CNN笔记(CS231N)——生成模型(Generative Models)
总览
之前我们讲的网络模型都是监督学习,这一讲我们要讲的是无监督学习。以下是本讲的总览

无监督学习与监督学习最大的不同就是我们只有数据,没有任何多余的标注,我们要做的就是学习数据中隐藏的某些结构。而生成模型就属于无监督学习的一种

生成模型
生成模型的目标是给定训练数据,希望能获得与训练数据相同的新数据样本。我们的目标是找到训练数据的分布函数

生成模型在很多场景有非常好的应用

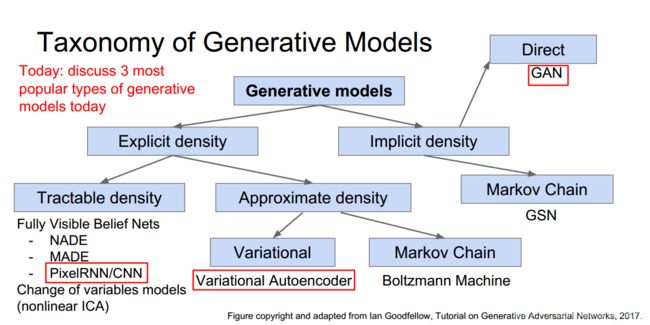
我们可以对生成模型进行分类,在本讲中我们主要讲下面圈起来的三种方法
PixelCNN/RNN
PixelCNN属于显式密度模型,它主要运用链式法则来将求出与训练数据相同的分布

一般是从图像的一个角开始,利用RNN逐步生成新的图像

为了加快训练速度,在PixelRNN上进行改进可以得到PixelCNN,但缺点是生成速度慢,像素也需要逐一生成

以下是二者的对比

变分编码器
变分编码器主要是引入了一个隐藏向量z的概念,把z作为条件,利用条件概率的公式计算相似性

在讲变分编码器之前先让我们看看自编码的概念,自编码主要是先对数据进行降维来保留数据中重要的特征

然后用解码器对特征向量z进行解码,希望得到重构的数据
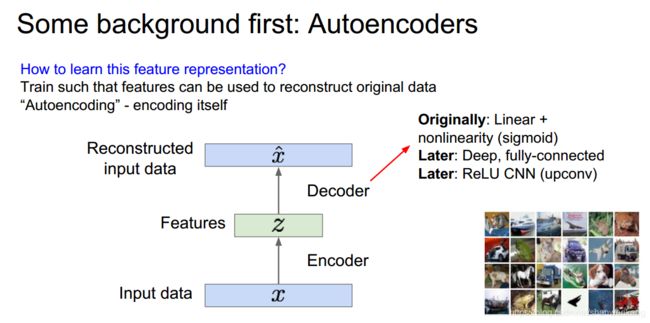
我们对这个网络进行训练,损失函数就是重构数据与原数据像素的差

当我们训练完成以后我们就可以认为我们的编码器学习到了提取重要特征的方法,能够很好的用隐藏特征z表示原图。这个时候我们就能抛开解码器,用编码器做一些其他的事情,例如初始化一些监督模型,达到数据降维的效果,这个时候当我们数据集比较小的时候也能对这个模型进行训练

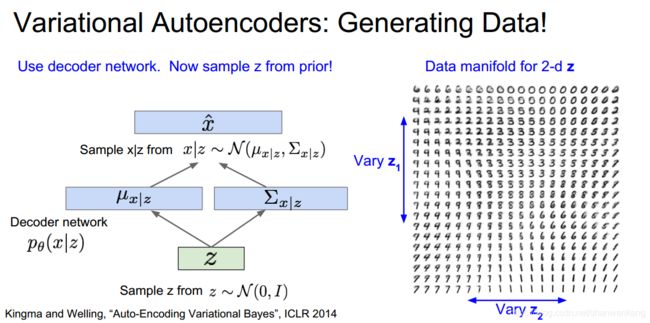
那么我们是否能用编码器来生成新的数据?这就是变分编码器的作用。我们希望能用隐藏特征z去生成数据x

这其中存在采样的过程,特征z与最终样本x都是对他们真实分布的一个采样结果
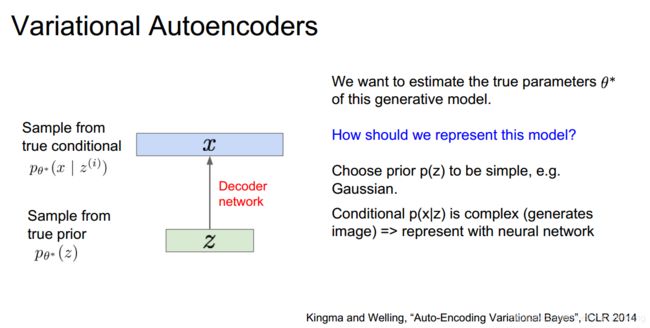
对于这个网络我们不能用传统的神经网络训练方法对它进行训练,因为这其中存在积分,所以它是intractable的。我们不可能计算出每个z对应的p(x|z),因此最后的p(x)是无法计算的

为了解决这个问题,有人提出了定义另外的一个编码网络来对解码网络进行近似

这其中存在的假设就是隐藏特征z与最终样本x都是满足高斯分布的,因此我们用神经网络训练得到z与x的均值与方差,即可构建出他们的分布函数,再从中进行采样就可以得到最终的结果

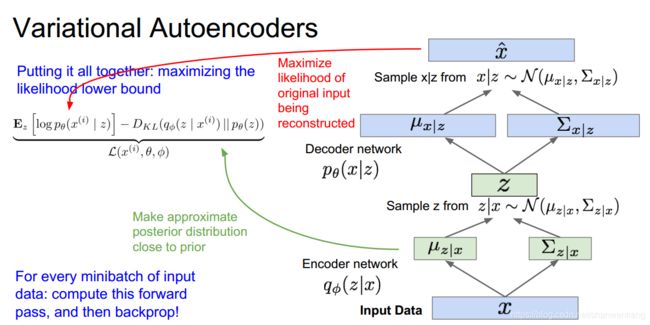
在引入了这个概念以后我们就能对最终的相似函数做如下推导

最终我们发现相似函数的一部分是tracable的,这部分是相似函数的下界,因此当我们无法最大化我们相似函数的时候我们只能选择最大化相似函数的下界

我们将公式结合我们的训练过程我们就能发现我们下界中前一部分是在最大化与原图的相似性,后一部分是在求出与先验信息最相思的后验分布
以下是利用变分编码器生成图像的结果

下面是对变分编码器的总结

GAN
我们之前讲的方法都是我们想求出显式的模型概率分布,现在我们可以抛弃这种方法,利用博弈论的思想来生成训练集的分布,这也就是GAN(Generative Adversarial Networks)。而生成这种复杂分布的方法就是通过神经网络

GAN网络中的博弈双方分别是生成网络与鉴别网络。生成网络的工作就是尽可能生成逼近真实的图像,鉴别网络的工作就是从真实的图像中分辨出人工合成的图像

如果把上面讲的思想用公式来表达就是以下式子

但如果采用这种目标函数会出现问题,由于目标函数中需要优化两个参数,一个需要用梯度上升,一个需要用梯度下降,因此二者结合起来效果并不是特别好。我们可以从右下角看出随着生成器效果越好,损失函数下降越快,这意味着当我们刚开始训练的时候梯度下降缓慢,而随着效果越来越好,损失函数下降越来越快,这显然不是我们想要的结果

为了保证在刚开始训练的时候能大大减小损失函数,我们可以更改目标函数,使得两个参数都用梯度上升的方法进行优化

以下是GAN的伪代码

当循环一定次数以后,我们就可以用生成器来生成非常类似真实的图像了

利用生成器生成图像的时候网络跟解码器结构类似,也是利用一个特征向量来生成图片,而不同的是我们一般选择随机向量作为这个向量,而不是一副图像经过编码器后生成的特殊向量
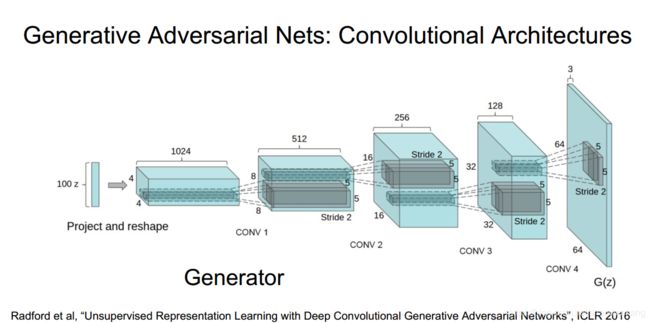
下面是网络实现的一些细节

GAN网络取得的效果非常好,也是最近研究的热点

一些优缺点被列举在下方

下面是本讲的总结
