【推荐系统】DeepFM模型
因子分解机(Factorization Machines, FM)通过对于每一维特征的隐变量内积来提取特征组合。虽然理论上来讲FM可以对高阶特征组合进行建模,但实际上因为计算复杂度的原因一般都只用到了二阶特征组合,对于更高阶的特征组合,可以用Deep解决。
FM因子分解机
数学原理:
- 当k足够大时,对于任意对称正定的实矩阵
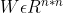 ,均存在实矩阵
,均存在实矩阵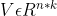 ,使得
,使得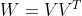
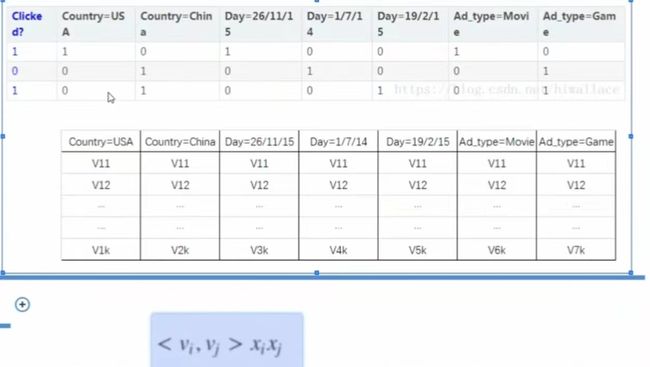
FM模型
- w0为偏置项,蓝色部分为特征一阶计算,橘色部分为特征二阶计算(包含特征的隐向量内积计算)

- 特征二阶计算中,将特征矩阵W分解为两个隐向量矩阵vi,vj

两个隐向量矩阵做矩阵运算得到W特征矩阵
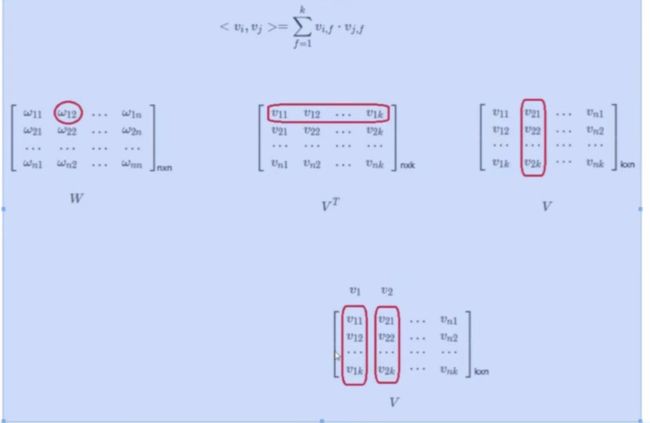
- 当二阶特征交叉时,不仅两个特征Xi,Xj之间相乘,这两个特征的各自的隐向量之间也要做内积运算。
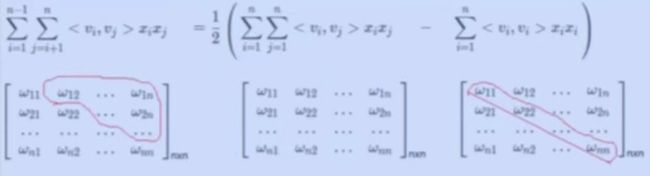
FM模型二阶计算部分推导
- 二阶计算部分 = 特征矩阵除对角线元素之外元素的一半(特征矩阵对称正定矩阵,对角线两侧元素完全相同。)
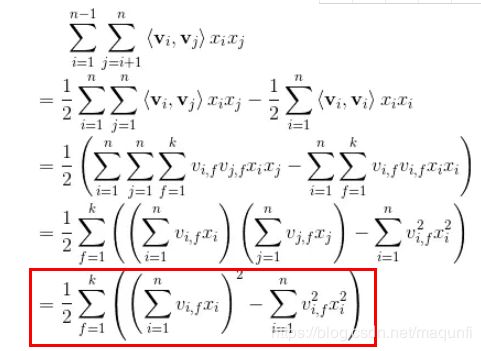
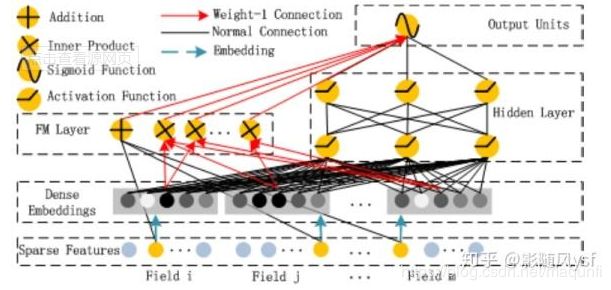
DeepFM
DeepFM包含两部分:神经网络部分与因子分解机部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的输入。
- 不需要预训练 FM 得到隐向量;
- 不需要人工特征工程;
- 能同时学习低阶和高阶的组合特征;
- FM 模块和 Deep 模块共享 Feature Embedding 部分,可以更快的训练,以及更精确的训练学习。

import tensorflow as tf
def get_dataset(file_path):
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=12,
label_name='label',
na_value="0",
num_epochs=1,
ignore_errors=True)
return dataset
train_dataset = get_dataset('trainingSamples.csv')
test_dataset = get_dataset('testSamples.csv')
#输入特征
inputs = {
'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),
'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),
'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),
'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),
'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),
'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),
'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),
'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),
'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),
'userRatedMovie1': tf.keras.layers.Input(name='userRatedMovie1', shape=(), dtype='int32'),
'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),
'userGenre2': tf.keras.layers.Input(name='userGenre2', shape=(), dtype='string'),
'userGenre3': tf.keras.layers.Input(name='userGenre3', shape=(), dtype='string'),
'userGenre4': tf.keras.layers.Input(name='userGenre4', shape=(), dtype='string'),
'userGenre5': tf.keras.layers.Input(name='userGenre5', shape=(), dtype='string'),
'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),
'movieGenre2': tf.keras.layers.Input(name='movieGenre2', shape=(), dtype='string'),
'movieGenre3': tf.keras.layers.Input(name='movieGenre3', shape=(), dtype='string'),
}
#将类别型特征进行One-hot编码,再进行embedding化得到稠密的特征向量
#movie Id
# One-hot
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
#embedding
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
#转化成multi-hot
movie_ind_col = tf.feature_column.indicator_column(movie_col)
# user Id
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
user_ind_col = tf.feature_column.indicator_column(user_col) # user id indicator columns
# 不同风格的特征list
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary',
'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
# 将类别特征进行hash映射。根据单词的序列顺序,把单词根据index转换成one hot encoding。
user_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="userGenre1",
vocabulary_list=genre_vocab)
# indicator_column(),将 categorical_column表示成 multi-hot形式的 dense tensor,同一个元素在一行出现多次, 计数会超过1
user_genre_ind_col = tf.feature_column.indicator_column(user_genre_col)
#embedding_column(),将稀疏矩阵转换为稠密矩阵
user_genre_emb_col = tf.feature_column.embedding_column(user_genre_col, 10)
# item genre embedding feature
item_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="movieGenre1",
vocabulary_list=genre_vocab)
item_genre_ind_col = tf.feature_column.indicator_column(item_genre_col)
item_genre_emb_col = tf.feature_column.embedding_column(item_genre_col, 10)
# FM的一阶特征运算
#将预处理完的类别特征列合并
cat_columns = [movie_ind_col, user_ind_col, user_genre_ind_col, item_genre_ind_col]
#数值型特征不用经过独热编码和特征稠密化,转换成可以输入神经网络的dense类型直接输入网络
#转换类型
deep_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]
#DenseFeatures(),针对类别型特征生成稠密张量
first_order_cat_feature = tf.keras.layers.DenseFeatures(cat_columns)(inputs)
first_order_cat_feature = tf.keras.layers.Dense(1, activation=None)(first_order_cat_feature)
#针对数值型特征生成稠密张量
first_order_deep_feature = tf.keras.layers.DenseFeatures(deep_columns)(inputs)
first_order_deep_feature = tf.keras.layers.Dense(1, activation=None)(first_order_deep_feature)
#添加一个对张量进行求和的层
first_order_feature = tf.keras.layers.Add()([first_order_cat_feature, first_order_deep_feature])
## FM的二阶特征运算
#类别特征
second_order_cat_columns_emb = [tf.keras.layers.DenseFeatures([item_genre_emb_col])(inputs),
tf.keras.layers.DenseFeatures([movie_emb_col])(inputs),
tf.keras.layers.DenseFeatures([user_genre_emb_col])(inputs),
tf.keras.layers.DenseFeatures([user_emb_col])(inputs)
]
second_order_cat_columns = []
for feature_emb in second_order_cat_columns_emb:
feature = tf.keras.layers.Dense(64, activation=None)(feature_emb)
feature = tf.keras.layers.Reshape((-1, 64))(feature)
second_order_cat_columns.append(feature)
#数值特征
second_order_deep_columns = tf.keras.layers.DenseFeatures(deep_columns)(inputs)
second_order_deep_columns = tf.keras.layers.Dense(64, activation=None)(second_order_deep_columns)
second_order_deep_columns = tf.keras.layers.Reshape((-1, 64))(second_order_deep_columns)
second_order_fm_feature = tf.keras.layers.Concatenate(axis=1)(second_order_cat_columns + [second_order_deep_columns])
#二阶特征计算
deep_feature = tf.keras.layers.Flatten()(second_order_fm_feature)
deep_feature = tf.keras.layers.Dense(32, activation='relu')(deep_feature)
deep_feature = tf.keras.layers.Dense(16, activation='relu')(deep_feature)
class ReduceLayer(tf.keras.layers.Layer):
#init(),参数初始化
def __init__(self, axis, op='sum', **kwargs):
super().__init__()
self.axis = axis
self.op = op
assert self.op in ['sum', 'mean']
#获取输入数据的shape
def build(self, input_shape):
pass
#调用call()会被执行
def call(self, input, **kwargs):
if self.op == 'sum':
return tf.reduce_sum(input, axis=self.axis)
elif self.op == 'mean':
return tf.reduce_mean(input, axis=self.axis)
return tf.reduce_sum(input, axis=self.axis)
second_order_sum_feature = ReduceLayer(1)(second_order_fm_feature)
second_order_sum_square_feature = tf.keras.layers.multiply([second_order_sum_feature, second_order_sum_feature])
second_order_square_feature = tf.keras.layers.multiply([second_order_fm_feature, second_order_fm_feature])
second_order_square_sum_feature = ReduceLayer(1)(second_order_square_feature)
## second_order_fm_feature
second_order_fm_feature = tf.keras.layers.subtract([second_order_sum_square_feature, second_order_square_sum_feature])
concatenated_outputs = tf.keras.layers.Concatenate(axis=1)([first_order_feature, second_order_fm_feature, deep_feature])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(concatenated_outputs)
model = tf.keras.Model(inputs, output_layer)
# compile the model, set loss function, optimizer and evaluation metrics
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', tf.keras.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])
# train the model
model.fit(train_dataset, epochs=5)
# evaluate the model
test_loss, test_accuracy, test_roc_auc, test_pr_auc = model.evaluate(test_dataset)
print('\n\nTest Loss {}, Test Accuracy {}, Test ROC AUC {}, Test PR AUC {}'.format(test_loss, test_accuracy,
test_roc_auc, test_pr_auc))
# print some predict results
predictions = model.predict(test_dataset)
for prediction, goodRating in zip(predictions[:12], list(test_dataset)[0][1][:12]):
print("Predicted good rating: {:.2%}".format(prediction[0]),
" | Actual rating label: ",
("Good Rating" if bool(goodRating) else "Bad Rating"))
【王喆-推荐系统】模型篇-(task7)DeepFM处理交叉特征
推荐系统 - DeepFM架构详解