Java并发编程实战_盖兹
文章目录
- 第一部分 基础知识
-
- 第1章 简介
-
- 1.1 并发简史
- 1.2 线程的优势
- 1.3 线程带来的风险
- 1.4 线程无处不在(框架线程或类线程并发注意点)
- 第2章 线程安全性
-
- 2.1 什么是线程安全性
- 2.2 原子性
- 2.3 加锁机制
-
- 内置锁:Synchronized关键字
- 可重入锁:获取锁的操作粒度是“线程”而不是调用
- 用锁来保护状态
- 活跃性与性能性
- 第3章 对象的共享
-
- 3.1 可见性
- 3.2 发布与逸出
- 3.3 线程封闭
- 3.4 对象的不变性
- 3.5 安全发布
- 第4章 对象的组合
-
- 4.1 设计线程安全的类
- 4.2 实例封闭
- 4.3 线程安全性委托
- 4.4 在现有的线程安全类中添加功能
- 4.5 将同步策略文档化
- 第5章 基础构建模块
-
-
- 5.1 同步容器类
- 5.2 并发容器
- 5.3 阻塞队列与生产者-消费者模式
- 5.4 阻塞方法和中断方法
- 5.5 同步工具类
-
- 5.5.1 闭锁
- 5.5.2 FutureTask
- 5.5.3 信号量
- 5.5.4 栅栏
- 5.6 构建高效且可伸缩的结果缓存
-
- 第一部分小结
- 第二部分 结构化并发应用程序
-
- 第6章 任务执行
-
- 6.1 在线程中执行任务
-
- 6.1.1 串行地执行任务
- 6.1.2 显示地为任务创建线程
- 6.1.3 无限制创造线程的不足
- 6.2 Executor框架
-
- 6.2.1 示例:基于Executor的Web服务器
- 6.2.2 执行策略
- 6.2.3 线程池
- 6.2.4 Executor的生命周期
- 6.2.5 延迟任务与周期任务
- 6.3 找出可利用的并行性
-
- 6.3.1 示例:串行的页面渲染器
- 6.3.2 携带结果的任务Callable与Future
- 6.3.3 示例:使用Future实现页面渲染器
- 6.3.4 在异构任务并行化中存在的局限
- 6.3.5 CompletionService:Executor与BlockingQueue
- 6.3.6 示例:使用CompletionService实现页面渲染
- 6.3.7 为任务设定时限
- 6.3.8 示例:旅行预定门户网站
- 小结
- 第7章 取消与关闭
-
- 7.1 任务取消
-
- 7.1.1 中断
- 7.1.2 中断策略
- 7.1.3 响应中断
- 7.1.4 示例:计时运行
- 7.1.5 通过Future来实现取消
- 7.1.6 处理不可中断的阻塞
- 7.1.7 采用newTaskFor来封装非标准的取消
- 7.2 停止基于线程的服务
-
- 7.2.1 示例:日志服务
- 7.2.2 关闭ExecutorService
- 7.2.3 "毒丸"对象
- 7.2.4 示例:只执行一次的服务
- 7.2.5 shutdownNow的局限性
- 7.3 处理非正常的线程终止
- 7.4 JVM关闭
-
- 7.4.1 关闭钩子
- 7.4.2 守护线程
- 7.4.3 终结器
- 小结
- 第8章 线程池的使用
-
- 8.1 在任务与执行策略之间的隐性耦合
-
- 8.1.1 线程饥饿死锁
- 8.1.2 运行时间较长的任务
- 8.2 设置线程池的大小
- 8.3 配置ThreadPoolExecutor
-
- 8.3.1 线程的创建与销毁
- 8.3.2 管理队列任务
- 8.3.3 饱和策略
- 8.3.4 线程工厂
- 8.3.5 在调用构造函数后再定制ThreadPoolExecutor
- 8.4 扩展ThreadPoolExecutor
- 8.5 递归算法的并行化
-
- 8.5.1 示例:谜题框架。
- 小结
- 第9章 图形用户界面应用程序
-
- 9.1 为什么GUI是单线程的
-
- 9.1.1 串行事件处理
- 9.1.2 Swing中的线程封闭机制
- 9.2 短时间的GUI任务
- 9.3 长时间的GUI任务
-
- 9.3.1 取消
- 9.3.2 进度标识与完成标识
- 9.4 共享数据模型
-
- 9.4.1 线程安全的数据模型
- 9.4.2 分解数据模型
- 9.5 其他形式的单线程子系统
- 小结
- 第三部分 活跃性、性能与测试
-
- 第10章 避免活跃性危险
-
- 10.1 死锁
-
- 10.1.1 锁顺序死锁
- 10.1.2 动态的锁顺序死锁
- 10.1.3 在协作对象之间发生的死锁
- 10.1.4 开放调用
- 10.1.5 资源死锁
- 10.2 死锁的诊断与避免
-
- 10.2.1 支持定时的锁
- 10.2.2 通过线程转储信息来分析死锁
- 10.3 其他活跃性危险
-
- 10.3.1 饥饿
- 10.3.2 糟糕的响应性
- 10.3.3 活锁
- 小结
- 第11章 性能与可伸缩性
-
- 11.1 对性能的思考
-
- 11.1.1 性能与可伸缩性
- 11.1.2 评估各种性能权衡因素
- 11.2 Amdahl定律
-
- 11.2.1 示例:在各种框架中隐藏的串行部分
- 11.2.2 Amdahl定律的应用
- 11.3 线程引入的开销
-
- 11.3.1 上下文切换
- 11.3.2 内存同步
- 11.3.3 阻塞
- 11.4 减少锁的竞争
-
- 11.4.1 缩小锁的范围(快进快出)
- 11.4.2 减小锁的粒度
- 11.4.3 锁分段
- 11.4.4 避免热点域
- 11.4.5 一些替代独占锁的方法
- 11.4.6 检测CPU的利用率
- 11.4.7 向对象池说“不”,(每次获取对象都需要同步,开销远超过分配内存的开销)
- 11.5 示例:比较Map的性能
- 11.6 减少上下文切换的开销
- 小结
- 第12章 并发程序的测试(未完)
-
- 12.1 正确性测试
- 第四部分 高级主题
-
- 第13章 显式锁
-
- 13.1 Lock和ReentrantLock
-
- 13.1.1 轮询锁与定时锁
- 13.1.2 可中断的锁获取操作
- 13.1.3 非块结构的加锁
- 13.2 性能考虑因素
- 13.3 公平性
- 13.4 在synchronized和ReentrantLock之间进行选择
- 13.5 读-写锁
- 小结
- 第14章 构建自定义的同步工具
-
- 14.1 状态依赖性的管理
-
- 14.1.1 示例:将前提条件的失败传递给调用者
- 14.1.2 示例2:通过轮询与休眠来实现简单的阻塞
- 14.1.3 条件队列
- 14.2 使用条件队列
-
- 14.2.1 条件谓词
- 14.2.2 过早唤醒
- 14.2.3 丢失的信号
- 14.2.4 通知
- 14.2.5 示例:阀门类
- 14.2.6 子类的安全问题
- 14.2.7 封装条件队列
- 14.2.8 入口协议与出口协议
- 14.3 显示的锁
- 14.4 Synchronized剖析
- 14.5 AbstractQueuedSynchronizer:抽象队列同步器(AQS)
- 14.6 JUC同步器中的AQS
-
- 14.6.1 ReentrantLock
- 14.6.2 Semaphore与CountDownLatch
- 14.6.3 FutureTask
- 14.6.4 ReentrantReadWriteLock
- 小结
- 第15章 原子变量与非阻塞同步机制
-
- 15.1 锁的劣势
- 15.2 硬件对并发的支持
-
- 15.2.1 比较并交换(CAS)
- 15.2.2 非阻塞的计数器
- 15.2.3 JVM对CAS的支持
- 15.3 原子变量类
-
- 15.3.1 原子变量是一种“更好的volatile”
- 15.3.2 性能比较:锁与原子变量
- 15.4 非阻塞算法
-
- 15.4.1 非阻塞的栈
- 15.4.2 非阻塞的链表
- 15.4.3 原子的域更新器
- 15.4.4 ABA问题
- 小结
- 第16章 Java内存模型
-
- 16.1 什么是内存模型,为什么需要它
-
- 16.1.1 平台的内存模型
- 16.1.2 重排序
- 16.1.3 Java内存模型简介
- 16.1.4 借助同步
- 16.2 发布
-
- 16.2.1 不安全的发布
- 16.2.2 安全的发布
- 16.2.3 安全初始化模式
- 16.2.4 双重检查加锁
- 16.3 初始化过程中的安全性
- 小结
简介:书中从 并发性和线程安全性的基本概念出发,介绍了如何使用类库提供的基本并发构建块,用于避免并发危险、构造线程安全的类以及验证线程安全的规则,
-
如何使用类库提供的基本并发构建块,用于避免并发危险;
-
构造线程安全的类以及验证线程安全的规则
-
如何将小的线程安全类组合成更大的线程安全类;
-
如何利用线程来提高并发程序的吞吐量,
-
如何识别可并行执行的任务,
-
如何提高单线程的子系统的响应性,
-
如何确保并发程序执行预期任务,
-
如何提高并发代码的性能和可伸缩性,
-
一些高级主题
第一部分 基础知识
第1章 简介
1.1 并发简史
促成计算机由串行向并行发展的原因:
-
资源利用率:比如任务调度如I/O时,CPU不要处于等待,而是处理其他任务;
-
公平性:多个用户应该平等的享受计算机资源;
-
便利性:比如,多个程序相互通信,要求程序之间是并发执行。
1.2 线程的优势
-
发挥多处理器强大能力;
-
建模的简单性:对于不同类型的任务,通过专门线程处理某一阶段的任务,可以以串行模型设计业务,简单了建模;
-
异步事件的简化处理;
-
响应更灵敏的用户界面。
1.3 线程带来的风险
-
安全性问题
-
安全性:永远不发生糟糕的事情
-
原因:多个线程修改共享的变量,导致结果不可预测;
-
解决方案:同步处理原子性操作。
-
-
活跃性问题
- 活跃性:某件正确的事最终发生,活跃性问题比如线程A无限等待线程B不会释放的资源,导致A阻塞,A等待后处理的语句永远不会发生。
- 原因:依赖于不同线程的事件发生时序。
-
性能问题
- 性能:正确的事情尽快发生
- 性能问题:服务时间过长、响应不灵敏等
1.4 线程无处不在(框架线程或类线程并发注意点)
- Timer类:TimeTask将在Timer管理的线程中执行,而不是由应用程序管理,如果某个TimeTask访问了应用程序中其他线程访问的数据,那么不仅TimeTask需要以线程安全的方式来访问数据,其他类也必须采用线程安全的方式来访问数据。通常实现这个目标,最简单的方式要确保TimeTask访问的对象本身是线程安全的,从而就能把线程安全性封装在共享对象内部;
- Servlet和JSP:Servlet、JSP、以及在ServletContext和HttpSession等容器中保存的Servlet过滤器和对象等,都必须是线程安全的。
- RMI:远程对象必须注意两个线程安全性问题,正确地协同在多个对象中共享的状态,以及对远程对象本身状态的访问。与Servlet相同,RMI对象应该做好被多个线程同时调用的准备,并且必须确保他们自身的线程安全性。
第2章 线程安全性
- 要编写线程安全的代码,其核心在于要对状态访问操作进行管理,特别是对共享的同时可变的状态的访问;
- 线程安全解决的方案:
- 不在线程之间共享该状态变量:ThreadLocal类;
- 将状态变量修改为不可变的变量;
- 在访问变量时采用同步机制
2.1 什么是线程安全性
- 一个对象可以被多个线程调用,就要注意该对象的线程安全性;
- 无状态对象一定是线程安全的。

2.2 原子性
-
竞态条件:某个计算的正确性取决于多个线程的交替执行时序时,通俗点说,基于一种可能失效的观察结果来做出判断或者执行某个计算,正确的结果取决于运气。
-
常见的竞态条件类型先检查后执行操作,如以下常见的实例:单例和延迟初始化

-
JUC包原子类管理对象状态

2.3 加锁机制
多个原子性引用如果有相互制约关系,并不能保证该类是线程安全的,如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4FeFVFj-1648810808293)(https://cdn.jsdelivr.net/gh/huangjt520/Image-host@master/picBook/2.5av87uwgbe00.webp)]
内置锁:Synchronized关键字
可重入锁:获取锁的操作粒度是“线程”而不是调用
/**
* @author huangjt
* @ClassName: Wight
* @Description:
* @Date 2022/3/11 9:53
*/
public class Wight {
public synchronized void dosomething(){
System.out.println("Wight的this is : "+ this.toString());
}
}
class SubWight extends Wight{
@Override
public synchronized void dosomething() {
System.out.println("SubWight 的 this is : "+ this.toString());
System.out.println("SubWight 的 super is : "+ super.toString());
super.dosomething();
}
public static void main(String[] args) {
SubWight subWight = new SubWight();
subWight.dosomething();
}
}
/***************结果为**********************/
/*
SubWight 的 this is : SubWight@1540e19d
SubWight 的 super is : SubWight@1540e19d
Wight的this is : SubWight@1540e19d
*/
由以上结果联系JVM内存结构可知,
- 子类调用父类的方法,引用都是子类的引用;
- 栈帧顶部super存取有父类方法区中的信息,也就是子类初始化的时候并不创建父类的实例,子类可以调用父类的方法。
用锁来保护状态
- 对于每个包含多个变量的不变性条件,其中涉及的所有变量都需要由同一个锁来保护
活跃性与性能性
- 评估线程安全、简单性、和性能,中间取得平衡
- 当执行时间较长的计算或者无法快速完成的操作时(如IO),一定不要持有锁。
第3章 对象的共享
3.1 可见性
由于指令重排序和虚拟机线程读取机制,可能造成读取到共享可变变量的失效数据,如下

-
失效数据
-
非原子性的64位操作:虚拟机允许将64位的读操作和写操作分解为两个32位的操作。因此,共享可变的long和double同步,用volatile关键字或者用锁保护起来
-
加锁与可见性
-
Volatile变量:禁止指令重排序和取值从主内存取,只能保证可见性,不能保证原子性,使用的时候需谨慎,常用使用场景如下

3.2 发布与逸出
-
发布:将对象能够在当前作用域之外的代码中使用;
-
逸出:当某个不应该发布的对象被发布时,这种情况就被称为逸出。常见的是构造器this逸出,因为初始化的时候还没有实例,this引用为空。所以不要再构造器中用隐式this引用

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CwIjl12E-1648810808295)(https://cdn.jsdelivr.net/gh/huangjt520/Image-host@master/picBook/使用工厂方法防止隐式逸出.2wqp11xr2me0.webp)]
3.3 线程封闭
-
Ad-hoc线程封闭:完全由程序实现承担。
-
栈封闭:只有通过局部变量才能访问对象

-
ThreadLocal类
3.4 对象的不变性
- 对象创建以后其状态不能修改
- 对象的所有域都是final类型;
- 对象是正常创建的。
3.5 安全发布
-
不正常的发布

-
安全发布的常用模式
-
原则
- 在静态初始化函数中初始化一个对象引用;
- 将对象的引用保存到volatile类型的域或者AtomicReferance对象中;
- 将对象的引用保存到某个正常的构造对象的final类型域中;
- 将对象的引用保存到一个由锁保护的域中。
-
JUC库作出的保证:
- 通过一个将一个键或者值放入HashTable、synchronizedMap或者ConcurrentMap中,可以安全地将它发布给任何从这些容器中访问它的线程;
- 通过将某个元素放入Vector、CopyOnWriteArrayList、CopyOnWriteArraySet、synchronizedList或synchronizedSet中,可以将该元素安全地发布到任何从这些容器中访问该元素的线程;
- 通过将某个元素放入 BlockingQueue 或者 ConcurrentLinkedQueue 中,可以将该元素安全 地发布到任何从这些队列中访问该元素的线程;
- 类库中的其他数据传递机制(例如 Future 和 Exchanger) 同样能实现安全发布,在介绍这 些机制时将讨论它们的安全发布功能。
-
通常发布静态构造的对象,最安全简单的方式是使用静态的初始化器
public static Holder hold = new Holder(); -
事实不可变对象
-
可变对象:安全发布后的每次对象访问都需要同步机制
-
安全地共享变量
- 线程封闭:线程封闭的对象只能由一个线程拥有,对象被封闭在该线程中,并且只能由这个线程修改;
- 只读共享
- 线程安全共享
- 保护对象:被保护的对象只能通过持有特定的锁来访问
-
第4章 对象的组合
4.1 设计线程安全的类
-
设计线程安全类的考虑要素
- 找出构成对象状态的所有变量
- 找出约束状态变量的不变性条件
- 建立对象状态的并发访问管理策略
-
收集同步需求
- 状态空间越小, 就越容易判断线程的状态。final 类型的域使用得越多, 就越能简化对象可能状态的分析过程;
- 在操作中还会包含一些后验条件来判断状态迁移是否是有效的;当下一个状态需要依赖当前状态时, 这个操作就必须是一个复合操作;
- 如果在一个不变性条件中包含多个变量, 那么在执行任何访问相关变量的操作时, 都必须持有保护这些变扯的锁。
-
依赖状态的操作
- 如果在某个操作中包含有基于状态的先验条件,那么这个操作就称为依赖状态的操作,如删除某个队列元素时,必须先保证队列不为空;
- 要想实现某个等待先验条件为真时才执行的操作,一种更简单的方法是通过现有的库类(如阻塞队列Blocking Queue)信号量(Semaphore))来实现依赖状态的行为;
-
状态的所有权
- 状态变量的所有权将决定采用何种加锁协议来维持变量状态的完整性。所有权意味着控制权;
- 如果发布了某个可变对象的引用,那么就不再拥有独立的控制权,最多是“共享控制权”。
4.2 实例封闭
-
你可以确保该对象只能由单个线程访问(线程封闭),或者通过一个锁来保护对该对象的所有访问。
-
封装简化了线程安全类的实现过程,它提供了一种实例封闭机制,当一个对象被封装到另一个对象中时,能够访问被封装对象的所有代码路径都是已知的。
-
通过将封装机制与合适的加锁策略结合起来,可以确保以线程安全的方式来使用非线程安全的对象;
-
将数据封装在对象内部,可以将数据的访问限制在对象的方法上,从而更容易确保线程在访问数据时总能持有正确的锁;
-
被封闭对象一定不能超过他们既定的作用域。
-
对象可以封闭在类的一 个实例(例如作为类 的一个私有成员)中, 或者封闭在某个作用域内(例如作为一个局部变扯), 再或者封闭在线程内(例如在某个线程中将对象从一个方法传递到另一 个方法, 而不是在多个线程之间共享该对象)。
-
通过封闭与加锁实现线程安全例子:1.私有;2.不可变;3.加锁访问

-
封闭机制更易于构造线程安全的类,因为当封闭类的状态时,在分析类的线程安全性时就无须检查整个程序。
-
监视器模式:将监视器对象的所有可变状态都封装起来,并由对象自己的内置锁来保护
-
Java监视器模式仅仅是一种编写代码的约定,对于任何一种锁对象,只要自始至终都使用该锁对象,都可以用来保护对象的状态。
-
监视器模式例子

-
使用私有的锁对象而不是对象的内置锁可以将锁封装起来,使客户代码无法得到锁,避免活跃性问题。
-
-
监视器模式例子二

4.3 线程安全性委托
-
线程安全性委托:委托给线程安全或者不可变状态

-
我们还可以将线程安全性委托给多个状态变量,只要这些变量是彼此独立,即组合而成的类并不会在其包含的多个状态变量上增加任何不变性条件。
-
如果一个状态变量是线程安全的,并且没有任何不变性条件来约束它的值,在变量的操作上也不存在任何不允许的状态转换,那么就可以安全地发布这个变量
-
发布底层的状态变量
4.4 在现有的线程安全类中添加功能
-
Java类库包含许多有用的“基础模块”类。通常,我们应该优先选择重用这些现有的类而不是创建新的类;
-
方式:
-
要添加一个新的原子操作,最安全的方法是修改原始的类,但这通常无法做到,因为可能无法访问或修改源代码,修改前还需要了解原始类的同步机制;
-
另一种方法是扩展这个类,增加原子操作方法;扩展操作比直接操作原始类更加脆弱,如果原始类改变同步策略,将会有大麻烦
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UPxZapE2-1648810808299)(https://cdn.jsdelivr.net/gh/huangjt520/Image-host@master/picBook/线程安全类添加功能.45dtouyctvy0.webp)]
-
客户端加锁机制:扩展类,并在操作列表上加锁,而不是加内置锁
-
错误客户端同步方式

-
客户端正确加锁机制

-
通过添加一个原子操作来扩展类是脆弱的,因为它将类的加锁代码分布到多个类中(容易造成死锁).然而,客户端加锁却更加脆弱,因为它将类的加锁代码放到与类完全无关的其他类中,当在那些并不承诺遵循加锁策略的类上使用客户端加锁时,要特别小心。
-
-
更好的方法——组合
-
暂时没看懂

-
-
4.5 将同步策略文档化
第5章 基础构建模块
第4章介绍了构造线程安全类时采用的一些技术,例如将线程安全性委托给现有的线程安全类。委托是创建线程安全类的一个最有效的策略:只需让现有的线程安全类管理所有的状态即可。
Java平台类库包含了丰富的并发基础构建模块,例如线程安全的容器类以及各种用于协调多个相互协作的线程控制流的同步工具类(Synchronizer)。本章将介绍其中一些最有用的并发构建模块,特别是在Java 5.0和Java 6中引入的一些新模块,以及在使用这些模块来构造并发应用程序时的一些常用模式。
5.1 同步容器类
-
同步容器类的问题:复合操作可能不是原子性的
-
Vector容器可能导致混乱的复合操作
public static Object getLast(Vector list){ int lastIndex=list.size()-1; return list.get(lastIndex); } -
Vector客户端委派加锁机制
public static Object getLast(Vector list){ synchronized(list){ int lastIndex=list.size()-1; return list.get(lastIndex); } }
-
-
迭代器与ConcurrentModificationException
- 及时失败策略(fail-fast):将计数器的变化与容器关联起来,如果在迭代期间计数器被修改,那么hasNext或next将抛出ConcurrentModificationException
-
隐藏迭代器
-
虽然加锁可以防止迭代器抛出ConcurrentModificationException,但你必须要记住在所有对共享容器进行迭代的地方都需要加锁。实际情况要更加复杂,因为在某些情况下,迭代器会隐藏起来
-
隐藏迭代器实例
public class HiddenIterator{ @GuardedBy("this")private final Set<Integer>set=new HashSet<Integer>(); public synchronized void add(Integer i){set.add(i);} public synchronized void remove(Integer i){set.remove(i);} public void addTenThings(){ Random r=new Random(); for(int i=0;i<10;i++)add(r.nextInt()); //toString隐式调用集合的迭代器 System.out.println("DEBUG:added ten elements to"+set); } } -
如果状态与保护它的同步代码之间相隔越远,那么开发人员就越容易忘记在访问状态时使用正确的同步。如果HiddenIterator用synchronizedSet来包装HashSet,并且对同步代码进行封装,那么就不会发生这种错误。
-
5.2 并发容器
-
同步容器与并发容器
- 同步容器缺点:为了同步导致所有对容器的状态访问都串行化,严重影响了性能。
- 通过并发容器来代替同步容器,可以极大地提高伸缩性并降低风险
-
容器与替代:
- ConcurrentHashMap
- CopyOnWriteArrayList:用于遍历操作为主要操作的情况下代替同步的List;
- BlockingQueue:增加了可阻塞的插入和获取等操作。如果队列为空,获取操作将阻塞,直到队列有值;如果队列已满,插入操作将阻塞,直到队列不满。
- ConcurrentSkipListMap
- ConcurrentSkipListSet
-
ConcurrentHashMap
-
与HashMap一样,ConcurrentHashMap也是一个基于散列的Map,但它使用了一种完全不同的加锁策略来提供更高的并发性和伸缩性:分段锁。
-
在这种机制中,任意数量的读取线程可以并发地访问Map,执行读取操作的线程和执行写入操作的线程可以并发地访问Map,并且一定数量的写入线程可以并发地修改Map
-
ConcurrentHashMap与其他并发容器一起增强了同步容器类:它们提供的迭代器不会抛出ConcurrentModificationException,因此不需要在迭代过程中对容器加锁
-
ConcurrentHashMap返回的迭代器具有弱一致性(Weakly Consistent),而并非“及时失败”。弱一致性的迭代器可以容忍并发的修改,当创建迭代器时会遍历已有的元素,并可以(但是不保证)在迭代器被构造后将修改操作反映给容器。
-
对于一些需要在整个Map上进行计算的方法,例如size和isEmpty,这些方法的语义被略微减弱了以反映容器的并发特性。
-
额外的Map操作:比较插入、比较删除、比较替代
public interface ConcurrentMap<K, V>extends Map<K, V>{ //仅当K没有相应的映射值时才插入V putIfAbsent(K key, V value); //仅当K被映射到V时才移除 boolean remove(K key, V value); //仅当K被映射到oldValue时才替换为newValue boolean replace(K key, V oldValue, V newValue); //仅当K被映射到某个值时才替换为newValueV replace(K key, V newValue); }
-
-
CopyOnWriteArrayList:CopyOnWriteArrayList用于替代同步List,在某些情况下它提供了更好的并发性能,并且在迭代期间不需要对容器进行加锁或复制
- “写入时复制(Copy-On-Write)”容器的线程安全性在于,只要正确地发布一个事实不可变的对象,那么在访问该对象时就不再需要进一步的同步。
- 在每次修改时,都会创建并重新发布一个新的容器副本,从而实现可变性。
- “写入时复制”容器的迭代器保留一个指向底层基础数组的引用,这个数组当前位于迭代器的起始位置,由于它不会被修改,因此在对其进行同步时只需确保数组内容的可见性。
- 显然,每当修改容器时都会复制底层数组,这需要一定的开销,特别是当容器的规模较大时。仅当迭代操作远远多于修改操作时,才应该使用“写入时复制”容器。
5.3 阻塞队列与生产者-消费者模式
-
阻塞队列提供了可阻塞的put和take方法,以及支持定时的offer和poll方法(不阻塞,返回结果用于资源管理);
-
如果队列已经满了,那么put方法将阻塞直到有空间可用;如果队列为空,那么take方法将会阻塞直到有元素可用.
-
队列可以是有界的也可以是无界的,无界队列永远都不会充满,因此无界队列上的put方法也永远不会阻塞。
-
阻塞队列支持生产者-消费者这种设计模式。
-
在构建高可靠的应用程序时,有界队列是一种强大的资源管理工具:它们能抑制并防止产生过多的工作项,使应用程序在负荷过载的情况下变得更加健壮。
-
如果阻塞队列并不完全符合设计需求,那么还可以通过**信号量(Semaphore)**来创建其他的阻塞数据结构(请参见5.5.3节)。
-
阻塞队列具体实现
- LinkedBlockingQueue
- ArrayBlockingQueue
- PriorityBlockingQueue
- SynchronousQueue:维护一组线程
-
示例1:桌面搜索
-
生产者:将符合条件的文件名称放入队列;消费者:为符合条件的文件建立索引
-
生产者代码示例
public class FileCrawler implements Runnable{ private final BlockingQueue<File>fileQueue; private final FileFilter fileFilter; private final File root; …… public void run() { try{ crawl(root); }catch(InterruptedException e){ Thread.currentThread().interrupt(); } } //生产者:将符合条件的文件名称放入阻塞队列 private void crawl(File root)throws InterruptedException{ File[]entries=root.listFiles(fileFilter); if(entries!=null){ for(File entry:entries) if(entry.isDirectory()) crawl(entry); else if(!alreadyIndexed(entry)) fileQueue.put(entry); } } } -
消费者代码示例
public class Indexer implements Runnable{ private final BlockingQueue<File>queue; public Indexer(BlockingQueue<File>queue){ this.queue=queue; } public void run(){ try{ while(true) indexFile(queue.take()); }catch(InterruptedException e){ Thread.currentThread().interrupt(); } } } -
生产者-消费者模式提供了一种适合线程的方法将桌面搜索问题分解为更简单的组件。将文件遍历与建立索引等功能分解为独立的操作,比将所有功能都放到一个操作中实现有着更高的代码可读性和可重用性:每个操作只需完成一个任务,并且阻塞队列将负责所有的控制流,因此每个功能的代码都更加简单和清晰。
-
-
串行线程封闭
- 线程封闭对象只能由单个线程拥有,但可以通过安全地发布该对象来“转移”所有权;在转移所有权后,也只有另一个线程能获得这个对象的访问权限,并且发布对象的线程不会再访问它;这种安全的发布确保了对象状态对于新的所有者来说是可见的,并且由于最初的所有者不会再访问它,因此对象将被封闭在新的线程中。新的所有者线程可以对该对象做任意修改,因为它具有独占的访问权。
- 对于可变对象,生产者-消费者这种设计与阻塞队列一起,促进了串行线程封闭,从而将对象所有权从生产者交付给消费者。
- 我们也可以使用其他发布机制来传递可变对象的所有权,但必须确保只有一个线程能接受被转移的对象;而且原线程转移对象所有权后不对对象进行操作(比如通过线程池机制就可以安全的转移对象所有权)
-
双端队列与工作密取
- Java 6增加了两种容器类型,Deque(发音为“deck”)和BlockingDeque,它们分别对Queue和BlockingQueue进行了扩展。
- Deque是一个双端队列,实现了在队列头和队列尾的高效插入和移除。具体实现包括ArrayDeque和LinkedBlockingDeque。
- 正如阻塞队列适用于生产者-消费者模式,双端队列同样适用于另一种相关模式,即工作密取(Work Stealing)
- 在生产者-消费者设计中,所有消费者有一个共享的工作队列,而在工作密取设计中,每个消费者都有各自的双端队列。如果一个消费者完成了自己双端队列中的全部工作,那么它可以从其他消费者双端队列末尾秘密地获取工作。
- 密取工作模式比传统的生产者-消费者模式具有更高的可伸缩性,这是因为工作者线程不会在单个共享的任务队列上发生竞争。在大多数时候,它们都只是访问自己的双端队列,从而极大地减少了竞争。当工作者线程需要访问另一个队列时,它会从队列的尾部而不是从头部获取工作,因此进一步降低了队列上的竞争程度。
- 工作密取非常适用于既是消费者也是生产者问题——当执行某个工作时可能导致出现更多的工作。例如,在网页爬虫程序中处理一个页面时,通常会发现有更多的页面需要处理。类似的还有许多搜索图的算法,例如在垃圾回收阶段对堆进行标记,都可以通过工作密取机制来实现高效并行
- 当双端队列为空时,它会在另一个线程的队列队尾查找新的任务,从而确保每个线程都保持忙碌状态。
5.4 阻塞方法和中断方法
-
当某方法抛出Interrupted-Exception时,表示该方法是一个阻塞方法,如果这个方法被中断,那么它将努力提前结束阻塞状态。
-
Thread提供了interrupt方法,用于中断线程或者查询线程是否已经被中断。每个线程都有一个布尔类型的属性,表示线程的中断状态,当中断线程时将设置这个状态。
-
中断是一种协作机制。一个线程不能强制其他线程停止正在执行的操作而去执行其他的操作。当线程A中断B时,A仅仅是要求B在执行到某个可以暂停的地方停止正在执行的操作——前提是如果线程B愿意停止下来。
-
当在代码中调用了一个将抛出InterruptedException异常的方法时,你自己的方法也就变成了一个阻塞方法,并且必须要处理对中断的响应
-
传递InterruptedException。避开这个异常通常是最明智的策略——只需把InterruptedException传递给方法的调用者。传递InterruptedException的方法包括,根本不捕获该异常,或者捕获该异常,然后在执行某种简单的清理工作后再次抛出这个异常。
-
恢复中断。有时候不能抛出InterruptedException,例如当代码是Runnable的一部分时。在这些情况下,必须捕获InterruptedException,并通过调用当前线程上的interrupt方法恢复中断状态,这样在调用栈中更高层的代码将看到引发了一个中断,恢复中断状态以避免屏蔽中断
public class TaskRunnable implements Runnable{ BlockingQueue<Task>queue; …… public void run(){ try{ processTask(queue.take());} catch(InterruptedException e){ //恢复被中断的状态 Thread.currentThread().interrupt(); } } }
-
-
在出现InterruptedException时不应该做的事情是,捕获它但不做出任何响应。只有在一种特殊的情况中才能屏蔽中断,即对Thread进行扩展,并且能控制调用栈上所有更高层的代码。
5.5 同步工具类
- 在容器类中,阻塞队列是一种独特的类:它们不仅能作为保存对象的容器,还能协调生产者和消费者等线程之间的控制流。
- 同步工具类可以是任何一个对象,只要它根据其自身的状态来协调线程的控制流。阻塞队列可以作为同步工具类,其他类型的同步工具类还包括信号量(Semaphore)、栅栏(Barrier)以及闭锁(Latch)。
- 所有的同步工具类都包含一些特定的结构化属性:它们封装了一些状态,这些状态将决定执行同步工具类的线程是继续执行还是等待,此外还提供了一些方法对状态进行操作,以及另一些方法用于高效地等待同步工具类进入到预期状态。
5.5.1 闭锁
-
闭锁是一种同步工具类,可以延迟线程的进度直到其到达终止状态。闭锁可以用来确保某些活动直到其他活动都完成后才继续执行。
-
闭锁的作用相当于一扇门:在闭锁到达结束状态之前,这扇门一直是关闭的,并且没有任何线程能通过,当到达结束状态时,这扇门会打开并允许所有的线程通过。当闭锁到达结束状态后,将不会再改变状态,因此这扇门将永远保持打开状态。
-
适用场景
- 确保某个计算在其需要的所有资源都被初始化之后才继续执行。二元闭锁(包括两个状态)可以用来表示“资源R已经被初始化”,而所有需要R的操作都必须先在这个闭锁上等待
- 确保某个服务在其依赖的所有其他服务都已经启动之后才启动。每个服务都有一个相关的二元闭锁。当启动服务S时,将首先在S依赖的其他服务的闭锁上等待,在所有依赖的服务都启动后会释放闭锁S,这样其他依赖S的服务才能继续执行
- 等待直到某个操作的所有参与者(例如,在多玩家游戏中的所有玩家)都就绪再继续执行。在这种情况中,当所有玩家都准备就绪时,闭锁将到达结束状态。
-
CountDownLatch是一种灵活的闭锁实现,可以在上述各种情况中使用,它可以使一个或多个线程等待一组事件发生。
-
闭锁状态包括一个计数器,该计数器被初始化为一个正数,表示需要等待的事件数量;
-
countDown方法递减计数器,表示有一个事件已经发生了,而await方法等待计数器达到零,这表示所有需要等待的事件都已经发生。如果计数器的值非零,那么await会一直阻塞直到计数器为零,或者等待中的线程中断,或者等待超时。
-
利用闭锁并发执行任务和等待最后一个线程完成任务后操作示例:
public class TestHarness{ public long timeTasks(int nThreads, final Runnable task)throws InterruptedException{ //闭锁开始门,初始化为1 final CountDownLatch startGate=new CountDownLatch(1); //闭锁结束门,初始化为线程数量 final CountDownLatch endGate=new CountDownLatch(nThreads); for(int i=0;i<nThreads;i++){ Thread t=new Thread(){ public void run(){ try{ //线程等待初始门为0,也就是所有线程准备就绪(初始化) startGate.await(); try{ //线程任务 task.run(); }finally{ //线程任务执行完毕的时候,将结束门递减 endGate.countDown(); } }catch(InterruptedException ignored){ } } }; //启动线程 t.start(); } long start=System.nanoTime(); //所有线程都准备完毕,将开始门递减,让所有线程结束等待状态,开始并发执行任务 startGate.countDown(); //结束门等待所有线程全部执行任务结束(即最后一个线程将结束门递减到0) endGate.await(); long end=System.nanoTime(); //记录执行时间 return end-start; } }- 为什么要在TestHarness中使用闭锁,而不是在线程创建后就立即启动?或许,我们希望测试n个线程并发执行某个任务时需要的时间。如果在创建线程后立即启动它们,那么先启动的线程将“领先”后启动的线程,并且活跃线程数量会随着时间的推移而增加或减少,竞争程度也在不断发生变化。
- 启动门将使得主线程能够同时释放所有工作线程,而结束门则使主线程能够等待最后一个线程执行完成,而不是顺序地等待每个线程执行完成。
-
5.5.2 FutureTask
-
FutureTask也可以用做闭锁。(FutureTask实现了Future语义,表示一种抽象的可生成结果的计算;
-
FutureTask表示的计算是通过Callable来实现的,相当于一种可生成结果的Runnable,并且可以处于以下3种状态:等待运行(Waiting to run),正在运行(Running)和运行完成(Completed).
-
“执行完成”表示计算的所有可能结束方式,包括正常结束、由于取消而结束和由于异常而结束等。当FutureTask进入完成状态后,它会永远停止在这个状态上。
-
Future.get的行为取决于任务的状态。如果任务已经完成,那么get会立即返回结果,否则get将阻塞直到任务进入完成状态,然后返回结果或者抛出异常。
-
FutureTask将计算结果从执行计算的线程传递到获取这个结果的线程,而FutureTask的规范确保了这种传递过程能实现结果的安全发布。
-
FutureTask在Executor框架中表示异步任务,此外还可以用来表示一些时间较长的计算,这些计算可以在使用计算结果之前启动.通过提前启动计算,可以减少在等待结果时需要的时间。示例如下:
public class Preloader{ //future 相当于一个中继,对上承接另一个线程的结果,对下传递这另一个线程的执行任务 private final FutureTask<ProductInfo> future=new FutureTask<ProductInfo>(new Callable<ProductInfo>(){ public ProductInfo call()throws DataLoadException{ return loadProductInfo(); } }); private final Thread thread=new Thread(future); public void start(){ thread.start(); } public ProductInfo get()throws DataLoadException, InterruptedException{ try{ return future.get(); }catch(ExecutionException e){ Throwable cause=e.getCause(); if(cause instanceof DataLoadException) throw(DataLoadException)cause; else throw launderThrowable(cause); } } }- 由于在构造函数或静态初始化方法中启动线程并不是一种好方法,因此提供了一个start方法来启动线程。当程序随后需要ProductInfo时,可以调用get方法,如果数据已经加载,那么将返回这些数据,否则将等待加载完成后再返回。
- Callable表示的任务可以抛出受检查的或未受检查的异常,并且任何代码都可能抛出一个Error。无论任务代码抛出什么异常,都会被封装到一个ExecutionException中,并在Future.get中被重新抛出。
5.5.3 信号量
-
计数信号量(Counting Semaphore)用来控制同时访问某个特定资源的操作数量,或者同时执行某个指定操作的数量。计数信号量还可以用来实现某种资源池,或者对容器施加边界。
-
Semaphore中管理着一组虚拟的许可(permit),许可的初始数量可通过构造函数来指定。在执行操作时可以首先获得许可(只要还有剩余的许可),并在使用以后释放许可。
-
如果没有许可,那么acquire将阻塞直到有许可(或者直到被中断或者操作超时)。release方法将返回一个许可给信号量。
-
Semaphore可以用于实现资源池,例如数据库连接池。我们可以构造一个固定长度的资源池,当池为空时,请求资源将会失败,但你真正希望看到的行为是阻塞而不是失败,并且当池非空时解除阻塞。如果将Semaphore的计数值初始化为池的大小,并在从池中获取一个资源之前首先调用acquire方法获取一个许可,在将资源返回给池之后调用release释放许可,那么acquire将一直阻塞直到资源池不为空。
-
同样,你也可以使用Semaphore将任何一种容器变成有界阻塞容器,如示例:
public class BoundedHashSet<T>{ private final Set<T>set; private final Semaphore sem; public BoundedHashSet(int bound){ this.set=Collections.synchronizedSet(new HashSet<T>()); sem=new Semaphore(bound); } public boolean add(T o)throws InterruptedException{ sem.acquire(); boolean wasAdded=false; try{ wasAdded=set.add(o); return wasAdded; }finally{ if(!wasAdded) sem.release(); } } public boolean remove(Object o){ boolean wasRemoved=set.remove(o); if(wasRemoved) sem.release(); return wasRemoved; } }- 信号量的计数值会初始化为容器容量的最大值。add操作在向底层容器中添加一个元素之前,首先要获取一个许可。如果add操作没有添加任何元素,那么会立刻释放许可;
- 同样,remove操作释放一个许可,使更多的元素能够添加到容器中。
- 底层的Set实现并不知道关于边界的任何信息,这是由BoundedHashSet来处理的。
- [1]在这种实现中不包含真正的许可对象,并且Semaphore也不会将许可与线程关联起来,因此在一个线程中获得的许可可以在另一个线程中释放可以将acquire操作视为是消费一个许可,而release操作是创建一个许可,Semaphore并不受限于它在创建时的初始许可数量。
5.5.4 栅栏
-
我们已经看到通过闭锁来启动一组相关的操作,或者等待一组相关的操作结束。闭锁是一次性对象,一旦进入终止状态,就不能被重置;
-
栅栏(Barrier)类似于闭锁,它能阻塞一组线程直到某个事件发生[CPJ 4,4.3]。栅栏与闭锁的关键区别在于,所有线程必须同时到达栅栏位置,才能继续执行。闭锁用于等待事件,而栅栏用于等待其他线程。
-
栅栏用于实现一些协议,例如几个家庭决定在某个地方集合:“所有人6:00在麦当劳碰头,到了以后要等其他人,之后再讨论下一步要做的事情。”
-
CyclicBarrier可以使一定数量的参与方反复地在栅栏位置汇集,它在并行迭代算法中非常有用:这种算法通常将一个问题拆分成一系列相互独立的子问题。当线程到达栅栏位置时将调用await方法,这个方法将阻塞直到所有线程都到达栅栏位置。如果所有线程都到达了栅栏位置,那么栅栏将打开,此时所有线程都被释放,而栅栏将被重置以便下次使用。如果对await的调用超时,或者await阻塞的线程被中断,那么栅栏就被认为是打破了,所有阻塞的await调用都将终止并抛出BrokenBarrierException。
-
如果成功地通过栅栏,那么await将为每个线程返回一个唯一的到达索引号,我们可以利用这些索引来“选举”产生一个领导线程,并在下一次迭代中由该领导线程执行一些特殊的工作。
-
CyclicBarrier还可以使你将一个栅栏操作传递给构造函数,这是一个Runnable,当成功通过栅栏时会(在一个子任务线程中)执行它,但在阻塞线程被释放之前是不能执行的。
-
在模拟程序中通常需要使用栅栏,例如某个步骤中的计算可以并行执行,但必须等到该步骤中的所有计算都执行完毕才能进入下一个步骤。
-
在程序清单5-15的CellularAutomata中给出了如何通过栅栏来计算细胞的自动化模拟,例如Conway的生命游戏(Gardner,1970)
public class CellularAutomata{ private final Board mainBoard; private final CyclicBarrier barrier; private final Worker[]workers; public CellularAutomata(Board board){ this.mainBoard=board; //获得得用线程数 int count=Runtime.getRuntime().availableProcessors(); this.barrier=new CyclicBarrier(count,new Runnable(){ //汇总值 public void run(){ mainBoard.commitNewValues(); } }); this.workers=new Worker[count]; for(int i=0;i<count;i++) //将大问题分解成小问题并行解决 workers[i]=new Worker(mainBoard.getSubBoard(count, i)); } private class Worker implements Runnable{ private final Board board; public Worker(Board board){ this.board=board; } public void run(){ while(!board.hasConverged()){ for(int x=0;x<board.getMaxX();x++) for(int y=0;y<board.getMaxY();y++) board.setNewValue(x, y,computeValue(x, y)); try{ barrier.await(); }catch(InterruptedException ex){ return; }catch(BrokenBarrierException ex){ return; } } } } public void start(){ for(int i=0;i<workers.length;i++) new Thread(workers[i]).start(); mainBoard.waitForConvergence(); } }- 合理的做法是,将问题分解成一定数量的子问题,为每个子问题分配一个线程来进行求解,之后再将所有的结果合并起来。CellularAutomata将问题分解为Ncpu个子问题,其中Ncpu等于可用CPU的数量,并将每个子问题分配给一个线程。[插图]在每个步骤中,工作线程都为各自子问题中的所有细胞计算新值。当所有工作线程都到达栅栏时,栅栏会把这些新值提交给数据模型。在栅栏的操作执行完以后,工作线程将开始下一步的计算,包括调用isDone方法来判断是否需要进行下一次迭代。
-
另一种形式的栅栏是Exchanger,它是一种两方(Two-Party)栅栏,各方在栅栏位置上交换数据[CPJ 3.4.3]。当两方执行不对称的操作时,Exchanger会非常有用,例如当一个线程向缓冲区写入数据,而另一个线程从缓冲区中读取数据。这些线程可以使用Exchanger来汇合,并将满的缓冲区与空的缓冲区交换。当两个线程通过Exchanger交换对象时,这种交换就把这两个对象安全地发布给另一方。
5.6 构建高效且可伸缩的结果缓存
-
使用HashMap和同步机制来初始化缓存
public interface Computable<A, V>{ V compute(A arg)throws InterruptedException; } public class ExpensiveFunctionimplements Computable<String, BigInteger>{ public BigInteger compute(String arg){ //在经过长时间的计算后 return new BigInteger(arg); } } //第一次尝试 public class Memoizer1<A, V>implements Computable<A, V>{ //用HashMap当做缓存器 @GuardedBy("this")private final Map<A, V>cache=new HashMap<A, V>(); private final Computable<A, V>c; public Memoizer1(Computable<A, V>c){ this.c=c; } //悲观加同步锁 public synchronized V compute(A arg)throws InterruptedException{ //从缓存获取 V result=cache.get(arg); if(result==null){ result=c.compute(arg); cache.put(arg, result); } return result; } }-
Memoizer1使用HashMap来保存之前计算的结果。compute方法将首先检查需要的结果是否已经在缓存中,如果存在则返回之前计算的值。否则,将把计算结果缓存在HashMap中,然后再返回。
-
HashMap不是线程安全的,因此要确保两个线程不会同时访问HashMap,Memoizer1采用了一种保守的方法,即对整个compute方法进行同步。这种方法能确保线程安全性,但会带来一个明显的可伸缩性问题:每次只有一个线程能够执行compute。如果另一个线程正在计算结果,那么其他调用compute的线程可能被阻塞很长时间。如果有多个线程在排队等待还未计算出的结果,那么compute方法的计算时间可能比没有“记忆”操作的计算时间更长。在图5-2中给出了当多个线程使用这种方法中的“记忆”操作时发生的情况。不被推荐

-
-
优化:使用ConcurrentHashMap替代HashMap
public class Memoizer2<A, V>implements Computable<A, V>{ private final Map<A, V>cache=new ConcurrentHashMap<A, V>(); private final Computable<A, V>c; public Memoizer2(Computable<A, V>c){ this.c=c; } public V compute(A arg)throws InterruptedException{ //存在典型的“比较-更新”问题 V result=cache.get(arg); if(result==null){ result=c.compute(arg); cache.put(arg, result); } return result; } }- Memoizer2比Memoizerl有着更好的并发行为:多线程可以并发地使用它;
- 但它在作为缓存时仍然存在一些不足——当两个线程同时调用compute时存在一个漏洞,可能会导致计算得到相同的值。在使用memoization的情况下,这只会带来低效,因为缓存的作用是避免相同的数据被计算多次。但对于更通用的缓存机制来说,这种情况将更为糟糕。对于只提供单次初始化的对象缓存来说,这个漏洞就会带来安全风险。
- Memoizer2的问题在于,如果某个线程启动了一个开销很大的计算,而其他线程并不知道这个计算正在进行,那么很可能会重复这个计算。
- 我们希望通过某种方法来表达“线程X正在计算f(27)”这种情况,这样当另一个线程查找f(27)时,它能够知道最高效的方法是等待线程X计算结束,然后再去查询缓存“f(27)的结果是多少?
-
进一步优化:基于FutureTask的Memoizing封装器
public class Memoizer3<A, V>implements Computable<A, V>{ //用FutureTask异步代替V private final Map<A, Future<V>>cache=new ConcurrentHashMap<A, Future<V>>(); private final Computable<A, V>c; public Memoizer3(Computable<A, V>c){ this.c=c; } public V compute(final A arg)throws InterruptedException{ //新线程进来,get会发现另一线程正在计算,导致阻塞等待计算完毕 //同时有新问题,如果两个线程进来,同时发现没有另一个线程在计算,两个线程并发执行,只不过比上一次并发的颗粒度更小而已 Future<V>f=cache.get(arg); //如果没找到,并发压入缓存 if(f==null){ Callable<V>eval=new Callable<V>(){ public V call()throws InterruptedException{ return c.compute(arg); } }; FutureTask<V>ft=new FutureTask<V>(eval); f=ft; cache.put(arg, ft); ft.run(); //在这里将调用c.compute } try{ return f.get(); }catch(ExecutionException e){ throw launderThrowable(e.getCause()); } } }-
Memoizer3将用于缓存值的Map重新定义为ConcurrentHashMap<A, Future<V>>,替换原来的ConcurrentHashMap<A, V>。Memoizer3首先检查某个相应的计算是否已经开始(Memoizer2与之相反,它首先判断某个计算是否已经完成)。如果还没有启动,那么就创建一个FutureTask,并注册到Map中,然后启动计算:如果已经启动,那么等待现有计算的结果。结果可能很快会得到,也可能还在运算过程中,但这对于Future.get的调用者来说是透明的。
-
Memoizer3的实现几乎是完美的:它表现出了非常好的并发性(基本上是源于ConcurrentHashMap高效的并发性),若结果已经计算出来,那么将立即返回。如果其他线程正在计算该结果,那么新到的线程将一直等待这个结果被计算出来。
-
它只有一个缺陷,即仍然存在两个线程计算出相同值的漏洞。这个漏洞的发生概率要远小于Memoizer2中发生的概率,但由于compute方法中的if代码块仍然是非原子(nonatomic)的“先检查再执行”操作,因此两个线程仍有可能在同一时间内调用compute来计算相同的值,即二者都没有在缓存中找到期望的值,因此都开始计算。这个错误的执行时序如图5-4所示。
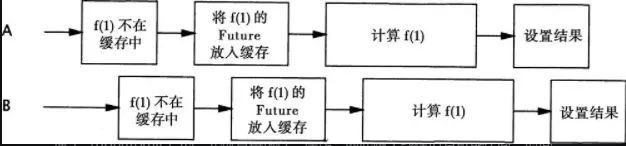
-
-
进一步优化:Memoizer3中存在这个问题的原因是,复合操作(“若没有则添加”)是在底层的Map对象上执行的,而这个对象无法通过加锁来确保原子性。程序清单5-19中的Memoizer使用了ConcurrentMap中的原子方法putIfAbsent,避免了Memoizer3的漏洞。
public class Memoizer<A, V>implements Computable<A, V>{ private final ConcurrentMap<A, Future<V>>cache=new ConcurrentHashMap<A, Future<V>>(); private final Computable<A, V>c; public Memoizer(Computable<A, V>c){ this.c=c; } public V compute(final A arg)throws InterruptedException{ while(true){ Future<V>f=cache.get(arg); if(f==null){ Callable<V>eval=new Callable<V>(){ public V call()throws InterruptedException{ return c.compute(arg); } }; FutureTask<V>ft=new FutureTask<V>(eval); //如果不存在就添加这一步将currentMap上锁 f=cache.putIfAbsent(arg, ft); //返回null表示放入成功,放入成功启动任务 if(f==null){ f=ft; ft.run(); } } try{ return f.get(); }catch(CancellationException e){ cache.remove(arg, f); }catch(ExecutionException e){ throw launderThrowable(e.getCause()); } } } } -
当缓存的是Future而不是值时,将导致缓存污染(Cache Pollution)问题:如果某个计算被取消或者失败,那么在计算这个结果时将指明计算过程被取消或者失败。为了避免这种情况,如果Memoizer发现计算被取消,那么将把Future从缓存中移除。如果检测到RuntimeException,那么也会移除Future,这样将来的计算才可能成功。
-
Memoizer同样没有解决缓存逾期的问题,但它可以通过使用FutureTask的子类来解决,在子类中为每个结果指定一个逾期时间,并定期扫描缓存中逾期的元素。(同样,它也没有解决缓存清理的问题,即移除旧的计算结果以便为新的计算结果腾出空间,从而使缓存不会消耗过多的内存。)
第一部分小结
- 可变状态是至关重要的:所有的并发问题都可以归结为如何协调对并发状态的访问。可变状态越少,就越容易确保线程安全性。
- 尽量将域声明为final类型,除非需要它们是可变的。
- 不可变对象一定是线程安全的:不可变对象能极大地降低并发编程的复杂性。它们更为简单而且安全,可以任意共享而无须使用加锁或保护性复制等机制。
- 封装有助于管理复杂性:在编写线程安全的程序时,虽然可以将所有数据都保存在全局变量中,但为什么要这样做?将数据封装在对象中,更易于维持不变性条件:将同步机制封装在对象中,更易于遵循同步策略。
- 用锁来保护每个可变变量。
- 当保护同一个不变性条件中的所有变量时,要使用同一个锁。
- 在执行复合操作期间,要持有锁。
- 如果从多个线程中访问同一个可变变量时没有同步机制,那么程序会出现问题。
- 不要故作聪明地推断出不需要使用同步。
- 在设计过程中考虑线程安全,或者在文档中明确地指出它不是线程安全的。
- 将同步策略文档化。
第二部分 结构化并发应用程序
第6章 任务执行
大多数并发应用程序都是围绕“任务执行(Task Execution)”来构造的:任务通常是一些抽象的且离散的工作单元。通过把应用程序的工作分解到多个任务中,可以简化程序的组织结构,提供一种自然的事务边界来优化错误恢复过程,以及提供一种自然的并行工作结构来提升并发性。
6.1 在线程中执行任务
- 当围绕“任务执行”来设计应用程序结构时,第一步就是要找出清晰的任务边界。
- 在理想情况下,各个任务之间是相互独立的:任务并不依赖于其他任务的状态、结果或边界效应。独立性有助于实现并发,因为如果存在足够多的处理资源,那么这些独立的任务都可以并行执行。
- 为了在调度与负载均衡等过程中实现更高的灵活性,每项任务还应该表示应用程序的一小部分处理能力。
- 应用程序提供商希望程序支持尽可能多的用户,从而降低每个用户的服务成本,而用户则希望获得尽快的响应。而且,当负荷过载时,应用程序的性能应该是逐渐降低,而不是直接失败。要实现上述目标,应该选择清晰的任务边界以及明确的任务执行策略。
- 大多数服务器应用程序都提供了一种自然的任务边界选择方式:以独立的客户请求为边界。Web服务器、邮件服务器、文件服务器、EJB容器以及数据库服务器等,这些服务器都能通过网络接受远程客户的连接请求。将独立的请求作为任务边界,既可以实现任务的独立性,又可以实现合理的任务规模。
6.1.1 串行地执行任务
-
最简单的策略就是在单个线程中串行地执行各项任务。
-
串行的Web服务器例子:
class SingleThreadWebServer{ public static void main(String[]args)throws IOException{ ServerSocket socket=new ServerSocket(80); while(true){ Socket connection=socket.accept(); handleRequest(connection); } } }-
SingleThreadWebServer很简单,且在理论上是正确的,但在实际生产环境中的执行性能却很糟糕,因为它每次只能处理一个请求.
-
主线程在接受连接与处理相关请求等操作之间不断地交替运行。当服务器正在处理请求时,新到来的连接必须等待直到请求处理完成,然后服务器将再次调用accept。
-
-
在单线程的服务器中,阻塞不仅会推迟当前请求的完成时间,而且还将彻底阻止等待中的请求被处理。如果请求阻塞的时间过长,用户将认为服务器是不可用的,因为服务器看似失去了响应。
-
同时,服务器的资源利用率非常低,因为当单线程在等待I/O操作完成时,CPU将处于空闲状态。
6.1.2 显示地为任务创建线程
-
通过为每个请求创建一个新的线程来提供服务,从而实现更高的响应性(不要这么做),如下所示:
class ThreadPerTaskWebServer{ public static void main(String[]args)throws IOException{ ServerSocket socket=new ServerSocket(80); while(true){ fnal Socket connection=socket.accept(); Runnable task=new Runnable(){ public void run(){ handleRequest(connection); } }; new Thread(task).start(); } } }- ThreadPerTaskWebServer在结构上类似于前面的单线程版本——主线程仍然不断地交替执行“接受外部连接”与“分发请求”等操作。区别在于,对于每个连接,主循环都将创建一个新线程来处理请求,而不是在主循环中进行处理。
-
比较串行与并行的三个结论
- 任务处理过程从主线程中分离出来,使得主循环能够更快地重新等待下一个到来的连接。这使得程序在完成前面的请求之前可以接受新的请求,从而提高响应性。(接受与处理分离);
- 任务可以并行处理,从而能同时服务多个请求。如果有多个处理器,或者任务由于某种原因被阻塞,例如等待I/O完成、获取锁或者资源可用性等,程序的吞吐量将得到提高。
- 任务处理代码必须是线程安全的,因为当有多个任务时会并发地调用这段代码。
-
在正常负载情况下,“为每个任务分配一个线程”的方法能提升串行执行的性能。只要请求的到达速率不超出服务器的请求处理能力,那么这种方法可以同时带来更快的响应性和更高的吞吐率。
6.1.3 无限制创造线程的不足
- 线程生命周期的开销非常高:
- 线程的创建与销毁并不是没有代价的。根据平台的不同,实际的开销也有所不同,但线程的创建过程都会需要时间,延迟处理的请求,并且需要JVM和操作系统提供一些辅助操作。
- 资源消耗:
- 活跃的线程会消耗系统资源,尤其是内存。
- 如果可运行的线程数量多于可用处理器的数量,那么有些线程将闲置。
- 大量空闲的线程会占用许多内存,给垃圾回收器带来压力,而且大量线程在竞争CPU资源时还将产生其他的性能开销。
- 稳定性:
- 在可创建线程的数量上存在一个限制。这个限制值将随着平台的不同而不同,并且受多个因素制约,包括JVM的启动参数、Thread构造函数中请求的栈大小,以及底层操作系统对线程的限制等[插图]。如果破坏了这些限制,那么很可能抛出OutOfMemoryError异常,要想从这种错误中恢复过来是非常危险的,更简单的办法是通过构造程序来避免超出这些限制。
- 在一定的范围内,增加线程可以提高系统的吞吐率,但如果超出了这个范围,再创建更多的线程只会降低程序的执行速度,并且如果过多地创建一个线程,那么整个应用程序将崩溃。
- 与其他的并发危险一样,在原型设计和开发阶段,无限制地创建线程或许还能较好地运行,但在应用程序部署后并处于高负载下运行时,才会有问题不断地暴露出来。因此,某个恶意的用户或者过多的用户,都会使Web服务器的负载达到某个阈值,从而使服务器崩溃。如果服务器需要提供高可用性,并且在高负载情况下能平缓地降低性能,那么这将是一个严重的故障。
6.2 Executor框架
-
线程池简化了线程的管理工作,并且java.util.concurrent提供了一种灵活的线程池实现作为Executor框架的一部分。
-
在Java类库中,任务执行的主要抽象不是Thread,而是Executor,Executor接口如下:
public interface Executor{ void execute(Runnable command); } -
Executor的实现还提供了对生命周期的支持,以及统计信息收集、应用程序管理机制和性能监视等机制。
-
Executor基于生产者-消费者模式,提交任务的操作相当于生产者(生成待完成的工作单元),执行任务的线程则相当于消费者(执行完这些工作单元)
6.2.1 示例:基于Executor的Web服务器
class TaskExecutionWebServer{
private static final int NTHREADS=100;
private static fnal Executor exec=Executors.newFixedThreadPool(NTHREADS);
public static void main(String[]args)throws IOException{
ServerSocket socket=new ServerSocket(80);
while(true){
final Socket connection=socket.accept();
Runnable task=new Runnable(){
public void run(){
handleRequest(connection);
}
};
exec.execute(task);
}
}
}
- 在TaskExecutionWebServer中,通过使用Executor,将请求处理任务的提交与任务的实际执行解耦开来,并且只需采用另一种不同的Executor实现,就可以改变服务器的行为;
- 改变Executor实现或配置所带来的影响要远远小于改变任务提交方式带来的影响.
- 通常,Executor的配置是一次性的,因此在部署阶段可以完成,而提交任务的代码却会不断地扩散到整个程序中,增加了修改的难度。
6.2.2 执行策略
- 通过将任务的提交与执行解耦开来,从而无须太大的困难就可以为某种类型的任务指定和修改执行策略。
- 在执行策略中定义了任务执行的“What、Where、When、How”等方面,包括:
- 在什么(What)线程中执行任务;
- 任务按照什么(What)顺序执行(FIFO、LIFO、优先级)?
- 有多少个(How Many)任务能并发执行?
- 在队列中有多少个(How Many)任务在等待执行?
- 如果系统由于过载而需要拒绝一个任务,那么应该选择哪一个(Which)任务?另外,如何(How)通知应用程序有任务被拒绝?
- 在执行一个任务之前或之后,应该进行哪些(What)动作?
- 各种执行策略都是一种资源管理工具,最佳策略取决于可用的计算资源以及对服务质量的需求。
- 通过限制并发任务的数量,可以确保应用程序不会由于资源耗尽而失败,或者由于在稀缺资源上发生竞争而严重影响性能。
- 通过将任务的提交与任务的执行策略分离开来,有助于在部署阶段选择与可用硬件资源最匹配的执行策略。
- 每当看到下面这种形式的代码时:new Thread(runnable).start()并且你希望获得一种更灵活的执行策略时,请考虑使用Executor来代替Thread。
6.2.3 线程池
- “在线程池中执行任务”比“为每个任务分配一个线程”优势更多:
- 通过重用现有的线程而不是创建新线程,可以在处理多个请求时分摊在线程创建和销毁过程中产生的巨大开销。
- 当请求到达时,工作线程通常已经存在,因此不会由于等待创建线程而延迟任务的执行,从而提高了响应性。
- 通过适当调整线程池的大小,可以创建足够多的线程以便使处理器保持忙碌状态,同时还可以防止过多线程相互竞争资源而使应用程序耗尽内存或失败。
- 类库提供了一个灵活的线程池以及一些有用的默认配置。可以通过调用Executors中的静态工厂方法之一来创建一个线程池:
- newFixedThreadPool:newFixedThreadPool将创建一个固定长度的线程池,每当提交一个任务时就创建一个线程,直到达到线程池的最大数量,这时线程池的规模将不再变化(如果某个线程由于发生了未预期的Exception而结束,那么线程池会补充一个新的线程)。
- newCachedThreadPool:newCachedThreadPool将创建一个可缓存的线程池,如果线程池的当前规模超过了处理需求时,那么将回收空闲的线程,而当需求增加时,则可以添加新的线程,线程池的规模不存在任何限制。
- newSingleThreadExecutor。newSingleThreadExecutor是一个单线程的Executor,它创建单个工作者线程来执行任务,如果这个线程异常结束,会创建另一个线程来替代。newSingleThreadExecutor能确保依照任务在队列中的顺序来串行执行(例如FIFO、LIFO、优先级)。
- newScheduledThreadPool:newScheduledThreadPool创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
- 建数千个线程来争夺有限的CPU和内存资源,因此服务器的性能将平缓地降低。通过使用Executor,可以实现各种调优、管理、监视、记录日志、错误报告和其他功能,如果不使用任务执行框架,那么要增加这些功能是非常困难的。
6.2.4 Executor的生命周期
-
JVM只有在所有(非守护)线程全部终止后才会退出。因此,如果无法正确地关闭Executor,那么JVM将无法结束。
-
由于Executor以异步方式来执行任务,因此在任何时刻,之前提交任务的状态不是立即可见的。有些任务可能已经完成,有些可能正在运行,而其他的任务可能在队列中等待执行。
-
当关闭应用程序时,可能采用最平缓的关闭形式(完成所有已经启动的任务,并且不再接受任何新的任务),也可能采用最粗暴的关闭形式(直接关掉机房的电源),以及其他各种可能的形式。
-
既然Executor是为应用程序提供服务的,因而它们也是可关闭的(无论采用平缓的方式还是粗暴的方式),并将在关闭操作中受影响的任务的状态反馈给应用程序。
-
为了解决执行服务的生命周期问题,Executor扩展了ExecutorService接口,添加了一些用于生命周期管理的方法(同时还有一些用于任务提交的便利方法):
//ExecutorService中的生命周期管理方法 public interface ExecutorService extends Executor{ void shutdown(); List<Runnable>shutdownNow(); boolean isShutdown(); boolean isTerminated(); boolean awaitTermination(long timeout, TimeUnit unit)throws InterruptedException; //……其他用于任务提交的便利方法 } -
ExecutorService的生命周期有3种状态:运行、关闭和已终止。
-
ExecutorService在初始创建时处于运行状态。shutdown方法将执行平缓的关闭过程:不再接受新的任务,同时等待已经提交的任务执行完成——包括那些还未开始执行的任务。shutdownNow方法将执行粗暴的关闭过程:它将尝试取消所有运行中的任务,并且不再启动队列中尚未开始执行的任务。
-
在ExecutorService关闭后提交的任务将由“拒绝执行处理器(RejectedExecution Handler)”来处理(请参见8.3.3节),它会抛弃任务,或者使得execute方法抛出一个未检查的Rejected-ExecutionException。
-
等所有任务都完成后,ExecutorService将转入终止状态。可以调用awaitTermination来等待ExecutorService到达终止状态,或者通过调用isTerminated来轮询ExecutorService是否已经终止。通常在调用awaitTermination之后会立即调用shutdown,从而产生同步地关闭ExecutorService的效果。
6.2.5 延迟任务与周期任务
- Timer类负责管理延迟任务(“在100ms后执行该任务”)以及周期任务(“每l0ms执行一次该任务”)。
- 然而,Timer存在一些缺陷,因此应该考虑使用ScheduledThreadPoolExecutor来代替它:
- Timer在执行所有定时任务时只会创建一个线程。如果某个任务的执行时间过长,那么将破坏其他TimerTask的定时精确性;
- 如果TimerTask抛出了一个未检查的异常,那么Timer将表现出糟糕的行为。Timer线程并不捕获异常,因此当TimerTask抛出未检查的异常时将终止定时线程。这种情况下,Timer也不会恢复线程的执行,而是会错误地认为整个Timer都被取消了。因此,已经被调度但尚未执行的TimerTask将不会再执行,新的任务也不能被调度。(这个问题称之为“线程泄漏[Thread Leakage]”。
- 如果要构建自己的调度服务,那么可以使用DelayQueue,它实现了BlockingQueue,并为ScheduledThreadPoolExecutor提供调度功能。
- Timer支持基于绝对时间而不是相对时间的调度机制,因此任务的执行对系统时钟变化很敏感,而ScheduledThreadPoolExecutor只支持基于相对时间的调度。
6.3 找出可利用的并行性
6.3.1 示例:串行的页面渲染器
6.3.2 携带结果的任务Callable与Future
-
Executor框架使用Runnable作为其基本的任务表示形式。Runnable是一种有很大局限的抽象,虽然run能写入到日志文件或者将结果放入某个共享的数据结构,但它不能返回一个值或抛出一个受检查的异常。
-
许多任务实际上都是存在延迟的计算——执行数据库查询,从网络上获取资源,或者计算某个复杂的功能。对于这些任务,Callable是一种更好的抽象:它认为主入口点(即call)将返回一个值,并可能抛出一个异常。
-
Executor执行的任务有4个生命周期阶段:创建、提交、开始和完成。由于有些任务可能要执行很长的时间,因此通常希望能够取消这些任务。
-
在Executor框架中,已提交但尚未开始的任务可以取消,但对于那些已经开始执行的任务,只有当它们能响应中断时,才能取消。取消一个已经完成的任务不会有任何影响。
-
Future表示一个任务的生命周期,并提供了相应的方法来判断是否已经完成或取消,以及获取任务的结果和取消任务等。
-
get方法的行为取决于任务的状态(尚未开始、正在运行、已完成)。如果任务已经完成,那么get会立即返回或者抛出一个Exception,如果任务没有完成,那么get将阻塞并直到任务完成。如果任务抛出了异常,那么get将该异常封装为ExecutionException并重新抛出。如果任务被取消,那么get将抛出CancellationException。如果get抛出了ExecutionException,那么可以通过getCause来获得被封装的初始异常。
-
Callable与Future接口
public interface Callable<V>{ V call()throws Exception; } public interface Future<V>{ boolean cancel(boolean mayInterruptIfRunning); boolean isCancelled(); boolean isDone(); V get()throws InterruptedException, ExecutionException,CancellationException; V get(long timeout, TimeUnit unit)throws InterruptedException, ExecutionException,CancellationException, TimeoutException; } -
可以通过许多种方法创建一个Future来描述任务。ExecutorService中的所有submit方法都将返回一个Future,从而将一个Runnable或Callable提交给Executor,并得到一个Future用来获得任务的执行结果或者取消任务。还可以显式地为某个指定的Runnable或Callable实例化一个FutureTask。(由于FutureTask实现了Runnable,因此可以将它提交给Executor来执行,或者直接调用它的run方法。)
-
要使用Callable来表示无返回值的任务,可使用Callable<Void>。
6.3.3 示例:使用Future实现页面渲染器
- 首先将渲染过程分解为两个任务,一个是渲染所有的文本,另一个是下载所有的图像。(因为其中一个任务是CPU密集型,而另一个任务是I/O密集型,因此这种方法即使在单CPU系统上也能提升性能。)
6.3.4 在异构任务并行化中存在的局限
- 在上个示例中,我们尝试并行地执行两个不同类型的任务——下载图像与渲染页面。然而,通过对异构任务进行并行化来获得重大的性能提升是很困难的。
- 当人数增加时,如何确保他们能帮忙而不是妨碍其他人工作,或者在重新分配工作时,并不是容易的事情。如果没有在相似的任务之间找出细粒度的并行性,那么这种方法带来的好处将减少。
- 如果渲染文本的速度远远高于下载图像的速度(可能性很大),那么程序的最终性能与串行执行时的性能差别不大,而代码却变得更复杂了。
- 因此,虽然做了许多工作来并发执行异构任务以提高并发度,但从中获得的并发性却是十分有限的。
- 只有当大量相互独立且同构的任务可以并发进行处理时,才能体现出将程序的工作负载分配到多个任务中带来的真正性能提升。
6.3.5 CompletionService:Executor与BlockingQueue
- 如果向Executor提交了一组计算任务,并且希望在计算完成后获得结果,那么可以保留与每个任务关联的Future,然后反复使用get方法.同时将参数timeout指定为0,从而通过轮询来判断任务是否完成。
- 这种方法虽然可行,但却有些繁琐。幸运的是,还有一种更好的方法:完成服务(CompletionService)。
- CompletionService将Executor和BlockingQueue的功能融合在一起。你可以将Callable任务提交给它来执行,然后使用类似于队列操作的take和poll等方法来获得已完成的结果,而这些结果会在完成时将被封装为Future。
- ExecutorCompletionService实现了CompletionService,并将计算部分委托给一个Executor。
- ExecutorCompletionService的实现非常简单。在构造函数中创建一个BlockingQueue来保存计算完成的结果。当计算完成时,调用Future-Task中的done方法。当提交某个任务时,该任务将首先包装为一个QueueingFuture,这是FutureTask的一个子类,然后再改写子类的done方法,并将结果放入BlockingQueue中。
6.3.6 示例:使用CompletionService实现页面渲染
-
可以通过CompletionService从两个方面来提高页面渲染器的性能:缩短总运行时间以及提高响应性。
-
为每一幅图像的下载都创建一个独立任务,并在线程池中执行它们,从而将串行的下载过程转换为并行的过程:这将减少下载所有图像的总时间。
-
此外,通过从CompletionService中获取结果以及使每张图片在下载完成后立刻显示出来,能使用户获得一个更加动态和更高响应性的用户界面
-
代码示例
public class Renderer{ private final ExecutorService executor; Renderer(ExecutorService executor){ this.executor=executor; } void renderPage(CharSequence source){ //获取文件信息 List<ImageInfo>info=scanForImageInfo(source); CompletionService<ImageData>completionService=new ExecutorCompletionService<ImageData>(executor); for(final ImageInfo imageInfo:info) completionService.submit(new Callable<ImageData>(){ //下载资源任务 public ImageData call(){ return imageInfo.downloadImage(); } }); //所有并行线程准备就绪后提醒 renderText(source); try{ for(int t=0,n=info.size();t<n;t++){ Future<ImageData>f=completionService.take(); //获取结果,如果没下载好会阻塞 ImageData imageData=f.get(); //渲染 renderImage(imageData); } }catch(InterruptedException e){ Thread.currentThread().interrupt(); }catch(ExecutionException e){ throw launderThrowable(e.getCause()); } } }
6.3.7 为任务设定时限
-
有时候,如果某个任务无法在指定时间内完成,那么将不再需要它的结果,此时可以放弃这个任务。类似地,一个门户网站可以从多个数据源并行地获取数据,但可能只会在指定的时间内等待数据,如果超出了等待时间,那么只显示已经获得的数据。
-
在有限时间内执行任务的主要困难在于,要确保得到答案的时间不会超过限定的时间,或者在限定的时间内无法获得答案。在支持时间限制的Future.get中支持这种需求:当结果可用时,它将立即返回,如果在指定时限内没有计算出结果,那么将抛出TimeoutException。
-
在使用限时任务时需要注意,当这些任务超时后应该立即停止,从而避免为继续计算一个不再使用的结果而浪费计算资源。要实现这个功能,可以由任务本身来管理它的限定时间,并且在超时后中止执行或取消任务。此时可再次使用Future,如果一个限时的get方法抛出了TimeoutException,那么可以通过Future来取消任务。如果编写的任务是可取消的(参见第7章),那么可以提前中止它,以免消耗过多的资源。
-
在指定时间内获取广告信息示例
Page renderPageWithAd()throws InterruptedException{ long endNanos=System.nanoTime()+TIME_BUDGET; Future<Ad>f=exec.submit(new FetchAdTask()); //在等待广告的同时显示页面 Page page=renderPageBody(); Ad ad; try{ //只等待指定的时间长度 long timeLeft=endNanos-System.nanoTime(); ad=f.get(timeLeft, NANOSECONDS); }catch(ExecutionException e){ ad=DEFAULT_AD; }catch(TimeoutException e){ ad=DEFAULT_AD; f.cancel(true); } page.setAd(ad); return page; } -
传递给get的timeout参数的计算方法是,将指定时限减去当前时间。这可能会得到负数,但java.util.concurrent中所有与时限相关的方法都将负数视为零,因此不需要额外的代码来处理这种情况。
-
Future.cancel的参数为true表示任务线程可以在运行过程中中断。请参见第7章。
6.3.8 示例:旅行预定门户网站
-
考虑这样一个旅行预定门户网站:用户输入旅行的日期和其他要求,门户网站获取并显示来自多条航线、旅店或汽车租赁公司的报价。在获取不同公司报价的过程中,可能会调用Web服务、访问数据库、执行一个EDI事务或其他机制。在这种情况下,不宜让页面的响应时间受限于最慢的响应时间,而应该只显示在指定时间内收到的信息。对于没有及时响应的服务提供者,页面可以忽略它们,或者显示一个提示信息,例如“Didnot hear from Air Java in time。”
-
从一个公司获得报价的过程与从其他公司获得报价的过程无关,因此可以将获取报价的过程当成一个任务,从而使获得报价的过程能并发执行。创建n个任务,将其提交到一个线程池,保留n个Future,并使用限时的get方法通过Future串行地获取每一个结果,这一切都很简单,但还有一个更简单的方法——invokeAll。
-
程序清单6-17使用了支持限时的invokeAll,将多个任务提交到一个ExecutorService并获得结果
private class QuoteTask implements Callable<TravelQuote>{ private final TravelCompany company; private final TravelInfo travelInfo; …… public TravelQuote call()throws Exception{ return company.solicitQuote(travelInfo); } } public List<TravelQuote>getRankedTravelQuotes(TravelInfo travelInfo, Set<TravelCompany>companies,Comparator<TravelQuote>ranking, long time, TimeUnit unit)throws InterruptedException{ List<QuoteTask>tasks=new ArrayList<QuoteTask>(); //添加任务,还未执行 for(TravelCompany company:companies) tasks.add(new QuoteTask(company, travelInfo)); //invokeAll执行集合中的任务,任务结果按迭代器顺序返回 List<Future<TravelQuote>>futures=exec.invokeAll(tasks, time, unit); List<TravelQuote>quotes=new ArrayList<TravelQuote>(tasks.size()); Iterator<QuoteTask>taskIter=tasks.iterator(); //记录各任务执行情况, //注意:保存的是Future而不是callable //callable集合作为迭代顺序 for(Future<TravelQuote>f:futures){ QuoteTask task=taskIter.next(); try{ quotes.add(f.get()); }catch(ExecutionException e){ quotes.add(task.getFailureQuote(e.getCause())); }catch(CancellationException e){ quotes.add(task.getTimeoutQuote(e)); } } //安装指定方式排序 Collections.sort(quotes, ranking); return quotes; }- InvokeAll方法的参数为一组任务,并返回一组Future。
- invokeAll按照任务集合中迭代器的顺序将所有的Future添加到返回的集合中,从而使调用者能将各个Future与其表示的Callable关联起来。
- 当所有任务都执行完毕时,或者调用线程被中断时,又或者超过指定时限时,invokeAll将返回。当超过指定时限后,任何还未完成的任务都会取消。当invokeAll返回后,每个任务要么正常地完成,要么被取消,而客户端代码可以调用get或isCancelled来判断究竟是何种情况。
小结
- 通过围绕任务执行来设计应用程序,可以简化开发过程,并有助于实现并发。
- Executor框架将任务提交与执行策略解耦开来,同时还支持多种不同类型的执行策略。当需要创建线程来执行任务时,可以考虑使用Executor。
- 要想在将应用程序分解为不同的任务时获得最大的好处,必须定义清晰的任务边界。
- 某些应用程序中存在着比较明显的任务边界,而在其他一些程序中则需要进一步分析才能揭示出粒度更细的并行性。
第7章 取消与关闭
- 要使任务和线程能安全、快速、可靠地停止下来,并不是一件容易的事。Java没有提供任何机制来安全地终止线程[1]。但它提供了中断(Interruption),这是一种协作机制,能够使一个线程终止另一个线程的当前工作。
- 这种协作式的方法是必要的,我们很少希望某个任务、线程或服务立即停止,因为这种立即停止会使共享的数据结构处于不一致的状态。
- 相反,在编写任务和服务时可以使用一种协作的方式:当需要停止时,它们首先会清除当前正在执行的工作,然后再结束。这提供了更好的灵活性,因为任务本身的代码比发出取消请求的代码更清楚如何执行清除工作。;执行任务的本身负责本身任务的清除,其他任务只提供取消的请求、响不响应取决于执行任务的本身。
- 生命周期结束(End-of-Lifecycle)的问题会使任务、服务以及程序的设计和实现等过程变得复杂,而这个在程序设计中非常重要的要素却经常被忽略。
- 一个在行为良好的软件与勉强运行的软件之间的最主要区别就是,行为良好的软件能很完善地处理失败、关闭和取消等过程。
- 本章将给出各种实现取消和中断的机制,以及如何编写任务和服务,使它们能对取消请求做出响应。
7.1 任务取消
-
如果外部代码能在某个操作正常完成之前将其置入“完成”状态,那么这个操作就可以称为可取消的(Cancellable)。
-
需要取消任务的场景
- 用户请求取消:如图形界面用户点击取消按钮;
- 有时间限制的操作。
- 应用程序事件。
- 错误。网页爬虫程序搜索相关的页面,并将页面或摘要数据保存到硬盘。当一个爬虫任务发生错误时(例如,磁盘空间已满),那么所有搜索任务都会取消,此时可能会记录它们的当前状态,以便稍后重新启动。
- 关闭。当一个程序或服务关闭时,必须对正在处理和等待处理的工作执行某种操作。在平缓的关闭过程中,当前正在执行的任务将继续执行直到完成,而在立即关闭过程中,当前的任务则可能取消。
-
在Java中没有一种安全的抢占式方法来停止线程,因此也就没有安全的抢占式方法来停止任务。只有一些协作式的机制,使请求取消的任务和代码都遵循一种协商好的协议。
-
其中一种协作机制能设置某个“已请求取消(Cancellation Requested)”标志,而任务将定期地查看该标志。如果设置了这个标志,那么任务将提前结束。
-
使用volatile类型的域来保存取消状态
@ThreadSafepublic class PrimeGenerator implements Runnable{ @GuardedBy("this")private final List<BigInteger>primes=new ArrayList<BigInteger>(); private volatile boolean cancelled; public void run(){ BigInteger p=BigInteger.ONE; while(!cancelled){ p=p.nextProbablePrime(); synchronized(this){ primes.add(p); } } } public void cancel(){ cancelled=true; } public synchronized List<BigInteger>get(){ return new ArrayList<BigInteger>(primes); } } -
一个仅运行一秒钟的素数生成器
List<BigInteger>aSecondOfPrimes()throws InterruptedException{ PrimeGenerator generator=new PrimeGenerator(); new Thread(generator).start(); try{ SECONDS.sleep(1); }finally{ generator.cancel(); } return generator.get(); } -
一个可取消的任务必须拥有取消策略(Cancellation Policy),在这个策略中将详细地定义取消操作的“How”、“When”以及“What”,即其他代码如何(How)请求取消该任务,任务在何时(When)检查是否已经请求了取消,以及在响应取消请求时应该执行哪些(What)操作。
-
PrimeGenerator使用了一种简单的取消策略:客户代码通过调用cancel来请求取消,PrimeGenerator在每次搜索素数前首先检查是否存在取消请求,如果存在则退出。
7.1.1 中断
-
PrimeGenerator中的取消机制最终会使得搜索素数的任务退出,但在退出过程中需要花费一定的时间。然而,如果使用这种方法的任务调用了一个阻塞方法,例如BlockingQueue.put,那么可能会产生一个更严重的问题——任务可能永远不会检查取消标志,因此永远不会结束。
-
不可靠的取消操作将把生产者置于阻塞的操作中(不要这么做)
class BrokenPrimeProducer extends Thread{ private final BlockingQueue<BigInteger>queue; private volatile boolean cancelled=false; BrokenPrimeProducer(BlockingQueue<BigInteger>queue){ this.queue=queue; } public void run(){ try{ BigInteger p=BigInteger.ONE; while(!cancelled) queue.put(p=p.nextProbablePrime()); }catch(InterruptedException consumed){ } } public void cancel(){ cancelled=true; } } void consumePrimes()throws InterruptedException{ BlockingQueue<BigInteger>primes=……; BrokenPrimeProducer producer=new BrokenPrimeProducer(primes); producer.start(); try{ while(needMorePrimes()) consume(primes.take()); }finally{ producer.cancel(); } } -
线程中断是一种协作机制,线程可以通过这种机制来通知另一个线程,告诉它在合适的或者可能的情况下停止当前工作,并转而执行其他的工作。
-
每个线程都有一个boolean类型的中断状态。当中断线程时,这个线程的中断状态将被设置为true。在Thread中包含了中断线程以及查询线程中断状态的方法,如程序清单7-4所示。interrupt方法能中断目标线程,而isInterrupted方法能返回目标线程的中断状态。静态的interrupted方法将清除当前线程的中断状态,并返回它之前的值,这也是清除中断状态的唯一方法。
public class Thread{ public void interrupt(){……} public boolean isInterrupted(){……} public static boolean interrupted(){……} …… } -
阻塞库方法,例如Thread.sleep和Object.wait等,都会检查线程何时中断,并且在发现中断时提前返回。它们在响应中断时执行的操作包括:清除中断状态,抛出InterruptedException,表示阻塞操作由于中断而提前结束.
-
当线程在非阻塞状态下中断时,它的中断状态将被设置,然后根据将被取消的操作来检查中断状态以判断发生了中断。通过这样的方法,中断操作将变得“有黏性”——如果不触发InterruptedException,那么中断状态将一直保持,直到明确地清除中断状态。
-
对中断操作的正确理解是:它并不会真正地中断一个正在运行的线程,而只是发出中断请求,然后由线程在下一个合适的时刻中断自己。(这些时刻也被称为取消点)。有些方法,例如wait、sleep和join等,将严格地处理这种请求,当它们收到中断请求或者在开始执行时发现某个已被设置好的中断状态时,将抛出一个异常。设计良好的方法可以完全忽略这种请求,只要它们能使调用代码对中断请求进行某种处理。设计糟糕的方法可能会屏蔽中断请求,从而导致调用栈中的其他代码无法对中断请求作出响应。
-
在使用静态的interrupted时应该小心,因为它会清除当前线程的中断状态。如果在调用interrupted时返回了true,那么除非你想屏蔽这个中断,否则必须对它进行处理——可以抛出InterruptedException,或者通过再次调用interrupt来恢复中断状态.
-
通常,中断是实现取消的最合理方式.
-
通过中断来取消
class PrimeProducer extends Thread{ private final BlockingQueue<BigInteger>queue; PrimeProducer(BlockingQueue<BigInteger>queue){ this.queue=queue; } public void run(){ try{ BigInteger p=BigInteger.ONE; while(!Thread.currentThread().isInterrupted()) queue.put(p=p.nextProbablePrime()); }catch(InterruptedException consumed){ /*允许线程退出*/ } } public void cancel(){ interrupt(); } }
7.1.2 中断策略
- 正如任务中应该包含取消策略一样,线程同样应该包含中断策略。中断策略规定线程如何解释某个中断请求——当发现中断请求时,应该做哪些工作(如果需要的话),哪些工作单元对于中断来说是原子操作,以及以多快的速度来响应中断。
- 最合理的中断策略是某种形式的线程级(Thread-Level)取消操作或服务级(Service-Level)取消操作:尽快退出,在必要时进行清理,通知某个所有者该线程已经退出。(Java目前采用的线程中断策略);
- 此外还可以建立其他的中断策略,例如暂停服务或重新开始服务,但对于那些包含非标准中断策略的线程或线程池,只能用于能知道这些策略的任务中。
- 区分任务和线程对中断的反应是很重要的。一个中断请求可以有一个或多个接收者——中断线程池中的某个工作者线程,同时意味着“取消当前任务”和“关闭工作者线程”。
- 任务不会在其自己拥有的线程中执行,而是在某个服务(例如线程池)拥有的线程中执行。对于非线程所有者的代码来说(例如,对于线程池而言,任何在线程池实现以外的代码),应该小心地保存中断状态,这样拥有线程的代码才能对中断做出响应,即使“非所有者”代码也可以做出响应。
- 这就是为什么大多数可阻塞的库函数都只是抛出InterruptedException作为中断响应。它们永远不会在某个由自己拥有的线程中运行,因此它们为任务或库代码实现了最合理的取消策略:尽快退出执行流程,并把中断信息传递给调用者,从而使调用栈中的上层代码可以采取进一步的操作。
- 当检查到中断请求时,任务并不需要放弃所有的操作——它可以推迟处理中断请求,并直到某个更合适的时刻。因此需要记住中断请求,并在完成当前任务后抛出InterruptedException或者表示已收到中断请求。这项技术能够确保在更新过程中发生中断时,数据结构不会被破坏。
- 任务不应该对执行该任务的线程的中断策略做出任何假设,除非该任务被专门设计为在服务中运行,并且在这些服务中包含特定的中断策略。无论任务把中断视为取消,还是其他某个中断响应操作,都应该小心地保存执行线程的中断状态。如果除了将InterruptedException传递给调用者外还需要执行其他操作,那么应该在捕获InterruptedException之后恢复中断状态.
- 正如任务代码不应该对其执行所在的线程的中断策略做出假设,执行取消操作的代码也不应该对线程的中断策略做出假设。线程应该只能由其所有者中断,所有者可以将线程的中断策略信息封装到某个合适的取消机制中,例如关闭(shutdown)方法。
- 由于每个线程拥有各自的中断策略,因此除非你知道中断对该线程的含义,否则就不应该中断这个线程。
7.1.3 响应中断
-
响应中断策略
- 非阻塞任务响应中断请求执行自定义中断策略
- 调用可中断的阻塞函数,如Thread.sleep()等,处理InterruptedException:
- 传递异常,使你的方法也成为可中断的阻塞方法;
- 恢复中断状态,从而使调用栈中的上层代码能够对其进行处理。
-
一种标准的方法就是通过再次调用interrupt来恢复中断状态。
-
你不能屏蔽InterruptedException,例如在catch块中捕获到异常却不做任何处理,除非在你的代码中实现了线程的中断策略。虽然PrimeProducer屏蔽了中断,但这是因为它已经知道线程将要结束,因此在调用栈中已经没有上层代码需要知道中断信息。由于大多数代码并不知道它们将在哪个线程中运行,因此应该保存中断状态。
-
只有实现了线程中断策略的代码才可以屏蔽中断请求。在常规的任务和库代码中都不应该屏蔽中断请求。
-
对于一些不支持取消但仍可以调用可中断阻塞方法的操作,它们必须在循环中调用这些方法,并在发现中断后重新尝试。在这种情况下,它们应该在本地保存中断状态,并在返回前恢复状态而不是在捕获InterruptedException时恢复状态,如程序清单7-7所示
public Task getNextTask(BlockingQueue<Taskgt>queue){ boolean interrupted=false; try{ while(true){ try{ return queue.take(); }catch(InterruptedException e){ //捕获这个错误说明调用该方法的线程设置为了中断,中断是线程的粒度或者是服务器的粒度,而不是集合的粒度 //保存中断状态 //1. 如果在这里恢复中断状态,那么阻塞 //2. 调用栈的上层设置该方法线程中断 //3. 又捕获中断 //4. 重复1-3过程 interrupted=true; //重新尝试 } } }finally{ if(interrupted) //恢复本线程的中断状态,即使该方法不支持中断,但是也要恢复为中断状态保持对象的一致性 Thread.currentThread().interrupt(); } } -
如果过早地设置中断状态,就可能引起无限循环(发现中断-抛弃中断错误-还原中断状态-发现中断…),因为大多数可中断的阻塞方法都会在入口处检查中断状态,并且当发现该状态已被设置时会立即抛出InterruptedException。(通常,可中断的方法会在阻塞或进行重要的工作前首先检查中断,从而尽快地响应中断)。
-
如果代码不会调用可中断的阻塞方法,那么仍然可以通过在任务代码中轮询当前线程的中断状态来响应中断。
-
在取消过程中可能涉及除了中断状态之外的其他状态。中断可以用来获得线程的注意,并且由中断线程保存的信息,可以为中断的线程提供进一步的指示。(当访问这些信息时,要确保使用同步。)例如,当一个由ThreadPoolExecutor拥有的工作者线程检测到中断时,它会检查线程池是否正在关闭。如果是,它会在结束之前执行一些线程池清理工作,否则它可能创建一个新线程将线程池恢复到合理的规模。
7.1.4 示例:计时运行
-
在外部线程中安排中断(不要这么做)
private static final ScheduledExecutorService cancelExec=……; public static void timedRun(Runnable r,long timeout, TimeUnit unit){ final Thread taskThread=Thread.currentThread(); cancelExec.schedule(new Runnable(){ public void run(){ taskThread.interrupt(); } },timeout, unit); r.run(); }- 它在调用线程中运行任务,并安排了一个取消任务,在运行指定的时间间隔后中断它。这解决了从任务中抛出未检查异常的问题,因为该异常会被timedRun的调用者捕获。
- 这是一种非常简单的方法,但却破坏了以下规则:在中断线程之前,应该了解它的中断策略。由于timedRun可以从任意一个线程中调用,因此它无法知道这个调用线程的中断策略。如果任务在超时之前完成,那么中断timedRun所在线程的取消任务将在timedRun返回到调用者之后启动。我们不知道在这种情况下将运行什么代码,但结果一定是不好的。
- 而且,如果任务不响应中断,那么timedRun会在任务结束时才返回,此时可能已经超过了指定的时限(或者还没有超过时限)。如果某个限时运行的服务没有在指定的时间内返回,那么将对调用者带来负面影响。
-
在专门的线程中中断任务:解决捕获未检查异常及了解调用中断的线程中断策略(将其放进一个专门的线程中)
public static void timedRun(final Runnable r,long timeout, TimeUnit unit)throws InterruptedException{ class RethrowableTask implements Runnable{ private volatile Throwable t; public void run(){ try{ //将任务再次封装,委派执行,如果有未检查错误,保存该错误状态后续处理 r.run(); }catch(Throwable t){ this.t=t; } } void rethrow(){ if(t!=null) throw launderThrowable(t); } } //设置新线程 RethrowableTask task=new RethrowableTask(); final Thread taskThread=new Thread(task); taskThread.start(); //定时中断新线程 cancelExec.schedule(new Runnable(){ public void run(){ taskThread.interrupt(); } },timeout, unit); //join:限时等待任务线程执行后,再执行本线程 taskThread.join(unit.toMillis(timeout)); //处理错误 task.rethrow(); }- 执行任务的线程拥有自己的执行策略,即使任务不响应中断,限时运行的方法仍能返回到它的调用者。
- 在启动任务线程之后,timedRun将执行一个限时的join方法。
- 由于Throwable将在两个线程之间共享,因此该变量被声明为volatile类型,从而确保安全地将其从任务线程发布到timedRun线程。
- 在这个示例的代码中解决了前面示例中的问题,但由于它依赖于一个限时的join,因此存在着join的不足:无法知道执行控制是因为线程正常退出而返回还是因为join超时而返回。
- 这是Thread API的一个缺陷,因为无论join是否成功地完成,在Java内存模型中都会有内存可见性结果,但join本身不会返回某个状态来表明它是否成功。
7.1.5 通过Future来实现取消
-
ExecutorService.submit将返回一个Future来描述任务。Future拥有一个cancel方法,该方法带有一个boolean类型的参数mayInterruptIfRunning,表示取消操作是否成功。(这只是表示任务是否能够接收中断,而不是表示任务是否能检测并处理中断。)
-
如果mayInterruptIfRunning为true并且任务当前正在某个线程中运行,那么这个线程能被中断。如果这个参数为false,那么意味着“若任务还没有启动,就不要运行它”,这种方式应该用于那些不处理中断的任务中。
-
执行任务的线程是由标准的Executor创建的,它实现了一种中断策略使得任务可以通过中断被取消,所以如果任务在标准Executor中运行,并通过它们的Future来取消任务,那么可以设置mayInterruptIfRunning。
-
当尝试取消某个任务时,不宜直接中断线程池,因为你并不知道当中断请求到达时正在运行什么任务——只能通过任务的Future来实现取消。**Future取消任务,thread中断线程。**这也是在编写任务时要将中断视为一个取消请求的另一个理由:可以通过任务的Future来取消它们。
-
通过Future来取消任务
public static void timedRun(Runnable r,long timeout, TimeUnit unit)throws InterruptedException{ Future<?>task=taskExec.submit(r); try{ task.get(timeout, unit); }catch(TimeoutException e){ //接下来任务将被取消 }catch(ExecutionException e){ ∥如果在任务中抛出了异常,那么重新抛出该异常 throw launderThrowable(e.getCause()); }finally{ ∥如果任务已经结束,那么执行取消操作也不会带来任何影响 task.cancel(true); //如果任务正在运行,那么将被中断 } }- 将任务提交给一个ExecutorService,并通过一个定时的Future.get来获得结果;
- 如果get在返回时抛出了一个TimeoutException,那么任务将通过它的Future来取消。(为了简化代码,这个版本的timedRun在finally块中将直接调用Future.cancel,因为取消一个已完成的任务不会带来任何影响。)
- 如果任务在被取消前就抛出一个异常,那么该异常将被重新抛出以便由调用者来处理异常。
- 另一种良好的编程习惯:取消那些不再需要结果的任务。
7.1.6 处理不可中断的阻塞
-
在Java库中,许多可阻塞的方法都是通过提前返回或者抛出InterruptedException来响应中断请求的,从而使开发人员更容易构建出能响应取消请求的任务。然而,并非所有的可阻塞方法或者阻塞机制都能响应中断。
-
如果一个线程由于执行同步的Socket I/O或者等待获得内置锁而阻塞,那么中断请求只能设置线程的中断状态,除此之外没有其他任何作用。
-
对于那些由于执行不可中断操作而被阻塞的线程,可以使用类似于中断的手段来停止这些线程,但这要求我们必须知道线程阻塞的原因。
-
不可中断阻塞场景
- Java.io包中的同步Socket I/O:在服务器应用程序中,最常见的阻塞I/O形式就是对套接字进行读取和写入。虽然InputStream和OutputStream中的read和write等方法都不会响应中断,但通过关闭底层的套接字,可以使得由于执行read或write等方法而被阻塞的线程抛出一个SocketException。
- Java.io包中的同步I/O:当中断一个正在InterruptibleChannel上等待的线程时,将抛出ClosedByInterruptException并关闭链路(这还会使得其他在这条链路上阻塞的线程同样抛出ClosedByInterruptException)。当关闭一个InterruptibleChannel时,将导致所有在链路操作上阻塞的线程都抛出AsynchronousCloseException。大多数标准的Channel都实现了InterruptibleChannel。
- Selector的异步I/O:如果一个线程在调用Selector.select方法(在java.nio.channels中)时阻塞了,那么调用close或wakeup方法会使线程抛出ClosedSelectorException并提前返回。
- 获取某个锁:如果一个线程由于等待某个内置锁而阻塞,那么将无法响应中断,因为线程认为它肯定会获得锁,所以将不会理会中断请求。但是,在Lock类中提供了lockInterruptibly方法,该方法允许在等待一个锁的同时仍能响应中断。
-
通过改写interrupt方法将非标准的取消操作封装在Thread中
public class ReaderThread extends Thread{ private final Socket socket; private final InputStream in; public ReaderThread(Socket socket)throws IOException{ this.socket=socket; this.in=socket.getInputStream(); } public void interrupt(){ try{ //关闭套接字,读写将中断的exception转化为其他exception // 改写中断机制的前提是需要知道阻塞非中断的其他中断方法:这里虽然Socket的IO不支持中断取消任务, // 但是IO支持关闭套接字抛出错误取消任务 socket.close(); }catch(IOException ignored){ }finally{ super.interrupt(); } } public void run(){ try{ byte[]buf=new byte[BUFSZ]; while(true){ int count=in.read(buf); if(count<0) break; else if(count>0) processBuffer(buf, count); } }catch(IOException e){ /*允许线程退出*/ } } }- ReaderThread管理了一个套接字连接,它采用同步方式从该套接字中读取数据,并将接收到的数据传递给processBuffer。
- 为了结束某个用户的连接或者关闭服务器,ReaderThread改写了interrupt方法,使其既能处理标准的中断,也能关闭底层的套接字。
- 因此,无论ReaderThread线程是在read方法中阻塞还是在某个可中断的阻塞方法中阻塞,都可以被中断并停止执行当前的工作。
7.1.7 采用newTaskFor来封装非标准的取消
-
我们可以通过newTaskFor方法来进一步优化ReaderThread中封装非标准取消的技术,这是Java 6在ThreadPoolExecutor中的新增功能。
-
newTaskFor是一个工厂方法,它将创建Future来代表任务。newTaskFor还能返回一个RunnableFuture接口,该接口扩展了Future和Runnable(并由FutureTask实现)。
-
通过定制表示任务的Future可以改变Future.cancel的行为。例如,定制的取消代码可以实现日志记录或者收集取消操作的统计信息,以及取消一些不响应中断的操作。
-
通过改写interrupt方法,ReaderThread可以取消基于套接字的线程。同样,通过改写任务的Future.cancel方法也可以实现类似的功能。
-
通过newTaskFor将非标准的取消操作封装在一个任务中
public interface CancellableTask<T> extends Callable<T>{ void cancel(); RunnableFuture<T> newTask(); } @ThreadSafe public class CancellingExecutor extends ThreadPoolExecutor{ …… protected<T>RunnableFuture<T>newTaskFor(Callable<T>callable){ if(callable instanceof CancellableTask) return((CancellableTask<T>)callable).newTask(); else return super.newTaskFor(callable); } } public abstract class SocketUsingTask<T>implements CancellableTask<T>{ @GuardedBy("this")private Socket socket; protected synchronized void setSocket(Socket s){ socket=s; } public synchronized void cancel(){ try{ if(socket!=null) socket.close(); }catch(IOException ignored){ } } public RunnableFuture<T>newTask(){ return new FutureTask<T>(this){ public boolean cancel(boolean mayInterruptIfRunning){ try{ SocketUsingTask.this.cancel(); }finally{ return super.cancel(mayInterruptIfRunning); } } }; } }- CancellableTask中定义了一个CancellableTask接口,该接口扩展了Callable,并增加了一个cancel方法和一个newTask工厂方法来构造RunnableFuture.
- CancellingExecutor扩展了ThreadPoolExecutor,并通过改写newTaskFor使得CancellableTask可以创建自己的Future。
- SocketUsingTask实现了CancellableTask,并定义了Future.cancel来关闭套接字和调用super.cancel。
- 如果SocketUsingTask通过其自己的Future来取消,那么底层的套接字将被关闭并且线程将被中断。因此它提高了任务对取消操作的响应性:不仅能够在调用可中断方法的同时确保响应取消操作,而且还能调用可阻调的套接字I/O方法。
7.2 停止基于线程的服务
- 应用程序通常会创建拥有多个线程的服务,例如线程池,并且这些服务的生命周期通常比创建它们的方法的生命周期更长。
- 正确的封装原则是:除非拥有某个线程,否则不能对该线程进行操控。线程有一个相应的所有者,即创建该线程的类。因此线程池是其工作者线程的所有者,如果要中断这些线程,那么应该使用线程池。
- 与其他封装对象一样,线程的所有权是不可传递的:应用程序可以拥有服务,服务也可以拥有工作者线程,但应用程序并不能拥有工作者线程,因此应用程序不能直接停止工作者线程。相反,服务应该提供生命周期方法(Lifecycle Method)来关闭它自己以及它所拥有的线程。
- 在ExecutorService中提供了shutdown和shutdownNow等方法。同样,在其他拥有线程的服务中也应该提供类似的关闭机制。
- 对于持有线程的服务,只要服务的存在时间大于创建线程的方法的存在时间,那么就应该提供生命周期方法。
7.2.1 示例:日志服务
-
通过调用log方法将日志消息放入某个队列中,并由其他线程来处理。
-
不支持关闭的生产者-消费者日志服务
public class LogWriter{ //日志队列 private final BlockingQueue<String>queue; //日志处理线程 private final LoggerThread logger; public LogWriter(Writer writer){ this.queue=new LinkedBlockingQueue<String>(CAPACITY); this.logger=new LoggerThread(writer); } //这个设置线程开始,也要想办法弄线程关闭呀,不然怎么停下来 public void start(){ logger.start(); } public void log(String msg)throws InterruptedException{ queue.put(msg); } private class LoggerThread extends Thread{ private final PrintWriter writer; …… public void run(){ try{ while(true) writer.println(queue.take()); }catch(InterruptedException ignored){ }finally{ writer.close(); } } } }- LogWriter中给出了一个简单的日志服务示例,其中日志操作在单独的日志线程中执行。
- 产生日志消息的线程并不会将消息直接写入输出流,而是由LogWriter通过BlockingQueue将消息提交给日志线程,并由日志线程写入。
- 这是一种多生产者单消费者(Multiple-Producer, Single-Consumer)的设计方式:每个调用log的操作都相当于一个生产者,而后台的日志线程则相当于消费者。如果消费者的处理速度低于生产者的生成速度,那么BlockingQueue将阻塞生产者,直到日志线程有能力处理新的日志消息。
- 为了使像LogWriter这样的服务在软件产品中能发挥实际的作用,还需要实现一种终止日志线程的方法,从而避免使JVM无法正常关闭。
-
要停止日志线程是很容易的,因为它会反复调用take,而take能响应中断。如果将日志线程修改为当捕获到InterruptedException时退出,那么只需中断日志线程就能停止服务。
-
然而,如果只是使日志线程退出,那么还不是一种完备的关闭机制。这种直接关闭的做法会丢失那些正在等待被写入到日志的信息,不仅如此,其他线程将在调用log时被阻塞,因为日志消息队列是满的,因此这些线程将无法解除阻塞状态。
-
当取消一个生产者-消费者操作时,需要同时取消生产者和消费者。在中断日志线程时会处理消费者,但在这个示例中,由于生产者并不是专门的线程,因此要取消它们将非常困难。
-
另一种关闭LogWriter的方法是:设置某个“已请求关闭”标志,以避免进一步提交日志消息,通过一种不可靠的方式为日志服务增加关闭支持
public void log(String msg)throws InterruptedException{ if(!shutdownRequested) queue.put(msg); else throw new IllegalStateException("logger is shut down"); }- 在收到关闭请求后,消费者会把队列中的所有消息写入日志,并解除所有在调用log时阻塞的生产者
- 然而,在这个方法中存在着竞态条件问题,使得该方法并不可靠。log的实现是一种“先判断再运行”的代码序列:生产者发现该服务还没有关闭,因此在关闭服务后仍然会将日志消息放入队列,这同样会使得生产者可能在调用log时阻塞并且无法解除阻塞状态。
-
为LogWriter提供可靠关闭操作的方法是解决竞态条件问题,因而要使日志消息的提交操作成为原子操作。然而,我们不希望在消息加入队列时去持有一个锁,因为put方法本身就可以阻塞。我们采用的方法是:通过原子方式来检查关闭请求,并且有条件地递增一个计数器来“保持”提交消息的权利,如程序清单7-15中的LogService所示。
public class LogService{ private final BlockingQueue<String>queue; private final LoggerThread loggerThread; private final PrintWriter writer; @GuardedBy("this")private boolean isShutdown; //计数器 @GuardedBy("this")private int reservations; public void start(){ loggerThread.start(); } public void stop(){ synchronized(this){ //那这样做判断的时候也要加锁 isShutdown=true; } loggerThread.interrupt(); } public void log(String msg)throws InterruptedException{ synchronized(this){ if(isShutdown) throw new IllegalStateException(……); //这样查看的时候也要加锁 ++reservations; } queue.put(msg); } private class LoggerThread extends Thread{ public void run(){ try{ while(true){ try{ synchronized(LogService.this){ //关闭了同时队列处理完了 if(isShutdown&&reservations==0) break; } String msg=queue.take(); synchronized(LogService.this){ --reservations; } writer.println(msg); }catch(InterruptedException e){ /*retry*/ } } }finally{ writer.close(); } } } }- 如果需要在单条日志消息中写入多行,那么要通过客户端加锁来避免多个线程不正确地交错输出。如果两个线程同时把多行栈追踪信息(Stack Trace)添加到同一个流中,并且每行信息对应一个println调用,那么这些信息在输出中将交错在一起,看上去就是一些虽然庞大但却毫无意义的栈追踪信息。
7.2.2 关闭ExecutorService
-
ExecutorService提供了两种关闭方法:使用shutdown正常关闭,以及使用shutdownNow强行关闭。
-
在复杂程序中,通常会将ExecutorService封装在某个更高级别的服务中,并且该服务能提供其自己的生命周期方法,例如程序清单7-16中LogService的一种变化形式,它将管理线程的工作委托给一个ExecutorService,而不是由其自行管理.
public class LogService{ private final ExecutorService exec=newSingleThreadExecutor(); …… public void start(){ } public void stop()throws InterruptedException{ try{ exec.shutdown(); exec.awaitTermination(TIMEOUT, UNIT); }finally{ writer.close(); } } public void log(String msg){ try{ exec.execute(new WriteTask(msg)); }catch(RejectedExecutionException ignored){ } } } -
通过封装ExecutorService,可以将所有权链(Ownership Chain)从应用程序扩展到服务以及线程,所有权链上的各个成员都将管理它所拥有的服务或线程的生命周期。
7.2.3 "毒丸"对象
-
另一种关闭生产者-消费者服务的方式就是使用“毒丸(Poison Pill)”对象:“毒丸”是指一个放在队列上的对象,其含义是:“当得到这个对象时,立即停止。”在FIFO(先进先出)队列中,“毒丸”对象将确保消费者在关闭之前首先完成队列中的所有工作,在提交“毒丸”对象之前提交的所有工作都会被处理,而生产者在提交了“毒丸”对象后,将不会再提交任何工作。
-
通过“毒丸”对象来关闭服务
public class IndexingService{ //毒丸 private static final File POISON=new File(""); //生产者线程 private final IndexerThread consumer=new IndexerThread(); //消费者线程 private final CrawlerThread producer=new CrawlerThread(); private final BlockingQueue<File>queue; private final FileFilter fileFilter; private final File root; //生产者线程 class CrawlerThread extends Thread{ /*程序清单7-18*/ public void run(){ try{ crawl(root); }catch(InterruptedException e){ /*发生异常*/ }finally{ //?TODO: while放在这里? 感觉应该放在try里面吧 while(true){ try{ queue.put(POISON); break; }catch(InterruptedException e1){ /*重新尝试*/ } } } } private void crawl(File root)throws InterruptedException{ …… } } //消费者线程 class IndexerThread extends Thread{ /*程序清单7-19*/ public void run(){ try{ while(true){ File file=queue.take(); if(fle==POISON) break; else indexFile(file); } }catch(InterruptedException consumed){ } } } public void start(){ producer.start(); consumer.start(); } public void stop(){ producer.interrupt(); } public void awaitTermination()throws InterruptedException{ consumer.join(); } }//IndexingService的生产者线程 public class CrawlerThread extends Thread{ public void run(){ try{ crawl(root); }catch(InterruptedException e){ /*发生异常*/ }finally{ //?while放在这里? while(true){ try{ queue.put(POISON); break; }catch(InterruptedException e1){ /*重新尝试*/ } } } } private void crawl(File root)throws InterruptedException{ …… } }//IndexingService的消费者线程 public class IndexerThread extends Thread{ public void run(){ try{ while(true){ File file=queue.take(); if(fle==POISON) break; else indexFile(file); } }catch(InterruptedException consumed){ } } } -
只有在生产者和消费者的数量都已知的情况下,才可以使用“毒丸”对象.
-
在Indexing-Service中采用的解决方案可以扩展到多个生产者:只需每个生产者都向队列中放入一个“毒丸”对象,并且消费者仅当在接收到Nproducers个“毒丸”对象时才停止。这种方法也可以扩展到多个消费者的情况,只需生产者将Nconsumers个“毒丸”对象放入队列。
-
然而,当生产者和消费者的数量较大时,这种方法将变得难以使用。只有在无界队列中,“毒丸”对象才能可靠地工作。
7.2.4 示例:只执行一次的服务
-
如果某个方法需要处理一批任务,并且当所有任务都处理完成后才返回,那么可以通过一个私有的Executor来简化服务的生命周期管理,其中该Executor的生命周期是由这个方法来控制的。(在这种情况下,invokeAll和invokeAny等方法通常会起较大的作用。)
-
使用私有的Executor,并且该Executor的生命周期受限于方法调用
boolean checkMail(Set<String>hosts, long timeout, TimeUnit unit)throws InterruptedException{ ExecutorService exec=Executors.newCachedThreadPool(); final AtomicBoolean hasNewMail=new AtomicBoolean(false); try{ for(final String host:hosts) exec.execute(new Runnable(){ public void run(){ if(checkMail(host)) hasNewMail.set(true); } }); }finally{ exec.shutdown(); exec.awaitTermination(timeout, unit); } return hasNewMail.get(); }- checkMail方法能在多台主机上并行地检查新邮件。它创建一个私有的Executor,并向每台主机提交一个任务。然后,当所有邮件检查任务都执行完成后,关闭Executor并等待结束。
7.2.5 shutdownNow的局限性
- 当通过shutdownNow来强行关闭ExecutorService时,它会尝试取消正在执行的任务,并返回所有已提交但尚未开始的任务,从而将这些任务写入日志或者保存起来以便之后进行处理。
- 我们无法通过常规方法来找出哪些任务已经开始但尚未结束。这意味着我们无法在关闭过程中知道正在执行的任务的状态,除非任务本身会执行某种检查。要知道哪些任务还没有完成,你不仅需要知道哪些任务还没有开始,而且还需要知道当Executor关闭时哪些任务正在执行。
7.3 处理非正常的线程终止
-
如果并发程序中的某个线程发生故障,那么通常并不会如此明显。在控制台中可能会输出栈追踪信息,但没有人会观察控制台。此外,当线程发生故障时,应用程序可能看起来仍然在工作,所以这个失败很可能会被忽略。
-
导致线程提前死亡的最主要原因就是RuntimeException。由于这些异常表示出现了某种编程错误或者其他不可修复的错误,因此它们通常不会被捕获。它们不会在调用栈中逐层传递,而是默认地在控制台中输出栈追踪信息,并终止线程。
-
线程非正常退出的后果可能是良性的,也可能是恶性的,这要取决于线程在应用程序中的作用。
-
典型的线程池工作者线程结构
public void run(){ Throwable thrown=null; try{ while(!isInterrupted()) runTask(getTaskFromWorkQueue()); }catch(Throwable e){//捕获异常并发布异常 thrown=e; }finally{ threadExited(this, thrown); } } -
在Thread API中同样提供了Uncaught-ExceptionHandler,它能检测出某个线程由于未捕获的异常而终结的情况。这两种方法是互补的,通过将主动捕获与它结合在一起,就能有效地防止线程泄漏问题。
-
当一个线程由于未捕获异常而退出时,JVM会把这个事件报告给应用程序提供的UncaughtExceptionHandler异常处理器(见程序清单7-24)。如果没有提供任何异常处理器,那么默认的行为是将栈追踪信息输出到System.err。
-
UncaughtExceptionHandler接口
public interface UncaughtExceptionHandler{ void uncaughtException(Thread t, Throwable e); } -
异常处理器如何处理未捕获异常,取决于对服务质量的需求。最常见的响应方式是将一个错误信息以及相应的栈追踪信息写入应用程序日志中,如程序清单7-25所示。
public class UEHLogger implements Thread.UncaughtExceptionHandler{ public void uncaughtException(Thread t, Throwable e){ Logger logger=Logger.getAnonymousLogger(); logger.log(Level.SEVERE,"Thread terminated with exception:"+t.getName(),e); } } -
异常处理器还可以采取更直接的响应,例如尝试重新启动线程,关闭应用程序,或者执行其他修复或诊断等操作。
-
在运行时间较长的应用程序中,通常会为所有线程的未捕获异常指定同一个异常处理器,并且该处理器至少会将异常信息记录到日志中。
-
要为线程池中的所有线程设置一个UncaughtExceptionHandler,需要为ThreadPool-Executor的构造函数提供一个ThreadFactory。(与所有的线程操控一样,只有线程的所有者能够改变线程的UncaughtExceptionHandler。)
-
标准线程池允许当发生未捕获异常时结束线程,但由于使用了一个try-finally代码块来接收通知,因此当线程结束时,将有新的线程来代替它。
-
如果没有提供捕获异常处理器或者其他的故障通知机制,那么任务会悄悄失败,从而导致极大的混乱。如果你希望在任务由于发生异常而失败时获得通知,并且执行一些特定于任务的恢复操作,那么可以将任务封装在能捕获异常的Runnable或Callable中,或者改写ThreadPoolExecutor的afterExecute方法。
-
令人困惑的是,只有通过execute提交的任务,才能将它抛出的异常交给未捕获异常处理器,而通过submit提交的任务,无论是抛出的未检查异常还是已检查异常,都将被认为是任务返回状态的一部分。如果一个由submit提交的任务由于抛出了异常而结束,那么这个异常将被Future.get封装在ExecutionException中重新抛出。
7.4 JVM关闭
- JVM既可以正常关闭,也可以强行关闭。
- 当最后一个“正常(非守护)”线程结束时;
- 调用了System.exit时;
- 通过其他特定于平台的方法关闭时(例如发送了SIGINT信号或键入Ctrl-C)
- 调用Runtime.halt或者在操作系统中“杀死”JVM进程(例如发送SIGKILL)来强行关闭JVM。
7.4.1 关闭钩子
-
在正常关闭中,JVM首先调用所有已注册的关闭钩子(Shutdown Hook)。关闭钩子是指通过Runtime.addShutdownHook注册的但尚未开始的线程。
-
JVM并不能保证关闭钩子的调用顺序。在关闭应用程序线程时,如果有(守护或非守护)线程仍然在运行,那么这些线程接下来将与关闭进程并发执行。当所有的关闭钩子都执行结束时,如果runFinalizersOnExit为true,那么JVM将运行终结器,然后再停止。
-
JVM并不会停止或中断任何在关闭时仍然运行的应用程序线程。当JVM最终结束时,这些线程将被强行结束。如果关闭钩子或终结器没有执行完成,那么正常关闭进程“挂起”并且JVM必须被强行关闭。当被强行关闭时,只是关闭JVM,而不会运行关闭钩子。
-
关闭钩子应该是线程安全的:它们在访问共享数据时必须使用同步机制,并且小心地避免发生死锁,这与其他并发代码的要求相同。
-
而且,关闭钩子不应该对应用程序的状态(例如,其他服务是否已经关闭,或者所有的正常线程是否已经执行完成)或者JVM的关闭原因做出任何假设,因此在编写关闭钩子的代码时必须考虑周全。
-
最后,关闭钩子必须尽快退出,因为它们会延迟JVM的结束时间,而用户可能希望JVM能尽快终止。
-
关闭钩子可以用于实现服务或应用程序的清理工作,例如删除临时文件,或者清除无法由操作系统自动清除的资源。
-
LogService在其start方法中注册一个关闭钩子,从而确保在退出时关闭日志文件。
public void start(){ Runtime.getRuntime().addShutdownHook(new Thread(){ public void run(){ try{ LogService.this.stop(); }catch(InterruptedException ignored){ } } }); } -
由于关闭钩子将并发执行,因此在关闭日志文件时可能导致其他需要日志服务的关闭钩子产生问题.为了避免这种情况,关闭钩子不应该依赖那些可能被应用程序或其他关闭钩子关闭的服务。
-
实现这种功能的一种方式是对所有服务使用同一个关闭钩子(而不是每个服务使用一个不同的关闭钩子),并且在该关闭钩子中执行一系列的关闭操作。这确保了关闭操作在单个线程中串行执行,从而避免了在关闭操作之间出现竞态条件或死锁等问题。无论是否使用关闭钩子,都可以使用这项技术,通过将各个关闭操作串行执行而不是并行执行,可以消除许多潜在的故障。
7.4.2 守护线程
- 有时候,你希望创建一个线程来执行一些辅助工作,但又不希望这个线程阻碍JVM的关闭。在这种情况下就需要使用守护线程(Daemon Thread)。
- 线程可分为两种:普通线程和守护线程。在JVM启动时创建的所有线程中,除了主线程以外,其他的线程都是守护线程(例如垃圾回收器以及其他执行辅助工作的线程)。当创建一个新线程时,新线程将继承创建它的线程的守护状态,因此在默认情况下,主线程创建的所有线程都是普通线程。
- 普通线程与守护线程之间的差异仅在于当线程退出时发生的操作。当一个线程退出时,JVM会检查其他正在运行的线程,如果这些线程都是守护线程,那么JVM会正常退出操作。当JVM停止时,所有仍然存在的守护线程都将被抛弃——既不会执行finally代码块,也不会执行回卷栈,而JVM只是直接退出。
- 我们应尽可能少地使用守护线程——很少有操作能够在不进行清理的情况下被安全地抛弃。特别是,如果在守护线程中执行可能包含I/O操作的任务,那么将是一种危险的行为。守护线程最好用于执行“内部”任务,例如周期性地从内存的缓存中移除逾期的数据。
7.4.3 终结器
- 当不再需要内存资源时,可以通过垃圾回收器来回收它们,但对于其他一些资源,例如文件句柄或套接字句柄,当不再需要它们时,必须显式地交还给操作系统。
- 为了实现这个功能,垃圾回收器对那些定义了finalize方法的对象会进行特殊处理:在回收器释放它们后,调用它们的finalize方法,从而保证一些持久化的资源被释放。
- 由于终结器可以在某个由JVM管理的线程中运行,因此终结器访问的任何状态都可能被多个线程访问,这样就必须对其访问操作进行同步。
- 终结器并不能保证它们将在何时运行甚至是否会运行,并且复杂的终结器通常还会在对象上产生巨大的性能开销。
- 要编写正确的终结器是非常困难的。[插图]在大多数情况下,通过使用finally代码块和显式的close方法,能够比使用终结器更好地管理资源。
- 唯一的例外情况在于:当需要管理对象,并且该对象持有的资源是通过本地方法获得的。基于这些原因以及其他一些原因,我们要尽量避免编写或使用包含终结器的类(除非是平台库中的类)[EJ Item 6]。避免使用终结器。
小结
- 在任务、线程、服务以及应用程序等模块中的生命周期结束问题,可能会增加它们在设计和实现时的复杂性。
- Java并没有提供某种抢占式的机制来取消操作或者终结线程。相反,它提供了一种协作式的中断机制来实现取消操作,但这要依赖于如何构建取消操作的协议,以及能否始终遵循这些协议。
- 通过使用FutureTask和Executor框架,可以帮助我们构建可取消的任务和服务。
第8章 线程池的使用
8.1 在任务与执行策略之间的隐性耦合
- 虽然Executor框架为制定和修改执行策略都提供了相当大的灵活性,但并非所有的任务都能适用所有的执行策略。有些类型的任务需要明确地指定执行策略,包括:
- 依赖性任务:如果提交给线程池的任务需要依赖其他的任务,那么就隐含地给执行策略带来了约束,此时必须小心地维持这些执行策略以避免产生活跃性问题。
- 使用线程封闭机制的任务:任务要求其执行所在的Executor是单线程的。如果将Executor从单线程环境改为线程池环境,那么将会失去线程安全性。
- 对响应时间敏感的任务:GUI应用程序对于响应时间是敏感的:如果用户在点击按钮后需要很长延迟才能得到可见的反馈,那么他们会感到不满。如果将一个运行时间较长的任务提交到单线程的Executor中,或者将多个运行时间较长的任务提交到一个只包含少量线程的线程池中,那么将降低由该Executor管理的服务的响应性。
- 使用ThreadLocal的任务:只有当线程本地值的生命周期受限于任务的生命周期时,在线程池的线程中使用ThreadLocal才有意义,而在线程池的线程中不应该使用ThreadLocal在任务之间传递值。
- 只有当任务都是同类型的并且相互独立时,线程池的性能才能达到最佳。
- 如果将运行时间较长的与运行时间较短的任务混合在一起,那么除非线程池很大,否则将可能造成“拥塞”。
- 如果提交的任务依赖于其他任务,那么除非线程池无限大,否则将可能造成死锁。
- 如果某些任务依赖于其他的任务,那么会要求线程池足够大,从而确保它们依赖任务不会被放入等待队列中或被拒绝,而采用线程封闭机制的任务需要串行执行。通过将这些需求写入文档,将来的代码维护人员就不会由于使用了某种不合适的执行策略而破坏安全性或活跃性。
8.1.1 线程饥饿死锁
- 在线程池中,如果任务依赖于其他任务,那么可能产生死锁。
- 在单线程的Executor中,如果一个任务将另一个任务提交到同一个Executor,并且等待这个被提交任务的结果,那么通常会引发死锁。(秀,这个任务还没结束,提交的任务不会执行,这个任务又等待提交的任务结果,笑死)
- 在更大的线程池中,如果所有正在执行任务的线程都由于等待其他仍处于工作队列中的任务而阻塞,那么会发生同样的问题。
- 这种现象被称为线程饥饿死锁(Thread StarvationDeadlock),只要线程池中的任务需要无限期地等待一些必须由池中其他任务才能提供的资源或条件,例如某个任务等待另一个任务的返回值或执行结果,那么除非线程池足够大,否则将发生线程饥饿死锁。
- 每当提交了一个有依赖性的Executor任务时,要清楚地知道可能会出现线程“饥饿”死锁,因此需要在代码或配置Executor的配置文件中记录线程池的大小限制或配置限制。
- 除了在线程池大小上的显式限制外,还可能由于其他资源上的约束而存在一些隐式限制。如果应用程序使用一个包含10个连接的JDBC连接池,并且每个任务需要一个数据库连接,那么线程池就好像只有10个线程,因为当超过10个任务时,新的任务需要等待其他任务释放连接。
8.1.2 运行时间较长的任务
- 如果任务阻塞的时间过长,那么即使不出现死锁,线程池的响应性也会变得糟糕。
- 执行时间较长的任务不仅会造成线程池堵塞,甚至还会增加执行时间较短任务的服务时间。如果线程池中线程的数量远小于在稳定状态下执行时间较长任务的数量,那么到最后可能所有的线程都会运行这些执行时间较长的任务,从而影响整体的响应性。
- 限定任务等待资源的时间,而不要无限制地等待。在平台类库的大多数可阻塞方法中,都同时定义了限时版本和无限时版本,例如Thread.join、BlockingQueue.put、CountDownLatch.await以及Selector.select等。如果等待超时,那么可以把任务标识为失败,然后中止任务或者将任务重新放回队列以便随后执行。这样,无论任务的最终结果是否成功,这种办法都能确保任务总能继续执行下去,并将线程释放出来以执行一些能更快完成的任务。如果在线程池中总是充满了被阻塞的任务,那么也可能表明线程池的规模过小。
8.2 设置线程池的大小
- 线程池的理想大小取决于被提交任务的类型以及所部署系统的特性。在代码中通常不会固定线程池的大小,而应该通过某种配置机制来提供,或者根据Runtime.availableProcessors来动态计算。
- 幸运的是,要设置线程池的大小也并不困难,只需要避免“过大”和“过小”这两种极端情况。
- 如果线程池过大,那么大量的线程将在相对很少的CPU和内存资源上发生竞争,这不仅会导致更高的内存使用量,而且还可能耗尽资源。
- 如果线程池过小,那么将导致许多空闲的处理器无法执行工作,从而降低吞吐率。
- 要想正确地设置线程池的大小,必须分析计算环境、资源预算和任务的特性
- 对于计算密集型的任务,在拥有Ncpu个处理器的系统上,当线程池的大小为Ncpu+1时,通常能实现最优的利用率。
- 对于包含I/O操作或者其他阻塞操作的任务,由于线程并不会一直执行,因此线程池的规模应该更大。要正确地设置线程池的大小,你必须估算出任务的等待时间与计算时间的比值。这种估算不需要很精确,并且可以通过一些分析或监控工具来获得。你还可以通过另一种方法来调节线程池的大小:在某个基准负载下,分别设置不同大小的线程池来运行应用程序,并观察CPU利用率的水平。
- 计算内存、文件句柄、套接字句柄和数据库连接等资源对线程池的约束条件是更容易的:计算每个任务对该资源的需求量,然后用该资源的可用总量除以每个任务的需求量,所得结果就是线程池大小的上限。
- 当任务需要某种通过资源池来管理的资源时,例如数据库连接,那么线程池和资源池的大小将会相互影响。如果每个任务都需要一个数据库连接,那么连接池的大小就限制了线程池的大小。同样,当线程池中的任务是数据库连接的唯一使用者时,那么线程池的大小又将限制连接池的大小。
8.3 配置ThreadPoolExecutor
-
ThreadPoolExecutor为一些Executor提供了基本的实现,这些Executor是由Executors中的newCachedThreadPool、newFixedThreadPool和newScheduledThreadExecutor等工厂方法返回的.ThreadPoolExecutor是一个灵活的、稳定的线程池,允许进行各种定制。
-
如果默认的执行策略不能满足需求,那么可以通过ThreadPoolExecutor的构造函数来实例化一个对象,并根据自己的需求来定制,并且可以参考Executors的源代码来了解默认配置下的执行策略,然后再以这些执行策略为基础进行修改。
-
ThreadPoolExecutor定义了很多构造函数,在程序清单给出了最常见的形式。
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable>workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler){……}
8.3.1 线程的创建与销毁
- 线程池的基本大小(Core Pool Size)、最大大小(Maximum Pool Size)以及存活时间等因素共同负责线程的创建与销毁。
- 基本大小也就是线程池的目标大小,即在没有任务执行时[插图]线程池的大小,并且只有在工作队列满了的情况下才会创建超出这个数量的线程。
- 线程池的最大大小表示可同时活动的线程数量的上限。
- 如果某个线程的空闲时间超过了存活时间,那么将被标记为可回收的,并且当线程池的当前大小超过了基本大小时,这个线程将被终止。
- 通过调节线程池的基本大小和存活时间,可以帮助线程池回收空闲线程占有的资源,从而使得这些资源可以用于执行其他工作。
- newFixedThreadPool工厂方法将线程池的基本大小和最大大小设置为参数中指定的值,而且创建的线程池不会超时。
- newCachedThreadPool工厂方法将线程池的最大大小设置为Integer.MAX_VALUE,而将基本大小设置为零,并将超时设置为1分钟,这种方法创建出来的线程池可以被无限扩展,并且当需求降低时会自动收缩。
- 在创建ThreadPoolExecutor初期,线程并不会立即启动,而是等到有任务提交时才会启动,除非调用prestartAllCoreThreads。
- 开发人员以免有时会将线程池的基本大小设置为零,从而最终销毁工作者线程以免阻碍JVM的退出。然而,如果在线程池中没有使用SynchronousQueue作为其工作队列(例如在newCachedThreadPool中就是如此),那么这种方式将产生一些奇怪的行为。如果线程池中的线程数量等于线程池的基本大小,那么仅当在工作队列已满的情况下ThreadPoolExecutor才会创建新的线程。因此,如果线程池的基本大小为零并且其工作队列有一定的容量,那么当把任务提交给该线程池时,只有当线程池的工作队列被填满后,才会开始执行任务,而这种行为通常并不是我们所希望的。在Java 6中,可以通过allowCoreThreadTimeOut来使线程池中的所有线程超时。对于一个大小有限的线程池并且在该线程池中包含一个工作队列,如果希望这个线程池在没有任务的情况下能销毁所有线程,那么可以启用这个特性并将基本大小设置为零。
8.3.2 管理队列任务
- 在有限的线程池中会限制可并发执行的任务数量(单线程除外)。
- 如果新请求的到达速率超过了线程池的处理速率,那么新到来的请求将累积起来。在线程池中,这些请求会在一个由Executor管理的Runnable队列中等待,而不会像线程那样去竞争CPU资源。
- 即使请求的平均到达速率很稳定,也仍然会出现请求突增的情况。尽管队列有助于缓解任务的突增问题,但如果任务持续高速地到来,那么最终还是会抑制请求的到达率以避免耗尽内存。[插图]甚至在耗尽内存之前,响应性能也将随着任务队列的增长而变得越来越糟。
- ThreadPoolExecutor允许提供一个BlockingQueue来保存等待执行的任务。基本的任务排队方法有3种:无界队列、有界队列和同步移交(SynchronousHandoff)。
- newFixedThreadPool和newSingleThreadExecutor在默认情况下将使用一个无界的LinkedBlockingQueue。如果所有工作者线程都处于忙碌状态,那么任务将在队列中等候。如果任务持续快速地到达,并且超过了线程池处理它们的速度,那么队列将无限制地增加。
- 一种更稳妥的资源管理策略是使用有界队列,例如ArrayBlockingQueue、有界的LinkedBlockingQueue、PriorityBlockingQueue。有界队列有助于避免资源耗尽的情况发生,但它又带来了新的问题:当队列填满后,新的任务该怎么办?(有许多饱和策略[Saturation Policy]可以解决这个问题。请参见8.3.3节。)在使用有界的工作队列时,队列的大小与线程池的大小必须一起调节。如果线程池较小而队列较大,那么有助于减少内存使用量,降低CPU的使用率,同时还可以减少上下文切换,但付出的代价是可能会限制吞吐量。
- 对于非常大的或者无界的线程池,可以通过使用SynchronousQueue来避免任务排队,以及直接将任务从生产者移交给工作者线程。
- SynchronousQueue不是一个真正的队列,而是一种在线程之间进行移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接受这个元素。如果没有线程正在等待,并且线程池的当前大小小于最大值,那么ThreadPoolExecutor将创建一个新的线程,否则根据饱和策略,这个任务将被拒绝。
- 使用直接移交将更高效,因为任务会直接移交给执行它的线程,而不是被首先放在队列中,然后由工作者线程从队列中提取该任务。只有当线程池是无界的或者可以拒绝任务时,SynchronousQueue才有实际价值。在newCachedThreadPool工厂方法中就使用了SynchronousQueue。
- 当使用像LinkedBlockingQueue或ArrayBlockingQueue这样的FIFO(先进先出)队列时,任务的执行顺序与它们的到达顺序相同。如果想进一步控制任务执行顺序,还可以使用PriorityBlockingQueue,这个队列将根据优先级来安排任务。
- 对于Executor, newCachedThreadPool工厂方法是一种很好的默认选择,它能提供比固定大小的线程池更好的排队性能[插图]。当需要限制当前任务的数量以满足资源管理需求时,那么可以选择固定大小的线程池,就像在接受网络客户请求的服务器应用程序中,如果不进行限制,那么很容易发生过载问题。
- 只有当任务相互独立时,为线程池或工作队列设置界限才是合理的。如果任务之间存在依赖性,那么有界的线程池或队列就可能导致线程“饥饿”死锁问题。此时应该使用无界的线程池,例如newCachedThreadPool[插图]。
8.3.3 饱和策略
-
ThreadPoolExecutor的饱和策略可以通过调用setRejectedExecutionHandler来修改。
-
JDK提供了几种不同的RejectedExecutionHandler实现,每种实现都包含有不同的饱和策略:AbortPolicy、CallerRunsPolicy、DiscardPolicy和DiscardOldestPolicy。
-
“中止(Abort)”策略是默认的饱和策略。该策略将抛出未检查的RejectedExecution-Exception。调用者可以捕获这个异常,然后根据需求编写自己的处理代码。
-
当新提交的任务无法保存到队列中等待执行时,“抛弃(Discard)”策略会悄悄抛弃该任务。
-
“抛弃最旧的(Discard-Oldest)”策略则会抛弃下一个将被执行的任务,然后尝试重新提交新的任务。(如果工作队列是一个优先队列,那么“抛弃最旧的”策略将导致抛弃优先级最高的任务,因此最好不要将“抛弃最旧的”饱和策略和优先级队列放在一起使用。)
-
“调用者运行(Caller-Runs)”策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。。它不会在线程池的某个线程中执行新提交的任务,而是在一个调用了execute的线程中执行该任务。
-
我们可以将WebServer示例修改为使用有界队列和“调用者运行”饱和策略,当线程池中的所有线程都被占用,并且工作队列被填满后,下一个任务会在调用execute时在主线程中执行。由于执行任务需要一定的时间,因此主线程至少在一段时间内不能提交任何任务,从而使得工作者线程有时间来处理完正在执行的任务。在这期间,主线程不会调用accept,因此到达的请求将被保存在TCP层的队列中而不是在应用程序的队列中。如果持续过载,那么TCP层将最终发现它的请求队列被填满,因此同样会开始抛弃请求。当服务器过载时,这种过载情况会逐渐向外蔓延开来——从线程池到工作队列到应用程序再到TCP层,最终达到客户端,导致服务器在高负载下实现一种平缓的性能降低。
-
当创建Executor时,可以选择饱和策略或者对执行策略进行修改。程序给出了如何创建一个固定大小的线程池,同时使用“调用者运行”饱和策略。
ThreadPoolExecutor executor=new ThreadPoolExecutor(N_THREADS, N_THREADS,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(CAPACITY)); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); -
当工作队列被填满后,没有预定义的饱和策略来阻塞execute。然而,通过使用Semaphore(信号量)来限制任务的到达率,就可以实现这个功能。在程序清单的BoundedExecutor中给出了这种方法,该方法使用了一个无界队列(因为不能限制队列的大小和任务的到达率),并设置信号量的上界设置为线程池的大小加上可排队任务的数量,这是因为信号量需要控制正在执行的和等待执行的任务数量。
@ThreadSafepublic class BoundedExecutor{ private final Executor exec; private final Semaphore semaphore; public BoundedExecutor(Executor exec, int bound){ this.exec=exec; this.semaphore=new Semaphore(bound); } public void submitTask(final Runnable command)throws InterruptedException{ semaphore.acquire(); try{ exec.execute(new Runnable(){ public void run(){ try{ command.run(); }finally{ semaphore.release(); } } }); }catch(RejectedExecutionException e){ semaphore.release(); } } }
8.3.4 线程工厂
-
每当线程池需要创建一个线程时,都是通过线程工厂方法(请参见程序清单8-5)来完成的。
-
默认的线程工厂方法将创建一个新的、非守护的线程,并且不包含特殊的配置信息。在ThreadFactory中只定义了一个方法newThread,每当线程池需要创建一个新线程时都会调用这个方法。
-
通过指定一个线程工厂方法,可以定制线程池的配置信息。
-
在许多情况下都需要使用定制的线程工厂方法。例如,你希望为线程池中的线程指定一个UncaughtExceptionHandler,或者实例化一个定制的Thread类用于执行调试信息的记录。你还可能希望修改线程的优先级(这通常并不是一个好主意。请参见10.3.1节)或者守护状态(同样,这也不是一个好主意。请参见7.4.2节)。或许你只是希望给线程取一个更有意义的名称,用来解释线程的转储信息和错误日志。
-
在程序清单的MyThreadFactory中给出了一个自定义的线程工厂。它创建了一个新的MyAppThread实例,并将一个特定于线程池的名字传递给MyAppThread的构造函数,从而可以在线程转储和错误日志信息中区分来自不同线程池的线程。在应用程序的其他地方也可以使用MyAppThread,以便所有线程都能使用它的调试功能。
public class MyThreadFactory implements ThreadFactory{ private final String poolName; public MyThreadFactory(String poolName){ this.poolName=poolName; } public Thread newThread(Runnable runnable){ return new MyAppThread(runnable, poolName); } } -
在MyAppThread中还可以定制其他行为,如程序清单所示,包括:为线程指定名字,设置自定义UncaughtExceptionHandler向Logger中写入信息,维护一些统计信息(包括有多少个线程被创建和销毁),以及在线程被创建或者终止时把调试消息写入日志。
//定制Thread基类 public class MyAppThread extends Thread{ public static final String DEFAULT_NAME="MyAppThread"; private static volatile boolean debugLifecycle=false; private static final AtomicInteger created=new AtomicInteger(); private static final AtomicInteger alive=new AtomicInteger(); private static final Logger log=Logger.getAnonymousLogger(); public MyAppThread(Runnable r){ this(r, DEFAULT_NAME); } public MyAppThread(Runnable runnable, String name){ super(runnable, name+"-"+created.incrementAndGet()); setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler(){ public void uncaughtException(Thread t,Throwable e){ log.log(Level.SEVERE,"UNCAUGHT in thread"+t.getName(),e); } }); } public void run(){ //复制debug标志以确保一致的值 boolean debug=debugLifecycle; if(debug) log.log(Level.FINE,"Created"+getName()); try{ alive.incrementAndGet(); super.run(); }finally{ alive.decrementAndGet(); if(debug) log.log(Level.FINE,"Exiting"+getName()); } } public static int getThreadsCreated(){ return created.get(); } public static int getThreadsAlive(){ return alive.get(); } public static boolean getDebug(){ return debugLifecycle; } public static void setDebug(boolean b){ debugLifecycle=b; } } -
如果在应用程序中需要利用安全策略来控制对某些特殊代码库的访问权限,那么可以通过Executor中的privilegedThreadFactory工厂来定制自己的线程工厂。通过这种方式创建出来的线程,将与创建privilegedThreadFactory的线程拥有相同的访问权限、AccessControlContext和contextClassLoader.
-
如果不使用privilegedThreadFactory,线程池创建的线程将从在需要新线程时调用execute或submit的客户程序中继承访问权限,从而导致令人困惑的安全性异常。
8.3.5 在调用构造函数后再定制ThreadPoolExecutor
-
在调用完ThreadPoolExecutor的构造函数后,仍然可以通过设置函数(Setter)来修改大多数传递给它的构造函数的参数(例如线程池的基本大小、最大大小、存活时间、线程工厂以及拒绝执行处理器(Rejected Execution Handler)).
-
如果Executor是通过Executors中的某个(newSingleThreadExecutor除外)工厂方法创建的,那么可以将结果的类型转换为ThreadPoolExecutor以访问设置器,如程序清单8-8所示。
ExecutorService exec=Executors.newCachedThreadPool(); if(exec instanceof ThreadPoolExecutor) ((ThreadPoolExecutor)exec).setCorePoolSize(10); elsethrow new AssertionError("Oops, bad assumption"); -
在Executors中包含一个unconfigurableExecutorService工厂方法,该方法对一个现有的ExecutorService进行包装,使其只暴露出ExecutorService的方法,因此不能对它进行配置
-
newSingleThreadExecutor返回按这种方式封装的ExecutorService,而不是最初的ThreadPoolExecutor。虽然单线程的Executor实际上被实现为一个只包含唯一线程的线程池,但它同样确保了不会并发地执行任务。如果在代码中增加单线程Executor的线程池大小,那么将破坏它的执行语义。
-
你可以在自己的Executor中使用这项技术以防止执行策略被修改。如果将ExecutorService暴露给不信任的代码,又不希望对其进行修改,就可以通过unconfigurableExecutorService来包装它。
8.4 扩展ThreadPoolExecutor
-
ThreadPoolExecutor是可扩展的,它提供了几个可以在子类化中改写的方法:beforeExecute、afterExecute和terminated,这些方法可以用于扩展ThreadPoolExecutor的行为。
- 在执行任务的线程中将调用beforeExecute和afterExecute等方法,在这些方法中还可以添加日志、计时、监视或统计信息收集的功能。
- 无论任务是从run中正常返回,还是抛出一个异常而返回,afterExecute都会被调用。(如果任务在完成后带有一个Error,那么就不会调用afterExecute。)如果beforeExecute抛出一个RuntimeException,那么任务将不被执行,并且afterExecute也不会被调用。
- 在线程池完成关闭操作时调用terminated,也就是在所有任务都已经完成并且所有工作者线程也已经关闭后。terminated可以用来释放Executor在其生命周期里分配的各种资源,此外还可以执行发送通知、记录日志或者收集finalize统计信息等操作。
-
在程序清单8-9的TimingThreadPool中给出了一个自定义的线程池,它通过beforeExecute、afterExecute和terminated等方法来添加日志记录和统计信息收集。
//增加了日志和计时等功能的线程池 public class TimingThreadPool extends ThreadPoolExecutor{ private final ThreadLocal<Long>startTime=new ThreadLocal<Long>(); private final Logger log=Logger.getLogger("TimingThreadPool"); private final AtomicLong numTasks=new AtomicLong(); private final AtomicLong totalTime=new AtomicLong(); protected void beforeExecute(Thread t, Runnable r){ super.beforeExecute(t, r); log.fine(String.format("Thread%s:start%s",t, r)); startTime.set(System.nanoTime()); } protected void afterExecute(Runnable r, Throwable t){ try{ long endTime=System.nanoTime(); long taskTime=endTime-startTime.get(); numTasks.incrementAndGet(); totalTime.addAndGet(taskTime); log.fine(String.format("Thread%s:end%s, time=%dns",t, r,taskTime)); }finally{ super.afterExecute(r, t); } } protected void terminated(){ try{ log.info(String.format("Terminated:avg time=%dns",totalTime.get()/numTasks.get())); }finally{ super.terminated(); } } }- 为了测量任务的运行时间,beforeExecute必须记录开始时间并把它保存到一个afterExecute可以访问的地方。因为这些方法将在执行任务的线程中调用,因此beforeExecute可以把值保存到一个ThreadLocal变量中,然后由afterExecute来读取。
- 在TimingThreadPool中使用了两个AtomicLong变量,分别用于记录已处理的任务数和总的处理时间,并通过terminated来输出包含平均任务时间的日志消息。
8.5 递归算法的并行化
-
如果循环中的迭代操作都是独立的,并且不需要等待所有的迭代操作都完成再继续执行,那么就可以使用Executor将串行循环转化为并行循环,在程序清单8-10的processSequentially和processInParallel中给出了这种方法。
//将串行执行转换为并行执行 void processSequentially(List<Element>elements){ for(Element e:elements) process(e); } void processInParallel(Executor exec, List<Element>elements){ for(final Element e:elements) exec.execute(new Runnable(){ public void run(){ process(e); } }); } -
调用processInParallel比调用processSequentially能更快地返回,因为processInParallel会在所有下载任务都进入了Executor的队列后就立即返回,而不会等待这些任务全部完成.
-
如果需要提交一个任务集并等待它们完成,那么可以使用ExecutorService.invokeAll,并且在所有任务都执行完成后调用CompletionService来获取结果,如第6章的Renderer所示。
-
当串行循环中的各个迭代操作之间彼此独立,并且每个迭代操作执行的工作量比管理一个新任务时带来的开销更多,那么这个串行循环就适合并行化。
-
在一些递归设计中同样可以采用循环并行化的方法。在递归算法中通常都会存在串行循环,而且这些循环可以按照程序清单8-10的方式进行并行化。
-
一种简单的情况是:在每个迭代操作中都不需要来自于后续递归迭代的结果。例如,程序清单8-11的sequentialRecursive用深度优先算法遍历一棵树,在每个节点上执行计算并将结果放入一个集合。修改后的parallelRecursive同样执行深度优先遍历,但它并不是在访问节点时进行计算,而是为每个节点提交一个任务来完成计算。
public<T>void sequentialRecursive(List<Node<T>>nodes,Collection<T>results){ for(Node<T>n:nodes){ results.add(n.compute()); sequentialRecursive(n.getChildren(),results); } } public<T>void parallelRecursive(final Executor exec,List<Node<T>>nodes,final Collection<T>results){ for(final Node<T>n:nodes){ exec.execute(new Runnable(){ public void run(){ results.add(n.compute()); } }); parallelRecursive(exec, n.getChildren(),results); } } -
当parallelRecursive返回时,树中的各个节点都已经访问过了(但是遍历过程仍然是串行的,只有compute调用才是并行执行的),并且每个节点的计算任务也已经放入Executor的工作队列。parallelRecursive的调用者可以通过以下方式等待所有的结果:创建一个特定于遍历过程的Executor,并使用shutdown和awaitTermination等方法,如程序清单8-12所示。
//程序清单8-12 等待通过并行方式计算的结果 public<T>Collection<T>getParallelResults(List<Node<T>>nodes)throws InterruptedException{ ExecutorService exec=Executors.newCachedThreadPool(); Queue<T>resultQueue=new ConcurrentLinkedQueue<T>(); parallelRecursive(exec, nodes, resultQueue); exec.shutdown(); exec.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS); return resultQueue; }
8.5.1 示例:谜题框架。
-
示例:谜题框架。这项技术的一种强大应用就是解决一些谜题,这些谜题都需要找出一系列的操作从初始状态转换到目标状态,例如类似于“搬箱子”[插图]、“Hi-Q”、“四色方柱(Instant Insanity)”和其他的棋牌谜题。
-
我们将“谜题”定义为:包含了一个初始位置,一个目标位置,以及用于判断是否是有效移动的规则集。规则集包含两部分:计算从指定位置开始的所有合法移动,以及每次移动的结果位置。
-
在程序清单8-13给出了表示谜题的抽象类,其中的类型参数P和M表示位置类和移动类。根据这个接口,我们可以写一个简单的串行求解程序,该程序将在谜题空间(Puzzle Space)中查找,直到找到一个解答或者找遍了整个空间都没有发现答案。
//程序清单8-13 表示“搬箱子”之类谜题的抽象类 public interface Puzzle<P, M>{ P initialPosition(); boolean isGoal(P position); Set<M>legalMoves(P position); P move(P position, M move); } -
程序清单8-14中的Node代表通过一系列的移动到达的一个位置,其中保存了到达该位置的移动以及前一个Node。只要沿着Node链接逐步回溯,就可以重新构建出到达当前位置的移动序列。
//程序清单8-14 用于谜题解决框架的链表节点 @Immutablestatic class Node<P, M>{ final P pos; final M move; final Node<P, M>prev; Node(P pos, M move, Node<P, M>prev){ …… } List<M>asMoveList(){ List<M>solution=new LinkedList<M>(); for(Node<P, M>n=this;n.move!=null;n=n.prev) solution.add(0,n.move); return solution; } } -
在程序清单8-15的SequentialPuzzleSolver中给出了谜题框架的串行解决方案,它在谜题空间中执行一个深度优先搜索,当找到解答方案(不一定是最短的解决方案)后结束搜索。
//程序清单8-15 串行的谜题解答器 public class SequentialPuzzleSolver<P, M>{ private final Puzzle<P, M>puzzle; private final Set<P>seen=new HashSet<P>(); public SequentialPuzzleSolver(Puzzle<P, M>puzzle){ this.puzzle=puzzle; } public List<M>solve(){ P pos=puzzle.initialPosition(); return search(new Node<P, M>(pos, null, null)); } private List<M>search(Node<P, M>node){ if(!seen.contains(node.pos)){ seen.add(node.pos); if(puzzle.isGoal(node.pos)) return node.asMoveList(); for(M move:puzzle.legalMoves(node.pos)){ P pos=puzzle.move(node.pos, move); Node<P, M>child=new Node<P, M>(pos, move, node); List<M>result=search(child); if(result!=null) return result; } } return null; } static class Node<P, M>{ /*程序清单8-14*/ } } -
通过修改解决方案以利用并发性,可以以并行方式来计算下一步移动以及目标条件,因为计算某次移动的过程在很大程度上与计算其他移动的过程是相互独立的。(之所以说“在很大程度上”,是因为在各个任务之间会共享一些可变状态,例如已遍历位置的集合。)如果有多个处理器可用,那么这将减少寻找解决方案所花费的时间。
-
在程序清单8-16的ConcurrentPuzzleSolver中使用了一个内部类SolverTask,这个类扩展了Node并实现了Runnable。大多数工作都是在run方法中完成的:首先计算出下一步可能到达的所有位置,并去掉已经到达的位置,然后判断(这个任务或者其他某个任务)是否已经成功地完成,最后将尚未搜索过的位置提交给Executor。
//程序清单8-16 并发的谜题解答器 public class ConcurrentPuzzleSolver<P, M>{ private final Puzzle<P, M>puzzle; private final ExecutorService exec; private final ConcurrentMap<P, Boolean>seen; final ValueLatch<Node<P, M>>solution=new ValueLatch<Node<P, M>>(); …… public List<M>solve()throws InterruptedException{ try{ P p=puzzle.initialPosition(); exec.execute(newTask(p, null, null)); //阻塞直到找到解答 Node<P, M>solnNode=solution.getValue(); return(solnNode==null)?null:solnNode.asMoveList(); }finally{ exec.shutdown(); } } protected Runnable newTask(P p, M m, Node<P, M>n){ return new SolverTask(p, m,n); } class SolverTask extends Node<P, M>implements Runnable{ …… public void run(){ if(solution.isSet()||seen.putIfAbsent(pos, true)!=null) return; //已经找到了解答或者已经遍历了这个位置 if(puzzle.isGoal(pos)) solution.setValue(this); else for(M m:puzzle.legalMoves(pos)) exec.execute(newTask(puzzle.move(pos, m),m, this)); } } } -
为了避免无限循环,在串行版本中引入了一个Set对象,其中保存了之前已经搜索过的所有位置。在ConcurrentPuzzleSolver中使用ConcurrentHashMap来实现相同的功能。这种做法不仅提供了线程安全性,还避免了在更新共享集合时存在的竞态条件,因为putIfAbsent只有在之前没有遍历过的某个位置才会通过原子方式添加到集合中。ConcurrentPuzzleSolver使用线程池的内部工作队列而不是调用栈来保存搜索的状态。
-
这种并发方法引入了一种新形式的限制并去掉了一种原有的限制,新的限制在这个问题域中更合适。串行版本的程序执行深度优先搜索,因此搜索过程将受限于栈的大小。并发版本的程序执行广度优先搜索,因此不会受到栈大小的限制(但如果待搜索的或者已搜索的位置集合大小超过了可用的内存总量,那么仍可能耗尽内存)。
-
为了在找到某个解答后停止搜索,需要通过某种方式来检查是否有线程已经找到了一个解答。如果需要第一个找到的解答,那么还需要在其他任务都没有找到解答时更新解答。这些需求描述的是一种闭锁(Latch)机制(请参见5.5.1节),具体地说,是一种包含结果的闭锁。
-
通过使用第14章中的技术,可以很容易地构造出一个阻塞的并且可携带结果的闭锁,但更简单且更不容易出错的方式是使用现有库中的类,而不是使用底层的语言机制。在程序清单8-17的ValueLatch中使用CountDownLatch来实现所需的闭锁行为,并且使用锁定机制来确保解答只会被设置一次。
//程序清单8-17 由ConcurrentPuzzleSolver使用的携带结果的闭锁 @ThreadSafe public class ValueLatch<T>{ @GuardedBy("this")private T value=null; private final CountDownLatch done=new CountDownLatch(1); public boolean isSet(){ return(done.getCount()==0); } public synchronized void setValue(T newValue){ if(!isSet()){ value=newValue; done.countDown(); } } public T getValue()throws InterruptedException{ done.await(); synchronized(this){ return value; } } } -
每个任务首先查询solution闭锁,找到一个解答就停止。
-
而在此之前,主线程需要等待,ValueLatch中的getValue将一直阻塞,直到有线程设置了这个值。ValueLatch提供了一种方式来保存这个值,只有第一次调用才会设置它。调用者能够判断这个值是否已经被设置,以及阻塞并等候它被设置。在第一次调用setValue时,将更新解答方案,并且CountDownLatch会递减,从getValue中释放主线程。
-
第一个找到解答的线程还会关闭Executor,从而阻止接受新的任务。要避免处理RejectedExecutionException,需要将拒绝执行处理器设置为“抛弃已提交的任务”。然后,所有未完成的任务最终将执行完成,并且在执行任何新任务时都会失败,从而使Executor结束。(如果任务运行的时间过长,那么可以中断它们而不是等它们完成。)
-
如果不存在解答,那么ConcurrentPuzzleSolver就不能很好地处理这种情况:如果已经遍历了所有的移动和位置都没有找到解答,那么在getSolution调用中将永远等待下去。当遍历了整个搜索空间时,串行版本的程序将结束,但要结束并发程序会更困难。其中一种方法是:记录活动任务的数量,当该值为零时将解答设置为null,如程序清单8-18所示。
//程序清单8-18 在解决器中找不到解答 public class PuzzleSolver<P, M>extends ConcurrentPuzzleSolver<P, M>{ …… private final AtomicInteger taskCount=new AtomicInteger(0); protected Runnable newTask(P p, M m, Node<P, M>n){ return new CountingSolverTask(p, m,n); } class CountingSolverTask extends SolverTask{ CountingSolverTask(P pos, M move, Node<P, M>prev){ super(pos, move, prev); taskCount.incrementAndGet(); } public void run(){ try{ super.run(); }finally{ if(taskCount.decrementAndGet()==0)solution.setValue(null); } } } } -
找到解答的时间可能比等待的时间要长,因此在解决器中需要包含几个结束条件。其中一个结束条件是时间限制,这很容易实现:在ValueLatch中实现一个限时的getValue(其中将使用限时版本的await),如果getValue超时,那么关闭Executor并声明出现了一个失败。另一个结束条件是某种特定于谜题的标准,例如只搜索特定数量的位置。此外,还可以提供一种取消机制,由用户自己决定何时停止搜索。
小结
- 对于并发执行的任务,Executor框架是一种强大且灵活的框架。它提供了大量可调节的选项,例如创建线程和关闭线程的策略,处理队列任务的策略,处理过多任务的策略,并且提供了几个钩子方法来扩展它的行为。
- 然而,与大多数功能强大的框架一样,其中有些设置参数并不能很好地工作,某些类型的任务需要特定的执行策略,而一些参数组合则可能产生奇怪的结果。
第9章 图形用户界面应用程序
9.1 为什么GUI是单线程的
- 早期的GUI应用程序都是单线程的,并且GUI事件在“主事件循环”进行处理。当前的GUI框架则使用了一种略有不同的模型:在该模型中创建一个专门事件分发线程(Event Dispatch Thread, EDT)来处理GUI事件。
- 许多人曾经尝试过编写多线程的GUI框架,但最终都由于竞态条件和死锁导致的稳定性问题而又重新回到单线程的事件队列模型:采用一个专门的线程从队列中抽取事件,并将它们转发到应用程序定义的事件处理器。
- 在多线程的GUI框架中更容易发生死锁问题,其部分原因在于,在输入事件的处理过程与GUI组件的面向对象模型之间会存在错误的交互。
- 用户引发的动作将通过一种类似于“气泡上升”的方式从操作系统传递给应用程序——操作系统首先检测到一次鼠标点击,然后通过工具包将其转化为“鼠标点击”事件,该事件最终被转换为一个更高层事件(例如“鼠标键被按下”事件)转发给应用程序的监听器。另一方面,应用程序引发的动作又会以“气泡下沉”的方式从应用程序返回到操作系统。例如,在应用程序中引发修改某个组件背景色的请求,该请求将被转发给某个特定的组件类,并最终转发给操作系统进行绘制。因此,一方面这组操作将以完全相反的顺序来访问相同的GUI对象;另一方面又要确保每个对象都是线程安全的,从而导致不一致的锁定顺序,并引发死锁(请参见第10章)。这种问题几乎在每次开发GUI工具包时都会重现。
- 另一个在多线程GUI框架中导致死锁的原因就是“模型-视图-控制(MVC)”这种设计模式的广泛使用。通过将用户的交互分解到模型、视图和控制等模块中,能极大地简化GUI应用程序的实现,但这却进一步增加了出现不一致锁定顺序的风险。
- “控制”模块将调用“模型”模块,而“模型”模块将发生的变化通知给“视图”模块。“控制”模块同样可以调用“视图”模块,并调用“模型”模块来查询模型的状态。这将再次导致不一致的锁定顺序并出现死锁。
- 单线程的GUI框架通过线程封闭机制来实现线程安全性。所有GUI对象,包括可视化组件和数据模型等,都只能在事件线程中访问。当然,这只是将确保线程安全性的一部分工作交给应用程序的开发人员来负责,他们必须确保这些对象被正确地封闭在事件线程中。
9.1.1 串行事件处理
- GUI应用程序需要处理一些细粒度的事件,例如点击鼠标、按下键盘或定时器超时等。事件是另一种类型的任务,而AWT和Swing提供的事件处理机制在结构上也类似于Executor。
- 因为只有单个线程来处理所有的GUI任务,因此会采用依次处理的方式——处理完一个任务后再开始处理下一个任务,在两个任务的处理过程之间不会重叠。清楚了这一点,就可以更容易地编写任务代码,而无须担心其他任务会产生干扰。
- 串行任务处理不利之处在于,如果某个任务的执行时间很长,那么其他任务必须等到该任务执行结束。如果这些任务的工作是响应用户输入或者提供可视化的界面反馈,那么应用程序看似会失去响应。如果在事件线程中执行时间较长的任务,那么用户甚至无法点击“取消”按钮,因为在该这个任务完成之前,将无法调用“取消”按钮的监听器。因此,在事件线程中执行的任务必须尽快地把控制权交还给事件线程。要启动一些执行时间较长的任务,例如对某个大型文档执行拼写检查,在文件系统中执行搜索,或者通过网络获取资源等,必须在另一个线程中执行这些任务,从而尽快地将控制权交还给事件线程。如果要在执行某个时间较长的任务时更新进度标识,或者在任务完成后提供一个可视化的反馈,那么需要再次执行事件线程中的代码。这也很快会使程序变得更复杂。
9.1.2 Swing中的线程封闭机制
-
所有Swing组件(例如JButton和JTable)和数据模型对象(例如TableModel和TreeModel)都被封闭在事件线程中,因此任何访问它们的代码都必须在事件线程中运行。GUI对象并非通过同步来确保一致性,而是通过线程封闭机制。这种方法的好处在于,当访问表现对象(Presentation Object)时在事件线程中运行的任务无须担心同步问题,而坏处在于,无法从事件线程之外的线程中访问表现对象。
-
Swing的单线程规则是:Swing中的组件以及模型只能在这个事件分发线程中进行创建、修改以及查询。
-
与所有的规则相同,这个规则也存在一些例外情况。Swing中只有少数方法可以安全地从其他线程中调用:
- SwingUtilities.isEventDispatchThread,用于判断当前线程是否是事件线程。
- SwingUtilities.invokeLater,该方法可以将一个Runnable任务调度到事件线程中执行(可以从任意线程中调用)。
- SwingUtilities.invokeAndWait,该方法可以将一个Runnable任务调度到事件线程中执行,并阻塞当前线程直到任务完成(只能从非GUI线程中调用)。
- 所有将重绘(Repaint)请求或重生效(Revalidation)请求插入队列的方法(可从任意线程中调用)。
- ·所有添加或移除监听器的方法(这些方法可以从任意线程中调用,但监听器本身一定要在事件线程中调用)。
-
可以将Swing的事件线程视为一个单线程的Executor,它处理来自事件队列的任务。
-
与线程池一样,有时候工作者线程会死亡并由另一个新线程来替代,但这一切要对任务透明。如果所有任务的执行时间都很短,或者任务调度的可预见性并不重要,又或者任务不能被并发执行,那么应该采用串行的和单线程的执行策略。
-
程序清单9-2中的GuiExecutor是一个Executor,它将任务委托给SwingUtilities来执行。
//程序清单9-2 基于SwingUtilities构建的Executor public class GuiExecutor extends AbstractExecutorService{ //采用“单件(Singleton)”模式,有一个私有构造函数和一个公有的工厂方法 private static final GuiExecutor instance=new GuiExecutor(); private GuiExecutor(){ } public static GuiExecutor instance(){ return instance;} public void execute(Runnable r){ if(SwingUtilities.isEventDispatchThread()) r.run(); else SwingUtilities.invokeLater(r); } //其他生命周期方法的实现 }
9.2 短时间的GUI任务
-
短时间的任务可以把整个操作都放在事件线程中执行,而对于长时间的任务,则应该将某些操作放到另一个线程中执行。
-
程序清单9-3创建了一个按钮,它的颜色在被按下时会随机地变化。当用户点击按钮时,工具包将事件线程中的一个ActionEvent投递给所有已注册的ActionListener。作为响应,ActionListener将选择一个新的颜色,并将按钮的背景色设置为这个新颜色。这样,在GUI工具包中产生事件,然后发送到应用程序,而应用程序则通过修改GUI来响应用户的动作。在这期间,执行控制始终不会离开事件线程,如图9-1所示。
//程序清单9-3 简单的事件监听器 final Random random=new Random(); final JButton button=new JButton("Change Color"); …… button.addActionListener(new ActionListener(){ public void actionPerformed(ActionEvent e){ button.setBackground(new Color(random.nextInt())); } });
-
这个示例揭示了GUI应用程序和GUI工具包之间的主要交互。只要任务是短期的,并且只访问GUI对象(或者其他线程封闭或线程安全的应用程序对象),那么就可以基本忽略与线程相关的问题,而在事件线程中可以执行任何操作都不会出问题。
-
图9-2给出了一个略微复杂的版本,其中使用了正式的数据模型,例如TableModel或TreeModel。Swing将大多数可视化组件都分为两个对象,即模型对象与视图对象。在模型对象中保存的是将被显示的数据,而在视图对象中则保存了控制显示方式的规则。模型对象可以通过引发事件来表示模型数据发生了变化,而视图对象则通过“订阅”来接收这些事件。当视图对象收到表示模型数据已发生变化的事件时,将向模型对象查询新的数据,并更新界面显示。因此,在一个修改表格内容的按钮监听器中,事件监听器将更新模型并调用其中一个fireXxx方法,这个方法会依次调用视图对象中表格模型监听器,从而更新视图的显示。同样,执行控制权仍然不会离开事件线程。(Swing数据模型的fireXxx方法通常会直接调用模型监听器,而不会向线程队列中提交新的事件,因此fireXxx方法只能从事件线程中调用。)

9.3 长时间的GUI任务
-
可以创建自己的Executor来执行长时间的任务。对于长时间的任务,可以使用缓存线程池。只有GUI应用程序很少会发起大量的长时间任务,因此即使线程池可以无限制地增长也不会有太大的风险。
-
首先来看一个简单的任务,该任务不支持取消操作和进度指示,也不会在完成后更新GUI,我们之后再将这些功能依次添加进来。在程序清单9-4中给出了一个与某个可视化组件绑定的监听器,它将一个长时间的任务提交给一个Executor。尽管有两个层次的内部类,但通过这种方式使某个GUI任务启动另一个任务还是很简单的:在事件线程中调用UI动作监听器,然后将一个Runnable提交到线程池中执行。
//将一个长时间任务绑定到一个可视化组件 ExecutorService backgroundExec=Executors.newCachedThreadPool(); …… button.addActionListener(new ActionListener(){ public void actionPerformed(ActionEvent e){ backgroundExec.execute(new Runnable(){ public void run(){ doBigComputation(); } }); } }); -
这个示例通过“Fire and Forget”[1]方式将长时间任务从事件线程中分离出来,这种方式可能并不是非常有用。在执行完一个长时间的任务后,通常会产生某种可视化的反馈。但你并不能从后台线程中访问这些表现对象,因此任务在完成时必须向事件线程提交另一个任务来更新用户界面。
-
程序清单9-5给出了如何实现这个功能的方式,但此时已经开始变得复杂了,即已经有了三层的内部类。动作监听器首先使按钮无效,并设置一个标签表示正在进行某个计算,然后将一个任务提交给后台的Executor。当任务完成时,它会在事件线程中增加另一个任务,该任务将重新激活按钮并恢复标签文本。
//程序清单9-5 支持用户反馈的长时间任务 button.addActionListener(new ActionListener(){ public void actionPerformed(ActionEvent e){ button.setEnabled(false); label.setText("busy"); backgroundExec.execute(new Runnable(){ public void run(){ try{ doBigComputation(); }finally{ GuiExecutor.instance().execute(new Runnable(){ public void run(){ button.setEnabled(true); label.setText("idle"); } }); } } }); } }); -
在按下按钮时触发的任务中包含3个连续的子任务,它们将在事件线程与后台线程之间交替运行。第一个子任务更新用户界面,表示一个长时间的操作已经开始,然后在后台线程中启动第二个子任务。当第二个子任务完成时,它把第三个子任务再次提交到事件线程中运行,第三个子任务也会更新用户界面来表示操作已经完成。在GUI应用程序中,这种“线程接力”是处理长时间任务的典型方法。
9.3.1 取消
-
当某个任务在线程中运行了过长时间还没有结束时,用户可能希望取消它。你可以直接通过线程中断来实现取消操作,但是一种更简单的办法是使用Future,专门用来管理可取消的任务。
-
如果调用Future的cancel方法,并将参数mayInterruptIfRunning设置为true,那么这个Future可以中断正在执行任务的线程。如果你编写的任务能够响应中断,那么当它被取消时就可以提前返回。在程序清单9-6给出的任务中,将轮询线程的中断状态,并且在发现中断时提前返回。
//程序清单9-6 取消一个长时间任务 Future<?>runningTask=null; //线程封闭 …… startButton.addActionListener(new ActionListener(){ public void actionPerformed(ActionEvent e){ if(runningTask!=null){ runningTask=backgroundExec.submit(new Runnable(){ public void run(){ while(moreWork()){ if(Thread.currentThread().isInterrupted()){ cleanUpPartialWork(); break; } doSomeWork(); } } }); }; } }); cancelButton.addActionListener(new ActionListener(){ public void actionPerformed(ActionEvent event){ if(runningTask!=null) runningTask.cancel(true); } }); -
由于runningTask被封闭在事件线程中,因此在对它进行设置或检查时不需要同步,并且“开始”按钮的监听器可以确保每次只有一个后台任务在运行.
-
然而,当任务完成时最好能通知按钮监听器,例如说可以禁用“取消”按钮。我们将在下一节解决这个问题。
9.3.2 进度标识与完成标识
-
通过Future来表示一个长时间的任务,可以极大地简化取消操作的实现。在FutureTask中也有一个done方法同样有助于实现完成通知。当后台的Callable完成后,将调用done。
-
通过done方法在事件线程中触发一个完成任务,我们能够构造一个BackgroundTask类,这个类将提供一个在事件线程中调用的onCompletion方法,如程序清单9-7所示。
//程序清单9-7 支持取消,完成通知以及进度通知的后台任务类 abstract class BackgroundTask<V> implements Runnable, Future<V>{ private final FutureTask<V> computation=new Computation(); private class Computation extends FutureTask<V>{ public Computation(){ super(new Callable<V>(){ public V call()throws Exception{ //不是说最好不要隐式发布吗 return BackgroundTask.this.compute(); } }); } protected final void done(){ GuiExecutor.instance().execute(new Runnable(){ public void run(){ V value=null; Throwable thrown=null; boolean cancelled=false; try{ value=get(); }catch(ExecutionException e){ thrown=e.getCause(); }catch(CancellationException e){ cancelled=true; }catch(InterruptedException consumed){ }finally{ onCompletion(value, thrown, cancelled); } }; }); } } protected void setProgress(final int current, final int max){ GuiExecutor.instance().execute(new Runnable(){ public void run(){ onProgress(current, max); } }); } //在后台线程中被取消 protected abstract V compute()throws Exception; //在事件线程中被取消 protected void onCompletion(V result, Throwable exception,boolean cancelled){ } protected void onProgress(int current, int max){ } //Future的其他方法 } -
基于FutureTask构造的BackgroundTask还能简化取消操作。Compute不会检查线程的中断状态,而是调用Future.isCancelled。程序清单9-8通过BackgroundTask重新实现了程序清单9-6中的示例程序。
//程序清单9-8 通过BackgroundTask来执行长时间的并且可取消的任务 startButton.addActionListener(new ActionListener(){ public void actionPerformed(ActionEvent e){ class CancelListener implements ActionListener{ BackgroundTask<?>task; public void actionPerformed(ActionEvent event){ if(task!=null) task.cancel(true); } } final CancelListener listener=new CancelListener(); listener.task=new BackgroundTask<Void>(){ public Void compute(){ while(moreWork()&&!isCancelled()) doSomeWork(); return null; } public void onCompletion(boolean cancelled, String s,Throwable exception){ cancelButton.removeActionListener(listener); label.setText("done"); } }; cancelButton.addActionListener(listener); backgroundExec.execute(listener.task); } });
9.4 共享数据模型
- Swing的表现对象(包括TableModel和TreeModel等数据模型)都被封闭在事件线程中。
- 最简单的情况是,数据模型中的数据由用户来输入或者由应用程序在启动时静态地从文件或其他数据源加载。在这种情况下,除了事件线程之外的任何线程都不可能访问到数据。
- 但在某些情况下,表现模型对象只是一个数据源(例如数据库、文件系统或远程服务等)的视图对象。这时,当数据在应用程序中进出时,有多个线程都可以访问这些数据。
- 例如,你可以使用一个树形控件来显示远程文件系统的内容。在显示树形控件之前,并不需要枚举整个文件系统——那样做会消耗大量的时间和内存。正确的做法是,当树节点被展开时才读取相应的内容。即使只枚举远程卷上的单个目录也可能花费很长的时间,因此你可以考虑在后台任务中执行枚举操作。当后台任务完成后,必须通过某种方式将数据填充到树形模型中。
- 可以使用线程安全的树形模型来实现这个功能:通过invokeLater提交一个任务,将数据从后台任务中“推入”事件线程,或者让事件线程池通过轮询来查看是否有数据可用。
9.4.1 线程安全的数据模型
- 只要阻塞操作不会过度地影响响应性,那么多个线程操作同一份数据的问题都可以通过线程安全的数据模型来解决。
- 如果数据模型支持细粒度的并发,那么事件线程和后台线程就能共享该数据模型,而不会发生响应性问题。
- 线程安全的数据模型必须在更新模板时产生事件,这样视图才能在数据发生变化后进行更新。
- 有时候,在使用版本化数据模型时,例如CopyOnWriteArrayList[CPJ2.2.3.3],可能要同时获得线程安全性、一致性以及良好的响应性。
9.4.2 分解数据模型
- 如果在程序中既包含用于表示的数据模型,又包含应用程序特定的数据模型,那么这种应用程序就被称为拥有一种分解模型设计(Fowler,2005)。
- 表现模型会注册共享模型的监听器,从而在更新时得到通知。然后,表示模型可以在共享模型中得到更新:通过将相关状态的快照嵌入到更新消息中,或者由表现模型在收到更新事件时直接从共享模型中获取数据。
- 快照这种方法虽然简单,但却存在着一些局限。当数据模型很小,更新频率不高,并且这两个模型的结构相似时,它可以工作得良好。如果数据模型很大,或者更新频率极高,在分解模型包含的信息中有一方或双方对另一方不可见,那么更高效的方式是发送增量更新信息而不是发送一个完整的快照。
- 增量更新的另一个好处是,细粒度的变化信息可以提高显示的视觉效果——如果只有一辆车移动,那么只需更新发生变化的区域,而不用重绘整个显示图形。
- 如果一个数据模型必须被多个线程共享,而且由于阻塞、一致性或复杂度等原因而无法实现一个线程安全的模型时,可以考虑使用分解模型设计。
9.5 其他形式的单线程子系统
- 线程封闭不仅仅可以在GUI中使用,每当某个工具需要被实现为单线程子系统时,都可以使用这项技术。有时候,当程序员无法避免同步或死锁等问题时,也将不得不使用线程封闭。例如,一些原生库(Native Library)要求:所有对库的访问,甚至当通过System.loadLibrary来加载库时,都必须放在同一个线程中执行。
小结
- 所有GUI框架基本上都实现为单线程的子系统,其中所有与表现相关的代码都作为任务在事件线程中运行。
- 由于只有一个事件线程,因此运行时间较长的任务会降低GUI程序的响应性,所以应该放在后台线程中运行。
- 在一些辅助类(例如SwingWorker以及在本章中构建的BackgroundTask)中提供了对取消、进度指示以及完成指示的支持,因此对于执行时间较长的任务来说,无论在任务中包含了GUI组件还是非GUI组件,在开发时都可以得到简化。
第三部分 活跃性、性能与测试
第10章 避免活跃性危险
- 我们使用加锁机制来确保线程安全,但如果过度地使用加锁,则可能导致锁顺序死锁(Lock-Ordering Deadlock)。
- 同样,我们使用线程池和信号量来限制对资源的使用,但这些被限制的行为可能会导致资源死锁(Resource Deadlock)。
- Java应用程序无法从死锁中恢复过来,因此在设计时一定要排除那些可能导致死锁出现的条件。
10.1 死锁
- 经典的“哲学家进餐”问题:5个哲学家去吃中餐,坐在一张圆桌旁。他们有5根筷子(而不是5双),并且每两个人中间放一根筷子。哲学家们时而思考,时而进餐。每个人都需要一双筷子才能吃到东西,并在吃完后将筷子放回原处继续思考。
- 有些筷子管理算法能够使每个人都能相对及时地吃到东西(例如一个饥饿的哲学家会尝试获得两根邻近的筷子,但如果其中一根正在被另一个哲学家使用,那么他将放弃已经得到的那根筷子,并等待几分钟之后再次尝试),但有些算法却可能导致一些或者所有哲学家都“饿死”(每个人都立即抓住自己左边的筷子,然后等待自己右边的筷子空出来,但同时又不放下已经拿到的筷子)。后一种情况将产生死锁。
- 死锁:每个人都拥有其他人需要的资源,同时又等待其他人已经拥有的资源,并且每个人在获得所有需要的资源之前都不会放弃已经拥有的资源。(拥有-等待-不放弃)。
- 当一个线程永远地持有一个锁,并且其他线程都尝试获得这个锁时,那么它们将永远被阻塞。
- 最简单的死锁形式或者称为“抱死[Deadly Embrace]”:在线程A持有锁L并想获得锁M的同时,线程B持有锁M并尝试获得锁L,那么这两个线程将永远地等待下去。
- 在数据库系统的设计中考虑了监测死锁以及从死锁中恢复。在执行一个事务(Transaction)时可能需要获取多个锁,并一直持有这些锁直到事务提交。因此在两个事务之间很可能发生死锁,但事实上这种情况并不多见。如果没有外部干涉,那么这些事务将永远等待下去。
- 但数据库服务器不会让这种情况发生。当它检测到一组事务发生了死锁时(通过在表示等待关系的有向图中搜索循环),将选择一个牺牲者并放弃这个事务。作为牺牲者的事务会释放它所持有的资源,从而使其他事务继续进行。应用程序可以重新执行被强行中止的事务,而这个事务现在可以成功完成,因为所有跟它竞争资源的事务都已经完成了。
- JVM在解决死锁问题方面并没有数据库服务那样强大。当一组Java线程发生死锁时,“游戏”将到此结束——这些线程永远不能再使用了。根据线程完成工作的不同,可能造成应用程序完全停止,或者某个特定的子系统停止,或者是性能降低。恢复应用程序的唯一方式就是中止并重启它,并希望不要再发生同样的事情。(Java程序线程死锁没有恢复机制)
10.1.1 锁顺序死锁
-
程序清单10-1中的LeftRightDeadlock存在死锁风险。
//程序清单10-1 简单的锁顺序死锁(不要这么做) //注意:容易发生死锁! public class LeftRightDeadlock{ private final Object left=new Object(); private final Object right=new Object(); public void leftRight(){ synchronized(left){ synchronized(right){ doSomething(); } } } public void rightLeft(){ synchronized(right){ synchronized(left){ doSomethingElse(); } } } } -
leftRight和rightLeft这两个方法分别获得left锁和right锁。如果一个线程调用了leftRight,而另一个线程调用了rightLeft,并且这两个线程的操作是交错执行,如图10-1所示,那么它们会发生死锁。
-
在LeftRightDeadlock中发生死锁的原因是:两个线程试图以不同的顺序来获得相同的锁。
-
如果按照相同的顺序来请求锁,那么就不会出现循环的加锁依赖性,因此也就不会产生死锁。如果每个需要锁L和锁M的线程都以相同的顺序来获取L和M,那么就不会发生死锁了。
-
要想验证锁顺序的一致性,需要对程序中的加锁行为进行全局分析。如果只是单独地分析每条获取多个锁的代码路径,那是不够的:leftRight和rightLeft都采用了“合理的”方式来获得锁,它们只是不能相互兼容。当需要加锁时,它们需要知道彼此正在执行什么操作。
10.1.2 动态的锁顺序死锁
-
有时候,并不能清楚地知道是否在锁顺序上有足够的控制权来避免死锁的发生。考虑程序清单10-2中看似无害的代码,它将资金从一个账户转入另一个账户。在开始转账之前,首先要获得这两个Account对象的锁,以确保通过原子方式来更新两个账户中的余额,同时又不破坏一些不变性条件,例如“账户的余额不能为负数”:
//程序清单10-2 动态的锁顺序死锁(不要这么做) //注意:容易发生死锁! public void transferMoney(Account fromAccount,Account toAccount,DollarAmount amount)throws InsufficientFundsException{ synchronized(fromAccount){ synchronized(toAccount){ if(fromAccount.getBalance().compareTo(amount)<0) throw new InsufficientFundsException(); else{ fromAccount.debit(amount); toAccount.credit(amount); } } } } -
在transferMoney中如何发生死锁?所有的线程似乎都是按照相同的顺序来获得锁,但事实上锁的顺序取决于传递给transferMoney的参数顺序,而这些参数顺序又取决于外部输入。如果两个线程同时调用transferMoney,其中一个线程从X向Y转账,另一个线程从Y向X转账,那么就会发生死锁:
A:transferMoney(myAccount, yourAccount,10); B:transferMoney(yourAccount, myAccount,20); -
这种死锁可以采用程序清单10-1中的方法来检查——查看是否存在嵌套的锁获取操作。由于我们无法控制参数的顺序,因此要解决这个问题,必须定义锁的顺序,并在整个应用程序中都按照这个顺序来获取锁。
-
在制定锁的顺序时,可以使用System.identityHashCode方法,该方法将返回由Object.hashCode返回的值。程序清单10-3给出了另一个版本的transferMoney,在该版本中使用了System.identityHashCode来定义锁的顺序。虽然增加了一些新的代码,但却消除了发生死锁的可能性:
//程序清单10-3 通过锁顺序来避免死锁 private static final Object tieLock=new Object(); public void transferMoney(final Account fromAcct,final Account toAcct,final DollarAmount amount)throws InsufficientFundsException{ class Helper{ public void transfer()throws InsufficientFundsException{ if(fromAcct.getBalance().compareTo(amount)<0) throw new InsufficientFundsException(); else{ fromAcct.debit(amount); toAcct.credit(amount); } } } int fromHash=System.identityHashCode(fromAcct); int toHash=System.identityHashCode(toAcct); if(fromHash<toHash){ synchronized(fromAcct){ synchronized(toAcct){ new Helper().transfer(); } } } else if(fromHash>toHash){ synchronized(toAcct){ synchronized(fromAcct){ new Helper().transfer(); } } } else{ synchronized(tieLock){ synchronized(fromAcct){ synchronized(toAcct){ new Helper().transfer(); } } } } } -
在极少数情况下,两个对象可能拥有相同的散列值,此时必须通过某种任意的方法来决定锁的顺序,而这可能又会重新引入死锁。为了避免这种情况,可以使用“加时赛(Tie-Breaking)”锁。在获得两个Account锁之前,首先获得这个“加时赛”锁,从而保证每次只有一个线程以未知的顺序获得这两个锁,从而消除了死锁发生的可能性(只要一致地使用这种机制)。
-
如果在Account中包含一个唯一的、不可变的,并且具备可比性的键值,例如账号,那么要制定锁的顺序就更加容易了:通过键值对对象进行排序,因而不需要使用“加时赛”锁。
-
在典型条件下会发生死锁的循环
public class DemonstrateDeadlock{ private static final int NUM_THREADS=20; private static final int NUM_ACCOUNTS=5; private static final int NUM_ITERATIONS=1000000; public static void main(String[]args){ final Random rnd=new Random(); final Account[]accounts=new Account[NUM_ACCOUNTS]; for(int i=0;i<accounts.length;i++) accounts[i]=new Account(); class TransferThread extends Thread{ public void run(){ for(int i=0;i<NUM_ITERATIONS;i++){ int fromAcct=rnd.nextInt(NUM_ACCOUNTS); int toAcct=rnd.nextInt(NUM_ACCOUNTS); DollarAmount amount=new DollarAmount(rnd.nextInt(1000)); transferMoney(accounts[fromAcct],accounts[toAcct],amount); } } } for(int i=0;i<NUM_THREADS;i++) new TransferThread().start(); } }
10.1.3 在协作对象之间发生的死锁
-
某些获取多个锁的操作并不像在LeftRightDeadlock或transferMoney中那么明显,这两个锁并不一定必须在同一个方法中被获取。
-
考虑程序清单10-5中两个相互协作的类,在出租车调度系统中可能会用到它们。Taxi代表一个出租车对象,包含位置和目的地两个属性,Dispatcher代表一个出租车车队。
//程序清单10-5 在相互协作对象之间的锁顺序死锁(不要这么做) //注意:容易发生死锁! class Taxi{ @GuardedBy("this")private Point location, destination; private final Dispatcher dispatcher; public Taxi(Dispatcher dispatcher){ this.dispatcher=dispatcher; } public synchronized Point getLocation(){ return location; } public synchronized void setLocation(Point location){ this.location=location; if(location.equals(destination)) dispatcher.notifyAvailable(this); } } class Dispatcher{ @GuardedBy("this")private final Set<Taxi>taxis; @GuardedBy("this")private final Set<Taxi>availableTaxis; public Dispatcher(){ taxis=new HashSet<Taxi>(); availableTaxis=new HashSet<Taxi>(); } public synchronized void notifyAvailable(Taxi taxi){ availableTaxis.add(taxi); } public synchronized Image getImage(){ Image image=new Image(); for(Taxi t:taxis) image.drawMarker(t.getLocation()); return image; } } -
调用setLocation的线程将首先获取Taxi的锁,然后获取Dispatcher的锁;调用getImage的线程将首先获取Dispatcher锁,然后再获取每一个Taxi的锁(每次获取一个).两个方法获取同样锁的顺序不同,可能会出现死锁。
-
然而要在Taxi和Dispatcher中查找死锁则比较困难:如果在持有锁的情况下调用某个外部方法,那么就需要警惕死锁。
-
如果在持有锁时调用某个外部方法,那么将出现活跃性问题。在这个外部方法中可能会获取其他锁(这可能会产生死锁),或者阻塞时间过长,导致其他线程无法及时获得当前被持有的锁。
10.1.4 开放调用
-
如果在调用某个方法时不需要持有锁,那么这种调用被称为开放调用(OpenCall)[CPJ 2.4.1.3]。依赖于开放调用的类通常能表现出更好的行为,并且与那些在调用方法时需要持有锁的类相比,也更易于编写。
-
这种通过开放调用来避免死锁的方法,类似于采用封装机制来提供线程安全的方法:虽然在没有封装的情况下也能确保构建线程安全的程序,但对一个使用了封装的程序进行线程安全分析,要比分析没有使用封装的程序容易得多。同理,分析一个完全依赖于开放调用的程序的活跃性,要比分析那些不依赖开放调用的程序的活跃性简单。
-
通过尽可能地使用开放调用,将更易于找出那些需要获取多个锁的代码路径,因此也就更容易确保采用一致的顺序来获得锁。
-
可以很容易地将程序清单10-5中的Taxi和Dispatcher修改为使用开放调用,从而消除发生死锁的风险。这需要使同步代码块仅被用于保护那些涉及共享状态的操作,如程序清单10-6所示。
//程序清单10-6 通过公开调用来避免在相互协作的对象之间产生死锁 @ThreadSafe class Taxi{ @GuardedBy("this")private Point location, destination; private final Dispatcher dispatcher; …… public synchronized Point getLocation(){ return location; } public void setLocation(Point location){ boolean reachedDestination; synchronized(this){ this.location=location; reachedDestination=location.equals(destination); } //在获得下一个锁的时候,释放自己拥有的锁 if(reachedDestination) dispatcher.notifyAvailable(this); } } @ThreadSafe class Dispatcher{ @GuardedBy("this")private final Set<Taxi>taxis; @GuardedBy("this")private final Set<Taxi>availableTaxis; …… public synchronized void notifyAvailable(Taxi taxi){ availableTaxis.add(taxi); } public Image getImage(){ Set<Taxi>copy; synchronized(this){ //这个代价就有点大了 copy=new HashSet<Taxi>(taxis); } Image image=new Image(); for(Taxi t:copy) image.drawMarker(t.getLocation()); return image; } } -
通常,如果只是为了语法紧凑或简单性(而不是因为整个方法必须通过一个锁来保护)而使用同步方法(而不是同步代码块),那么就会导致程序清单10-5中的问题。(此外,收缩同步代码块的保护范围还可以提高可伸缩性,在11.4.1节中给出了如何确定同步代码块大小的方法。)
-
在程序中应尽量使用开放调用。与那些在持有锁时调用外部方法的程序相比,更易于对依赖于开放调用的程序进行死锁分析。
-
有时候,在重新编写同步代码块以使用开放调用时会产生意想不到的结果,因为这会使得某个原子操作变为非原子操作。
-
在许多情况下,使某个操作失去原子性是可以接受的。例如,对于两个操作:更新出租车位置以及通知调度程序这辆出租车已准备好出发去一个新的目的地,这两个操作并不需要实现为一个原子操作。在其他情况中,虽然去掉原子性可能会出现一些值得注意的结果,但这种语义变化仍然是可以接受的。
-
在容易产生死锁的版本中,getImage会生成某个时刻下的整个车队位置的完整快照,而在重新改写的版本中,getImage将获得每辆出租车不同时刻的位置。
-
然而,在某些情况下,丢失原子性会引发错误,此时需要通过另一种技术来实现原子性。
-
例如,在构造一个并发对象时,使得每次只有单个线程执行使用了开放调用的代码路径。例如,在关闭某个服务时,你可能希望所有正在运行的操作执行完成以后,再释放这些服务占用的资源。如果在等待操作完成的同时持有该服务的锁,那么将很容易导致死锁,但如果在服务关闭之前就释放服务的锁,则可能导致其他线程开始新的操作。
-
这个问题的解决方法是,在将服务的状态更新为“关闭”之前一直持有锁,这样其他想要开始新操作的线程,包括想关闭该服务的其他线程,会发现服务已经不可用,因此也就不会试图开始新的操作。然后,你可以等待关闭操作结束,并且知道当开放调用完成后,只有执行关闭操作的线程才能访问服务的状态。因此,这项技术依赖于构造一些协议(而不是通过加锁)来防止其他线程进入代码的临界区。
10.1.5 资源死锁
- 正如当多个线程相互持有彼此正在等待的锁而又不释放自己已持有的锁时会发生死锁,当它们在相同的资源集合上等待时,也会发生死锁。
- 另一种基于资源的死锁形式就是线程饥饿死锁(Thread-StarvationDeadlock):一个任务提交另一个任务,并等待被提交任务在单线程的Executor中执行完成。
- 如果某些任务需要等待其他任务的结果,那么这些任务往往是产生线程饥饿死锁的主要来源,有界线程池/资源池与相互依赖的任务不能一起使用。
10.2 死锁的诊断与避免
- 如果一个程序每次至多只能获得一个锁,那么就不会产生锁顺序死锁。
- 如果必须获取多个锁,那么在设计时必须考虑锁的顺序:尽量减少潜在的加锁交互数量,将获取锁时需要遵循的协议写入正式文档并始终遵循这些协议。
- 在使用细粒度锁的程序中,可以通过使用一种两阶段策略(Two-Part Strategy)来检查代码中的死锁:首先,找出在什么地方将获取多个锁(使这个集合尽量小),然后对所有这些实例进行全局分析,从而确保它们在整个程序中获取锁的顺序都保持一致。
- 尽可能地使用开放调用,这能极大地简化分析过程。
- 如果所有的调用都是开放调用,那么要发现获取多个锁的实例是非常简单的,可以通过代码审查,或者借助自动化的源代码分析工具。
10.2.1 支持定时的锁
- 还有一项技术可以检测死锁和从死锁中恢复过来,即显式使用Lock类中的定时tryLock功能(参见第13章)来代替内置锁机制。
- 当使用内置锁时,只要没有获得锁,就会永远等待下去,而显式锁则可以指定一个超时时限(Timeout),在等待超过该时间后tryLock会返回一个失败信息。如果超时时限比获取锁的时间要长很多,那么就可以在发生某个意外情况后重新获得控制权。
- 当定时锁失败时,你并不需要知道失败的原因。或许是因为发生了死锁,或许某个线程在持有锁时错误地进入了无限循环,还可能是某个操作的执行时间远远超过了你的预期。然而,至少你能记录所发生的失败,以及关于这次操作的其他有用信息,并通过一种更平缓的方式来重新启动计算,而不是关闭整个进程。
- 即使在整个系统中没有始终使用定时锁,使用定时锁来获取多个锁也能有效地应对死锁问题。
- 如果在获取锁时超时,那么可以释放这个锁,然后后退并在一段时间后再次尝试,从而消除了死锁发生的条件,使程序恢复过来。(这项技术只有在同时获取两个锁时才有效,如果在嵌套的方法调用中请求多个锁,那么即使你知道已经持有了外层的锁,也无法释放它。)
10.2.2 通过线程转储信息来分析死锁
-
虽然防止死锁的主要责任在于你自己,但JVM仍然通过线程转储(ThreadDump)来帮助识别死锁的发生。线程转储包括各个运行中的线程的栈追踪信息,这类似于发生异常时的栈追踪信息。线程转储还包含加锁信息,例如每个线程持有了哪些锁,在哪些栈帧中获得这些锁,以及被阻塞的线程正在等待获取哪一个锁。
-
在生成线程转储之前,JVM将在等待关系图中通过搜索循环来找出死锁。如果发现了一个死锁,则获取相应的死锁信息,例如在死锁中涉及哪些锁和线程,以及这个锁的获取操作位于程序的哪些位置。
-
(kill-3),或者在UNIX平台中按下Ctrl-\键,在Windows平台中按下Ctrl-Break键。在许多IDE(集成开发环境)中都可以请求线程转储。
-
内置锁与获得它们所在的线程栈帧是相关联的,而显式的Lock只与获得它的线程相关联。
-
程序清单10-7给出了一个J2EE应用程序中获取的部分线程转储信息。在导致死锁的故障中包括3个组件:一个J2EE应用程序,一个J2EE容器,以及一个JDBC驱动程序,分别由不同的生产商提供。这3个组件都是商业产品,并经过了大量的测试,但每一个组件中都存在一个错误,并且这个错误只有当它们进行交互时才会显现出来,并导致服务器出现一个严重的故障。
Found one Java-level deadlock: ============================= "ApplicationServerThread": waiting to lock monitor 0x080f0cdc(a MumbleDBConnection), which is held by"ApplicationServerThread" "ApplicationServerThread": waiting to lock monitor 0x080f0ed4(a MumbleDBCallableStatement), which is held by"ApplicationServerThread" Java stack information for the threads listed above: "ApplicationServerThread": at MumbleDBConnection.remove_statement -waiting to lock<0x650f7f30>(a MumbleDBConnection) at MumbleDBStatement.close -locked<0x6024ffb0>(a MumbleDBCallableStatement) …… "ApplicationServerThread": at MumbleDBCallableStatement.sendBatch -waiting to lock<0x6024ffb0>(a MumbleDBCallableStatement) at MumbleDBConnection.commit -locked<0x650f7f30>(a MumbleDBConnection) ……
10.3 其他活跃性危险
- 尽管死锁是最常见的活跃性危险,但在并发程序中还存在一些其他的活跃性危险,包括:饥饿、丢失信号和活锁等。(“丢失信号”这种活跃性危险将在14.2.3节中介绍。)
10.3.1 饥饿
- 当线程由于无法访问它所需要的资源而不能继续执行时,就发生了“饥饿(Starvation)”
- 。引发饥饿的最常见资源就是CPU时钟周期。如果在Java应用程序中对线程的优先级使用不当,或者在持有锁时执行一些无法结束的结构(例如无限循环,或者无限制地等待某个资源),那么也可能导致饥饿,因为其他需要这个锁的线程将无法得到它。
- 通常,我们尽量不要改变线程的优先级。只要改变了线程的优先级,程序的行为就将与平台相关,并且会导致发生饥饿问题的风险。你经常能发现某个程序会在一些奇怪的地方调用Thread.sleep或Thread.yield,这是因为该程序试图克服优先级调整问题或响应性问题,并试图让低优先级的线程执行更多的时间
- 要避免使用线程优先级,因为这会增加平台依赖性,并可能导致活跃性问题。在大多数并发应用程序中,都可以使用默认的线程优先级。
10.3.2 糟糕的响应性
- 除饥饿以外的另一个问题是糟糕的响应性,如果在GUI应用程序中使用了后台线程,那么这种问题是很常见的
- CPU密集型的后台任务仍然可能对响应性造成影响,因为它们会与事件线程共同竞争CPU的时钟周期。在这种情况下就可以发挥线程优先级的作用,此时计算密集型的后台任务将对响应性造成影响。如果由其他线程完成的工作都是后台任务,那么应该降低它们的优先级,从而提高前台程序的响应性。
- 不良的锁管理也可能导致糟糕的响应性。如果某个线程长时间占有一个锁(或许正在对一个大容器进行迭代,并且对每个元素进行计算密集的处理),而其他想要访问这个容器的线程就必须等待很长时间。
10.3.3 活锁
- 活锁(Livelock)是另一种形式的活跃性问题,该问题尽管不会阻塞线程,但也不能继续执行,因为线程将不断重复执行相同的操作,而且总会失败。
- 活锁通常发生在处理事务消息的应用程序中:如果不能成功地处理某个消息,那么消息处理机制将回滚整个事务,并将它重新放到队列的开头。
- 如果消息处理器在处理某种特定类型的消息时存在错误并导致它失败,那么每当这个消息从队列中取出并传递到存在错误的处理器时,都会发生事务回滚。由于这条消息又被放回到队列开头,因此处理器将被反复调用,并返回相同的结果。(有时候也被称为毒药消息,PoisonMessage。)虽然处理消息的线程并没有阻塞,但也无法继续执行下去。这种形式的活锁通常是由过度的错误恢复代码造成的,因为它错误地将不可修复的错误作为可修复的错误。
- 当多个相互协作的线程都对彼此进行响应从而修改各自的状态,并使得任何一个线程都无法继续执行时,就发生了活锁:这就像两个过于礼貌的人在半路上面对面地相遇:他们彼此都让出对方的路,然而又在另一条路上相遇了。因此他们就这样反复地避让下去。
- 要解决这种活锁问题,需要在重试机制中引入随机性:
- 例如,在网络上,如果两台机器尝试使用相同的载波来发送数据包,那么这些数据包就会发生冲突。这两台机器都检查到了冲突,并都在稍后再次重发。如果二者都选择了在1秒钟后重试,那么它们又会发生冲突,并且不断地冲突下去,因而即使有大量闲置的带宽,也无法使数据包发送出去
- 为了避免这种情况发生,需要让它们分别等待一段随机的时间。(以太协议定义了在重复发生冲突时采用指数方式回退机制,从而降低在多台存在冲突的机器之间发生拥塞和反复失败的风险。)在并发应用程序中,通过等待随机长度的时间和回退可以有效地避免活锁的发生。
小结
- 活跃性故障是一个非常严重的问题,因为当出现活跃性故障时,除了中止应用程序之外没有其他任何机制可以帮助从这种故障时恢复过来。
- 最常见的活跃性故障就是锁顺序死锁。
- 在设计时应该避免产生锁顺序死锁:确保线程在获取多个锁时采用一致的顺序。
- 最好的解决方法是在程序中始终使用开放调用。这将大大减少需要同时持有多个锁的地方,也更容易发现这些地方。
第11章 性能与可伸缩性
- 线程的最主要目的是提高程序的运行性能。
- 线程的最主要目的是提高程序的运行性能[1]。线程可以使程序更加充分地发挥系统的可用处理能力,从而提高系统的资源利用率。此外,线程还可以使程序在运行现有任务的情况下立即开始处理新的任务,从而提高系统的响应性。
- 然而,许多提升性能的技术同样会增加复杂性,因此也就增加了在安全性和活跃性上发生失败的风险。
- 虽然我们希望获得更好的性能——提升性能总会令人满意,但始终要把安全性放在第一位。首先要保证程序能正确运行,然后仅当程序的性能需求和测试结果要求程序执行得更快时,才应该设法提高它的运行速度。
- 在设计并发的应用程序时,最重要的考虑因素通常并不是将程序的性能提升至极限。
11.1 对性能的思考
- 提升性能意味着用更少的资源做更多的事情。
- 当操作性能由于某种特定的资源而受到限制时,我们通常将该操作称为资源密集型的操作,例如,CPU密集型、数据库密集型等。
- 尽管使用多个线程的目标是提升整体性能,但与单线程的方法相比,使用多个线程总会引入一些额外的性能开销。造成这些开销的操作包括:线程之间的协调(例如加锁、触发信号以及内存同步等),增加的上下文切换,线程的创建和销毁,以及线程的调度等。
- 如果过度地使用线程,那么这些开销甚至会超过由于提高吞吐量、响应性或者计算能力所带来的性能提升。
- 要想通过并发来获得更好的性能,需要努力做好两件事情:更有效地利用现有处理资源,以及在出现新的处理资源时使程序尽可能地利用这些新资源。从性能监视的视角来看,CPU需要尽可能保持忙碌状态。
11.1.1 性能与可伸缩性
- 应用程序的性能可以采用多个指标来衡量,例如服务时间、延迟时间、吞吐率、效率、可伸缩性以及容量等。
- 可伸缩性指的是:当增加计算资源时(例如CPU、内存、存储容量或I/O带宽),程序的吞吐量或者处理能力能相应地增加。
- 在并发应用程序中针对可伸缩性进行设计和调整时所采用的方法与传统的性能调优方法截然不同。
- 当进行性能调优时,其目的通常是用更小的代价完成相同的工作,例如通过缓存来重用之前计算的结果,或者采用时间复杂度为O(n2)算法来代替复杂度为O(n log n)的算法。
- 在进行可伸缩性调优时,其目的是设法将问题的计算并行化,从而能利用更多的计算资源来完成更多的工作。
- 性能的这两个方面——“多快”和“多少”,是完全独立的,有时候甚至是相互矛盾的。要实现更高的可伸缩性或硬件利用率,通常会增加各个任务所要处理的工作量,例如把任务分解为多个“流水线”子任务时。
- 我们熟悉的三层程序模型,即在模型中的表现层、业务逻辑层和持久化层是彼此独立的,并且可能由不同的系统来处理,这很好地说明了提高可伸缩性通常会造成性能损失的原因。如果把表现层、业务逻辑层和持久化层都融合到单个应用程序中,那么在处理第一个工作单元时,其性能肯定要高于将应用程序分为多层并将不同层次分布到多个系统时的性能。这种单一的应用程序避免了在不同层次之间传递任务时存在的网络延迟,同时也不需要将计算过程分解到不同的抽象层次,因此能减少许多开销(例如在任务排队、线程协调以及数据复制时存在的开销)。
- 然而,当这种单一的系统到达自身处理能力的极限时,会遇到一个严重的问题:要进一步提升它的处理能力将非常困难。因此,我们通常会接受每个工作单元执行更长的时间或消耗更多的计算资源,以换取应用程序在增加更多资源的情况下处理更高的负载。
- 对于服务器应用程序来说,“多少”这个方面——可伸缩性、吞吐量和生产量,往往比“多快”这个方面更受重视。
11.1.2 评估各种性能权衡因素
- 避免不成熟的优化。首先使程序正确,然后再提高运行速度——如果它还运行得不够快。
- 当进行决策时,有时候会通过增加某种形式的成本来降低另一种形式的开销(例如,增加内存使用量以降低服务时间),也会通过增加开销来换取安全性。
- 在对性能的调优时,一定要有明确的性能需求(这样才能知道什么时候需要调优,以及什么时候应该停止),此外还需要一个测试程序以及真实的配置和负载等环境。
- 以测试为基准,不要猜测。
11.2 Amdahl定律
-
Amdahl定义了理论上的并行程序与串行程序相比的加速关系。
-
Amdahl定律描述的是:在增加计算资源的情况下,程序在理论上能够实现最高加速比,这个值取决于程序中可并行组件与串行组件所占的比重。假定F是必须被串行执行的部分,那么根据Amdahl定律,在包含N个处理器的机器中,最高的加速比为:
S p e e d u p < = 1 / ( F + ( 1 − F ) / N ) Speedup <= 1/(F+(1-F)/N) Speedup<=1/(F+(1−F)/N) -
要预测应用程序在某个多处理器系统中将实现多大的加速比,还需要找出任务中的串行部分。
-
假设应用程序中N个线程正在执行程序清单11-1中的doWork,这些线程从一个共享的工作队列中取出任务进行处理,而且这里的任务都不依赖于其他任务的执行结果或影响。
//程序清单11-1 对任务队列的串行访问 public class WorkerThread extends Thread{ private final BlockingQueue<Runnable>queue; public WorkerThread(BlockingQueue<Runnable>queue){ this.queue=queue; } public void run(){ while(true){ try{ Runnable task=queue.take(); task.run(); }catch(InterruptedException e){ break; /*允许线程退出*/ } } } }- 初看上去,这个程序似乎能完全并行化:各个任务之间不会相互等待,因此处理器越多,能够并发处理的任务也就越多。然而,在这个过程中包含了一个串行部分——从队列中获取任务。
- 所有工作者线程都共享同一个工作队列,因此在对该队列进行并发访问时需要采用某种同步机制来维持队列的完整性。如果通过加锁来保护队列的状态,那么当一个线程从队列中取出任务时,其他需要获取下一个任务的线程就必须等待,这就是任务处理过程中的串行部分。
- 这个示例还忽略了另一种常见的串行操作:对结果进行处理。所有有用的计算都会生成某种结果或者产生某种效应——如果不会,那么可以将它们作为“死亡代码”删除掉。由于Runnable没有提供明确的结果处理过程,因此这些任务一定会产生某种效果,例如将它们的结果写入到日志或者保存到某个数据结构。
- 通常,日志文件和结果容器都会由多个工作者线程共享,并且这也是一个串行部分。如果所有线程都将各自的计算结果保存到自行维护数据结构中,并且在所有任务都执行完成后再合并所有的结果,那么这种合并操作也是一个串行部分。
-
在所有并发程序中都包含一些串行部分。
11.2.1 示例:在各种框架中隐藏的串行部分
- 吞吐量的差异来源于两个队列中不同比例的串行部分。同步的LinkedList采用单个锁来保护整个队列的状态,并且在offer和remove等方法的调用期间都将持有这个锁。ConcurrentLinkedQueue使用了一种更复杂的非阻塞队列算法(请参见15.4.2节),该算法使用原子引用来更新各个链接指针。
11.2.2 Amdahl定律的应用
- 如果能准确估计出执行过程中串行部分所占的比例,那么Amdahl定律就能量化当有更多计算资源可用时的加速比。
- 在评估一个算法时,要考虑算法在数百个或数千个处理器的情况下的性能表现,从而对可能出现的可伸缩性局限有一定程度的认识。
- 例如,在11.4.2节和11.4.3节中介绍了两种降低锁粒度的技术:锁分解(将一个锁分解为两个锁)和锁分段(把一个锁分解为多个锁)。当通过Amdahl定律来分析这两项技术时,我们会发现,如果将一个锁分解为两个锁,似乎并不能充分利用多处理器的能力。锁分段技术似乎更有前途,因为分段的数量可随着处理器数量的增加而增加。
11.3 线程引入的开销
- 在多个线程的调度和协调过程中都需要一定的性能开销:对于为了提升性能而引入的线程来说,并行带来的性能提升必须超过并发导致的开销。
11.3.1 上下文切换
- 如果可运行的线程数大于CPU的数量,那么操作系统最终会将某个正在运行的线程调度出来,从而使其他线程能够使用CPU。这将导致一次上下文切换,在这个过程中将保存当前运行线程的执行上下文,并将新调度进来的线程的执行上下文设置为当前上下文。
- 切换上下文需要一定的开销,而在线程调度过程中需要访问由操作系统和JVM共享的数据结构。应用程序、操作系统以及JVM都使用一组相同的CPU。在JVM和操作系统的代码中消耗越多的CPU时钟周期,应用程序的可用CPU时钟周期就越少。
- 当一个新的线程被切换进来时,它所需要的数据可能不在当前处理器的本地缓存中,因此上下文切换将导致一些缓存缺失,因而线程在首次调度运行时会更加缓慢。这就是为什么调度器会为每个可运行的线程分配一个最小执行时间,即使有许多其他的线程正在等待执行:它将上下文切换的开销分摊到更多不会中断的执行时间上,从而提高整体的吞吐量(以损失响应性为代价)。
- 当线程由于等待某个发生竞争的锁而被阻塞时,JVM通常会将这个线程挂起,并允许它被交换出去。如果线程频繁地发生阻塞,那么它们将无法使用完整的调度时间片。在程序中发生越多的阻塞(包括阻塞I/O,等待获取发生竞争的锁,或者在条件变量上等待),与CPU密集型的程序就会发生越多的上下文切换,从而增加调度开销,并因此而降低吞吐量。
- 上下文切换的实际开销会随着平台的不同而变化,然而按照经验来看:在大多数通用的处理器中,上下文切换的开销相当于5 000~10000个时钟周期,也就是几微秒。
- UNIX系统的vmstat命令和Windows系统的perfmon工具都能报告上下文切换次数以及在内核中执行时间所占比例等信息。如果内核占用率较高(超过10%),那么通常表示调度活动发生得很频繁,这很可能是由I/O或竞争锁导致的阻塞引起的。
11.3.2 内存同步
- 同步操作的性能开销包括多个方面。在synchronized和volatile提供的可见性保证中可能会使用一些特殊指令,即内存栅栏(Memory Barrier)。
- 内存栅栏可以刷新缓存,使缓存无效,刷新硬件的写缓冲,以及停止执行管道。内存栅栏可能同样会对性能带来间接的影响,因为它们将抑制一些编译器优化操作。在内存栅栏中,大多数操作都是不能被重排序的。
- 在评估同步操作带来的性能影响时,区分有竞争的同步和无竞争的同步非常重要。
- 现代的JVM能通过优化来去掉一些不会发生竞争的锁,从而减少不必要的同步开销。
- 一些更完备的JVM能通过逸出分析(Escape Analysis)来找出不会发布到堆的本地对象引用(因此这个引用是线程本地的)。
- 即使不进行逸出分析,编译器也可以执行锁粒度粗化(Lock Coarsening)操作,即将邻近的同步代码块用同一个锁合并起来。
- 不要过度担心非竞争同步带来的开销。这个基本的机制已经非常快了,并且JVM还能进行额外的优化以进一步降低或消除开销。因此,我们应该将优化重点放在那些发生锁竞争的地方。
- 某个线程中的同步可能会影响其他线程的性能。同步会增加共享内存总线上的通信量,总线的带宽是有限的,并且所有的处理器都将共享这条总线。如果有多个线程竞争同步带宽,那么所有使用了同步的线程都会受到影响。
11.3.3 阻塞
- 非竞争的同步可以完全在JVM中进行处理(Bacon等,1998),而竞争的同步可能需要操作系统的介入,从而增加开销。
- 当在锁上发生竞争时,竞争失败的线程肯定会阻塞。JVM在实现阻塞行为时,可以采用自旋等待(Spin-Waiting,指通过循环不断地尝试获取锁,直到成功)或者通过操作系统挂起被阻塞的线程。
- 这两种方式的效率高低,要取决于上下文切换的开销以及在成功获取锁之前需要等待的时间。如果等待时间较短,则适合采用自旋等待方式,而如果等待时间较长,则适合采用线程挂起方式。有些JVM将根据对历史等待时间的分析数据在这两者之间进行选择,但是大多数JVM在等待锁时都只是将线程挂起。
- 当线程无法获取某个锁或者由于在某个条件等待或在I/O操作上阻塞时,需要被挂起,在这个过程中将包含两次额外的上下文切换,以及所有必要的操作系统操作和缓存操作:被阻塞的线程在其执行时间片还未用完之前就被交换出去,而在随后当要获取的锁或者其他资源可用时,又再次被切换回来。(由于锁竞争而导致阻塞时,线程在持有锁时将存在一定的开销:当它释放锁时,必须告诉操作系统恢复运行阻塞的线程。)
11.4 减少锁的竞争
- 串行操作会降低可伸缩性,并且上下文切换也会降低性能。在锁上发生竞争时将同时导致这两种问题,因此减少锁的竞争能够提高性能和可伸缩性。
- 在并发程序中,对可伸缩性的最主要威胁就是独占方式的资源锁。
- 有两个因素将影响在锁上发生竞争的可能性:锁的请求频率,以及每次持有该锁的时间。
- 如果二者的乘积很小,那么大多数获取锁的操作都不会发生竞争,因此在该锁上的竞争不会对可伸缩性造成严重影响。
- 然而,如果在锁上的请求量很高,那么需要获取该锁的线程将被阻塞并等待。在极端情况下,即使仍有大量工作等待完成,处理器也会被闲置。
- 有3种方式可以降低锁的竞争程度:
- 减少锁的持有时间。
- 降低锁的请求频率。
- 使用带有协调机制的独占锁,这些机制允许更高的并发性。
11.4.1 缩小锁的范围(快进快出)
-
降低发生竞争可能性的一种有效方式就是尽可能缩短锁的持有时间。例如,可以将一些与锁无关的代码移出同步代码块,尤其是那些开销较大的操作,以及可能被阻塞的操作,例如I/O操作。
-
程序清单11-4给出了一个示例,其中锁被持有过长的时间。userLocationMatches方法在一个Map对象中查找用户的位置,并使用正则表达式进行匹配以判断结果值是否匹配所提供的模式。整个userLocationMatches方法都使用了synchronized来修饰,但只有Map.get这个方法才真正需要锁。
//程序清单11-4 将一个锁不必要地持有过长时间 @ThreadSafe public class AttributeStore{ @GuardedBy("this")private final Map<String, String>attributes=new HashMap<String, String>(); public synchronized boolean userLocationMatches(String name,String regexp){ String key="users."+name+".location"; //只有这一操作才需要锁,确保得到的是有有效值;如果是背包类型,甚至不需要加锁 String location=attributes.get(key); if(location==null) return false; else return Pattern.matches(regexp, location); } } -
在程序清单11-5的BetterAttributeStore中重新编写了AttributeStore,从而大大减少了锁的持有时间。
// 程序清单11-5 减少锁的持有时间 @ThreadSafe public class BetterAttributeStore{ @GuardedBy("this")private final Map<String, String>attributes=new HashMap<String, String>(); public boolean userLocationMatches(String name, String regexp){ String key="users."+name+".location"; String location; synchronized(this){ location=attributes.get(key); } if(location==null) return false; else return Pattern.matches(regexp, location); } } -
通过缩小userLocationMatches方法中锁的作用范围,能极大地减少在持有锁时需要执行的指令数量。根据Amdahl定律,这样消除了限制可伸缩性的一个因素,因为串行代码的总量减少了。
-
由于在AttributeStore中只有一个状态变量attributes,因此可以通过将线程安全性委托给其他的类来进一步提升它的性能(参见4.3节)。通过用线程安全的Map(Hashtable、synchronizedMap或ConcurrentHashMap)来代替attributes,AttributeStore可以将确保线程安全性的任务委托给顶层的线程安全容器来实现。这样就无须在AttributeStore中采用显式的同步,缩小在访问Map期间锁的范围,并降低了将来的代码维护者无意破坏线程安全性的风险(例如在访问attributes之前忘记获得相应的锁)。
-
尽管缩小同步代码块能提高可伸缩性,但同步代码块也不能过小——一些需要采用原子方式执行的操作(例如对某个不变性条件中的多个变量进行更新)必须包含在一个同步块中。此外,同步需要一定的开销,当把一个同步代码块分解为多个同步代码块时(在确保正确性的情况下),反而会对性能提升产生负面影响。[插图]在分解同步代码块时,理想的平衡点将与平台相关,但在实际情况中,仅当可以将一些“大量”的计算或阻塞操作从同步代码块中移出时,才应该考虑同步代码块的大小。
11.4.2 减小锁的粒度
-
另一种减小锁的持有时间的方式是降低线程请求锁的频率(从而减小发生竞争的可能性)。这可以通过锁分解和锁分段等技术来实现。
-
这些技术中将采用多个相互独立的锁来保护独立的状态变量,从而改变这些变量在之前由单个锁来保护的情况。这些技术能减小锁操作的粒度,并能实现更高的可伸缩性,然而,使用的锁越多,那么发生死锁的风险也就越高。
-
如果一个锁需要保护多个相互独立的状态变量,那么可以将这个锁分解为多个锁,并且每个锁只保护一个变量,从而提高可伸缩性,并最终降低每个锁被请求的频率。
-
在程序清单11-6的ServerStatus中给出了某个数据库服务器的部分监视接口,该数据库维护了当前已登录的用户以及正在执行的请求。当一个用户登录、注销、开始查询或结束查询时,都会调用相应的add和remove等方法来更新ServerStatus对象。这两种类型的信息是完全独立的,ServerStatus甚至可以被分解为两个类,同时确保不会丢失功能。
//程序清单11-6 对锁进行分解 public class ServerStatus{ //用户与请求状态 @GuardedBy("this")public final Set<String>users; @GuardedBy("this")public final Set<String>queries; …… public synchronized void addUser(String u){ users.add(u); } public synchronized void addQuery(String q){ queries.add(q); } public synchronized void removeUser(String u){ users.remove(u); } public synchronized void removeQuery(String q){ queries.remove(q); } } -
在代码中不是用ServerStatus锁来保护用户状态和查询状态,而是每个状态都通过一个锁来保护,如程序清单11-7所示
//程序清单11-7 将ServerStatus重新改写为使用锁分解技术 @ThreadSafe public class ServerStatus{ @GuardedBy("users")public final Set<String>users; @GuardedBy("queries")public final Set<String>queries; …… public void addUser(String u){ synchronized(users){ users.add(u); } } public void addQuery(String q){ synchronized(queries){ queries.add(q); } } //去掉同样被改写为使用被分解锁的方法 }- 在对锁进行分解后,每个新的细粒度锁上的访问量将比最初的访问量少。(通过将用户状态和查询状态委托给一个线程安全的Set,而不是使用显式的同步,能隐含地对锁进行分解,因为每个Set都会使用一个不同的锁来保护其状态。)
- 如果在锁上存在适中而不是激烈的竞争时,通过将一个锁分解为两个锁,能最大限度地提升性能。如果对竞争并不激烈的锁进行分解,那么在性能和吞吐量等方面带来的提升将非常有限,但是也会提高性能随着竞争提高而下降的拐点值。对竞争适中的锁进行分解时,实际上是把这些锁转变为非竞争的锁,从而有效地提高性能和可伸缩性。
11.4.3 锁分段
-
把一个竞争激烈的锁分解为两个锁时,这两个锁可能都存在激烈的竞争。虽然采用两个线程并发执行能提高一部分可伸缩性,但在一个拥有多个处理器的系统中,仍然无法给可伸缩性带来极大的提高。在ServerStatus类的锁分解示例中,并不能进一步对锁进行分解。
-
在某些情况下,可以将锁分解技术进一步扩展为对一组独立对象上的锁进行分解,这种情况被称为锁分段。
-
例如,在ConcurrentHashMap的实现中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod16)个锁来保护。假设散列函数具有合理的分布性,并且关键字能够实现均匀分布,那么这大约能把对于锁的请求减少到原来的1/16。正是这项技术使得ConcurrentHashMap能够支持多达16个并发的写入器。(要使得拥有大量处理器的系统在高访问量的情况下实现更高的并发性,还可以进一步增加锁的数量,但仅当你能证明并发写入线程的竞争足够激烈并需要突破这个限制时,才能将锁分段的数量超过默认的16个。)
-
锁分段的一个劣势在于:与采用单个锁来实现独占访问相比,要获取多个锁来实现独占访问将更加困难并且开销更高。
-
通常,在执行一个操作时最多只需获取一个锁,但在某些情况下需要加锁整个容器,例如当ConcurrentHashMap需要扩展映射范围,以及重新计算键值的散列值要分布到更大的桶集合中时,就需要获取分段所集合中所有的锁。
-
要获取内置锁的一个集合,能采用的唯一方式是递归。
-
在程序清单11-8的StripedMap中给出了基于散列的Map实现,其中使用了锁分段技术。它拥有N_LOCKS个锁,并且每个锁保护散列桶的一个子集。大多数方法,例如get,都只需要获得一个锁,而有些方法则需要获得所有的锁,但并不要求同时获得,例如clear方法的实现。
//程序清单11-8 在基于散列的Map中使用锁分段技术 @ThreadSafe public class StripedMap{ //同步策略:buckets[n]由locks[n%N_LOCKS]来保护 private static final int N_LOCKS=16; private final Node[]buckets; private final Object[]locks; private static class Node{ …… } public StripedMap(int numBuckets){ buckets=new Node[numBuckets]; locks=new Object[N_LOCKS]; for(int i=0;i<N_LOCKS;i++) locks[i]=new Object(); } private final int hash(Object key){ return Math.abs(key.hashCode()%buckets.length); } public Object get(Object key){ int hash=hash(key); synchronized(locks[hash%N_LOCKS]){ for(Node m=buckets[hash];m!=null;m=m.next) if(m.key.equals(key)) return m.value; } return null; } public void clear(){ for(int i=0;i<buckets.length;i++){ //更大的开销 synchronized(locks[i%N_LOCKS]){ buckets[i]=null; } } } …… }- 这种清除Map的方式并不是原子操作,因此可能当StripedMap为空时其他的线程正并发地向其中添加元素。如果要使该操作成为一个原子操作,那么需要同时获得所有的锁。然而,如果客户代码不加锁并发容器来实现独占访问,那么像size或isEmpty这样的方法的计算结果在返回时可能会变得无效,因此,尽管这种行为有些奇怪,但通常是可以接受的。
11.4.4 避免热点域
- 锁分解和锁分段技术都能提高可伸缩性,因为它们都能使不同的线程在不同的数据(或者同一个数据的不同部分)上操作,而不会相互干扰。
- 如果程序采用锁分段技术,那么一定要表现出在锁上的竞争频率高于在锁保护的数据上发生竞争的频率。如果一个锁保护两个独立变量X和Y,并且线程A想要访问X,而线程B想要访问Y(这类似于在ServerStatus中,一个线程调用addUser,而另一个线程调用addQuery),那么这两个线程不会在任何数据上发生竞争,即使它们会在同一个锁上发生竞争。
- 当每个操作都请求多个变量时,锁的粒度将很难降低。这是在性能与可伸缩性之间相互制衡的另一个方面,一些常见的优化措施,例如将一些反复计算的结果缓存起来,都会引入一些“热点域(Hot Field)”,而这些热点域往往会限制可伸缩性。
- 当实现HashMap时,你需要考虑如何在size方法中计算Map中的元素数量。最简单的方法就是,在每次调用时都统计一次元素的数量。一种常见的优化措施是,在插入和移除元素时更新一个计数器,虽然这在put和remove等方法中略微增加了一些开销,以确保计数器是最新的值,但这将把size方法的开销从O(n)降低到O(1)。
- 在单线程或者采用完全同步的实现中,使用一个独立的计数能很好地提高类似size和isEmpty这些方法的执行速度,但却导致更难以提升实现的可伸缩性,因为每个修改map的操作都需要更新这个共享的计数器。
- 即使使用锁分段技术来实现散列链,那么在对计数器的访问进行同步时,也会重新导致在使用独占锁时存在的可伸缩性问题。一个看似性能优化的措施——缓存size操作的结果,已经变成了一个可伸缩性问题。在这种情况下,计数器也被称为热点域,因为每个导致元素数量发生变化的操作都需要访问它。
- 为了避免这个问题,ConcurrentHashMap中的size将对每个分段进行枚举并将每个分段中的元素数量相加,而不是维护一个全局计数。为了避免枚举每个元素,ConcurrentHashMap为每个分段都维护了一个独立的计数,并通过每个分段的锁来维护这个值。
- 如果size方法的调用频率与修改Map操作的执行频率大致相当,那么可以采用这种方式来优化所有已分段的数据结构,即每当调用size时,将返回值缓存到一个volatile变量中,并且每当容器被修改时,使这个缓存中的值无效(将其设为-1)。如果发现缓存的值非负,那么表示这个值是正确的,可以直接返回,否则,需要重新计算这个值。
11.4.5 一些替代独占锁的方法
- 如果size方法的调用频率与修改Map操作的执行频率大致相当,那么可以采用这种方式来优化所有已分段的数据结构,即每当调用size时,将返回值缓存到一个volatile变量中,并且每当容器被修改时,使这个缓存中的值无效(将其设为-1)。如果发现缓存的值非负,那么表示这个值是正确的,可以直接返回,否则,需要重新计算这个值。
- ReadWriteLock(请参见第13章)实现了一种在多个读取操作以及单个写入操作情况下的加锁规则:如果多个读取操作都不会修改共享资源,那么这些读取操作可以同时访问该共享资源,但在执行写入操作时必须以独占方式来获取锁。对于读取操作占多数的数据结构,ReadWriteLock能提供比独占锁更高的并发性。而对于只读的数据结构,其中包含的不变性可以完全不需要加锁操作。
- 原子变量(请参见第15章)提供了一种方式来降低更新“热点域”时的开销,例如静态计数器、序列发生器、或者对链表数据结构中头节点的引用。(在第2章的示例中使用了AtomicLong来维护Servlet的计数器。)
- 原子变量类提供了在整数或者对象引用上的细粒度原子操作(因此可伸缩性更高),并使用了现代处理器中提供的底层并发原语(例如比较并交换[compare-and-swap])
- 如果在类中只包含少量的热点域,并且这些域不会与其他变量参与到不变性条件中,那么用原子变量来替代它们能提高可伸缩性。
11.4.6 检测CPU的利用率
- 当测试可伸缩性时,通常要确保处理器得到充分利用。一些工具,例如UNIX系统上的vmstat和mpstat,或者Windows系统的perfmon,都能给出处理器的“忙碌”状态。
- 如果所有CPU的利用率并不均匀(有些CPU在忙碌地运行,而其他CPU却并非如此),那么你的首要目标就是进一步找出程序中的并行性。不均匀的利用率表明大多数计算都是由一小组线程完成的,并且应用程序没有利用其他的处理器。
- 如果CPU没有得到充分利用,那么需要找出其中的原因。通常有以下几种原因:
- 负载不充足。
- I/O密集。可以通过iostat或perfmon来判断某个应用程序是否是磁盘I/O密集型的,或者通过监测网络的通信流量级别来判断它是否需要高带宽。
- 外部限制。如果应用程序依赖于外部服务,例如数据库或Web服务,那么性能瓶颈可能并不在你自己的代码中。
- 锁竞争。使用分析工具可以知道在程序中存在何种程度的锁竞争,以及在哪些锁上存在“激烈的竞争”。
- 如果应用程序正在使CPU保持忙碌状态,那么可以使用监视工具来判断是否能通过增加额外的CPU来提升程序的性能。如果一个程序只有4个线程,那么可以充分利用一个4路系统的计算能力,但当移植到8路系统上时,却未必能获得性能提升,因为可能需要更多的线程才会有效利用剩余的处理器。(可以通过重新配置程序将工作负载分配给更多的线程,例如调整线程池的大小。)在vmstat命令的输出中,有一栏信息是当前处于可运行状态但并没有运行(由于没有足够的CPU)的线程数量。如果CPU的利用率很高,并且总会有可运行的线程在等待CPU,那么当增加更多的处理器时,程序的性能可能会得到提升。
11.4.7 向对象池说“不”,(每次获取对象都需要同步,开销远超过分配内存的开销)
- 为了解决“缓慢的”对象生命周期问题,许多开发人员都选择使用对象池技术,在对象池中,对象能被循环使用,而不是由垃圾收集器回收并在需要时重新分配
- 在并发应用程序中,对象池的表现更加糟糕。当线程分配新的对象时,基本上不需要在线程之间进行协调,因为对象分配器通常会使用线程本地的内存块,所以不需要在堆数据结构上进行同步。
- 然而,如果这些线程从对象池中请求一个对象,那么就需要通过某种同步来协调对对象池数据结构的访问,从而可能使某个线程被阻塞。
- 如果某个线程由于锁竞争而被阻塞,那么这种阻塞的开销将是内存分配操作开销的数百倍,因此即使对象池带来的竞争很小,也可能形成一个可伸缩性瓶颈。
11.5 示例:比较Map的性能
-
不同Map实现的可伸缩性比较

-
同步容器的数量并非越多越好。单线程情况下的性能与ConcurrentHashMap的性能基本相当,但当负载情况由非竞争性转变成竞争性时——这里是两个线程,同步容器的性能将变得糟糕。
11.6 减少上下文切换的开销
- 当任务在运行和阻塞这两个状态之间转换时,就相当于一次上下文切换。
- 在服务器应用程序中,发生阻塞的原因之一就是在处理请求时产生各种日志消息。为了说明如何通过减少上下文切换的次数来提高吞吐量,我们将对两种日志方法的调度行为进行分析。
- 在大多数日志框架中都是简单地对println进行包装,当需要记录某个消息时,只需将其写入日志文件中。在第7章的LogWriter中给出了另一种方法:记录日志的工作由一个专门的后台线程完成,而不是由发出请求的线程完成。
- 从开发人员的角度来看,这两种方法基本上是相同的。但二者在性能上可能存在一些差异,这取决于日志操作的工作量,即有多少线程正在记录日志,以及其他一些因素,例如上下文切换的开销等。
- 日志操作的服务时间包括与I/O流类相关的计算时间,如果I/O操作被阻塞,那么还会包括线程被阻塞的时间。
- 如果有多个线程在同时记录日志,那么还可能在输出流的锁上发生竞争,这种情况的结果与阻塞I/O的情况一样——线程被阻塞并等待锁,然后被线程调度器交换出去。在这种日志操作中包含了I/O操作和加锁操作,从而导致上下文切换次数的增多,以及服务时间的增加。
- 请求服务的时间不应该过长,主要有以下原因
- 首先,服务时间将影响服务质量:服务时间越长,就意味着有程序在获得结果时需要等待更长的时间。但更重要的是,服务时间越长,也就意味着存在越多的锁竞争。
- 。但更重要的是,服务时间越长,也就意味着存在越多的锁竞争。
- 通过将I/O操作从处理请求的线程中分离出来,可以缩短处理请求的平均服务时间。调用log方法的线程将不会再因为等待输出流的锁或者I/O完成而被阻塞,它们只需将消息放入队列,然后就返回到各自的任务中。另一方面,虽然在消息队列上可能会发生竞争,但put操作相对于记录日志的I/O操作(可能需要执行系统调用)是一种更为轻量级的操作,因此在实际使用中发生阻塞的概率更小(只要队列没有填满)。由于发出日志请求的线程现在被阻塞的概率降低,因此该线程在处理请求时被交换出去的概率也会降低。
- 我们所做的工作就是把一条包含I/O操作和锁竞争的复杂且不确定的代码路径变成一条简单的代码路径。
- 从某种意义上讲,我们只是将工作分散开来,并将I/O操作移到了另一个用户感知不到开销的线程上(这本身已经获得了成功)。通过把所有记录日志的I/O转移到一个线程,还消除了输出流上的竞争,因此又去掉了一个竞争来源。这将提升整体的吞吐量,因为在调度中消耗的资源更少,上下文切换次数更少,并且锁的管理也更简单。
- 通过把I/O操作从处理请求的线程转移到一个专门的线程,类似于两种不同救火方案之间的差异:第一种方案是所有人排成一队,通过传递水桶来救火;第二种方案是每个人都拿着一个水桶去救火。在第二种方案中,每个人都可能在水源和着火点上存在更大的竞争(结果导致了只能将更少的水传递到着火点),此外救火的效率也更低,因为每个人都在不停的切换模式(装水、跑步、倒水、跑步……)。在第一种解决方案中,水不断地从水源传递到燃烧的建筑物,人们付出更少的体力却传递了更多的水,并且每个人从头至尾只需做一项工作。正如中断会干扰人们的工作并降低效率,阻塞和上下文切换同样会干扰线程的正常执行。
- ]如果日志模块将I/O操作从发出请求的线程转移到另一个线程,那么通常可以提高性能,但也会引入更多的设计复杂性,例如中断(当一个在日志操作中阻塞的线程被中断,将出现什么情况)、服务担保(日志模块能否保证队列中的日志消息都能在服务结束之前记录到日志文件)、饱和策略(当日志消息的产生速度比日志模块的处理速度更快时,将出现什么情况),以及服务生命周期(如何关闭日志模块,以及如何将服务状态通知给生产者)。
小结
- 由于使用线程常常是为了充分利用多个处理器的计算能力,因此在并发程序性能的讨论中,通常更多地将侧重点放在吞吐量和可伸缩性上,而不是服务时间。
- Amdahl定律告诉我们,程序的可伸缩性取决于在所有代码中必须被串行执行的代码比例。
- 因为Java程序中串行操作的主要来源是独占方式的资源锁,因此通常可以通过以下方式来提升可伸缩性:减少锁的持有时间,降低锁的粒度,以及采用非独占的锁或非阻塞锁来代替独占锁。
第12章 并发程序的测试(未完)
- 在编写并发程序时,可以采用与编写串行程序时相同的设计原则与设计模式。二者的差异在于,并发程序存在一定程度的不确定性,而在串行程序中不存在这个问题。这种不确定性将增加不同交互模式以及故障模式的数量,因此在设计并发程序时必须对这些模式进行分析。
- 在测试串行程序正确性与性能等方面所采用的技术,同样可以用于测试并发程序,但对于并发程序而言,可能出错的地方远比串行程序多。
- 在测试并发程序时,所面临的主要挑战在于:潜在错误的发生并不具有确定性,而是随机的。要在测试中将这些故障暴露出来,就需要比普通的串行程序测试覆盖更广的范围并且执行更长的时间。
- 并发测试大致分为两类,即安全性测试与活跃性测试。
- 在进行安全性测试时,通常会采用测试不变性条件的形式,即判断某个类的行为是否与其规范保持一致。
- 测试活跃性本身也存在问题。活跃性测试包括进展测试和无进展测试两方面,这些都是很难量化的——如何验证某个方法是被阻塞了,而不只是运行缓慢?同样,如何测试某个算法不会发生死锁?要等待多久才能宣告它发生了故障?
- 与活跃性测试相关的是性能测试。性能可以通过多个方面来衡量,包括:
- 吞吐量:指一组并发任务中已完成任务所占的比例
- 响应性:指请求从发出到完成之间的时间(也称为延迟)
- 可伸缩性:指在增加更多资源的情况下(通常指CPU),吞吐量(或者缓解短缺)的提升情况。
12.1 正确性测试
第四部分 高级主题
第13章 显式锁
- 在Java 5.0之前,在协调对共享对象的访问时可以使用的机制只有synchronized和volatile。Java 5.0增加了一种新的机制:ReentrantLock。与之前提到过的机制相反,ReentrantLock并不是一种替代内置加锁的方法,而是当内置加锁机制不适用时,作为一种可选择的高级功能。
13.1 Lock和ReentrantLock
-
与内置加锁机制不同的是,Lock接口提供了一种无条件的、可轮询的、定时的以及可中断的锁获取操作,所有加锁和解锁的方法都是显式的。
-
在Lock的实现中必须提供与内部锁相同的内存可见性语义,但在加锁语义、调度算法、顺序保证以及性能特性等方面可以有所不同。(第14章将介绍Lock.newCondition。)
-
在程序清单13-1给出的Lock接口中定义了一组抽象的加锁操作。
// 程序清单13-1 Lock接口 public interface Lock{ void lock(); void lockInterruptibly()throws InterruptedException; boolean tryLock(); boolean tryLock(long timeout, TimeUnit unit)throws InterruptedException; void unlock(); Condition newCondition(); } -
ReentrantLock实现了Lock接口,并提供了与synchronized相同的互斥性和内存可见性。在获取ReentrantLock时,有着与进入同步代码块相同的内存语义,在释放ReentrantLock时,同样有着与退出同步代码块相同的内存语义。
-
为什么要创建一种与内置锁如此相似的新加锁机制?
-
在大多数情况下,内置锁都能很好地工作,但在功能上存在一些局限性,例如,无法中断一个正在等待获取锁的线程,或者无法在请求获取一个锁时无限地等待下去.
-
内置锁必须在获取该锁的代码块中释放,这就简化了编码工作,并且与异常处理操作实现了很好的交互,但却无法实现非阻塞结构的加锁规则。
-
程序清单13-2给出了Lock接口的标准使用形式。这种形式比使用内置锁复杂一些:必须在finally块中释放锁。否则,如果在被保护的代码中抛出了异常,那么这个锁永远都无法释放。
Lock lock=new ReentrantLock(); …… lock.lock(); try{ //更新对象状态 //捕获异常,并在必要时恢复不变性条件 }finally{ //一定要再结束的时候释放锁 lock.unlock(); } -
如果没有使用finally来释放Lock,那么相当于启动了一个定时炸弹。当“炸弹爆炸”时,将很难追踪到最初发生错误的位置,因为没有记录应该释放锁的位置和时间。这就是ReentrantLock不能完全替代synchronized的原因:它更加“危险”,因为当程序的执行控制离开被保护的代码块时,不会自动清除锁。
13.1.1 轮询锁与定时锁
-
可定时的与可轮询的锁获取模式是由tryLock方法实现的,与无条件的锁获取模式相比,它具有更完善的错误恢复机制。
-
在内置锁中,死锁是一个严重的问题,恢复程序的唯一方法是重新启动程序,而防止死锁的唯一方法就是在构造程序时避免出现不一致的锁顺序。可定时的与可轮询的锁提供了另一种选择:避免死锁的发生。
-
如果不能获得所有需要的锁,那么可以使用可定时的或可轮询的锁获取方式,从而使你重新获得控制权,它会释放已经获得的锁,然后重新尝试获取所有锁(或者至少会将这个失败记录到日志,并采取其他措施)。
-
程序清单13-3给出了另一种方法来解决10.1.2节中动态顺序死锁的问题:使用tryLock来获取两个锁,如果不能同时获得,那么就回退并重新尝试。如果在指定时间内不能获得所有需要的锁,那么transferMoney将返回一个失败状态,从而使该操作平缓地失败。
// 程序清单13-3 通过tryLock来避免锁顺序死锁 public boolean transferMoney(Account fromAcct,Account toAcct,DollarAmount amount,long timeout,TimeUnit unit)throws InsufficientFundsException, InterruptedException{ long fixedDelay=getFixedDelayComponentNanos(timeout, unit); long randMod=getRandomDelayModulusNanos(timeout, unit); long stopTime=System.nanoTime()+unit.toNanos(timeout); while(true){ if(fromAcct.lock.tryLock()){ try{ if(toAcct.lock.tryLock()){ try{ if(fromAcct.getBalance().compareTo(amount)<0) throw new InsufficientFundsException(); else{ fromAcct.debit(amount); toAcct.credit(amount); return true; } }finally{ toAcct.lock.unlock(); } } }finally{ fromAcct.lock.unlock(); } } if(System.nanoTime()<stopTime) return false; NANOSECONDS.sleep(fixedDelay+rnd.nextLong()%randMod); } } -
程序清单13-4试图在Lock保护的共享通信线路上发送一条消息,如果不能在指定时间内完成,代码就会失败。定时的tryLock能够在这种带有时间限制的操作中实现独占加锁行为。
//程序清单13-4 带有时间限制的加锁 public boolean trySendOnSharedLine(String message,long timeout, TimeUnit unit)throws InterruptedException{ long nanosToLock=unit.toNanos(timeout)-estimatedNanosToSend(message); if(!lock.tryLock(nanosToLock, NANOSECONDS)) return false; try{ return sendOnSharedLine(message); }finally{ lock.unlock(); } }
13.1.2 可中断的锁获取操作
-
可中断的锁获取操作同样能在可取消的操作中使用加锁。lockInterruptibly方法能够在获得锁的同时保持对中断的响应(内置锁不响应中断),并且由于它包含在Lock中,因此无须创建其他类型的不可中断阻塞机制。
-
可中断的锁获取操作的标准结构比普通的锁获取操作略微复杂一些,因为需要两个try块。(如果在可中断的锁获取操作中抛出了InterruptedException,那么可以使用标准的try-finally加锁模式。)在程序清单13-5中使用了lockInterruptibly来实现程序清单13-4中的sendOnSharedLine,以便在一个可取消的任务中调用它。
//程序清单13-5 可中断的锁获取操作 public boolean sendOnSharedLine(String message)throws InterruptedException{ lock.lockInterruptibly(); try{ return cancellableSendOnSharedLine(message); }finally{ lock.unlock(); } } private boolean cancellableSendOnSharedLine(String message)throws InterruptedException{ …… } -
定时的tryLock同样能响应中断,因此当需要实现一个定时的和可中断的锁获取操作时,可以使用tryLock方法。
13.1.3 非块结构的加锁
锁分段技术。
13.2 性能考虑因素
可伸缩性。
13.3 公平性
- 在ReentrantLock的构造函数中提供了两种公平性选择:创建一个非公平的锁(默认)或者一个公平的锁。
- 在公平的锁上,线程将按照它们发出请求的顺序来获得锁,但在非公平的锁上,则允许“插队”:当一个线程请求非公平的锁时,如果在发出请求的同时该锁的状态变为可用,那么这个线程将跳过队列中所有的等待线程并获得这个锁。(在Semaphore中同样可以选择采用公平的或非公平的获取顺序。)
- 在公平的锁中,如果有另一个线程持有这个锁或者有其他线程在队列中等待这个锁,那么新发出请求的线程将被放入队列中。在非公平的锁中,只有当锁被某个线程持有时,新发出请求的线程才会被放入队列中。
- 在大多数情况下,非公平锁的性能要高于公平锁的性能。
- 在激烈竞争的情况下,非公平锁的性能高于公平锁的性能的一个原因是:在恢复一个被挂起的线程与该线程真正开始运行之间存在着严重的延迟。假设线程A持有一个锁,并且线程B请求这个锁。由于这个锁已被线程A持有,因此B将被挂起。当A释放锁时,B将被唤醒,因此会再次尝试获取锁。与此同时,如果C也请求这个锁,那么C很可能会在B被完全唤醒之前获得、使用以及释放这个锁。这样的情况是一种“双赢”的局面:B获得锁的时刻并没有推迟,C更早地获得了锁,并且吞吐量也获得了提高。
- 当持有锁的时间相对较长,或者请求锁的平均时间间隔较长,那么应该使用公平锁。在这些情况下,“插队”带来的吞吐量提升(当锁处于可用状态时,线程却还处于被唤醒的过程中)则可能不会出现。
13.4 在synchronized和ReentrantLock之间进行选择
- 与显式锁相比,内置锁仍然具有很大的优势。ReentrantLock的危险性比同步机制要高,如果忘记在finally块中调用unlock,那么虽然代码表面上能正常运行,但实际上已经埋下了一颗定时炸弹,并很有可能伤及其他代码。仅当内置锁不能满足需求时,才可以考虑使用ReentrantLock。
- 在一些内置锁无法满足需求的情况下,ReentrantLock可以作为一种高级工具。当需要一些高级功能时才应该使用ReentrantLock,这些功能包括:可定时的、可轮询的与可中断的锁获取操作,公平队列,以及非块结构的锁。否则,还是应该优先使用synchronized。
- 未来更可能会提升synchronized而不是ReentrantLock的性能。因为synchronized是JVM的内置属性,它能执行一些优化,例如对线程封闭的锁对象的锁消除优化,通过增加锁的粒度来消除内置锁的同步(请参见11.3.2节),而如果通过基于类库的锁来实现这些功能,则可能性不大
13.5 读-写锁
-
ReentrantLock实现了一种标准的互斥锁:每次最多只有一个线程能持有ReentrantLock。但对于维护数据的完整性来说,互斥通常是一种过于强硬的加锁规则,因此也就不必要地限制了并发性。互斥是一种保守的加锁策略,虽然可以避免“写/写”冲突和“写/读”冲突,但同样也避免了“读/读”冲突。
-
在读-写锁实现的加锁策略中,允许多个读操作同时进行,但每次只允许一个写操作。
-
在程序清单13-6的ReadWriteLock中暴露了两个Lock对象,其中一个用于读操作,而另一个用于写操作。要读取由ReadWriteLock保护的数据,必须首先获得读取锁,当需要修改ReadWriteLock保护的数据时,必须首先获得写入锁。
//程序清单13-6 ReadWriteLock接口 public interface ReadWriteLock{ Lock readLock(); Lock writeLock(); } -
读-写锁是一种性能优化措施,在一些特定的情况下能实现更高的并发性。在实际情况中,对于在多处理器系统上被频繁读取的数据结构,读-写锁能够提高性能。而在其他情况下,读-写锁的性能比独占锁的性能要略差一些,这是因为它们的复杂性更高。如果要判断在某种情况下使用读-写锁是否会带来性能提升,最好对程序进行分析。由于ReadWriteLock使用Lock来实现锁的读-写部分,因此如果分析结果表明读-写锁没有提高性能,那么可以很容易地将读-写锁换为独占锁。
-
在读取锁和写入锁之间的交互可以采用多种实现方式。ReadWriteLock中的一些可选实现包括:
- 释放优先。当一个写入操作释放写入锁时,并且队列中同时存在读线程和写线程,那么应该优先选择读线程,写线程,还是最先发出请求的线程?
- 读线程插队。如果锁是由读线程持有,但有写线程正在等待,那么新到达的读线程能否立即获得访问权,还是应该在写线程后面等待?如果允许读线程插队到写线程之前,那么将提高并发性,但却可能造成写线程发生饥饿问题。
- 重入性。读取锁和写入锁是否是可重入的?
- 降级。如果一个线程持有写入锁,那么它能否在不释放该锁的情况下获得读取锁?这可能会使得写入锁被“降级”为读取锁,同时不允许其他写线程修改被保护的资源。
- 升级。读取锁能否优先于其他正在等待的读线程和写线程而升级为一个写入锁?在大多数的读-写锁实现中并不支持升级,因为如果没有显式的升级操作,那么很容易造成死锁。(如果两个读线程试图同时升级为写入锁,那么二者都不会释放读取锁。)
-
ReentrantReadWriteLock为这两种锁都提供了可重入的加锁语义。与ReentrantLock类似,ReentrantReadWriteLock在构造时也可以选择是一个非公平的锁(默认)还是一个公平的锁。在公平的锁中,等待时间最长的线程将优先获得锁。如果这个锁由读线程持有,而另一个线程请求写入锁,那么其他读线程都不能获得读取锁,直到写线程使用完并且释放了写入锁。在非公平的锁中,线程获得访问许可的顺序是不确定的。写线程降级为读线程是可以的,但从读线程升级为写线程则是不可以的(这样做会导致死锁)。
-
与ReentrantLock类似的是,ReentrantReadWriteLock中的写入锁只能有唯一的所有者,并且只能由获得该锁的线程来释放。
-
当锁的持有时间较长并且大部分操作都不会修改被守护的资源时,那么读-写锁能提高并发性。在程序清单13-7的ReadWriteMap中使用了ReentrantReadWriteLock来包装Map,从而使它能在多个读线程之间被安全地共享,并且仍然能避免“读-写”或“写-写”冲突.在现实中,ConcurrentHashMap的性能已经很好了,因此如果只需要一个并发的基于散列的映射,那么就可以使用ConcurrentHashMap来代替这种方法,但如果需要对另一种Map实现(例如LinkedHashMap)提供并发性更高的访问,那么可以使用这项技术。
//程序清单13-7 用读-写锁来包装Map public class ReadWriteMap<K, V>{ private final Map<K, V>map; private final ReadWriteLock lock=new ReentrantReadWriteLock(); private final Lock r=lock.readLock(); private final Lock w=lock.writeLock(); public ReadWriteMap(Map<K, V>map){ this.map=map; } public V put(K key, V value){ w.lock(); try{ return map.put(key, value); }finally{ w.unlock(); } } //对remove(),putAll(),clear()等方法执行相同的操作 public V get(Object key){ r.lock(); try{ return map.get(key); }finally{ r.unlock(); } } //对其他只读的Map方法执行相同的操作 } -
图13-3给出了分别用ReentrantLock和ReadWriteLock来封装ArrayList的吞吐量比较
小结
- 与内置锁相比,显式的Lock提供了一些扩展功能,在处理锁的不可用性方面有着更高的灵活性,并且对队列行有着更好的控制。
- 但ReentrantLock不能完全替代synchronized,只有在synchronized无法满足需求时,才应该使用它。
- 读-写锁允许多个读线程并发地访问被保护的对象,当访问以读取操作为主的数据结构时,它能提高程序的可伸缩性。
第14章 构建自定义的同步工具
本章将介绍实现状态依赖性的各种选择,以及在使用平台提供的状态依赖性机制时需要遵守的各项规则。
14.1 状态依赖性的管理
-
并发程序中,基于状态的条件可能会由于其他线程的操作而改变:一个资源池可能在几条指令之前还是空的,但现在却变为非空的,因为另一个线程可能会返回一个元素到资源池。对于并发对象上依赖状态的方法,虽然有时候在前提条件不满足的情况下不会失败,但通常有一种更好的选择,即等待前提条件变为真。
-
依赖状态的操作可以一直阻塞直到可以继续执行,这比使它们先失败再实现起来要更为方便且更不易出错。为了突出高效的条件等待机制的价值,我们将首先介绍如何通过轮询与休眠等方式来(勉强地)解决状态依赖性问题。(阻塞队列、轮询、休眠)
-
可阻塞的状态依赖操作的形式如程序清单14-1所示。这种加锁模式有些不同寻常,因为锁是在操作的执行过程中被释放与重新获取的。
//程序清单14-1 可阻塞的状态依赖操作的结构 acquire lock on object statewhile(precondition does not hold){ release lockwait until precondition might hold optionally fail if interrupted or timeout expires reacquire lock } perform action release lock- 构成前提条件的状态变量必须由对象的锁来保护,从而使它们在测试前提条件的同时保持不变.
- 如果前提条件尚未满足,就必须释放锁,以便其他线程可以修改对象的状态,否则,前提条件就永远无法变成真。在再次测试前提条件之前,必须重新获得锁。
-
在生产者-消费者的设计中经常会使用像ArrayBlockingQueue这样的有界缓存。
-
在有界缓存提供的put和take操作中都包含有一个前提条件:不能从空缓存中获取元素,也不能将元素放入已满的缓存中。当前提条件未满足时,依赖状态的操作可以抛出一个异常或返回一个错误状态(使其成为调用者的一个问题),也可以保持阻塞直到对象进入正确的状态。
-
接下来介绍有界缓存的几种实现,其中将采用不同的方法来处理前提条件失败的问题。在每种实现中都扩展了程序清单14-2中的BaseBoundedBuffer,在这个类中实现了一个基于数组的循环缓存,其中各个缓存状态变量(buf、head、tail和count)均由缓存的内置锁来保护。它还提供了同步的doPut和doTake方法,并在子类中通过这些方法来实现put和take操作,底层的状态将对子类隐藏。
//程序清单14-2 有界缓存实现的基类 @ThreadSafe public abstract class BaseBoundedBuffer<V>{ @GuardedBy("this")private final V[]buf; @GuardedBy("this")private int tail; @GuardedBy("this")private int head; @GuardedBy("this")private int count; protected BaseBoundedBuffer(int capacity){ this.buf=(V[])new Object[capacity]; } protected synchronized final void doPut(V v){ buf[tail]=v; if(++tail==buf.length) tail=0; ++count; } protected synchronized final V doTake(){ V v=buf[head]; buf[head]=null; if(++head==buf.length) head=0; --count; return v; } public synchronized final boolean isFull(){ return count==buf.length; } public synchronized final boolean isEmpty(){ return count==0; } }
14.1.1 示例:将前提条件的失败传递给调用者
-
程序清单14-3的GrumpyBoundedBuffer是第一个简单的有界缓存实现。put和take方法都进行了同步以确保实现对缓存状态的独占访问,因为这两个方法在访问缓存时都采用“先检查再运行”的逻辑策略。
//程序清单14-3 当不满足前提条件时,有界缓存不会执行相应的操作 @ThreadSafe public class GrumpyBoundedBuffer<V> extends BaseBoundedBuffer<V>{ public GrumpyBoundedBuffer(int size){ super(size); } public synchronized void put(V v)throws BufferFullException{ if(isFull()) throw new BufferFullException(); doPut(v); } public synchronized V take()throws BufferEmptyException{ if(isEmpty()) throw new BufferEmptyException(); return doTake(); } }- 异常应该用于发生异常条件的情况中[EJ Item 39]。“缓存已满”并不是有界缓存的一个异常条件,就像“红灯”并不表示交通信号灯出现了异常。
- 在实现缓存时得到的简化(使调用者管理状态依赖性)并不能抵消在使用时存在的复杂性,因为现在调用者必须做好捕获异常的准备,并且在每次缓存操作时都需要重试。
-
程序清单14-4给出了对take的调用——并不是很漂亮,尤其是当程序中有许多地方都调用put和take方法时。
//程序清单14-4 调用GrumpyBoundedBuffer的代码 while(true){ try{ V item=buffer.take(); //对于item执行一些操作 break; }catch(BufferEmptyException e){ Thread.sleep(SLEEP_GRANULARITY); } }- 这种方法的一种变化形式是,当缓存处于某种错误的状态时返回一个错误值。这是一种改进,因为并没有放弃异常机制,抛出的异常意味着“对不起,请再试一次”,但这种方法并没有解决根本问题:调用者必须自行处理前提条件失败的情况。
-
调用者可以不进入休眠状态,而直接重新调用take方法,这种方法被称为忙等待或自旋等待。如果缓存的状态在很长一段时间内都不会发生变化,那么使用这种方法就会消耗大量的CPU时间。但是,调用者也可以进入休眠状态来避免消耗过多的CPU时间,但如果缓存的状态在刚调用完sleep就立即发生变化,那么将不必要地休眠一段时间。
-
因此,客户代码必须要在二者之间进行选择:要么容忍自旋导致的CPU时钟周期浪费,要么容忍由于休眠而导致的低响应性。(除了忙等待与休眠之外,还有一种选择就是调用Thread.yield,这相当于给调度器一个提示:现在需要让出一定的时间使另一个线程运行。假如正在等待另一个线程执行工作,那么如果选择让出处理器而不是消耗完整个CPU调度时间片,那么可以使整体的执行过程变快。)
-
如果将状态依赖性交给调用者管理,那么将导致一些功能无法实现,例如维持FIFO顺序,由于迫使调用者重试,因此失去了“谁先到达”的信息。
14.1.2 示例2:通过轮询与休眠来实现简单的阻塞
-
程序清单14-5中的SleepyBoundedBuffer尝试通过put和take方法来实现一种简单的“轮询与休眠”重试机制,从而使调用者无须在每次调用时都实现重试逻辑。
//程序清单14-5 使用简单阻塞实现的有界缓存 @ThreadSafe public class SleepyBoundedBuffer<V> extends BaseBoundedBuffer<V>{ public SleepyBoundedBuffer(int size){ super(size); } public void put(V v)throws InterruptedException{ while(true){ synchronized(this){ if(!isFull()){ doPut(v); return; } } Thread.sleep(SLEEP_GRANULARITY); } } public V take()throws InterruptedException{ while(true){ synchronized(this){ if(!isEmpty()) return doTake(); } Thread.sleep(SLEEP_GRANULARITY); } } }- 如果缓存为空,那么take将休眠并直到另一个线程在缓存中放入一些数据;如果缓存是满的,那么put将休眠并直到另一个线程从缓存中移除一些数据,以便有空间容纳新的数据。
- 这种方法将前提条件的管理操作封装起来,并简化了对缓存的使用——这正是朝着正确的改进方向迈出了一步。
-
SleepyBoundedBuffer的实现远比之前的实现复杂。缓存代码必须在持有缓存锁的时候才能测试相应的状态条件,因为表示状态条件的变量是由缓存锁保护的。如果测试失败,那么当前执行的线程将首先释放锁并休眠一段时间,从而使其他线程能够访问缓存。当线程醒来时,它将重新请求锁并再次尝试执行操作,因而线程将反复地在休眠以及测试状态条件等过程之间进行切换,直到可以执行操作为止。
-
从调用者的角度看,这种方法能很好地运行,如果某个操作可以执行,那么就立即执行,否则就阻塞,调用者无须处理失败和重试。要选择合适的休眠时间间隔,就需要在响应性与CPU使用率之间进行权衡。
-
SleepyBoundedBuffer对调用者提出了一个新的需求:处理InterruptedException。当一个方法由于等待某个条件变成真而阻塞时,需要提供一种取消机制(请参见第7章)。与大多数具备良好行为的阻塞库方法一样,SleepyBoundedBuffer通过中断来支持取消,如果该方法被中断,那么将提前返回并抛出InterruptedException。
-
这种通过轮询与休眠来实现阻塞操作的过程需要付出大量的努力。如果存在某种挂起线程的方法,并且这种方法能够确保当某个条件成真时线程立即醒来,那么将极大地简化实现工作。这正是条件队列实现的功能。
14.1.3 条件队列
-
“条件队列”这个名字来源于:它使得一组线程(称之为等待线程集合)能够通过某种方式来等待特定的条件变成真。
-
传统队列的元素是一个个数据,而与之不同的是,条件队列中的元素是一个个正在等待相关条件的线程。
-
正如每个Java对象都可以作为一个锁,每个对象同样可以作为一个条件队列,并且Object中的wait、notify和notifyAll方法就构成了内部条件队列的API。
-
对象的内置锁与其内部条件队列是相互关联的,要调用对象X中条件队列的任何一个方法,必须持有对象X上的锁。这是因为“等待由状态构成的条件”与“维护状态一致性”这两种机制必须被紧密地绑定在一起:只有能对状态进行检查时,才能在某个条件上等待,并且只有能修改状态时,才能从条件等待中释放另一个线程。
-
Object.wait会自动释放锁,并请求操作系统挂起当前线程,从而使其他线程能够获得这个锁并修改对象的状态。当被挂起的线程醒来时,它将在返回之前重新获取锁。从直观上来理解,调用wait意味着“我要去休息了,但当发生特定的事情时唤醒我”,而调用通知方法就意味着“特定的事情发生了”。
-
在程序清单14-6的BoundedBuffer中使用了wait和notifyAll来实现一个有界缓存。这比使用“休眠”的有界缓存更简单,并且更高效(当缓存状态没有发生变化时,线程醒来的次数将更少),响应性也更高(当发生特定状态变化时将立即醒来)。
//程序清单14-6 使用条件队列实现的有界缓存 @ThreadSafe public class BoundedBuffer<V> extends BaseBoundedBuffer<V>{ //条件谓词:not-full(!isFull()) //条件谓词:not-empty(!isEmpty()) public BoundedBuffer(int size){ super(size); } //阻塞并直到:not-full public synchronized void put(V v)throws InterruptedException{ while(isFull()) wait(); doPut(v); notifyAll(); } //阻塞并直到:not-empty public synchronized V take()throws InterruptedException{ while(isEmpty()) wait(); V v=doTake(); notifyAll(); return v; } } -
在产品的正式版本中还应包括限时版本的put和take,这样当阻塞操作不能在预计时间内完成时,可以因超时而返回。通过使用定时版本的Object.wait,可以很容易实现这些方法。
14.2 使用条件队列
条件队列使构建高效以及高可响应性的状态依赖类变得更容易,但同时也很容易被不正确地使用。虽然许多规则都能确保正确地使用条件队列,但在编译器或系统平台上却并没有强制要求遵循这些规则。(这也是为什么要尽量基于LinkedBlockingQueue、Latch、Semaphore和FutureTask等类来构造程序的原因之一,如果能避免使用条件队列,那么实现起来将容易许多。)
14.2.1 条件谓词
- 要想正确地使用条件队列,关键是找出对象在哪个条件谓词上等待。
- 条件谓词将在等待与通知等过程中导致许多困惑,因为在API中没有对条件谓词进行实例化的方法,并且在Java语言规范或JVM实现中也没有任何信息可以确保正确地使用它们。
- 但如果没有条件谓词,条件等待机制将无法发挥作用。
- 条件谓词是使某个操作成为状态依赖操作的前提条件。在有界缓存中,只有当缓存不为空时,take方法才能执行,否则必须等待。对take方法来说,它的条件谓词就是“缓存不为空”,take方法在执行之前必须首先测试该条件谓词。
- 将与条件队列相关联的条件谓词以及在这些条件谓词上等待的操作都写入文档。
- 在条件等待中存在一种重要的三元关系,包括加锁、wait方法和一个条件谓词。在条件谓词中包含多个状态变量,而状态变量由一个锁来保护,因此在测试条件谓词之前必须先持有这个锁。锁对象与条件队列对象(即调用wait和notify等方法所在的对象)必须是同一个对象。
- 在BoundedBuffer中,缓存的状态是由缓存锁保护的,并且缓存对象被用做条件队列。take方法将获取请求缓存锁,然后对条件谓词(即缓存为非空)进行测试。如果缓存非空,那么它会移除第一个元素。之所以能这样做,是因为take此时仍然持有保护缓存状态的锁。如果条件谓词不为真(缓存为空),那么take必须等待并直到另一个线程在缓存中放入一个对象。take将在缓存的内置条件队列上调用wait方法,这需要持有条件队列对象上的锁
- wait方法将释放锁,阻塞当前线程,并等待直到超时,然后线程被中断或者通过一个通知被唤醒。在唤醒进程后,wait在返回前还要重新获取锁。当线程从wait方法中被唤醒时,它在重新请求锁时不具有任何特殊的优先级,而要与任何其他尝试进入同步代码块的线程一起正常地在锁上进行竞争。
- 的wait时,调用者必须已经持有与条件队列相关的锁,并且这个锁必须保护着构成条件谓词的状态变量。
14.2.2 过早唤醒
-
内置条件队列可以与多个条件谓词一起使用。当一个线程由于调用notifyAll而醒来时,并不意味该线程正在等待的条件谓词已经变成真了。
-
在发出通知的线程调用notifyAll时,条件谓词可能已经变成真,但在重新获取锁时将再次变为假。在线程被唤醒到wait重新获取锁的这段时间里,可能有其他线程已经获取了这个锁,并修改了对象的状志。
-
基于所有这些原因,每当线程从wait中唤醒时,都必须再次测试条件谓词,如果条件谓词不为真,那么就继续等待(或者失败)。由于线程在条件谓词不为真的情况下也可以反复地醒来,因此必须在一个循环中调用wait,并在每次迭代中都测试条件谓词。程序清单14-7给出了条件等待的标准形式。
//程序清单14-7 状态依赖方法的标准形式 void stateDependentMethod()throws InterruptedException{ //必须通过一个锁来保护条件谓词 synchronized(lock){ while(!conditionPredicate()) lock.wait(); //现在对象处于合适的状态 } } -
当使用条件等待时(例如Object.wait或Condition.await):
- 通常都有一个条件谓词——包括一些对象状态的测试,线程在执行前必须首先通过这些测试。
- 在调用wait之前测试条件谓词,并且从wait中返回时再次进行测试。
- 在一个循环中调用wait。
- 确保使用与条件队列相关的锁来保护构成条件谓词的各个状态变量。
- 当调用wait、notify或notifyAll等方法时,一定要持有与条件队列相关的锁。
- 在检查条件谓词之后以及开始执行相应的操作之前,不要释放锁。
14.2.3 丢失的信号
- 丢失的信号是指:线程必须等待一个已经为真的条件,但在开始等待之前没有检查条件谓词。
- 如果线程A通知了一个条件队列,而线程B随后在这个条件队列上等待,那么线程B将不会立即醒来,而是需要另一个通知来唤醒它。像上述程序清单中警示之类的编码错误(例如,没有在调用wait之前检测条件谓词)就会导致信号的丢失。如果按照程序清单14-7的方式来设计条件等待,那么就不会发生信号丢失的问题。
14.2.4 通知
-
到目前为止,我们介绍了条件等待的前一半内容:等待。另一半内容是通知。
-
在缓存变为非空时,为了使take解除阻塞,必须确保在每条使缓存变为非空的代码路径中都发出一个通知。
-
每当在等待一个条件时,一定要确保在条件谓词变为真时通过某种方式发出通知。并且尽快释放锁
-
在条件队列API中有两个发出通知的方法,即notify和notifyAll。无论调用哪一个,都必须持有与条件队列对象相关联的锁。
-
在调用notify时,JVM会从这个条件队列上等待的多个线程中选择一个来唤醒,而调用notifyAll则会唤醒所有在这个条件队列上等待的线程。由于在调用notify或notifyAll时必须持有条件队列对象的锁,而如果这些等待中线程此时不能重新获得锁,那么无法从wait返回,因此发出通知的线程应该尽快地释放锁,从而确保正在等待的线程尽可能快地解除阻塞。
-
由于多个线程可以基于不同的条件谓词在同一个条件队列上等待,因此如果使用notify而不是notifyAll,那么将是一种危险的操作,因为单一的通知很容易导致类似于信号丢失的问题。
-
只有同时满足以下两个条件时,才能用单一的notify而不是notifyAll:
- 所有等待线程的类型都相同。只有一个条件谓词与条件队列相关,并且每个线程在从wait返回后将执行相同的操作。
- 单进单出。在条件变量上的每次通知,最多只能唤醒一个线程来执行。
-
由于大多数类并不满足这些需求,因此普遍认可的做法是优先使用notifyAll而不是notify。虽然notifyAll可能比notify更低效,但却更容易确保类的行为是正确的。
-
在BoundedBuffer的put和take方法中采用的通知机制是保守的:每当将一个对象放入缓存或者从缓存中移走一个对象时,就执行一次通知。我们可以对其进行优化:首先,仅当缓存从空变为非空,或者从满转为非满时,才需要释放一个线程。并且,仅当put或take影响到这些状态转换时,才发出通知。这也被称为“条件通知(Conditional Notification)。
//程序清单14-8 在BoundedBuffer.put中使用条件通知 public synchronized void put(V v)throws InterruptedException{ while(isFull()) wait(); //从空变为非空,唤醒take boolean wasEmpty=isEmpty(); doPut(v); if(wasEmpty) //主要是为了唤醒take notifyAll(); } -
单次通知和条件通知都属于优化措施。通常,在使用这些优化措施时,应该遵循“首选使程序正确地执行,然后才使其运行得更快”这个原则。如果不正确地使用这些优化措施,那么很容易在程序中引入奇怪的活跃性故障。
14.2.5 示例:阀门类
-
闭锁能阻止线程通过开始阀门,并直到阀门被打开,此时所有的线程都可以通过该阀门。虽然闭锁机制通常都能满足需求,但在某些情况下存在一个缺陷:按照这种方式构造的阀门在打开后无法重新关闭。
-
通过使用条件等待,可以很容易地开发一个可重新关闭的ThreadGate类,如程序清单14-9所示。
//程序清单14-9 使用wait和notifyAll来实现可重新关闭的阀门 @ThreadSafe public class ThreadGate{ //条件谓词:opened-since(n)(isOpen||generation>n) @GuardedBy("this")private boolean isOpen; @GuardedBy("this")private int generation; public synchronized void close(){ isOpen=false; } public synchronized void open(){ ++generation; isOpen=true; notifyAll(); } //阻塞并直到:opened-since(generation on entry) public synchronized void await()throws InterruptedException{ int arrivalGeneration=generation; while(!isOpen&&arrivalGeneration==generation) wait(); } }- ThreadGate可以打开和关闭阀门,并提供一个await方法,该方法能一直阻塞直到阀门被打开。
- 在await中使用的条件谓词比测试isOpen复杂得多。
- 这种条件谓词是必需的,因为如果当阀门打开时有N个线程正在等待它,那么这些线程都应该被允许执行。然而,如果阀门在打开后又非常快速地关闭了,并且await方法只检查isOpen,那么所有线程都可能无法释放:当所有线程收到通知时,将重新请求锁并退出wait,而此时的阀门可能已经再次关闭了。因此,在ThreadGate中使用了一个更复杂的条件谓词:每次阀门关闭(?开启吧)时,递增一个“Generation”计数器,如果阀门现在是打开的,或者阀门自从该线程到达后就一直是打开的,那么线程就可以通过await。
14.2.6 子类的安全问题
- 要想支持子类化,那么在设计类时需要保证:如果在实施子类化时违背了条件通知或单次通知的某个需求,那么在子类中可以增加合适的通知机制来代表基类。
- 对于状态依赖的类,要么将其等待和通知等协议完全向子类公开(并且写入正式文档),要么完全阻止子类参与到等待和通知等过程中。
- 当设计一个可被继承的状态依赖类时,至少需要公开条件队列和锁,并且将条件谓词和同步策略都写入文档。此外,还可能需要公开一些底层的状态变量。(最糟糕的情况是,一个状态依赖的类虽然将其状态向子类公开,但却没有将相应的等待和通知等协议写入文档,这就类似于一个类虽然公开了它的状态变量,但却没有将其不变性条件写入文档。)
- 另外一种选择就是完全禁止子类化,例如将类声明为final类型,或者将条件队列、锁和状态变量等隐藏起来,使子类看不见它们。否则,如果子类破坏了在基类中使用notify的方式,那么基类需要修复这种破坏。
- 考虑一个无界的可阻塞栈,当栈为空时,pop操作将阻塞,但push操作通常可以执行。这就满足了使用单次通知的需求。如果在这个类中使用了单次通知,并且在其一个子类中添加了一个阻塞的“弹出两个连续元素”方法,那么就会出现两种类型的等待线程:等待弹出一个元素的线程和等待弹出两个元素的线程。但如果基类将条件队列公开出来,并且将使用该条件队列的协议也写入文档,那么子类就可以将push方法改写为执行notifyAll,从而重新确保安全性。
14.2.7 封装条件队列
- 通常,我们应该把条件队列封装起来,因而除了使用条件队列的类,就不能在其他地方访问它。否则,调用者会自以为理解了在等待和通知上使用的协议,并且采用一种违背设计的方式来使用条件队列。(除非条件队列对象对于你无法控制的代码来说是不可访问的,否则就不可能要求在单次通知中的所有等待线程都是同一类型的。如果外部代码错误地在条件队列上等待,那么可能通知协议,并导致一个“被劫持的”信号。)
- 不幸的是,这条建议——将条件队列对象封装起来,与线程安全类的最常见设计模式并不一致,在这种模式中建议使用对象的内置锁来保护对象自身的状态。在BoundedBuffer中给出了这种常见的模式,即缓存对象自身既是锁,又是条件队列。然而,可以很容易将BoundedBuffer重新设计为使用私有的锁对象和条件队列,唯一的不同之处在于,新的BoundedBuffer不再支持任何形式的客户端加锁。
14.2.8 入口协议与出口协议
- Wellings(Wellings,2004)通过“入口协议和出口协议(Entry and ExitProtocols)”来描述wait和notify方法的正确使用。
- 对于每个依赖状态的操作,以及每个修改其他操作依赖状态的操作,都应该定义一个入口协议和出口协议。
- 入口协议就是该操作的条件谓词,出口协议则包括,检查被该操作修改的所有状态变量,并确认它们是否使某个其他的条件谓词变为真,如果是,则通知相关的条件队列。
- 在AbstractQueuedSynchronizer(java.util.concurrent包中大多数依赖状态的类都是基于这个类构建的)中使用出口协议(请参见14.4节)。这个类并不是由同步器类执行自己的通知,而是要求同步器方法返回一个值来表示该类的操作是否已经解除了一个或多个等待线程的阻塞。
14.3 显示的锁
-
正如Lock是一种广义的内置锁,Condition(参见程序清单14-10)也是一种广义的内置条件队列。Condition接口如下:
//程序清单14-10 Condition接口 public interface Condition{ void await()throws InterruptedException; boolean await(long time, TimeUnit unit)throws InterruptedException; long awaitNanos(long nanosTimeout)throws InterruptedException; void awaitUninterruptibly(); boolean awaitUntil(Date deadline)throws InterruptedException; void signal(); void signalAll(); } -
内置条件队列存在一些缺陷。每个内置锁都只能有一个相关联的条件队列,因而在像BoundedBuffer这种类中,多个线程可能在同一个条件队列上等待不同的条件谓词,并且在最常见的加锁模式下公开条件队列对象。这些因素都使得无法满足在使用notifyAll时所有等待线程为同一类型的需求.
-
如果想编写一个带有多个条件谓词的并发对象,或者想获得除了条件队列可见性之外的更多控制权,就可以使用显式的Lock和Condition而不是内置锁和条件队列,这是一种更灵活的选择。
-
一个Condition和一个Lock关联在一起,就像一个条件队列和一个内置锁相关联一样。要创建一个Condition,可以在相关联的Lock上调用Lock.newCondition方法。
-
正如Lock比内置加锁提供了更为丰富的功能,Condition同样比内置条件队列提供了更丰富的功能:在每个锁上可存在多个等待、条件等待可以是可中断的或不可中断的、基于时限的等待,以及公平的或非公平的队列操作。
-
与内置条件队列不同的是,对于每个Lock,可以有任意数量的Condition对象。Condition对象继承了相关的Lock对象的公平性,对于公平的锁,线程会依照FIFO顺序从Condition.await中释放。
-
特别注意:在Condition对象中,与wait、notify和notifyAll方法对应的分别是await、signal和signalAll。但是,Condition对Object进行了扩展,因而它也包含wait和notify方法。一定要确保使用正确的版本——await和signal。
-
程序清单14-11给出了有界缓存的另一种实现,即使用两个Condition,分别为notFull和notEmpty,用于表示“非满”与“非空”两个条件谓词。当缓存为空时,take将阻塞并等待notEmpty,此时put向notEmpty发送信号,可以解除任何在take中阻塞的线程。
//程序清单14-11 使用显式条件变量的有界缓存 @ThreadSafe public class ConditionBoundedBuffer<T>{ protected final Lock lock=new ReentrantLock(); //条件谓词:notFull(count<items.length) private final Condition notFull=lock.newCondition(); //条件谓词:notEmpty(count>0) private final Condition notEmpty=lock.newCondition(); @GuardedBy("lock")private final T[]items=(T[])new Object[BUFFER_SIZE]; @GuardedBy("lock")private int tail, head, count; //阻塞并直到:notFull public void put(T x)throws InterruptedException{ lock.lock(); try{ while(count==items.length) notFull.await(); items[tail]=x; if(++tail==items.length) tail=0; ++count; notEmpty.signal(); }finally{ lock.unlock(); } } //阻塞并直到:notEmpty public T take()throws InterruptedException{ lock.lock(); try{ while(count==0) notEmpty.await(); T x=items[head]; items[head]=null; if(++head==items.length) head=0; --count; notFull.signal(); return x; }finally{ lock.unlock(); } } } -
通过将两个条件谓词分开并放到两个等待线程集中,Condition使其更容易满足单次通知的需求。signal比signalAll更高效,它能极大地减少在每次缓存操作中发生的上下文切换与锁请求的次数。
-
与内置锁和条件队列一样,当使用显式的Lock和Condition时,也必须满足锁、条件谓词和条件变量之间的三元关系。在条件谓词中包含的变量必须由Lock来保护,并且在检查条件谓词以及调用await和signal时,必须持有Lock对象。
-
在使用显式的Condition和内置条件队列之间进行选择时,与在ReentrantLock和synchronized之间进行选择是一样的:如果需要一些高级功能,例如使用公平的队列操作或者在每个锁上对应多个等待线程集,那么应该优先使用Condition而不是内置条件队列。(如果需要ReentrantLock的高级功能,并且已经使用了它,那么就已经做出了选择。)
14.4 Synchronized剖析
-
在ReentrantLock和Semaphore这两个接口之间存在许多共同点。这两个类都可以用做一个“阀门”,即每次只允许一定数量的线程通过,并当线程到达阀门时,可以通过(在调用lock或acquire时成功返回),也可以等待(在调用lock或acquire时阻塞),还可以取消(在调用tryLock或tryAcquire时返回“假”,表示在指定的时间内锁是不可用的或者无法获得许可)。而且,这两个接口都支持可中断的、不可中断的以及限时的获取操作,并且也都支持等待线程执行公平或非公平的队列操作。
-
证明可以通过锁来实现计数信号量(如程序清单14-12中的SemaphoreOnLock所示),以及可以通过计数信号量来实现锁。
//程序清单14-12 使用Lock来实现信号量 //并非java.util.concurrent.Semaphore的真实实现方式 @ThreadSafe public class SemaphoreOnLock{ private final Lock lock=new ReentrantLock(); //条件谓词:permitsAvailable(permits>0) private final Condition permitsAvailable=lock.newCondition(); @GuardedBy("lock")private int permits; SemaphoreOnLock(int initialPermits){ lock.lock(); try{ permits=initialPermits; }finally{ lock.unlock(); } } //阻塞并直到:permitsAvailable public void acquire()throws InterruptedException{ lock.lock(); try{ while(permits<=0) permitsAvailable.await(); --permits; }finally{ lock.unlock(); } } public void release(){ lock.lock(); try{ ++permits; permitsAvailable.signal(); }finally{ lock.unlock(); } } } -
事实上,它们在实现时都使用了一个共同的基类,即AbstractQueuedSynchronizer(AQS),这个类也是其他许多同步类的基类。AQS是一个用于构建锁和同步器的框架,许多同步器都可以通过AQS很容易并且高效地构造出来。
-
不仅ReentrantLock和Semaphore是基于AQS构建的,还包括CountDownLatch、ReentrantReadWriteLock、SynchronousQueue[插图]和FutureTask。
-
AQS解决了在实现同步器时涉及的大量细节问题,例如等待线程采用FIFO队列操作顺序。在不同的同步器中还可以定义一些灵活的标准来判断某个线程是应该通过还是需要等待。
-
基于AQS来构建同步器能带来许多好处。它不仅能极大地减少实现工作,而且也不必处理在多个位置上发生的竞争问题(这是在没有使用AQS来构建同步器时的情况)。在SemaphoreOnLock中,获取许可的操作可能在两个时刻阻塞——当锁保护信号量状态时,以及当许可不可用时。在基于AQS构建的同步器中,只可能在一个时刻发生阻塞,从而降低上下文切换的开销,并提高吞吐量。在设计AQS时充分考虑了可伸缩性,因此java.util.concurrent中所有基于AQS构建的同步器都能获得这个优势。
14.5 AbstractQueuedSynchronizer:抽象队列同步器(AQS)
-
在基于AQS构建的同步器类中,最基本的操作包括各种形式的获取操作和释放操作。获取操作是一种依赖状态的操作,并且通常会阻塞。当使用锁或信号量时,“获取”操作的含义就很直观,即获取的是锁或者许可,并且调用者可能会一直等待直到同步器类处于可被获取的状态。在使用CountDownLatch时,“获取”操作意味着“等待并直到闭锁到达结束状态”,而在使用FutureTask时,则意味着“等待并直到任务已经完成”。“释放”并不是一个可阻塞的操作,当执行“释放”操作时,所有在请求时被阻塞的线程都会开始执行。
-
如果一个类想成为状态依赖的类,那么它必须拥有一些状态。AQS负责管理同步器类中的状态,它管理了一个整数状态信息,可以通过getState, setState以及compareAndSetState等protected类型方法来进行操作。
-
这个整数可以用于表示任意状态。例如,ReentrantLock用它来表示所有者线程已经重复获取该锁的次数,Semaphore用它来表示剩余的许可数量,FutureTask用它来表示任务的状态(尚未开始、正在运行、已完成以及已取消)。在同步器类中还可以自行管理一些额外的状态变量,例如,ReentrantLock保存了锁的当前所有者的信息,这样就能区分某个获取操作是重入的还是竞争的。
-
程序清单14-13给出了AQS中的获取操作与释放操作的形式。根据同步器的不同,获取操作可以是一种独占操作(例如ReentrantLock),也可以是一个非独占操作(例如Semaphore和CountDownLatch)。
//程序清单14-13 AQS中获取操作和释放操作的标准形式 boolean acquire()throws InterruptedException{ while(当前状态不允许获取操作){ if(需要阻塞获取请求){ 如果当前线程不在队列中,则将其插入队列阻塞当前线程 }else{ 返回失败 } 可能更新同步器的状态如果线程位于队列中,则将其移出队列返回成功 } } void release(){ 更新同步器的状态 if(新的状态允许某个被阻塞的线程获取成功) 解除队列中一个或多个线程的阻塞状态 } -
一个获取操作包括两部分。
- 首先,同步器判断当前状态是否允许获得操作,如果是,则允许线程执行,否则获取操作将阻塞或失败。这种判断是由同步器的语义决定的。例如,对于锁来说,如果它没有被某个线程持有,那么就能被成功地获取,而对于闭锁来说,如果它处于结束状态,那么也能被成功地获取。
- 其次,就是更新同步器的状态,获取同步器的某个线程可能会对其他线程能否也获取该同步器造成影响。例如,当获取一个锁后,锁的状态将从“未被持有”变成“已被持有”,而从Semaphore中获取一个许可后,将把剩余许可的数量减1。然而,当一个线程获取闭锁时,并不会影响其他线程能否获取它,因此获取闭锁的操作不会改变闭锁的状态。
-
如果某个同步器支持独占的获取操作,那么需要实现一些保护方法,包括tryAcquire、tryRelease和isHeldExclusively等,而对于支持共享获取的同步器,则应该实现tryAcquire-Shared和tryReleaseShared等方法。AQS中的accuire、acquireShared、release和releaseShared等方法都将调用这些方法在子类中带有前缀try的版本来判断某个操作是否能执行。
-
在同步器的子类中,可以根据其获取操作和释放操作的语义,使用getState、setState以及compareAndSetState来检查和更新状态,并通过返回的状态值来告知基类“获取”或“释放”同步器的操作是否成功。例如,如果tryAcquireShared返回一个负值,那么表示获取操作失败,返回零值表示同步器通过独占方式被获取,返回正值则表示同步器通过非独占方式被获取。对于tryRelease和tryReleaseShared方法来说,如果释放操作使得所有在获取同步器时被阻塞的线程恢复执行,那么这两个方法应该返回true。
-
为了使支持条件队列的锁(例如ReentrantLock)实现起来更简单,AQS还提供了一些机制来构造与同步器相关联的条件变量。
-
程序清单14-14中的OneShotLatch是一个使用AQS实现的二元闭锁。它包含两个公有方法:await和signal,分别对应获取操作和释放操作。
//程序清单14-14 使用AbstractQueuedSynchronizer实现的二元闭锁 @ThreadSafe public class OneShotLatch{ private final Sync sync=new Sync(); public void signal(){ sync.releaseShared(0); } public void await()throws InterruptedException{ sync.acquireSharedInterruptibly(0); } private class Sync extends AbstractQueuedSynchronizer{ protected int tryAcquireShared(int ignored){ //如果闭锁是开的(state==1),那么这个操作将成功,否则将失败 return(getState()==1)?1:-1; } protected boolean tryReleaseShared(int ignored){ setState(1); //现在打开闭锁 return true; //现在其他的线程可以获取该闭锁 } } }- 起初,闭锁是关闭的,任何调用await的线程都将阻塞并直到闭锁被打开。当通过调用signal打开闭锁时,所有等待中的线程都将被释放,并且随后到达闭锁的线程也被允许执行。
- 在OneShotLatch中,AQS状态用来表示闭锁状态——关闭(0)或者打开(1)。
- await方法调用AQS的acquireSharedInterruptibly,然后接着调用OneShotLatch中的tryAcquireShared方法。在tryAcquireShared的实现中必须返回一个值来表示该获取操作能否执行。如果之前已经打开了闭锁,那么tryAcquireShared将返回成功并允许线程通过,否则就会返回一个表示获取操作失败的值。
- acquireSharedInterruptibly方法在处理失败的方式,是把这个线程放入等待线程队列中。类似地,signal将调用releaseShared,接下来又会调用tryReleaseShared。在tryReleaseShared中将无条件地把闭锁的状态设置为打开,(通过返回值)表示该同步器处于完全被释放的状态。因而AQS让所有等待中的线程都尝试重新请求该同步器,并且由于tryAcquireShared将返回成功,因此现在的请求操作将成功。
-
OneShotLatch是一个功能全面的、可用的、性能较好的同步器,并且仅使用了大约20多行代码就实现了。当然,它缺少了一些有用的特性,例如限时的请求操作以及检查闭锁的状态,但这些功能实现起来同样很容易,因为AQS提供了限时版本的获取方法,以及一些在常见检查中使用的辅助方法。
-
oneShotLatch也可以通过扩展AQS来实现,而不是将一些功能委托给AQS,但这种做法并不合理[EJ Item 14],原因有很多。这样做将破坏OneShotLatch接口(只有两个方法)的简洁性,并且虽然AQS的公共方法不允许调用者破坏闭锁的状态,但调用者仍可以很容易地误用它们。java.util.concurrent中的所有同步器类都没有直接扩展AQS,而是都将它们的相应功能委托给私有的AQS子类来实现。
14.6 JUC同步器中的AQS
- java.util.concurrent中的许多可阻塞类,例如
- ReentrantLock、
- Semaphore、
- ReentrantRead-WriteLock、
- CountDownLatch、
- SynchronousQueue和
- FutureTask等
14.6.1 ReentrantLock
-
ReentrantLock只支持独占方式的获取操作,因此它实现了tryAcquire、tryRelease和isHeldExclusively,程序清单14-15给出了非公平版本的tryAcquire。
//程序清单14-15 基于非公平的ReentrantLock实现tryAcquire protected boolean tryAcquire(int ignored){ final Thread current=Thread.currentThread(); int c=getState(); if(c==0){ if(compareAndSetState(0,1)){ owner=current; return true; } }else if(current==owner){ setState(c+1); return true; } return false; }- 当一个线程尝试获取锁时,tryAcquire将首先检查锁的状态。如果锁未被持有,那么它将尝试更新锁的状态以表示锁已经被持有。
- 由于状态可能在检查后被立即修改,因此tryAcquire使用compareAndSetState来原子地更新状态,表示这个锁已经被占有,并确保状态在最后一次检查以后就没有被修改过。
- 如果锁状态表明它已经被持有,并且如果当前线程是锁的拥有者,那么获取计数会递增,如果当前线程不是锁的拥有者,那么获取操作将失败。
-
ReentrantLock将同步状态用于保存锁获取操作的次数,并且还维护一个owner变量来保存当前所有者线程的标识符,只有在当前线程刚刚获取到锁,或者正要释放锁的时候,才会修改这个变量.
-
在tryRelease中检查owner域,从而确保当前线程在执行unlock操作之前已经获取了锁:在tryAcquire中将使用这个域来区分获取操作是重入的还是竞争的。
14.6.2 Semaphore与CountDownLatch
-
Semaphore将AQS的同步状态用于保存当前可用许可的数量。tryAcquireShared方法(请参见程序清单14-16)首先计算剩余许可的数量,如果没有足够的许可,那么会返回一个值表示获取操作失败。如果还有剩余的许可,那么tryAcquireShared会通过compareAndSetState以原子方式来降低许可的计数。如果这个操作成功(这意味着许可的计数自从上一次读取后就没有被修改过),那么将返回一个值表示获取操作成功。在返回值中还包含了表示其他共享获取操作能否成功的信息,如果成功,那么其他等待的线程同样会解除阻塞。
//程序清单14-16 Semaphore中的tryAcquireShared与tryReleaseShared protected int tryAcquireShared(int acquires){ while(true){ int available=getState(); int remaining=available-acquires; if(remaining<0||compareAndSetState(available, remaining)) return remaining; } } protected boolean tryReleaseShared(int releases){ while(true){ int p=getState(); if(compareAndSetState(p, p+releases)) return true; } } -
当没有足够的许可,或者当tryAcquireShared可以通过原子方式来更新许可的计数以响应获取操作时,while循环将终止。虽然对compareAndSetState的调用可能由于与另一个线程发生竞争而失败(请参见15.3节),并使其重新尝试,但在经过了一定次数的重试操作以后,在这两个结束条件中有一个会变为真。
-
同样,tryReleaseShared将增加许可计数,这可能会解除等待中线程的阻塞状态,并且不断地重试直到更新操作成功。tryReleaseShared的返回值表示在这次释放操作中解除了其他线程的阻塞。
-
CountDownLatch使用AQS的方式与Semaphore很相似:在同步状态中保存的是当前的计数值。countDown方法调用release,从而导致计数值递减,并且当计数值为零时,解除所有等待线程的阻塞。await调用acquire,当计数器为零时,acquire将立即返回,否则将阻塞。
14.6.3 FutureTask
- 在FutureTask中,AQS同步状态被用来保存任务的状态,例如,正在运行、已完成或已取消。
- FutureTask还维护一些额外的状态变量,用来保存计算结果或者抛出的异常。
- 此外,它还维护了一个引用,指向正在执行计算任务的线程(如果它当前处于运行状态),因而如果任务取消,该线程就会中断。
14.6.4 ReentrantReadWriteLock
- ReadWriteLock接口表示存在两个锁:一个读取锁和一个写入锁,但在基于AQS实现的ReentrantReadWriteLock中,单个AQS子类将同时管理读取加锁和写入加锁。
- Reentrant-ReadWriteLock使用了一个16位的状态来表示写入锁的计数,并且使用了另一个16位的状态来表示读取锁的计数。
- 在读取锁上的操作将使用共享的获取方法与释放方法,在写入锁上的操作将使用独占的获取方法与释放方法。
- AQS在内部维护一个等待线程队列,其中记录了某个线程请求的是独占访问还是共享访问.
- 在ReentrantReadWriteLock中,当锁可用时,如果位于队列头部的线程执行写入操作,那么线程会得到这个锁,如果位于队列头部的线程执行读取访问,那么队列中在第一个写入线程之前的所有线程都将获得这个锁。
小结
- 要实现一个依赖状态的类——如果没有满足依赖状态的前提条件,那么这个类的方法必须阻塞,那么最好的方式是基于现有的库类来构建,例如Semaphore.BlockingQueue或CountDownLatch,如第8章的ValueLatch所示。
- 然而,有时候现有的库类不能提供足够的功能,在这种情况下,可以使用内置的条件队列、显式的Condition对象或者AbstractQueuedSynchronizer来构建自己的同步器。
- 内置条件队列与内置锁是紧密绑定在一起的,这是因为管理状态依赖性的机制必须与确保状态一致性的机制关联起来。同样,显式的Condition与显式的Lock也是紧密地绑定到一起的,并且与内置条件队列相比,还提供了一个扩展的功能集,包括每个锁对应于多个等待线程集,可中断或不可中断的条件等待,公平或非公平的队列操作,以及基于时限的等待。
第15章 原子变量与非阻塞同步机制
- 与基于锁的方案相比,非阻塞算法在设计和实现上都要复杂得多,但它们在可伸缩性和活跃性上却拥有巨大的优势。
- 由于非阻塞算法可以使多个线程在竞争相同的数据时不会发生阻塞,因此它能在粒度更细的层次上进行协调,并且极大地减少调度开销。而且,在非阻塞算法中不存在死锁和其他活跃性问题。
15.1 锁的劣势
- 现代的许多JVM都对非竞争锁获取和锁释放等操作进行了极大的优化,但如果有多个线程同时请求锁,那么JVM就需要借助操作系统的功能。如果出现了这种情况,那么一些线程将被挂起并且在稍后恢复运行[插图]。当线程恢复执行时,必须等待其他线程执行完它们的时间片以后,才能被调度执行。在挂起和恢复线程等过程中存在着很大的开销,并且通常存在着较长时间的中断。
- 如果在基于锁的类中包含有细粒度的操作(例如同步容器类,在其大多数方法中只包含了少量操作),那么当在锁上存在着激烈的竞争时,调度开销与工作开销的比值会非常高。
- volatile变量同样存在一些局限:虽然它们提供了相似的可见性保证,但不能用于构建原子的复合操作。因此,当一个变量依赖其他的变量时,或者当变量的新值依赖于旧值时,就不能使用volatile变量。这些都限制了volatile变量的使用,因此它们不能用来实现一些常见的工具,例如计数器或互斥体(mutex)。
- 锁定还存在其他一些缺点。当一个线程正在等待锁时,它不能做任何其他事情。如果被阻塞线程的优先级较高,而持有锁的线程优先级较低,那么这将是一个严重的问题——也被称为优先级反转(Priority Inversion)。即使高优先级的线程可以抢先执行,但仍然需要等待锁被释放,从而导致它的优先级会降至低优先级线程的级别。
- 即使忽略这些风险,锁定方式对于细粒度的操作(例如递增计数器)来说仍然是一种高开销的机制。
15.2 硬件对并发的支持
- 计算机底层提供乐观的冲突检查机制指令。
15.2.1 比较并交换(CAS)
-
CAS包含了3个操作数——需要读写的内存位置V、进行比较的值A和拟写入的新值B。当且仅当V的值等于A时,CAS才会通过原子方式用新值B来更新V的值,否则不会执行任何操作。
-
程序清单15-1中的SimulatedCAS说明了CAS语义
//程序清单15-1 模拟CAS操作 @ThreadSafe public class SimulatedCAS{ @GuardedBy("this")private int value; public synchronized int get(){ return value; } public synchronized int compareAndSwap(int expectedValue,int newValue){ int oldValue=value; if(oldValue==expectedValue) value=newValue; return oldValue; } public synchronized boolean compareAndSet(int expectedValue,int newValue){ return(expectedValue==compareAndSwap(expectedValue, newValue)); } } -
失败的线程并不会被挂起(这与获取锁的情况不同:当获取锁失败时,线程将被挂起),而是被告知在这次竞争中失败,并可以再次尝试.
-
CAS的典型使用模式是:首先从V中读取值A,并根据A计算新值B,然后再通过CAS以原子方式将V中的值由A变成B(只要在这期间没有任何线程将V的值修改为其他值)。由于CAS能检测到来自其他线程的干扰,因此即使不使用锁也能够实现原子的读-改-写操作序列。
15.2.2 非阻塞的计数器
-
程序清单15-2中的CasCounter使用CAS实现了一个线程安全的计数器。递增操作采用了标准形式——读取旧的值,根据它计算出新值(加1),并使用CAS来设置这个新值。
//程序清单15-2 基于CAS实现的非阻塞计数器 @ThreadSafe public class CasCounter{ private SimulatedCAS value; public int getValue(){ return value.get(); } public int increment(){ int v; do{ v=value.get(); }while(v!=value.compareAndSwap(v, v+1)) ; return v+1; } } -
如果CAS失败,那么该操作将立即重试。通常,反复地重试是一种合理的策略,但在一些竞争很激烈的情况下,更好的方式是在重试之前首先等待一段时间或者回退,从而避免造成活锁问题。
-
CasCounter不会阻塞,但如果其他线程同时更新计数器,那么会多次执行重试操作。
-
当竞争程度不高时,基于CAS的计数器在性能上远远超过了基于锁的计数器,而在没有竞争时甚至更高.
-
如果要快速获取无竞争的锁,那么至少需要一次CAS操作再加上与其他锁相关的操作,因此基于锁的计数器即使在最好的情况下也会比基于CAS的计数器在一般情况下能执行更多的操作。由于CAS在大多数情况下都能成功执行(假设竞争程度不高),因此硬件能够正确地预测while循环中的分支,从而把复杂控制逻辑的开销降至最低。
-
在实现锁定时需要遍历JVM中一条非常复杂的代码路径,并可能导致操作系统级的锁定、线程挂起以及上下文切换等操作。
-
。在最好的情况下,在锁定时至少需要一次CAS,因此虽然在使用锁时没有用到CAS,但实际上也无法节约任何执行开销。另一方面,在程序内部执行CAS时不需要执行JVM代码、系统调用或线程调度操作。在应用级上看起来越长的代码路径,如果加上JVM和操作系统中的代码调用,那么事实上却变得更短。
-
CAS的主要缺点是,它将使调用者处理竞争问题(通过重试、回退、放弃),而在锁中能自动处理竞争问题(线程在获得锁之前将一直阻塞)。
15.2.3 JVM对CAS的支持
- 在支持CAS的平台上,运行时把它们编译为相应的(多条)机器指令。
- 在原子变量类(例如java.util.concurrent.atomic中的AtomicXxx)中使用了这些底层的JVM支持为数字类型和引用类型提供一种高效的CAS操作,而在java.util.concurrent中的大多数类在实现时则直接或间接地使用了这些原子变量类。
15.3 原子变量类
- 原子变量比锁的粒度更细,量级更轻,并且对于在多处理器系统上实现高性能的并发代码来说是非常关键的。
- 原子变量类相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。在发生竞争的情况下能提供更高的可伸缩性,因为它直接利用了硬件对并发的支持
- 共有12个原子变量类,可分为4组:标量类(Scalar)、更新器类、数组类以及复合变量类。最常用的原子变量就是标量类:AtomicInteger、AtomicLong、AtomicBoolean以及AtomicReference。所有这些类都支持CAS,此外,AtornicInteger和AtomicLong还支持算术运算。(要想模拟其他基本类型的原子变量,可以将short或byte等类型与int类型进行转换,以及使用floatToIntBits或doubleToLongBits来转换浮点数。)
- 原子数组类(只支持Integer、Long和Reference版本)中的元素可以实现原子更新。原子数组类为数组的元素提供了volatile类型的访问语义,这是普通数组所不具备的特性——volatile类型的数组仅在数组引用上具有volatile语义,而在其元素上则没有。
- 尽管原子的标量类扩展了Number类,但并没有扩展一些基本类型的包装类,例如Integer或Long。事实上,它们也不能进行扩展:基本类型的包装类是不可修改的,而原子变量类是可修改的。在原子变量类中同样没有重新定义hashCode或equals方法,每个实例都是不同的。与其他可变对象相同,它们也不宜用做基于散列的容器中的键值。
15.3.1 原子变量是一种“更好的volatile”
-
在程序清单15-3的CasNumber-Range中使用了AtomicReference和IntPair来保存状态,并通过使用compare-AndSet,使它在更新上界或下界时能避免NumberRange的竞态条件。
//程序清单15-3 通过CAS来维持包含多个变量的不变性条件 public class CasNumberRange{ @Immutable private static class IntPair{ final int lower; //不变性条件:lower<=upper final int upper; …… } private final AtomicReference<IntPair>values=new AtomicReference<IntPair>(new IntPair(0,0)); public int getLower(){ return values.get().lower; } public int getUpper(){ return values.get().upper; } public void setLower(int i){ while(true){ IntPair oldv=values.get(); if(i>oldv.upper) throw new IllegalArgumentException("Can't set lower to"+i+">upper"); IntPair newv=new IntPair(i, oldv.upper); if(values.compareAndSet(oldv, newv)) return; } } //对setUpper采用类似的方法 }
15.3.2 性能比较:锁与原子变量
-
CPU少高竞争的锁与原子类比较
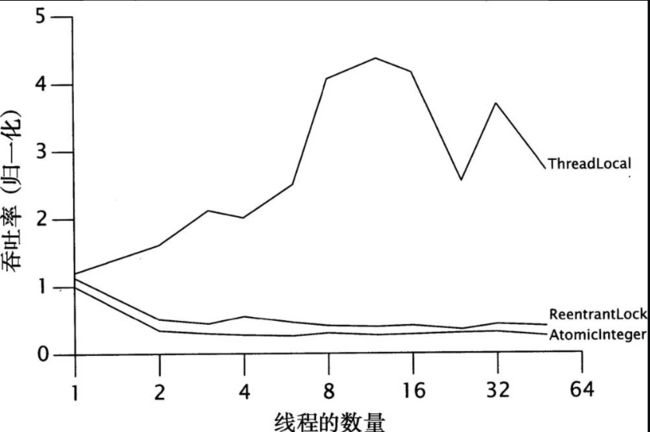
-
CPU多低竞争下锁与原子类比较
-
从这些图中可以看出,在高度竞争的情况下,锁的性能将超过原子变量的性能,但在更真实的竞争情况下,原子变量的性能将超过锁的性能.
-
这是因为锁在发生竞争时会挂起线程,从而降低了CPU的使用率和共享内存总线上的同步通信量。另一方面,如果使用原子变量,那么发出调用的类负责对竞争进行管理。与大多数基于CAS的算法一样,AtomicPseudoRandom在遇到竞争时将立即重试,这通常是一种正确的方法,但在激烈竞争环境下却导致了更多的竞争。
-
在实际情况中,原子变量在可伸缩性上要高于锁,因为在应对常见的竞争程度时,原子变量的效率会更高。
-
锁与原子变量在不同竞争程度上的性能差异很好地说明了各自的优势和劣势。在中低程度的竞争下,原子变量能提供更高的可伸缩性,而在高强度的竞争下,锁能够更有效地避免竞争。(在单CPU的系统上,基于CAS的算法在性能上同样会超过基于锁的算法,因为CAS在单CPU的系统上通常能执行成功,只有在偶然情况下,线程才会在执行读-改-写的操作过程中被其他线程抢占执行。)
-
在图15-1和图15-2中都包含了第三条曲线,它是一个使用ThreadLocal来保存PRNG状态的PseudoRandom。这种实现方法改变了类的行为,即每个线程都只能看到自己私有的伪随机数字序列,而不是所有线程共享同一个随机数序列,这说明了,如果能够避免使用共享状态,那么开销将会更小。我们可以通过提高处理竞争的效率来提高可伸缩性,但只有完全消除竞争,才能实现真正的可伸缩性。
15.4 非阻塞算法
- 如果在某种算法中,一个线程的失败或挂起不会导致其他线程也失败或挂起,那么这种算法就被称为非阻塞算法。
- 如果在算法的每个步骤中都存在某个线程能够执行下去,那么这种算法也被称为无锁(Lock-Free)算法。
- 如果在算法中仅将CAS用于协调线程之间的操作,并且能正确地实现,那么它既是一种无阻塞算法,又是一种无锁算法。
- 在非阻塞算法中通常不会出现死锁和优先级反转问题(但可能会出现饥饿和活锁问题,因为在算法中会反复地重试)。
15.4.1 非阻塞的栈
-
在程序清单15-6的ConcurrentStack中给出了如何通过原子引用来构建栈的示例。
//程序清单15-6 使用Treiber算法(Treiber,1986)构造的非阻塞栈 @ThreadSafe public class ConcurrentStack<E>{ AtomicReference<Node<E>>top=new AtomicReference<Node<E>>(); public void push(E item){ Node<E>newHead=new Node<E>(item); Node<E>oldHead; do{ oldHead=top.get(); newHead.next=oldHead; }while(!top.compareAndSet(oldHead, newHead)) ; } public E pop(){ Node<E>oldHead; Node<E>newHead; do{ oldHead=top.get(); if(oldHead==null) return null; newHead=oldHead.next; }while(!top.compareAndSet(oldHead, newHead)) ; return oldHead.item; } private static class Node<E>{ public final E item; public Node<E>next; public Node(E item){ this.item=item; } } } -
栈是由Node元素构成的一个链表,其中栈顶作为根节点,并且在每个元素中都包含了一个值以及指向下一个元素的链接。push方法创建一个新的节点,该节点的next域指向当前的栈顶,然后使用CAS把这个新节点放入栈顶。如果在开始插入节点时,位于栈顶的节点没有发生变化,那么CAS就会成功,如果栈顶节点发生了变化(例如由于其他线程在本线程开始之前插入或移除了元素),那么CAS将会失败,而push方法会根据栈的当前状态来更新节点,并且再次尝试。无论哪种情况,在CAS执行完成后,后栈仍会处于一致的状态。
-
在CasCounter和ConcurrentStack中说明了非阻塞算法的所有特性:某项工作的完成具有不确定性,必须重新执行。
-
在像ConcurrentStack这样的非阻塞算法中都能确保线程安全性,因为compareAndSet像锁定机制一样,既能提供原子性,又能提供可见性。
15.4.2 非阻塞的链表
-
链接队列比栈更为复杂,因为它必须支持对头节点和尾结点的快速访问。因此,它需要单独维护的头指针和尾指针。有两个指针指向位于尾部的节点:当前最后一个元素的next指针,以及尾节点。当成功地插入一个新元素时,这两个指针都需要采用原子操作来更新。
-
在更新这两个指针时需要不同的CAS操作,并且如果第一个CAS成功,但第二个CAS失败,那么队列将处于不一致的状态。而且,即使这两个CAS都成功了,那么在执行这两个CAS之间,仍可能有另一个线程会访问这个队列。因此,在为链接队列构建非阻塞算法时,需要考虑到这两种情况。
-
第一个技巧是,即使在一个包含多个步骤的更新操作中,也要确保数据结构总是处于一致的状态。这样,当线程B到达时,如果发现线程A正在执行更新,那么线程B就可以知道有一个操作已部分完成,并且不能立即开始执行自己的更新操作。然后,B可以等待(通过反复检查队列的状态)并直到A完成更新,从而使两个线程不会相互干扰。
-
虽然这种方法能够使不同的线程“轮流”访问数据结构,并且不会造成破坏,但如果一个线程在更新操作中失败了,那么其他的线程都无法再访问队列。要使得该算法成为一个非阻塞算法,必须确保当一个线程失败时不会妨碍其他线程继续执行下去。
-
**第二个技巧是,如果当B到达时发现A正在修改数据结构,那么在数据结构中应该有足够多的信息,使得B能完成A的更新操作。**如果B“帮助”A完成了更新操作,那么B可以执行自己的操作,而不用等待A的操作完成。当A恢复后再试图完成其操作时,会发现B已经替它完成了。
-
在许多队列算法中,空队列通常都包含一个“哨兵(Sentinel)节点”或者“哑(Dummy)节点”,并且头节点和尾节点在初始化时都指向该哨兵节点。尾节点通常要么指向哨兵节点(如果队列为空),即队列的最后一个元素,要么(当有操作正在执行更新时)指向倒数第二个元素。图15-3给出了一个处于正常状态(或者说稳定状态)的包含两个元素的队列。

-
在程序清单15-7的LinkedQueue中给出了Michael-Scott提出的非阻塞链接队列算法中的插入部分(Michael and Scott,1996),在ConcurrentLinkedQueue中使用的正是该算法。
//程序清单15-7 Michael-Scott(Michael and Scott,1996)非阻塞算法中的插入算法 @ThreadSafe public class LinkedQueue<E>{ private static class Node<E>{ final E item; final AtomicReference<Node<E>>next; public Node(E item, Node<E>next){ this.item=item; this.next=new AtomicReference<Node<E>>(next); } } //哨兵节点 private final Node<E>dummy=new Node<E>(null, null); private final AtomicReference<Node<E>>head=new AtomicReference<Node<E>>(dummy); private final AtomicReference<Node<E>>tail=new AtomicReference<Node<E>>(dummy); public boolean put(E item){ Node<E>newNode=new Node<E>(item, null); while(true){ Node<E>curTail=tail.get(); Node<E>tailNext=curTail.next.get(); if(curTail==tail.get()){ if(tailNext!=null){ //A 队列处于中间状态,推进尾节点 tail.compareAndSet(curTail, tailNext); }else{ //B 处于稳定状态,尝试插入新节点 if(curTail.next.compareAndSet(null, newNode)){ //C 插入操作成功,尝试推进尾节点 tail.compareAndSet(curTail, newNode); //D return true; } } } } } }- 当插入一个新的元素时,需要更新两个指针。首先更新当前最后一个元素的next指针,将新节点链接到列表队尾,然后更新尾节点,将其指向这个新元素。在这两个操作之间,队列处于一种中间状态,在第二次更新完成后,队列将再次处于稳定状态.
- 实现这两个技巧时的关键点在于:当队列处于稳定状态时,尾节点的next域将为空,如果队列处于中间状态,那么tail.next将为非空。因此,任何线程都能够通过检查tail.next来获取队列当前的状态。而且,当队列处于中间状态时,可以通过将尾节点向前移动一个节点,从而结束其他线程正在执行的插入元素操作,并使得队列恢复为稳定状态。
- LinkedQueue.put方法在插入新元素之前,将首先检查队列是否处于中间状态(步骤A)。如果是,那么有另一个线程正在插入元素(在步骤C和D之间)。此时当前线程不会等待其他线程执行完成,而是帮助它完成操作,并将尾节点向前推进一个节点(步骤B)。然后,它将重复执行这种检查,以免另一个线程已经开始插入新元素,并继续推进尾节点,直到它发现队列处于稳定状态之后,才会开始执行自己的插入操作。
- 由于步骤C中的CAS将把新节点链接到队列尾部,因此如果两个线程同时插入元素,那么这个CAS将失败。在这样的情况下,并不会造成破坏:不会发生任何变化,并且当前的线程只需重新读取尾节点并再次重试。如果步骤C成功了,那么插入操作将生效,第二个CAS(步骤D)被认为是一个“清理操作”,因为它既可以由执行插入操作的线程来执行,也可以由其他任何线程来执行。如果步骤D失败,那么执行插入操作的线程将返回,而不是重新执行CAS,因为不再需要重试——另一个线程已经在步骤B中完成了这个工作。
15.4.3 原子的域更新器
-
在ConcurrentLinkedQueue中没有使用原子引用来表示每个Node,而是使用普通的volatile类型引用,并通过基于反射的AtomicReferenceFieldUpdater来进行更新,如程序清单15-8所示
//程序清单15-8 在ConcurrentLinkedQueue中使用原子的域更新器 private class Node<E>{ private final E item; private volatile Node<E>next; public Node(E item){ this.item=item; } private static AtomicReferenceFieldUpdater<Node, Node>nextUpdater=AtomicReferenceFieldUpdater.newUpdater(Node.class, Node.class,"next"); } -
原子的域更新器类表示现有volatile域的一种基于反射的“视图”,从而能够在已有的volatile域上使用CAS.
-
在更新器类中没有构造函数,要创建一个更新器对象,可以调用newUpdater工厂方法,并制定类和域的名字。域更新器类没有与某个特定的实例关联在一起,因而可以更新目标类的任意实例中的域。更新器类提供的原子性保证比普通原子类更弱一些,因为无法保证底层的域不被直接修改——compareAndSet以及其他算术方法只能确保其他使用原子域更新器方法的线程的原子性。
-
在ConcurrentLinkedQueue中,使用nextUpdater的compareAndSet方法来更新Node的next域。
-
几乎在所有情况下,普通原子变量的性能都很不错,只有在很少的情况下才需要使用原子的域更新器。(如果在执行原子更新的同时还需要维持现有类的串行化形式,那么原子的域更新器将非常有用。)
15.4.4 ABA问题
- ABA问题是一种异常现象:如果在算法中的节点可以被循环使用,那么在使用“比较并交换”指令时就可能出现这种问题(主要在没有垃圾回收机制的环境中)。
- 有时候还需要知道“自从上次看到V的值为A以来,这个值是否发生了变化?”在某些算法中,如果V的值首先由A变成B,再由B变成A,那么仍然被认为是发生了变化,并需要重新执行算法中的某些步骤。
- 如果在算法中采用自己的方式来管理节点对象的内存,那么可能出现ABA问题。在这种情况下,即使链表的头节点仍然指向之前观察到的节点,那么也不足以说明链表的内容没有发生改变。
- 如果通过垃圾回收器来管理链表节点仍然无法避免ABA问题,那么还有一个相对简单的解决方案:不是更新某个引用的值,而是更新两个值,包括一个引用和一个版本号。即使这个值由A变为B,然后又变为A,版本号也将是不同的。
- AtomicStampedReference(以及AtomicMarkableReference)支持在两个变量上执行原子的条件更新。AtomicStampedReference将更新一个“对象-引用”二元组,通过在引用上加上“版本号”,从而避免[插图]ABA问题。类似地,AtomicMarkableReference将更新一个“对象引用-布尔值”二元组,在某些算法中将通过这种二元组使节点保存在链表中同时又将其标记为“已删除的节点”。
小结
- 非阻塞算法通过底层的并发原语(例如比较并交换而不是锁)来维持线程的安全性。
- 这些底层的原语通过原子变量类向外公开,这些类也用做一种“更好的volatile变量”,从而为整数和对象引用提供原子的更新操作。
- 非阻塞算法在设计和实现时非常困难,但通常能够提供更高的可伸缩性,并能更好地防止活跃性故障的发生。
- 在JVM从一个版本升级到下一个版本的过程中,并发性能的主要提升都来自于(在JVM内部以及平台类库中)对非阻塞算法的使用。
第16章 Java内存模型
- 我们尽可能地避开了Java内存模型(JMM)的底层细节,而将重点放在一些高层设计问题,例如安全发布,同步策略的规范以及一致性等
- 本章将介绍Java内存模型的底层需求以及所提供的保证,此外还将介绍在本书给出的一些高层设计原则背后的原理。
16.1 什么是内存模型,为什么需要它
- JVM的重排序提高了性能,但是阻碍了局部有依赖的串行性;
- JVM的数据保存在寄存器或者缓存中,对其他处理器而言不是可见的;
- 为了提高性能,增加处理器核心方式取代了提高时钟频率的方式;
- 对于线程共享变量,以上几点矛盾无疑需要解决。
- JMM规定了JVM必须遵循一组最小保证,这组保证规定了对变量的写入操作在何时将对于其他线程可见。JMM在设计时就在可预测性和程序的易于开发性之间进行了权衡,从而在各种主流的处理器体系架构上能实现高性能的JVM。
16.1.1 平台的内存模型
- 在不同的平台,要想确保每个处理器都能在任意时刻知道其他处理器正在进行的工作,将需要非常大的开销。
- 为了使Java开发人员无须关心不同架构上内存模型之间的差异,Java还提供了自己的内存模型,并且JVM通过在适当的位置上插入内存栅栏来屏蔽在JMM与底层平台内存模型之间的差异。
- 程序执行一种简单假设:想象在程序中只存在唯一的操作执行顺序,而不考虑这些操作在何种处理器上执行,并且在每次读取变量时,都能获得在执行序列中(任何处理器)最近一次写入该变量的值。这种乐观的模型就被称为串行一致性。
- 在现代支持共享内存的多处理器(和编译器)中,当跨线程共享数据时,会出现一些奇怪的情况,除非通过使用内存栅栏来防止这些情况的发生。幸运的是,Java程序不需要指定内存栅栏的位置,而只需通过正确地使用同步来找出何时将访问共享状态。
16.1.2 重排序
- 各种使操作延迟或者看似乱序执行的不同原因,都可以归为重排序。
- 由于每个线程中的各个操作之间不存在数据流依赖性,因此这些操作可以乱序执行。(即使这些操作按照顺序执行,但在将缓存刷新到主内存的不同时序中也可能出现这种情况,从线程B的角度看,线程A中的赋值操作可能以相反的次序执行。)
- 内存级的重排序会使程序的行为变得不可预测。如果没有同步,那么推断出执行顺序将是非常困难的,而要确保在程序中正确地使用同步却是非常容易的。同步将限制编译器、运行时和硬件对内存操作重排序的方式,从而在实施重排序时不会破坏JMM提供的可见性保证。
16.1.3 Java内存模型简介
- Java内存模型是通过各种操作来定义的,包括对变量的读/写操作,监视器的加锁和释放操作,以及线程的启动和合并操作。
- JMM为程序中所有的操作定义了一个偏序关系[插图],称之为Happens-Before。要想保证执行操作B的线程看到操作A的结果(无论A和B是否在同一个线程中执行),那么在A和B之间必须满足Happens-Before关系。如果两个操作之间缺乏Happens-Before关系,那么JVM可以对它们任意地重排序。
- 当一个变量被多个线程读取并且至少被一个线程写入时,如果在读操作和写操作之间没有依照Happens-Before来排序,那么就会产生数据竞争问题。
- Happens-Before的规则包括:
- 程序顺序规则。如果程序中操作A在操作B之前,那么在线程中A操作将在B操作之前执行。
- 监视器锁规则。在监视器锁上的解锁操作必须在同一个监视器锁上的加锁操作之前执行。
- volatile变量规则。对volatile变量的写入操作必须在对该变量的读操作之前执行。
- 线程启动规则。在线程上对Thread.Start的调用必须在该线程中执行任何操作之前执行。
- 线程结束规则。线程中的任何操作都必须在其他线程检测到该线程已经结束之前执行,或者从Thread.join中成功返回,或者在调用Thread.isAlive时返回false。
- 中断规则。当一个线程在另一个线程上调用interrupt时,必须在被中断线程检测到interrupt调用之前执行(通过抛出InterruptedException,或者调用isInterrupted和interrupted)。
- 终结器规则。对象的构造函数必须在启动该对象的终结器之前执行完成。
- 传递性。如果操作A在操作B之前执行,并且操作B在操作C之前执行,那么操作A必须在操作C之前执行。
16.1.4 借助同步
-
由于Happens-Before的排序功能很强大,因此有时候可以“借助(Piggyback)”现有同步机制的可见性属性。这需要将Happens-Before的程序顺序规则与其他某个顺序规则(通常是监视器锁规则或者volatile变量规则)结合起来,从而对某个未被锁保护的变量的访问操作进行排序。
-
这项技术由于对语句的顺序非常敏感,因此很容易出错。它是一项高级技术,并且只有当需要最大限度地提升某些类(例如ReentrantLock)的性能时,才应该使用这项技术。
-
程序清单16-2给出了innerSet和innerGet等方法,在保存和获取result时将调用这些方法。由于innerSet将在调用releaseShared(这又将调用tryReleaseShared)之前写入result,并且innerGet将在调用acquireShared(这又将调用tryReleaseShared)之后读取result,因此将程序顺序规则与volatile变量规则结合在一起,就可以确保innerSet中的写入操作在innerGet中的读取操作之前执行。
//程序清单16-2 说明如何借助同步的FutureTask的内部类 //FutureTask的内部类 private final class Sync extends AbstractQueuedSynchronizer{ private static final int RUNNING=1,RAN=2,CANCELLED=4; private V result; private Exception exception; void innerSet(V v){ while(true){ int s=getState(); if(ranOrCancelled(s)) return; if(compareAndSetState(s, RAN)) break; } result=v; releaseShared(0); done(); } V innerGet()throws InterruptedException, ExecutionException{ acquireSharedInterruptibly(0); if(getState()==CANCELLED) throw new CancellationException(); if(exception!=null) throw new ExecutionException(exception); return result; } } -
之所以将这项技术称为“借助”,是因为它使用了一种现有的Happens-Before顺序来确保对象X的可见性,而不是专门为了发布X而创建一种Happens-Before顺序。
-
下,这种“借助”技术是非常合理的。例如,当某个类在其规范中规定它的各个方法之间必须遵循一种Happens-Before关系,基于BlockingQueue实现的安全发布就是一种“借助”。如果一个线程将对象置入队列并且另一个线程随后获取这个对象,那么这就是一种安全发布,因为在BlockingQueue的实现中包含有足够的内部同步来确保入列操作在出列操作之前执行。
-
在类库中提供的其他Happens-Before排序包括:
- 将一个元素放入一个线程安全容器的操作将在另一个线程从该容器中获得这个元素的操作之前执行。
- 在CountDownLatch上的倒数操作将在线程从闭锁上的await方法中返回之前执行。
- 释放Semaphore许可的操作将在从该Semaphore上获得一个许可之前执行。
- Future表示的任务的所有操作将在从Future.get中返回之前执行。
- 向Executor提交一个Runnable或Callable的操作将在任务开始执行之前执行。
-
·一个线程到达CyclicBarrier或Exchanger的操作将在其他到达该栅栏或交换点的线程被释放之前执行。如果CyclicBarrier使用一个栅栏操作,那么到达栅栏的操作将在栅栏操作之前执行,而栅栏操作又会在线程从栅栏中释放之前执行。
16.2 发布
16.2.1 不安全的发布
-
如果无法确保发布共享引用的操作在另一个线程加载该共享引用之前执行,那么对新对象引用的写入操作将与对象中各个域的写入操作重排序(从使用该对象的线程的角度来看)。
-
在这种情况下,另一个线程可能看到对象引用的最新值,但同时也将看到对象的某些或全部状态中包含的是无效值,即一个被部分构造对象。
-
错误的延迟初始化将导致不正确的发布,如程序清单16-3所示
//程序清单16-3 不安全的延迟初始化(不要这么做) @NotThreadSafe public class UnsafeLazyInitialization{ private static Resource resource; public static Resource getInstance(){ if(resource==null) resource=new Resource(); //不安全的发布 return resource; } } -
初看起来,在程序中存在的问题只有在2.2.2节中介绍的竞态条件问题。在某些特定条件下,例如当Resource的所有实例都相同时,你或许会忽略这些问题(以及在多次创建Resource实例时存在的低效率问题)。然而,即使不考虑这些问题,UnsafeLazyInitialization仍然是不安全的,因为另一个线程可能看到对部分构造的Resource实例的引用。
-
假设线程A是第一个调用getInstance的线程。它将看到resource为null,并且初始化一个新的Resource,然后将resource设置为执行这个新实例。当线程B随后调用getInstance,它可能看到resource的值为非空,因此使用这个已经构造好的Resource。最初这看不出任何问题,但线程A写入resource的操作与线程B读取resource的操作之间不存在Happens-Before关系。在发布对象时存在数据竞争问题,因此B并不一定能看到Resource的正确状态。
-
当新分配一个Resource时,Resource的构造函数将把新实例中的各个域由默认值(由Object构造函数写入的)修改为它们的初始值。由于在两个线程中都没有使用同步,因此线程B看到的线程A中的操作顺序,可能与线程A执行这些操作时的顺序并不相同。因此,即使线程A初始化Resource实例之后再将resource设置为指向它,线程B仍可能看到对resource的写入操作将在对Resource各个域的写入操作之前发生。因此,线程B就可能看到一个被部分构造的Resource实例,该实例可能处于无效状态,并在随后该实例的状态可能出现无法预料的变化。
-
除了不可变对象以外,使用被另一个线程初始化的对象通常都是不安全的,除非对象的发布操作是在使用该对象的线程开始使用之前执行。
16.2.2 安全的发布
- 保证发布对象的操作将在使用对象的线程开始使用该对象的引用之前执行。
- 通过使用一个由锁保护共享变量或者使用共享的volatile类型变量,也可以确保对该变量的读取操作和写入操作按照Happens-Before关系来排序。
- 事实上,Happens-Before比安全发布提供了更强可见性与顺序保证。
- 与内存写入操作的可见性相比,从转移对象的所有权以及对象公布等角度来看,它们更符合大多数的程序设计。Happens-Before排序是在内存访问级别上操作的,它是一种“并发级汇编语言”,而安全发布的运行级别更接近程序设计。
16.2.3 安全初始化模式
-
有时候,我们需要推迟一些高开销的对象初始化操作,并且只有当使用这些对象时才进行初始化,但我们也看到了在误用延迟初始化时导致的问题。在程序清单16-4中,通过将getResource方法声明为synchronized,可以修复UnsafeLazyInitialization中的问题。
//程序清单16-4 线程安全的延迟初始化 @ThreadSafe public class SafeLazyInitialization{ private static Resource resource; public synchronized static Resource getInstance(){ if(resource==null) resource=new Resource(); return resource; } }- 由于getInstance的代码路径很短(只包括一个判断预见和一个预测分支),因此如果getInstance没有被多个线程频繁调用,那么在SafeLazyInitialization上不会存在激烈的竞争,从而能提供令人满意的性能。
-
静态初始化器是由JVM在类的初始化阶段执行,即在类被加载后并且被线程使用之前。由于JVM将在初始化期间获得一个锁[JLS 12.4.2],并且每个线程都至少获取一次这个锁以确保这个类已经加载,因此在静态初始化期间,内存写入操作将自动对所有线程可见。因此无论是在被构造期间还是被引用时,静态初始化的对象都不需要显式的同步。
-
如程序清单16-5所示,通过使用提前初始化(Eager Initialization),避免了在每次调用SafeLazyInitialization中的getInstance时所产生的同步开销。通过将这项技术和JVM的延迟加载机制结合起来,可以形成一种延迟初始化技术,从而在常见的代码路径中不需要同步。
//程序清单16-5 提前初始化 @ThreadSafe public class EagerInitialization{ private static Resource resource=new Resource(); public static Resource getResource(){ return resource; } } -
在程序清单16-6的“延迟初始化占位(Holder)类模式”[EJ Item 48]中使用了一个专门的类来初始化Resource。JVM将推迟ResourceHolder的初始化操作,直到开始使用这个类时才初始化[JLS 12.4.1],并且由于通过一个静态初始化来初始化Resource,因此不需要额外的同步。
//程序清单16-6 延长初始化占位类模式 @ThreadSafe public class ResourceFactory{ private static class ResourceHolder{ public static Resource resource=new Resource(); } public static Resource getResource(){ return ResourceHolder.resource; } }
16.2.4 双重检查加锁
-
如程序清单16-7所示双重检查加锁(DCL)
//程序清单16-7 双重检查加锁(不要这么做 @NotThreadSafe public class DoubleCheckedLocking{ private static Resource resource;public static Resource getInstance(){ if(resource==null){ synchronized(DoubleCheckedLocking.class){ if(resource==null) resource=new Resource(); } } return resource; } } -
DCL的真正问题在于:当在没有同步的情况下读取一个共享对象时,可能发生的最糟糕事情只是看到一个失效值(在这种情况下是一个空值),此时DCL方法将通过在持有锁的情况下再次尝试来避免这种风险。然而,实际情况远比这种情况糟糕——线程可能看到引用的当前值,但对象的状态值却是失效的,这意味着线程可以看到对象处于无效或错误的状态。
-
如果把resource声明为volatile类型,那么就能启用DCL,并且这种方式对性能的影响很小,因为volatile变量读取操作的性能通常只是略高于非volatile变量读取操作的性能。
16.3 初始化过程中的安全性
-
如果能确保初始化过程的安全性,那么就可以使得被正确构造的不可变对象在没有同步的情况下也能安全地在多个线程之间共享,而不管它们是如何发布的,甚至通过某种数据竞争来发布。
-
初始化安全性将确保,对于被正确构造的对象,所有线程都能看到由构造函数为对象给各个final域设置的正确值,而不管采用何种方式来发布对象。
-
初始化安全性意味着,程序清单16-8的SafeStates可以安全地发布,即便通过不安全的延迟初始化,或者在没有同步的情况下将SafeStates的引用放到一个公有的静态域,或者没有使用同步以及依赖于非线程安全的HashSet。
//程序清单16-8 不可变对象的初始化安全性 @ThreadSafe public class SafeStates{ private fnal Map<String, String>states; public SafeStates(){ states=new HashMap<String, String>(); states.put("alaska","AK"); states.put("alabama","AL"); …… states.put("wyoming","WY"); } public String getAbbreviation(String s){ return states.get(s); } } -
初始化安全性只能保证通过final域可达的值从构造过程完成时开始的可见性。对于通过非final域可达的值,或者在构成过程完成后可能改变的值,必须采用同步来确保可见性。
小结
- Java内存模型说明了某个线程的内存操作在哪些情况下对于其他线程是可见的。其中包括确保这些操作是按照一种Happens-Before的偏序关系进行排序,而这种关系是基于内存操作和同步操作等级别来定义的。
- 如果缺少充足的同步,那么当线程访问共享数据时,会发生一些非常奇怪的问题。
- 如果使用第2章与第3章介绍的更高级规则,例如@GuardedBy和安全发布,那么即使不考虑Happens-Before的底层细节,也能确保线程安全性。