【3D点云】弱监督点云分割(论文解读 CVPR2020)
文章目录
- 一、摘要
-
- 1.Introduction
- 2.四点贡献
- 二、相关工作
-
- 1.不完全(半监督)学习
- 2.不准确注释
- 3.点云分析
- 三、方法论
-
- 1.点云编码网络(encoder)
- 2.不完整的监督分支
- 3.不精确的监督分支
- 4.孪生自监督
- 5. 空间和颜色平滑度约束
- 6.训练
- 四、实验
- 总结
题目: Weakly Supervised Semantic Point Cloud Segmentation: Towards 10× Fewer Labels
论文:https://arxiv.org/pdf/2004.04091.pdf
代码:https://github.com/alex-xun-xu/WeakSupPointCloudSeg
一、摘要
在这项工作中,我们提出了一种弱监督点云分割方法,它只需要一小部分的点被标记。这是通过 学习梯度近似 和 利用额外的空间和颜色平滑约束 来实现。在三个不同程度的弱监督的公共数据集上进行了实验。
1.Introduction
有监督的方法有[19,20,33,12,29] (两个任务:点云 形状分类 和 点云分割 )
[12] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di,and Baoquan Chen. Pointcnn: Convolution on x-transformed points. In NIPS, 2018.
[19] Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas.PointNet: Deep learning on point sets for 3D classification and segmentation. In CVPR, 2017.
[20] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NIPS, pages 5099–5108,2017.
[29] Lei Wang, Yuchun Huang, Yaolin Hou, Shenman Zhang, and Jie Shan. Graph attention convolution for point cloud semantic segmentation. In CVPR, 2019.
[33] Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma,Michael M Bronstein, and Justin M Solomon. Dynamicgraph cnn for learning on point clouds. ACM Transactions on Graphics (TOG), 2019.
为了使弱监督分割具有很强的上下文建模能力和处理通用的三维点云数据,我们选择建立在最先进的深度神经网络来学习点云特征嵌入。给定部分标记的点云数据,我们采用了一个不完全的监督分支,它只惩罚标记点。这是因为不完全监督的学习梯度可以被认为是完全监督的抽样近似。在3.2节我们分析了,近似梯度在分布上收敛于真实梯度,间隙呈正态分布,方差与采样点的数量成反比。因此,如果给定足够的标记点,近似的梯度接近于真实的梯度。结论是,在每个样本中用更少的标记点广泛地注释更多的样本,总是比用更多(或完全)标记点集中地标记更少的样本更好。
由于上述方法只对标记点施加约束,我们在三个正交方向上对未标记点提出附加约束:
1.首先,我们引入了一个额外的不精确监督分支,它以类似于多实例学习[35,7]的方式定义了点云样本级交叉熵损失。它的目的是抑制关于负类别的任何点的激活。
2.其次,我们引入了一个孪生自监督分支,通过增强训练样本的随机平面内旋转和翻转,然后鼓励原始的和增强的point-wise 预测是一致的。
3.最后,我们观察到语义部分/对象, 在局部空间和颜色空间中通常是连续的。
为此,我们提出了一个空间和颜色平滑度约束,以鼓励具有相似颜色的空间相邻点具有相同的预测。这种约束可以通过求解类似于图[38]上标签传播的软约束,在推理阶段应用。我们提出的网络如图2所示。
*
我们的网络架构用于弱监督的点云分割。红线表示反向传播流。
2.四点贡献
- 这是第一个在深度学习环境下研究弱监督点云分割的工作。
- 我们对弱监督的成功作出了一个解释,并且提供对固定标签预算下的注释策略的见解
- 我们采用基于不精确监督、自监督和空间和颜色平滑度的三个额外损失来进一步约束未标记数据。
- 实验在三个公共数据集上进行了实验,作为鼓励未来研究的benchmarks。
二、相关工作
具体地说,我们关注两种类型的弱监管:不完全和不准确( incomplete and inexact supervision)
1.不完全(半监督)学习
这在文献[38,3,17,2,10,27,8]中也被称为半监督学习。少量标注:几个边界框或像素被标记用于图像分割任务[17,2],或者几个节点被标记用于图形推理[27]。成功的原因通常归因于问题特定假设的利用,包括图流形[38,3,27]、空间和颜色连续性[17,2]等。另一种工作方式是基于集成学习,通过引入额外的约束条件,如原始数据和改变数据之间的一致性,例如添加噪声[22]、旋转[10]或ad对抗性训练[15]。
在这项工作中,我们利用了最先进的深度神经网络,和其中重新分配额外的空间约束,以进一步规范模型。因此,我们利用了深度模型和几何先验提供的空间相关性。
2.不准确注释
他们的目标是从图像分割任务的每幅 图像级注释 [9,24]中推断出每幅像素的预测。提出了类激活图(CAM)[35],以突出CNN的关注基于区别性的监督。它是一个很好的弱监督分割[9,32]的 先验模型。不准确的监督往往是对不完全的监督的 补充,因此,它也被使用改进半监督图像分割[2]。在这项工作中,我们引入不精确监督作为不完全监督的补充。
3.点云分析
PointNet[19]是通过级联多层感知器(mlps)来学习三维点云特征的点云的分类和分割;这些工作[20,33,12,30,11]提出通过局部池化或图卷积来利用局部几何。在点云分析的所有任务中,有语义分割由于其在机器人技术中的潜在应用,现有的工作依赖于在point-level 学习[19]一个分类器。然而,这种范式需要详尽的点级标记,并且不能很好地进行扩展。我们还注意到,[26]提出在训练目标中增加空间平滑正则化。[5]提出通过CRF来细化预测。然而,这两项工作都需要充分的监督。
[11] Loic Landrieu and Martin Simonovsky. Large-scale point cloud semantic segmentation with superpoint graphs. In CVPR, 2018.
[12] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. Pointcnn: Convolution on x-transformed points. In NIPS, 2018.
[20] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NIPS, pages 5099–5108, 2017.
[30] Shenlong Wang, Simon Suo, Wei-Chiu Ma, Andrei Pokrovsky, and Raquel Urtasun. Deep parametric continuous convolutional neural networks. In CVPR, 2018.
[33] Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (TOG), 2019.
三、方法论
1.点云编码网络(encoder)
输入的第b个点云可表示成:![]() 。N为点云数量,F为特征维度(xyzrgb)。语义分割标签可表示为
。N为点云数量,F为特征维度(xyzrgb)。语义分割标签可表示为![]() ,one-hot编码为:
,one-hot编码为:![]() 。经过神经网络,点云特征变为
。经过神经网络,点云特征变为![]() 。备选encode网络有:[19, 20, 12](后面两个为pointnet++)
。备选encode网络有:[19, 20, 12](后面两个为pointnet++)
[12] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. Pointcnn: Convolution on x-transformed points. In NIPS, 2018.
后续实验中会有性能对比。
2.不完整的监督分支
我们假设点云样本{X_b}中,只有几个点被标记为真值,二进制掩码表示为: M∈{0,1}_B×N,即标记点为1,0是otherwise。标记点上的软最大交叉熵损失定义为:
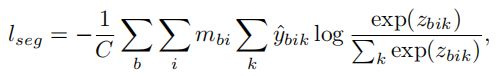 ,
,
其中, ![]() 是归一化变量。实验发现,我们的方法在只有10%的标记点上产生了竞争的结果,即||M||_1/(B·N)=0.1。
是归一化变量。实验发现,我们的方法在只有10%的标记点上产生了竞争的结果,即||M||_1/(B·N)=0.1。
我们首先假设两个权重相似的网络—— 一个经过完全监督训练,另一个经过弱监督,应该产生相似的结果。假设两个网络都以相同的初始化开始,那么在每一步中,梯度的相似性就越高,这意味着两个网络收敛到相似结果的机会就越大。
全监督与弱监督的梯度表示如下:
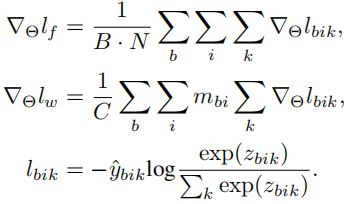
在每个训练步骤中,学习梯度的方向 是相对于每个单独的点计算出的梯度的平均值。假设![]() 与期望
与期望 ![]() 和方差
和方差 ![]() 独立同分布,采样平均值(采样n个目标)为:
独立同分布,采样平均值(采样n个目标)为:![]() 。可验证出:
。可验证出:
![]() ,其中
,其中![]()
根据中心极限定理,我们在分布上有以下收敛性:
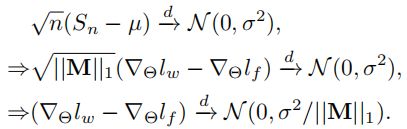
这基本上说明了,完全监督与弱监督的 梯度差值 呈正态分布,方差为σ^2 / ||M||_1。因此,足够数量的标记点,即足够大的||M||1,能够很好地近似∇Θlf 和 ∇Θlw。虽然σ的值很难提前估计,但我们的方法产生的结果与完全监督少于10×的标记点的效果相当。
3.不精确的监督分支
假设每个部分至少有一个标记点,每个训练样本 X_b 都伴随着一个不精确的标签![]() ,相当于对所有点进行最大池化。因此,不精确的监督分支以类似于多实例学习[18,7]的方式构建。特征嵌入Z_b首先是全局最大合并的,即
,相当于对所有点进行最大池化。因此,不精确的监督分支以类似于多实例学习[18,7]的方式构建。特征嵌入Z_b首先是全局最大合并的,即![]() 由于¯zb定义了每个类别上的对数,因此可以采用交叉熵作为损失:
由于¯zb定义了每个类别上的对数,因此可以采用交叉熵作为损失:

基本原理是,对于那些在样本中没有的部分类别,不应该用高对数来预测任何点。不完整的监督 分支只在一个很小的分支上进行监督N个标签点,而 不精确监督 分支在样本水平上监督所有点,因此它们是互补的。
4.孪生自监督
尽管有上述两次损失,但大多数未标记的点仍然没有受到任何约束的训练。对这些点的额外限制可能会进一步改善研究结果。.我们假设 对任何点的预测都是旋转和镜像翻转不变的。这一假设尤其适用于3D CAD形状和以X方向旋转的室内场景例如,在一个房间中,语义标签不应该随着不同的视角而改变。考虑到这一点,我们设计了一个具有两个共享参数编码器f1(X)和f2(X)的孪生网络结构。数据增强为:沿着X轴和/或Y轴的镜像和一个XoY平面的旋转,即: θ ∼ U(0, 2π)均匀分布;a, b, c ∼ B(1, 0.5)伯努利分布
第一个矩阵控制旋转的程度,第二个矩阵控制镜像和X,Y交换。将旋转不变约束转化为**g(f1(X))和g(f2(X˜))**的概率预测之间的散度最小化(其中g(·)是softmax函数),用L2的距离来测量散度:
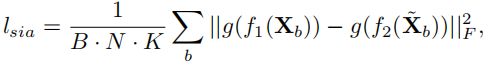
5. 空间和颜色平滑度约束
三维形状或场景的 语义标签 在空间和颜色空间中都是平滑的。在我们的弱监督环境下,当嵌入大量的未标记点没有很好地受到分割损失的约束时,显式约束更有利。
可以在点云上定义一个流形,以通过一个图形来解释局部的几何形状和颜色。为了构造 Manifold graph,我们首先计算通道c(xyz或rgb)的成对距离![]() ,即
,即![]()
然后,通过搜索每个点的k个最近邻k(x),可以构造一个k-nn图,并将相应的权值矩阵W_c∈R_N×N写为
 我们取,xyz和rgb两个权重矩阵的和,xyz和rgb作为Manifold graph,以产生一个更可靠的流形:
我们取,xyz和rgb两个权重矩阵的和,xyz和rgb作为Manifold graph,以产生一个更可靠的流形:![]()
![]() 这是合理的,因为xyz通道模糊了边界,而rgb通道分别连接了遥远的点。如果在空间距离和颜色上构造的流形与标记的GT矛盾,我们在W中添加了额外的必须链接和不可链接约束[31],以加强遵从性到已知的注释,即:
这是合理的,因为xyz通道模糊了边界,而rgb通道分别连接了遥远的点。如果在空间距离和颜色上构造的流形与标记的GT矛盾,我们在W中添加了额外的必须链接和不可链接约束[31],以加强遵从性到已知的注释,即: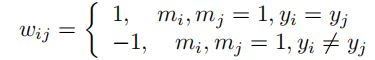
训练阶段:
我们引入了一个流形正则化器[3],以鼓励每个点的特征嵌入符合之前得到的流形。如果w_ij表示较高,并保持无约束,那么预测f(xi)应该保持在f(xj)附近。正则化器为:
 其中Z是所有点的预测。
其中Z是所有点的预测。
预测阶段:
众所周知,在图像分割中,CNN的预测没有很好地考虑边界,[4,9]和CRF经常被使用来细化原始预测。在弱监督点云分割中,由于标签有限,这个问题加剧。为了缓解这一问题,我们引入了一个半监督的标签传播程序[38]来改进预测。具体来说,细化的预测Z˜应该符合拉普拉斯L定义的空间和颜色流形,同时不应与网络预测Z偏离太多。目标为:
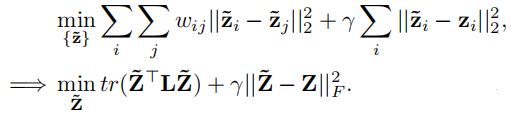
6.训练
最终的训练目标是结合上述所有目标,即总=l_seg+λ1l_mil+λ2l_sia+λ3l_smo。我们根据经验设置了λ1,λ2,λ3=1。在等式中选择k-nn图为k=10、η=1e3和γ为1。
四、实验
三个数据集:ShapeNet 是一个CAD模型数据集,包含来自16个类别的16,881个形状,每个形状都有50个部分的注释。对于每个训练样本,我们从每个部分中随机选择一个点的子集来进行标记。
PartNet[16]被提出用于更细粒度的点云学习。它由24个独特的形状类别组成,共有26,671个形状。
S3DIS[1],用于对室内场景的理解。它由6个区域组成,每个区域覆盖几个房间。
S3DIS数据集中选定房间的分割结果。从左到右,我们依次可视化RGB视图,地面真相,完全监督分割,弱监督基线方法和我们的最终方法结果。

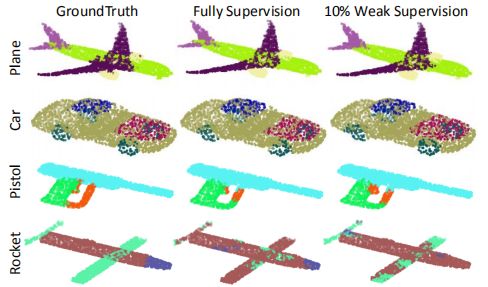
特别是,我们提出的方法能够通过平滑有噪声的区域来大大改善基线结果。尽管如此,我们在不同物体之间的边界上观察到我们的方法的一些错误。在ShapeNet上的分割结果如图所示(这些例子再次证明了弱监督方法具有高度竞争的性能。对于飞机和汽车的类别,监管薄弱的结果都非常接近完全监督)。
总结
在本文中,我们发现现有的点云 encoder network 只需要少量的标记点,就可以为点云分割任务产生非常具有竞争力的性能。我们从统计学的角度提供分析,并洞察了固定标签预算下的注释策略。此外,我们提出了三个额外的训练损失,即不精确监督、孪生自监督、空间和色彩平滑,进一步规范模型。在三个公共数据集上进行了实验,以验证了我们提出的有效性方法特别是,该结果与减少10×标记点的完全监督相当。