前言
在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性。而有了文本之间相似性的度量方式,我们便可以利用划分法的K-means、基于密度的DBSCAN或者是基于模型的概率方法进行文本之间的聚类分析;另一方面,我们也可以利用文本之间的相似性对大规模语料进行去重预处理,或者找寻某一实体名称的相关名称(模糊匹配)。而衡量两个字符串的相似性有很多种方法,如最直接的利用hashcode,以及经典的主题模型或者利用词向量将文本抽象为向量表示,再通过特征向量之间的欧式距离或者皮尔森距离进行度量。本文围绕文本相似性度量的主题,从最直接的字面距离的度量到语义主题层面的度量进行整理总结,并将平时项目中用到的文本相似性代码进行了整理,如有任何纰漏还请指出,我会第一时间改正^v^。(ps.平时用的Java和scala较多,本文主要以Java为例。)
字面距离
提到如何比较两个字符串,我们从最初编程开始就知道:字符串有字符构成,只要比较比较两个字符串中每一个字符是否相等便知道两个字符串是否相等,或者更简单一点将每一个字符串通过哈希函数映射为一个哈希值,然后进行比较。但是这种方法有一个很明显的缺点,就是过于“硬”,对于相似性的度量其只有两种,0不相似,1相似,哪怕两个字符串只有一个字符不相等也是不相似,这在NLP的很多情况是无法使用的,所以下文我们就“软”的相似性的度量进行整理,而这些方法仅仅考虑了两个文本的字面距离,无法考虑到文本内在的语义内容。
common lang库
文中在部分代码应用中使用了Apache提供的common lang库,该库包含很多Java标准库中没有的但却很实用的函数。其maven引用如下:
<dependency>
<groupId>org.apache.commonsgroupId> <artifactId>commons-lang3artifactId> <version>3.4version> dependency>相同字符数
在传统的字符串比较过程中,我们考虑字符串中每个字符是否相等,并且考虑了字符出现的顺序,如果不考虑字符出现的顺序,我们可以利用两个文本之间相同的字符数量,很简单不再赘述,可以利用common lang中的getFuzzyDistance:
int dis = StringUtils.getFuzzyDistance(term, query, Locale.CHINA);莱文斯坦距离(编辑距离)
定义
我们在学习动态规划的时候,一个很经典的算法便是计算两个字符串的编辑距离,即:
莱文斯坦距离,又称Levenshtein距离,是编辑距离(edit distance)的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如将kitten一字转成sitting:
- sitten (k→s)
- sittin (e→i)
- sitting (→g)
那么二者的编辑距离为3。
俄罗斯科学家弗拉基米尔·莱文斯坦在1965年提出这个概念。
实现方式
我们可以利用common lang中StringUtils的函数来计算:
int dis = StringUtils.getLevenshteinDistance(s1, s2);
//实现 public static int getLevenshteinDistance(CharSequence s, CharSequence t) { if (s == null || t == null) { throw new IllegalArgumentException("Strings must not be null"); } int n = s.length(); // length of s int m = t.length(); // length of t if (n == 0) { return m; } else if (m == 0) { return n; } if (n > m) { // swap the input strings to consume less memory final CharSequence tmp = s; s = t; t = tmp; n = m; m = t.length(); } int p[] = new int[n + 1]; //'previous' cost array, horizontally int d[] = new int[n + 1]; // cost array, horizontally int _d[]; //placeholder to assist in swapping p and d // indexes into strings s and t int i; // iterates through s int j; // iterates through t char t_j; // jth character of t int cost; // cost for (i = 0; i <= n; i++) { p[i] = i; } for (j = 1; j <= m; j++) { t_j = t.charAt(j - 1); d[0] = j; for (i = 1; i <= n; i++) { cost = s.charAt(i - 1) == t_j ? 0 : 1; // minimum of cell to the left+1, to the top+1, diagonally left and up +cost d[i] = Math.min(Math.min(d[i - 1] + 1, p[i] + 1), p[i - 1] + cost); } // copy current distance counts to 'previous row' distance counts _d = p; p = d; d = _d; } // our last action in the above loop was to switch d and p, so p now // actually has the most recent cost counts return p[n]; }Jaro距离
定义
Jaro Distance也是字符串相似性的一种度量方式,也是一种编辑距离,Jaro 距离越高本文相似性越高;而Jaro–Winkler distance是Jaro Distance的一个变种。据说是用来判定健康记录上两个名字是否相同,也有说是是用于人口普查。从最初其应用我们便可看出其用法和用途,其定义如下:

其中
 是匹配数目(保证顺序相同)
是匹配数目(保证顺序相同) 字符串长度
字符串长度 是换位数目
是换位数目
其中t换位数目表示:两个分别来自S1和S2的字符如果相距不超过

我们就认为这两个字符串是匹配的;而这些相互匹配的字符则决定了换位的数目t,简单来说就是不同顺序的匹配字符的数目的一半即为换位的数目t,举例来说,MARTHA与MARHTA的字符都是匹配的,但是这些匹配的字符中,T和H要换位才能把MARTHA变为MARHTA,那么T和H就是不同的顺序的匹配字符,t=2/2=1。
而Jaro-Winkler则给予了起始部分就相同的字符串更高的分数,他定义了一个前缀p,给予两个字符串,如果前缀部分有长度为 的部分相同,则Jaro-Winkler Distance为:

 是两个字符串的Jaro Distance
是两个字符串的Jaro Distance 是前缀的相同的长度,但是规定最大为4
是前缀的相同的长度,但是规定最大为4 则是调整分数的常数,规定不能超过0.25,不然可能出现dw大于1的情况,Winkler将这个常数定义为0.1
则是调整分数的常数,规定不能超过0.25,不然可能出现dw大于1的情况,Winkler将这个常数定义为0.1
举个简单的例子:
计算 的距离
的距离

我们利用 可以得到一个匹配窗口距离为3,图中黄色部分便是匹配窗口,其中1表示一个匹配,我们发现两个X并没有匹配,因为其超出了匹配窗口的距离3。我们可以得到:
可以得到一个匹配窗口距离为3,图中黄色部分便是匹配窗口,其中1表示一个匹配,我们发现两个X并没有匹配,因为其超出了匹配窗口的距离3。我们可以得到:




其Jaro score为:

而计算Jaro–Winkler score,我们使用标准权重 ,其结果如下:
,其结果如下:

实现方式
同样我们可以利用common lang中的getJaroWinklerDistance函数来实现,注意这里实现的是Jaro–Winkler distance
double dis = StringUtils.getJaroWinklerDistance(reviewName.toLowerCase(), newsName.toLowerCase()); //实现 public static double getJaroWinklerDistance(final CharSequence first, final CharSequence second) { final double DEFAULT_SCALING_FACTOR = 0.1; //标准权重 if (first == null || second == null) { throw new IllegalArgumentException("Strings must not be null"); } final double jaro = score(first,second); // 计算Jaro score final int cl = commonPrefixLength(first, second); // 计算公共前缀长度 final double matchScore = Math.round((jaro + (DEFAULT_SCALING_FACTOR * cl * (1.0 - jaro))) *100.0)/100.0; // 计算 Jaro-Winkler score return matchScore; }应用
在Wetest舆情监控中,我们在找寻游戏名简称和全称的对应关系时便使用到了Jaro-Winkler score进行衡量,其中我们将Jaro分数大于0.6的认为是相似文本,之后在总的相似文本中提取最相似的作为匹配项,实现效果还不错: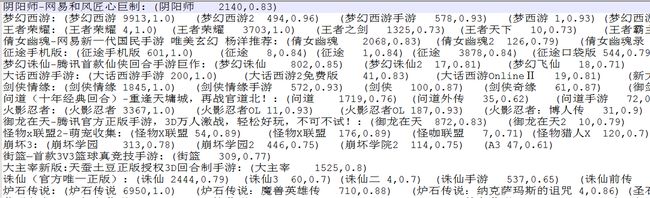
其中冒号左边是待匹配项,右边是匹配项<游戏名 词频,Jaro-Winkler score>,Jaro-Winkler score较高的一般都是正确的匹配项。
SimHash
定义
SimHash是一种局部敏感hash,它也是Google公司进行海量网页去重使用的主要算法。
传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大。所以传统的Hash是无法在签名的维度上来衡量原内容的相似度,而SimHash本身属于一种局部敏感哈希算法,它产生的hash签名在一定程度上可以表征原内容的相似度。
我们主要解决的是文本相似度计算,要比较的是两个文章是否相似,当然我们降维生成了hash签名也是用于这个目的。看到这里估计大家就明白了,我们使用的simhash就算把文章中的字符串变成 01 串也还是可以用于计算相似度的,而传统的hash却不行。
我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过传统hash计算为:
0001000001100110100111011011110
1010010001111111110010110011101
通过上面的例子我们可以很清晰的发现simhash的局部敏感性,相似文本只有部分01变化,而hash值很明显,即使变化很小一部分,也会相差很大。
基本流程
注:具体的事例摘自Lanceyan[10]的博客《海量数据相似度计算之simhash和海明距离》
- 分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程的流程图为:
相似性度量
有了simhash值,我们需要来度量两个文本间的相似性,就像上面的例子一样,我们可以比较两个simhash间0和1不同的数量。这便是汉明距离(Hamming distance)
在信息论中,两个等长字符串之间的汉明距离(英语:Hamming distance)是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。
汉明重量是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是1的个数,所以11101的汉明重量是4。
例如:
1011101与1001001之间的汉明距离是2
一般在利用simhash进行文本相似度比较时,我们认为汉明距离小于3的文本是相似的。
存储索引

存储:
- 将一个64位的simhash签名拆分成4个16位的二进制码。(图上红色的16位)
- 分别拿着4个16位二进制码查找当前对应位置上是否有元素。(放大后的16位)
- 对应位置没有元素,直接追加到链表上;对应位置有则直接追加到链表尾端。(图上的 S1 — SN)
查找:
- 将需要比较的simhash签名拆分成4个16位的二进制码。
- 分别拿着4个16位二进制码每一个去查找simhash集合对应位置上是否有元素。
- 如果有元素,则把链表拿出来顺序查找比较,直到simhash小于一定大小的值,整个过程完成。
- 在去重时,因为汉明距离小于3则为重复文本,那么如果存在simhash相似的文本,对于四段simhash则至少有一段simhash是相同的,所以在去重时对于待判断文本D,如果D中每一段的simhash都没有相同的,那么D为无重复文本。
原理:
借鉴hashmap算法找出可以hash的key值,因为我们使用的simhash是局部敏感哈希,这个算法的特点是只要相似的字符串只有个别的位数是有差别变化。那这样我们可以推断两个相似的文本,至少有16位的simhash是一样的。具体选择16位、8位、4位,大家根据自己的数据测试选择,虽然比较的位数越小越精准,但是空间会变大。分为4个16位段的存储空间是单独simhash存储空间的4倍。
实现
在实际NLP的使用中,我利用Murmur3作为字符串的64位哈希值,用Java和spark分别实现了一个simhash的版本
我将源码放在了github上,如下链接:
github: xlturing/simhashJava
其中利用了结巴作为文本的分词工具,Murmur3用来产生64位的hashcode。另外根据上述存储方式,进行了simhash分段存储,提高搜索速度,从而进行高效查重。
应用
simhash从最一开始用的最多的场景便是大规模文本的去重,对于爬虫从网上爬取的大规模语料数据,我们需要进行预处理,删除重复的文档才能进行后续的文本处理和挖掘,那么利用simhash是一种不错的选择,其计算复杂度和效果都有一个很好的折中。
但是在实际应用过程中,也发现一些badcase,完全无关的文本正好对应成了相同的simhash,精确度并不是很高,而且simhash更适用于较长的文本,但是在大规模语料进行去重时,simhash的计算速度优势还是很不错的。
语义相似性
在NLP中有时候我们度量两个短文本或者说更直接的两个词语的相似性时,直接通过字面距离是无法实现的,如:中国-北京,意大利-罗马,这两个短语之间的相似距离应该是类似的,因为都是首都与国家的关系;再比如(男人、男孩),(女人、女孩)应该是相同的关系,但是我们看其字面距离都是0。
想要做到语义层面的度量,我们需要用到机器学习建模,而自然语言的问题转化为机器学习的首要问题便是找到一种方法把自然语言的符号数学化。
背景知识
在自然语言处理领域中,有两大理论方向,一种是基于统计的经验主义方法,另一种是基于规则的理性主义方法[15]。而随着计算机性能的提升,以及互联网发展而得到的海量语料库,目前NLP的研究更多是基于统计的经验主义方法。所以在本文讨论的语义相似性中,也是从统计学的角度出发进行总结。
统计语言模型
对于统计语言模型而言,最基础的理论便是贝叶斯理论(Bayes' theorem PS.关于贝叶斯理论强烈推荐:数学之美番外篇:平凡而又神奇的贝叶斯方法,一篇深入浅出的好文。另外推荐下自己师兄参与翻译的作品《贝叶斯方法——概率编程与贝叶斯推断》很全面的贝叶斯理论+实践书籍)。对于大规模语料库,我们可以通过词频的方式来获取概率,例如100个句子中,出现了1次"Okay",那么

而同样的对于句子"An apple ate the chicken"我们可以认为其概率为0,因为这不符合我们说话的逻辑。
统计语言模型是用来计算一个句子的概率,其通常基于一个语料库D来构建。如何表示一个句子的概率呢?我们用 来表示一个基元(通常就是指词语,也可以是字或短语),那么对于一个由N个词组成的句子W可以表示为
来表示一个基元(通常就是指词语,也可以是字或短语),那么对于一个由N个词组成的句子W可以表示为

那么其联合概率

就可以认为是该句子的概率,根据贝叶斯公式的链式法则可以得到:

其中条件概率 便是语言模型的参数,如果我们把这些全部算出来,那么一个句子的概率我们就能很轻易的得出。但是很明显,这个参数的量是巨大的是无法计算的。这时我们可以将
便是语言模型的参数,如果我们把这些全部算出来,那么一个句子的概率我们就能很轻易的得出。但是很明显,这个参数的量是巨大的是无法计算的。这时我们可以将 映射到某个等价类
映射到某个等价类 ,从而降低参数数目。
,从而降低参数数目。
ps.语料库我们用C表示,而词典D一般为语料中出现的所有不重复词
n-gram模型
既然每个单词依赖的单词过多,从而造成了参数过多的问题,那么我们就简单点,假设每个单词只与其前n-1个单词有关,这便是n-1阶Markov假设,也就是n-gram模型的基本思想。
那么对于句子W的概率我们可以简化如下:

那么对于最简单的一阶情况也称unigram或uni-gram或monogram(二阶bigram 三阶trigram)就简单表示为

为了在句首和句尾能够统一,我们一般会在句首加一个BOS标记,句尾加一个EOS标记,那么对于句子"Mark wrote a book",其概率可以表示如下:

为了预估 条件概率,根据大数定理,简单统计语料库中
条件概率,根据大数定理,简单统计语料库中 出现的频率,并进行归一化。我们用c来表示频率,那么可表示如下:
出现的频率,并进行归一化。我们用c来表示频率,那么可表示如下:

其中分母在unigram中就可以简单认为是词语 出现的次数。
出现的次数。
在n-gram模型中还有一个很重要的问题就是平滑化,因为再大的语料库都不可能涵盖所有情况,考虑两个问题:
 那么
那么 就是0吗?
就是0吗? 那么就是1吗?
那么就是1吗?
这显然是不合理的,这就需要进行平滑,这里不展开讨论。
根据最大似然,我们可以得到:

其中C表示语料库, 表示词语的上下文,而这里对于n-gram模型
表示词语的上下文,而这里对于n-gram模型 ,取对数后的对数似然函数为:
,取对数后的对数似然函数为:

从上式我们可以看出 可以看做是
可以看做是 关于的函数,即:
关于的函数,即:

其中 为待定参数集,通过语料库训练得到参数集后,F便确定了,我们不需要再存储概率,可以直接计算得到,而语言模型中很关键的就在于F的构造
为待定参数集,通过语料库训练得到参数集后,F便确定了,我们不需要再存储概率,可以直接计算得到,而语言模型中很关键的就在于F的构造
词向量
为了从使得计算机从语义层面理解人类语言,首先要做的就是将语言数学化,如何进行表示呢?人们便提出了词向量的概念,即用一个向量来表示一个词。
One-hot Representation
一种最简单词向量就是利用词频向量将高维的语义空间抽象成数学符号表示,向量长度为词典 的大小
的大小 ,这种表示方式非常直观,但是容易造成维度灾难,并且还是不能刻画语义的信息。
,这种表示方式非常直观,但是容易造成维度灾难,并且还是不能刻画语义的信息。
词语表示
对于词语而言,用一个向量来表示一个词,最直观简单的方式就是将每个词变为一个很长的向量,向量长度便是词典的长度,其中绝大部分为0,只有一个维度为1代表了当前词。
假设语料库:“冲突容易引发战争”,那么词典为
- D=[冲突,容易,引发,战争]
- 冲突=[1,0,0,0]
- 战争=[0,0,0,1]
每个词都是含有一个1的n维向量( ),这种方式我们压缩存储下,就是给每个词语分配一个ID,通常实际变成我们最简单的就是用hash值表示一个词语。这种方式可以用在SVM、最大熵和CRF等等算法中,完成NLP的大多数场景。例如,我们可以直接将
),这种方式我们压缩存储下,就是给每个词语分配一个ID,通常实际变成我们最简单的就是用hash值表示一个词语。这种方式可以用在SVM、最大熵和CRF等等算法中,完成NLP的大多数场景。例如,我们可以直接将
但是缺点很明显,就是我们用这种方式依旧无法度量两个词的语义相似性,任意两个词之间都是孤立的,比如上面的冲突和战争是近义词,但是却没有任何关联性。
文档表示
同样文档也可以用词频向量的形式来表示,一般我们会利用tf-idf作为每一个词的特征值,之后会挑选每篇文档比较重要的部分词来表示一篇文档,拿游戏来说,如下:
[王者荣耀, 阴阳师, 梦幻西游]
- doc1:[tf-idf(王者荣耀), tf-idf(阴阳师), tf-idf(梦幻西游)]
- doc2:[tf-idf(王者荣耀), tf-idf(阴阳师), tf-idf(梦幻西游)]
然后我们就可以利用K-means等聚类算法进行聚类分析,当然对于每篇文档,一般我们只会选取部分词汇,因为如果词汇过多可能造成NLP中常见的维度“灾难”。这种方式在大多数NLP场景中都是适用的,但是由于这种表示往往是建立在高维空间,为了避免维度灾难就要损失一定的语义信息,这也是这种方法的弊端。
Distributed representation
另外一种词向量的表示Distributed representation最早由 Hinton在 1986年提出。它是一种低维实数向量,这种向量一般长成这个样子:
[0.792, −0.177, −0.107, 0.109, −0.542, …]
维度以 50 维和 100 维比较常见,当然了,这种向量的表示不是唯一的。
Distributed representation的关键点在于,将高维空间中的词汇映射到一个低维的向量空间中,并且让相关或者相似的词,在距离上更接近(看到这里大家有没有想到普通hash以及simhash的区别呢?),这里引用一张图片(来自[13]):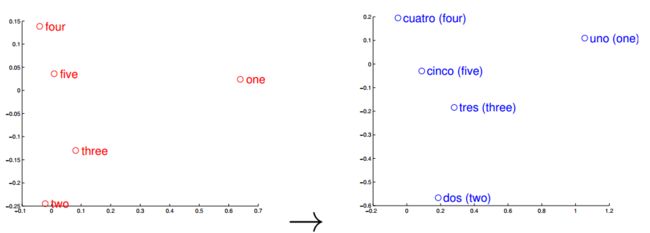
图中是英语和西班牙语通过训练分别得到他们的词向量空间,之后利用PCA主成分分析进行降维表示在二维坐标图中的。我们可以清晰的看出,对于两种语系的一二三四五,在空间距离上竟是如此的相似,这就是Distributed representation词向量表示的意义所在。
这种采用低维空间表示法,不但解决了维数灾难问题,并且挖掘了word之间的关联属性,从而提高了向量语义上的准确度,下面我们讨论的语言模型都是基于这种词向量表示方式。
PS. 有时候也会出现Word Represention或 Word Embedding(所谓词嵌入)的说法。另外我们这里说的词向量是在词粒度进行分析,当然我们也可以在字粒度的字向量、句子粒度的句向量以及文档粒度的文档向量进行表示分析。
主题模型
在长文本的篇章处理中,主题模型是一种经典的模型,经常会用在自然语言处理、推荐算法等应用场景中。本节从LDA的演变过程对LDA进行阐述,然后就LDA在长文本相似性的判断聚类上做简要说明。
LSA
首先对于一篇文档Document,词语空间的一个词频向量 如下:
如下:

其中每个维度表示某一词语term在该文档中出现的次数,最终对于大量的训练样本,我们可以得到训练样本的矩阵X,如下图:
LSA的基本思想,便是利用最基本的SVD奇异值分解,将高维语义空间映射到低维空间,其流程如下: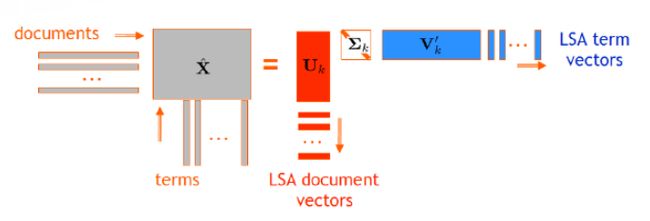
这样对于训练样本中词表的每一个term我们便得到了一个低维空间的向量表示。但LSA的显著问题便是值考虑词频,并不区分同一词语的不同含义
PLSA
LSA基于最基本的SVD分解,但缺乏严谨的数理统计逻辑,于是Hofmann提出了PLSA,其中P便是Probabilistic,其基本的假设是每个文档所表示的词频空间向量w服从多项式分布(Multinomial distribution)
简单扯两句多项式分布:
-
伯努利分布(Bernoulli distribution)我们从接触概率论开始便知道,即所谓的投硬币,其离散分布如下:

但是吊吊的数学家们总喜欢做一些优雅的让人看不懂的事情,所以也可以写作如下公式:
其中k为0或者1 -
二项分布(Binomial distribution):


如果进行次投硬币实验,计算出现m次正面朝上的概率
伯努利分布是二项分布中n=1时的特殊情况 -
Categorical分布(Categorical distribution),如果我们将投硬币改成掷骰子,那么原来一维向量x就会变成一个六维向量,其中每一维度为1表示出现该面,0表示没出现,用数学表示即对于随机变量X有k中情况,其中第
 种情况出现的概率为
种情况出现的概率为 :
:
那么我们可以得到其离散概率分布如下:
其中如果 那么
那么 为1,否则为0
为1,否则为0 -
多项式分布(Multinomial distribution):与二项分布类似,Categorical分布进行N次试验,便得到多项式分布:

同样我们可以写成吊吊的形式:
其中 为gamma函数:当n>0,则
为gamma函数:当n>0,则 (ps.该形式与狄利克雷分布(Dirichlet distribution)的形式非常相似,因为多项式分布是狄利克雷分布的共轭先验)
(ps.该形式与狄利克雷分布(Dirichlet distribution)的形式非常相似,因为多项式分布是狄利克雷分布的共轭先验)
OK简单梳理了下过去的知识,PLSA假设每篇文档的词频向量服从Categorical分布,那么对于整个训练样本的词频矩阵W则服从多项式分布。PLSA利用了aspect model,引入了潜在变量z(即所谓主题),使其变成一个混合模型(mixture model)。其图模型如下:
其中 表示文档集,Z便是PLSA中引入的隐含变量(主题/类别),
表示文档集,Z便是PLSA中引入的隐含变量(主题/类别), 表示词表。
表示词表。 表示单词出现在文档
表示单词出现在文档 的概率,
的概率, 表示文档
表示文档 中出现主题
中出现主题 下的单词的概率,
下的单词的概率, 给定主题
给定主题 出现单词
出现单词 的概率。其中每个主题在所有词项上服从Multinomial分布,每个文档在所有主题上服从Multinmial分布。按照生成模型,整个文档的生成过程如下:
的概率。其中每个主题在所有词项上服从Multinomial分布,每个文档在所有主题上服从Multinmial分布。按照生成模型,整个文档的生成过程如下:
(1)以的概率生成文档
(2)以的概率选中主题
(3)以的概率产生一个单词
那么对于单词出现在文档的联合概率分布,而是隐含变量。

其中和分别对应了两组Multinomial分布,PLSA需要训练两组分布的参数
LDA
有了PLSA,那么LDA就相对简单了,其相当于贝叶斯(Bayes' theorem PS.关于贝叶斯理论强烈推荐:数学之美番外篇:平凡而又神奇的贝叶斯方法,一篇深入浅出的好文)PLSA即:
LDA=Bayesian pLSA
为什么这么说呢?我们站在贝叶斯理论的角度看上文提到的PLSA,基于上文的阐述,我们知道PLSA的假设是文档-词语的词频矩阵服从多项式分布(multinomial distribution),那么在贝叶斯理论中,相当于我们找到了似然函数,那么想要计算后验概率时,我们需要找到先验概率。
简单扯两句共轭先验:
根据贝叶斯理论我们有如下形式:

OK其中 我们可以成为似然函数即一件事情发生的似然性(最大似然估计),那么
我们可以成为似然函数即一件事情发生的似然性(最大似然估计),那么 相当于先验概率分布,一般
相当于先验概率分布,一般 为一个常数,所以忽略。那么对于计算后验概率,我们需要找到似然函数和先验分布。
为一个常数,所以忽略。那么对于计算后验概率,我们需要找到似然函数和先验分布。
一般当我们已知似然函数的形式的时候,我们需要找到先验分布,那么对于所有满足[0,1]区间内的分布都符合这个条件,为了计算简单,我们采用与似然函数形式尽量一致的分布作为先验分布,这就是所谓的共轭先验。
在上文中介绍多项式分布时提到了Dirichlet分布,我们看多项式分布的形式如下:

那么我们需要找寻形式相似如下的分布:

而Dirichlet分布的形式如下:

看出来了吧,去掉左边的Beta分布不说,在右边的形式上Dirichlet分布和Multinomial分布是及其相似的,所以Dirichlet分布是Multinomial分布的共轭先验。
再回到LDA,根据之前分析的PLSA可知,每个文档中词的Topic分布服从Multinomial分布,其先验选取共轭先验即Dirichlet分布;每个Topic下词的分布服从Multinomial分布,其先验也同样选取共轭先验即Dirichlet分布。其图模型如下:
我们可以看出LDA中每篇文章的生成过程如下:
- 选择单词数N服从泊松分布,
 ,
, - 选择服从狄利克雷分布,
 ,
, - 对于N个单词中的每个单词
 a. 选择一个主题
a. 选择一个主题 ,服从多项分布
,服从多项分布 , b. 以概率
, b. 以概率 生成单词,其中表示在主题上的条件多项式概率。
生成单词,其中表示在主题上的条件多项式概率。
在LDA中我们可以利用来表示一篇文档。
应用
从之前LDA的阐述中,我们可以利用来表示一篇文档,那么我们自然可以利用这个向量对文档进行语义层面的词语和文档的相似性分析从而达到聚类、推荐的效果。当然了LDA本身对于文档分析出的主题,以及每个主题下的词汇,就是对于文档词汇的一层低维聚类。
之前用过Git上Java版的LDA实现,但是语料不是很大,对其性能并不能做出很好的评估。其地址如下:
github: A Java implemention of LDA(Latent Dirichlet Allocation)
public static void main(String[] args) { // 1. Load corpus from disk Corpus corpus = Corpus.load("data/mini"); // 2. Create a LDA sampler LdaGibbsSampler ldaGibbsSampler = new LdaGibbsSampler(corpus.getDocument(), corpus.getVocabularySize()); // 3. Train it ldaGibbsSampler.gibbs(10); // 4. The phi matrix is a LDA model, you can use LdaUtil to explain it. double[][] phi = ldaGibbsSampler.getPhi(); Map[] topicMap = LdaUtil.translate(phi, corpus.getVocabulary(), 10); LdaUtil.explain(topicMap); } 其采用吉布斯采样的方法对LDA进行求解。之后自己也准备尝试用spark进行实现,看是否能够对性能进行优化。
Word2Vec
谷歌的Tomas Mikolov团队开发了一种词典和术语表的自动生成技术,能够把一种语言转变成另一种语言。该技术利用数据挖掘来构建两种语言的结构模型,然后加以对比。每种语言词语之间的关系集合即“语言空间”,可以被表征为数学意义上的向量集合。在向量空间内,不同的语言享有许多共性,只要实现一个向量空间向另一个的映射和转换,语言翻译即可实现。该技术效果非常不错,对英语和西语间的翻译准确率高达90%。
什么是word2vec?你可以理解为word2vec就是将词表征为实数值向量的一种高效的算法模型,其利用神经网络(关于神经网络之前有简单进行整理:马里奥AI实现方式探索 ——神经网络+增强学习),可以通过训练,把对文本内容的处理简化为K维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似。(PS. 这里往往人们会将word2vec和深度学习挂钩,但其实word2vec仅仅只是用了一个非常浅层的神经网络,跟深度学习的关系并不大。)
Word2vec输出的词向量可以被用来做很多NLP相关的工作,比如聚类、找同义词、词性分析等等。如果换个思路, 把词当做特征,那么Word2vec就可以把特征映射到K维向量空间,可以为文本数据寻求更加深层次的特征表示 。
神经网络语言模型
word2vec的思想最早起源于2003年Yoshua Bengio等人的论文A Neural Probabilistic Language Model:
Traditional but very successful approaches based on n-grams obtain generalization by concatenating very short overlapping sequences seen in the training set. We propose to fight the curse of dimensionality by learning a distributed representation for words which allows each training sentence to inform the model about an exponential number of semantically neighboring
sentences. [16]
从文中摘要中的这段话我们可以看出,神经网络语言模型提出的初衷便是为了解决传统的n-gram模型中维度灾难的问题,用distributed representation词向量的形式来表示每一个词语。
文中提出的模型利用了一个三层神经网络如下图(一般投影层算在输入层中,这里分开阐述):
其中,对于语料库C,词典D的长度为(|D|=N)为语料库C的词汇量大小。对于任意一个词 ,表示其前n-1个词语,类似于n-gram模型,二元对
,表示其前n-1个词语,类似于n-gram模型,二元对 为一个训练样本。我们
为一个训练样本。我们 为词向量,词向量的维度为m。图中W,U分别为投影层和隐藏层以及隐藏层和输出层之间的权值矩阵,p,q分别为隐藏层和输出层上的偏置向量。
为词向量,词向量的维度为m。图中W,U分别为投影层和隐藏层以及隐藏层和输出层之间的权值矩阵,p,q分别为隐藏层和输出层上的偏置向量。
论文中给出的神经网络模型如下图:
其中C(i)表示第i个词的特征向量(词向量),我们看到图中第一层为词的上下文的每个词向量,在第二层我们将输入层的n-1个词向量按顺序首尾拼接在一起,形成一个长向量,其长度为(n-1)m,输入到激活函数tanh双曲正切函数中,计算方式如下:

经过上述两步计算得到的 只是一个长度为N的向量,我们看到图中第三层还做了一次softmax(Softmax function)归一化,归一化后
只是一个长度为N的向量,我们看到图中第三层还做了一次softmax(Softmax function)归一化,归一化后
就可以表示为:

 为词在词典D中的索引。
为词在词典D中的索引。
在之前的背景知识n-gram模型

我们知道语言模型中很关键的便是F的确定,其中参数如下:
- 词向量:
 ,以及填充向量(上下文词汇不够n时)
,以及填充向量(上下文词汇不够n时) - 神经网络参数:

论文的主要贡献有一下两点:
-
词语之间的相似性可以通过词向量来表示
不同于之前我们讨论的One-hot Representation表示方式,论文中指出在进行训练时,向量空间表达的词语维度一般为30、60或100,远远小于词典长度17000,避免了维度灾难。同时语义相似句子的概率是相似的。比如:某个语料库中的两个句子S1="A dog is running in the room", S2="A cat is running in the room",两个句子从语义上看仅仅是在dog和cat处有一点区别,假设在语料库中S1=1000即出现1000次而S2=1即仅出现一次,按照之前我们讲述的n-gram模型,p(S1)>>p(S2),但是我们从语义上来看dog和cat在句子中无论从句法还是语义上都扮演了相似的角色,所以两者概率应该相似才对。
而神经网络语言模型可以做到这一点,原因是:1)在神经网络语言模型中假设了相似的词在词向量上也是相似的,即向量空间中的距离相近,2)模型中的概率函数关于词向量是光滑的,那么词向量的一个小变化对概率的影响也是一个小变化,这样下面的句子:A dog is ruuning in the room
A cat is running in the room
The cat is running in the room
A dog is walking in the bedroom
The dog was walking in the bedroom
只要在语料库中出现一个,其他句子的概率也会相应增大。
- 基于词向量的模型在概率计算上已经是平滑的,不需要像n-gram模型一样做额外的平滑处理,因为在softmax阶段我们已经做了归一化,有了平滑性。
我们最终训练得到的词向量,在整个神经网络模型中,似乎只是一个参数,但是这个副作用也正是word2vec中的核心产物。
CBOW和Skip-gram模型
word2vec中用到了两个重要模型:CBOW(Continuous Bag-of-Words Model)和Skip-gram(Continuous Skip-gram Model)模型,文中作者Tomas Mikolov[17]给出了模型图如下:
由图中我们看出word2vec是一个三层结构的神经网络:输入层、投影层和输出层(这里我们发现word2vec与上面我们阐述的神经网络模型的显著区别是去掉了隐藏层)。对于图中左边的CBOW模型,是已知当前词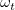 的上下文
的上下文 的前提下预测当前词;而正好相反,Skip-gram模型是已知当前词的前提下来预测其上下文。
的前提下预测当前词;而正好相反,Skip-gram模型是已知当前词的前提下来预测其上下文。
CBOW模型的目标函数,即其对数似然函数形式如下:

而Skip-gram模型的优化目标函数则形如:

Mikolov在word2vec中提出了两套框架,Hieraichical Softmax和Negative Sampling,这里由于博文篇幅太长了,就不错过多阐述,只对基于Hieraichical Softmax的CBOW模型进行简单总结。
CBOW模型中,与之前神经网络语言模型类似表示一个样本,其中表示词的前后各c个词语(共2c个),其三层结构我们可以细化如下:
- 输入层:包含中2c个词的词向量,每个词向量的维度都是m
- 投影层:将输入层的2c个词向量做求和累加,即

- 输出层:输出层对应一颗二叉树,它是以语料中出现过的词作为叶子节点,以各词在语料中出现的次数作为权重构造出来的一颗Huffman树(Huffman coding),其叶子节点共N(=|D|)个对应语料库D中的各个词,非叶子节点为N-1个。
对比我们之前讨论的最早的神经网络语言模型,CBOW模型的区别主要为以下三点:
- 从输入层到投影层的操作,前者通过拼接,而后者通过累加求和
- 前者有隐藏层,后者无隐藏层
- 输出层前者是线性结构(softmax),后者是树形结构(Hierarchical softmax)
word2vec对于词典D中的任意词,Huffman树必存在一条从根结点到词的路径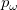 (且唯一)。路径上存在
(且唯一)。路径上存在 个分支(每条路径上的总结点数为
个分支(每条路径上的总结点数为 ),将每个分支看做一次二次分类,每一次分类产生一个概率,将这些概率乘起来,便是所需的
),将每个分支看做一次二次分类,每一次分类产生一个概率,将这些概率乘起来,便是所需的 。在二分类的过程中,可以利用Huffman编码值,即左树为1右树为0进行逻辑回归分类。
。在二分类的过程中,可以利用Huffman编码值,即左树为1右树为0进行逻辑回归分类。
word2vec在求解的过程中主要利用了梯度下降的方法,调整学习率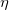 ,这里我们不再长篇大论的阐述,具体可以参考文献[14],对word2vec中的数学原理阐述的非常清晰。
,这里我们不再长篇大论的阐述,具体可以参考文献[14],对word2vec中的数学原理阐述的非常清晰。
应用
word2vec从被发布起就是各种大红大紫,在谷歌的翻译系统中,得到了很好的验证。围绕本篇博文的主题,即文本相似度的度量,word2vec产生的词向量可以非常方便的让我们做这件事情,利用欧氏距离或者cos都可以。
在之前Wetest舆情项目,做句法分析时,需要找寻某一个词的同类词语,我们用用户的游戏评论训练word2vec,效果还是不错的如下图:
对于游戏的人工想到的维度词进行同类扩展,得到扩展维度词。
之前在应用时是自己师兄使用的python版word2vec,而Java对于word2vec有一个较好的东东DL4J,但其性能我并没有经过大规模预料测试,这个大家用的时候需谨慎。
OK,长舒一口气~,好长的一篇整理,整个文章虽然涵盖了好多个模型、算法,但是围绕的一个主题便是如何度量两个文本之间的相似性,从字面和语义两个角度对自己平时用过接触过的模型算法进行整理归纳,如有任何纰漏还请留言指出,我会第一时间改正。(感谢身边的同事和大神给予的指导帮助)