EfficientNetV2网络详解
原论文名称:EfficientNetV2: Smaller Models and Faster Training
论文下载地址:https://arxiv.org/abs/2104.00298
原论文提供代码:https://github.com/google/automl/tree/master/efficientnetv2
在bilibili上的讲解视频:https://b23.tv/M4hagB
自己使用pytorch实现的代码:pytorch_classification/Test11_efficientnetV2
自己使用tensorflow2实现的代码:tensorflow_classification/Test11_efficientnetV2
文章目录
-
- 0 前言
- 1 EfficientNetV1中存在的问题
- 2 EfficientNetV2中做出的贡献
- 3 NAS 搜索
- 4 EfficientNetV2网络框架
-
- 4.1 EfficientNetV2-S的详细参数
- 4.2 EfficientNetV2-M的详细参数
- 4.3 EfficientNetV2-L的详细参数
- 4.4 EfficientNetV2其他训练参数
- 4.5 EfficientNetV2与其他模型训练时间对比
- 5 Progressive Learning渐进学习策略
0 前言
在之前的文章中有详细讲解过EfficientNetV1,地址,今天接着讲下EfficientNetV2,这篇文章是在今年(2021)4月份发布的,但源码是这两天才放出来的,因为很多网络细节必须通过源码才能看清,所以简单阅读下源码后就来总结下这篇文章。首先放张论文中给出的EfficientNetV2的性能参数。
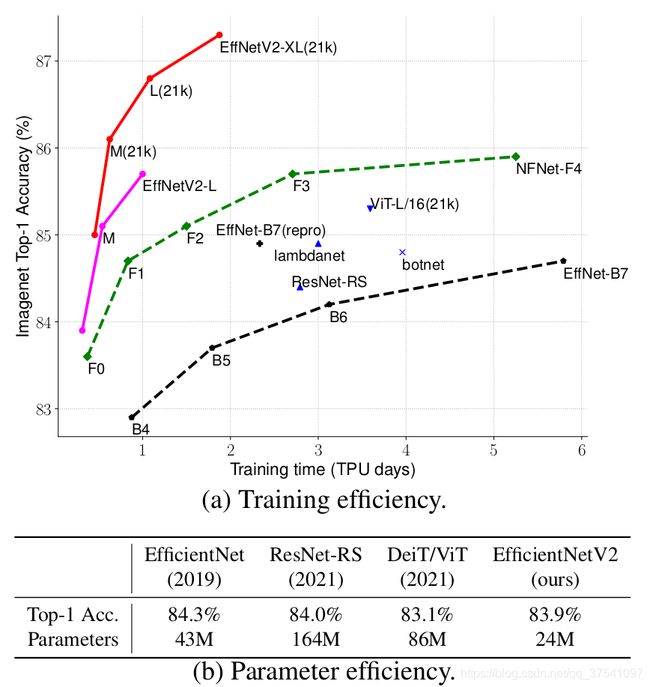
通过上图很明显能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少(比当前火热的Vision Transformer还要强)。EfficientNetV2-XL (21k)在ImageNet ILSVRC2012的Top-1上达到87.3%。在EfficientNetV1中作者关注的是准确率,参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。
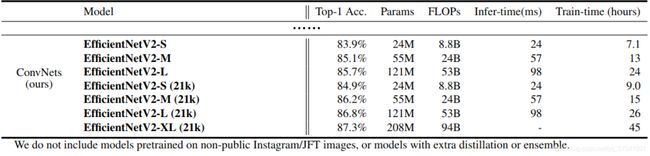
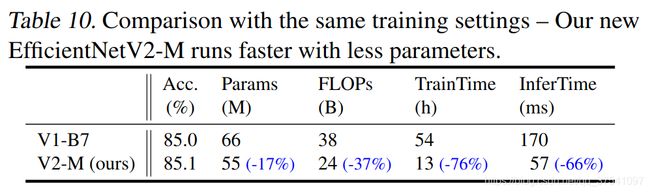
1 EfficientNetV1中存在的问题
作者系统性的研究了EfficientNet的训练过程,并总结出了三个问题:
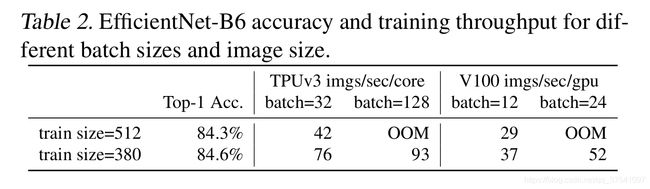
- 训练图像的尺寸很大时,训练速度非常慢。 这确实是个槽点,在之前使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。通过下表可以看到,在Tesla V100上当训练的图像尺寸为380x380时,batch_size=24还能跑起来,当训练的图像尺寸为512x512时,batch_size=24时就报OOM(显存不够)了。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size.
- 在网络浅层中使用Depthwise convolutions速度会很慢。 虽然
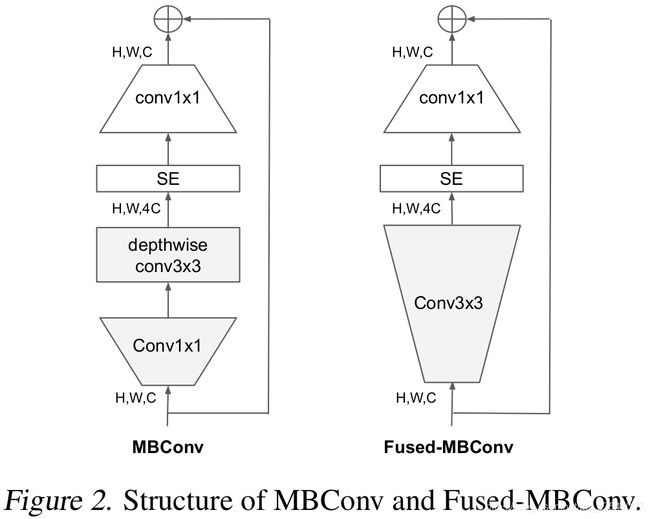
Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv结构也非常简单,即将原来的MBConv结构(之前在将EfficientNetv1时有详细讲过)主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图2所示。作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,如表3所示,将stage2,3,4都替换成Fused-MBConv结构后,在Tesla V100上从每秒训练155张图片提升到216张。但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。
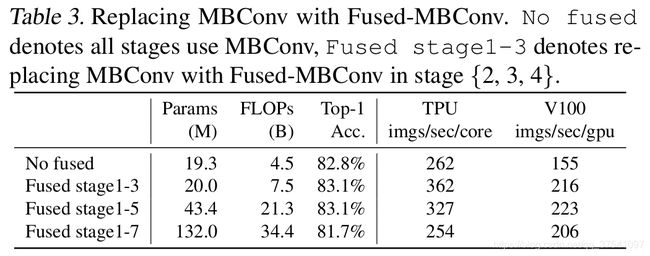
- 同等的放大每个stage是次优的。 在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。
2 EfficientNetV2中做出的贡献
在之前的一些研究中,大家主要关注的是准确率以及参数数量(注意,参数数量少并不代表推理速度更快)。但在近些年的研究中,大家开始关注网络的训练速度以及推理速度(可能是准确率刷不动了)。但他们提升训练速度通常是以增加参数数量作为代价的。而这篇文章是同时关注训练速度以及参数数量的。
However, their training speed often comes with the cost of more paramters. This paper aims to significantly imporve both training and parameter efficiency than prior art.
这篇文章做出的三个贡献:
- 引入新的网络(EfficientNetV2),该网络在训练速度以及参数数量上都优于先前的一些网络。
- 提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如
dropout、data augmentation和mixup)。通过实验展示了该方法不仅能够提升训练速度,同时还能提升准确率。 - 通过实验与先前的一些网络相比,训练速度提升11倍,参数数量减少为 1 6.8 \frac{1}{6.8} 6.81。
3 NAS 搜索
这里采用的是trainning-aware NAS framework,搜索工作主要还是基于之前的Mnasnet以及EfficientNet. 但是这次的优化目标联合了accuracy、parameter efficiency以及trainning efficiency三个维度。这里是以EfficientNet作为backbone,设计空间包含:
- convolutional operation type : {
MBConv,Fused-MBConv} - number of layer
- kernel size : {
3x3,5x5} - expansion ratio (
MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3): {1,4,6}
另外,作者通过以下方法来减小搜索空间的范围:
- 移除不需要的搜索选项,例如pooling skip操作(因为在EfficientNet中并没有使用到)
- 重用EfficientNet中搜索的channel sizes(需进一步补充)
接着在搜索空间中随机采样了1000个模型,并针对每个模型训练10个epochs(使用较小的图像尺度)。搜索奖励结合了模型准确率A,标准训练一个step所需时间S以及模型参数大小P,奖励函数可写成:
A ⋅ S w ⋅ P v A\cdot{S^w}\cdot{P^v} A⋅Sw⋅Pv
其中, w = − 0.07 w=-0.07 w=−0.07, v = − 0.05 v=-0.05 v=−0.05.
4 EfficientNetV2网络框架
表4展示了作者使用NAS搜索得到的EfficientNetV2-S模型框架(注意,在源码中Stage6的输出Channels是等于256并不是表格中的272,Stage7的输出Channels是1280并不是表格中的1792,后续论文的版本会修正过来)。相比与EfficientNetV1,主要有以下不同:
- 第一个不同点在于EfficientNetV2中除了使用到
MBConv模块外,还使用了Fused-MBConv模块(主要是在网络浅层中使用)。 - 第二个不同点是EfficientNetV2会使用较小的
expansion ratio(MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3)比如4,在EfficientNetV1中基本都是6. 这样的好处是能够减少内存访问开销。 - 第三个不同点是EfficientNetV2中更偏向使用更小(
3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。通过下表可以看到使用的kernel_size全是3x3的,由于3x3的感受野是要比5x5小的,所以需要堆叠更多的层结构以增加感受野。 - 最后一个不同点是移除了EfficientNetV1中最后一个步距为1的stage(就是EfficientNetV1中的stage8,不了解的可以看下我之前写的EfficientNetV1网络详解),可能是因为它的参数数量过多并且内存访问开销过大(由于网络是通过NAS搜索出来的,所有这里也是作者的猜测)。
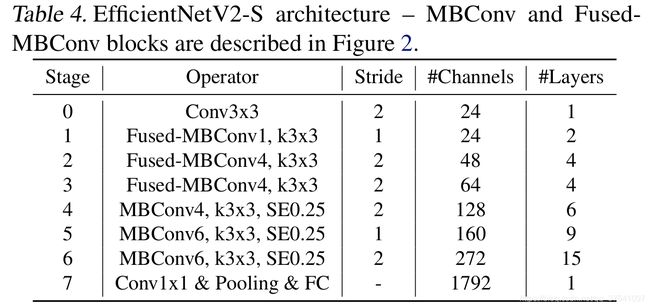
通过上表可以看到EfficientNetV2-S分为Stage0到Stage7(EfficientNetV1中是Stage1到Stage9)。Operator表示在当前Stage中使用的模块:
-
Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN -
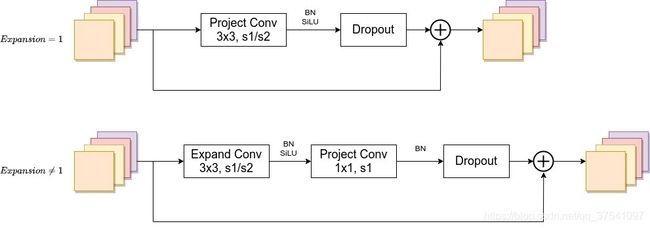
Fused-MBConv模块上面再讲EfficientNetV1存在问题章节有讲到过,模块名称后跟的1,4表示expansion ratio,k3x3表示kenel_size为3x3,下面是我自己重绘的结构图,注意当expansion ratio等于1时是没有expand conv的,还有这里是没有使用到SE结构的(原论文图中有SE)。注意当stride=1且输入输出Channels相等时才有shortcut连接。还需要注意的是,当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。具体可参考Deep Networks with Stochastic Depth这篇文章。
-
MBConv模块和EfficientNetV1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的 1 4 \frac{1}{4} 41详情可查看我之前的文章,下面是我自己重绘的MBConv模块结构图。注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。

Stride就是步距,注意每个Stage中会重复堆叠Operator模块多次,只有第一个Opertator模块的步距是按照表格中Stride来设置的,其他的默认都是1。 #Channels表示该Stage输出的特征矩阵的Channels,#Layers表示该Stage重复堆叠Operator的次数。
4.1 EfficientNetV2-S的详细参数
首先在官方的源码中有个baseline config注意这个不是V2-S的配置,在efficientnetv2 -> effnetv2_configs.py文件中 。
#################### EfficientNet V2 configs ####################
v2_base_block = [ # The baseline config for v2 models.
'r1_k3_s1_e1_i32_o16_c1',
'r2_k3_s2_e4_i16_o32_c1',
'r2_k3_s2_e4_i32_o48_c1',
'r3_k3_s2_e4_i48_o96_se0.25',
'r5_k3_s1_e6_i96_o112_se0.25',
'r8_k3_s2_e6_i112_o192_se0.25',
]
EfficientNetV2-S的配置是在baseline的基础上采用了width倍率因子1.4, depth倍率因子1.8得到的(这两个倍率因子是EfficientNetV1-B4中采用的)。
v2_s_block = [ # about base * (width1.4, depth1.8)
'r2_k3_s1_e1_i24_o24_c1',
'r4_k3_s2_e4_i24_o48_c1',
'r4_k3_s2_e4_i48_o64_c1',
'r6_k3_s2_e4_i64_o128_se0.25',
'r9_k3_s1_e6_i128_o160_se0.25',
'r15_k3_s2_e6_i160_o256_se0.25',
]
为了方便理解,还是对照着表4来看(注意,在源码中Stage6的输出Channels是等于256并不是表格中的272,Stage7的输出Channels是1280并不是表格中的1792,后续论文的版本会修正过来)。
上面给出的配置是针对带有Fused-MBConv或者MBConv模块的Stage,例如在EfficientNetV2-S中就是Stage1到Stage6. 每一行配置对应一个Stage中的信息。其中:
r代表当前Stage中Operator重复堆叠的次数k代表kernel_sizes代表步距stridee代表expansion ratioi代表input channelso代表output channelsc代表conv_type,1代表Fused-MBConv,0代表MBConv(默认为MBConv)se代表使用SE模块,以及se_ratio
比如r2_k3_s1_e1_i24_o24_c1代表,Operator重复堆叠2次,kernel_size等于3,stride等于1,expansion等于1,input_channels等于24,output_channels等于24,conv_type为Fused-MBConv。
源码中关于解析配置的方法如下:
def _decode_block_string(self, block_string):
"""Gets a block through a string notation of arguments."""
assert isinstance(block_string, str)
ops = block_string.split('_')
options = {}
for op in ops:
splits = re.split(r'(\d.*)', op)
if len(splits) >= 2:
key, value = splits[:2]
options[key] = value
return hparams.Config(
kernel_size=int(options['k']),
num_repeat=int(options['r']),
input_filters=int(options['i']),
output_filters=int(options['o']),
expand_ratio=int(options['e']),
se_ratio=float(options['se']) if 'se' in options else None,
strides=int(options['s']),
conv_type=int(options['c']) if 'c' in options else 0,
)
通过配置文件可知Stage0的卷积核个数是24(i24)
4.2 EfficientNetV2-M的详细参数
EfficientNetV2-M的配置是在baseline的基础上采用了width倍率因子1.6, depth倍率因子2.2得到的(这两个倍率因子是EfficientNetV1-B5中采用的)。
v2_m_block = [ # about base * (width1.6, depth2.2)
'r3_k3_s1_e1_i24_o24_c1',
'r5_k3_s2_e4_i24_o48_c1',
'r5_k3_s2_e4_i48_o80_c1',
'r7_k3_s2_e4_i80_o160_se0.25',
'r14_k3_s1_e6_i160_o176_se0.25',
'r18_k3_s2_e6_i176_o304_se0.25',
'r5_k3_s1_e6_i304_o512_se0.25',
]
通过配置文件可知Stage0的卷积核个数是24(i24)
4.3 EfficientNetV2-L的详细参数
EfficientNetV2-L的配置是在baseline的基础上采用了width倍率因子2.0, depth倍率因子3.1得到的(这两个倍率因子是EfficientNetV1-B7中采用的)。
v2_l_block = [ # about base * (width2.0, depth3.1)
'r4_k3_s1_e1_i32_o32_c1',
'r7_k3_s2_e4_i32_o64_c1',
'r7_k3_s2_e4_i64_o96_c1',
'r10_k3_s2_e4_i96_o192_se0.25',
'r19_k3_s1_e6_i192_o224_se0.25',
'r25_k3_s2_e6_i224_o384_se0.25',
'r7_k3_s1_e6_i384_o640_se0.25',
]
通过配置文件可知Stage0的卷积核个数是32(i32)
4.4 EfficientNetV2其他训练参数
下面是源码中给出的配置信息,我们这里只简单看下efficientnetv2-s,efficientnetv2-m和efficientnetv2-l三个参数,其中的v2_s_block,v2_m_block以及v2_l_block就是上面刚刚讲到过的网络配置参数,剩下就关注下train_size, eval_size, dropout, randaug, mixup, aug即可。比如efficientnetv2-s的train_size=300(注意实际训练中train_size是会变化的,后面讲Progressive Learning中会细讲),eval_size=684,dropout=0.2,randaug=10,mixup=0,aug='randaug'.
efficientnetv2_params = {
# (block, width, depth, train_size, eval_size, dropout, randaug, mixup, aug)
'efficientnetv2-s': # 83.9% @ 22M
(v2_s_block, 1.0, 1.0, 300, 384, 0.2, 10, 0, 'randaug'),
'efficientnetv2-m': # 85.2% @ 54M
(v2_m_block, 1.0, 1.0, 384, 480, 0.3, 15, 0.2, 'randaug'),
'efficientnetv2-l': # 85.7% @ 120M
(v2_l_block, 1.0, 1.0, 384, 480, 0.4, 20, 0.5, 'randaug'),
'efficientnetv2-xl':
(v2_xl_block, 1.0, 1.0, 384, 512, 0.4, 20, 0.5, 'randaug'),
# For fair comparison to EfficientNetV1, using the same scaling and autoaug.
'efficientnetv2-b0': # 78.7% @ 7M params
(v2_base_block, 1.0, 1.0, 192, 224, 0.2, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b1': # 79.8% @ 8M params
(v2_base_block, 1.0, 1.1, 192, 240, 0.2, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b2': # 80.5% @ 10M params
(v2_base_block, 1.1, 1.2, 208, 260, 0.3, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b3': # 82.1% @ 14M params
(v2_base_block, 1.2, 1.4, 240, 300, 0.3, 0, 0, 'effnetv1_autoaug'),
}
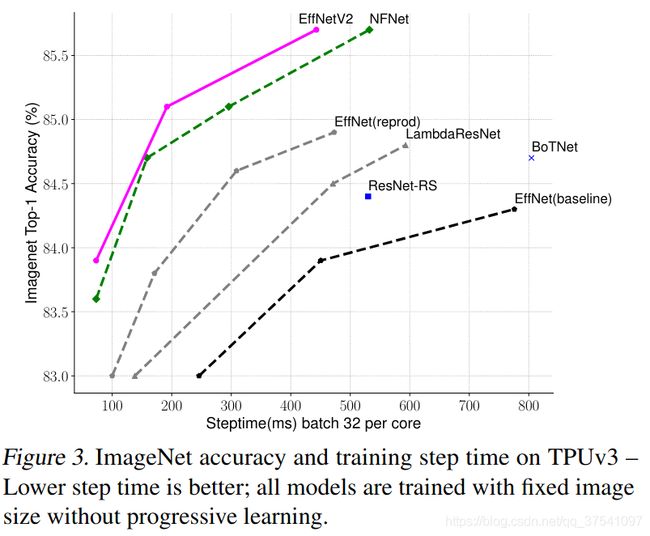
4.5 EfficientNetV2与其他模型训练时间对比
下图展示一系列模型在固定训练图像尺寸(注意,这里还没有使用渐进的学习策略)时训练每个step的时间以及最终的Accuracy曲线。通过下面曲线可以看到EfficientNetV2的训练速度更快,并且能够达到当前SOTA。
5 Progressive Learning渐进学习策略
前面提到过,训练图像的尺寸对训练模型的效率有很大的影响。所以在之前的一些工作中很多人尝试使用动态的图像尺寸(比如一开始用很小的图像尺寸,后面再增大)来加速网络的训练,但通常会导致Accuracy降低。为什么会出现这种情况呢?作者提出了一个猜想:Accuracy的降低是不平衡的正则化unbalanced regularization导致的。在训练不同尺寸的图像时,应该使用动态的正则方法(之前都是使用固定的正则方法)。
为了验证这个猜想,作者接着做了一些实验。在前面提到的搜索空间中采样并训练模型,训练过程中尝试使用不同的图像尺寸以及不同强度的数据增强data augmentations。当训练的图片尺寸较小时,使用较弱的数据增强augmentation能够达到更好的结果;当训练的图像尺寸较大时,使用更强的数据增强能够达到更好的接果。如下表所示,当Size=128,RandAug magnitude=5时效果最好;当Size=300,RandAug magnitude=15时效果最好:

基于以上实验,作者就提出了渐进式训练策略Progressive Learning。如下图所示,在训练早期使用较小的训练尺寸以及较弱的正则方法weak regularization,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法adding stronger regularization。这里所说的regularization包括dropout rate,RandAugment magnitude以及mixup ratio。

接着作者将渐进式学习策略抽象成了一个公式来设置不同训练阶段使用的训练尺寸以及正则化强度。假设整个训练过程有 N N N步,目标训练尺寸(最终训练尺度)是 S e S_e Se,正则化列表(最终正则强度) ϕ e = { ϕ e k } \phi_e=\left\{\phi_e^k\right\} ϕe={ϕek}其中 k k k代表 k k k种正则方法(刚刚说了,有Dropout、RandAugment以及Mixup三种)。初始化训练尺寸 S 0 S_0 S0,初始化正则化强度为 ϕ 0 = { ϕ 0 k } \phi_0=\left\{\phi_0^k\right\} ϕ0={ϕ0k}。接着将整个训练过程划分成 M M M个阶段,对于第 i i i个阶段( 1 ≤ i ≤ M 1 \leq i \leq M 1≤i≤M)模型的训练尺寸为 S i S_i Si,正则化强度为 ϕ i = { ϕ i k } \phi_i=\left\{\phi_i^k\right\} ϕi={ϕik}。对于不同阶段直接使用线性插值的方法递增。具体流程如下:

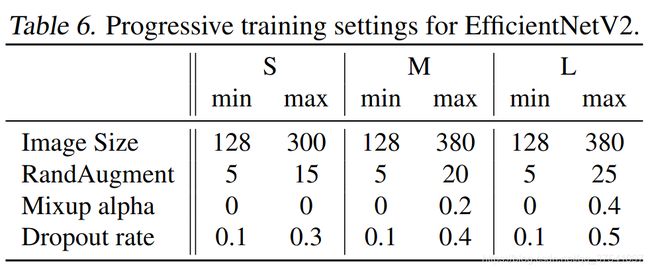
下表给出了EfficientNetV2(S,M,L)三个模型的渐进学习策略参数:
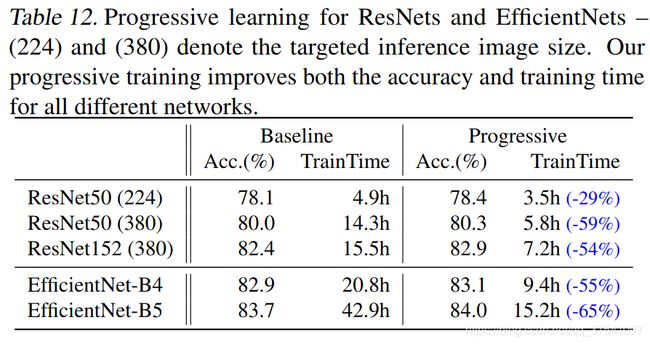
通过以上策略作者在表7中列出了一大堆模型的训练对比,由于表格太大了这里就不展示了,想看的自己翻下原文。通过对比可以看出使用渐进式学习策略确实能够有效提升训练速度。为了进一步验证渐进式学习策略的有效性,作者还在Resnet以及EfficientNetV1上进行了测试,如下表所示,使用了渐进式学习策略后确实能够有效提升训练速度并且能够小幅提升Accuracy。
讲到这,文章的大致内容就讲完了,更多详细细节建议大家仔细去阅读原论文。