数据分析---numpy补充
文章目录
-
-
- 操作文件 loadtxt
- numpy函数去重、排序
-
操作文件 loadtxt
- loadtxl读取txt文本、csv文件
loadtxt(fname,dtype=,comment=‘#’,delimit=None,converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0,encoding=‘bytes’)
fname:指定文件名称或字符串。支持压缩文件,包括gz\bz格式
dtype:数据类型。默认为float
comments:字符串或字符串组成的列表。表示注释字符集开始的标志,默认为#
dellmlter:字符串。分隔符。
converters:字典。将特定列的数据转换为字典中对应的函数的浮点数数据。例如将空值转换为0,默认为空。
skiprows:跳过特定行数据。例如跳过前一行(可能是标题或注释)。默认为 0。
usecols:元组。用来指定要读取数据的列,第一列为0。例如(1,3,5),默认为空。
unpack:布尔型。指定是否转置数组,如果为真则转置,默认为False
ndmin:整数型。指定返回的数组至少包含特定维度的数组。值域为0、1、2.默认为0
encoding:编码,确认文件是gbk还是utf-8格式
返回:从文件中读取的数组
- 读取普通文件
#读取普通文件,可以不用设置分隔符(空格 制表符)
import numpy as np
data=np.loadtxt('data.txt')
print(data,data.shape)

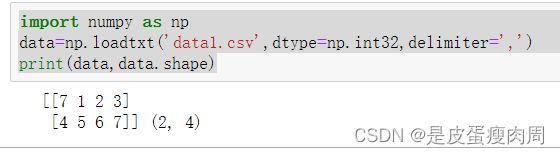
#读取csv文件,取药设置分隔符,csv默认为,号
data=np.loadtxt('csv_test.csv',dtype=np.int32,delimiter=',')
print(data,data.shape)
- 不同标识符不同信息 数据读取
user_info=np.dtype([('name','U10'),('age','i1')]
print(user_info)

#计算平均年龄
ages=data['age']
ages.mean()

- 读取指定的行、列
import numpy as np
user_info=np.dtype([('age','i1'),('heigth','i2')])
print(user_info)
data=np.loadtxt('data1.csv',dtype=user_info,delimiter=',',skiprows=1,usecols=(1,2))
print(data)
numpy函数去重、排序
- 去重

a=np.array([5,2,6,2,7,5,6,8,2,9])
print(a)
#对数字a进行去重
uq=np.unique(a)
print(uq)

#数组去重后的索引数组
u,indices=np.unique(a,return_index=True)
#打印去重后数组的索引
print(u)

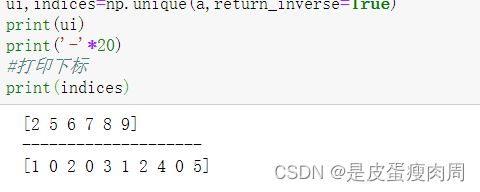
#去重数组的下标
ui,indices=np.unique(a,return_inverse=True)
print(ui)
print('-'*20)
#打印下标
print(indices)
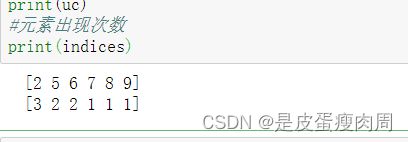
#返回去重元素的重复数量
uc,indices=np.unique(a,return_counts=True)
print(uc)
#元素出现次数
print(indices)
- 排序

a=np.array([[3,5,7],[6,1,4]])
print("a的数组:\n",a)
print("排序后的\n",np.sort(a))

#以行为参照,数据排序
print(np.sort(a,axis=0))

#以列为参照,数据排序
print(np.sort(a,axis=0))
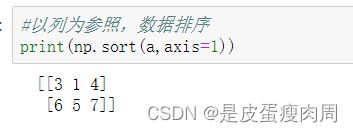
#设置在sort函数中排序字段
dt=np.dtype([('name','S10'),('age',int)])
a=np.array([("raju",21),("anli",25),("ravi",17),("amar",27)],dtype=dt)
print(a)
#按照name
print(np.sort(a,order='name'))
#按照年龄
print(np.sort(a,order='age'))

- np.argsort()沿着指定的轴,对输入数组的元素进行排序,并且返回排序后的元素索引数组
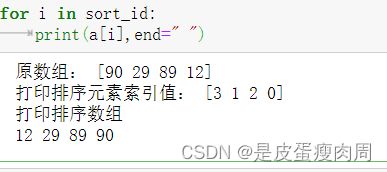
a=np.array([90,29,89,12])
print("原数组:",a)
sort_id=np.argsort(a)
print("打印排序元素索引值:",sort_id)
sort_a=a[sort_id]
print("打印排序数组")
for i in sort_id:
print(a[i],end=" ")