垃圾回收器之 G1 垃圾回收器
4.4 G1
定义:Garbage First
- 2004论文发布
- 2009 JDK 6u14 体验
- 2012 JDK 7u4 官方支持
- 2019 JDK9 默认 (废弃了之前的 CMS 垃圾回收器)
G1取代了之前的CMS垃圾回收器
适用场景
-
同时注重吞吐量(Throughput)和低延迟(Low latency),默认的暂停目标是 200ms
G1(读作 Garbage One)它是同时会注重吞吐量和低延迟,它的内部也是基于这种并发的,它也是一种 属于并发的垃圾回收器,跟我们之前提到的 CMS 在某些目标上是一致的,它追求的是低延迟,可以在用户 线程工作的同时我的垃圾回收线程也并发的去执行,另外它也借鉴了之前的 Parallel 那种注重吞吐量的 垃圾回收器的一些思想,它可以进行一个调整,你可以设置一个目标,比如说它默认的一个暂停目标就是通过 -XX:MaxGCPauseMillis=time 这样一个参数来设置一个暂停目标。默认是200ms,从这个设置的暂停目标值来看,它确实追求的是 一种低延迟,当然如果吞吐量对你的应用程序更为重要,你可以把这个暂停目标呢给它提高一些,就是 提升你的吞吐量。这是第一个应用场景。 -
超大堆内存,会将堆划分为多个大小相等的 Region
那第二个呢就是,它呢适合那种超大的堆内存,现在随着硬件的不断发展,内存也是越来越大,尤其是 服务器内存可以使用的内存量越来越大,有一篇评测,G1 跟 CMS 都属于这种并发的垃圾回收器,在 堆内存较小的这种场景下,它俩其实速度上或者说暂停时间上其实是不相上下的,但是如果随着堆内存 的容量越来越大,那么 G1 它的优势就特别明显了,就比 CMS 暂停时间更领先,那他的这个对超大 堆内存管理的思想就是把这个堆划分成了多个大小相等的 Region(区域),把整个堆内存划分成大小 相等的区域,每个区域都可以独立的作为伊甸园、幸存区还有老年代,有一个相关的参数叫 -XX:G1HeapRegionSize=size ,就是设置它这个区域的大小,当然设置这个区域必须设成1 / 2 / 4 / 8 / 16 这样的大小,其实从这 可以想象到,如果堆内存过大,那肯定是回收速度越来越慢,因为那要涉及到对象的复制包括标记,内存大确 实会对这两项速度都会造成影响,而把它分成小的区域来进行管理,化整为零,那么这样呢就可以进行一些优化, 加快它的标记包括拷贝的速度。 -
整体上是标记+整理算法,两个区域之间是复制算法
G1在整体上它使用的是标记整理算法,所以它可以避免之前 CMS 垃圾回收器的那种标记清除算法产生的内存碎片 问题,但是它两个区域之间,两个 Region 之间用的是复制算法。
G1它在JDK1~8还不是默认的,所以你需要用一个开关 -XX:UseG1GC 这个开关把它启用,如果是用了JDK9以后的版本,它已经是默认的了,这个开关就不用显式的启用了。
相关JVM参数:
-
-XX:UseG1GC
G1它在JDK1~8还不是默认的,用 -XX:UseG1GC 这个开关把它启用,如果是用了JDK9以后的版本, 它已经是默认的了,这个开关就不用显式的启用了。 -
-XX:G1HeapRegionSize=size
设置区域的大小,当然设置这个区域必须设成1 / 2 / 4 / 8 / 16 这样的大小 -
-XX:MaxGCPauseMillis=time
G1也借鉴了之前的 Parallel 那种注重吞吐量的垃圾回收器的一些思想,它可以 进行一个调整,你可以设置一个目标,比如说它默认的一个暂停目标就是通过 -XX:MaxGCPauseMillis=time 这样一个参数来设置一个暂停目标。默认是200ms。
1)G1垃圾回收阶段
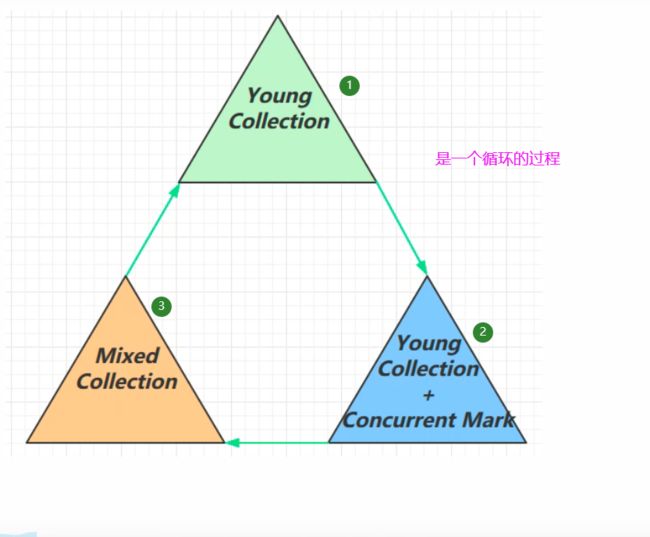
网上对G1的回收阶段有不同的说法,参考Oracle JVM工程师的一个说法:
他把整个 G1 的垃圾回收阶段分成了这么三个,第一个叫 Young Collection,
就是对新生代的垃圾收集,第二个阶段呢叫 Young Collection + Concurrent Mark,
就是新生代的垃圾收集同时呢会执行一些并发的标记,这是第二个阶段,第三个阶段呢
它叫 Mixed Collection 混合收集,那这三个阶段呢它是一个循环的过程,刚开始是这个
新生代的垃圾收集,经过一段时间,当老年代的内存超过一个阈值了,那么它会在新生代垃圾
收集的同时呢进行并发的标记,等这个阶段完成了以后,它会进行一个混合收集,混合收集
它就是会对新生代、幸存区还有老年代都来进行一个规模较大的一次收集,等内存释放掉了,
混合收集结束,这时候伊甸园的内存都被释放掉,它会再次进入新生代的一个垃圾收集过程,
这是一个循环的过程,那我们就来详细看一下每个阶段它的工作流程,那我们先来看看这个
新生代的收集。
2)Young Collection
G1 垃圾回收的第一个阶段
- 会 STW


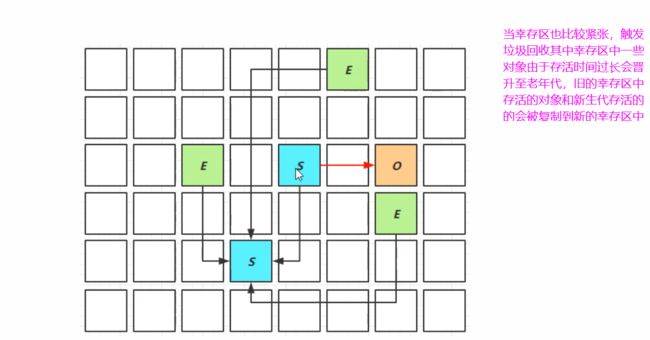
新生代呢它的一个内存布局如图,实际上我们之前提到过对于 G1 这个垃圾回收器,它就把整个堆内存
划分成了大小相等的一个个的区域,每个区域都可以独立作为伊甸园、幸存区、和老年代,那刚开始呢
这个区域里面都是白色的,就是表示它是空闲的区域,当然我们新创建了一些对象,类加载时创建的一些
对象,刚开始会分配到伊甸园区域里,这个 E 呢,绿色的 E,就代表伊甸园的区域,当这个伊甸园区域
它逐渐被占满(也可以设置伊甸园它的总的区域的大小),当这个区域逐渐被占满,就会触发一次这个叫做
Young Collection 新生代的垃圾回收,新生代的垃圾回收跟之前我们学的其他垃圾回收器一样,都会触发
一个 Stop The World,当然这个时间呢相对是比较短的,我们看一下第2张图,新生代的垃圾回收就会
把这个幸存的对象给它以复制的算法给它放入幸存区,这是一段时间工作以后新生代内存紧张了就会执行
垃圾回收操作把幸存对象给它复制进幸存区。那再工作一段时间当我的幸存区的这个对象也比较多了,并且
有的时候这个幸存区的对象存活年龄超过一定时间(这跟以前都一样),这个时候又会触发新生代的垃圾回收,
幸存区的这个对象呢,有一部分会晋升到这个老年代,当然你还不够年龄的它会再次拷贝另一个幸存区空间去,
新生代的一些幸存对象也会复制到这个新的幸存区去。
3)Young Collection + CM
G1 垃圾回收的第二个阶段
-
在 Young GC 时会进行 GC Root 的初始标记
-
在老年代占用堆内存达到阈值时,进行并发标记(不会 STW),有下面的JVM参数决定阈值
-XX:InitiatingHeapOccupancyPercent=percent

下面呢我们来学习 G1 垃圾回收的第二个阶段,它叫做新生代的垃圾回收和并发标记阶段,这里的 CM 就是指
Concurrent Mark,就是并发标记的意思。我们进行垃圾回收的过程中要对这些对象进行初始标记和并发标记,
初始标记呢就是说我要找到那些根对象,标记那些根对象,而并发标记呢是再从根对象出发,去顺着它的引用链
去标记其它的对象,那么这个初始标记呢它是在 Young GC 是就发生了,Young GC 世界暂停的时候它就对这
些根对象会做一个初始标记,所以初始标记不会占用我们并发标记的时间,它仅仅发生在新生代的垃圾回收时,
那么什么时候会进行并发标记呢,它是等老年代占用的堆空间比例达到一定的阈值时,这时候会发生并发标记,
并发标记跟我们以前 CMS 的并发标记类似,它是并发执行的,在标记的同时呢,不会影响到用户的工作线程,
也就是不会 STW,那这个阈值可以通过JVM的参数来进行一个控制,就是这样一个参数
-XX:InitiatingHeapOccupancyPercent=percent(默认45%)
,它的默认值是45%,就是整个老年代占用到整个堆空间的大约45%时,它就会进行这个并发标记了。
4)Mixed Collection
G1 垃圾回收的第三个阶段
会对 E(伊甸园)、S(幸存区)、O(老年代) 进行全面垃圾回收
- 最终标记(Remark)会 STW
- 拷贝存活(Evacuation)会 STW
-XX:MaxGCPauseMillis=ms

下面呢我们来看 G1 垃圾回收时的第三个阶段,叫做 Mixed Collection 混合收集,在混合收集阶段呢,它会对
伊甸园、幸存区、老年代这三个区域进行一个全面的垃圾回收,我们可以参考图片来更好的理解,E 也就是伊甸园区,
它的幸存对象会被复制算法复制到幸存区中去,另一些幸存区中的幸存对象不够年龄的也会复制到这个幸存区,当然有
一些符合晋升条件的对象,会晋升到老年代的区域去,这些都是属于新生代的回收,当然这是发生在 Mixed Collection
混合收集阶段的,那么还有一部分老年代的区域它里面也经过了之前的并发标记阶段发现里面有些对象已经没用了,但是这个
时候注意老年代也是采用了复制算法从旧的老年代区域把幸存对象复制到新的老年代的区域。那为什么没有把所有老年代幸存
的对象都复制到新的老年代区域呢,是因为这个时候 G1 垃圾回收器它会根据你的最大暂停时间去有选择的进行一个回收,
怎么理解呢,因为有的时候我们堆内存的空间太大了,这时候老年代的垃圾回收它可能时间比较长,因为是复制算法嘛,
大量的对象要从一个区域复制到另外一个区域,这个时间较长就达不到我们之前设置的这个 MaxGCPauseMillis 这个最大暂停
时间的目标了,那为了要达到这个目标,那么 G1 呢它就会从这些老年代里挑出那些回收价值最高的那几个区域,也就是它认为
这几个区域如果回收了我能释放的空间释放的比较多,那它就只挑其中一部分区域来进行一个垃圾回收,这样的话,复制的区域少了,
那么自然这个就可以达到我们暂停时间的目标了,需要的垃圾回收时间就相对的变短了,当然如果是这个要复制的对象没那么多,
我们的暂停时间目标也可以达到,那它就会把所有的老年代区域都进行一个复制,复制一方面是为了保留哪些存活对象,另一方面是
为了整理内存,减少空间碎片,所以这是我们这个叫混合收集它的一个工作方式。
解释一下为什么官方把它叫做 Garbage First,它是优先要回收那些垃圾最多的区域,在混合收集的阶段对老年代的这些区域来讲,
它要优先收集那些垃圾最多的区域,主要的目的就是为了达到我们暂停时间短的目标,最后要注意一点,就是不管在我们混合收集的
各个阶段,它有最终标记还有拷贝存活这两个阶段都会 STW,最终标记这个阶段呢主要就是为了在我之前并发标记的过程中可能会漏掉
一些对象,为什么这么说呢,你并发标记的同时其他的用户线程也在工作,可能会产生一些新的垃圾改变一些对象的引用,这样呢
都会对我并发标记的结果产生影响,所以呢需要在混合收集的阶段先 STW,然后去执行一个最终标记,当然最终标记完成了我们就把
这个存活的对象进行一个拷贝,当然这个拷贝的过程,对老年代的拷贝来讲它并不是所有的老年代都会发生拷贝动作,它只会回收那些
垃圾最多的老年代区域。
5)Full GC
- SerialGC
- 新生代内存不足发生的垃圾收集 - Minor GC
- 老年代内存不足发生的垃圾收集 - Full GC
- ParallelGC
- 新生代内存不足发生的垃圾收集 - Minor GC
- 老年代内存不足发生的垃圾收集 - Full GC
- CMS
- 新生代内存不足发生的垃圾收集 - Minor GC
- 老年代内存不足
- G1
- 新生代内存不足发生的垃圾收集 - Minor GC
- 老年代内存不足
我们对以前提到的 Minor GC 跟 Full GC 的概念在这里再进行一个辨析,到目前为止,学过了
好几款垃圾回收器了,有串行的、并行的,还有 CMS 跟 G1 都称之为并发的垃圾回收器。它们有
一些共同特点,它们在新生代内存不足时,触发的垃圾收集我们都可以称之为叫 Minor GC。但是
串行的和并行的这两款垃圾收集器,它们由于老年代内存不足触发的垃圾收集我们直接就可以称之为
叫 Full GC了。但是对于 CMS 跟 G1 它俩稍微有些不一样,它们的老年代内存不足触发的垃圾收
集还要分两种情况。以 G1 为例来进行说明,G1 垃圾收集器老年代内存不足有一个阈值,当你的老
年代内存跟整个堆内存内存占比达到45%(默认值)以上的时候,它就会触发一个并发标记的阶段,以
及后续混合收集的阶段,这两个阶段工作的过程中,如果你的回收速度是高于新的用户线程产生的垃圾
的速度的时候,也就是我的回收速度比你新产生的垃圾快,来得及打扫,这个时候还不叫 Full GC,这
个时候还是处于并发垃圾收集的阶段,虽然重新标记和数据拷贝的过程还会有暂停,但是这个暂停时间还
是相对很短的,这还称不上 Full GC,那 G1在什么时候才会发生 Full GC呢,就是当你的垃圾回收的
速度跟不上垃圾产生的速度了,新产生的垃圾比你的回收速度快了,这个时候并发收集就失败了,就跟以前
的 CMS 类似,这时候它就会退化一个串行的收集,串行收集这时候就会叫Full GC了,特别的慢,当然也会
更长时间的 STW 导致响应时间变长。 CMS 当然也是一样,它是并发失败了以后才叫 Full GC,如果并发
没有失败这时候还处于并发收集阶段,它也不会出现 Full GC,那么判断的一个依据就是回头可以看一下
GC 日志GC日志里打印出 Full GC的字样了,才叫做 Full GC,我们的 CMS 也好,G1 也好,它们如果是
工作在并发收集的阶段回收速度高于你的垃圾产生速度,它后台的回收日志里是不会有 Full GC的字样的。
6)Young Collection 跨代引用
- 新生代回收的跨代引用(老年代引用新生代)问题
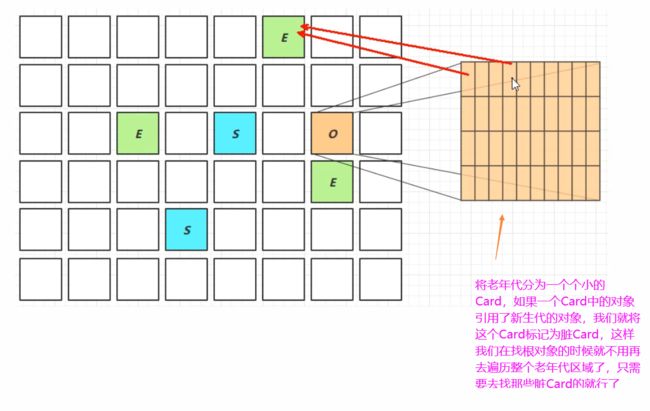
下面呢我们来看一些细节问题,先来学习一下新生代垃圾回收的跨代引用问题,我们回忆一下
新生代垃圾回收的过程,首先也是要找到根对象,然后根对象呢,可达性分析,再找到存活
对象,存活对象进行一个复制,复制到幸存区,这里就有一个问题,那我们要找这种新生代对象
它的根对象,通过根对象要进行一个查找,那首先我们得找根对象,根对象呢有一部分是来自于
老年代的,那老年代呢通常它的存活对象都非常的多,如果我们去遍历整个老年代,去找这个根
对象,显然呢效率是非常低的,因此呢采用的是一种卡表的技术,把这个老年代的区域再进行一个
细分,分成了一个个的小的Card,每个小的Card呢大概是512k,那如果这个老年代其中有一个对象
它是引用了这个新生代的对象那么这个对应的Card我们就把它标记为脏Card,这样的话好处就是
我将来就不用去找整个老年代了,我在做 GC Root遍历的时候,不用去找整个老年代了,而是只
需要去关注那些脏Card区域就可以了,这样其实就是减少我的搜索范围,提高扫描根对象的效率。
- 卡表与 Remembered Set
- 在引用变更时通过 post - write barrier + dirty card queue
- concurrent refinement threads 更新 Remembered Set
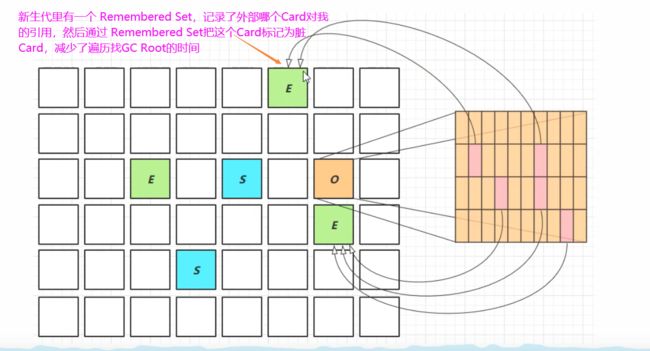
那我们来看第二张图,在第二张里面粉红色的区域就是脏Card区域,它们其中都有对象引用了另外Region,也就是新生代
Region中的对象。新生代这边会有 Remembered Set,它会记录从外部对我的一些引用,也就是记录都有哪些脏Card,
将来去对新生代去做垃圾回收的时候,我就可以先通过 Remembered Set 直到它对应的那些脏Card,然后再到这些脏Card
去遍历 GC Root,这样呢就减少了GC Root的遍历时间。那这里就有一个问题啊,我们需要标记这些脏Card,它是通过一个叫
post - write barrier 这样一个写屏障在每次对象的引用发生变更时他都要去更新这个脏Card,就把 Crad Table中的
Card 标记为脏Card,那么这个是一个异步操作,它不会立刻去完成脏Card的更新,那么它会把这个更新的指令放在脏Card的
队列之中,将来呢由一个线程去完成脏Card的更新操作,这是我们在新生代垃圾回收时跨代引用时就利用了这种Card Table
和 Remembered Set 的技术来加速了新生代的垃圾回收。
7)Remark
- pre-write barrier + satb_mark_queue

# 关于重标记相关的知识
之前我们在学习 CMS 跟 G1 这些并发垃圾回收器时,都提到了它们都有这么两个阶段,一个阶段呢叫并发标记阶段,
另外一个呢叫重新标记阶段,也就是我们这里提到的 Remark 这个阶段,对于 Remark 阶段呢,我们之前没有详细地
说明,现在我们来学习一下 Remark 阶段相关的知识,我们看上面的图片,这张图片表示的是并发标记阶段时对象的一个
处理状态,其中图里这种黑色的表示已经处理完成的,并且它们都是有引用在引用它们,所以黑色的将来是表示在结束时,
会被保留下来,会存活下来的对象,灰色的呢是正在处理当中的,而白色的是尚未处理的,当然,上图是一个中间状态。
如果最后都处理完成了,那上图灰色的因为有强引用在引用着它,所以它最终会变成黑色,也就是它还是会存活,灰色
右边的白色因为也有引用在引用它,因此它也会存活,最后也会变成黑色存活下来。至于上面的白色因为没有人引用它了,
它最终还是白色,它就会被当成垃圾回收。也就是等我们垃圾回收结束时会根据对象的黑白这个状态来区分它到底是应该
存活还是应该当成垃圾。
接下来我们来看一个例子:




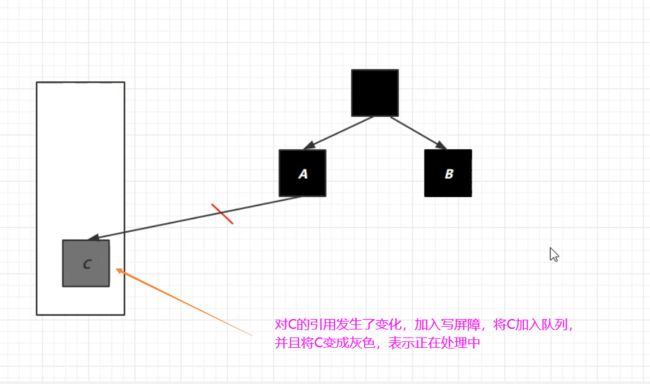
这张图呢还是刚才那三种状态,分别是黑色:已经处理完,灰色:尚在处理中,白色:还没有处理到它,现在我们
思考一个问题,比如说我处理到了这个灰色的这个B对象,然后因为有强引用引用着它,所以把它变成黑色,将来会
存活,但是等我处理到C的时候,注意这是一个并发标记,并发标记就意味着它同时呢会有用户的线程对这个对象的
引用做修改,比如说它把这个引用给断掉,那处理B的时候接下来该处理C了,它发现C跟B之间已经没有联系了,所以
处理到C的时候它就会进行一个标记,说你C将来是个白色的,那等整个并发标记结束以后呢,这个C对象由于它仍然是
白色,最后就会被当成垃圾回收掉,这是一种情况。但是我们可以考虑另外一种情况,在C被处理完了以后,并发标记
可能还没有结束,这时候用户线程又改变了C的引用地址,比如说呢它又把C对象当成是A对象的一个属性做了一次复制
操作,C的引用又发生改变了,这时候问题又来了,因为C之前已经处理过了,他认为已经是白色的,那A呢又是黑色的,
以后不会处理它了,因为认为它处理过了嘛,所以等到整个并发标记结束以后,C就被漏了,我们仍然认为C是白色的,
是垃圾,就要把它回收掉,但这样就不对了,为什么呢,这时候有一个强引用引用着它,再把它回收掉就不合理了,
所以我们要对对象的引用做进一步地检查,就是我们刚刚提到的Remark重新标记阶段,就是为了防止这样的现象发生的。
具体的做法是这样的,当对象它的引用发生改变时,JVM就会给它加入一个写屏障,什么叫写屏障呢,只要你的对象引用
发生了改变,这个写屏障的代码就会被执行。比如说我们刚才把C的引用给了A的其中一个属性,这说明C的引用发生了变
化,既然发生了变化,那么写屏障的指令就会被执行。写屏障指令干了些什么事呢,它就会把这个C加入到一个队列当中,
并且把C编程灰色,表示它还没有处理完,等到整个并发标记结束了,接下来进入重新标记阶段,重新标记呢会 STW,
让其它的用户线程都暂停,这个时候重新标记的线程就会把队列中的对象一个一个取出来,再做一次检查,发现你是灰色
的,那还要对它进行进一步的判断、处理,结果又发现有强引用引用着它,因此还应该把它变成黑色,这样的话就不会让
C对象被误当成垃圾回收掉了。以上就是在Remark阶段做的事情。它是在pre-write barrier写屏障技术在对象引用改
变前把这个对象加入到了一个队列,并且表示它是未被处理的,这个队列的名称叫 satb_mark_queue,将来的 Remark
阶段就可以配合这个队列来对这些对象进行进一步的判断,以上就是重标记阶段的一些相关知识。
8)JDK 8u20 字符串去重
- 优点:节省大量内存
- 缺点:略微多占用了 cpu 时间,新生代回收时间略微增加
-XX:+UseStringDeduplication
String s1 = new String("hello"); //char[]{'h', 'e', 'l', 'l', 'o'}
String s2 = new String("hello"); //char[]{'h', 'e', 'l', 'l', 'o'}
- 将所有新分配的字符串放入一个队列
- 当新生代回收时,G1 并发检查是否有字符串重复
- 如果它们值一样,让它们引用同一个 char[]
- 注意,与String.intern() 不一样
- String.intern() 关注的是字符串对象
- 而字符串去重关注的是 char[]
- 在 JVM内部,(String.intern()和G1的去重)使用了不同的字符串表
这里介绍一些 G1 垃圾回收器它的一些优化,它的优化是在持续进行中,这里只介绍一些从 JDK8 开始的优化到
JDK 9,至于更新的优化呢,这里没有赘述。
在 JDk8u 20 这个版本中,它实现了一个字符串去重功能,我们来思考这么一个问题:
String s1 = new String("hello"); //char[]{'h', 'e', 'l', 'l', 'o'}
String s2 = new String("hello"); //char[]{'h', 'e', 'l', 'l', 'o'}
看上面两行代码,它都是用new关键字创建了两个值相同的String对象,在 JDK8 中字符串它的底层是使用了
char[]数组来存储每一个字符,比如说 "hello" 这个字符串它的底层就是char[]数组,里面有
'h', 'e', 'l', 'l', 'o' 这几个字符,现在new了两个字符串,但实际上这个char[]数组的
也是有两个,显然如果我们有大量创建新字符串的动作,这个字符串对内存的占用是相当可观的,那能
想到的一种办法我们可以用之前介绍过的 intern() 方法来实现一个去重,但是除此以外 G1 这个垃圾
回收器它又引出了一种新的办法,它会将所有新分配的字符串放入一个队列,然后在新生代垃圾回收时,
它就会并发的去检查这个队列中新创建的字符串是不是跟已有的字符串有重复,如果它们的值是一样的,
那会让它们引用一个相同的char[],意思就是s1字符串原本引用的是后边的char[]数组,在垃圾回收
并发检查的阶段,它就会让s1引用下面的char[]数组,让s2也引用下面的char[]数组,这样的话虽然
是两个字符串对象,但是它底层的char[]数组是同一个。原理就是让两个字符串对象引用同一个char[]
数组,但是要注意它和String.intern() 是不太一样的,String.intern() 关注的是字符串对象,
它是让字符串对象本身不重复,它使用了一个StringTable来去重,但是G1这种字符串去重技术,关注
的是char[]数组,它俩在JVM内部使用的是不同的字符串表。当然要开启这个字符串去重功能需要需要
打开一个开关:-XX:+UseStringDeduplication,这个开关是默认打开的,优点是会节省大量的内存,
缺点呢它会略微多占用一些cpu的时间,因为它是在新生代发生的去重检查,所以它会让新生代的垃圾回收
时间略微的增加,但是在总的性能上来看,它带来的收益还是远远高于它占用的cpu时间和新生代的垃圾回收
的时间的
9)JDK 8u40 并发标记类卸载
所有对象都经过并发标记后,就能知道哪些类不再被使用,当一个类加载器的所有类都不再使用,则卸载它所加载的所有类
-XX:+ClassUnloadingWithConcurrentMark 默认启用
这里介绍在 JDK 8u40 这个更新中对 G1 垃圾回收器它的一个功能增强, 这个功能增强呢叫做
并发标记时的类卸载,在我们之前的 JDK 版本中,这个类一般是没办法卸载的,只要加载了以后,
它就会一直占用着内存,其实有的时候很多自定义的类加载器创建和加载类使用过一段时间以后其实
就没人再用了,这个时候如果还让他们占用着内存,其实对垃圾回收也是不利的,从这个 8u40 这个
版本开始,G1 它就会做这样一件事:它会在所有对象经过并发标记阶段以后,它就能知道哪些类不再
被使用了,这时候它就会尝试去执行一个类卸载的操作,当然这个卸载条件比较苛刻一些,首先这个类
它们的实例都被回收掉,第二就是这个类所在的类加载器其中的所有类都不再使用了,这时候它就会把
这个类加载器里面所有的类全部卸载掉。虽然这个条件苛刻了一些,但是如果是对一些框架程序,这些
框架程序很多都使用了自定义的类加载器,那么这种情况还是会发生的,就是一个类加载中所有类还有
所有类它们的实例全部没人用了,那它就可以把它全部卸载掉。当然我们 JDK 的这些类加载器它们加
载类是一般不会卸载的,因为 JDK 的类加载器就是启动类加载器还有扩展类加载器还有应用程序类加
载器,它们都是始终会存在的,不会类卸载,只是对于我们自定义的类加载器才会这种类卸载的功能和
需求,通过 -XX:+ClassUnloadingWithConcurrentMark 这个参数就可以让这个卸载功能得到
一个启用,这是默认启用的。
10)JDK 8u60 回收巨型对象
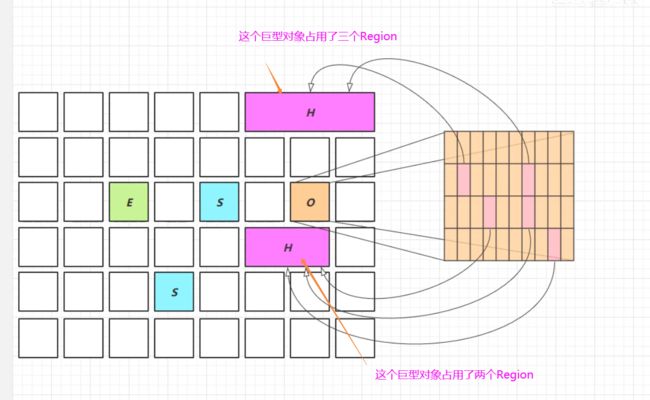

- 一个对象大于Region的一半时,称之为巨型对象
- G1 不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1 会跟踪老年代所有 incoming 引用,这样老年代 incoming 引用为 0 的巨型对象就可以在新生代垃圾回收时处理掉
在 JDK 8u60 这个版本中,对 G1 的功能进行了一项增强,这个增强呢就是可以让它回收巨型对象,在 G1
它的区域划分中一共有四种区域,伊甸园区、幸存区、老年代区,其实还有一种就是这种巨型对象区域,这个
巨型对象呢它的一个条件默认的是当一个对象它的大小大于整个Region的一半的时候,我们就可以把它称之为
巨型对象,那这个巨型对象呢它在内存中的分布,它也许会占到更多的区域,比如图中下面的巨型对象占用了两
个Region,上面的巨型对象占用了三个Region,这称之为巨型对象。那巨型对象呢它的的垃圾回收呢其实要跟
其他的普通对象的垃圾回收要进行一个区分,因为巨型对象它要进行拷贝这个代价是比较高的,所以 G1 不会对巨
型对象进行拷贝,并且回收时也会优先回收这个巨型对象,他对巨型对象的回收有一些优化的处理。G1 会跟踪从老
年代到巨型对象中的所有 incoming 引用,当老年代的 incoming 引用为0时,怎么理解呢,老年代它有 Card Table,
只要老年代中的 Card Table 中的某个卡引用了这个巨型对象,那这个 Card 也会标记为脏的,显然图片中上面的
巨型对象从老年代出发对它的引用是两个,下面的巨型对象从老年代的脏Card中出发,它的引用有三个,当某个巨型对象
从老年代的引用为0时,没有人再从老年代引用它了,那它就可以在新生代的垃圾回收时被回收掉了。
总的意思就是希望巨型对象越早回收越好,最好就在新生代的垃圾回收时就把它处理掉。
`
11)JDK 9 并发标记起始时间的调整
- 并发标记必须在堆内存占满前完成,否则退化为 Full GC
- JDK 9 之前需要使用 -XX:InitiatingHeapOccupancyPercent
- JDK 9 可以动态调整
- -XX:InitiatingHeapOccupancyPercent 用来设置初始值
- 进行数据采样并动态调整
- 总会添加一个安全的空挡空间
JDK 9 中呢对 G1 这个垃圾回收器又有很多很多的功能增强,其中一项比较重要的是它并发标记时间的一个调整,G1
它也面临一个 Full GC 的问题,如果垃圾回收它的速度跟不上垃圾产生的速度,最终它也是会退化为 Full GC 的,
在现在这个 G1 的版本中,即使是 Full GC,也早已变成了多线程,但是肯定是不好嘛,Full GC 它 STW 的时间
肯定更长,所以我们还是要尽可能地避免 Full GC 的发生,那怎么去减少 Full GC 的情况呢,我们可以提前让这个
垃圾回收开始,让我们的并发标记,混合收集提前开始,这样就能够减少 Full GC 发生的几率,在 JDK 9 之前,我们
要设置 这样一个参数:-XX:InitiatingHeapOccupancyPercent,这个参数就是指老年代它的内存跟整个堆内存的
占比阈值,当你超过这个阈值的时候它这个并发的垃圾回收就开始了,这个阈值呢默认是45%,但 JDK 9 以后,发现有的
时候如果把这个阈值固定了它其实就不太好了,定的大了容易产生 Full GC,定的小了又频繁的去做并发标记和混合收集,
那怎么办呢,JDK 9 里它可以去动态地调整这个阈值,也就是我们刚刚的参数仅仅是用来设置了一个初始值,比如说我们
初始默认是45%,但是呢它后面在垃圾回收的过程中它可以对数据进行采样并且动态调整这个阈值可以把这个阈值调大调小,
总之呢它会添加一个安全的空挡空间。让这个堆的空闲空间总够的大,容纳那些浮动的垃圾,这样呢就可以尽可能的避免并
发垃圾回收退化成 Full GC 的垃圾回收了。
12)JDK 9 更高效的回收
- 250+增强
- 180+bug修复
- https://docs.oracle.com/en/java/javase/12/gctuning
JDK 9 中对 G1 垃圾回收器它的功能增强是非常多的,根据官方的宣传资料,有250项的功能增强,有
180多项的bug修复,当然最新的JDK已经发展到了JDK12,所以这期间的更多的功能增强包括bug修复肯定
也是很多的。给我们这样一个信号,G1 它是越来越成熟、越来越好,可能每一个版本的更新都会带来更好的
响应时间以及更高效智能的回收算法,也建议大家多看 Oracle 的官方文档的最新的一些说明,现在市面上
很多的文章包括一些资料它们对 G1 的介绍还是停留在比较早的版本,比较早的版本中 G1 它的性能并不是
那么突出,建议大家去阅读一下 Oracle 官方的HotSpot Virtual Machine Garbage Collection Tuning Guide
它的调优指南,这个调优指南里针对 G1 它的垃圾回收器有更官方的介绍,包括 G1 它的调优,包括 JDK 12
里面最新的 Z Garbage Collection,关于一些新的技术对于扩展知识面了解底层的技术实现是非常有帮助的。