 接口。下面我们介绍几种常见的OutputFormat实现类。
① 文本输出 TextOutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString0方法把它们转换为字符串。
② SequenceFileOutputFormat
将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
③ 自定义OutputFormat
根据用户需求,自定义实现输出。
2. 自定义OutputFormat
自定义OutputFormat使用场景及步骤:
① 使用场景
为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。例如∶要在一个MapReduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义OutputFormat来实现。
② 自定义OutputFormat步骤
(1)自定义一个类继承FileOutputFormat。
(2)改写RecordWriter,具体改写输出数据的方法write()。
3. 定义OutputFormat案例实操
1)需求
过滤输入的log日志,包含yyds的网站输出到e:/yyds.log,不包含yyds的网站输出到e:/other.log。
(1)输入数据
log.txt
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.sohu.com
http://www.sina.com
http://www.atguigu.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
2)需求分析
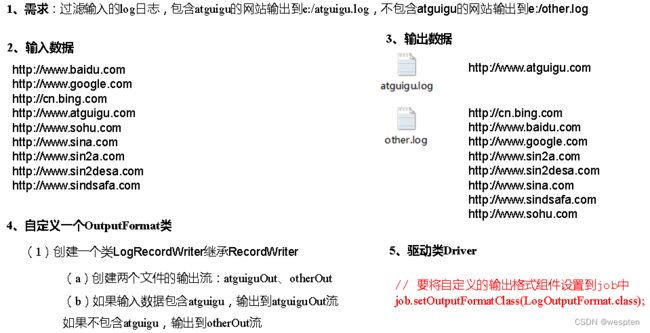
3)案例实操
(1)编写FilterMapper类
package com.yyds.mapreduce.outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//不做任何处理,直接写出一行log数据
context.write(value,NullWritable.get());
}
} (2)编写FilterReducer类
package com.yyds.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//防止有相同的数据,迭代写出
for (NullWritable value : values) {
context.write(key,NullWritable.get());
}
}
} (3)自定义一个OutputFormat类
package com.yyds.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogOutputFormat extends FileOutputFormat {
@Override
public RecordWriter getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
//创建一个自定义的RecordWriter返回
LogRecordWriter logRecordWriter = new LogRecordWriter(job);
return logRecordWriter;
}
} (4)编写RecordWriter类
package com.yyds.mapreduce.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class LogRecordWriter extends RecordWriter {
private FSDataOutputStream atguiguOut;
private FSDataOutputStream otherOut;
public LogRecordWriter(TaskAttemptContext job) {
try {
//获取文件系统对象
FileSystem fs = FileSystem.get(job.getConfiguration());
//用文件系统对象创建两个输出流对应不同的目录
atguiguOut = fs.create(new Path("d:/hadoop/atguigu.txt"));
otherOut = fs.create(new Path("d:/hadoop/other.txt"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
String log = key.toString();
//根据一行的log数据是否包含yyds,判断两条输出流输出的内容
if (log.contains("atguigu")) {
atguiguOut.writeBytes(log + "\n");
} else {
otherOut.writeBytes(log + "\n");
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
//关流
IOUtils.closeStream(yydsOut);
IOUtils.closeStream(otherOut);
}
} (5)编写FilterDriver类
package com.yyds.mapreduce.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogDriver.class);
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置自定义的outputformat
job.setOutputFormatClass(LogOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("D:\\input"));
//虽然我们自定义了outputformat,但是因为我们的outputformat继承自fileoutputformat
//而fileoutputformat要输出一个_SUCCESS文件,所以在这还得指定一个输出目录
FileOutputFormat.setOutputPath(job, new Path("D:\\logoutput"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}11、Join多种应用
1. Reduce Join
Reduce Join工作原理:
Map端的主要工作∶为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作∶在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并就ok了。
2. Reduce Join案例实操
1)需求
订单数据表t_order:
| id |
pid |
amount |
| 1001 |
01 |
1 |
| 1002 |
02 |
2 |
| 1003 |
03 |
3 |
| 1004 |
01 |
4 |
| 1005 |
02 |
5 |
| 1006 |
03 |
6 |
商品信息表t_product:
| pid |
pname |
| 01 |
小米 |
| 02 |
华为 |
| 03 |
格力 |
将商品信息表中数据根据商品pid合并到订单数据表中。
最终数据形式:
| id |
pname |
amount |
| 1001 |
小米 |
1 |
| 1004 |
小米 |
4 |
| 1002 |
华为 |
2 |
| 1005 |
华为 |
5 |
| 1003 |
格力 |
3 |
| 1006 |
格力 |
6 |
2)需求分析
通过将关联条件作为Map输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联。
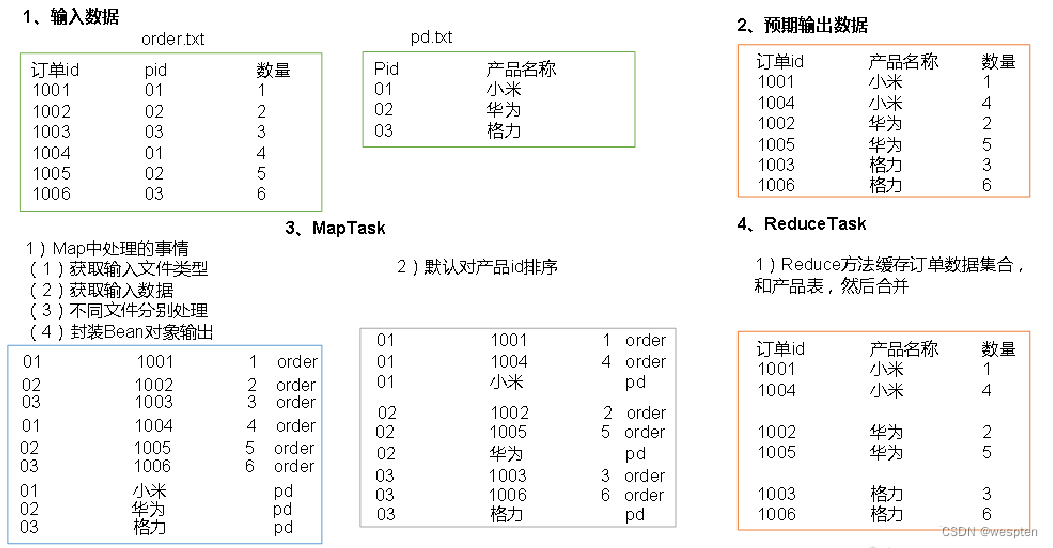
3)代码实现
(1)创建商品和订单合并后的Bean类
package com.yyds.mapreduce.reducejoin;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TableBean implements Writable {
private String id; //订单id
private String pid; //产品id
private int amount; //产品数量
private String pname; //产品名称
private String flag; //判断是order表还是pd表的标志字段
public TableBean() {
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public String toString() {
return id + "\t" + pname + "\t" + amount;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(pid);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF();
this.pid = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.flag = in.readUTF();
}
}(2)编写TableMapper类
package com.yyds.mapreduce.reducejoin;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class TableMapper extends Mapper {
private String filename;
private Text outK = new Text();
private TableBean outV = new TableBean();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取对应文件名称
InputSplit split = context.getInputSplit();
FileSplit fileSplit = (FileSplit) split;
filename = fileSplit.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//判断是哪个文件,然后针对文件进行不同的操作
if(filename.contains("order")){ //订单表的处理
String[] split = line.split("\t");
//封装outK
outK.set(split[1]);
//封装outV
outV.setId(split[0]);
outV.setPid(split[1]);
outV.setAmount(Integer.parseInt(split[2]));
outV.setPname("");
outV.setFlag("order");
}else { //商品表的处理
String[] split = line.split("\t");
//封装outK
outK.set(split[0]);
//封装outV
outV.setId("");
outV.setPid(split[0]);
outV.setAmount(0);
outV.setPname(split[1]);
outV.setFlag("pd");
}
//写出KV
context.write(outK,outV);
}
} (3)编写TableReducer类
package com.yyds.mapreduce.reducejoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
public class TableReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
ArrayList orderBeans = new ArrayList<>();
TableBean pdBean = new TableBean();
for (TableBean value : values) {
//判断数据来自哪个表
if("order".equals(value.getFlag())){ //订单表
//创建一个临时TableBean对象接收value
TableBean tmpOrderBean = new TableBean();
try {
BeanUtils.copyProperties(tmpOrderBean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
//将临时TableBean对象添加到集合orderBeans
orderBeans.add(tmpOrderBean);
}else { //商品表
try {
BeanUtils.copyProperties(pdBean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
//遍历集合orderBeans,替换掉每个orderBean的pid为pname,然后写出
for (TableBean orderBean : orderBeans) {
orderBean.setPname(pdBean.getPname());
//写出修改后的orderBean对象
context.write(orderBean,NullWritable.get());
}
}
} (4)编写TableDriver类
package com.yyds.mapreduce.reducejoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TableDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TableDriver.class);
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TableBean.class);
job.setOutputKeyClass(TableBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\output"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}4)测试
运行程序查看结果:
1004 小米 4
1001 小米 1
1005 华为 5
1002 华为 2
1006 格力 6
1003 格力 35)总结
Reduce Join缺点及解决方案:
缺点∶这种方式中,合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜。
解决方案∶Map端实现数据合并
3. Map Join
1)使用场景
Map Join适用于一张表十分小、一张表很大的场景。
2)优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
3)具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在Driver驱动类中加载缓存。
//缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file:///e:/cache/pd.txt"));
//如果是集群运行,需要设置HDFS路径
job.addCacheFile(new URI("hdfs://hadoop102:9820/cache/pd.txt"));4. Map Join案例实操
1)需求
订单数据表t_order:
| id |
pid |
amount |
| 1001 |
01 |
1 |
| 1002 |
02 |
2 |
| 1003 |
03 |
3 |
| 1004 |
01 |
4 |
| 1005 |
02 |
5 |
| 1006 |
03 |
6 |
商品信息表t_product:
| pid |
pname |
| 01 |
小米 |
| 02 |
华为 |
| 03 |
格力 |
将商品信息表中数据根据商品pid合并到订单数据表中。
最终数据形式:
| id |
pname |
amount |
| 1001 |
小米 |
1 |
| 1004 |
小米 |
4 |
| 1002 |
华为 |
2 |
| 1005 |
华为 |
5 |
| 1003 |
格力 |
3 |
| 1006 |
格力 |
6 |
2)需求分析
MapJoin适用于关联表中有小表的情形。
Map端表合并案例分析(Distributedcache)

3)实现代码
(1)先在MapJoinDriver驱动类中添加缓存文件
package com.yyds.mapreduce.mapjoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class MapJoinDriver {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置加载jar包路径
job.setJarByClass(MapJoinDriver.class);
// 3 关联mapper
job.setMapperClass(MapJoinMapper.class);
// 4 设置Map输出KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 5 设置最终输出KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 加载缓存数据
job.addCacheFile(new URI("file:///D:/input/inputcache/pd.txt"));
// Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0
job.setNumReduceTasks(0);
// 6 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\output"));
// 7 提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}(2)在MapJoinMapper类中的setup方法中读取缓存文件
package com.yyds.mapreduce.mapjoin;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapJoinMapper extends Mapper {
private Map pdMap = new HashMap<>();
private Text text = new Text();
//任务开始前将pd数据缓存进pdMap
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//通过缓存文件得到小表数据pd.txt
URI[] cacheFiles = context.getCacheFiles();
Path path = new Path(cacheFiles[0]);
//获取文件系统对象,并开流
FileSystem fs = FileSystem.get(context.getConfiguration());
FSDataInputStream fis = fs.open(path);
//通过包装流转换为reader,方便按行读取
BufferedReader reader = new BufferedReader(new InputStreamReader(fis, "UTF-8"));
//逐行读取,按行处理
String line;
while (StringUtils.isNotEmpty(line = reader.readLine())) {
//切割一行
//01 小米
String[] split = line.split("\t");
pdMap.put(split[0], split[1]);
}
//关流
IOUtils.closeStream(reader);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//读取大表数据
//1001 01 1
String[] fields = value.toString().split("\t");
//通过大表每行数据的pid,去pdMap里面取出pname
String pname = pdMap.get(fields[1]);
//将大表每行数据的pid替换为pname
text.set(fields[0] + "\t" + pname + "\t" + fields[2]);
//写出
context.write(text,NullWritable.get());
}
} 12、计数器应用
Hadoop为每个作业维护若干内置计数器,以描述多项指标。例如,某些计数器记录已处理的字节数和记录数,使用户可监控已处理的输入数据量和已产生的输出数据量。
1. 计数器API
(1)采用枚举的方式统计计数
enum MyCounter{MALFORORMED,NORMAL} //对收举定义的自定义计数器加1
context.getCounter(MyCounter.MALFORORMED).increment(1);
(2)采用计数器组、计数器名称的方式统计
context.getCounter("counterGroup","counter").increment(1);//组名和计数器名称随便起,但最好有意义。
(3)计数结果在程序运行后的控制台上查看。
2. 计数器案例实操
详见数据清洗案例。
13、数据清洗(ETL)
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
1)需求
去除日志中字段个数小于等于11的日志行内容。
(1)输入数据
194.237.142.21 - - [18/Sep/2013:06:49:18 +0000] "GET /wp-content/uploads/2013/07/rstudio-git3.png HTTP/1.1" 304 0 "-" "Mozilla/4.0 (compatible;)"
183.49.46.228 - - [18/Sep/2013:06:49:23 +0000] "-" 400 0 "-" "-"
163.177.71.12 - - [18/Sep/2013:06:49:33 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
163.177.71.12 - - [18/Sep/2013:06:49:36 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:42 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:45 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
60.208.6.156 - - [18/Sep/2013:06:49:48 +0000] "GET /wp-content/uploads/2013/07/rcassandra.png HTTP/1.0" 200 185524 "http://cos.name/category/software/packages/" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:50:08 +0000] "-" 400 0 "-" "-"
183.195.232.138 - - [18/Sep/2013:06:50:16 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
183.195.232.138 - - [18/Sep/2013:06:50:16 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
66.249.66.84 - - [18/Sep/2013:06:50:28 +0000] "GET /page/6/ HTTP/1.1" 200 27777 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
221.130.41.168 - - [18/Sep/2013:06:50:37 +0000] "GET /feed/ HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
157.55.35.40 - - [18/Sep/2013:06:51:13 +0000] "GET /robots.txt HTTP/1.1" 200 150 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
50.116.27.194 - - [18/Sep/2013:06:51:35 +0000] "POST /wp-cron.php?doing_wp_cron=1379487095.2510800361633300781250 HTTP/1.0" 200 0 "-" "WordPress/3.6; http://blog.fens.me"
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /nodejs-socketio-chat/ HTTP/1.1" 200 10818 "http://www.google.com/url?sa=t&rct=j&q=nodejs%20%E5%BC%82%E6%AD%A5%E5%B9%BF%E6%92%AD&source=web&cd=1&cad=rja&ved=0CCgQFjAA&url=%68%74%74%70%3a%2f%2f%62%6c%6f%67%2e%66%65%6e%73%2e%6d%65%2f%6e%6f%64%65%6a%73%2d%73%6f%63%6b%65%74%69%6f%2d%63%68%61%74%2f&ei=rko5UrylAefOiAe7_IGQBw&usg=AFQjCNG6YWoZsJ_bSj8kTnMHcH51hYQkAA&bvm=bv.52288139,d.aGc" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:36 +0000] "GET /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:36 +0000] "GET /wp-includes/js/comment-reply.min.js?ver=3.6 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:36 +0000] "GET /wp-content/uploads/2013/08/chat.png HTTP/1.1" 200 48968 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:36 +0000] "GET /wp-content/uploads/2013/08/chat2.png HTTP/1.1" 200 59852 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:37 +0000] "GET /wp-content/uploads/2013/08/socketio.png HTTP/1.1" 200 80493 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.248.178.212 - - [18/Sep/2013:06:51:37 +0000] "GET /nodejs-grunt-intro/ HTTP/1.1" 200 51770 "http://blog.fens.me/series-nodejs/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.248.178.212 - - [18/Sep/2013:06:51:40 +0000] "GET /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 HTTP/1.1" 200 7200 "http://blog.fens.me/nodejs-grunt-intro/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.248.178.212 - - [18/Sep/2013:06:51:40 +0000] "GET /wp-includes/js/comment-reply.min.js?ver=3.6 HTTP/1.1" 200 786 "http://blog.fens.me/nodejs-grunt-intro/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.248.178.212 - - [18/Sep/2013:06:51:40 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 200 45307 "http://blog.fens.me/nodejs-grunt-intro/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.248.178.212 - - [18/Sep/2013:06:51:40 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 200 93128 "http://blog.fens.me/nodejs-grunt-intro/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.248.178.212 - - [18/Sep/2013:06:51:40 +0000] "GET /wp-includes/js/comment-reply.min.js?ver=3.6 HTTP/1.1" 200 786 "http://blog.fens.me/nodejs-grunt-intro/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.215.204.118 - - [18/Sep/2013:06:51:41 +0000] "-" 400 0 "-" "-"
58.215.204.118 - - [18/Sep/2013:06:51:41 +0000] "-" 400 0 "-" "-"
58.215.204.118 - - [18/Sep/2013:06:51:41 +0000] "-" 400 0 "-" "-"
157.55.35.40 - - [18/Sep/2013:06:51:43 +0000] "GET /rhadoop-java-basic/ HTTP/1.1" 200 26780 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
58.248.178.212 - - [18/Sep/2013:06:51:43 +0000] "GET /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 HTTP/1.1" 200 7200 "http://blog.fens.me/nodejs-grunt-intro/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.248.178.212 - - [18/Sep/2013:06:51:45 +0000] "GET /wp-content/uploads/2013/08/grunt.png HTTP/1.1" 200 199040 "http://blog.fens.me/nodejs-grunt-intro/" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
58.215.204.118 - - [18/Sep/2013:06:52:26 +0000] "GET /nodejs-async/ HTTP/1.1" 200 12647 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:52:27 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-async/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:52:27 +0000] "GET /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-async/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:52:27 +0000] "GET /wp-includes/js/comment-reply.min.js?ver=3.6 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-async/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
163.177.71.12 - - [18/Sep/2013:06:52:29 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
58.215.204.118 - - [18/Sep/2013:06:52:29 +0000] "GET /nodejs-async/?cf_action=sync_comments&post_id=2357 HTTP/1.1" 200 48 "http://blog.fens.me/nodejs-async/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
163.177.71.12 - - [18/Sep/2013:06:52:32 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
58.215.204.118 - - [18/Sep/2013:06:52:32 +0000] "-" 400 0 "-" "-"
58.215.204.118 - - [18/Sep/2013:06:52:33 +0000] "-" 400 0 "-" "-"
58.215.204.118 - - [18/Sep/2013:06:52:33 +0000] "-" 400 0 "-" "-"
101.226.68.137 - - [18/Sep/2013:06:52:36 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:52:39 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
183.195.232.138 - - [18/Sep/2013:06:53:12 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
183.195.232.138 - - [18/Sep/2013:06:53:12 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
222.66.59.174 - - [18/Sep/2013:06:53:30 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0"
222.66.59.174 - - [18/Sep/2013:06:53:36 +0000] "-" 400 0 "-" "-"
216.24.201.254 - - [18/Sep/2013:06:53:57 +0000] "GET /feed/ HTTP/1.1" 200 33867 "-" "Mozilla/5.0 (Ubuntu; X11; Linux x86_64; rv:8.0) Gecko/20100101 Firefox/8.0"
58.215.204.118 - - [18/Sep/2013:06:54:48 +0000] "GET /r-json-rjson/ HTTP/1.1" 200 11500 "http://blog.fens.me/nodejs-async/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
61.135.216.105 - - [18/Sep/2013:06:54:51 +0000] "GET /comments/feed/ HTTP/1.1" 304 0 "-" "Mozilla/5.0 (compatible;YoudaoFeedFetcher/1.0;http://www.youdao.com/help/reader/faq/topic006/;1 subscribers;)"
222.66.59.174 - - [18/Sep/2013:06:55:19 +0000] "-" 400 0 "-" "-"
163.177.71.12 - - [18/Sep/2013:06:55:24 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
163.177.71.12 - - [18/Sep/2013:06:55:27 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:55:30 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:55:33 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
222.66.59.174 - - [18/Sep/2013:06:55:51 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)"
183.195.232.138 - - [18/Sep/2013:06:56:07 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
183.195.232.138 - - [18/Sep/2013:06:56:07 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
71.96.108.116 - - [18/Sep/2013:06:56:40 +0000] "GET /vps-ip-dns/ HTTP/1.1" 200 11403 "http://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=6&cad=rja&ved=0CHIQFjAF&url=http%3A%2F%2Fblog.fens.me%2Fvps-ip-dns%2F&ei=j045UrP5AYX22AXsg4G4DQ&usg=AFQjCNGsJfLMNZnwWXNpTSUl6SOEzfF6tg&sig2=YY1oxEybUL7wx3IrVIMfHA&bvm=bv.52288139,d.b2I" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0"
71.96.108.116 - - [18/Sep/2013:06:56:40 +0000] "GET /wp-content/themes/silesia/style.css HTTP/1.1" 200 7554 "http://blog.fens.me/vps-ip-dns/" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0"
71.96.108.116 - - [18/Sep/2013:06:56:40 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 200 32851 "http://blog.fens.me/vps-ip-dns/" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0"
71.96.108.116 - - [18/Sep/2013:06:56:40 +0000] "GET /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 HTTP/1.1" 200 7200 "http://blog.fens.me/vps-ip-dns/" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0"
71.96.108.116 - - [18/Sep/2013:06:56:40 +0000] "GET /wp-includes/js/comment-reply.min.js?ver=3.6 HTTP/1.1" 200 786 "http://blog.fens.me/vps-ip-dns/" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0"
71.96.108.116 - - [18/Sep/2013:06:56:40 +0000] "GET /wp-content/themes/silesia/js/jquery.cycle.all.min.js HTTP/1.1" 200 7784 "http://blog.fens.me/vps-ip-dns/" "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0"
(2)期望输出数据
每行字段长度都大于11。
2)需求分析
需要在Map阶段对输入的数据根据规则进行过滤清洗。
3)实现代码
(1)编写LogMapper类
package com.yyds.mapreduce.weblog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取1行数据
String line = value.toString();
// 2 解析日志
boolean result = parseLog(line,context);
// 3 日志不合法退出
if (!result) {
return;
}
// 4 日志合法就直接写出
context.write(value, NullWritable.get());
}
// 2 封装解析日志的方法
private boolean parseLog(String line, Context context) {
// 1 截取
String[] fields = line.split(" ");
// 2 日志长度大于11的为合法
if (fields.length > 11) {
// 系统计数器
context.getCounter("ETL", "True").increment(1);
return true;
}else {
context.getCounter("ETL", "False").increment(1);
return false;
}
}
} (2)编写LogDriver类
package com.yyds.mapreduce.weblog;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/inputlog", "e:/output1" };
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(LogDriver.class);
// 3 关联map
job.setMapperClass(LogMapper.class);
// 4 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置reducetask个数为0
job.setNumReduceTasks(0);
// 5 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}14、MapReduce开发总结
1. 输入数据接口∶InputFormat
(1)默认使用的实现类是∶TextInputFormat
(2)TextInputFormat的功能逻辑是∶一次读一行文本,然后将该行的起始偏移量作为key,行内容作为value返回。
(3)CombineTextInputFormat可以把多个小文件合并成一个切片处理,提高处理效率。
2. 逻辑处理接口∶Mapper
用户根据业务需求实现其中三个方法∶map()、setup()、cleanup()
3. Partitioner分区
(1)有默认实现 HashPartitioner,逻辑是根据key的哈希值和numReduces来返回一个分区号;key.hashCode()&Integer.MAXVALUE %numReduces
(2)如果业务上有特别的需求,可以自定义分区。
4. Comparable排序
(1)当我们用自定义的对象作为key来输出时,就必须要实现WritableComparable接口,重写其中的compareTo()方法。
(2)部分排序∶对最终输出的每一个文件进行内部排序。
(3)全排序∶对所有数据进行排序,通常只有一个Reduce。
(4)二次排序∶排序的条件有两个。
5. Combiner合并
Combiner合并可以提高程序执行效率,减少IO传输。但是使用时必须不能影响原有的业务处理结果。
6. 逻辑处理接口∶Reducer
用户根据业务需求实现其中三个方法∶reduce()、setup()、cleanup()
7. 输出数据接口∶OutputFormat
(1)默认实现类是TextOutputFormat,功能逻辑是∶将每一个KV对,向目标文本文件输出一行。
(2)将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
(3)用户还可以自定义OutputFormat。
15、Yarn资源调度器
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
1. Yarn基本架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成:
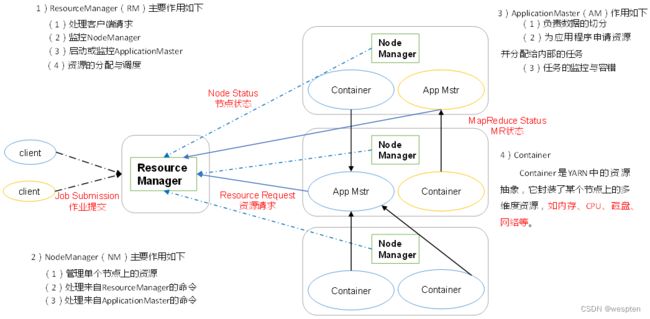
2. Yarn工作机制
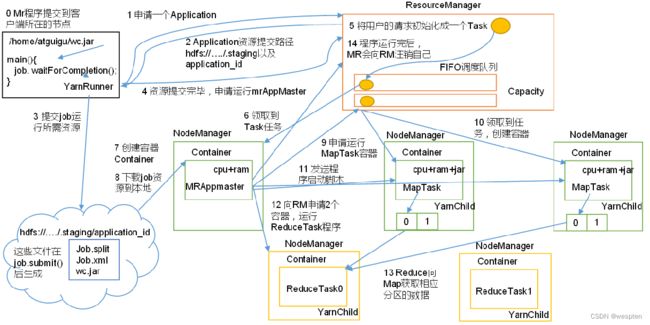
(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
3. 作业提交全过程
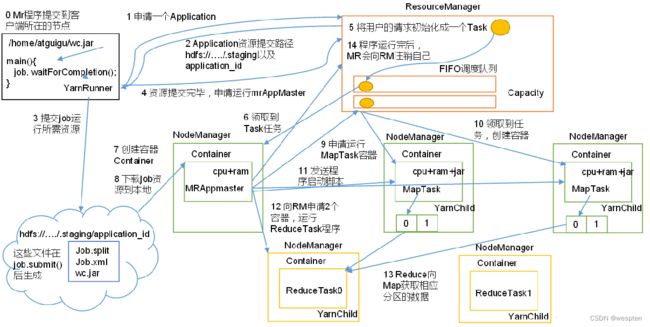
作业提交全过程详解
(1)作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
(2)作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
(3)任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(4)任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
(5)进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
作业提交过程之MapReduce:
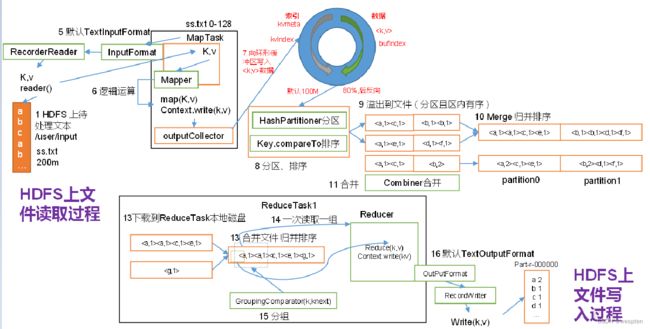
4. 资源调度器
目前,Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop3.1.3默认的资源调度器是Capacity Scheduler。
具体设置详见:yarn-default.xml文件
The class to use as the resource scheduler.
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
1)先进先出调度器(FIFO)
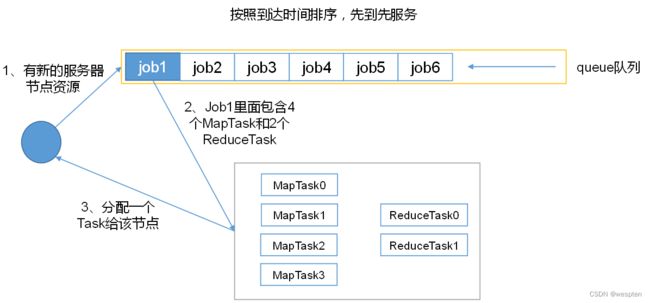
Hadoop最初设计目的是支持大数据批处理作业,如日志挖掘、Web索引等作业,
为此,Hadoop仅提供了一个非常简单的调度机制:FIFO,即先来先服务,在该调度机制下,所有作业被统一提交到一个队列中,Hadoop按照提交顺序依次运行这些作业。
但随着Hadoop的普及,单个Hadoop集群的用户量越来越大,不同用户提交的应用程序往往具有不同的服务质量要求,典型的应用有以下几种:
批处理作业:这种作业往往耗时较长,对时间完成一般没有严格要求,如数据挖掘、机器学习等方面的应用程序。
交互式作业:这种作业期望能及时返回结果,如SQL查询(Hive)等。
生产性作业:这种作业要求有一定量的资源保证,如统计值计算、垃圾数据分析等。
此外,这些应用程序对硬件资源需求量也是不同的,如过滤、统计类作业一般为CPU密集型作业,而数据挖掘、机器学习作业一般为I/O密集型作业。因此,简单的FIFO调度策略不仅不能满足多样化需求,也不能充分利用硬件资源。
2)容量调度器(Capacity Scheduler)

Capacity Scheduler Capacity Scheduler 是Yahoo开发的多用户调度器,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用。而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
总之,Capacity Scheduler 主要有以下几个特点:
①容量保证。管理员可为每个队列设置资源最低保证和资源使用上限,而所有提交到该队列的应用程序共享这些资源。
②灵活性,如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。这种资源灵活分配的方式可明显提高资源利用率。
③多重租赁。支持多用户共享集群和多应用程序同时运行。为防止单个应用程序、用户或者队列独占集群中的资源,管理员可为之增加多重约束(比如单个应用程序同时运行的任务数等)。
④安全保证。每个队列有严格的ACL列表规定它的访问用户,每个用户可指定哪些用户允许查看自己应用程序的运行状态或者控制应用程序(比如杀死应用程序)。此外,管理员可指定队列管理员和集群系统管理员。
⑤动态更新配置文件。管理员可根据需要动态修改各种配置参数,以实现在线集群管理。
3)公平调度器(Fair Scheduler)
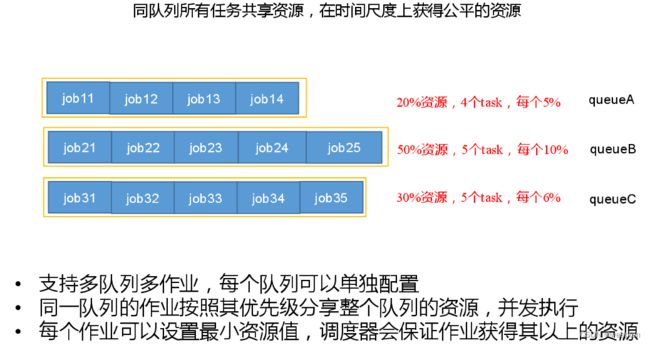
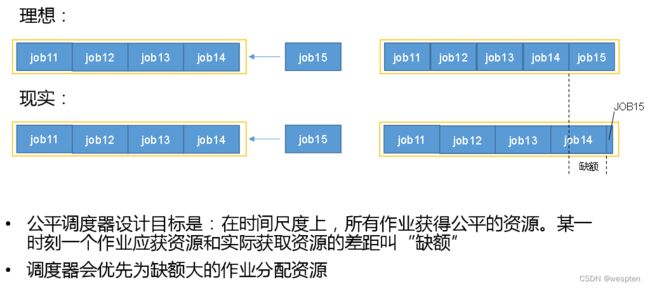
Fair Scheduler Fair Schedulere是Facebook开发的多用户调度器。
公平调度器的目的是让所有的作业随着时间的推移,都能平均地获取等同的共享资源。当有作业提交上来,系统会将空闲的资源分配给新的作业,每个任务大致上会获取平等数量的资源。和传统的调度策略不同的是它会让小的任务在合理的时间完成,同时不会让需要长时间运行的耗费大量资源的任务挨饿!
同Capacity Scheduler类似,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用;当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
当然,Fair Scheduler也存在很多与Capacity Scheduler不同之处,这主要体现在以下几个方面:
- 资源公平共享。在每个队列中,Fair Scheduler 可选择按照FIFO、Fair或DRF策略为应用程序分配资源。其中,
FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,就是禁用掉每个队列中的Task共享队列资源,此时公平调度器相当于上面讲过的容量调度器。
Fair策略
Fair 策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
【扩展:】最大最小公平算法举例:
1)不加权(关注点是job的个数)
有一条队列总资源12个, 有4个job,对资源的需求分别是:
job1->1, job2->2 , job3->6, job4->5
第一次算: 12 / 4 = 3
job1: 分3 --> 多2个
job2: 分3 --> 多1个
job3: 分3 --> 差3个
job4: 分3 --> 差2个
第二次算: 3 / 2 = 1.5
job1: 分1
job2: 分2
job3: 分3 --> 差3个 --> 分1.5 --> 最终: 4.5
job4: 分3 --> 差2个 --> 分1.5 --> 最终: 4.5
第n次算: 一直算到没有空闲资源2)加权(关注点是job的权重)
有一条队列总资源16,有4个job
对资源的需求分别是: job1->4 job2->2 job3->10 job4->4
每个job的权重为: job1->5 job2->8 job3->1 job4->2
第一次算: 16 / (5+8+1+2) = 1
job1: 分5 --> 多1
job2: 分8 --> 多6
job3: 分1 --> 少9
job4: 分2 --> 少2
第二次算: 7 / (1+2) = 7/3
job1: 分4
job2: 分2
job3: 分1 --> 分7/3 --> 少
job4: 分2 --> 分14/3(4.66) -->多2.66
第三次算:
job1: 分4
job2: 分2
job3: 分1 --> 分7/3 --> 分2.66
job4: 分4
第n次算: 一直算到没有空闲资源DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU, 100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
① 支持资源抢占。当某个队列中有剩余资源时,调度器会将这些资源共享给其他队列,而当该队列中有新的应用程序提交时,调度器要为它回收资源。为了尽可能降低不必要的计算浪费,调度器采用了先等待再强制回收的策略,即如果等待一段时间后尚有未归还的资源,则会进行资源抢占:从那些超额使用资源的队列中杀死一部分任务,进而释放资源。
yarn.scheduler.fair.preemption=true 通过该配置开启资源抢占。
② 提高小应用程序响应时间。由于采用了最大最小公平算法,小作业可以快速获取资源并运行完成
5. 容量调度器多队列提交案例
1)需求
Yarn默认的容量调度器是一条单队列的调度器,在实际使用中会出现单个任务阻塞整个队列的情况。同时,随着业务的增长,公司需要分业务限制集群使用率。这就需要我们按照业务种类配置多条任务队列。
2)配置多队列的容量调度器
默认Yarn的配置下,容量调度器只有一条Default队列。在capacity-scheduler.xml中可以配置多条队列,并降低default队列资源占比:
yarn.scheduler.capacity.root.queues
default,hive
The queues at the this level (root is the root queue).
yarn.scheduler.capacity.root.default.capacity
40
yarn.scheduler.capacity.root.default.maximum-capacity
60
同时为新加队列添加必要属性:
yarn.scheduler.capacity.root.hive.capacity
60
yarn.scheduler.capacity.root.hive.user-limit-factor
1
yarn.scheduler.capacity.root.hive.maximum-capacity
yarn.scheduler.capacity.root.hive.state
RUNNING
yarn.scheduler.capacity.root.hive.acl_submit_applications
*
yarn.scheduler.capacity.root.hive.acl_administer_queue
*
yarn.scheduler.capacity.root.hive.acl_application_max_priority
*
yarn.scheduler.capacity.root.hive.maximum-application-lifetime
-1
yarn.scheduler.capacity.root.hive.default-application-lifetime
-1
在配置完成后,重启Yarn或者执行yarn rmadmin -refreshQueues刷新队列,就可以看到两条队列:
3)向Hive队列提交任务
默认的任务提交都是提交到default队列的。如果希望向其他队列提交任务,需要在Driver中声明:
public class WcDrvier {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.queuename","hive");
//1. 获取一个Job实例
Job job = Job.getInstance(configuration);
//2. 设置类路径
job.setJarByClass(WcDrvier.class);
//3. 设置Mapper和Reducer
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
//4. 设置Mapper和Reducer的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setCombinerClass(WcReducer.class);
//5. 设置输入输出文件
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//6. 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}这样,这个任务在集群提交时,就会提交到hive队列:
16、常见错误及解决方案
1)导包容易出错。尤其Text和CombineTextInputFormat。
2)Mapper中第一个输入的参数必须是LongWritable或者NullWritable,不可以是IntWritable. 报的错误是类型转换异常。
3)java.lang.Exception: java.io.IOException: Illegal partition for 13926435656 (4),说明Partition和ReduceTask个数没对上,调整ReduceTask个数。
4)如果分区数不是1,但是reducetask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
5)在Windows环境编译的jar包导入到Linux环境中运行:
hadoop jar wc.jar com.yyds.mapreduce.wordcount.WordCountDriver /user/yyds/ /user/yyds/output报如下错误:
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/yyds/mapreduce/wordcount/WordCountDriver : Unsupported major.minor version 52.0原因是Windows环境用的jdk1.7,Linux环境用的jdk1.8。
解决方案:统一jdk版本。
6)缓存pd.txt小文件案例中,报找不到pd.txt文件
原因:大部分为路径书写错误。还有就是要检查pd.txt.txt的问题。还有个别电脑写相对路径找不到pd.txt,可以修改为绝对路径。
7)报类型转换异常。
通常都是在驱动函数中设置Map输出和最终输出时编写错误。
Map输出的key如果没有排序,也会报类型转换异常。
8)集群中运行wc.jar时出现了无法获得输入文件。
原因:WordCount案例的输入文件不能放用HDFS集群的根目录。
9)出现了如下相关异常
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:609)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)
at org.apache.hadoop.util.Shell.(Shell.java:364) 解决方案:拷贝hadoop.dll文件到Windows目录C:\Windows\System32。个别同学电脑还需要修改Hadoop源码。
方案二:创建如下包名,并将NativeIO.java拷贝到该包名下
NativeIO.java
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.io.nativeio;
import java.io.File;
import java.io.FileDescriptor;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.lang.reflect.Field;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.CommonConfigurationKeys;
import org.apache.hadoop.fs.HardLink;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SecureIOUtils.AlreadyExistsException;
import org.apache.hadoop.util.NativeCodeLoader;
import org.apache.hadoop.util.Shell;
import org.apache.hadoop.util.PerformanceAdvisory;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import sun.misc.Unsafe;
import com.google.common.annotations.VisibleForTesting;
/**
* JNI wrappers for various native IO-related calls not available in Java. These
* functions should generally be used alongside a fallback to another more
* portable mechanism.
*/
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class NativeIO {
public static class POSIX {
// Flags for open() call from bits/fcntl.h
public static final int O_RDONLY = 00;
public static final int O_WRONLY = 01;
public static final int O_RDWR = 02;
public static final int O_CREAT = 0100;
public static final int O_EXCL = 0200;
public static final int O_NOCTTY = 0400;
public static final int O_TRUNC = 01000;
public static final int O_APPEND = 02000;
public static final int O_NONBLOCK = 04000;
public static final int O_SYNC = 010000;
public static final int O_ASYNC = 020000;
public static final int O_FSYNC = O_SYNC;
public static final int O_NDELAY = O_NONBLOCK;
// Flags for posix_fadvise() from bits/fcntl.h
/* No further special treatment. */
public static final int POSIX_FADV_NORMAL = 0;
/* Expect random page references. */
public static final int POSIX_FADV_RANDOM = 1;
/* Expect sequential page references. */
public static final int POSIX_FADV_SEQUENTIAL = 2;
/* Will need these pages. */
public static final int POSIX_FADV_WILLNEED = 3;
/* Don't need these pages. */
public static final int POSIX_FADV_DONTNEED = 4;
/* Data will be accessed once. */
public static final int POSIX_FADV_NOREUSE = 5;
/*
* Wait upon writeout of all pages in the range before performing the write.
*/
public static final int SYNC_FILE_RANGE_WAIT_BEFORE = 1;
/*
* Initiate writeout of all those dirty pages in the range which are not
* presently under writeback.
*/
public static final int SYNC_FILE_RANGE_WRITE = 2;
/*
* Wait upon writeout of all pages in the range after performing the write.
*/
public static final int SYNC_FILE_RANGE_WAIT_AFTER = 4;
private static final Log LOG = LogFactory.getLog(NativeIO.class);
private static boolean nativeLoaded = false;
private static boolean fadvisePossible = true;
private static boolean syncFileRangePossible = true;
static final String WORKAROUND_NON_THREADSAFE_CALLS_KEY = "hadoop.workaround.non.threadsafe.getpwuid";
static final boolean WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT = true;
private static long cacheTimeout = -1;
private static CacheManipulator cacheManipulator = new CacheManipulator();
public static CacheManipulator getCacheManipulator() {
return cacheManipulator;
}
public static void setCacheManipulator(CacheManipulator cacheManipulator) {
POSIX.cacheManipulator = cacheManipulator;
}
/**
* Used to manipulate the operating system cache.
*/
@VisibleForTesting
public static class CacheManipulator {
public void mlock(String identifier, ByteBuffer buffer, long len) throws IOException {
POSIX.mlock(buffer, len);
}
public long getMemlockLimit() {
return NativeIO.getMemlockLimit();
}
public long getOperatingSystemPageSize() {
return NativeIO.getOperatingSystemPageSize();
}
public void posixFadviseIfPossible(String identifier, FileDescriptor fd, long offset, long len, int flags)
throws NativeIOException {
NativeIO.POSIX.posixFadviseIfPossible(identifier, fd, offset, len, flags);
}
public boolean verifyCanMlock() {
return NativeIO.isAvailable();
}
}
/**
* A CacheManipulator used for testing which does not actually call mlock. This
* allows many tests to be run even when the operating system does not allow
* mlock, or only allows limited mlocking.
*/
@VisibleForTesting
public static class NoMlockCacheManipulator extends CacheManipulator {
public void mlock(String identifier, ByteBuffer buffer, long len) throws IOException {
LOG.info("mlocking " + identifier);
}
public long getMemlockLimit() {
return 1125899906842624L;
}
public long getOperatingSystemPageSize() {
return 4096;
}
public boolean verifyCanMlock() {
return true;
}
}
static {
if (NativeCodeLoader.isNativeCodeLoaded()) {
try {
Configuration conf = new Configuration();
workaroundNonThreadSafePasswdCalls = conf.getBoolean(WORKAROUND_NON_THREADSAFE_CALLS_KEY,
WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT);
initNative();
nativeLoaded = true;
cacheTimeout = conf.getLong(CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_KEY,
CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_DEFAULT) * 1000;
LOG.debug("Initialized cache for IDs to User/Group mapping with a " + " cache timeout of "
+ cacheTimeout / 1000 + " seconds.");
} catch (Throwable t) {
// This can happen if the user has an older version of libhadoop.so
// installed - in this case we can continue without native IO
// after warning
PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t);
}
}
}
/**
* Return true if the JNI-based native IO extensions are available.
*/
public static boolean isAvailable() {
return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded;
}
private static void assertCodeLoaded() throws IOException {
if (!isAvailable()) {
throw new IOException("NativeIO was not loaded");
}
}
/** Wrapper around open(2) */
public static native FileDescriptor open(String path, int flags, int mode) throws IOException;
/** Wrapper around fstat(2) */
private static native Stat fstat(FileDescriptor fd) throws IOException;
/** Native chmod implementation. On UNIX, it is a wrapper around chmod(2) */
private static native void chmodImpl(String path, int mode) throws IOException;
public static void chmod(String path, int mode) throws IOException {
if (!Shell.WINDOWS) {
chmodImpl(path, mode);
} else {
try {
chmodImpl(path, mode);
} catch (NativeIOException nioe) {
if (nioe.getErrorCode() == 3) {
throw new NativeIOException("No such file or directory", Errno.ENOENT);
} else {
LOG.warn(
String.format("NativeIO.chmod error (%d): %s", nioe.getErrorCode(), nioe.getMessage()));
throw new NativeIOException("Unknown error", Errno.UNKNOWN);
}
}
}
}
/** Wrapper around posix_fadvise(2) */
static native void posix_fadvise(FileDescriptor fd, long offset, long len, int flags) throws NativeIOException;
/** Wrapper around sync_file_range(2) */
static native void sync_file_range(FileDescriptor fd, long offset, long nbytes, int flags)
throws NativeIOException;
/**
* Call posix_fadvise on the given file descriptor. See the manpage for this
* syscall for more information. On systems where this call is not available,
* does nothing.
*
* @throws NativeIOException
* if there is an error with the syscall
*/
static void posixFadviseIfPossible(String identifier, FileDescriptor fd, long offset, long len, int flags)
throws NativeIOException {
if (nativeLoaded && fadvisePossible) {
try {
posix_fadvise(fd, offset, len, flags);
} catch (UnsupportedOperationException uoe) {
fadvisePossible = false;
} catch (UnsatisfiedLinkError ule) {
fadvisePossible = false;
}
}
}
/**
* Call sync_file_range on the given file descriptor. See the manpage for this
* syscall for more information. On systems where this call is not available,
* does nothing.
*
* @throws NativeIOException
* if there is an error with the syscall
*/
public static void syncFileRangeIfPossible(FileDescriptor fd, long offset, long nbytes, int flags)
throws NativeIOException {
if (nativeLoaded && syncFileRangePossible) {
try {
sync_file_range(fd, offset, nbytes, flags);
} catch (UnsupportedOperationException uoe) {
syncFileRangePossible = false;
} catch (UnsatisfiedLinkError ule) {
syncFileRangePossible = false;
}
}
}
static native void mlock_native(ByteBuffer buffer, long len) throws NativeIOException;
/**
* Locks the provided direct ByteBuffer into memory, preventing it from swapping
* out. After a buffer is locked, future accesses will not incur a page fault.
*
* See the mlock(2) man page for more information.
*
* @throws NativeIOException
*/
static void mlock(ByteBuffer buffer, long len) throws IOException {
assertCodeLoaded();
if (!buffer.isDirect()) {
throw new IOException("Cannot mlock a non-direct ByteBuffer");
}
mlock_native(buffer, len);
}
/**
* Unmaps the block from memory. See munmap(2).
*
* There isn't any portable way to unmap a memory region in Java. So we use the
* sun.nio method here. Note that unmapping a memory region could cause crashes
* if code continues to reference the unmapped code. However, if we don't
* manually unmap the memory, we are dependent on the finalizer to do it, and we
* have no idea when the finalizer will run.
*
* @param buffer
* The buffer to unmap.
*/
public static void munmap(MappedByteBuffer buffer) {
if (buffer instanceof sun.nio.ch.DirectBuffer) {
sun.misc.Cleaner cleaner = ((sun.nio.ch.DirectBuffer) buffer).cleaner();
cleaner.clean();
}
}
/** Linux only methods used for getOwner() implementation */
private static native long getUIDforFDOwnerforOwner(FileDescriptor fd) throws IOException;
private static native String getUserName(long uid) throws IOException;
/**
* Result type of the fstat call
*/
public static class Stat {
private int ownerId, groupId;
private String owner, group;
private int mode;
// Mode constants
public static final int S_IFMT = 0170000; /* type of file */
public static final int S_IFIFO = 0010000; /* named pipe (fifo) */
public static final int S_IFCHR = 0020000; /* character special */
public static final int S_IFDIR = 0040000; /* directory */
public static final int S_IFBLK = 0060000; /* block special */
public static final int S_IFREG = 0100000; /* regular */
public static final int S_IFLNK = 0120000; /* symbolic link */
public static final int S_IFSOCK = 0140000; /* socket */
public static final int S_IFWHT = 0160000; /* whiteout */
public static final int S_ISUID = 0004000; /* set user id on execution */
public static final int S_ISGID = 0002000; /* set group id on execution */
public static final int S_ISVTX = 0001000; /* save swapped text even after use */
public static final int S_IRUSR = 0000400; /* read permission, owner */
public static final int S_IWUSR = 0000200; /* write permission, owner */
public static final int S_IXUSR = 0000100; /* execute/search permission, owner */
Stat(int ownerId, int groupId, int mode) {
this.ownerId = ownerId;
this.groupId = groupId;
this.mode = mode;
}
Stat(String owner, String group, int mode) {
if (!Shell.WINDOWS) {
this.owner = owner;
} else {
this.owner = stripDomain(owner);
}
if (!Shell.WINDOWS) {
this.group = group;
} else {
this.group = stripDomain(group);
}
this.mode = mode;
}
@Override
public String toString() {
return "Stat(owner='" + owner + "', group='" + group + "'" + ", mode=" + mode + ")";
}
public String getOwner() {
return owner;
}
public String getGroup() {
return group;
}
public int getMode() {
return mode;
}
}
/**
* Returns the file stat for a file descriptor.
*
* @param fd
* file descriptor.
* @return the file descriptor file stat.
* @throws IOException
* thrown if there was an IO error while obtaining the file stat.
*/
public static Stat getFstat(FileDescriptor fd) throws IOException {
Stat stat = null;
if (!Shell.WINDOWS) {
stat = fstat(fd);
stat.owner = getName(IdCache.USER, stat.ownerId);
stat.group = getName(IdCache.GROUP, stat.groupId);
} else {
try {
stat = fstat(fd);
} catch (NativeIOException nioe) {
if (nioe.getErrorCode() == 6) {
throw new NativeIOException("The handle is invalid.", Errno.EBADF);
} else {
LOG.warn(String.format("NativeIO.getFstat error (%d): %s", nioe.getErrorCode(),
nioe.getMessage()));
throw new NativeIOException("Unknown error", Errno.UNKNOWN);
}
}
}
return stat;
}
private static String getName(IdCache domain, int id) throws IOException {
Map idNameCache = (domain == IdCache.USER) ? USER_ID_NAME_CACHE : GROUP_ID_NAME_CACHE;
String name;
CachedName cachedName = idNameCache.get(id);
long now = System.currentTimeMillis();
if (cachedName != null && (cachedName.timestamp + cacheTimeout) > now) {
name = cachedName.name;
} else {
name = (domain == IdCache.USER) ? getUserName(id) : getGroupName(id);
if (LOG.isDebugEnabled()) {
String type = (domain == IdCache.USER) ? "UserName" : "GroupName";
LOG.debug("Got " + type + " " + name + " for ID " + id + " from the native implementation");
}
cachedName = new CachedName(name, now);
idNameCache.put(id, cachedName);
}
return name;
}
static native String getUserName(int uid) throws IOException;
static native String getGroupName(int uid) throws IOException;
private static class CachedName {
final long timestamp;
final String name;
public CachedName(String name, long timestamp) {
this.name = name;
this.timestamp = timestamp;
}
}
private static final Map USER_ID_NAME_CACHE = new ConcurrentHashMap();
private static final Map GROUP_ID_NAME_CACHE = new ConcurrentHashMap();
private enum IdCache {
USER, GROUP
}
public final static int MMAP_PROT_READ = 0x1;
public final static int MMAP_PROT_WRITE = 0x2;
public final static int MMAP_PROT_EXEC = 0x4;
public static native long mmap(FileDescriptor fd, int prot, boolean shared, long length) throws IOException;
public static native void munmap(long addr, long length) throws IOException;
}
private static boolean workaroundNonThreadSafePasswdCalls = false;
public static class Windows {
// Flags for CreateFile() call on Windows
public static final long GENERIC_READ = 0x80000000L;
public static final long GENERIC_WRITE = 0x40000000L;
public static final long FILE_SHARE_READ = 0x00000001L;
public static final long FILE_SHARE_WRITE = 0x00000002L;
public static final long FILE_SHARE_DELETE = 0x00000004L;
public static final long CREATE_NEW = 1;
public static final long CREATE_ALWAYS = 2;
public static final long OPEN_EXISTING = 3;
public static final long OPEN_ALWAYS = 4;
public static final long TRUNCATE_EXISTING = 5;
public static final long FILE_BEGIN = 0;
public static final long FILE_CURRENT = 1;
public static final long FILE_END = 2;
public static final long FILE_ATTRIBUTE_NORMAL = 0x00000080L;
/**
* Create a directory with permissions set to the specified mode. By setting
* permissions at creation time, we avoid issues related to the user lacking
* WRITE_DAC rights on subsequent chmod calls. One example where this can occur
* is writing to an SMB share where the user does not have Full Control rights,
* and therefore WRITE_DAC is denied.
*
* @param path
* directory to create
* @param mode
* permissions of new directory
* @throws IOException
* if there is an I/O error
*/
public static void createDirectoryWithMode(File path, int mode) throws IOException {
createDirectoryWithMode0(path.getAbsolutePath(), mode);
}
/** Wrapper around CreateDirectory() on Windows */
private static native void createDirectoryWithMode0(String path, int mode) throws NativeIOException;
/** Wrapper around CreateFile() on Windows */
public static native FileDescriptor createFile(String path, long desiredAccess, long shareMode,
long creationDisposition) throws IOException;
/**
* Create a file for write with permissions set to the specified mode. By
* setting permissions at creation time, we avoid issues related to the user
* lacking WRITE_DAC rights on subsequent chmod calls. One example where this
* can occur is writing to an SMB share where the user does not have Full
* Control rights, and therefore WRITE_DAC is denied.
*
* This method mimics the semantics implemented by the JDK in
* {@link java.io.FileOutputStream}. The file is opened for truncate or append,
* the sharing mode allows other readers and writers, and paths longer than
* MAX_PATH are supported. (See io_util_md.c in the JDK.)
*
* @param path
* file to create
* @param append
* if true, then open file for append
* @param mode
* permissions of new directory
* @return FileOutputStream of opened file
* @throws IOException
* if there is an I/O error
*/
public static FileOutputStream createFileOutputStreamWithMode(File path, boolean append, int mode)
throws IOException {
long desiredAccess = GENERIC_WRITE;
long shareMode = FILE_SHARE_READ | FILE_SHARE_WRITE;
long creationDisposition = append ? OPEN_ALWAYS : CREATE_ALWAYS;
return new FileOutputStream(
createFileWithMode0(path.getAbsolutePath(), desiredAccess, shareMode, creationDisposition, mode));
}
/** Wrapper around CreateFile() with security descriptor on Windows */
private static native FileDescriptor createFileWithMode0(String path, long desiredAccess, long shareMode,
long creationDisposition, int mode) throws NativeIOException;
/** Wrapper around SetFilePointer() on Windows */
public static native long setFilePointer(FileDescriptor fd, long distanceToMove, long moveMethod)
throws IOException;
/** Windows only methods used for getOwner() implementation */
private static native String getOwner(FileDescriptor fd) throws IOException;
/** Supported list of Windows access right flags */
public static enum AccessRight {
ACCESS_READ(0x0001), // FILE_READ_DATA
ACCESS_WRITE(0x0002), // FILE_WRITE_DATA
ACCESS_EXECUTE(0x0020); // FILE_EXECUTE
private final int accessRight;
AccessRight(int access) {
accessRight = access;
}
public int accessRight() {
return accessRight;
}
};
/**
* Windows only method used to check if the current process has requested access
* rights on the given path.
*/
private static native boolean access0(String path, int requestedAccess);
/**
* Checks whether the current process has desired access rights on the given
* path.
*
* Longer term this native function can be substituted with JDK7 function
* Files#isReadable, isWritable, isExecutable.
*
* @param path
* input path
* @param desiredAccess
* ACCESS_READ, ACCESS_WRITE or ACCESS_EXECUTE
* @return true if access is allowed
* @throws IOException
* I/O exception on error
*/
public static boolean access(String path, AccessRight desiredAccess) throws IOException {
return true;
// return access0(path, desiredAccess.accessRight());
}
/**
* Extends both the minimum and maximum working set size of the current process.
* This method gets the current minimum and maximum working set size, adds the
* requested amount to each and then sets the minimum and maximum working set
* size to the new values. Controlling the working set size of the process also
* controls the amount of memory it can lock.
*
* @param delta
* amount to increment minimum and maximum working set size
* @throws IOException
* for any error
* @see POSIX#mlock(ByteBuffer, long)
*/
public static native void extendWorkingSetSize(long delta) throws IOException;
static {
if (NativeCodeLoader.isNativeCodeLoaded()) {
try {
initNative();
nativeLoaded = true;
} catch (Throwable t) {
// This can happen if the user has an older version of libhadoop.so
// installed - in this case we can continue without native IO
// after warning
PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t);
}
}
}
}
private static final Log LOG = LogFactory.getLog(NativeIO.class);
private static boolean nativeLoaded = false;
static {
if (NativeCodeLoader.isNativeCodeLoaded()) {
try {
initNative();
nativeLoaded = true;
} catch (Throwable t) {
// This can happen if the user has an older version of libhadoop.so
// installed - in this case we can continue without native IO
// after warning
PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t);
}
}
}
/**
* Return true if the JNI-based native IO extensions are available.
*/
public static boolean isAvailable() {
return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded;
}
/** Initialize the JNI method ID and class ID cache */
private static native void initNative();
/**
* Get the maximum number of bytes that can be locked into memory at any given
* point.
*
* @return 0 if no bytes can be locked into memory; Long.MAX_VALUE if there is
* no limit; The number of bytes that can be locked into memory
* otherwise.
*/
static long getMemlockLimit() {
return isAvailable() ? getMemlockLimit0() : 0;
}
private static native long getMemlockLimit0();
/**
* @return the operating system's page size.
*/
static long getOperatingSystemPageSize() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
return unsafe.pageSize();
} catch (Throwable e) {
LOG.warn("Unable to get operating system page size. Guessing 4096.", e);
return 4096;
}
}
private static class CachedUid {
final long timestamp;
final String username;
public CachedUid(String username, long timestamp) {
this.timestamp = timestamp;
this.username = username;
}
}
private static final Map uidCache = new ConcurrentHashMap();
private static long cacheTimeout;
private static boolean initialized = false;
/**
* The Windows logon name has two part, NetBIOS domain name and user account
* name, of the format DOMAIN\UserName. This method will remove the domain part
* of the full logon name.
*
* @param Fthe
* full principal name containing the domain
* @return name with domain removed
*/
private static String stripDomain(String name) {
int i = name.indexOf('\\');
if (i != -1)
name = name.substring(i + 1);
return name;
}
public static String getOwner(FileDescriptor fd) throws IOException {
ensureInitialized();
if (Shell.WINDOWS) {
String owner = Windows.getOwner(fd);
owner = stripDomain(owner);
return owner;
} else {
long uid = POSIX.getUIDforFDOwnerforOwner(fd);
CachedUid cUid = uidCache.get(uid);
long now = System.currentTimeMillis();
if (cUid != null && (cUid.timestamp + cacheTimeout) > now) {
return cUid.username;
}
String user = POSIX.getUserName(uid);
LOG.info("Got UserName " + user + " for UID " + uid + " from the native implementation");
cUid = new CachedUid(user, now);
uidCache.put(uid, cUid);
return user;
}
}
/**
* Create a FileInputStream that shares delete permission on the file opened,
* i.e. other process can delete the file the FileInputStream is reading. Only
* Windows implementation uses the native interface.
*/
public static FileInputStream getShareDeleteFileInputStream(File f) throws IOException {
if (!Shell.WINDOWS) {
// On Linux the default FileInputStream shares delete permission
// on the file opened.
//
return new FileInputStream(f);
} else {
// Use Windows native interface to create a FileInputStream that
// shares delete permission on the file opened.
//
FileDescriptor fd = Windows.createFile(f.getAbsolutePath(), Windows.GENERIC_READ,
Windows.FILE_SHARE_READ | Windows.FILE_SHARE_WRITE | Windows.FILE_SHARE_DELETE,
Windows.OPEN_EXISTING);
return new FileInputStream(fd);
}
}
/**
* Create a FileInputStream that shares delete permission on the file opened at
* a given offset, i.e. other process can delete the file the FileInputStream is
* reading. Only Windows implementation uses the native interface.
*/
public static FileInputStream getShareDeleteFileInputStream(File f, long seekOffset) throws IOException {
if (!Shell.WINDOWS) {
RandomAccessFile rf = new RandomAccessFile(f, "r");
if (seekOffset > 0) {
rf.seek(seekOffset);
}
return new FileInputStream(rf.getFD());
} else {
// Use Windows native interface to create a FileInputStream that
// shares delete permission on the file opened, and set it to the
// given offset.
//
FileDescriptor fd = NativeIO.Windows.createFile(
f.getAbsolutePath(), NativeIO.Windows.GENERIC_READ, NativeIO.Windows.FILE_SHARE_READ
| NativeIO.Windows.FILE_SHARE_WRITE | NativeIO.Windows.FILE_SHARE_DELETE,
NativeIO.Windows.OPEN_EXISTING);
if (seekOffset > 0)
NativeIO.Windows.setFilePointer(fd, seekOffset, NativeIO.Windows.FILE_BEGIN);
return new FileInputStream(fd);
}
}
/**
* Create the specified File for write access, ensuring that it does not exist.
*
* @param f
* the file that we want to create
* @param permissions
* we want to have on the file (if security is enabled)
*
* @throws AlreadyExistsException
* if the file already exists
* @throws IOException
* if any other error occurred
*/
public static FileOutputStream getCreateForWriteFileOutputStream(File f, int permissions) throws IOException {
if (!Shell.WINDOWS) {
// Use the native wrapper around open(2)
try {
FileDescriptor fd = NativeIO.POSIX.open(f.getAbsolutePath(),
NativeIO.POSIX.O_WRONLY | NativeIO.POSIX.O_CREAT | NativeIO.POSIX.O_EXCL, permissions);
return new FileOutputStream(fd);
} catch (NativeIOException nioe) {
if (nioe.getErrno() == Errno.EEXIST) {
throw new AlreadyExistsException(nioe);
}
throw nioe;
}
} else {
// Use the Windows native APIs to create equivalent FileOutputStream
try {
FileDescriptor fd = NativeIO.Windows.createFile(
f.getCanonicalPath(), NativeIO.Windows.GENERIC_WRITE, NativeIO.Windows.FILE_SHARE_DELETE
| NativeIO.Windows.FILE_SHARE_READ | NativeIO.Windows.FILE_SHARE_WRITE,
NativeIO.Windows.CREATE_NEW);
NativeIO.POSIX.chmod(f.getCanonicalPath(), permissions);
return new FileOutputStream(fd);
} catch (NativeIOException nioe) {
if (nioe.getErrorCode() == 80) {
// ERROR_FILE_EXISTS
// 80 (0x50)
// The file exists
throw new AlreadyExistsException(nioe);
}
throw nioe;
}
}
}
private synchronized static void ensureInitialized() {
if (!initialized) {
cacheTimeout = new Configuration().getLong("hadoop.security.uid.cache.secs", 4 * 60 * 60) * 1000;
LOG.info("Initialized cache for UID to User mapping with a cache" + " timeout of " + cacheTimeout / 1000
+ " seconds.");
initialized = true;
}
}
/**
* A version of renameTo that throws a descriptive exception when it fails.
*
* @param src
* The source path
* @param dst
* The destination path
*
* @throws NativeIOException
* On failure.
*/
public static void renameTo(File src, File dst) throws IOException {
if (!nativeLoaded) {
if (!src.renameTo(dst)) {
throw new IOException("renameTo(src=" + src + ", dst=" + dst + ") failed.");
}
} else {
renameTo0(src.getAbsolutePath(), dst.getAbsolutePath());
}
}
public static void link(File src, File dst) throws IOException {
if (!nativeLoaded) {
HardLink.createHardLink(src, dst);
} else {
link0(src.getAbsolutePath(), dst.getAbsolutePath());
}
}
/**
* A version of renameTo that throws a descriptive exception when it fails.
*
* @param src
* The source path
* @param dst
* The destination path
*
* @throws NativeIOException
* On failure.
*/
private static native void renameTo0(String src, String dst) throws NativeIOException;
private static native void link0(String src, String dst) throws NativeIOException;
/**
* Unbuffered file copy from src to dst without tainting OS buffer cache
*
* In POSIX platform: It uses FileChannel#transferTo() which internally attempts
* unbuffered IO on OS with native sendfile64() support and falls back to
* buffered IO otherwise.
*
* It minimizes the number of FileChannel#transferTo call by passing the the src
* file size directly instead of a smaller size as the 3rd parameter. This saves
* the number of sendfile64() system call when native sendfile64() is supported.
* In the two fall back cases where sendfile is not supported,
* FileChannle#transferTo already has its own batching of size 8 MB and 8 KB,
* respectively.
*
* In Windows Platform: It uses its own native wrapper of CopyFileEx with
* COPY_FILE_NO_BUFFERING flag, which is supported on Windows Server 2008 and
* above.
*
* Ideally, we should use FileChannel#transferTo() across both POSIX and Windows
* platform. Unfortunately, the
* wrapper(Java_sun_nio_ch_FileChannelImpl_transferTo0) used by
* FileChannel#transferTo for unbuffered IO is not implemented on Windows. Based
* on OpenJDK 6/7/8 source code, Java_sun_nio_ch_FileChannelImpl_transferTo0 on
* Windows simply returns IOS_UNSUPPORTED.
*
* Note: This simple native wrapper does minimal parameter checking before copy
* and consistency check (e.g., size) after copy. It is recommended to use
* wrapper function like the Storage#nativeCopyFileUnbuffered() function in
* hadoop-hdfs with pre/post copy checks.
*
* @param src
* The source path
* @param dst
* The destination path
* @throws IOException
*/
public static void copyFileUnbuffered(File src, File dst) throws IOException {
if (nativeLoaded && Shell.WINDOWS) {
copyFileUnbuffered0(src.getAbsolutePath(), dst.getAbsolutePath());
} else {
FileInputStream fis = null;
FileOutputStream fos = null;
FileChannel input = null;
FileChannel output = null;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dst);
input = fis.getChannel();
output = fos.getChannel();
long remaining = input.size();
long position = 0;
long transferred = 0;
while (remaining > 0) {
transferred = input.transferTo(position, remaining, output);
remaining -= transferred;
position += transferred;
}
} finally {
IOUtils.cleanup(LOG, output);
IOUtils.cleanup(LOG, fos);
IOUtils.cleanup(LOG, input);
IOUtils.cleanup(LOG, fis);
}
}
}
private static native void copyFileUnbuffered0(String src, String dst) throws NativeIOException;
}
10)自定义Outputformat时,注意在RecordWirter中的close方法必须关闭流资源。否则输出的文件内容中数据为空。
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
if (yydsfos != null) {
atguigufos.close();
}
if (otherfos != null) {
otherfos.close();
}
}六、高可用Hadoop大数据平台部署与维护
1、部署高可用的hadoop大数据平台
1. 安装配置环境介绍
在这里我们选用4台机器进行示范,操作系统为centos7.5,各台机器的职责如下表格所示:
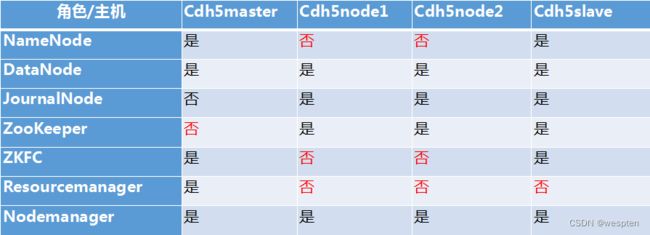
2. Zookeeper安装过程
1)下载解压zookeeper
下载地址:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.6/,解压到指定目录:这里我们统一安装到/opt目录下。
在/opt目录中创建zookeeper目录。把文件解压到zookeeper目录中,这样做是为了以后整个软件可以打包移植。包括后面我们会安装hadoop、HBase、Hive等软件,都是安装到/opt目录中。
2)修改配置文件
进入zookeeper中conf目录,拷贝命名zoo_sample.cfg 为zoo.cfg。我们一般不修改配置文件默认的示例文件,修改赋值其子文件。
编辑zoo.cfg,内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
dataLogDir=/data/zookeeper/zkdatalog
clientPort=2181
server.1=cdh5node1:2888:3888
server.2=cdh5node2:2888:3888
server.3=cdh5slave:2888:3888接着,创建/data/zookeeper目录后。进入此文件夹,创建文件myid,填入1。这里写入的1,是在zoo.cfg文本中的server.1中的1。
接着,登录cdh5node2节点,按照上面方法继续安装zookeeper,然后在cdh5node2节点的/data/zookeeper目录下继续创建内容为2的myid文件,其余节点,安照上面配置,依此写入相应的数字。zkdatalog文件夹,是为了指定zookeeper产生日志指定相应的路径。
3)添加环境变量
在hadoop用户的.bashrc文件中添加zookeeper环境变量,内容如下:
export ZOOKEEPER_HOME=/opt/zookeeper/current
export PATH=$PATH:$ZOOKEEPER_HOME/bin3. hadoop的安装
1)下载hadoop
这里我们采用CDH发行版本,cloudera CDH官方网站下载地址为:
http://www.cloudera.com/downloads.html,也可以到下面地址下载不同版本:
http://archive.cloudera.com/cdh/
http://archive.cloudera.com/cdh4/
http://archive.cloudera.com/cdh5/,这里我们下载CDH5最新版本CDH5.15.1版本。 2)JDK的安装
CDH5.15.1版本对JDK是有要求的,jdk需要oracle JDK1.7.0_55以上,或者JDK1.8.0_31以上。这里我们使用jdk1.8.0_162版本。
将JDK下载完成后,放到系统的/usr/java目录下,为了运维方面,推荐做如下操作:
[root@cdh5node1 java]# mkdir /usr/java
[root@cdh5node1 java]# cd /usr/java
[root@cdh5node1 java]# ln -s jdk1.8.0_162 default通过软连接的方式可以将不同jdk版本连接到default这个目录下,这样做对于以后jdk版本的升级非常方便,无需修改关于jdk的环境变量信息。
3)安装CDH5.15.1
这里约定,将hadoop程序部署到系统的/opt目录下,将hadoop的配置文件部署到/etc/hadoop目录下。通过将程序和配置文件分离部署,有利于以后hadoop的维护和升级管理。
CDH支持yum/apt包,RPM包,tarball包多种安装方式,根据hadoop运维需要,我们选择tarball的安装方式。
tarball方式安装很简单,只需解压文件即可完成安装,然后将解压后的目录放到/opt目录下,进行授权即可,安装过程如下:
[root@cdh5namenode opt]# useradd hadoop
[root@cdh5namenode opt]mkdir /opt/hadoop
[root@cdh5namenode opt]mkdir /etc/hadoop
[root@cdh5namenode opt]#cd /opt/hadoop
[root@cdh5namenode hadoop]#tar zxvf hadoop-2.6.0-cdh5.15.1.tar.gz
[root@cdh5namenode hadoop]#cp /opt/hadoop/hadoop-2.6.0-cdh5.15.1/etc/hadoop \
>/etc/hadoop/conf
[root@cdh5namenode hadoop]#ln –s hadoop-2.6.0-cdh5.15.1 current
[root@cdh5namenode hadoop]#chown -R hadoop:hadoop /opt/hadoop
[root@cdh5namenode hadoop]# chown -R hadoop:hadoop /etc/hadoop 4)设置hadoop用户环境变量
设置hadoop环境变量主要是设置jdk、hadoop主程序、hadoop配置文件等配置信息,环境变量可以有多种配置方法,可以配置到/etc/profile文件中,也可以配置到hadoop用户的.bash_profile或.bashrc文件中,这里我们将环境变量配置到.bashrc文件中,内容如下:
export JAVA_HOME=/usr/java/default
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_PREFIX=/opt/hadoop/current
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HTTPFS_CATALINA_HOME=${HADOOP_PREFIX}/share/hadoop/httpfs/tomcat
export CATALINA_BASE=${HTTPFS_CATALINA_HOME}
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
export HTTPFS_CONFIG=/etc/hadoop/conf
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin 5)设置主机名本地解析
Hadoop默认通过主机名识别每个节点,因此需要设置每个节点的主机名和IP解析关系,有两种方法可以实现此功能,一种是在hadoop集群内部部署DNS server,通过DNS解析功能实现主机名和IP的解析,此方法适合大型hadoop集群结构,如果集群节点较少(少于100个),也可以通过在每个节点添加本地解析的方式实现主机名和IP的解析。
这里采用本地解析的方式来解析主机名,在hadoop每个节点的/etc/hosts文件中添加如下内容:
172.16.212.50 cdh5master
172.16.212.51 cdh5node1
172.16.212.52 cdh5node2
172.16.212.53 cdh5slave
4. hadoop的配置
Hadoop需要进行配置的文件一共包括6个,分别是hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和hosts。除了hdfs-site.xml文件在不同集群配置不同外,其余文件在集群节点的配置是完全一样的,可以复制。
1)配置hadoop-env.sh
hadoop-env.sh文件是hadoop的环境变量配置文件,主要是对hadoop的JDK路径,JVM优化参数进行设置等,初次安装hadoop时,只需修改如下内容即可,修改后的结果如下:
export JAVA_HOME=/usr/java/default 注意:这里的JAVA_HOME的值是jdk的安装路径。请修改为自己的地址
2)配置core-site.xml
core-site.xml是namenode的核心配置文件,主要对namenode的属性进行设置,也仅仅在namenode节点生效。core-site.xml文件有很多参数,但不是所有参数都需要进行设置,只需要设置必须的和常用的一些参数即可,下面列出了必须的和常用的一些参数的设置以及参数含义:
fs.defaultFS
hdfs://cdh5
这里的值指的是默认的HDFS路径。当有多个HDFS集群同时工作时,用户如果不写集群名称,那么默认使用哪个呢?所以,需要在这里指定!该值来自于hdfs-site.xml中的配置。
hadoop.tmp.dir
/var/tmp/hadoop-${user.name}
这里的路径默认是NameNode、DataNode、JournalNode等存放临时数据的公共目录。用户也可以自己单独指定这三类节点的目录。
ha.zookeeper.quorum
cdh5node1, cdh5node2, cdh5slave
这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点:
fs.trash.interval
60
定义.Trash目录下文件被永久删除前保留的时间。在文件被从HDFS永久删除前,用户可以自由地把文件从该目录下移出来并立即还原。默认值是0说明垃圾回收站功能是关闭的。一般开启这个会比较好,以防错误删除重要文件。单位是分钟。
3)配置hdfs-site.xml
hdfs-site.xml文件是hdfs的核心配置文件,主要配置namenode、datanode的一些基于HDFS的属性信息、在namenode和datanode节点生效。hdfs-site.xml文件有很多参数,但不是所有参数都需要进行设置,只需要设置必须的和常用的一些参数即可,下面列出了必须的和常用的一些参数的设置以及参数含义:
dfs.nameservices
cdh5
使用federation时,使用了2个HDFS集群。这里抽象出两个NameService实际上就是给这2个HDFS集群起了个别名。名字可以随便起,相互不重复即可
dfs.ha.namenodes.cdh5
nn1,nn2
指定NameService是cdh5的namenode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可。
dfs.namenode.rpc-address.cdh5.nn1
cdh5master:9000
指定nn1的RPC地址。
dfs.namenode.rpc-address.cdh5.nn2
cdh5slave:9000
指定nn2的RPC地址。
dfs.namenode.http-address.cdh5.nn1
cdh5master:50070
指定nn1的http地址。
dfs.namenode.http-address.cdh5.nn2
cdh5slave:50070
指定nn2的http地址。
dfs.namenode.shared.edits.dir
qjournal://cdh5node1:8485; cdh5node2:8485; cdh5slave:8485/cdh5
指定cluster1的两个NameNode共享edits文件目录时,使用的JournalNode集群信息
dfs.ha.automatic-failover.enabled.cdh5
true
指定cdh5是否启动自动故障恢复,即当NameNode出故障时,是否自动切换到另一台NameNode。
dfs.client.failover.proxy.provider.cdh5
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
配置失败自动切换实现方式,指定cdh5出故障时,哪个实现类负责执行故障切换。
dfs.journalnode.edits.dir
/data1/hadoop/dfs/jn
指定JournalNode集群在对NameNode的目录进行共享时,自己存储数据的本地磁盘存放数据的位置。
dfs.replication
2
指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可。
dfs.ha.fencing.methods
shell(/bin/true)
配置隔离机制,一旦需要NameNode切换,使用shell方式进行操作。
dfs.namenode.name.dir
file:///data1/hadoop/dfs/name,file:///data2/hadoop/dfs/name
true
这个参数用于确定将HDFS文件系统的元信息保存在什么目录下。
如果这个参数设置为多个目录,那么这些目录下都保存着元信息的多个备份。
dfs.datanode.data.dir
file:///data1/hadoop/dfs/data,file:///data2/hadoop/dfs/data,file:///data3/hadoop/dfs/data,file:///data4/hadoop/dfs/data
true
这个参数用于确定将HDFS文件系统的数据保存在什么目录下。
我们可以将这个参数设置为多个分区上目录,即可将HDFS建立在不同分区上。
dfs.block.size
134217728
设置hdfs块大小,这么设置的是每个块128M。
dfs.permissions
true
是否在HDFS中开启权限检查,true表示开启,false表示关闭,生产环境建议开启。
dfs.permissions.supergroup
supergroup
指定超级用户组。仅能设置一个。
dfs.hosts
/etc/hadoop/conf/hosts
可与namenode连接的主机地址文件指定,hosts文件中每行一个主机名。
dfs.hosts.exclude
/etc/hadoop/conf/hosts-exclude
不允许与namenode连接的主机地址文件设定,与上面hosts文件写法一样。
4)配置mapred-site.xml
mapred-site.xml文件是MRv1版本中针对MR的配置文件,此文件在hadoop2.x版本以后,需要配置的参数很少,下面列出了必须的和常用的一些参数的设置以及参数含义:
mapreduce.framework.name
yarn
指定运行mapreduce的环境是yarn,与hadoop1.x版本截然不同的地方。
mapreduce.jobhistory.address
cdh5master:10020
MapReduce JobHistory Server地址。
mapreduce.jobhistory.webapp.address
cdh5master:19888
MapReduce JobHistory Server Web UI地址。
5)配置yarn-site.xml
yarn-site.xml文件是yarn资源管理框架的核心配置文件:
yarn.resourcemanager.hostname
cdh5master
自定ResourceManager的地址,还是单点,这是隐患。
yarn.resourcemanager.scheduler.address
cdh5master:8030
ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。
yarn.resourcemanager.resource-tracker.address
cdh5master:8031
ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。
yarn.resourcemanager.address
cdh5master:8032
ResourceManager对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等。
yarn.resourcemanager.admin.address
cdh5master:8033
ResourceManager对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等。
yarn.resourcemanager.webapp.address
nn.uniclick.cloud:8088
ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。
yarn.nodemanager.aux-services
mapreduce_shuffle
指定NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce。
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.local-dirs
file:///data1/hadoop/yarn/local,file:///data2/hadoop/yarn/local,file:///data3/hadoop/yarn/local,file:///data4/hadoop/yarn/local
Yarn应用的中间结果数据存储目录,建议配置多个磁盘,平衡IO。
yarn.nodemanager.log-dirs
file:///data1/hadoop/yarn/logs,file:///data2/hadoop/yarn/logs
Yarn应用日志的本地存储目录,建议配置多个磁盘,平衡IO.
yarn.nodemanager.resource.memory-mb
2048
NodeManager可以使用的最大物理内存。注意,该参数是不可修改的,一旦设置,整个运行过程中不可动态修改。另外,该参数的默认值是8192MB,即使你的机器内存不够8192MB,YARN也会按照这些内存来使用。
yarn.nodemanager.resource.cpu-vcores
2
NodeManager可以使用的虚拟CPU个数。
6)配置hosts文件
在/etc/hadoop/conf下创建hosts文件,内容如下:
cdh5master
cdh5node1
cdh5node2
cdh5slave
2、Hadoop集群启动
启动时,要非常小心,请严格按照我这里描述的步骤做,每一步要检查自己的操作是否正确。
1. 首先检查各个节点的配置文件是否正确
除了hdfs-site.xml文件,要保证其它配置文件在各个节点完全一样,这样便于日后维护。
2. 启动ZooKeeper集群
在cdh5node1、cdh5node2、cdh5slave上分别执行命令:
zkServer.sh start命令输出:
[hadoop@cdh5node1 zookeeper]$ zkServer.sh start
JMX enabled by default
Using config: /opt/zookeeper/current/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED3. 格式化ZooKeeper集群
格式化目的是在ZooKeeper集群上建立HA的相应节点。在cdh5master节点执行如下命令:
[root@cdh5master hadoop]# /opt/hadoop/current/bin/hdfs zkfc –formatZK4. 启动journalnode
在cdh5node1、cdh5node2、cdh5slave上分别执行命令:
./hadoop-daemon.sh start journalnode在每个节点执行完启动命令后,每个节点都执行以下验证。验证(以cdh5node1为例):
[hadoop@cdh5node1 sbin]$ jps
15279 Jps
15187 JournalNode
14899 QuorumPeerMain启动JournalNode后,会在本地磁盘产生一个目录/data1/hadoop/dfs/jn,此目录是在配置文件定义过的,用户保存NameNode的edits文件的数据。
5. 格式化集群NameNode
从cdh5master和cdh5slave中任选一个即可,这里选择的是cdh5master,在cdh5master执行以下命令:
./hdfs namenode -format -clusterId cdh5-1命令输出:
[root@cdh5master hadoop]# /opt/hadoop/current/bin/hdfs namenode -format -clusterId cdh5-1 //此名称可随便指定
18/07/28 18:30:20 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hadoop
STARTUP_MSG: host = cdh5master/172.16.213.235
STARTUP_MSG: args = [-format, -clusterId, cdh5-1]
STARTUP_MSG: version = 2.6.0-cdh5.15.1格式化NameNode会在磁盘产生一个目录,用于保存NameNode的fsimage、edits等文件。
6. 启动cdh5master上的NameNode
在cdh5master上执行命令:
/opt/hadoop/current/sbin/hadoop-daemon.sh start namenode命令输出:
[hadoop@cdh5master sbin]$/opt/hadoop/current/sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/hadoop/current/logs/hadoop-hadoop-namenode-cdh5master.out
[hadoop@cdh5master sbin]$ jps
11724 NameNode
11772 Jps启动后,产生一个新的java进程NameNode。
7. 把NameNode的数据从cdh5master同步到cdh5slave中
在cdh5slave上执行命令:
/opt/hadoop/current/bin/hdfs namenode –bootstrapStandby8. 启动cdh5slave上的NameNode
在cdh5slave上执行命令:
/opt/hadoop/current/sbin/hadoop-daemon.sh start namenode命令输出:
[hadoop@cdh5slave sbin]$/opt/hadoop/current/sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/hadoop/current/logs/hadoop-hadoop-namenode-cdh5slaver.out
[hadoop@cdh5slave sbin]$ jps
11724 NameNode
11772 Jps启动后,产生一个新的java进程NameNode。
9. 启动ZooKeeper FailoverController
在两个NameNode都启动后,默认将都处于standby状态,要将某个节点转变成active状态,就需要首先在此节点上启动zkfc服务。
首先在cdh5master执行命令:
/opt/hadoop/current/sbin/hadoop-daemon.sh start zkfc命令输出(以cdh5master为例):
[root@cdh5master hadoop]# /opt/hadoop/current/sbin/hadoop-daemon.sh start zkfc这样cdh5master节点的namenode状态将变成active,也就是变成了HA的主节点。接着在cdh5slave上也启动zkfc服务,启动后,cdh5slave上的namenode状态将保持为standby。
10. 启动datanode服务
在cdh5master、cdh5slave、cdh5node1、cdh5node2上依次启动datanode服务,操作如下:
命令输出(以cdh5master为例):
[root@cdh5master hadoop]# /opt/hadoop/current/sbin/hadoop-daemon.sh start datanode这样datanode服务就启动起来了。
11. 启动resourcemanager和nodemanager服务
在cdh5master上启动resourcemanager服务,操作如下:
[root@cdh5master hadoop]# /opt/hadoop/current/sbin/yarn-daemon.sh start resourcemanager接着依次在cdh5node1、cdh5node2、cdh5slave上依次启动nodemanager服务,操作如下:
命令输出(以cdh5node1为例):
[root@cdh5node1 hadoop]# /opt/hadoop/current/sbin/yarn-daemon.sh start nodemanager这样nodemanager和resourcemanager服务就启动起来了。
12. 启动historyserver服务
historyserver服务用于日志查看,通过如下命令在cdh5master节点启动historyserver服务,操作如下:
[root@cdh5master hadoop]#/opt/hadoop/current/sbin/mr-jobhistory-daemon.sh start historyserver至此,hadoop集群服务完全启动,分布式hadoop集群部署完成。
3、Hadoop HA 高可用企业级实战
1. HA概述
(1)所谓HA(High Availablity),即高可用(7*24小时不中断服务)。
(2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
(3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
(4)NameNode主要在以下两个方面影响HDFS集群
- NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
- NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
2. HDFS-HA工作机制
通过多个NameNode消除单点故障。
HDFS-HA工作要点:
1)元数据管理方式需要改变
内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以做写操作;
所有的NameNode都可以读取Edits;
共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
2)需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
3)必须保证两个NameNode之间能够ssh无密码登录
4)隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
3. HDFS-HA自动故障转移工作机制
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程,如图3-20所示。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
(1)故障检测
集群中的每个NameNode在ZooKeeper中维护了一个会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
(2)现役NameNode选择
ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
1)健康监测
ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2)ZooKeeper会话管理
当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
3)基于ZooKeeper的选择
如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。
HDFS-HA故障转移机制:
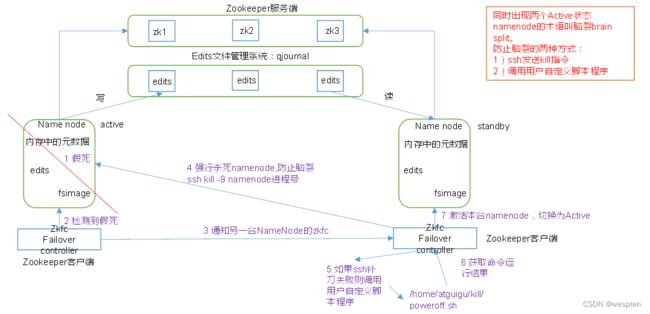
4. HDFS-HA集群配置
① 环境准备
(1)修改IP
(2)修改主机名及主机名和IP地址的映射
(3)关闭防火墙
(4)ssh免密登录
(5)安装JDK,配置环境变量等
② 规划集群
| hadoop102 |
hadoop103 |
hadoop104 |
| NameNode |
NameNode |
NameNode |
| ZKFC |
ZKFC |
ZKFC |
| JournalNode |
JournalNode |
JournalNode |
| DataNode |
DataNode |
DataNode |
| ZK |
ZK |
ZK |
| ResourceManager |
||
| NodeManager |
NodeManager |
NodeManager |
③ 配置Zookeeper集群
1)集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
2)解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
[yyds@hadoop102 software]$ tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/(2)在/opt/module/zookeeper-3.5.7/这个目录下创建zkData
[yyds@hadoop102 zookeeper-3.5.7]$ mkdir -p zkData(3)重命名/opt/module/zookeeper-3.4.14/conf这个目录下的zoo_sample.cfg为zoo.cfg
[yyds@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg3)配置zoo.cfg文件
(1)具体配置
dataDir=/opt/module/zookeeper-3.5.7/zkData增加如下配置:
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888(2)配置参数解读
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的IP地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
4)集群操作
(1)在/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件
[yyds@hadoop102 zkData]$ touch myid添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码。
(2)编辑myid文件
[yyds@hadoop102 zkData]$ vi myid在文件中添加与server对应的编号:如2。
(3)拷贝配置好的zookeeper到其他机器上
[yyds@hadoop102 module]$ scp -r zookeeper-3.5.7/ yyds@hadoop103:/opt/module/
[yyds@hadoop102 module]$ scp -r zookeeper-3.5.7/ yyds@hadoop104:/opt/module/并分别修改myid文件中内容为3、4。
(4)分别启动zookeeper
[yyds@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[yyds@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[yyds@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start(5)查看状态
[yyds@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
[yyds@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: leader
[yyds@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower④ 配置HDFS-HA集群
1)官方地址:Apache Hadoop
2)在opt目录下创建一个ha文件夹
[yyds@hadoop102 ~]$ cd /opt
[yyds@hadoop102 opt]$ sudo mkdir ha
[yyds@hadoop102 opt]$ sudo chown yyds:yyds /opt/ha3)将/opt/module/下的 hadoop-3.1.3拷贝到/opt/ha目录下(记得删除data 和 log目录)
[yyds@hadoop102 opt]$ cp -r /opt/module/hadoop-3.1.3 /opt/ha/4)配置hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_2125)配置core-site.xml
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/opt/ha/hadoop-3.1.3/data
6)配置hdfs-site.xml
dfs.namenode.name.dir
file://${hadoop.tmp.dir}/name
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/data
dfs.journalnode.edits.dir
${hadoop.tmp.dir}/jn
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2,nn3
dfs.namenode.rpc-address.mycluster.nn1
hadoop102:8020
dfs.namenode.rpc-address.mycluster.nn2
hadoop103:8020
dfs.namenode.rpc-address.mycluster.nn3
hadoop104:8020
dfs.namenode.http-address.mycluster.nn1
hadoop102:9870
dfs.namenode.http-address.mycluster.nn2
hadoop103:9870
dfs.namenode.http-address.mycluster.nn3
hadoop104:9870
dfs.namenode.shared.edits.dir
qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/yyds/.ssh/id_rsa
7)分发配置好的hadoop环境到其他节点
⑤ 启动HDFS-HA集群
1)将HADOOP_HOME环境变量更改到HA目录
[yyds@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh将HADOOP_HOME部分改为如下:
##HADOOP_HOME
export HADOOP_HOME=/opt/ha/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin2)在各个JournalNode节点上,输入以下命令启动journalnode服务
[yyds@hadoop102 ~]$ hdfs --daemon start journalnode
[yyds@hadoop103 ~]$ hdfs --daemon start journalnode
[yyds@hadoop104 ~]$ hdfs --daemon start journalnode3)在[nn1]上,对其进行格式化,并启动
[yyds@hadoop102 ~]$ hdfs namenode -format
[yyds@hadoop102 ~]$ hdfs --daemon start namenode4)在[nn2]和[nn3]上,同步nn1的元数据信息
[yyds@hadoop103 ~]$ hdfs namenode -bootstrapStandby
[yyds@hadoop104 ~]$ hdfs namenode -bootstrapStandby5)启动[nn2]和[nn3]
[yyds@hadoop103 ~]$ hdfs --daemon start namenode
[yyds@hadoop104 ~]$ hdfs --daemon start namenode6)查看web页面显示
hadoop102(standby):
hadoop103(standby):
hadoop104(standby):
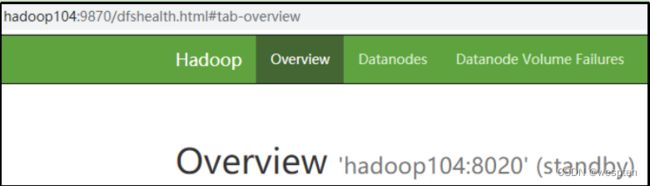
7)在所有节点上,启动datanode
[yyds@hadoop102 ~]$ hdfs --daemon start datanode
[yyds@hadoop103 ~]$ hdfs --daemon start datanode
[yyds@hadoop104 ~]$ hdfs --daemon start datanode8)将[nn1]切换为Active
[yyds@hadoop102 ~]$ hdfs haadmin -transitionToActive nn19)查看是否Active
[yyds@hadoop102 ~]$ hdfs haadmin -getServiceState nn1⑥ 配置HDFS-HA自动故障转移
1)具体配置
(1)在hdfs-site.xml中增加
dfs.ha.automatic-failover.enabled
true
(2)在core-site.xml文件中增加
ha.zookeeper.quorum
hadoop102:2181,hadoop103:2181,hadoop104:2181
(3)修改后分发配置文件
[yyds@hadoop102 etc]$ pwd
/opt/ha/hadoop-3.1.3/etc
[yyds@hadoop102 etc]$ xsync hadoop/2)启动
(1)关闭所有HDFS服务
[yyds@hadoop102 ~]$ stop-dfs.sh(2)启动Zookeeper集群
[yyds@hadoop102 ~]$ zkServer.sh start
[yyds@hadoop103 ~]$ zkServer.sh start
[yyds@hadoop104 ~]$ zkServer.sh start(3)启动Zookeeper以后,然后再初始化HA在Zookeeper中状态
[yyds@hadoop102 ~]$ hdfs zkfc -formatZK(4)启动HDFS服务
[yyds@hadoop102 ~]$ start-dfs.sh(5)可以去zkCli.sh客户端查看Namenode选举锁节点内容
[zk: localhost:2181(CONNECTED) 7] get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn2 hadoop103 �>(�>
cZxid = 0x10000000b
ctime = Tue Jul 14 17:00:13 CST 2020
mZxid = 0x10000000b
mtime = Tue Jul 14 17:00:13 CST 2020
pZxid = 0x10000000b
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x40000da2eb70000
dataLength = 33
numChildren = 03)验证
(1)将Active NameNode进程kill,查看网页端三台Namenode的状态变化
[yyds@hadoop102 ~]$ kill -9 namenode的进程id5. YARN-HA配置
① YARN-HA工作机制
1)官方文档:Apache Hadoop 3.1.3 – ResourceManager High Availability
2)YARN-HA工作机制
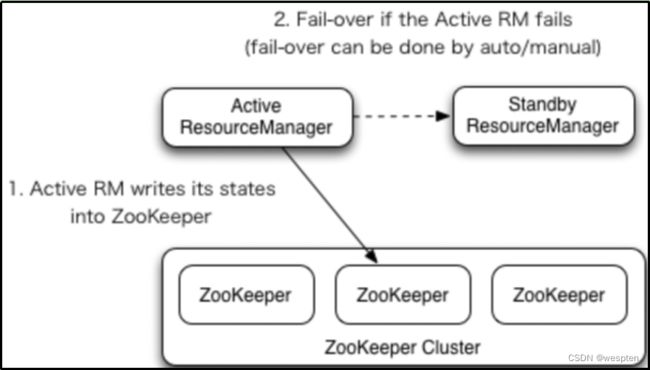
② 配置YARN-HA集群
1)环境准备
(1)修改IP
(2)修改主机名及主机名和IP地址的映射
(3)关闭防火墙
(4)ssh免密登录
(5)安装JDK,配置环境变量等
(6)配置Zookeeper集群
2)规划集群
| hadoop102 |
hadoop103 |
hadoop104 |
| NameNode |
NameNode |
NameNode |
| JournalNode |
JournalNode |
JournalNode |
| DataNode |
DataNode |
DataNode |
| ZK |
ZK |
ZK |
| ResourceManager |
ResourceManager |
|
| NodeManager |
NodeManager |
NodeManager |
3)具体配置
(1)yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster-yarn1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop102
yarn.resourcemanager.webapp.address.rm1
hadoop102:8088
yarn.resourcemanager.address.rm1
hadoop102:8032
yarn.resourcemanager.scheduler.address.rm1
hadoop102:8030
yarn.resourcemanager.resource-tracker.address.rm1
hadoop102:8031
yarn.resourcemanager.hostname.rm2
hadoop103
yarn.resourcemanager.webapp.address.rm2
hadoop103:8088
yarn.resourcemanager.address.rm2
hadoop103:8032
yarn.resourcemanager.scheduler.address.rm2
hadoop103:8030
yarn.resourcemanager.resource-tracker.address.rm2
hadoop103:8031
yarn.resourcemanager.zk-address
hadoop102:2181,hadoop103:2181,hadoop104:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
(2)同步更新其他节点的配置信息,分发配置文件
[yyds@hadoop102 etc]$ xsync hadoop/4)启动hdfs
[yyds@hadoop102 ~]$ start-dfs.sh5)启动YARN
(1)在hadoop102或者hadoop103中执行
[yyds@hadoop102 ~]$ start-yarn.sh(2)查看服务状态
[yyds@hadoop102 ~]$ yarn rmadmin -getServiceState rm1(3)可以去zkCli.sh客户端查看ResourceManager选举锁节点内容
[yyds@hadoop102 ~]$ zkCli.sh
[zk: localhost:2181(CONNECTED) 16] get -s /yarn-leader-election/cluster-yarn1/ActiveStandbyElectorLock
cluster-yarn1rm1
cZxid = 0x100000022
ctime = Tue Jul 14 17:06:44 CST 2020
mZxid = 0x100000022
mtime = Tue Jul 14 17:06:44 CST 2020
pZxid = 0x100000022
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x30000da33080005
dataLength = 20
numChildren = 0(4)web端查看hadoop102:8088和hadoop103:8088的YARN的状态,和NameNode对比,查看区别
6. HDFS Federation架构设计
① NameNode架构的局限性
1)Namespace(命名空间)的限制
由于NameNode在内存中存储所有的元数据(metadata),因此单个NameNode所能存储的对象(文件+块)数目受到NameNode所在JVM的heap size的限制。50G的heap能够存储20亿(200million)个对象,这20亿个对象支持4000个DataNode,12PB的存储(假设文件平均大小为40MB)。随着数据的飞速增长,存储的需求也随之增长。单个DataNode从4T增长到36T,集群的尺寸增长到8000个DataNode。存储的需求从12PB增长到大于100PB。
2)隔离问题
由于HDFS仅有一个NameNode,无法隔离各个程序,因此HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序。
3)性能的瓶颈
由于是单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量。
② HDFS Federation架构设计
能不能有多个NameNode:
| NameNode |
NameNode |
NameNode |
| 元数据 |
元数据 |
元数据 |
| Log |
machine |
电商数据/话单数据 |
HDFS Federation架构设计:
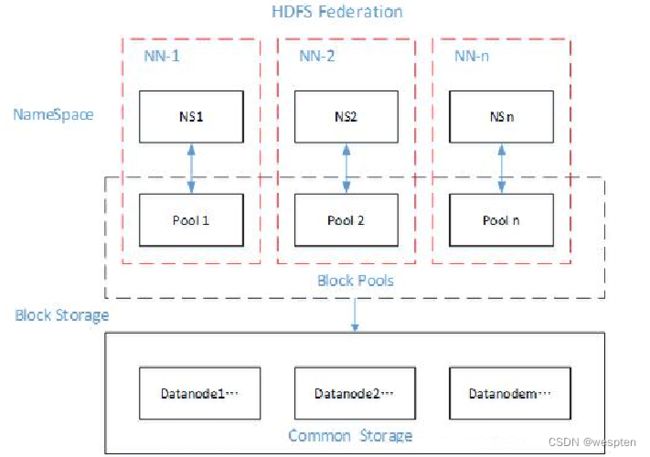
③ HDFS Federation应用思考
不同应用可以使用不同NameNode进行数据管理图片业务、爬虫业务、日志审计业务。Hadoop生态系统中,不同的框架使用不同的NameNode进行管理NameSpace。(隔离性)
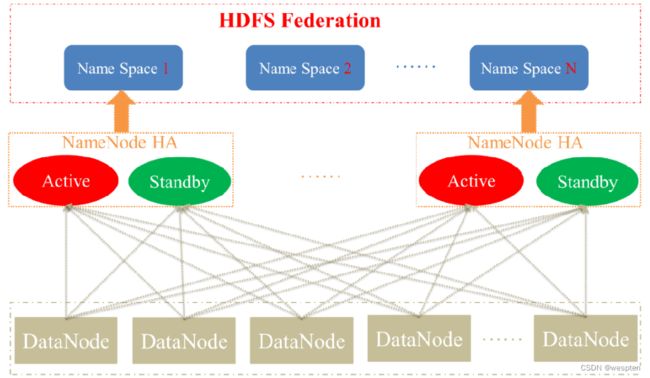
七、Hadoop企业优化
1、Hadoop数据压缩
压缩技术能够有效减少底层存储系统(HDFS)读写字节数。压缩提高了网络带宽和磁盘空间的效率。在运行MR程序时,I/O操作、网络数据传输、Shuffle 和Merge要花大量的时间,尤其是数据规模很大和工作负载密集的情况下,因此,使用数据压缩显得非常重要。
鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘IO和网络传输非常有帮助。可以在任意Map Reduce阶段启用压缩。不过,尽管压缩与解压操作的CPU开销不高,其性能的提升和资源的节省并非没有代价。
1)压缩策略和原则
压缩是提高Hadoop运行效率的一种优化策略。
通过对Mapper、Reducer运行过程的数据进行压缩,以减少磁盘IO,提高MR程序运行速度。
注意∶采用压缩技术减少了磁盘IO,但同时增加了CPU运算负担。所以,压缩特性运用得当能是高性能,但运用不当也可能降低性能。
压缩基本原则:
(1)运算密集型的job,少用压缩。
(2)IO密集型的job,多用压缩。
2)MR支持的压缩编码
| 压缩格式 |
hadoop自带? |
算法 |
文件扩展名 |
是否可切分 |
换成压缩格式后,原来的程序是否需要修改 |
| DEFLATE |
是,直接使用 |
DEFLATE |
.deflate |
否 |
和文本处理一样,不需要修改 |
| Gzip |
是,直接使用 |
DEFLATE |
.gz |
否 |
和文本处理一样,不需要修改 |
| bzip2 |
是,直接使用 |
bzip2 |
.bz2 |
是 |
和文本处理一样,不需要修改 |
| LZO |
否,需要安装 |
LZO |
.lzo |
是 |
需要建索引,还需要指定输入格式 |
| Snappy |
是,直接使用 |
Snappy |
.snappy |
否 |
和文本处理一样,不需要修改 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 |
对应的编码/解码器 |
| DEFLATE |
org.apache.hadoop.io.compress.DefaultCodec |
| gzip |
org.apache.hadoop.io.compress.GzipCodec |
| bzip2 |
org.apache.hadoop.io.compress.BZip2Codec |
| LZO |
com.hadoop.compression.lzo.LzopCodec |
| Snappy |
org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
| 压缩算法 |
原始文件大小 |
压缩文件大小 |
压缩速度 |
解压速度 |
| gzip |
8.3GB |
1.8GB |
17.5MB/s |
58MB/s |
| bzip2 |
8.3GB |
1.1GB |
2.4MB/s |
9.5MB/s |
| LZO |
8.3GB |
2.9GB |
49.3MB/s |
74.6MB/s |
snappy | A fast compressor/decompressor
Snappy is a compression/decompression library. It does not aim for maximum compression, or compatibility with any other compression library; instead, it aims for very high speeds and reasonable compression. For instance, compared to the fastest mode of zlib, Snappy is an order of magnitude faster for most inputs, but the resulting compressed files are anywhere from 20% to 100% bigger.On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
3)压缩方式选择
(1)Gzip压缩
优点∶压缩率比较高,而且压缩/解压速度也比较快;Hadoop本身支持,在应用中处理Gaip格式的文件就和直接处理文本一样;大部分Linux系统都自带Gzip命令,使用方便。
缺点∶不支持Split。
应用场景∶当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑用Gzip压缩格式。例如说一天或者一个小时的日志压缩成一个Gzip文件。
(2)Bzip2压缩
优点∶支持Split;具有很高的压缩率,比Gzip压缩率都;Hadoop本身自带,使用方便。
缺点∶压缩/解压速度慢。
应用场景∶适合对速度要求不高,但需要较高的压缩率的时候;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持Split,而且兼容之前的应用程序的情况。
(3)Lzo压缩
优点∶压缩/解压速度也比较快,合理的压缩率;支持Split,是Hadoop中最流行的压缩格式;可以在Linux系统下安装Zop命令,使用方便。
缺点∶压缩率比Gzip要低一些;Hadoop本身不支持,需要安装;在应用中对Lzo格式的文件需要做一些特殊处理(为了支持Split需要建索引,还需要指定InputFormat为Lzo格式)。
应用场景∶一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,Lzo优点越越明显。
(4)Snappy压缩
优点∶高速压缩速度和合理的压缩率。
缺点∶不支持Split;压缩率比Gzip要低;Hadoop本身不支持,需要安装。
应用场景∶当MapReduce作业的Mq输出的数据比较大的时候,作为Map到Reduce的中间数据的压缩格式;或者作为一个MapReduce作业的输出和另外一个MapReduce作业的输入。
4)压缩位置选择
压缩可以在MapReduce作用的任意阶段启用。
MapReduce数据压缩:

5)压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数:
6)压缩实操案例
(1)数据流的压缩和解压缩(扩展)
CompressionCodec有两个方法可以用于轻松地压缩或解压缩数据。
要想对正在被写入一个输出流的数据进行压缩,我们可以使用createOutputStream(OutputStreamout)方法创建一个CompressionOutputStream,将其以压缩格式写入底层的流。
相反,要想对从输入流读取而来的数据进行解压缩,则调用createlnputStream(InputStreamin)函数,从而获得一个CompressionInputStream,从而从底层的流读取未压缩的数据。
测试一下如下压缩方式:
| DEFLATE |
org.apache.hadoop.io.compress.DefaultCodec |
| gzip |
org.apache.hadoop.io.compress.GzipCodec |
| bzip2 |
org.apache.hadoop.io.compress.BZip2Codec |
package com.yyds.mapreduce.compress;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestCompress {
public static void main(String[] args) throws IOException {
compress("D:\\input\\inputcompression\\JaneEyre.txt"
,"org.apache.hadoop.io.compress.BZip2Codec");
//decompress("D:\\input\\inputcompression\\JaneEyre.txt.bz2");
}
//压缩
private static void compress(String filename, String method) throws IOException {
//1 获取输入流
FileInputStream fis = new FileInputStream(new File(filename));
//2 获取输出流
//获取压缩编解码器codec
CompressionCodecFactory factory = new CompressionCodecFactory(new Configuration());
CompressionCodec codec = factory.getCodecByName(method);
//获取普通输出流,文件后面需要加上压缩后缀
FileOutputStream fos = new FileOutputStream(new File(filename + codec.getDefaultExtension()));
//获取压缩输出流,用压缩解码器对fos进行压缩
CompressionOutputStream cos = codec.createOutputStream(fos);
//3 流的对拷
IOUtils.copyBytes(fis,cos,new Configuration());
//4 关闭资源
IOUtils.closeStream(cos);
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
}
//解压缩
private static void decompress(String filename) throws IOException {
//0 校验是否能解压缩
CompressionCodecFactory factory = new CompressionCodecFactory(new Configuration());
CompressionCodec codec = factory.getCodec(new Path(filename));
if (codec == null) {
System.out.println("cannot find codec for file " + filename);
return;
}
//1 获取输入流
FileInputStream fis = new FileInputStream(new File(filename));
CompressionInputStream cis = codec.createInputStream(fis);
//2 获取输出流
FileOutputStream fos = new FileOutputStream(new File(filename + ".decodec"));
//3 流的对拷
IOUtils.copyBytes(cis,fos,new Configuration());
//4 关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(cis);
IOUtils.closeStream(fis);
}
}(2)Map输出端采用压缩
即使你的MapReduce的输入输出文件都是未压缩的文件,你仍然可以对Map任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,对其压缩可以提高很多性能,这些工作只要设置两个属性即可,我们来看下代码怎么设置。
1)给大家提供的Hadoop源码支持的压缩格式有:BZip2Codec 、DefaultCodec
package com.yyds.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 开启map端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class,CompressionCodec.class);
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}2)Mapper保持不变
package com.yyds.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 循环写出
for(String word:words){
k.set(word);
context.write(k, v);
}
}
} 3)Reducer保持不变
package com.yyds.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
// 1 汇总
for(IntWritable value:values){
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
} (3)Reduce输出端采用压缩
基于WordCount案例处理。
1)修改驱动
package com.yyds.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.Lz4Codec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}2)Mapper和Reducer保持不变。
2、MapReduce优化
MapReduce出现跑的慢。
程序效率的瓶颈在于两点∶
1. 计算机性能
CPU、内存、磁盘健康、网络。
2. I/O操作优化
(1)数据倾斜
(2)Map和Reduce数设置不合理
(3)Map运行时间太长,导致Reduce等待过久
(4)小文件过多
(5)大量的不可切片的超大压缩文件
(6)Spill次数过多
(7)Merge次数过多等
MapReduce优化方法:
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
1)数据输入
(1)合并小文件∶在执行MR任务前将小文件进行合并,大量的小文件会产生大量的Map任务,增大Map任务装载次数,而任务的装载比较耗时,从而导致MR运行较慢。
(2)采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景。
2)Map阶段
(1)减少溢写(Spill)次数∶通过调整mapreduce.task.io.sort.mb及mapreduce.map.sort.spill.percent参数值,增大触发Spill的内存上限,减少Spill次数,从而减少磁盘IO。
(2)减少合并(Merge)次数∶通过调整mapreduce.task.io.sort.factor参数,增大Merge的文件数目,减少Merge的次数,从而缩短MR处理时间。
(3)在Map之后,不影响业务逻辑前提下,先进行Combine处理,减少I/O。
3)Reduce阶段
(1)合理设置Map和Reduce数∶两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致Map、Reduce任务间竞争资源,造成处理超时等错误。
(2)设置Map、Reduce共存∶调整mapreduce.jobreduce.slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
(3)规避使用Reduce∶因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
(4)合理设置Reduce端的Buffer∶默认情况下,数据达到一个阈值的时候,Buffer中的数据就会写入磁盘,然后Reduce会从磁盘中获得所有的数据。
也就是说,Buffer和Reduce是没有直接关联的,中间多次写磁盘->读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得Buffer中的一部分数据可以直接输送到Reduce,从而减少IO开销∶mapreduce.reduce.reduce.input.buffer.percent,默认为0.0。当值大于0的时候,会保留指定比例的内存读Buffer中的数据直接拿给Reduce使用。这样一来,设置Buffer需要内存,读取数据需要内存,Reduce计算也要内存,所以要根据作业的运行情况进行调整。
4)I/O传输
1)采用数据压缩的方式,减少网络IO的的时间。安装Snappy和LZO压缩编码器。
2)使用SequenceFile二进制文件。
5)数据倾斜问题
1. 数据倾斜现象
数据频率倾斜———某一个区域的数据量要远远大于其他区域。
数据大小倾斜———部分记录的大小远远大于平均值。
2. 减少数据倾斜的方法
方法1∶抽样和范围分区
可以通过对原始数据进行抽样得到的结果集来预设分区边界值。
方法2∶自定义分区
基于输出键的背景知识进行自定义分区。例如,如果Map输出键的单词来源于一本书,且其中某几个专业词汇较多。那么就可以自定义分区将这这些专业词汇发送给固定的一部分Reduce实例,而将其他的都发送给剩余的Reduce实例。
方法3∶Combiner
使用Combiner可以大量地减小数据倾斜。在可能的情况下,Combine的目的就是聚合并精简数据。
方法4∶采用Map Join,尽量避免Reduce Join。
MapReduce常用的调优参数:
1)资源相关参数
(1)以下参数是在用户自己的MR应用程序中配置就可以生效(mapred-default.xml)
| 配置参数 |
参数说明 |
| mapreduce.map.memory.mb |
一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.reduce.memory.mb |
一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.map.cpu.vcores |
每个MapTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.cpu.vcores |
每个ReduceTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.shuffle.parallelcopies |
每个Reduce去Map中取数据的并行数。默认值是5 |
| mapreduce.reduce.shuffle.merge.percent |
Buffer中的数据达到多少比例开始写入磁盘。默认值0.66 |
| mapreduce.reduce.shuffle.input.buffer.percent |
Buffer大小占Reduce可用内存的比例。默认值0.7 |
| mapreduce.reduce.input.buffer.percent |
指定多少比例的内存用来存放Buffer中的数据,默认值是0.0 |
(2)应该在YARN启动之前就配置在服务器的配置文件中才能生效(yarn-default.xml)
| 配置参数 |
参数说明 |
| yarn.scheduler.minimum-allocation-mb |
给应用程序Container分配的最小内存,默认值:1024 |
| yarn.scheduler.maximum-allocation-mb |
给应用程序Container分配的最大内存,默认值:8192 |
| yarn.scheduler.minimum-allocation-vcores |
每个Container申请的最小CPU核数,默认值:1 |
| yarn.scheduler.maximum-allocation-vcores |
每个Container申请的最大CPU核数,默认值:32 |
| yarn.nodemanager.resource.memory-mb |
给Containers分配的最大物理内存,默认值:8192 |
(3)Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)
| 配置参数 |
参数说明 |
| mapreduce.task.io.sort.mb |
Shuffle的环形缓冲区大小,默认100m |
| mapreduce.map.sort.spill.percent |
环形缓冲区溢出的阈值,默认80% |
2)容错相关参数(MapReduce性能优化)
| 配置参数 |
参数说明 |
| mapreduce.map.maxattempts |
每个Map Task最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.reduce.maxattempts |
每个Reduce Task最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.task.timeout |
Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000(10分钟)。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是:“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。 |
3、Hadoop小文件优化方法
1. Hadoop小文件弊端
HDFS上每个文件都要在NameNode上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行MR计算时,会生成过多切片,需要启动过多的MapTask。每个MapTask处理的数据量小,导致MapTask的处理时间比启动时间还小,白白消耗资源。
2. Hadoop小文件解决方案
1)小文件优化的方向
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
(2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
(3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。
(4)开启uber模式,实现jvm重用
2)Hadoop Archive
是一个高效的将小文件放入HDFS块中的文件存档工具,能够将多个小文件打包成一个HAR文件,从而达到减少NameNode的内存使用
3)SequenceFile
SequenceFile是由一系列的二进制k/v组成,如果为key为文件名,value为文件内容,可将大批小文件合并成一个大文件
4)CombineTextInputFormat
CombineTextInputFormat用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片。
5)开启uber模式,实现jvm重用。默认情况下,每个Task任务都需要启动一个jvm来运行,如果Task任务计算的数据量很小,我们可以让同一个Job的多个Task运行在一个Jvm中,不必为每个Task都开启一个Jvm.
开启uber模式,在mapred-site.xml中添加如下配置:
mapreduce.job.ubertask.enable
true
mapreduce.job.ubertask.maxmaps
9
mapreduce.job.ubertask.maxreduces
1
mapreduce.job.ubertask.maxbytes
八、Hadoop新特性
1、Hadoop2.x新特性
1. 集群间数据拷贝
1)scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/yyds/hello.txt // 推 push
scp -r root@hadoop103:/user/yyds/hello.txt hello.txt // 拉 pull
scp -r root@hadoop103:/user/yyds/hello.txt root@hadoop104:/user/yyds //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
2)采用distcp命令实现两个Hadoop集群之间的递归数据复制
[yyds@hadoop102 hadoop-3.1.3]$ bin/hadoop distcp hdfs://hadoop102:9820/user/yyds/hello.txt hdfs://hadoop105:9820/user/yyds/hello.txt2. 小文件存档
1、HDFS存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
2、解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。

1)案例实操
(1)需要启动YARN进程
[yyds@hadoop102 hadoop-3.1.3]$ start-yarn.sh(2)归档文件
把/user/yyds/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/user/yyds/output路径下。
[yyds@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName input.har -p /user/yyds/input /user/yyds/output(3)查看归档
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /user/yyds/output/input.har
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///user/yyds/output/input.har(4)解归档文件
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:/// user/yyds/output/input.har/* /user/yyds3. 回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
1)回收站参数设置及工作机制
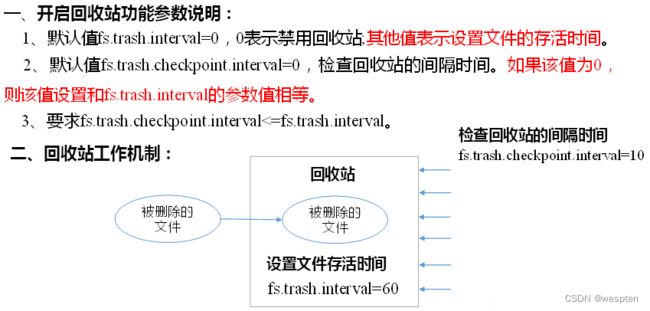
2)启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
fs.trash.interval
1
fs.trash.checkpoint.interval
1
3)查看回收站
回收站目录在hdfs集群中的路径:/user/yyds/.Trash/….
4)通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);5)通过网页上直接删除的文件也不会走回收站。
6)只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站。
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /user/yyds/input
2020-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:9820/user/yyds/input' to trash at: hdfs://hadoop102:9820/user/yyds/.Trash/Current/user/yyds/input7)恢复回收站数据
[yyds@hadoop102 hadoop-3.1.3]$ hadoop fs -mv
/user/yyds/.Trash/Current/user/yyds/input /user/yyds/input2、Hadoop3.x新特性
1. 多NN的HA架构
HDFS NameNode高可用性的初始实现为单个活动NameNode和单个备用NameNode,将edits复制到三个JournalNode。该体系结构能够容忍系统中一个NN或一个JN的故障。
但是,某些部署需要更高程度的容错能力。Hadoop3.x允许用户运行多个备用NameNode。例如,通过配置三个NameNode和五个JournalNode,群集能够容忍两个节点而不是一个节点的故障。
2. 纠删码
HDFS中的默认3副本方案在存储空间和其他资源(例如,网络带宽)中具有200%的开销。但是,对于I / O活动相对较低暖和冷数据集,在正常操作期间很少访问其他块副本,但仍会消耗与第一个副本相同的资源量。
纠删码(Erasure Coding)能够在不到50% 的数据冗余情况下提供和3副本相同的容错能力,因此,使用纠删码作为副本机制的改进是自然而然的。
查看集群支持的纠删码策略:hdfs ec -listPolicies
九、Hadoop知识总结
第一部分:HDFS相关问题
1、描述一下HDFS的数据写入流程
首先由客户端想NameNode服务发起写数据请求,NameNode接收到请求后会进行基本验证,验证内容包括对请求上传的路径进行合法验证其次还要对请求的用户进行权限验证。验证没有问题后,NameNode会响应客户端允许上传。接下来客户端会对文件按照blocksize大小进行切块,切完块后依次以块为单位进行上传。此时客户端会请求上传第一个块信息,服务端接收到上传请求后会依据HDFS默认的机架感知原理默认情况下返回三台存放数据块副本的DataNode机器。客户端接收到机器列表后会依据网络拓扑的原理找到其中一台机器进行传输通道的建立,然后依次和三台机器进行串行连接,这样的连接方式主要的为了减轻客户端本地的IO的压力。当通道建立成功后,客户端会通过HDFS的FSOutputStream流对象进行数据传输,数据传输的最小单位为packet。传输过程中每太DataNode服务器是串行连接,依次将数据传递。最后一个数据块被传输完成后相当于一次写入结束,如果还有数据块需要传输,那就接着传输第二个数据块。
2、描述一下HDFS的数据读取流程
首先和写数据一样,由客户端向NameNode发出请求,NameNode接收到请求后会进行文件下载路径的合法性校验以及权限验证。如果验证没有问题,就会给客户端返回目标文件的元数据信息,信息中包含目标文件数据块对应的DataNode的位置信息。然后客户端根据具体的DataNode位置信息结合就近原则网络拓扑原理找到离自己最近的一台服务器对数据进行访问下载,最后通过HDFS提供的FSInputStream对象将数据读取到本地。如果有多个块信息 就会请求多次DataNode直到目标文件的全部数据被下载。
3、简述HDFS的架构,其中每个服务的作用
HDFS是Hadoop架构中的负责完成数据的分布式存储管理的文件系统。非高可用HDFS集群工作的时候会启动三个服务,分别是NameNode 和 DataNode以及SecondaryNameNode 。其中NameNode是HDFS的中心服务,主要维护管理文件系统中的文件的元数据信息,DataNode主要负责存储文件的真实数据块信息,当然在DataNode的数据块信息中也包含一下关于当前数据块的元数据信息 例如 检验值 数据长度 时间戳等。在非高可用HDFS集群中 NameNode和DataNode可以理解为是一对多的关系。二者在集群工作中也要保持通信,通常默认3秒钟会检测一下心跳。最后SecondaryNameNode的工作很单一,就是为了给NameNode的元数据印象文件和编辑日志进行合并,并自己也保留一份元数据信息 以防NameNode元数据丢失后有恢复的保障。
4、HDFS中如何实现元数据的维护
NameNode的元数据信息是通过fsimage文件 + edits编辑日志来维护的,当NameNode启动的时候fsimage文件和edits编辑日志的内容会被加载到内存中进行合并形成最新的元数据信息,当我们对元数据进行操作的时候,考虑到直接修改文件的低效性,从而不会直接修改fsimage文件,而是会往edits编辑日志文件中追加操作记录。当满足一定条件的时候 我们会让SecondaryNameNode来完成fsimage文件和edits 编辑日志文件的合并,SecondaryNameNode首先会让NameNode停止对正在使用的edits编辑日志文件的使用,并重新生成一个新的edits编辑日志文件。接着把NameNode 的fsimage文件和已停止的edits文件拷贝到本地在内存中将edits编辑日志文件的操作记录合并到fsimage 文件中形成一个最新的fsimage文件,最后会将这个最新的fsimage文件推送给NameNode并自己也备份一份。
5、描述一下NN和DN的关系,以及DN的工作流程
NameNode和DataNode从数据结构上看,就是一对多的关系,一个HDFS集群中是能只能有一个NameNode用于维护元数据信息,同时会有多个DataNode用于存储真实的数据块。当HDFS集群启动的时候,首先会进入到安全模式下,在安全模式下我们只能对数据进行读取不能进行任何写操作,此时集群的每一台DataNode服务器会向NameNode注册自己,注册成功后DataNode会上报自己的数据块详细信息,当数据块汇报满足 最小副本条件后,安全模式就自动退出。此后 DataNode和NameNode每三秒会通信一次,如果NameNode检测到DataNode没有响应,会继续检测 一直到10分30秒后还没有检测到 就确定当前DataNode不可用。
第二部分:MapReduce相关问题
1、描述一下手写MR的大概流程和规范
首先,从MapReduce程序的结构划分可以分为三部分,第一是 程序的执行入口通常简称为驱动类,驱动类主要编写MR作业的提交流程以及自定义的一些配置项。第二是 Map阶段的核心类需要自定并且继承Hadoop提供的Mapper类,重写Mapper类中的map方法,在map方法中遍写自己的业务逻辑代码将数据处理后利用context 上下文对象的写出落盘。第三是 Reduce阶段的核心类同时也需要继承Hadoop提供的Reducer类,并重写reduce 方法,在reduce方法中编写自己的业务逻辑代码,处理完数据后也是通过context上下文对象将数据写出,这也就是最终的结果文件。
2、如何实现Hadoop中的序列化,以及Hadoop的序列化和Java的序列化有什么区别
首先序列化是把内存中的Java对象转化成二进制字节码,反序列化是将二进制字节码转化成Java对象,通常我们在对Java对象进行磁盘持久化写入或者将Java对象作为数据进行网络传输的时候需要进行序列化,相反如果要将J数据从磁盘读出并转化成Java对象需要进行反序列化。实现Hadoop中的序列化需要让JavaBean对象实现Writable接口,并重写write() 方法和readFields()方法,其中write()方法是序列化方法,readFields()方法是反序列化方法。
Hadoop序列化和Java序列化的区别在于,Java序列化更重量级,Java序列化的后的结果不仅仅生成二进制字节码文件,同时还会针对当前Java对象生成对应的检验信息以及集成体系结构,这样的话 无形中我们需要维护更多的数据,但是Hadoop序列化不会产生除了Java对象内部属性外的任何信息,整体内容更加简洁紧凑,读写速度相应也会提升很多,这也符合了大数据的处理背景。
3、概述一下MR程序的执行流程
简单的描述,MR程序执行先从InputFormat类说起,由InputFormat负责数据读入,并在内部实现切片,每一个切片的数据对应生成一个MapTask任务,MapTask中按照文件的行逐行数据进行处理,每一行数据会调用一次我们自定义的Mapper类的map方法,map方法内部实现具体的业务逻辑,处理完数据会通过context对象将数据写出到磁盘(此处会经历Shuffle过程,详情请参考下面第七问!!!),接下来ReduceTask会开始执行,首先ReduceTask会将MapTask处理完的数据结果拷贝过来,每一组相同key的values会会调用一次我们自定的Reducer类的reduce方法,当数据处理完成后,会通过context对象将数据结果写出到磁盘上。
4、InputFormat负责数据写的时候要进行切片,为什么切片大小默认是128M
首先切片大小是可以通过修改配置参数来改变的,但是默认情况下是和切块blocksize大小一致,这样做的目的就是为了在读取数据的时候正好能一次性读取一个块的数据,避免了在集群环境下发生跨机器读取的情况,如果跨机器读取会造成二外的网络IO,不利于MR程序执行效率的提升。
5、描述一下切片的逻辑(从源码角度描述)
MR中的切片是发生在数据读入的阶段中,所以我们要关注InputFormat的实现,通过追溯源码,在InputFormat这个抽象类中有一个getSplits(),这个方法就是我们实现切片的具体逻辑。首先我们先关注两个变量,分别是 minSize 和 maxSize,通过对源码的跟踪默认情况 minSize = 1,maxSize = Long.MAX_VALUE,源码中声明了一个集合List splits = new ArrayList();,用于装载将来的切片对象并返回。接下来我们根据提交的job信息获取到当前要进行切片的文件详情,首先判断点前文件是否可以进行切分,这一步主要考虑到一些不支持切分的压缩文件时不能进行切片操作,否则就破坏了数据的完整性,如果当前文件可以切片的话,那么接下来就要计算切片的大小,计算切片大小一共需要三个因子,分别是minSize 、maxSize 、blocksize ,最后通过Math.max(minSize, Math.min(maxSize, blockSize)); 计算逻辑获取到切片大小,默认情况切片大小和数据库块大小一致,如果我们想改变切片大小可以通过修改一下两个配置参数实现 mapreduce.input.fileinputformat.split.minsize mapreduce.input.fileinputformat.split.maxsize,
如果把切片大小调大改mapreduce.input.fileinputformat.split.minsize 如果把切片大小调小改mapreduce.input.fileinputformat.split.maxsize。
当我们可以获取到切片大小后就可以继续往下执行,在最终完成切片之前还有一个关键判断,就是判断剩余文件是否要继续进行切片,如果剩余文件/切片大小>1.1 那就继续切片,否则就不会再进行切片,这个规则考虑的情况就就是让将来的切片尽可能资源使用均衡,不至于很小的文件内容也开启一个MapTask。到此整个切片规则就表述完毕了!
6、CombineTextInputFormat机制是怎么实现的
CombineTextInputFormat也是InputFormat的一个实现类,主要用于解决小文件场景的。如果我们在处理大量小文件的时候由于默认的切片规则是针对文件进行切片,所以就导致大量MapTask的产生 但是每一个MapTask处理的文件又很小 这样就违背了MapReduce的设计初衷。如果遇到以上场景我们就不能使用默认的切片规则了,而是使用CombineTextInputFormat中的切片规则。
CombineTextInputFormat中的切片规则大概思路是 先在Job提交的时候设定一个参数为切片最大的值,当这个值设置好以后并且在Job提交中指定使用InputFormat的实现类为CombineTextInputFormat,那么接下来在切片的过程中首先会把当前文件的大小和设置的切片的最大值进行比较,如果小于切片的最大值那就单独划分为一块,如果大于切片的最大值并且小于两倍的切片的最大值那就把当前文件一分为二划分成两个块,以此类推逐个对文件进行处理,这个过程称之为虚拟过程。最后生成真正的切片的时候 根据虚拟好的文件进行合并,只要合并后文件大小不超过最开始设置好的切片的最大值那就继续追加合并文件直到达到设置好的切片的最大值,此时就会产生一个切片对应生成一个MapTask。
7、阐述一下 Shuffle机制流程
shuffle是MR执行过程中很重要,也是必不可少的一个过程。当MapTask执行完map() 方法后通过context对象写数据的时候开始执行shuffle过程。首先数据先从Map端写入到环形缓冲区内,写出的数据会根据分区规则进入到指定的分区,并且同时在内存中进行区内排序。环形缓冲区默认大小为100M,当数据的写入的容量达到缓冲区大小的80%,数据开始向磁盘溢写,如果数据很多的情况下 可能发生N次溢写,这样在磁盘上就会产生多个溢写文件,并且保证每个溢写文件中区内数据是有序的,接下来在磁盘中会把多次溢写的文件归并到一起形成一个文件,这归并的过程中会根据相同的分区进行归并排序,保证归并完的文件区内是有序的,到此shuffle过程在Map端就完成了。 接着Map端输出的数据会作为Reduce端的输入数据再次进行汇总操作,此时ReduceTask任务会把每一个MapTask中计算完的相同的分区的数据拷贝到ReduceTask的内存中,如果内存放不下,开始写入磁盘,再接着就是对数据进行归并排序,排完序还要根据相同key进行分组,将来一组相同的key对应的values调用一次reduce方法。如果有多个分区就会产生多个ReduceTask来处理,处理的逻辑都一样。
8、在MR程序中由谁来决定分区的数量,哪个阶段环节会开始往分区中写数据
MR程序中,从编码设置的角度分析,在Job提交的时候可以设置ReduceTask的数量,ReduceTask的数量就决定的分区的编号,默认有多少ReduceTask任务就会产生多少个分区,但是具体应该设置多少ReduceTask是由具体的业务决定。在Map阶段的map方法中通过context.write()往出写数据的时候其实就往指定的分区中写数据了。
9、阐述MR中实现分区的思路(从源码角度分析)
分区是MR中一个重要的概念,通常情况下 分区是由具体业务逻辑决定的,默认情况下不指定分区数量就会有一个分区,如果要指定分区我们可以通过在Job提交的时候指定ReduceTask的数量来指定的分区的数量。我们从Map端处理完数据后,数据就会被溢写到指定的分区中,而决定一个kv数据究竟写到哪个分区中是由Hadoop提供的分区器对象控制的,这个对象叫做Partitioner。
Partitioner对象默认的实现HashPartitioner类,通过追溯源码 当我们调用map方法往出写数据的时候,会调用到HashPartitioner,它的规则就是用当前写出数据的key 和在Job提交中设置的ReducesTask的数量做取余运算,得到的结果就是当前数据要写入的分区的分区编号。 除此之外,我们也可以自定义分区器对象,需要继承Hadoop提供的Partitioner对象,然后重写getPartition() 方法,在该方法中根据自己的业务实现分区编号的返回。最后再将我们自定义的分区器对象设置到Job提交的代码中覆盖默认的分区规则。
10、Hadoop中实现排序的两种方案分别是什么
第一种实现方式是 直接让参与比较的对象实现 WritableComparable 接口,并指定泛型,接下来 实现compareTo() 方法 在该方法中实现比较规则即可。
第二种实现方式是 自定义一个比较器对象,需要继承WritableComparator类 ,重写它的compare方法,注意在构造器中调用父类对当前的要参与比较的对象进行实例化。注意当前要参与比较的对象必须要实现WritableComparable 接口。最后在Job提交代码中将自定义的比较器对象设置到Job中就可以了。
11、描述一下Hadoop中实现排序比较的规则(源码角度分析)
Hadoop中的排序比较,本质上就是给某个对象获取到一个比较器对象,至于比较逻辑就直接调用该比较器对象中的compareTo() 方法来实现即可!接下来我们主要聊聊如何给一个对象获取比较器对象。从源码角度分析,我们在Hadoop的MapTask类中的init方法中关注一行代码comparator=job.getOutputKeyComparator(); 此代码就是在获取比较器对象,跟到该方法中,首先源码中会先从Job配置中获取是否指定过自定义的比较器对象,如果获取到已经设置的比较器对象的Class文件,接下来就会利用反射将比较器对象创建出来,到此获取比较器对象的流程就结束了。
如果我们没有在Job中设置自定义的比较器对象,那就没办法用反射的形式获取比较器对象,接下来Hadoop框架会帮助我们创建,具体思路如下:
1. 在获取之前有个前提 判断当前job的MapOutputKeyClass 是否实现了WritableComparable接口,因为我们 实现比较的时候是根据key进行比较的,所以重点关注MapOutputKeyClass。
2. 如果上面一步正常,MapOutputKeyClass实现了WritableComparable接口,接下来考虑到参与比较的对象是Hadoop自身的数据类型,例如Text 、LongWritable 等,这些数据类型在类加载的时候就已将获取到了比较器对象,并且以当前对象的class为key,一当前对象的比较器对象为value维护在内存中的一个叫做comparators的HashMap中。所以从源码上看会执行
WritableComparator comparator = comparators.get(c); 这样以及代码,意思就是从comparators这个HashMap中根据当前对象的class文件获取它的比较器对象。如果不出意外到这就可以获取Hadoop自身数据类型对象的比较对象了。但是考虑的一些异常情况,比如内存溢出导致GC垃圾回收这时候可能会获取不到比较器对象,那么接下来会执行forceInit(c);这样一个方法,让类重新再加载一遍,确保万无一失。如果到此还是获取不到比较器对象,那么只有一种情况了,那就是当前的参与比较的对象不是Hadoop自身的数据类型,而是我们自定义的对象,在源码中也已看到 最后执行了一句
comparator = new WritableComparator(c, conf, true); 代码,意思是Hadoop会给我创建一个比较器对象。以上就是Hadoop中获取比较器对象的全过程了!
12、编写MR的时候什么情况下使用Combiner ,具体实现流程是什么
Combiner流程再MR中是一个可选流程,通常也是一种优化手段,当我们执行完Map阶段的计算后数据量比较大,kv组合过多。这样在Reduce阶段执行的时候会造成拷贝大量的数据以及汇总更多的数据。为了减轻Reduce的压力,此时可以选择在Map阶段进行Combiner操作,将一些汇总工作提前进行,这样会减少kv的数量从而在数据传输的过程中对IO的消耗也大大降低。
实现Combiner的大概流程为:首先需要自定义一个Combiner类,接着继承Hadoop的Reducer类,重写reduce()方法,在该方法中进行合并汇总。最后把自定义的Combiner类设置到Job中即可!
13、OutputFormat自定义实现流程描述一下
OutputFormat类是MR中最后一个流程了,它主要负责数据最终结果的写出,一般我们不需要自定义,默认即可。但是如果我们对象最终输出结果文件的名称或者输出路径有个性化的要求,就可以通过自定OutputFormat来实现。实现流程大概如下:
首先自定义个OutputFormat类,然后继承OutputFormat,重写OutputFormat的getRecordWriter()方法,在该方法中返回 RecordWriter 对象。由于RecordWriter 也是Hadoop内部对象,如果我们想实现自己的逻辑,我们还得自定义个RecordWriter类,然后继承RecordWriter类,重写该类中的write() 方法和close()方法,在write() 方法中实现数据写出的逻辑,在close()方法对资源进行关闭。
14、MR实现 ReduceJoin 的思路,以及ReduceJoin方案有哪些不足
说到MR中的ReduceJoin,首先在Map阶段我们对需要jion的两个文件的数据进行统一搜集,用一个对象去管理,另外还要再改对象中新增一个属性用于记录每一条数据的来源情况。当在Map阶段将数据搜集好后,直接写出,写出的时候一定要注意输出的key的选择,这个key一定两个文件的关联字段。接下来Reduce阶段开始执行,先把Map端处理完的数据拷贝过来,然后一组相同key的values就会进入到reduce() 方法,由于之前已经定义好key是两文件的关联数据,那本次进入reduce() 的做join就可以,第一步根据不同的数据来源将两文件的数据分别利用容器或者对象维护起来,然后遍历其中一个容器根据具体业务逻辑将想要关联的数据获取到即可 然后输出结果。
以上就是ReduceJoin的大概思路,但是ReduceJoin相对来说比较耗费性能,而且如果出现数据倾斜场景,更不太好处理。
15、MR实现 MapJoin 的思路,以及MapJoin的局限性是什么
MapJoin顾名思义就是在Map端直接进行Join,不会走Reduce阶段,这样就很大程度的提升了MR的属性效率,同时也解决的数据倾斜给Reduce阶段带来的问题。接下来就聊聊MapJoin的核心思路,首先MapJoin的前提就是我们面对需要join的两个文件符合一个是大文件一个是小文件的条件。再次前提下,我们可以将小的文件提前缓存的内存中,然后让Map端直接处理大文件,每处理一行数据就根据当前的关联的字段到内存中获取想要的数据,然后将结果写出。