Supervised Contrastive Replay 论文详解 通过NCM分类器和图片回放实现增量学习
论文地址:[2103.13885] Supervised Contrastive Replay: Revisiting the Nearest Class Mean Classifier in Online Class-Incremental Continual Learning (arxiv.org)
Supervised contrastive replay: revisiting the nearest class mean classifier in online class-incremental continual learning
基于原始图片rehearsal的增量学习方法
目录
1.贡献点
2.方法
2.1 模型框架
2.2 NCM分类器
2.3 supervised contrastive learning(SCL)
2.4 supervised contrastive replay (SCR)
3.实验
4.总结
1.贡献点
本文的方法是基于Rehearsal的增量学习方法。因为Memory之中的原始图片也经过了特征提取模块,所以本文基于的是直接存储原始图片的rehearsal方法。
本文研究如何让特征提取模块提取出的特征更具判别性。
在线增量任务,大量的研究说明NCM分类器会比softmax分类器取得更好的结果。通过作者的观测,进行了大量的NCM和softmax分类器的对比实验,得到了一些可靠的结果。
本文提出了SCR(supervised contrastive replay),这个方法可以让同类的样本在embedding空间更接近,不同类的样本在embedding空间距离更远。
本文通过大量的实验对比,SCR的方法在多个数据集上,比SOTA方法具有更明显的优势。
可看效果:
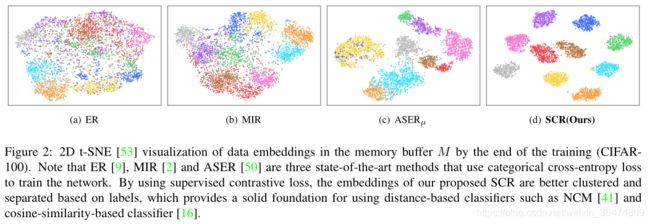
基于不同特征回放的特征可视化,可以看出本文的方法SCR,可以取得较好的聚类效果。同类特征可视化后更近,不同类特征可视化之后更远,不清晰分类边界清晰。
2.方法
2.1 模型框架

训练过程中,训练的batch来自两个地方,一个来自于增量数据Bn,另一个来自于Memory, Bm,m存在于buffer之中。训练过程流程如下:输入经过encoder进行特征提取,再经过projection head然后送入 Supervised contrastive loss进行训练。相当于模型有两个网络,一个是特征提取模块,另一个映射模块。
test的过程,encoder之后的projection head映射模块被移除,直接将特征送入到NCM分类器中进行分类。
2.2 NCM分类器
NCM分类器是近两年增量学习之中广泛采用的分类器,之所以采用NCM分类器,与CNN分类器的以下缺点有关:
- FC层和softmax分类器很容易被类别不均衡问题所困扰。
- task-recency bias : 模型总是偏向于最近训练过的任务。
根据本文的实验,
NCM分类器与memory buffer相结合,会取得更好的效果。
对比了SCR与supervised contrastive loss: 同类的样本在embedding空间更接近,不同类的样本在embedding空间距离更远。
NCM分类相比softmax分类器的优点:
- 分类器新类别到来之后,softmax分类器的FC层需要变化结构,NCM无需变化结构
- 编码器权重与模型权重是耦合的,如果编码器的权重改变,则模型权重也需要跟着改变。NCM分类器对于encoder的变化时更加鲁棒,不用像FC层一样,要与encoder的权值绑定。
- task-recency bias 模型训练完成之后偏向于最近训练的task,NCM不会引入task- recency bias,因为各个任务在NCM之中是等权重的。

后文实验Figure5可以看出,各种增量学习方法之中,NCM分类器的优势明显优于softmax分类器
2.3 supervised contrastive learning(SCL)
SCL的目的是,将同样类别的样本在embedding空间上的距离更近,不同类样本在embedding空间上的距离更远。
假定样本是x,经过增强Aug()后的样本x^=Aug(x), 编码网络Enc()将输入转化为超球R上的点。 r=Enc(x)∈R
投影网络将r投影为向量z z=Proj(r) ∈R
相当于流程 样本x 数据增强x^, 编码网络Enc(), 投影网络 Proj()
物体经过编码网络和映射网络后的r和d都是超球面上的点
对应SCL loss是:

此loss的目的是,让当前样本与同类样本的投影距离更近,与非同类样本的投影距离更远。
- zi表示样本经过编码,投影之后的向量
- zp表示同类正样本经过编码,投影之后的向量
- zj表示非同类样本经过编码投影之后的向量
- tao是温度系数
2.4 supervised contrastive replay (SCR)
假定新任务batch为Bn,旧任务batch为Bm,(memory,旧任务从memory之中取出),
训练过程通过SCL loss更新映射网络和编码网络的权重。包括Enc网络和Proj网络,
测试阶段删除掉Proj网络,相当于样本经过Enc网络之后的特征直接当作用于分类的特征。
算法框图如下:

关于memory buffer如何存储和更新,不是此文探讨的重点,
因此此文参考了ASER方法,Dongsub shim: Online class-incremental continual with adversarial shapley value. AAAI 2021和
GSS (NIPS 2019) : Gradient-Based Sample Selection, a replay method that diversifies the gradients of the samples in the replay memory
3.实验
figure 6显示了本文的方法和其他主流方法对比

关于SCR的消融实验:

b是memory buffer的处理方式的对比,即选取什么样的特征存储于分类器之中,有点惊异, Random的memory选取方式效果最好,比GSS和ASER的方法都好。难道说明,GSS(NIPS2019)和ASER(AAAI2021)的方式居然不如随机抽取的方式好?
4.总结
将基于原始样本回放的方法与NCM分类器相结合,SCR的主要贡献在于提取出具有判别性的特征。
本文中值得注意的是,样本选取的方式,消融实验之中,居然memory buffer用随机的方式选取的准确率最好,比GSS(NIPS2019)和ASER(AAAI2021)的方式都好,有点反常,值得分析一下原因。