欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
本篇文章是我在读期间,对自然语言处理中的文本相似度问题研究取得的一点小成果。如果你对自然语言处理 (natural language processing, NLP) 和卷积神经网络(convolutional neural network, CNN)有一定的了解,可以直接看摘要和LSF-SCNN创新与技术实现部分。如果能启发灵感,应用于更多的现实场景中带来效果提升,那才是这篇文章闪光的时刻。如果你没有接触过NLP和CNN,也不在担心,可以从头到尾听我娓娓道来。有任何问题,欢迎交流。
1. 摘要
LSF-SCNN,即基于词汇语义特征的跳跃卷积模型 (Lexical Semantic Feature based Skip Convolution neural network ),基于卷积神经网络模型引入三种优化策略:词汇语义特征 (Lexical Semantic Feature, LSF)、跳跃卷积 (Skip Convolution, SC)和K-Max均值采样 (K-Max Average Pooling, KMA) ,分别在词汇粒度、短语粒度、句子粒度上抽取更加丰富的语义特征,从而更好的在向量空间构建短文本语义表达模型,并广泛的适用于问答系统 (question answering)、释义识别 (paraphrase identification) 和文本蕴含 (textual entailment)等计算成对儿出现的短文本的相似度的任务中。
2. 从词向量到文本向量
人类的语言,是人类独有的进化千百万年后形成的信息表达方式。相比于具有原始信号输入的图像(像素)和语音(声谱),符号化的自然语言属于更加高层认知的抽象实体。因此,自然语言处理的第一步也是至关重要的一步就是怎样将符号化的自然语言表示成计算机可以理解的数值形式。
对于自然语言的理解,在语言粒度上遵循着自底向上从字、词、句、段落最后到篇章的研究思路。在对最小粒度的字的符号化表达上,基本可以分为两种:one-hot representation和word distributed representation。
- one-hot representation是将所有的词构建成一个词典,每个词对应一个索引,该词对应的索引位为1,其他位为0。例如,词典为{welcome to taobao},那么welcome就可以表示为[1,0,0],taobao就表示成[0,0,1]。这种方式有两个缺点:一是维数灾难;二是语义鸿沟,任意两个单词都是正交且孤立的,无法表征词语间的相似性。即便如此,配合传统的最大熵、SVM等算法也很好的实现了NLP中各种主流任务。
- word distributed representation在深度学习 (Deep Learning)方法中较常用,通常中文翻译成词向量,或者词嵌入 (word embedding)。它用低维实数变量(常用的有50维,100维,300维)来表示词典中的每一个词。这种方式相比于one-hot representation最大的优点是在向量空间上,可以将词语之间的语义相关关系映射成如欧式距离等距离量度上的大小关系。现有的词向量训练的方法都是在用神经网络训练语言模型的同时,顺便得到了词向量。如果对词向量非常感兴趣,可以参考[1]
在大多数NLP的任务中,如情感分类、机器翻译、问答系统等,都需要以自然语句作为输入。那么,怎样以词向量为基础,表达一个短语或一句话的语义呢?短语或者句子能否也通过向量的形式表达?答案是肯定的。在深度学习框架下,有许多神经网络,如卷积神经网络CNN[2]、递归神经网络Recursive NN[3]、循环神经网络Recurrent NN[4]等,都可以将词向量序列有效的编码成短语或句子向量。
- Recursive NN通常自底向上地基于语法解析树的结构逐层生成短语、句子的向量表达,同时受限于生成语法解析树的准确率。
- Recurrent NN通常应用于具有时序关系的序列问题,并假设一个序列当前的输出与之前的输出有关,神经网络会对前面的信息进行记忆并应用于当前输出的计算中。
- CNN在多种NLP任务中,被证实在同时从语法和语义两个层面学习句子向量表达上表现突出,独有的卷积操作使其可以学习到在文本长序列中具有稳定表达方式的短序列的特征,而与其出现位置无关。
3. 短文本相似度计算的现有解决方案
通过神经网络学习到的短语或句子向量就可以进一步应用于以短文本相似度计算为核心的多种任务中,如问答系统中的答案选择问题 (Answer Selection,AS),即从输入问题的特定候选答案列表中,筛选可以回答问题的正确答案,本质是一个二分类问题(预测为正确的答案标记为1,错误的答案标记为0。)再如,释义识别任务,即判断两句话是否表达同一种语义。
目前,基于CNN模型的短文本相似度的计算方法可以大致分为两类:一类是基于Siamese结构的神经网络模型,先分别学习输入的文本对儿的句子向量表达,再基于句子向量计算相似度;另一类是直接以词语粒度的相似度矩阵作为输入,学习并计算文本相似度。下面将分别展开介绍。
3.1 基于Siamese结构的神经网络模型
这里列举最近两年比较有代表性的两篇文章。
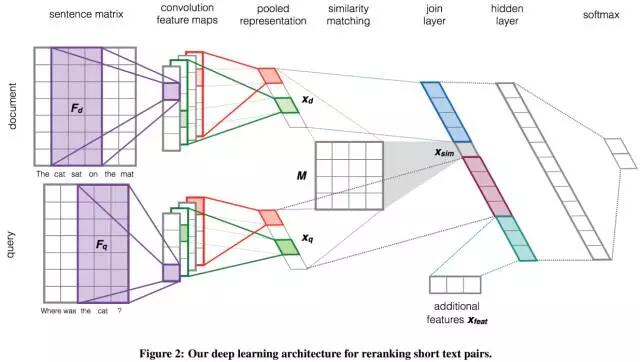
如下图所示,是Severyn发表在2015年SIGIR上的文章[5],并用于TREC上的两个NLP任务:答案选择和微博检索。以答案选择任务为例,从左至右,作者采用上下并行的双通道浅层CNN模型来分别学习输入的问题和答案的句子向量表达,然后经过相似度矩阵M计算相似度,全连接层和隐藏层进行特征整合和非线性变换,最后softmax层来输出输入候选答案被预测为正确或者错误的概率。左半部分的双通道CNN即可理解为学习从词向量到句子向量的表达模型。
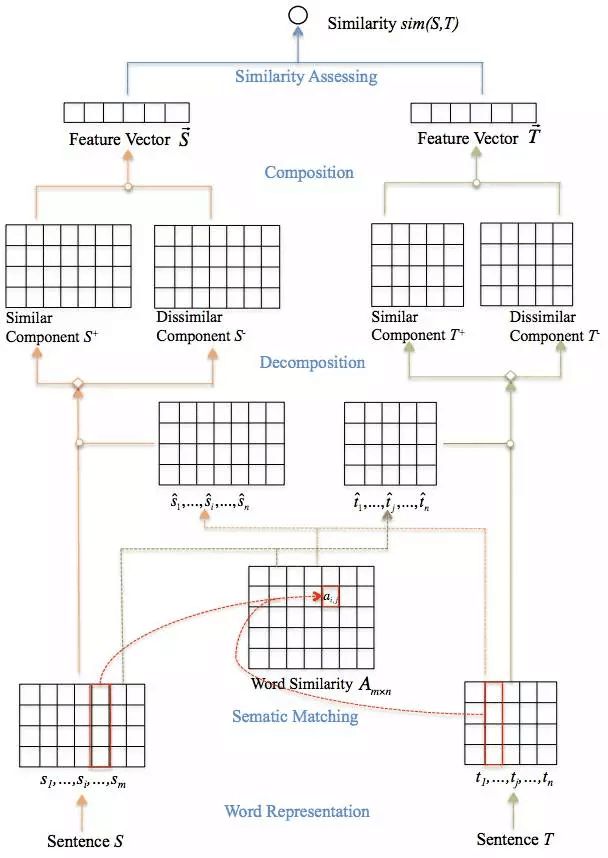
如下图所示,是Wang发表在2016年COLING的文章[6],同样应用于答案选择任务,并在两个公认基准数据集WikiQA和QASent上进行了测试。文章的核心想法是采用双通道CNN来抽取输入问题和答案之间的相似性与不相似性,整合成最终的句子向量并计算相似性。
3.2 基于词语粒度的相似度矩阵直接学习并计算文本相似度
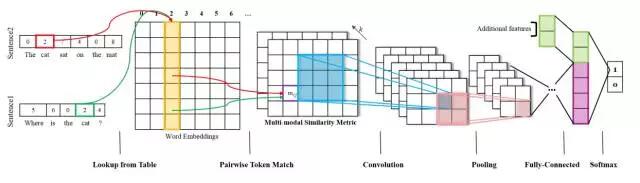
如下图,Meng在其文章中[7]直接基于词向量计算输入文本对儿在单词粒度上的相似度(计算方式有多种:欧式距离、余弦距离、参数化的相似矩阵),并以此为后续深层卷积神经网络的输入,最终学习得到的向量经过全连接层和softmax层进行预测。
4. LSF-SCNN模型创新与技术实现
有了前面在深度学习框架下,文本向量学习的背景和基于CNN短文本相似度的现有方法的总结和介绍,终于进入本篇文章的重头戏,LSF-SCNN模型的介绍。LSF-SCNN模型延续了基于Siamese结构神经网络模型构建短文本表达模型的总体思路[5],但通过引入三种优化策略:词汇语义特征 (Lexical Semantic Feature, LSF)、跳跃卷积 (Skip Convolution, SC)和K-Max均值采样 (K-Max Average Pooling, KMA) ,分别在词汇粒度、短语粒度、句子粒度上抽取更加丰富的语义特征,并在答案选择AS计算短文本相似度问题上取得了非常好的效果。
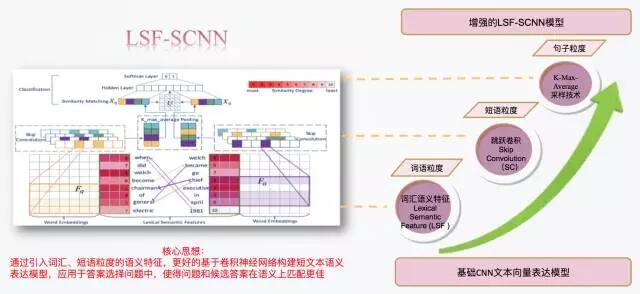
下图展示了LSF-SCNN的整体框架图,自底向上,LSF-SCNN模型由3个模块组成:(1)对于输入的问题和候选答案,我们利用词汇语义特征技术为每个单词计算LSF特征值,以此来表征问题与答案之间的语义交互特征。LSF特征会和词嵌入拼接在一起构成词语粒度上更加丰富的特征表达,表达词的向量再次拼接构成句子矩阵。(2)问题和候选答案的句子矩阵经过跳跃卷积层和K-Max均值采样层,最终形成对问题和答案各自的向量表达,记作Xq和Xa 。(3)Xq和Xa会根据学习得到的相似度计算矩阵M得到一个相似度分数。最后,相似度分数和Xq、Xa整合一起作为分类器的输入,最终得到输入候选答案a被预测为正确答案和错误答案的概率。接下来,我将一一介绍三个优化技术的实现细节。
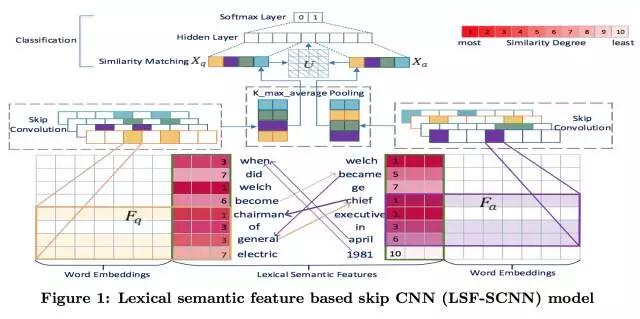
4.1 词汇语义特征技术(Lexical Semantic Feature,LSF)
-
LSF技术提出的原因:
基于Siamese的神经网络结构有个缺点就是将输入的文本对儿看做互不相关的句子,相互独立的用同一套神经网络结构去学习文本的向量表达。但是在短文本相似度相关任务中,如问题和候选答案,往往是文本对儿间在语义、词语表达、语序等方面存在关联,而前人方法忽略了这点。少部分学者注意到了这点,但目前所用方法局限于:借助额外知识标记近义词/反义词、上位词/下位词等关系;或者引入字符串匹配信息,严格匹配标记为1,其余为0。因此,本文提出的LSF技术是一项用来构建问题与答案之间的语义交互特征的技术。 -
LSF核心想法:
LSF技术将词语粒度上的相似性量化细分为t个相似度,从而建立输入文本对儿之间的语义关联,为后续神经网络提供更加丰富的语义特征输入。 -
LSF技术可行性分析:
LSF技术将词语粒度上的相似性量化细分为t个相似度,不仅可以包含前人提出的近义词、反义词关系,如chairman和chief的LSF为1, 字符串匹配如welch和welch被标记为1,也可以涵盖更多的相似性。
例如,april和when不是近义词,在字符串上也无法匹配,但LSF可以捕捉到他们之间有6的相似度,而april正是回答该问题的正确答案,
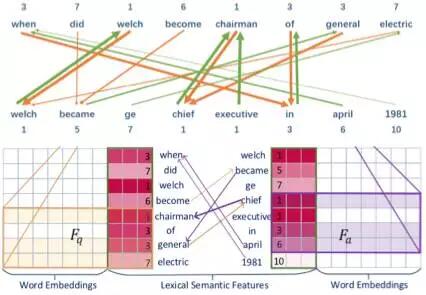
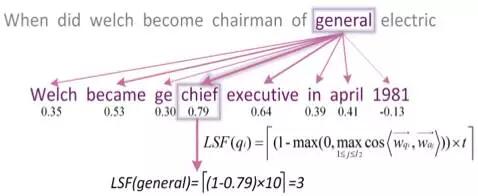
- LSF特征怎样计算得到?
问题和答案中的每一个单词都会有一个LSF特征,具体来说是一个[0,t]上的整数值。LSF的计算过程可通过下面一个例子说明,当我们想要求解问题中general一词的LSF特征时,第一步我们需要计算general与答案中每一个词的余弦相似度并选取其中的最大值,因此chief被选取出来。第二步,余弦相似度值的最大值0.79将通过一个映射函数映射为一个[0,t]区间的整数,当我们假定t=10,最终计算得到general的LSF特征为3。这是合理的,general和chief一定程度上是近义词。
4.2 跳跃卷积技术(Skip Convolution,SC)
- SC技术核心想法: 在短语粒度上,我们提出跳跃卷积SC技术。下图展示了以the cat sat on the mat为例,设定卷积窗口长度为4时,且步长为1跳跃一次,跳跃卷积方式在传统卷积方式上的改进:
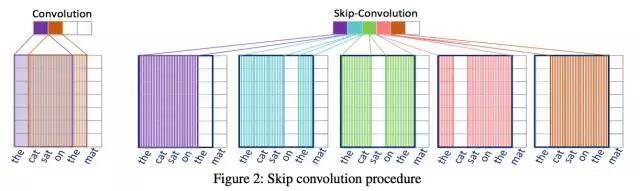
- 传统卷积方式将取得如下短语特征:{the cat sat on, cat sat on the, sat on the mat}
-
跳跃卷积将取得如下短语特征{the cat sat on, the cat sat the, the cat on the, the sat on the, cat sat on the, cat sat on mat, cat sat the mat, cat on the mat, sat on the mat }。
-
SC的技术实现:
如上图所示,左侧传统卷积方式将卷积窗口作为一个整体,自左向右每次移动一个单词的步长进行卷积操作。相比而言,跳跃卷积则是同样自左向右每次移动一个单词的步长,但移动的并非卷积窗口的整体,而是整体中的一列。例如,上图右侧,初始卷积抽取了短语“the cat sat on”(紫色框)的特征;而后将覆盖在“on”上的卷积窗口的那一列向右移动一个单词的步长,从而得到短语“the cat sat the”(蓝色框)的特征;接着,将覆盖在“sat”上的一列向右移动一个单词的步长,从而得到短语“the cat on the”(绿色框)的特征,以此类推。 -
SC技术可行性分析:
传统卷积方式只允许在特定大小的卷积窗口中对相邻的词语进行卷积,而跳跃卷积可以通过跳跃停用词如the、形容词等,在特定大小的卷积窗口中将抽取到包含更完整更浓缩的主体语义信息的短语特征如‘cat sat on mat’,从而提升了短语粒度上特征的丰富性。虽然,跳跃卷积相比于传统卷积方式,也会额外抽取到许多无用的短语的特征。但实验结果证明,跳跃卷积技术对增加短语特征丰富性的帮助,要大于额外增加的无用短语特征带来的噪音的影响。
SC技术实现可以参考[8]。Lei的文章应用于情感分类 (sentiment classification) 和新闻分类 (news categorization) 任务,而本文应用于答案选择任务。
4.3 K-Max均值采样技术(K-Max Average Pooling,KMA)
-
K-Max均值采样提出的背景:
卷积神经网络中的池化层,也称采样层,主流有两种方法:最大值采样 (max pooling) 和均值采样 (average pooling)。但上述两种方法也存在一定的局限性,由此,Zeiler and Fergus[9]提出了对于最大值采样的一些改进技术,Kalchbrenner[10]提出了动态k-max采样技术。 -
K-Max均值采样的核心思想:
本文提出的K-max均值采样技术结合了最大值采样和均值采样。具体而言,对于卷积层传入的特征矩阵
(feature map),K-Max采样技术选取其中最大的前K个值,并取其平均值作为最终的采样结果。K-Max均值采样的好处,一方面可以减少异常噪音点的影响,另一方面可以保留表现比较强的特征的强度。虽然想法简单,但实验证明对模型的提升效果较好。
5. 实验结果
5.1 实验数据
本文在两个公认标准数据集QASent和WikiQA设计全面的实验。下图展示了两个数据集的一些统计信息。
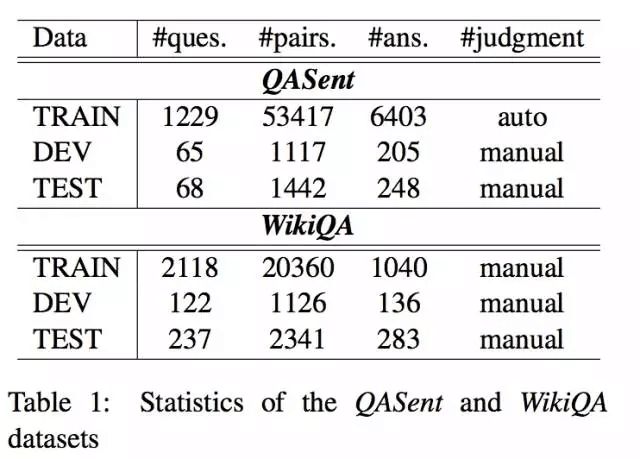
两个数据集有以下两方面区别:
- QASent候选答案从文档库中抽取出来,而WikiQA候选答案来自Bing日志(被查询的问题所返回的链接列表,筛选出被五个不相同的用户点击过的链接,并从选中链接的摘要中抽取答案),因此WikiQA更加真实、更能反映用户的真实查询意图。
- QASent候选答案要求至少与问题有一个非停用单词,而WikiQA中20.3%的答案与问题不存在相同单词,因此WikiQA对LSF技术提出了更高的挑战。
5.2 实验结果:
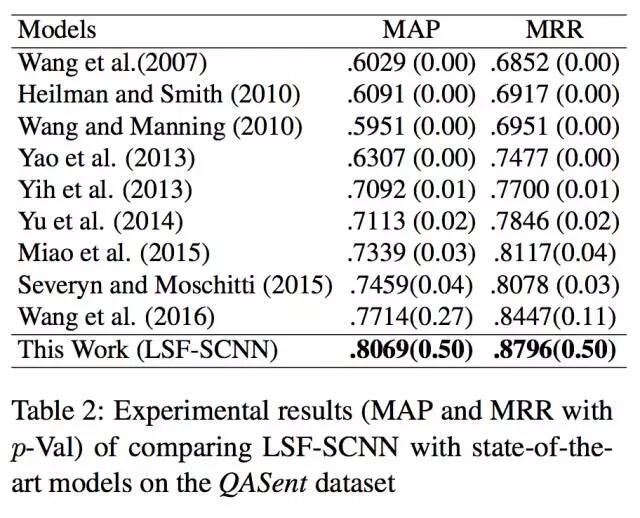
下面两个表格分别展示了LSF-SCNN模型与前人方法在QASent和WikiQA两个数据集上的效果对比,由此可见,LSF-SCNN模型相比于当前最好的方法,在MAP和MRR两个指标上,对QASent数据集提升了3.5%,对WikiQA数据集提升了1.2%。答案选择问题的baseline比较高,所以LSF-SCNN的提升效果还是非常显著的。
6. 总结
本文主要介绍了LSF-SCNN模型,即基于词汇语义特征的跳跃卷积模型 (Lexical Semantic Feature based Skip Convolution neural network ),基于卷积神经网络模型引入三种优化策略:词汇语义特征 (Lexical Semantic Feature, LSF)、跳跃卷积 (Skip Convolution, SC)和K-Max均值采样 (K-Max Average Pooling, KMA) ,分别在词汇粒度、短语粒度、句子粒度上抽取更加丰富的语义特征,从而更好的在向量空间构建短文本语义表达模型,并在答案选择 (Answer Selection) 问题上进行了实验验证。
其中词汇语义特征LSF技术可以更广泛的应用于基于神经网络结构学习文本对儿间向量表达的相关任务。跳跃卷积SC技术和K-Max均值采样技术更广泛的使用于存在卷积层和采样层的神经网络结构中。三种技术既可以根据需要单独使用,也可以相互助益共同提升模型整体效果。
原文:https://dl.acm.org/citation.cfm?spm=5176.100239.blogcont157756.28.rldvdc&id=3054216
本文转载于全球人工智能微信公众号
相关阅读
爸爸去哪儿玩转黑科技:快来测测自己和老爸有多像?
研究 AI 识别同性恋竟受到死亡威胁!论文作者回应如下
人脸对齐:ASM (主动形状模型)算法
此文已由作者授权腾讯云技术社区发布,转载请注明原文出处
原文链接:https://cloud.tencent.com/community/article/499759?fromSource=gwzcw.632157.632157.632157