监控系统架构方案
前言
对于企业级服务器管理,站群管理,针对服务器的监控是非常必要的。
通常,在电脑出现卡死,或进程停止或被挂起的情况下,大家都会使用任务管理器查看进程情况。针对电脑流畅性或资源优化,通常会使用资源管理器进行分析。然而,像windows资源管理器在开启的情况下,仅能查看六十秒的资源使用。而linux下,我们使用top,htop等命令,或ps等命令查看进程与资源使用情况也是仅能查看实时监控的。
那么,在该情况下若服务器出现问题,命令无法执行的情况下如何快速定位问题所在及资源占用情况?
从商业云服务上看,像是ucloud,tencent,aliyun等厂商的云服务器都提供了资源监控。但基础资源监控仅能帮助我们判定该服务器是因为内存,还是磁盘等资源过载而导致的宕机。然而,这种资源监控都是针对单个服务器的,不可将所有服务器实现统一监控,而在监控可视化方面也是可选性太低。
那么,针对服务器实现统一监控与集中化管理,这里我们使用Prometheus监控系统作演示。
Prometheus
Prometheus, a Cloud Native Computing Foundation project, is a systems and service monitoring system. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts when specified conditions are observed.
The features that distinguish Prometheus from other metrics and monitoring systems are:
- A multi-dimensional data model (time series defined by metric name and set of key/value dimensions)
- PromQL, a powerful and flexible query language to leverage this dimensionality
- No dependency on distributed storage; single server nodes are autonomous
- An HTTP pull model for time series collection
- Pushing time series is supported via an intermediary gateway for batch jobs
- Targets are discovered via service discovery or static configuration
- Multiple modes of graphing and dashboarding support
- Support for hierarchical and horizontal federation
Prometheus 是一个云原生计算基金会项目,是一个系统和服务监控系统。 它以给定的时间间隔从配置的目标收集指标,评估规则表达式,显示结果,并在观察到指定条件时触发警报。
Prometheus 与其他指标和监控系统的区别在于:
多维数据模型(由指标名称和键/值维度集定义的时间序列)
PromQL,一种强大且灵活的查询语言,可利用此维度
不依赖分布式存储; 单个服务器节点是自治的
用于时间序列收集的 HTTP 拉取模型
通过用于批处理作业的中间网关支持推送时间序列
通过服务发现或静态配置发现目标
图形和仪表板支持的多种模式
支持分层和水平联合
我们来看看Prometheus的架构
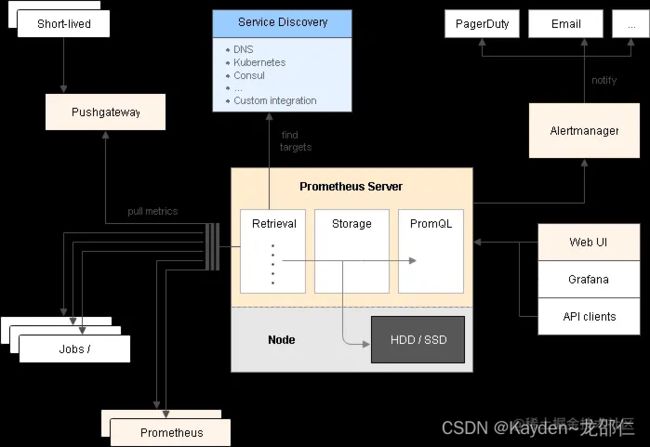
架构方案
假设我们有四个服务器,一个为windows系统,三个为linux系统。
我们使用其中一个linux服务器作为监控中心。
我们将服务器标记为A、B、C、D。
A:监控中心linux服务器(192.168.0.1)
B:linux服务器(192.168.0.2)
C:linux服务器(192.168.0.3)
D:windows服务器(192.168.0.4)
对于监控中心,我们部署grafana和prometheue于A服务器。Prometheus在采集各服务器数据后,由监控中心的Grafana对Prometheus所采集的数据进行展示。
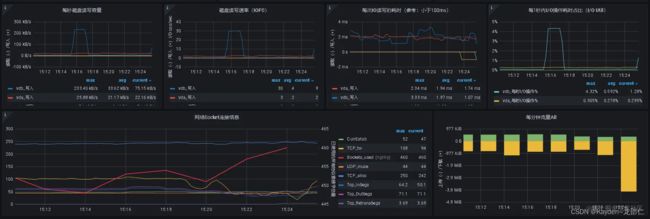
针对服务器内存、CPU、硬盘、I/O,我们可以使用prometheus-node-exporter进行采集后,由监控中心Prometheus采集节点数据。效果如下:

对于windows服务器的资源监控展示,如下:
(资源监控windows和linux默认不于同一页面展示,若不使用官方模板,可以自行编写Dashboard更改sql语句适应性)
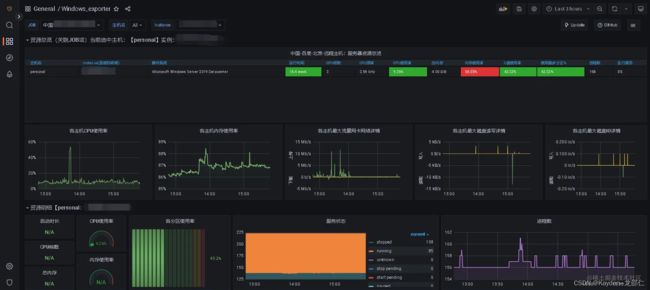

该方案可实现对于多台服务器针对资源占用监控。而当任何一台服务器异常,我们都可以查看Grafana监控并查看异常所在。
针对linux进程,我们可以使用prometheus-process-exporter进行采集,由由监控中心Prometheus采集节点数据。效果如下:
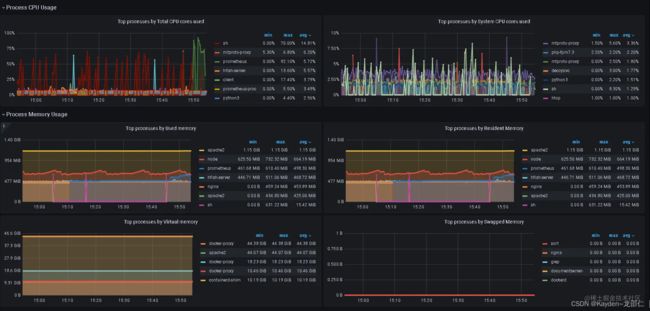


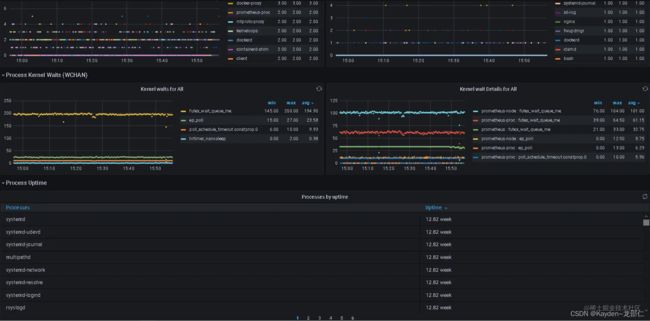
如此,在任何服务器出现任何异常时,我们都能够对异常情况进行快速定位。仅需到监控中心查看资源占用情况,并查看对应服务器的进程监控,即可得出结论。
部署说明
仅prometheus+grafana监控服务器资源
根据架构规划,我们先部署A服务器的promethus,再部署B,C,D服务器的prometheus-nide-exporter。
以下部署方案为基于pull的部署方案。

A服务器部署
Prometheus部署
我们先部署A服务器(监控中心)。
由于使用APT包管理器直接下载Prometheus是默认包含prometheus-node-exporter的,因此我们直接使用APT命令下载Prometheus即可。
apt install prometheus
进入prometheus文件夹并添加节点信息
cd /etc/prometheus
vim prometheus.yml
于配置文件末尾加入以下配置,采集节点数据。
- job_name: linux-node-1
static_configs:
- targets: ['192.168.0.1:9100']
- job_name: linux-node-2
static_configs:
- targets: ['192.168.0.2:9100']
- job_name: linux-node-3
static_configs:
- targets: ['192.168.0.3:9100']
- job_name: windows-node-4
static_configs:
- targets: ['192.168.0.4:9100']
备注:此处linux-node-1为需要采集的主机名,targets:[‘ip:port’]此处为需要采集的IP和端口。主机名不可重复,prometheus-node-exporter的默认端口为9001。
我们也可以修改配置文件,修改抓取间隔。如下示例为每10s抓取一次。
scrape_interval: 10s
更改配置文件后,使用以下命令重启Prometheus服务即可。
如果需要更改prometheus-node-exporter端口,可使用以下命令挂起。以下示例为使用9101端口。
prometheus-node-exporter --web.listen-address=":9101" &
由于使用以上命令挂起,在重启后是失效,我们可以使用以下命令将该命令写入开机自启动与定时任务。
cat > /etc/rc.local << EOF
prometheus-node-exporter --web.listen-address=":9101" &
EOF
当然,我们也可以使用crontab -e将该命令写入定时任务。
Grafana部署
这里我们使用docker部署grafana。
linux系统下没有安装docker的,可以使用笔者提供的一键安装docker命令。
wget [email protected] --http-passwd=HSC2019 https://download.hscsec.cn/docker.sh && chmod +777 docker.sh && ./docker.sh
以上命令将自动安装最新版的docker及docker-compose,并替换镜像为腾讯。
使用以下命令启动Grafana
docker run -d --name=grafana -p 3000:3000 --restart=always grafana/grafana-enterprise:latest
启动后,访问3000端口,使用默认账号:admin;密码:admin即可登录。
登录后,于仪表盘导入官方仪表盘,进入import输入仪表盘编号并导入。
- 主机监控(linux):8919
- 进程监控(linux) 8378
- 主机监控(windows): 10467
B,C服务器部署
使用APT包管理器安装prometheus-node-exporter即可。
apt install prometheus-node-exporter
对于访问控制,建议在防火墙设置9100端口白名单,仅允许监控中心服务器访问(192.168.0.1)。云服务器厂商提供控制台防火墙服务的可以直接设置,也可以使用iptables设置。
D服务器部署
对于windows服务器,我们只需在github下载最的prometheus-node-exporter发布版本并运行即可。当然,我们也可以把他设置为开机自启动。
github地址:
prometheus-community / windows_exporter
prometheus+grafana监控服务器资源与进程
由于进程监控仅适用于linux,不适用于windows系统,本部分仅说明对于linux进程监控的部署。
本部分内容为基于以上部分。
A,B,C服务器部署
对于linux服务器我们使用apt包管理器安装prometheus-process-exporter即可。
apt install prometheus-process-exporter
安装后,Grafana并不能直接展示使用上文提到的面板展示数据。我们需要运行以下命令更改配置文件并重启使数据能够正常获取并展示。
apt-get install prometheus-process-exporter -y
mkdir -p /etc/prometheus-process-exporter
cat > /etc/prometheus-process-exporter/prometheus-process-exporter.yaml << EOF
process_names:
- name: "{{.Comm}}"
cmdline:
- '.+'
EOF
systemctl stop prometheus-process-exporter
cat > /lib/systemd/system/prometheus-process-exporter.service << EOF
[Unit]
Description=Prometheus exporter that mines /proc to report on selected processes
Documentation=https://github.com/ncabatoff/process-exporter man:prometheus-process-exporter(1)
After=network.target
[Service]
User=prometheus
EnvironmentFile=/etc/default/prometheus-process-exporter
ExecStart=/usr/bin/prometheus-process-exporter -config.path /etc/prometheus-process-exporter/prometheus-process-exporter.yaml
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl restart prometheus-process-exporter
对于访问控制,建议在防火墙设置9256端口白名单,仅允许监控中心服务器访问(192.168.0.1)。云服务器厂商提供控制台防火墙服务的可以直接设置,也可以使用iptables设置。
在A服务器更改配置文件:
cd /etc/prometheus
vim prometheus.yml
于配置文件末尾加入以下配置,采集节点数据。
- job_name: linux-node-process-1
static_configs:
- targets: ['192.168.0.1:9256']
- job_name: linux-node-process-2
static_configs:
- targets: ['192.168.0.2:9256']
- job_name: linux-node-process-3
static_configs:
- targets: ['192.168.0.3:9256']
更改配置文件后使用以下命令重启Prometheus服务即可。
systemctl restart prometheus