微积分(预备知识)
文章目录
-
- 微积分
-
- 导数和微分
- 偏导数
- 梯度
- 链式法则
- 小结
微积分
在2500年前,古希腊人把一个多边形分成三角形,并把它们的面积相加,才找到计算多边形面积的方法。为了求出曲线形状(比如圆)的面积,古希腊人在这样的形状上刻内接多边形。
如下图所示,内接多边形的等长边越多,就越接近圆。 这个过程也被称为逼近法(method of exhaustion)。
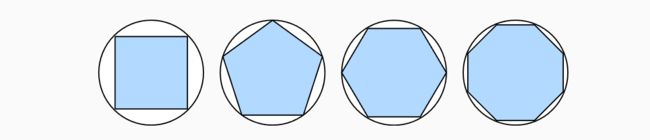
事实上,逼近法就是**积分(integral calculus)**的起源, 我们将在 sec_integral_calculus中详细描述。
2000多年后,微积分的另一支,**微分(differential calculus)**被发明出来。在微分学最重要的应用是优化问题,即考虑如何把事情做到最好。
在深度学习中,我们“训练”模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好。 通常情况下,变得更好意味着最小化一个损失函数(loss function), 即一个衡量“我们的模型有多糟糕”这个问题的分数。 最终,我们真正关心的是生成一个模型,它能够在从未见过的数据上表现良好。 但“训练”模型只能将模型与我们实际能看到的数据相拟合。 因此,我们可以将拟合模型的任务分解为两个关键问题:
- 优化(optimization):用模型拟合观测数据的过程;
- 泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。
为了在后面的章节中更好地理解优化问题和方法, 本节提供了一个非常简短的入门教程,快速掌握深度学习中常用的微分知识。
导数和微分
我们首先讨论导数的计算,这是几乎所有深度学习优化算法的关键步骤。在深度学习中,我们通常选择对于模型参数可微的损失函数。
简而言之,对于每个参数, 如果我们把这个参数增加或减少一个无穷小的量,我们可以知道损失会以多快的速度增加或减少,假设我们有一个函数 f = R ⇒ R f = R\Rightarrow R f=R⇒R,其输入和输出都是标量。 如果的导数存在,这个极限被定义为
f ′ ( x ) = lim h → 0 f ( x + h ) − f ( x ) h f'(x) = \lim\limits_{h \rightarrow 0}{\frac{f(x+h) - f(x)}{h}} f′(x)=h→0limhf(x+h)−f(x)
如果 f ′ ( a ) f'(a) f′(a)存在,则称在处是 可微(differentiable) 的。 如果 f f f 在一个区间内的每个数上都是可微的,则此函数在此区间中是可微的。 我们可以将导数 f ′ ( x ) f'(x) f′(x) 解释为 f ( x ) f(x) f(x) 相对于 x x x 的瞬时(instantaneous)变化率。 所谓的瞬时变化率是基于 x x x 中的变化 h h h,且接近 0 0 0。
为了更好地解释导数,让我们做一个实验。 定义 u = f ( x ) = 3 x 2 − 4 x u = f(x) = 3x^2 - 4x u=f(x)=3x2−4x 如下:
import numpy as np #导入numpy数据处理包
from matplotlib_inline import backend_inline #导入backend_inline工具包
import matplotlib.pyplot as plt #导入torch工具包
def f(x): #定义函数f(x)
return 3 * x ** 2 - 4 * x
通过令 x = 1 x=1 x=1 并让 h h h 接近 0 0 0 , 即该结果 f ′ ( x ) = lim h → 0 f ( x + h ) − f ( x ) h f'(x) = \lim\limits_{h \rightarrow 0}{\frac{f(x+h) - f(x)}{h}} f′(x)=h→0limhf(x+h)−f(x) 越来越接近 2 2 2 。
虽然这个实验不是一个数学证明,但我们稍后会看到,当 x = 1 x=1 x=1 时,导数 u ′ u' u′ 是 2 2 2 。
def numerical_lim(f,x,h): #定义计算极限的函数,即导数
return (f(x+h)-f(x))/h
h = 0.1 #定义h初始化为0.1
for i in range(5):
print(f'h={h:.5f}, numberical_lim={numerical_lim(f,1,h):.5f}') #输出h变化时每次的导数值的变化
h *= 0.1 #h累计减少
h=0.10000, numberical_lim=2.30000
h=0.01000, numberical_lim=2.03000
h=0.00100, numberical_lim=2.00300
h=0.00010, numberical_lim=2.00030
h=0.00001, numberical_lim=2.00003


def use_svg_display():
"""使用svg格式在Jupyter中显示绘图"""
backend_inline.set_matplotlib_formats('svg')
我们定义set_figsize函数来设置图表大小。
def set_figsize(figsize=(3.5, 2.5)):
"""设置matplotlib的图表大小"""
use_svg_display()
plt.rcParams['figure.figsize'] = figsize
下面的set_axes函数用于设置由matplotlib生成图表的轴的属性。
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):
"""设置matplotlib的轴"""
axes.set_xlabel(xlabel) #设置图表的x轴标签
axes.set_ylabel(ylabel) #设置图表的y轴标签
axes.set_xscale(xscale) #设置x范围
axes.set_yscale(yscale) #设置y范围
axes.set_xlim(xlim)
axes.set_ylim(ylim) #设置x,y轴的度量
if legend:
axes.legend(legend) #显示所有的标签
axes.grid()
通过这三个用于图形配置的函数,我们定义了plot函数来简洁地绘制多条曲线, 因为我们需要在整个书中可视化许多曲线。
def plot(X, Y=None, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5), axes=None):
"""绘制数据点"""
if legend is None:
legend = []
set_figsize(figsize)
axes = axes if axes else plt.gca()
# 如果X有一个轴,输出True
def has_one_axis(X):
return (hasattr(X, "ndim") and X.ndim == 1 or isinstance(X, list)
and not hasattr(X[0], "__len__"))
if has_one_axis(X):
X = [X]
if Y is None:
X, Y = [[]] * len(X), X
elif has_one_axis(Y):
Y = [Y]
if len(X) != len(Y):
X = X * len(Y)
axes.cla()
for x, y, fmt in zip(X, Y, fmts):
if len(x):
axes.plot(x, y, fmt)
else:
axes.plot(y, fmt)
set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
现在我们可以绘制函数 u = f ( x ) = 3 x 2 − 4 x u = f(x) = 3x^2 - 4x u=f(x)=3x2−4x及其在 x = 1 x=1 x=1 处的切线 f ′ ( x ) = 2 x − 3 f'(x) = 2x - 3 f′(x)=2x−3 , 其中系数 x = 6 x = 6 x=6 是切线的斜率。
x = np.arange(0, 3, 0.1)
plot(x, [f(x), 2 * x - 3], 'x', 'f(x)', legend=['f(x)', 'Tangent line (x=1)'])

偏导数
到目前为止,我们只讨论了仅含一个变量的函数的微分。
在深度学习中,函数通常依赖于许多变量。 因此,我们需要将微分的思想推广到 多元函数(multivariate function) 上。

梯度

链式法则
然而,上面方法可能很难找到梯度。 这是因为在深度学习中,多元函数通常是复合(composite)的, 所以我们可能没法应用上述任何规则来微分这些函数。 幸运的是,链式法则使我们能够微分复合函数。

小结
微分和积分是微积分的两个分支,前者可以应用于深度学习中的优化问题。
导数可以被解释为函数相对于其变量的瞬时变化率,它也是函数曲线的切线的斜率。
梯度是一个向量,其分量是多变量函数相对于其所有变量的偏导数。
链式法则使我们能够微分复合函数。