Modern C++ 学习笔记——C++函数式编程
往期精彩:
- Modern C++ 学习笔记——易用性改进篇
- Modern C++ 学习笔记 —— 右值、移动篇
- Modern C++ 学习笔记 —— 智能指针篇
- Modern C++ 学习笔记 —— lambda表达式篇
- Modern C++ 学习笔记 —— C++面向对象编程
- Modern C++ 学习笔记 —— C++函数式编程
Modern C++ 学习笔记——C++函数式编程
关键字:lambda表达式、函数式编程
文章目录
- Modern C++ 学习笔记——C++函数式编程
-
- 函数式编程
-
- 什么是函数式编程?
- 函数式编程
- 函数式编程的特点
- 函数式编程用到的技术
-
- first class function(头等函数)
- map & reduce & filter
-
- map
- reduce
- filter
- pipeline(管道)
- currying (柯里化)
- recursing & tail recursion optimization (递归&尾递归优化)
函数式编程
在之前的系列文章中介绍过函数对象和lambda表达式,本篇文章就来讲讲它们的主要用途——函数式编程。
什么是函数式编程?
那什么是函数编程呢?它其实来自于数学中的理念.
f(x) = 2x^2 +x+3
g(x) = 3f(x) + 5 = 6x^2 + 3x + 14
h(x) = f(x) + g(x) = 8x^2 + 4x + 17
正如上面的数学函数一样,对于函数式编程,它只关心于定义输入数据和输出数据的关系,在数学表达式中我们称其为输入与输出的一种映射(map),即用函数定义输入数据和输出数据的关系是什么样的。
这样就可以得到关于函数式编程一下特点:
- 无状态:函数不维护任何状态。函数式编程的核心精神是stateless。
- 不可变数据:输入数据不可变,动了输入数据就有危险,所以要返回新的数据集。
或许这么说有点干燥,为了更好的帮助理解,再举一个最简单的例子:
int copy_add(int x, int y)
{
return x + y;
}
int nocopy_add(int& x, int& y)
{
x += y;
return x;
}
以上两个函数都实现了对输入的两个int类型值进行相加并且返回的功能,第一个函数式比较纯粹的函数,符合我们上面所说的函数式编程的特点。再看第二个函数,它将入参设为引用(在项目中,为了减少值对象拷贝的性能消耗,常把入参设为引用),这就带来了问题——入参很容易在函数内部被改变。
在著作《Functional Programming in C++》(非常推荐此书)中给出了关于函数式编程的定义:
Functional programming is a style of programming that emphasizes the evaluation of expressions, rather than execution of commands. The expressions in these languages are formed by using functions to combine basic values. A functional language is a language that supports and encourages programming in a functional style.
简单来说:在OOP(面向对象编程)中,正如大多数人做的那样,更多的考虑是算法的步骤,即对对象的处理。而在函数式编程里你需要学会如下的思考方式:什么是输入,什么是输出,还有需要执行哪些转换将两者映射起来。
函数式编程
在介绍了函数编程之后,我们尝试使用其思想来解决实际的问题:假如有个vector保存着文件中的所有单词,需要统计其所有单词出现的频率,并且按照评率高低输出对应单词。最传统的命令式编程大概会这么写:
void print_word(vector<string>& words) {
unordered_map<string, int> wordCount;
for (auto&& s : words) {
unordered_map<string, int>::iterator iter = wordCount.find(s);
if (iter == wordCount.end()) {
wordCount.insert({s, 1});
} else {
wordCount[s]++;
}
}
vector<pair<int, string>> reverseword;
for (auto it = wordCount.begin(); it != wordCount.end(); ++it) {
reverseword.emplace_back(make_pair(it->second, it->first));
}
sort(reverseword.begin(), reverseword.end(), [](const pair<int, string>& lhs, const pair<int, string>& rhs) {
return lhs.first > rhs.first;
}); // 高阶函数
for (auto& p : reverseword) {
cout << "word is " << p.second << ", count is " << p.first << endl;
}
}
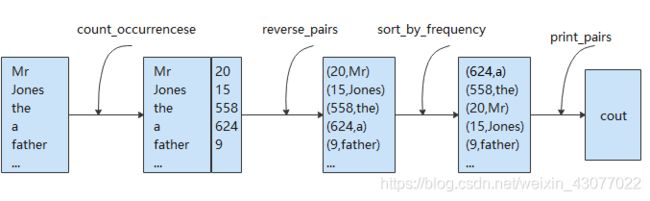
为完成所需要的功能,主要由以下过程组成:
- 将所有的单词插入unordered_map
vector< string> -> unordered_map - 将unordered_map
unordered_map - 对所有pair
vector - 遍历vector,输出单词和统计次数
vector
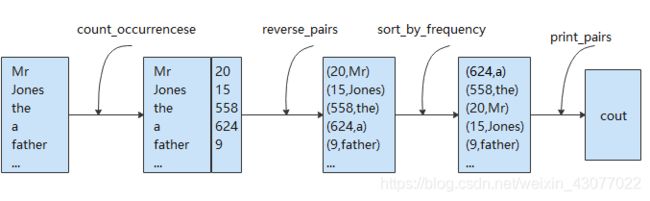
可以看出我们可以拆为更小的函数(做更简单的事),然后将他们组合起来:
unordered_map<string, int> count_occurrencese(vector<string> items);
vector<pair<int, string>> reverse_pairs(unordered_map<string, int> pairs);
vector<pair<int, string>> sort_by_frequency(vector<pair<int, string>>);
void print_pairs(vector<pair<int, string>> pairs);
是不是发现了什么端倪?是的,我们可以通过组合的方式完成上面命令式代码同样的功能。
void print_words(vector<string>& words)
{
return print_pairs(
sort_by_frequency(
reverse_pairs(
count_occurrencese(words)
)
);
}
或许你会觉得这也没啥嘛,之前的代码不也是按照如此的算法过程实现的。那么我们考虑如下场景:当我的输入不在是vector,而是一个文件,统计其中单词频率并输出,我们只需要在声明一个函数words: file -> vector完成文件到单词的映射,之后与上面类似进行组合即可,而不用再对print_words进行修改。当输入变成已统计好的unordered_map时候,也同理。
我们把之前过程是编程范式叫做——指令式编程,而把函数式编程范式叫做——声明式编程。可不要小瞧这一个思维的转变,它带来的变化可谓是相当大的。还是上面的例子,假如我们对其使用一些C++中的语法糖,你会发现是如此甜蜜:
template <typename C, typename T = typename C::value_type>
std::unordered_map<T, unsigned int> count_occurrences(const C& collection)
template <typename C, typename P1, typename P2>
std::vector<std::pair<P2, P1>> reverse_pairs(const C& collection);
在上面的声明中,函数count_occurrences变得将能够接受任何集合,只要其能够推断其包含项的类型(C::value_type)。从此它不再局限于我们上面需求中,你可以用来来统计字符串中字符、整数列表中的整数值、字符串集合中的字符串等等。其他声明的函数也可以做类似的扩展。
函数式编程的特点
函数式编程期望函数的行为项数学上的函数,而非一个计算机上的“子程序”。这样的函数一般被称为纯函数(pure function),主要体现在确定性。所谓确定性,就是像数学中那样,f(x) = y 这个函数无论什么场景都会得到同样的结果。而不是像程序中的很多函数那样。同一个参数,在不同的场景下会计算出相同的结果,这个我们称之为函数的确定性。所谓不同的场景,就是我们的函数会根据运行中的状态信息的不同而发生变化。
我们的代码也体现了函数式编程的一些特点:
- 会影响函数结果的只是函数的参数,没有对环境的依赖。
- 返回的结果就是函数执行的唯一结果,不产生对环境的其他影响。
- 函数的执行没有顺序上的问题
- 函数可以像普通的对象一样被传递、使用或返回。
- 代码更像是说明式而非命令式。熟悉函数式编程后,你会发现说明式代码的可读性比命令式更高,代码更短,可复用性更高。
- 无状态,没有状态就没有伤害,就像没有依赖就没有伤害一样。
函数式编程用到的技术
first class function(头等函数)
正如前文所述,在函数式编程中函数就如同对象一样,可以被传递、使用、或返回。而这些函数被称为头等函数, 也有人将函数式编程中的函数称为一等公民。
在C++中可以做到这一点的有函数对象,lambda表达式(推荐阅读[lambda表达式篇](https://blog.csdn.net/weixin_43077022/article/details/117926275?spm=1001.2014.3001.5501),此外还有std::function,std::bind等。
class filter{ // 函数对象
public:
students()
{
names.insert("abc");
names.insert("John");
}
bool operator()(std::string name) {
return names.find(name) == names.end();
}
private:
set<std::string> names;
};
// lambda 表达式,用auto捕获匿名函数对象
auto add2 = [](int x) { return x + 2; }
map & reduce & filter
在函数式编程很多函数已称为了基本的惯用法(在不同语言有不同名字),而**map(映射)、reduce(归并)和filter(过滤)**为其中最为常见也是最为基础的三个。
map
Map在C++中的直接映射是transform(头文件< algorithm>)。他所做的事情也是数学上的映射,把一个范围里的对象转换为相同数量的另外一些对象。假如有类person,我需要获得人到姓名的映射,即vector
struct person;
vector<string> GetNames(vector<person> people)
{
vector<string> names;
transform(people.begin(), people.end(), back_inserter(names), [](const person& tmp) {
return tmp.name;
});
return names;
}
std::back_inserter是定义在头文件
reduce
Reduce在C++中的直接映射是accumulate(头文件< numeric>)。它的功能是在指定的范围内,使用给定的出事和函数对象,从左到右对数值进行归并[4]。看两个计算平均值的写法:
double average_score_1(const vector<int>& scores)
{
int sum = 0;
for (int socre : scores) {
sum += socre;
}
return sum / (double)scores.size();
}
double average_score_2(const vector<int>& scores)
{
return accumulate(scores.begin(), scores.end(), 0) / (double)scores.size();
}
此外,还可以提供第四个参数用于其他计算,例如如下代码实现累乘:
int product = std::accumulate(v.begin(), v.end(), 1, std::multiplies<int>());
上述的代码可以显而易见的得出,比起过程式的语言来说,函数式编程在代码上要更容易阅读。(传统过程式的语言需要使用for/while循环,然后在各种变量中把数据倒过来倒过去的)。此外,再考虑我们之前说到的函数是无状态的,这意味着并行无问题,尤其在本例中明显。在面临大量的数据时,函数式编程能够提供并行性。而在C++17引入了std::reduce[5],以及执行策略[6]让其并行计算成为可能。
int main()
{
std::vector<double> v(10'000'007, 0.5);
{
auto t1 = std::chrono::high_resolution_clock::now();
double result = std::accumulate(v.begin(), v.end(), 0.0);
auto t2 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> ms = t2 - t1;
std::cout << std::fixed << "std::accumulate result " << result
<< " took " << ms.count() << " ms\n";
}
{
auto t1 = std::chrono::high_resolution_clock::now();
double result = std::reduce(std::execution::par, v.begin(), v.end());
auto t2 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> ms = t2 - t1;
std::cout << "std::reduce result "
<< result << " took " << ms.count() << " ms\n";
}
}
可能的输出:
std::accumulate result 5000003.50000 took 12.7365 ms
std::reduce result 5000003.50000 took 5.06423 ms
filter
Filter的功能是进行过滤,筛选出符合条件的成员。在C++中的映射有copy_if和partition。
auto is_female = [](const person& tmp) { return tmp.female; };
auto iter = std::partition(people.begin(), people.end(), is_female);
vector<person> females;
std::copy_if(people.cbegin(), people.cend(), std::back_inserter(females), is_female);
pipeline(管道)
该技术的意思是,将函数实例成一个一个的action,然后将一组 action 放到一个数组或是列表中,再把数据传给这个 action list,数据就像一个 pipeline 一样顺序地被各个函数所操作,最终得到我们想要的结果。正如在前文组装函数那样。
void print_words(vector<string>& words)
{
return print_pairs(
sort_by_frequency(
reverse_pairs(
count_occurrencese(words)
)
);
}
pipeline 管道借鉴于Unix Shell的管道操作——把若干个命令串起来,前面命令的输出成为后面命令的输入,如此完成一个流式计算。(注:管道绝对是一个伟大的发明,他的设哲学就是KISS – 让每个功能就做一件事,并把这件事做到极致,软件或程序的拼装会变得更为简单和直观。)
比如shell命令:
ps auwwx | awk '{print $2}' | sort -n | xargs echo
查看一个用户执行的进程列表,列出来以后,然后取第二列,第二列是它的进程 ID,排个序,再把它显示出来。
在C++20引入范围库(ranges)之后,可以使用operator |链接两个范围适配器闭包对象的结果。而在此之前我们可以尝试重载管道符,达到类似的效果。以下例子仅为了说明该项技术。
template<typename T, typename F>
auto operator | (T t, F f) -> T
{
return f(t);
}
auto f = [](const int& a) {return a + 1;};
auto g = [](const int& a) {return a * 2;};
auto h = [](const int& a) {return a - 1;};
auto y = 3 | h | g | f;
currying (柯里化)
将一个函数的多个参数分解成多个函数,然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数。简单点说就是函数到函数。
auto addThree = [](int x, int y, int z){
return x + y + z; };
auto addTwoToOne = [addThree](int x, int y) {
return [=](int z) {
return addThree(x, y, z);
};
};
auto addOneToTwo = [addThree](int x) {
return [=](int y, int z) {
return addThree(x, y, z);
};
};
auto addOneByOne = [addTwoToOne](int x) {
return [=](int y) {
return addTwoToOne(x, y);
};
};
cout << "addThree = " << addThree(1, 2, 3) <<endl;
cout << "addTwoToone = " << addTwoToOne(1, 2)(3) <<endl;
cout << "addOneToTwo = " << addOneByOne(1)(2)(4) <<endl;
在上面的代码中addThree函数实现了对三个int值进行相加的操作。然后对该函数进行了拆分,将其拆为addTwoToOne,进而拆为addOneToOne,在调用的时候就变成了
addOneByOne(1)(2)(4),而这个过程就被称作currying(柯里化)。
我们上面做的那个函数拆解也正是此意。
recursing & tail recursion optimization (递归&尾递归优化)
递归最大的好处就是简化代码,可以把一个复杂问题用很简单的代码描述出来。(注意:递归的精髓是描述问题,这也是函数是编程的精髓)。
我们也知道递归的危害,那就是如果递归很深的话,stack受不了,并会导致性能大幅度下降。因此,我们使用尾递归优化技术——每次递归时都会重用stack,这样能够提升性能。或许Stack Overflow上的这篇问答能够帮你解释What is tail call optimization?
C++ 标准库并不保证尾递归优化能够执行,但是主流的C++编译器(如GCC\Clang\MVSC)都是支持尾递归优化的。
[1]《Functional Programming in C++》
https://www.manning.com/books/functional-programming-in-c-plus-plus
[2]https://zh.cppreference.com/w/cpp/algorithm/transform
[3]https://zh.cppreference.com/w/cpp/iterator/back_inserter
[4]https://zh.cppreference.com/w/cpp/algorithm/accumulate
[5]https://zh.cppreference.com/w/cpp/algorithm/reduce
[6]https://zh.cppreference.com/w/cpp/algorithm/execution_policy_tag_t
[7]https://zh.cppreference.com/w/cpp/algorithm/partition
[8]https://zh.cppreference.com/w/cpp/ranges
[9]How can currying be done in C++?
https://stackoverflow.com/questions/152005/how-can-currying-be-done-in-c
[10]https://coolshell.cn/articles/10822.html