论文阅读《Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection》
论文地址:https://arxiv.org/abs/2103.01903
目录
-
- 1、存在的问题
- 2、Introduction
- 3、算法简介
- 4、算法细节
-
- 4.1、语义空间投影
- 4.2、关系推理模块relation reasoning
- 4.3、解耦微调
- 5、实验
-
-
- VOC
- COCO
- 跨域 COCO to VOC
- 隐式样本丢失
- 消融实验
-
- 必备知识
1、存在的问题
深度学习算法通常需要大量带注释的数据才能获得优异的性能。为了获得足够的注释数据,一种常见的方法是从现实世界中收集大量样本,并花费大量时间进行标注以生成ground-truth标签。然而,这并不能从根本上解决样本量很少的问题。由于现实世界中的数据存在分布不平衡的问题,即长尾分布,总是存在一些只有少数样本可用的罕见案例。但是,不管数据的可用性如何,新类和基类之间的语义关系都是恒定的。 本文提出一种SRR-FSD算法,尝试在使用视觉信息的同时使用语义关系,并且将显式的关系推理引入到小样本目标检测中。
2、Introduction
explicit 显式样本: 新类中有标签的对象
explicit shot:新类中有标签的对象数量,即shot数
implicit 隐式样本: 预训练的分类数据集中包含的新类中的对象,也就是类别和新类类别重叠的对象
implicit shot:隐式样本的数量
如下图所示,横坐标为显式样本的数量,纵坐标为不同算法在同一数据集上的性能。
可以看出,对于显式样本而言,在同一数据集上的性能对显式样本数量非常敏感,一些小样本目标检测方法的1- shot性能不到5-shot 或10-shot性能的一半。
对于隐式样本而言,预训练模型可以提前从数据集中获取大量新类中的目标样本(即隐式样本),并在进一步训练之前将其知识编码到参数中。所以如果在训练backbone时,没有将ImageNet中的隐式样本剔除掉,那么backbone中就会包含新类的相关信息,会对模型的性能产生正面影响;如果从预训练数据集中删除这些隐式样本,则会对性能产生负面影响。

图中实线表示backbone是在ImageNet上预训练的。
虚线表示训练backbone时,将ImageNet中novel类中出现过的类剔除掉(是否使用了ImageNet预训练的backbone)。
由上图可知本文提出的SRR-FSD算法对explicit shots(x轴)和implicit shots都更为稳定。
作者认为之所以在同一数据集上的性能对样本数量非常敏感,是因为没有考虑基类和新类之间的语义关系。
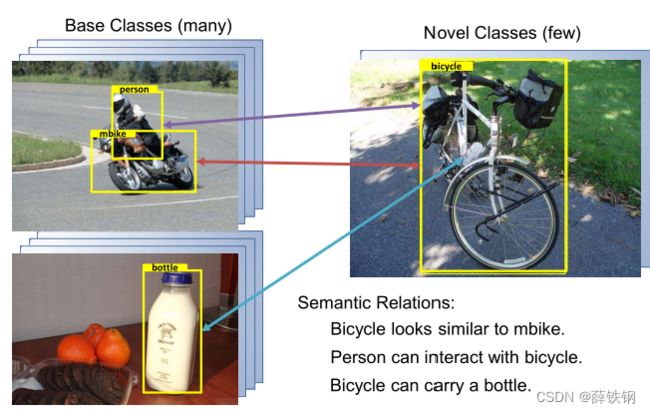
在学习新类时仅仅通过图像来学习,这一过程在不同类之间是独立的,即学习新类数据时仅仅使用了视觉信息,而没有考虑到新类数据和基类数据的语义关系。 随着图像数据的减少,能够获得的视觉信息也就变得极其有限。需要意识到,基类和新类之间的语义信息始终存在,例如,在下图中,如果我们有先验知识,就可以得知新类“自行车”看起来类似于“摩托车”,可以与“人”交互,可以携带“瓶子”,那么学习“自行车”的概念就比仅仅使用几张图像要容易得多。当视觉信息难以获取时,这种语义关系就更加关键。
3、算法简介
本文提出的小样本检测器SRR-FSD以端到端的方式同时从视觉信息和语义关系中学习新目标。
具体来说,使用单词嵌入来构建语义空间。在类的词嵌入的指导下,训练检测器,让检测器将目标从视觉空间投影到语义空间,并将其图像表示与相应的类的词嵌入对齐。
为了解决:
1、视觉和语义的跨域问题: 语义空间投影学习将视觉空间中的概念与语义空间对齐,但是它仍然独立地处理每个类,并且没有在类之间进行知识传播。
2、启发式知识图简单地使用原始嵌入,效果并不好: 在0 shot或者few shot的识别算法中,知识图G被定义为一个基于启发式的。它通常由常识知识的数据库构成,方法是通过规则路径对子图进行采样,使得语义相关的类有着更强的联系。例如,ImageNet数据集中的类具有从WordNet中采样的知识图,然而,小样本目标检测的数据集中的类别并没有很高的语义相关,也没有像ImageNet具有严格的层次结构。我们发现唯一可用的启发式是基于一篇图卷积方法中提到的object co-occurrence方法。尽管共现的统计数据很容易计算出来,但它并不等价于语义关系。
提出了由图像数据驱动的动态关系图,利用学习到的图进行关系推理,扩充原始嵌入以减少域间距(domain gap),同时弥补启发式知识图的不足
4、算法细节
4.1、语义空间投影
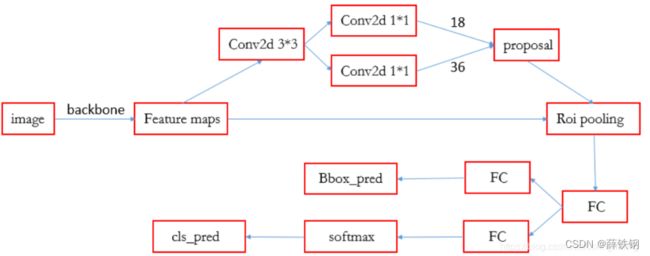
本文提出的SRR-FSD算法是建立在Faster R-CNN上的,可以分为两个阶段。
第一个阶段是基本的训练阶段,检测器在基类数据集上进行训练,如下图中的上半部分所示。
第二阶段是从视觉信息和语义关系中学习新目标的阶段,如下图的下半部分所示。

1、在Faster R-CNN中,它为每个区域候选框提取一个特征向量,并把特征向量分别送入分类分支和回归分支,在分类分支中,通过全连接层把特征向量转化为d维的向量v,v乘以一个可学习的权重矩阵W, W ∈ R N × d W\in\ R^{N × d} W∈ RN×d
2、经过softmax激活函数得到一个概率分布: p = s o f t m a x ( W v + b ) p=softmax(Wv + b) p=softmax(Wv+b) (1)
其中,N是类别数量,b是一个长度为N的可学习的偏置向量,训练过程中使用交叉熵损失。
Faster R-CNN的网络结构可以参考下图:
为了同时从视觉信息和语义关系中学习对象,构建了一个语义空间,并将视觉特征v投射到这个语义空间中:
1、首先使用数据集中所有对应类的词向量构建成一个语义空间semantic space,表示为 W e ∈ R N × d e We\in\ R^{N × de} We∈ RN×de ,对应于N个目标类(包括背景)。
2、将视觉向量v投影到语义空间We中,让视觉向量v和语义向量对齐。
3、训练一个检测器来学习分类分支的线性投影矩阵P, P ∈ R d × d e P\in\ R^{d × de} P∈ Rd×de,则上述**概率分布变为: p = s o f t m a x ( W e P v + b ) p=softmax(WePv + b) p=softmax(WePv+b)**
在这里,We是固定不变的,P是可学习的。
其实这块有些没看懂,我个人理解的是,We和v相当于公式(1)中的特征向量,P相当于公式(1)中可学习的权重矩阵,同时起到了对齐视觉向量v和语义向量We的作用。
4.2、关系推理模块relation reasoning
We从自然语言中对语义概念的知识进行编码。零样本没有图像的支持image support,只能依靠embedding,而小样本便可以同时依赖图像和embedding来学习新类的概念。这些embedding可以在图像支持很少的时候指引检测器向一个合适的方向收敛。
但如果support增多,由于域间距(domain gap)的影响,来自embedding的知识可能造成误导使结果变差。因此,需要对语义信息进行增强来减少域间距,之前有个工作对每个词向量独立的训练一个转换,但本文利用的类间显式关系对于增强语义更有效果,也就是这里提出的动态关系图。
知识图是一个N X N的邻接矩阵,表示每个相邻邻接对之间的关系强度,通过图卷积运算进行分类操作。
语义空间通过关系推理模块relation reasoning扩充,得到扩充后的增强空间augmented space,再进行视觉向量v和语义向量对齐,因此**更新概率预测为: p = s o f t m a x ( G W e P v + b ) p=softmax(GWePv + b) p=softmax(GWePv+b)**
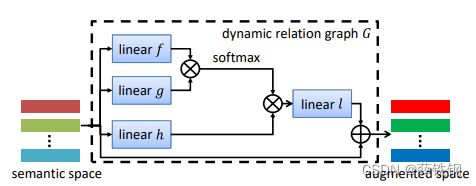
动态关系图使用自注意力机制来实现,如下图所示。语义空间We输入到关系推理模块relation reasoning中,分别经过三个线性层f,g,h进行变换。
首先,f和g的输出进行点积,得到一个自注意力矩阵,该矩阵乘以h的输出,再经过另一个线性层l,最后使用残差结构将原始的We矩阵连接在l的输出上。
如果将线性层f、g、h、l中的变换分别表示为Tf、Tg、Th、Tl,那么可以推导出:

其中,We’是经过关系推理模块后的增广词向量矩阵,将用作计算分类分数的权重
δ是在输入矩阵的最后一个维度上操作的softmax函数。
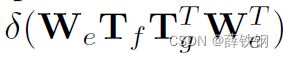 可理解为一个N×N动态知识图,其中可学习参数为Tf和Tg。通过图卷积运算参与分类分数的计算,该运算连接We中的N个单词嵌入,使得知识在它们之间传播。
可理解为一个N×N动态知识图,其中可学习参数为Tf和Tg。通过图卷积运算参与分类分数的计算,该运算连接We中的N个单词嵌入,使得知识在它们之间传播。
Th和Tl可被视为独立应用于每个词向量的可学习转换(?)
用We’表示的概率预测为: p = s o f t m a x ( W e ′ P v + b ) p=softmax(We'Pv + b) p=softmax(We′Pv+b)
另外,学习动态图的另一个优点是它可以很容易地适应新的类别。因为图不是固定的,而是从输入的语义空间中的词向量动态生成的。我们不需要重新定义一个新的图,也不需要从头重新训练检测器。可以简单地插入新类的相应嵌入并微调检测器。
4.3、解耦微调
微调阶段,只解耦SRR-FSD的最后几层。
对于分类子网,对于关系推理模块中的参数和投影矩阵P进行微调。
对于定位子网,它不依赖于词向量,而是与分类子网共享特征。本文发现在新目标上的定位学习可以通过共享特征干扰分类子网,导致许多误报。解耦两个子网之间共享的全连接层可以有效地使每个子网为其任务学习更好的特性。换句话说,分类子网和定位子网有不同的全连接层,独立进行微调。
完整算法步骤:
1、首先使用数据集中所有对应类的词向量构建成一个语义空间semantic space,表示为 W e ∈ R N × d e We\in\ R^{N × de} We∈ RN×de ,对应于N个目标类(包括背景);
2、语义空间通过关系推理模块扩充,得到增广词向量矩阵We’;
3、将视觉向量v投影到语义空间We’中,让视觉向量v和语义向量对齐;
4、训练一个检测器来学习分类分支的线性投影矩阵P, P ∈ R d × d e P\in\ R^{d × de} P∈ Rd×de,则上述 概率分布变为: p = s o f t m a x ( W e ′ P v + b ) p=softmax(We'Pv + b) p=softmax(We′Pv+b)
5、实验
实验参数设置
| 项目 | Value |
|---|---|
| 框架 | MMDection |
| backbone | RestNet-101和特征金字塔FPN |
| 训练方法 | 随机梯度下降法SGD |
| batchsize | 16 |
| 学习率 | 0.02 |
| 动量 | 0.9 |
| 权重衰减 | 0.0001 |
| 第二个微调阶段的学习率 | 0.001 |
| 词向量 | 300维的word2vec 向量 |
输入图像的采样方法是:以50%的概率在基类数据集和心累数据集中随机选择一个数据集合,然后从所选择的数据集中随机选择一幅图像。
VOC
VOC2007和2012的训练/评估集用于训练,2007测试集用于测试。在20个目标类中,有5个类被选为新类,其余15个是基类,有3个不同的基类/新类拆分。新类都有k个带标签的对象,其中k等于1,2,3,5,10。在第一个基础训练阶段,SRR-FSD训练了18个epoch,学习率在第12和第15个阶段乘以0.1。在第二个微调阶段,训练500× |Dn|步,其中 |Dn|是k-shot新数据集中的图像数。

COCO
具有5000个图像的minival集用于测试,train/val集中的其余图像用于训练。在80个类别中,与VOC重叠的20个类别是k=10的新类别,每个类别30张,其余60个类别是基类。

跨域 COCO to VOC
基类数据集设置和上一步中相同,使用COCO数据集的60类,新的数据集由VOC数据集的20个类中的每个类的10个样本组成。
由下图可以看出,在跨域情况下,本算法泛化性能良好。

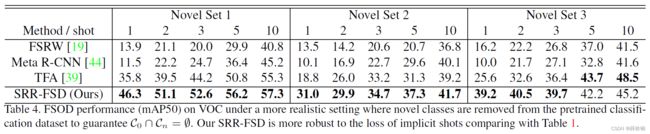
隐式样本丢失
为了研究本算法在更现实的情况下的性能,从预训练的分类数据集中删除新类。
在这种隐式样本丢失的情况下,即当新目标仅在新数据集中可用时,本文提出的算法具有更强的鲁棒性。
消融实验
语义空间投影使得模型更加稳定。
关系推理模块促进自适应知识传播。
解耦减少了误报。
必备知识
长尾分布
语义嵌入
Transformer