卷积神经网络的详解
前言:
卷积神经网络(Convolution Neural Network,CNN)是通过模拟人脑视觉系统,采取卷积层和池化层依次交替的模型结构,卷积层使原始信号得到增强,提高信噪比,池化层利用图像局部相关性原理,对图像进行邻域间采样,在减少数据量的同时提取有用信息,同时参数减少和权值共享使得系统训练时间长的问题得到改善。
目前主流的典型卷积神经网络(CNN),比如VGG, GoogleNet,ResNet都是由简单的CNN调整,组合而来。
一.卷积神经网络结构定义及原理
CNN是一种多层网络,它的每一层由多个二维平面构成,卷积神经网络结构如下图所示。
每一个二维平面由多个神经元构成。CNN的网络结构也可分为3部分:输入层,隐藏层与输出层。CNN的输入层是直接输入二维图像信息,这一点与传统的神经网络输入层需要输入一维向量有所不同。通常将输入层到隐藏层的映射称为一个特征映射,也就是通过卷积层得到特征提取层,经过pooling之后得到特征映射层。
隐藏层由三种网络构成——卷积层,池化层,全连接层。
卷积层:该层的每个神经元与上层对应的局部感受域相连,通过滤波器和非线性变换来提取局部感受域的特征。当每个局部特征被提取之后,不同的局部特征间的空间关系也就确定下来了。
池化层:可以对卷积层提取的特征进行降维,同时可以增加模型的抗畸变能力。
全连接层:连接层的神经元和传统的神经网络一样是全连接的,模型中一般至少有一层全连接层。
输出层:输出层位于全连接层之后,对从全连接层得到的特征进行分类输出。
在keras中搭建全连接层时,将二维数据转换为一维数据,可通道如keras,layers模块中Flatten完成。语句如下
from keras.layers import Flatten
#搭建神经网络时,加入Flatten()层
model.add(Flatten())
#Flatten函数将返回一组拷贝数据,对于输入的二维数据,默认按行展开,输出一维数据。该函数可将卷积过程中输出的二维数据转换成一维数据输入全连接层
二. 卷积层
在这个卷积层,有两个关键操作:
- 局部关联。每个神经元看做一个滤波器(filter)
- 窗口(receptive field)滑动, filter对局部数据计算
先介绍卷积层遇到的几个名词:
- 深度/depth(解释见下图)
- 步长/stride (窗口一次滑动的长度)
- 填充值/zero-padding,指的是边界填充0
卷积过程如下:(滑动窗口就是卷积池)

例如下图:输入一个5*5的数据图(蓝色方格),经过(1,1)的填充0后得到7*7的数据图,然后经过3*3的卷积池,步长为1对该数据图进行卷积操作后得到一个5*5的特征图的过程

例如:卷积权值的计算(注意,下面蓝色矩阵周围有一圈灰色的框,那些就是上面所说到的填充值0)

这里的蓝色矩阵就是输入的图像,粉色矩阵就是卷积层的神经元(指的是过滤器即卷积池),这里表示了有两个神经元(w0,w1)。outputvolume绿色矩阵就是经过卷积运算后的输出矩阵,这里的步长设置为2。粉色的矩阵(filter卷积池)滑动对蓝色的矩阵(输入图像)进行矩阵内积计算并将三个内积运算的结果与偏置值b相加(比如上面图的计算:(0+0+0)+(0+-2-2)+(0+0+0) + 1= 0- 4-+0+ 1 = -3),计算后的值就是绿框矩阵的一个元素。
卷积池向左滑动两步(步长为2)得如下:
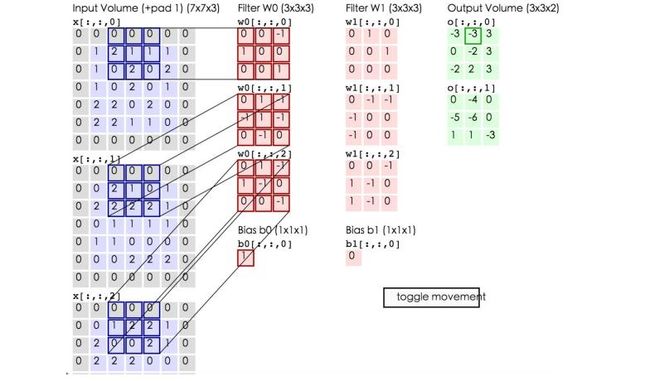
同理卷积可得:
蓝色的矩阵(输入图像)对粉色的矩阵(filter)进行矩阵内积计算并将三个内积运算的结果与偏置值b相加(比如上面图的计算:2+(-2+1-2)+(1-2-2) + 1= 2 - 3 - 3 + 1 = -3),计算后的值就是绿框矩阵的一个元素。
下面是整个输入图像(5*5*3)先经过填充0,再经过两个卷积池(3*3)卷积后的整个过程,得出两个特征图outvolume
权值共享(参数共享)机制
- 在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。神经元就是图像处理中的滤波器,比如边缘检测专用的Sobel滤波器,即卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。
- 需要估算的权重个数减少: AlexNet 1亿 => 3.5w
- 一组固定的权重和不同窗口内数据做内积: 卷积
如下图是一组固定的输入图像经过不同的卷积池卷积得到不同的特征

激活
卷积计算之后,通常会加入偏置(bias), 并引入非线性激活函数(activation function),这里定义bias为b,activation function 是 函数f(),经过激活函数,得出结果

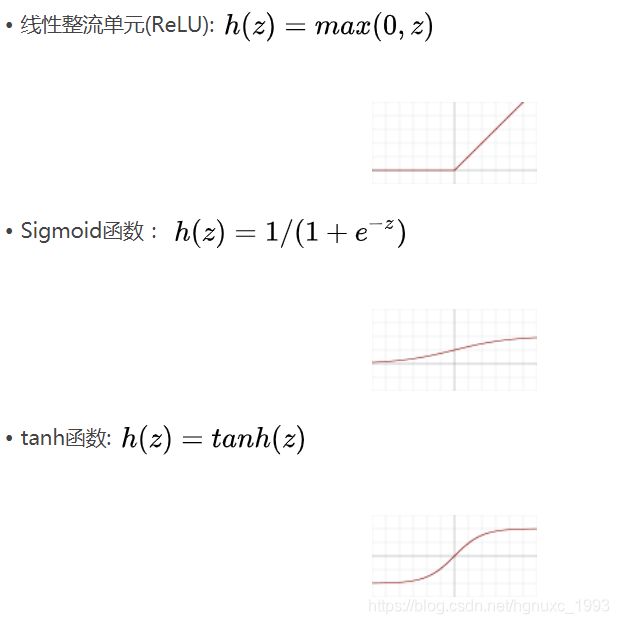
这里请注意,bias不与元素位置相关,只与层有关。主流的activation function 有如下:
卷积层的激活函数一般为函数relu,因为它的特点是收敛快,求梯度简单,但较脆弱,图像如下。
根据实际参数大小等性质调整。
基于keras框架卷积层的参数代码
from keras.layers import Conv2D,MaxPooling2D,Dense
#卷积层的参数
keras.layers.convolutional.Conv2D(
filters=64, #卷积核数目(即输出的维度)
kernel_size=(2,2),#卷积核的宽度和长度
strides=1,#步长
padding="valid",#补0策略,为same或valid
activation="relu",#激活函数
data_format=None, #channels_first或channels_last。channels_first对应的输入shape是(batch,heght,width,channels)
#channels_last对应的输入shape是batch,channels,heght,width),默认是channels_last
dilation_rate=(1,1) #指定dilated convolution中的膨胀比例。任何不为1的dilation_rate与任何不为1的strides均不兼容
use_bias=True, #是否使用偏置项
kernel_initializer="glorot_uniform", #权重初始化方法
bias_initializer="zeros",#偏置初始化
kernel_regularizer=None, #对权重施加正则项
bias_regularizer=None, #对偏置施加正则项
activity_regularizer=None,#对输出施加正则项
kernel_constraint=None,#对权重施加约束项
bias_constraint=None #对偏置施加约束项
)三.池化层
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。池化(pooling),是一种降采样操作(subsampling),池化层的主要目标是降低feature maps的特征空间,或者可以认为是降低feature maps的分辨率。因为feature map参数太多,而图像细节不利于高层特征的抽取。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
池化层的具体作用:
- 特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
- 特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
-
在一定程度上防止过拟合,更方便优化。
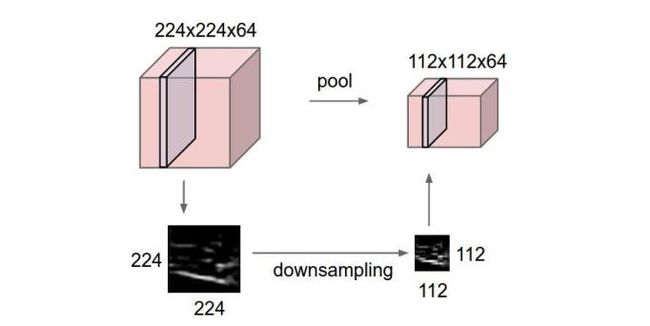
目前主要的pooling操作有:
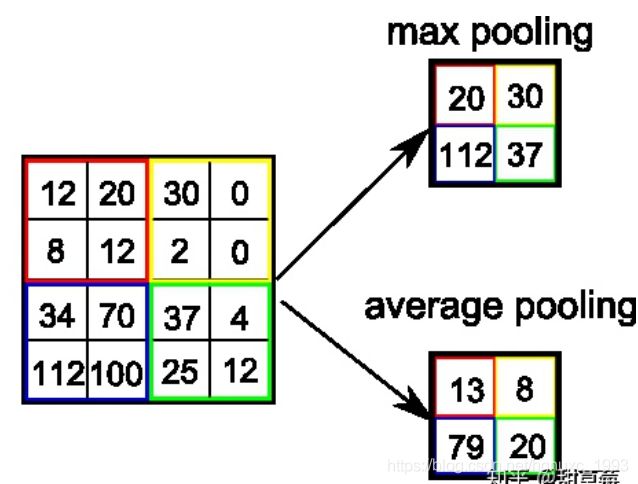
- 最大值池化 Max pooling:如上图所示,2 * 2的max pooling就是取4个像素点中最大值保留,实际用的较多的就是Max pooling
- 平均值池化 Average pooling: 如上图所示, 2 * 2的average pooling就是取4个像素点中平均值值保留
- L2池化 L2 pooling: 即取均方值保留
基于keras框架最大池化层的参数代码
#最大池化层的参数
keras.layers.pooling.MaxPooling2D(
pool_size=(2,2), #池化窗口大小
strids=1, #步长
padding="valid" #填充0的方式
data_format=channels_last #默认为channels_last
)四.全连接层
全连接层同传统神经网络一样,神经元之间采用全连接的方式。在卷积神经网络模型中一般至少有一层全连接层,全连接层连接这卷积神经网络中的卷积网络与输出层,将卷积网络部分输出的二维特征信息转换成一维特征信息,(这里需要引入Flatten()层转化成一维向量)通过不断训练,隐式地得到输入样本的特征表示,再将这些特征表示送入输出层进行分类输出。
全连接层的神经元个数通常为4096,2048,1024,对于采用全连接的神经网络,很容易造成过拟合,所以对于全连接层需要加入Dropout层来防止过拟合现象。
以下网络模型就是传统神经网络,用的就是全连接层;
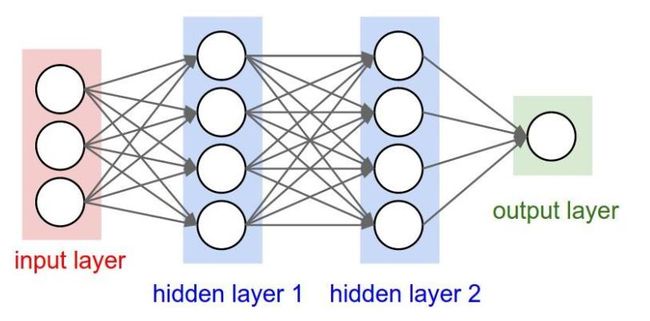
基于keras框架全连接层的参数代码
#全连接层
keras.layers.Dense(
units=1024, #该层神经元的个数,也是该层输出神经元个数
activation="relu",#激活函数
bias_initializer="zeros",#偏置初始化
kernel_regularizer=None, #对权重施加正则项
bias_regularizer=None, #对偏置施加正则项
activity_regularizer=None,#对输出施加正则项
kernel_constraint=None,#对权重施加约束项
bias_constraint=None #对偏置施加约束项
)五.卷积神经网络的优缺点
优点
•共享卷积核,对高维数据处理无压力
•无需手动选取特征,训练好权重,即得特征分类效果好
缺点
•需要调参,需要大样本量,训练最好要GPU
•物理含义不明确(也就说,我们并不知道每个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
六.典型的卷积神经网络
| 名称 | 特点 |
|---|---|
| LeNet5 | 没啥特点-不过是第一个CNN应该要知道,具有一个输入层,两个卷积层,两个池化层,三个全连接层(其中包含输出层) |
| AlexNet | 引入了ReLU和dropout,引入数据增强、池化相互之间有覆盖,三个卷积一个最大池化+三个全连接层 |
| VGGNet | 采用11和33的卷积核以及2*2的最大池化使得层数变得更深。常用VGGNet-16和VGGNet19 |
| Google Inception Net | 这个在控制了计算量和参数量的同时,获得了比较好的分类性能,和上面相比有几个大的改进:1、去除了最后的全连接层,而是用一个全局的平均池化来取代它; 2、引入Inception Module,这是一个4个分支结合的结构。所有的分支都用到了11的卷积,这是因为11性价比很高,可以用很少的参数达到非线性和特征变换。3、Inception V2第二版将所有的55变成2个33,而且提出来著名的Batch Normalization;4、Inception V3第三版就更变态了,把较大的二维卷积拆成了两个较小的一维卷积,加速运算、减少过拟合,同时还更改了Inception Module的结构。 |
| 微软ResNet残差神经网络(Residual Neural Network) | 1、引入高速公路结构,可以让神经网络变得非常深2、ResNet第二个版本将ReLU激活函数变成y=x的线性 |
卷积神经网络的常用框架
Caffe
•源于Berkeley的主流CV工具包,支持C++,python,matlab
•Model Zoo中有大量预训练好的模型供使用
Torch
•Facebook用的卷积神经网络工具包
•通过时域卷积的本地接口,使用非常直观
•定义新网络层简单
TensorFlow
•Google的深度学习框架
•TensorBoard可视化很方便
•数据和模型并行化好,速度快
keras
TensorFlow的升级版,
操作简单,易于新手操作
七.简单卷积神经网络的代码实现
此卷积神经网络是基于keras框架实现mnist的分类
代码:
from keras.datasets import mnist
from keras.utils import np_utils
from keras.layers.core import Dense,Activation ,Dropout
from keras.models import Sequential
from keras.layers import Convolution2D
from keras.layers import MaxPool2D,Flatten
from keras.utils.vis_utils import plot_model
from matplotlib import pyplot as plt
#图像数据预处理
(X_train,Y_train),(X_test,Y_test)=mnist.load_data()
X_test1=X_test #备份未经处理的测试数据,为最后预测阶段做准备
Y_test1=Y_test #备份未经处理的测试标签,为最后预测阶段做准备
X_train=X_train.reshape(-1,28,28,1).astype("float32")/255.0 #四维张量
X_test=X_test.reshape(-1,28,28,1).astype("float32")/255.0
#标签预处理
nb_classes=10
Y_train=np_utils.to_categorical(Y_train,nb_classes)
Y_test=np_utils.to_categorical(Y_test,nb_classes)
#简单cnn的搭建(一个输入层,两个隐藏层,一个全连接层,一个输出层)
#是基于序惯式Sequential()搭建网络模型的
model=Sequential()
#第一层卷积层
model.add(Convolution2D(
filters=32, #卷积核个数
kernel_size=5, #卷积核大小5*5
strides=1,
padding="same",#像素填充方式选择same
activation="relu",
input_shape=(28, 28, 1)#输入数据28*28*1
))
#model.add(Activation("relu"))
#第一层池化层
model.add(MaxPool2D(
pool_size=(2,2),#池化窗口大小2*2
strides=(2,2),#池化步长为2
padding="same" #像素填充方式为same
))
#第二层隐藏层
model.add(Convolution2D(
filters=64, #卷积核的个数
kernel_size=(5,5),#卷积核的大小
padding="same",#填充方式
activation="relu"
))
#model.add(Activation("relu"))
#第二层池化层
model.add(MaxPool2D(pool_size=2,#池化窗口大小
strides=(2,2),#池化步长
padding="same"
))
#将卷积层输出为二维数组,全连接层输入为一维数组,Flatten默认按行降维,返回一个一维数组
model.add(Flatten())
#全连接层
model.add(Dense(1024)) #全连接层,该层有1024个神经元,一般都是1024,2048,4096个神经元
model.add(Activation("relu")) #激活函数
model.add(Dropout(0.2)) #设置为0.2,该层会随机忽略百分之20的神经元
#输出层
model.add(Dense(nb_classes)) #输出层,神经元个数为10,对mnist数据集时分类
model.add(Activation("softmax")) #激活函数
#显示模型摘要
model.summary()
#plot_model(model=model, to_file="model_cnn.png", show_shapes=True)
#编译
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"]
)
#训练
nb_epoch=10
batchsize=1024
training =model.fit(
x=X_train,
y=Y_train,
epochs=nb_epoch,
batch_size=batchsize,
verbose=2,
validation_split=0.2
)
#画出训练过程随着时期(epoc)准确率的变化图
def show_accuracy1(train_history,train,validation):
plt.plot(training.history[train],linestyle="-",color="b") #训练数据结果,“-”代表实线,“b“代表蓝色
plt.plot(training.history[validation],linestyle="--",color="r")#训练数据结果,“--”代表虚线,“r“代表红色
plt.title("Training_accurancy")
plt.xlabel("epoch") #显示x轴标签epoc
plt.ylabel("train") #显示y轴标签train
plt.legend(["train","validation"],loc="lower right")
plt.show()
show_accuracy1(training,"accuracy","val_accuracy")
#画出训练过程中随着时期(epoch)误差的变化图
def show_accuracy2(train_history,train,validation):
plt.plot(training.history[train],linestyle="-",color="b") #训练数据结果,“-”代表实线,“b“代表蓝色
plt.plot(training.history[validation],linestyle="--",color="r")#训练数据结果,“--”代表虚线,“r“代表红色
plt.title("Training_loss")
plt.xlabel("epoch") #显示x轴标签epoc
plt.ylabel("train") #显示y轴标签train
plt.legend(["train","validation"],loc="upper right")
plt.show()
show_accuracy2(training,"loss","val_loss")
#模型评估
test=model.evaluate(X_test,Y_test,verbose=1)
print("误差:",test[0])
print("准确率:",test[1])
#预测
prediction=model.predict_classes(X_test) #将预测结果存到prediction
def plot_image(image): #输入为原始图像
fig=plt.gcf() #获取当前的图像
fig.set_size_inches(2,2)#设置图像大小
plt.imshow(image,cmap="binary") #使用plt.inshow显示图像
plt.show() #开始绘图
#查看图像,真是标签及与测值
def pre_result(i):
plot_image(X_test1[i])
print("真实值:",Y_test1[i])
print("预测值:",prediction[i])
pre_result(4) #即第五项测试项预测八.总结
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。