新东方基于Hologres实时离线一体化数仓建设实践
业务介绍
新东方教育科技集团定位于以学生全面成长为核心,以科技为驱动力的综合性教育集团。集团由1993年成立的北京新东方学校发展壮大而来,拥有短期培训系统、基础教育系统、文化传播系统等业务。
在互联网大潮中,新东方在IT技术上也不断重构,持续投入大数据建设,研发大数据的相关技术和应用,从而快速而精准地响应业务需求,并用数据为集团各级领导提供决策依据。新东方的大数据应用主要包括两部分:
- 企业应用端的业务场景(B端):包括交易,教学,人员等数据,数据规模为TB级。数据会被按照不同的条件和学校层级等,形成营收、教学、客服、财富人事等实时报表,为CRM系统的成千上万名业务顾问提供线索和商机的明细报表查询,同时也供各级管理人员了解业务的运行情况,辅助业务决策。
- 互联网直接面向用户场景(C端):主要为招生引流类、云教室等应用,包括网页版,App端,H5等,数据量为PB级。这部分数据记录了用户(学员和潜在用户)在新东方的教学闭环轨迹,C端数据除了生成常规的运营报表外,还会绘制用户画像,进而开发推荐系统和圈选等应用,改善C端各种应用的用户体验,进一步精细化运营。
数仓建设和应用痛点
为了满足日益增长的业务需求,集团开始投入数仓建设。在数据仓库建设的初期,以业务驱动为主。通过阿里云的MaxCompute为核心构建数据仓库,直接集成业务库数据以及WEB应用的OSS日志等,然后在数据仓库中分析业务数据并产生统计分析结果。初期的架构如下:
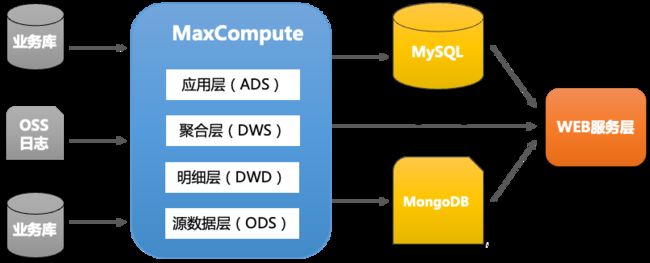
根据业务需要,将中小型规模的结果导入MySQL并支持数据更新。数据规模较大的只读结果则导入 MongoDB。
然后Web服务层查询MySQL和MongoDB并向用户提供服务接口, Web服务层也可以通过Lightning加速接口直接查询MaxCompute的数据,
Lightning协议是MaxCompute查询加速服务,支持以PostgreSQL协议及语法连接访问MaxCompute数据,相比MaxCompute提供的odps jdbc接口速度要快得多。原因是后者把每次访问作为一个Map-Reduce处理,即使很小的数据量查询响应时间也要超过10秒,而 Lightning能将延时降到百毫秒内,满足业务结果报表的展示需求。目前Lightning服务进入服务下线阶段,新的加速服务由Hologres加速集群替代。
使用这套架构可以在较短的时间内满足报表开发、用户画像和推荐服务等需求,为新东方的日常运营和招生引流提供较好的数据支持。但是随着业务的开展,这套架构越来越难以满足用户的需求,主要体现在:
- 实时性,业务希望能够达到1分钟级甚至秒级的实时性,而使用MaxCompute只能完成批量处理,一般只能提供分钟级(一般5分钟以上)的延时
- 来自Web服务层的高并发查询,MaxCompute的大数据量查询只能支持到100左右的QPS,满足不了来自C端应用的高并发查询
- 复杂逻辑的大数据量分析和Ad-hoc查询,随着分析数据迅速从数百G上涨到TB级,在多个数亿行以上的数据进行复杂报表开发,单实例MySQL难以支持;而MongoDB无法使用标准的SQL进行复杂查询,同时MongoDB本身复杂的查询业务,开发效率很低。
- Lightning接口虽然支持标准的SQL并且某些场景上速度比较快,但是Lightning开始逐渐下线,需要找到替换的方法。
实时数仓选型
要解决以上的业务痛点,就需要找到能满足实时数仓建设需求的产品。大数据团队调研了多种实时数仓方案,基于新东方的数据和应用特点进行选型,方案比对如下:
| 产品 | Ad-hoc查询 | 高并发支持(QPS) | SQL支持 | TP(交易)支持 | 与MaxCompute/Flink集成 | 文档和技术支持 |
|---|---|---|---|---|---|---|
| ClickHouse 20.1 | 支持PB级以上 | 默认支持100的并发查询,qps取决于单个查询的响应时间 | 单表查询支持较好,复杂报表查询支持较弱 | 通过mutation支持update,较弱 | 支持 | 文档丰富,社区支持较好 |
| Doris 0.9 | 支持PB级以上 | 数百 | 兼容MySQL | 不支持 | 通过兼容MySQL与MaxCompute集成,与Flink的集成 不明确 | 文档和社区都较差 |
| Hologres 1.1 | 支持PB级以上 | 数万以上 | 兼容PostgreSQL | DDL支持 | 与MaxCompute直接在存储层集成,并且都兼容PostgreSQL,提供Flink Connector集成 | 阿里在线文档和技术支持 |
| Tidb 4.x (含Tiflash) | 支持PB级以上 | 数万以上 | 兼容MySQL | 支持 | 支持 | 文档丰富,社区支持较好 |
| Elastic Search 7.x | 支持PB级以上 | 数万以上 | 不支持标准SQL | 不支持 | 支持与MaxCompute集成,Flink Connector只支持Source | 文档丰富,社区支持较好 |
从以上的表格能看出,Tidb和Hologres可以较好地解决新东方在大数据方面面临的问题。但是Tidb需要私有云部署并运维,而MaxCompute部署在公有云,两者在不同的云环境。Hologres是阿里云提供的云原生服务,并与MaxCompute都部署在公有云,且在Pangu文件层紧密集成,数据交换效率远高于其他外部系统,两者都兼容PostgreSQL,从离线数据仓库开发迁移到实时数据仓库开发难度降低。
基于以上的分析,选择Hologres作为实时数仓。
实时数仓建设
实时数仓是在离线数仓的基础上,基于Lambda架构构建,离线和实时同时进行建设。有关Lambda的,参阅:Lambda architecture
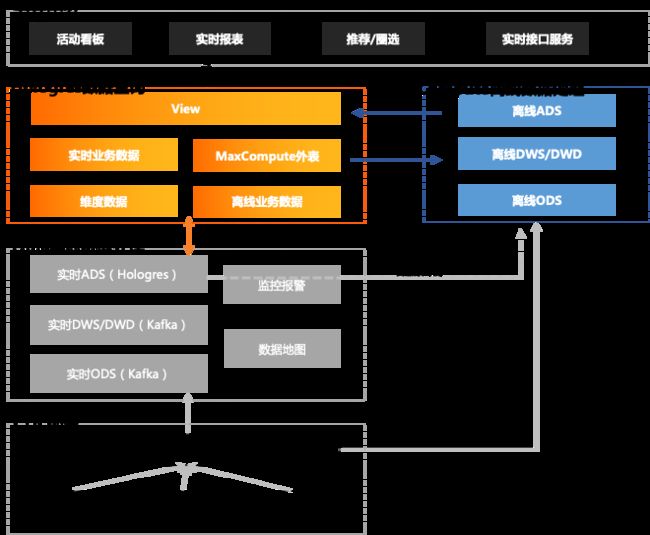
架构的各组件说明:
1)数据源:
- Binlog,即各类应用(B端和C端)的数据库Binlog,对于SQL SERVER的数据库则是CT log;
- App消息,即App运行时上报的事件;
- Web日志/埋点日志,即Web服务器所产生的ngix日志,以及Web app/H5运行时埋点服务产生的日志
2)CDC数据总线(简称CDC)
- CDC数据总线采集数据源,写入Kafka Topic。对于离线数仓和实时数仓, CDC都是直接交互的数据源/
- CDC包括Source Connector、Kafka 集群、Sink Connector三部分。 Source Connector 负责从数据源采集数据并写入Kafka集群的Topic,而Sink Connector则将Kafka Topic的数据ETL到目标库,包括实时和离线数仓。
- CDC易于部署和监控,并提供了简单的数据过滤,成本较低,数据ETL任务尽量采用CDC。
3)离线数据处理
- 离线数据处理基于MaxCompute搭建,用于计算全量数据,数据源来自于CDC的实时导入。离线数据经过离线数仓计算(ODS->DWD/DWS→ADS)导入Hologres作为存量数据,一部分离线的DWD/DWS数据也导入Hologres作为维表的存量数据。
- Flink计算任务会将ADS层结果Sink到MaxCompute, 用于数据备份。
4)实时数据处理
实时数据处理基于阿里云托管的 Flink流式计算引擎。与离线数仓处理固定日期的数据(如T+1)不同,实时数仓处理的是流式数据,从任务启动开始,就一直运行,除非异常终止,否则不会结束。数仓的层次与离线数仓类似,根据实时处理的特点做了简化。如下表所示:
| 数仓层次 | 描述 | 数据载体 |
|---|---|---|
| ODS层 | 与数据源表结构相似,数据未经过处理 | Kafka Topic/cdc Connector |
| DWD/DWS层 | 数据仓库层,根据业务线/主题处理数据,可复用 | Kafka Topic |
| DIM层 | 维度层 | holo 维表,Kafka Topic |
| ADS层 | 应用层,面向应用创建,存储处理结果 | holo实时结果表,Kafka Topic |
5)Hologres 数据查询
Hologres同时作为实时数据和MaxCompute离线数据加速查询的分析引擎,存储所有的实时数仓所需的数据表,包括维度数据表(维表)、实时结果表、存量数据表以及查询View和外表等。数据表的定义和用途如下表所示:
| 数据表名称 | 描述 | 数仓层次 | 数据源 |
|---|---|---|---|
| 维度数据表 | 维度建模后的数据表,在实时计算时事实表通过JDBC查询 | DIM层 | 初始化数据来自离线数仓dim 层、CDC、Flink维表计算任务 |
| 实时结果表 | 实时数仓的计算结果表 | 实时数仓DWS/ADS层 | 实时数仓的DWS/ADS层计算任务 |
| 存量结果表 | 离线数仓的计算结果表 | 实时数仓DWS/ADS层 | 离线数仓的DWS/ADS层计算任务 |
| 查询view | 合并实时和存量结果,对外提供统一的展示View | 实时数仓ADS层 | 存量结果表 |
| 实时结果表 | |||
| 外表 | 来自MaxCompute的数据表引用 | 各层次 | 离线数仓 |
| 备份表 | 备份实时计算一段时间内的数据,用于做数据校验和问题诊断 | DWD/DWS层 | 实时数仓 |
应用场景
通过新的架构,支持了新东方集团内如下应用场景:
- 实时报表查询:为CRM系统的成千上万名业务顾问提供线索和商机的明细报表查询,同时为管理层提供实时活动看板服务,延时秒级,辅助业务决策。
- Ad-hoc查询:B端和C端运营人员可以直接通过Hologres定制自己的复杂业务查询
- 用户轨迹和画像场景:实时处理用户来自B端和C端的数据,生成用户轨迹和标签,为业务快速决策提供依据。
- 推荐系统和圈选业务:通过Maxcompute训练离线模型,并通过Flink数据调整模型的参数。基于用户的实时轨迹数据圈选出符合条件的用户并推送服务,进一步精细化运营。
使用实践
一个典型的实时任务处理流程如下图所示:
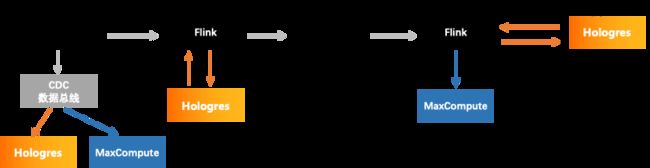
- ODS层数据通过CDC数据总线导入MaxCompute, 提供离线计算源数据。 同时也会将数据写入到Hologres,用于做数据验证。 在Hologres中,维表存储全量数据。而其他类型的ODS数据表一般存储时间>离线的计算周期即可,如离线T+1,则存储2天,无相应的离线计算任务根据验证数据周期而定。
- Flink任务读取ODS层数据作为输入,与存储在Hologres中的维表做关联,计算的结果存储到DWD/DWS层的Kafka Topic中,同时将结果写入到Hologres用于数据验证,数据存储时间与ODS层相同
- Flink任务读取DWD/DWS层数据,与存储在Hologres中的维表做关联, 将结算的结果存储到Hologres。根据应用需要,如果是Lambda架构,存储时间>离线的计算周期即可,如离线T+1,则存储2天,如果是Kappa架构,保留全部数据, 同时将结果数据写入离线数仓用于离线分析用(可选)。
下面具体介绍在每一步处理流程中的使用实践与经验优化,以帮助达到更好的效果。
数据验证
由于实时处理源数据和结果都是动态的,数据验证无法在任务中进行。可以在Hologres中,对实时数仓的各层落仓结果进行验证。由于实时处理和时间相关,每一层次的数据都需要带上一个处理时间戳(Process Time)。在Lambda架构中,将实时结果和离线结果进行比对,假设离线处理周期为T+1, 则实时处理取时间戳与昨天的数据进行比对,计算出准确率。如果是Kappa架构,需要进行逻辑验证,并与业务人员处理的结果数据进行比对。
全量数据初始化
Kafka Topic一般存储几天内的数据,不能提供全量数据,所以需要从离线数仓进行全量数据初始化,将维表、ADS层结果等导入Hologres。
Hologres维表的Lookup和性能优化
1)Lookup
在Flink计算任务中,流表和Hologres的维度数据表Join,就是Lookup。Lookup需要解决两个问题:
- 维表索引:实际处理过程是每条流表的数据,使用Join 条件的列去维表中查询,将结果返回。Hologres的维表的索引需要和Flink SQL的Join key一致。
- 维表的延迟:由于维表的数据导入是另外的任务(CDC任务或者Flink任务),就会出现数据不同步的情况,流表数据已到,而关联的维度数据没有入库。
对于问题1, 在创建Hologres的维度表时,需要根据Flink SQL的需要去设置表的各类索引,尤其是Distribution key和Clustering key,使之与Join的关联条件列一致,有关Hologres维表的索引会在后面小节提到。
对于问题2,维表和流表Join中,处理两者数据不同步的问题,通过设置窗口可以解决大部分问题,但是因为watermark触发窗口执行,需要兼顾维表数据延迟较多的情况,因而watermark duration设置较高,从而导致了数据处理任务的Latency很高,有时不符合快速响应的业务要求,这时可以采用联合Join,,将双流Join和Lookup结合起来。
维表数据包括两部分: 1. Hologres维表,查询全量数据. 2. 从维表对应的Kafka Topic创建的流表,查询最新的数据。Join时,先取维表对应的流表数据,如果不存在取Hologres维表的数据。
以下是一个例子,t_student(学员表)的流表和t_account(用户表) Join获取学员的user id
combined join
//stream table:stream_uc_account
val streamUcAccount: String =
s"""
CREATE TABLE `stream_t_account` (
`user_id` VARCHAR
,`mobile` VARCHAR
.......(omitted)
,WATERMARK FOR event_time AS event_time - INTERVAL '20' SECOND
) WITH (
'connector' = 'kafka'
.......(omitted)
)
""".stripMargin
//dim table:t_account
val odsUcAccount: String =
s"""
CREATE TABLE `t_account` WITH (
'connector' = 'jdbc',
.......(omitted)
) LIKE stream_t_account (excluding ALL)
""".stripMargin
//query sql: combined join
val querySql:String =
s"""
select
coalesce(stm_acc.user_id,acc.user_id) as user_id
from t_student stu
LEFT JOIN stm_acc
ON stu.stu_id = stm_acc.student_id
AND stu.modified_time
BETWEEN stm_acc.modified_time - INTERVAL '5' MINUTE
AND stm_acc.modified_time + INTERVAL '5' SECOND
LEFT JOIN uc_account FOR SYSTEM_TIME AS OF stu.process_time AS acc
ON stu.stu_id = acc.student_id
2)维表性能的优化
Flink SQL在Lookup时,流表每一条数据到来,会对Join的维表执行一次点查,Join的条件就是查询条件,例如对于流表stm_A和维表dim_B,Join条件为stm_A.id = dim.B.id
当 id=id1的stm_A数据到来时,会产生一条查询: select from dim_B where id=id1,由于维表查询的频率非常高,所以Join的维表列应该有索引。
Hologres索引包括: distribution key,clustering key,bitmap key,segment key(event timestamp) , 有关索引,可以参考 holo表的创建和索引
注意:维表推荐用Hologres行存表,但是在实际情况中,因为维表还用于adhoc一类的分析查询业务,所以本实践中大部分维表是列存表,以下实践结论是基于列存表和查询情况设定的,仅供参考,请根据业务情况合理设置。
实践结论1:维表的Join列设置成distribution key
由于当前使用列存作为维度表,维表的列数会影响查询性能,对于同一个维表,8个列和16个列的性能相差50%以上,建议join用到的列都设置成distribution key,不能多也不能少。如果使用行存表,没有这个限制。
实践结论2:尽可能减少维表的属性列
在应用中,维表可能有多个维度列会被用于Join,例如表T1,有两个维度列F1、F2分别用做和流表A,B的Join条件。根据F1和F2之间的关系,如果F1…F2→1…n,就在F1上创建distribution key, 反过来则在F2上创建,即在粒度较大的维度列上创建distribution key。
实践结论3: 一个维度表有多个维度列并且是Hierarchy时,在粒度较大的列上创建distribution key,并用在Join条件中
如果 F1…F2是多对多的关系,说明一个维表有两个交错的维度,而不是层次维度(hierarchy)上,需要进行拆分。
查询时,不管Lookup是否必须用到distribution key索引列,都要把distribution key索引放在Join条件里
示例: 维表t1有两个维度列:stu_code和roster_code,distribution key加在stu_code上
流表stm_t2需要 Lookup 维表t1,关联条件是两个表的roster_code相同
select <field list> from FROM stm_t2 stm JOIN t1 FOR SYSTEM_TIME AS OF stm.process_time AS dim ON stm.stu_code = dim.stu_code and stm.roster_code = dim.roster_code
业务价值
经过半年的实时数仓建设,并在集团内广泛使用。为业务的带来的价值如下:
- 为运营人员提供了1分钟级/秒级的实时看板服务和实时报表,业务人员可以及时了解到用户的反馈和业务的进程,从而调整运营策略,提高运营效率。
- 为C端应用提供了秒级的实时用户画像服务和用户圈选服务,从而可以让推荐系统及时根据用户反馈调整推荐产品列表,提高用户体验
- 开发效率大为提高,开发人员从之前的架构迁移到Hologres+Flink SQL上后,开发效率提高了1-2倍,学习的梯度也降低了很多。
- 运维成本下降,之前需要维护MySQL, MongoDB等异构系统,而Hologres是云原生服务,无需维护一个运维团队。
作者:陈毓林, 新东方互联网技术中心大数据工程师。在新东方从事多年大数据架构研发,数据集成平台开发,以及业务数据分析等,主要技术领域包括基于flink的实时计算和优化,kafka相关的数据交换和集成等阿里云的云原生技术。