深度学习 Day 11——利用卷神经网络进行彩色图片分类
深度学习 Day 11——利用卷神经网络进行彩色图片分类
文章目录
- 深度学习 Day 11——利用卷神经网络进行彩色图片分类
-
- 一、前言
- 二、我的环境
- 三、前期工作
-
- 1、设置GPU
- 2、导入依赖项
- 3、导入数据
- 4、设置归一化
- 5、数据可视化
- 四、构建CNN网络
-
- 1、关于卷积层
- 2、关于池化层
- 3、构建CNN网络模型
- 五、编译模型
- 六、训练模型
- 七、利用模型进行预测
- 八、模型评估
- 九、最后我想说
一、前言
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章地址: 深度学习100例-卷积神经网络(CNN)彩色图片分类 | 第2天
- 作者:K同学啊
之前暑假参加了21天学习挑战赛,我选的学习方向是深度学习,带队博主是K同学啊,因为经过一个暑假的学习,我现在对深度学习方面比较的感兴趣,所以我也就继续选择加入了K同学啊的365天深度学习训练营,继续开始我的学习,学习一个复杂高级的领域,如果能有人带队,那么学习起来将会事半功倍,但更重要的还是自己要养成长期学习的自律习惯。
本周的任务就是利用CNN卷神经网络进行彩色图片的分类,废话不多说,我们开始学习!
二、我的环境
- 电脑系统:Windows 11
- 语言环境:Python 3.8.5
- 编译器:DataSpell 2022.2
- 深度学习环境:TensorFlow 2.3.4
- 显卡及显存:RTX 3070 8G
三、前期工作
1、设置GPU
设置GPU的话,是需要看你的电脑性能的,如果电脑GPU不行,很容易导致电脑爆显存,所以如果你的电脑显存很高,那么就只使用GPU那样会比较的快,但是对于很多学生来说,大部分都是使用的笔记本来学习,所以,我推荐使用CPU来训练,然后利用GPU进行加速,这样适用于大多数笔记本。
只使用GPU:
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]], "GPU")
使用CPU+GPU:
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
2、导入依赖项
import os
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
3、导入数据
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
本期的数据会自动下载。
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 19s 0us/step
4、设置归一化
归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而减小奇异样本数据导致的不良影响。
奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛。因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
# 将像素的值标准化至0到1的区间内。
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
((50000, 32, 32, 3), (10000, 32, 32, 3), (50000, 1), (10000, 1))
5、数据可视化
我们来查看一下我们下载的数据:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(20,10))
for i in range(20):
plt.subplot(5,10,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

四、构建CNN网络
1、关于卷积层
何为卷积,简单的来说我们将对图像应用过滤器以获得结果图像,任何的图像都可以表示为像素矩阵,每一个像素代表一种颜色强度。

卷积过程:

我们通过将过滤器应用于我们的输入图像来构建另一个图像,我们设置应用的过滤器,设置不同的形状和值,将会得到不同的图像。
2、关于池化层
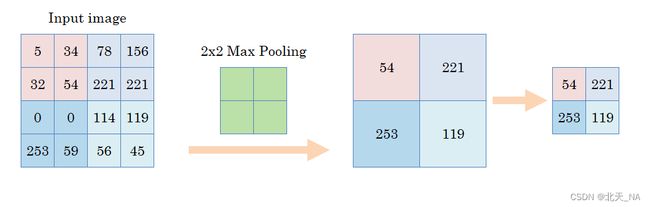
采用像素组并对它们进行拟合,池化层包括最大池化层和平均池化层,其中前者可以更好的提取特征纹理,后者可以更好的保留背景信息但是很容易导致图片模糊,所以现在一般都使用最大池化层,而很少使用平均池化层,池化可以增强卷积的能力。
3、构建CNN网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)), #卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), #卷积层3,卷积核3*3
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取
layers.Dense(10) #输出层,输出预期结果
])
model.summary() # 打印网络结构
它运行的结果是:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 64) 65600
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
五、编译模型
model.compile(optimizer='adam', # 优化器
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 损失函数
metrics=['accuracy']) # 准确率
六、训练模型
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
训练的结果是:
Epoch 1/10
1563/1563 [==============================] - 22s 14ms/step - loss: 1.5232 - accuracy: 0.4456 - val_loss: 1.2786 - val_accuracy: 0.5375
Epoch 2/10
1563/1563 [==============================] - 21s 14ms/step - loss: 1.1450 - accuracy: 0.5943 - val_loss: 1.1863 - val_accuracy: 0.5808
Epoch 3/10
1563/1563 [==============================] - 23s 15ms/step - loss: 0.9940 - accuracy: 0.6496 - val_loss: 0.9785 - val_accuracy: 0.6507
Epoch 4/10
1563/1563 [==============================] - 23s 14ms/step - loss: 0.8987 - accuracy: 0.6850 - val_loss: 0.9459 - val_accuracy: 0.6738
Epoch 5/10
1563/1563 [==============================] - 21s 14ms/step - loss: 0.8341 - accuracy: 0.7101 - val_loss: 0.9146 - val_accuracy: 0.6800
Epoch 6/10
1563/1563 [==============================] - 22s 14ms/step - loss: 0.7791 - accuracy: 0.7262 - val_loss: 0.8781 - val_accuracy: 0.6970
Epoch 7/10
1563/1563 [==============================] - 20s 13ms/step - loss: 0.7342 - accuracy: 0.7437 - val_loss: 0.9449 - val_accuracy: 0.6870
Epoch 8/10
1563/1563 [==============================] - 21s 13ms/step - loss: 0.6919 - accuracy: 0.7572 - val_loss: 0.8571 - val_accuracy: 0.7085
Epoch 9/10
1563/1563 [==============================] - 20s 13ms/step - loss: 0.6542 - accuracy: 0.7712 - val_loss: 0.8844 - val_accuracy: 0.7028
Epoch 10/10
1563/1563 [==============================] - 21s 13ms/step - loss: 0.6199 - accuracy: 0.7827 - val_loss: 0.8452 - val_accuracy: 0.7164
七、利用模型进行预测
我们前面利用了训练集进行了模型训练,现在我们将使用测试集来进行真实环境的预测,其中预测得到的是每一个类别的概率大小,该数字越大该图片被分为该类别的可能性也就越大,我们就通过这个来对图片进行分类。
我们随机抽几个查看一下它的预测结果:
plt.imshow(test_images[1])
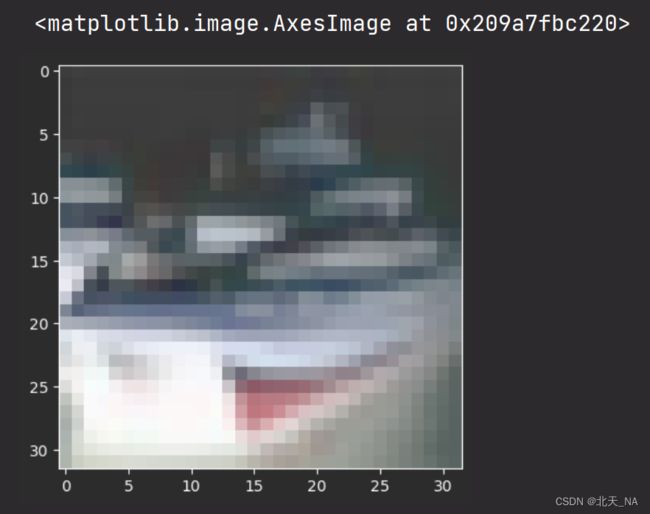
import numpy as np
pre = model.predict(test_images)
print(class_names[np.argmax(pre[1])])
它预测的是:
ship
再来一个:
plt.imshow(test_images[3])

pre = model.predict(test_images)
print(class_names[np.argmax(pre[3])])
它预测的是:
airplane
再试一个:
plt.imshow(test_images[100])

pre = model.predict(test_images)
print(class_names[np.argmax(pre[100])])
它预测的结果是:
deer
我们发现它预测的还很准确,但我们只是随机的抽取了几个,存在很大的偶然性,所以我们接下来进行模型评估,看看我们的模型构建的怎么样。
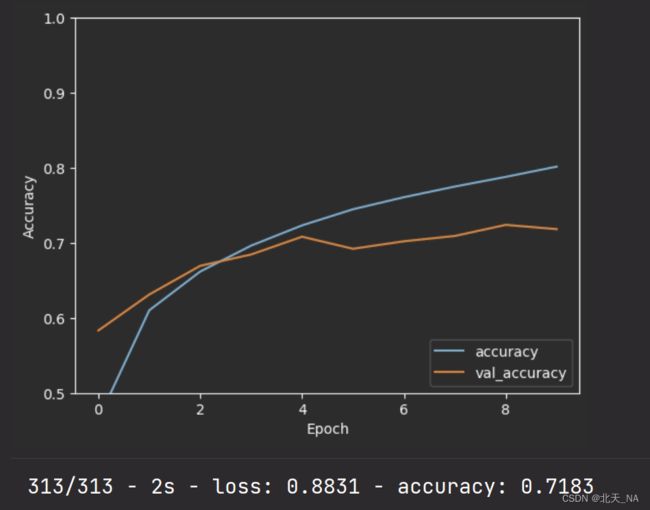
八、模型评估
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)

我们打印测试准确率看看:
print(test_acc)
它得到的结果是:
0.7182999849319458
可以看出我们训练的准确率在71.8%.
我后面我又尝试了一下增加训练次数到100,发现准确率降低了,说明如果训练集很大,那么它应该会在一个值趋于上下波动范围,如果再增加训练次数可能准确率还是会降低。
九、最后我想说
365天深度学习训练营是每个月至少参加3周的学习任务,每周的任务只有一个,完成的结果将以博客的形式写出来,如果不能完成则会被淘汰,这也可以大大的提高学习效率,没有一点挑战,大学生活可能就会变得枯燥乏味。
努力提高自己的综合实力,养成良好的编程习惯,我相信我一定可以变得更好,我们一起变得更加优秀。
这是我记录我学习成长的专栏,欢迎大家去观看,谢谢!
Python深度学习专栏
最后,创作不易,期待得到你们的支持!
