K-medoids中心聚类算法
K-medoids中心聚类算法
- K-medoids聚类算法的基本思想
- K-medoids算法步骤
- 实验源码
- 结果展示
Medoid在英文中的意思为“中心点”
所以,K-Medoids算法又叫K-中心点聚类算法
与K-means有所不同的是:K-medoids算法不采用簇中对象的平均值作为参照点,而是选用簇中位置最中心的对象,即中心点作为参照点
那么问题来了,该怎么找聚类对象中的代表对象,也就是中心点呢?
首先为每个簇随意选择一个代表对象,剩余的对象根据其与代表对象的距离分配给最近的一个簇;然后反复地用非代表对象的距离来替代代表对象,以改进聚类质量(PAM——Partitioning Around Medoids)
K-medoids聚类算法的基本思想
1.首先为每个簇随意选择一个代表对象;剩余的对象根据其与代表对象的距离分配给最近的一个簇
2.然后反复地用非代表对象来替代代表对象,以改进聚类的质量
3.聚类结果的质量用一个代价函数来估算,该函数评估了对象与其参照对象之间的平均相异度

K-medoids算法步骤
- 随机选择k个对象作为初始的代表对象
- repeat
- 指派每个剩余的对象给它离它最近的代表对象所代表的簇
- 随意地选择一个非代表对象Orandom(random为下标)
- 计算用Orandom代替Oj的总代价S
- 如果S<0,则用Orandom替换Oj,形成新的k个代表对象的集合
- until不发生变化
实验源码
# 导入第三方模块库
import copy
import random
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 空间三维画图
# 从excel中读取数据
def load_data(path):
# 从excel中读取出数据,并用dataframe存储
df = pd.read_excel(path)
# 记录所读取的数据共有多少列
column_count = df.shape[1]
# 将dataframe中的数据值转换为列表
df_li = df.values.tolist()
# 将存储好数据的列表转换为数组
dataSet = np.array(df_li)
# 返回值
return dataSet,column_count
# 计算欧式距离
def distance(dataSet,medoids,k):
dis_list = []
for data in dataSet:
diff = (np.tile(data,(k,1))) - medoids
squaredDiff = diff ** 2
squaredDist = np.sum(squaredDiff,axis=1)
distance = squaredDist ** 0.5
dis_list.append(distance)
dis_list = np.array(dis_list)
return dis_list
# 根据欧式距离计算cost
def cost(dataSet,medoids):
medoids_index = medoids["cen_index"] #从中心集字典中取出medoids列表
k = len(medoids_index) # 中心对象的个数
cost = 0 # 设定初始的cost为0
medoids_Object = dataSet[medoids_index,:]
dis = distance(dataSet,medoids_Object,k)
cost = dis.min(axis=1).sum()
medoids["t_cost"] = cost
def Assment(dataSet,medoids):
medoids_index = medoids["cen_index"]
# 求出中心点数组
medoids_Object = dataSet[medoids_index]
# 中心点数组长度,即有几个中心点
k = len(medoids_index)
# 分别求样本数据到每一个中心点的欧式距离
dis = distance(dataSet,medoids_Object,k)
# 最小距离对应的索引
index = dis.argmin(axis=1)
# 将最小距离索引存储到列表中
for i in range(k):
medoids[i] = np.where(index == i)
def K_Medoids(dataSet,k):
# 初始化中心点数集,并做聚类
current_medoids = {} # 当前的中心
# 在数据集中随机找出k个中心
current_medoids["cen_index"] = random.sample(set(range(dataSet.shape[0])),k)
# 按照当前的中心对数据集进行聚类
Assment(dataSet,current_medoids)
# 计算当前所需要的cost
cost(dataSet,current_medoids)
# 定义旧的中心点集字典,当当前中心不满足要求时,将当前质心存储到旧中心点集里面
old_medoids = {}
old_medoids["cen_index"] = []
counter = 1 # 计算一共循环几次
# 比较新旧中心点集是否相等
while set(old_medoids["cen_index"]) != set(current_medoids["cen_index"]):
print(counter)
counter = counter + 1
# deepcopy表示复制当前中心点集,并在内存中开辟新的地址进行存储
# 防止current_medoids的修改影响到best_medoids,导致混乱
best_medoids = copy.deepcopy(current_medoids)
old_medoids = copy.deepcopy(current_medoids)
for i in range(dataSet.shape[0]):
for j in range(k):
if i != j:
# 用非中心点来代表中心点,改善聚类质量
tmp_medoids = copy.deepcopy(current_medoids)
tmp_medoids["cen_index"][j] = i
# 再次进行分配和计算需要的cost
Assment(dataSet,tmp_medoids)
cost(dataSet,tmp_medoids)
# 找出cost最小的medoids
if(best_medoids["t_cost"]>tmp_medoids["t_cost"]):
best_medoids = copy.deepcopy(tmp_medoids)
# 将最好的中心点对象对应的字典信息返回
current_medoids = copy.deepcopy(best_medoids)
print('cost is:',current_medoids["t_cost"])
return current_medoids
# 数据可视化
def visualization(dataSet,medoids_list):
if column_count == 2:
for i in range(len(dataSet)):
plt.scatter(dataSet[i][0],dataSet[i][1],marker = 'o',color = 'blue',s = 40,label = '原始点')
for j in range(len(medoids_list)):
plt.scatter(medoids_list[j][0],medoids_list[j][1],marker = 'x',color = 'red',s = 50,label = '中心')
plt.show()
elif column_count == 3:
fig = plt.figure()
ax = Axes3D(fig)
for i in range(len(dataSet)):
ax.scatter(dataSet[i][0],dataSet[i][1],dataSet[i][2],marker = 'o',color = 'blue',s = 40,label = '原始点')
for j in range(len(medoids_list)):
ax.scatter(medoids_list[j][0],medoids_list[j][1],medoids_list[j][2],marker = 'x',color = 'red',s = 50,label = '中心')
ax.set_zlabel('Z', fontdict={'size': 15, 'color': 'red'})
ax.set_ylabel('Y', fontdict={'size': 15, 'color': 'red'})
ax.set_xlabel('X', fontdict={'size': 15, 'color': 'red'})
plt.show()
else:
pass
if __name__ == '__main__':
path = input(r'请输入文件的路径:')
dataSet,column_count = load_data(path)
k = int(input('请输入簇数k的值:'))
# 生成一个字典,存储对应的中心点的索引以及所聚类出的簇
cluster = K_Medoids(dataSet,k)
# 定义两个空字典来存储相应的中心点和集群数
medoids_list = []
cluster_list = []
for i in range(k):
medoids_list.append(dataSet[cluster["cen_index"][i]].tolist())
cluster_list.append(dataSet[cluster[i][0]].tolist())
print('中心点集为:',medoids_list)
print('集群为:',cluster_list)
visualization(dataSet,medoids_list)
结果展示


数据集还是用的上一章所讲的K-means算法的数据集
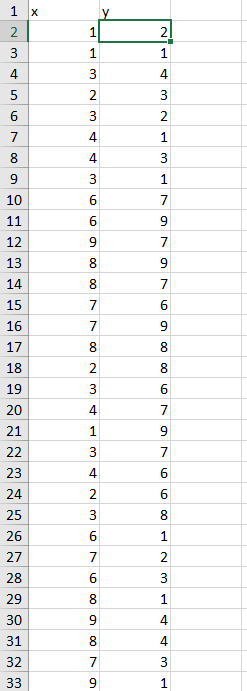
代码部分参考数据挖掘——PAM(K-Medoids)聚类算法学习
代码注释都很详细,欢迎大家相互交流!