CBMI 2022-《ALADIN》-蒸馏细粒度对齐分数以实现高效的图文匹配和检索
【写在前面】
在涉及视觉和语言的共同理解的任务中,图像-文本匹配正在发挥主导作用。此任务通常被用作预训练目标,以打造能够共同处理图像和文本的体系结构。尽管如此,它有一个直接的下游应用程序: 跨模态检索,它包括查找与给定查询文本相关的图像,反之亦然。解决此任务在跨模态搜索引擎中至关重要。许多最近的方法为image-text匹配问题提出了有效的解决方案,主要是使用最近的大型视觉语言 (VL) Transformer网络。但是,这些模型通常在计算上很昂贵,尤其是在推理时。这阻止了它们在大规模跨模态检索方案中的采用,在这种方案中,结果应几乎立即提供给用户。在本文中,作者通过提出一个对齐和蒸馏网络 (ALADIN) 来填补有效性和效率之间的差距。ALADIN首先通过在细粒度的图像和文本上对齐来产生高效的分数。然后,它通过提取从细粒度对齐中获得的相关性得分来学习共享的嵌入空间-可以在其中执行有效的kNN搜索。作者在MS-COCO上获得了显著的结果,表明本文的方法可以与最先进的VL Transformer竞争,同时速度几乎快90倍。
1. 论文和代码地址

ALADIN: Distilling Fine-grained Alignment Scores for Efficient Image-Text Matching and Retrieval
论文地址:https://arxiv.org/abs/2207.14757
代码地址:未开源
2. Motivation
随着深度学习方法的日益强大和大规模数据的可用性,多模态处理已成为最有前途的研究课题之一。特别是,大部分的重点放在图像和自然语言句子的联合处理上。通过理解文本和图像之间隐藏的语义联系,许多作品解决了具有挑战性的多模态问题,例如图像字幕或视觉问答。在这些任务中,image-text匹配具有至关重要的意义: 它包括为每个给定的 (图像,文本) 对输出相关性得分,其中如果图像与文本相关,则得分高,否则得分低。尽管此任务通常用作视觉语言预训练目标,但对于跨模态图像文本检索至关重要,它通常由两个子任务组成: 图像检索 (希望与给定文本相关的图像) 和文本检索,要求更好地描述输入图像的句子。在现代跨模态搜索引擎中,高效有效地解决这些检索任务具有重要的战略意义。
许多最先进的图像-文本匹配模型,如Oscar 或UNITER ,包括具有早期融合的大型和深度多模态视觉语言 (VL) Transformer,其计算成本很高,尤其是在推理阶段。实际上,在推理过程中,应通过多模态Transformer转发来自测试集的所有 (图像,文本) 对,以获得相关性得分。这在大型数据集中显然是不可行的,在大规模检索场景中是不可用的,因为系统延迟应该尽可能小。
为了实现这样的性能目标,文献中的许多方法都将图像和文本嵌入在一个共同的空间中,其中相似性是通过简单的点积来衡量的。这允许引入离线阶段,在该阶段中,所有数据集项都被编码和存储,在该阶段中,仅通过网络转发查询并与所有离线存储的元素进行比较。尽管这些方法非常有效,但它们通常不如使用大型VL Transformer进行早期模态融合的方法有效。
根据这些观察结果,在本文中,作者提出了一种对齐和蒸馏网络模型 (ALADIN),该模型利用大型VLTransformer获得的知识来构建有效而有效的图像文本检索模型。特别是,作者采用了后期融合方法,以便将两个视觉和文本管道保持分离,直到最终匹配阶段。第一个目标包括使用简单而有效的对齐头将图像区域与句子单词对齐。然后,通过使用学习到排名的目标从对齐头提取分数来学习常见的视觉文本嵌入空间。在这种情况下,将学习的对齐分数用作ground truth (教师) 分数。
作者表明,在广泛使用的ms-coco数据集上,对齐分数可以达到与大型联合视觉语言模型 (例如UNITER和OSCAR) 相当的结果,同时效率更高,尤其是在推理过程中。另一方面,用于学习公共空间的蒸馏分数可以击败相同数据集上以前的公共空间方法,从而为大规模检索开辟了基于度量的索引的道路。
本文的贡献如下:
1)作者使用两个预训练的VL Transformer实例作为主干来提取单独的视觉和文本特征。
2)作者采用一种简单而有效的对准方法来产生高质量的分数,而不是大型联合VL Transformer的可扩展性差的输出。
3)作者通过将问题框架为一个学习到排名的任务,并使用对齐头输出中的分数来提取最终分数,从而创建一个信息丰富的嵌入空间。
3. 方法
提出的体系结构由两个不同的阶段组成。第一阶段,称为骨干,由预训练的大型视觉语言转换器VinVL 的层组成,这是对强大的OSCAR模型的扩展 。在主干中,语言和视觉路径不会通过交叉注意机制进行交互,因此可以在推理时独立地提取两种模态中的特征。
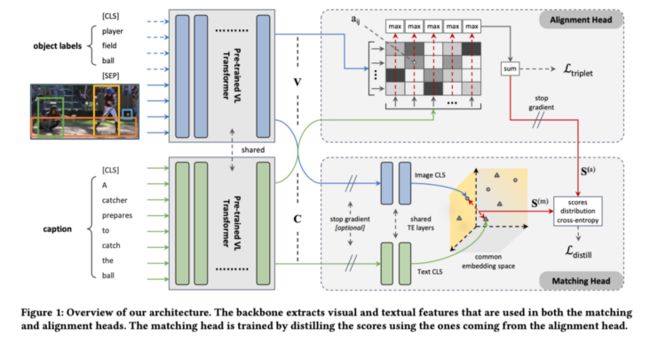
相反,第二阶段由两个单独的头组成: 对齐头和匹配头。对齐头用于预训练网络,以细粒度的方式有效地对齐视觉和文本概念,如TERAN 中所做的那样。不同地,匹配头用于构造信息交叉模态公共空间,该空间可用于有效地将图像和文本表示为固定长度向量,以用于大规模检索。使用来自对齐头的分数作为指导,提取来自匹配头的分数。总体架构如上图所示。
3.1 Vision-Language Backbone
作为特征提取的主干,作者使用VinVL中的预训练层,这是对大规模视觉语言OSCAR模型的扩展。作者的目标是为输入中的图像V和文本C获得合适的矢量表示。特别是,作者在图像文本检索任务上采用了预训练的模型。作者在输出序列的CLS token之上使用了二进制分类头,并对模型进行了训练,以预测输入图像和文本句子是否相关。
在本文的用例中,视觉和文本管道应分开,以便可以在推理时独立forward它们。因此,作者使用VinVL体系结构的两个实例,在共享权重配置中独立地转发这两个模态,如图上所示。
作者将从对象区域提取的视觉特征及其标签都用作视觉token,并且两个子序列由SEP token分隔。最后,解纠缠的VinVL架构的最后一层的输出是两个序列$V=\left\{v_{\mathrm{cls}}, \boldsymbol{v}_{1}, \boldsymbol{v}_{2}, \ldots, \boldsymbol{v}_{N}\right\}$表示图像V,$\boldsymbol{C}=\left\{\boldsymbol{c}_{\mathrm{cls}}, \boldsymbol{c}_{1}, \boldsymbol{c}_{2}, \ldots, \boldsymbol{c}_{M}\right\}$表示文本C。在两个序列中,第一个元素是CLS token,用于收集整个图像或文本的代表性信息。
3.2 Alignment Head
对齐头包括相似度矩阵,其计算视觉token与文本token之间的细粒度相关性。然后将细粒度的相似性合并以获得图像和文本之间的最终全局相关性。特别是,作者使用类似于TERAN 中使用的配方。具体来说,主干输出中的特征用于计算视觉文本token对齐矩阵 $A \in \mathbb{R}^{n \times m}$ ,构建如下:
$$ A=a_{i j}^{k l}=\operatorname{cosine}\left(v_{i}, c_{j}\right)=\frac{v_{i}^{T} c_{j}}{\left\|v_{i}\right\|\left\|c_{j}\right\|} \quad i \in g_{k}, j \in g_{l} $$
其中,$g_{k}$是来自第图像的区域特征的索引集合,而$g_{l}$是来自第个句子的单词的索引集合。此时,图像k和字幕l之间的相似度$s_{k l}$通过适当的汇集函数汇集相似度矩阵沿维度(,)来计算。
作者使用 “最大区域总和” 策略,该策略计算以下最终相似性得分:
$$ S^{(\mathrm{a})}=s_{k l}^{(\mathrm{a})}=\sum_{j \in g_{l}} \max _{i \in g_{k}} A_{i j} $$
用于计算公式中的点积相似度类似于视觉token和文本token之间的交叉注意的计算。区别归结为视觉和文本pipeline之间的交互,这种交互仅发生在整个结构的最后。这种后期的交叉关注使得序列 V和C可缓存,无需forward
每当向系统发出新的查询 (视觉或文本) 时,整个体系结构。仅涉及简单的非参数运算的的计算非常高效,可以在GPU上轻松实现以获得高推理速度。用于强制此网络为每个 (图像,文本) 对产生合适的相似性的损失函数是hinge-based triplet ranking loss:
$$ \mathcal{L}_{\text {triplet }}=\sum_{k, l} \max _{l^{\prime}}\left[\alpha+s_{k l^{\prime}}-s_{k l}\right]_{+}+\max _{k^{\prime}}\left[\alpha+s_{k^{\prime} l}-s_{k l}\right]_{+}, $$
其中$s_{k l}$是在图像和字幕之间估计的相似性,以及$[x]_{+} \equiv \max (0, x)$;值‘,’是在mini-batch中找到的图像和字幕难例的索引,是定义正负对之间应该保持的最小间隔的margin。
鉴于对齐头直接连接到主干,在此新的对准目标上对主干进行了微调。
3.3 Matching Head
匹配头部使用从主干给出的相同序列和,并使用它们来产生用于图像V的特征$\tilde{u} \in \mathbb{R}^{d}$和用于字幕C的$\tilde{\boldsymbol{c}} \in \mathbb{R}^{\boldsymbol{d}}$。这些表示被强制放置在相同的维嵌入空间中。在这个空间中,可以使用度量空间方法或倒排文件高效地计算-nerest-Neighbor搜索,以便在给定文本查询的情况下快速检索图像,反之亦然。具体地说,通过2层Transformer编码器(TE)forward 和:
$$ \bar{V}=\operatorname{TE}(V) ; \quad \bar{C}=\operatorname{TE}(C) $$
TE在两个通道之间共享权重,编码整个图像和字幕的最终向量是从TE层输出的CLS token:$\tilde{v}=\bar{V}[0]=\bar{v}_{\mathrm{cls}}$和$\tilde{\boldsymbol{c}}=\overline{\boldsymbol{C}}[0]=\overline{\boldsymbol{c}}_{\mathrm{cls}}$。最终的相关度被简单地计算为来自第个图像(M)的向量$\tilde{\boldsymbol{v}}_{k}$和来自第个句子的$\tilde{\boldsymbol{s}}_{l}$之间的余弦相似性:$S^{(\mathrm{m})}=s_{k l}^{(\mathrm{m})}=\operatorname{cosine}\left(\tilde{v}_{k}, \tilde{\boldsymbol{s}}_{l}\right)$。
原则上,可以使用hinge-based triplet ranking loss来优化公共空间。鉴于对齐头的良好有效性和效率折衷,作者提出使用先前学习的$S^{(a)}$作为老师来学习的分布$S^{(\mathrm{m})}$。
具体地说,作者把从$S^{(\mathrm{a})}$中提取$S^{(\mathrm{m})}$的分布作为一个学习排序问题。作者使用在ListNet方法中开发的数学框架,该框架对给定所有对象的分数的情况下一个对象被排在最前面的概率进行建模。与这个框架不同,这里需要针对两个不同的纠缠分布进行优化:当句子用作查询时,文本-图像相似度的分布,以及当将图像用作查询时,图像-文本相似度的分布。具体地,在给定文本查询和图像查询的情况下,图像和文本分别相对于(A)成为第一元素的概率是:
$$ P_{S^{(\mathrm{a})}}(i)=\frac{\exp \left(s_{i k}^{(\mathrm{a})}\right)}{\sum_{t=1}^{B} \exp \left(s_{t k}^{(\mathrm{a})}\right)} ; P_{S^{(\mathrm{a})}}(j)=\frac{\exp \left(s_{l j}^{(\mathrm{a})}\right)}{\sum_{t=1}^{B} \exp \left(s_{t j}^{(\mathrm{a})}\right)} $$
其中是batch大小,因为学习过程仅限于当前batch中的图像和句子。因此,在训练期间,只使用查询检索个图像,而使用查询检索个文本元素。类似地,可以在$S^{(\mathrm{m})}$上定义类似的概率:
$$ P_{S^{(\mathrm{m})}}(i)=\frac{\exp \left(\tau s_{i k}^{(\mathrm{m})}\right)}{\sum_{t=1}^{B} \exp \left(\tau s_{t k}^{(\mathrm{m})}\right)} ; P_{S^{(\mathrm{m})}}(j)=\frac{\exp \left(\tau s_{l j}^{(\mathrm{m})}\right)}{\sum_{t=1}^{B} \exp \left(\tau s_{t j}^{(\mathrm{m})}\right)} $$
其中是补偿$S^{(m)}$在[0,1]范围内的温度超参数。实验发现,=6.0时在实践中效果很好。对于图像到文本和文本到图像的情况,最终的匹配损失都可以表示为$P_{S^{(a)}}$和$P_{S^{(m)}}$概率之间的交叉熵。
$$ \mathcal{L}_{\text {distill }}=-\sum_{i=1}^{B} P_{s^{(\mathrm{a})}(i)} \log \left(P_{s^{(\mathrm{m})}}(i)\right)-\sum_{j=1}^{B} P_{s^{(\mathrm{a})}(j)} \log \left(P_{s^{(\mathrm{m})}}(j)\right) $$
需要准确且密集的教师分数才能获得对教师分布$P_{\boldsymbol{s}^{(\mathrm{a})}}(i)$和$P_{\boldsymbol{s}^{(\mathrm{a})}}(j)$的良好估计。这在一定程度上促使选择首先研究一种有效和高效的对准头部,该对准头部可以输出分数作为匹配头部的ground truth。
3.4 Training
在训练阶段,遵守以下限制:(A)只有在训练对准头时才对主干进行微调,(B)梯度不会向后流过$S^{(\mathrm{a})}$当训练匹配头时(如上图中通过停止梯度指示所示)。限制(B)是基于分数$\boldsymbol{S}^{(\mathrm{a})}$用作教师分数。因此,不应该修改主干的权重,因为假设主干已经用对齐头进行了训练。考虑到这些限制,作者分两步训练网络。首先,通过使用$\mathcal{L}_{\text {triplet }}$更新骨干权重来训练对齐头。然后,冻结了主干,并通过使用$\mathcal{L}_{\text {distill }}$更新二层Transformer编码器的权值来学习匹配头。
4.实验

上表展示了本文方法在MS-COCO 1K上的检索实验结果,在测试时,除了本文的模型之外,所有报告的模型都需要按$O\left(n^{2} r\right)$的顺序计算网络forward步骤的数量,其中是图像的数量,是与每个图像关联的句子数量。
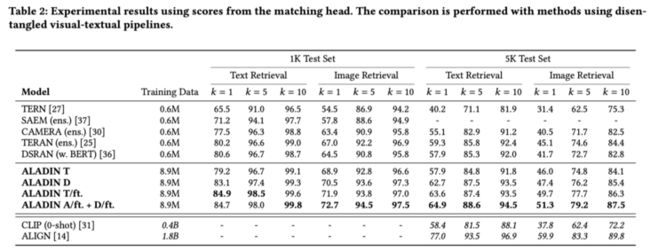
作者使用类似的方法将本文的匹配头创建的公共空间与其他解缠方法进行比较。结果如上表所示。如上所述,为了比较,作者还报告了使用hinge-based triplet loss直接训练的匹配头。而不需要从对齐头中提取分数。

为了更好地显示本文的模型在计算时间方面的优势,在图上中,作者绘制了与其他方法相比本文方法的有效性与效率的关系图。
5. 总结
本文提出了一种高效的视觉-文本跨模态检索体系结构。具体来说,作者提出了使用最先进的VL Transformer作为主干,通过独立forward视觉和文本管道来了解对齐分数。然后,使用对齐头产生的分数来学习视觉-文本公共空间,该公共空间可以容易地产生可索引的定长特征。具体地说,使用学习排序蒸馏目标来解决这个问题,该目标实验性地证明了它比hinge-based triplet ranking loss优化公共空间的有效性。在MS-COCO上进行的实验证实了该方法的有效性。结果表明,该方法弥补了效率和效率之间的差距,使该系统能够部署在大规模的跨通道检索场景中。
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

“点个在看,月薪十万!”
“学会点赞,身价千万!”
【技术交流】
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!!
请关注FightingCV公众号,并后台回复ECCV2022即可获得ECCV中稿论文汇总列表。
推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称

本文由mdnice多平台发布