YOLOv3&YOLOv5输出结果说明
本文使用的yolov3和yolov5工程文件均为github上ultralytics基于pytorch的v3和v5代码,其训练集输出结果类型基本一致,主要介绍了其输出结果,本文是一篇学习笔记
本文使用的yolov3代码github下载地址:yolov3
模型训练具体步骤可查看此篇博客:
yolov3模型训练——使用yolov3训练自己的模型
本文使用的yolov5代码github下载地址:yolov5
模型训练具体步骤可查看此篇博客:
yolov5模型训练———使用yolov5训练自己的数据集
本文主要包括以下内容:
- 1. confusion_matrix.png
- 2. F1_curve.png
- 3. labels.jpg
- 4. P_curve.png
- 5. PR_curve.png
- 6. R_curve.png
- 7. results.png
- 8. results.txt
yolov3模型训练输出结果如下图所示:

yolov5模型训练输出结果如下图所示:

(这版的v3和v5输出结果类型看起来是一模一样,我用的同一个数据集进行的训练,所以输出的可视化结果也非常相似,v5在服务器上的结果截图没有保存,这里用了windows下的视图)
1. confusion_matrix.png
confusion_matrix.png指的是混淆矩阵(Confusion Matrix)
在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;
每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目;每一列中的数值表示真实数据被预测为该类的数目。
混淆矩阵结构如下图所示:

2. F1_curve.png
F1_Score:数学定义为 F1分数(F1-Score),又称为平衡F分数(Balanced Score),它被定义为正确率和召回率的调和平均数。在 β=1 的情况,F1-Score的取值范围为0到1,1是最好,0是最差。其计算公式如下图所示:

3. labels.jpg
第一个图 classes:每个类别的数据量
第二个图 labels:标签
第三个图 center xy
第四个图 labels 标签的长和宽
4. P_curve.png
精确率Precision和置信度confidence的关系图
5. PR_curve.png
PR曲线中的P代表的是Precision(精准率),R代表的是Recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即map。
如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)。
Precision(精准率)表示分类器检测为正确正样本占所有预测为正样本的百分比,即在当前遍历的预测框中,检测到正确目标预测框所占的比例。其公式如下图所示:
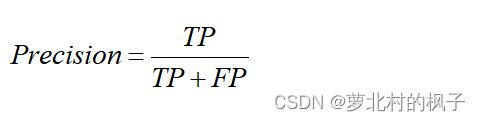
Recall(召回率)表示分类器检测为正确正样本占所有正样本的百分比,即在所有的真值边界框中,检测到正确正样本边界框所占的比例。其公式如下图所示:

Precision和Recall一般是一对矛盾的性能度量指标;
提高Precision 提高二分类器预测正例门槛,使得二分类器预测的正例尽可能是真实正例;
提高Recall 降低二分类器预测正例门槛,使得二分类器尽可能将真实的正例挑选
6. R_curve.png
召回率Recall和置信度confidence之间的关系
7. results.png
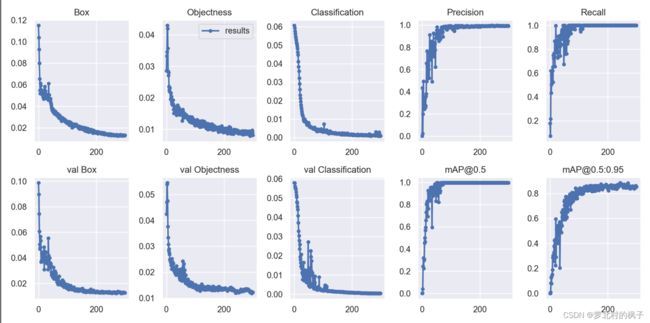
(1)yolov3与yolov5的损失函数可以分为三部分:类别损失函数(Classification loss)、置信度损失函数(Confidence loss)和位置损失函数(Localization loss)
Box_loss:Box为CIoU损失函数均值,越小方框越准;
Objectness_loss:Objectness为目标检测损失均值,越小目标检测越准;
Classification_loss:Classification为分类损失均值,越小分类越准;
val Box_loss: 验证集bounding box损失;
val Objectness_loss:验证集目标检测loss均值;
val classification_loss:验证集分类loss均值;
(2)
Precision:精确率随训练次数的变化曲线
Recall:召回率随训练次数的变化曲线
(3)AP值是衡量目标检测模型分类器性能优劣的重要评估指标,AP值越大则分类器性能越好,越小则分类器性能越差;AP值的大小等于P-R曲线与坐标轴围成区域的面积。
mAP表示所有标签类别AP值的平均值,mAP值越大,说明模型性能越好。
[email protected]:表示在IoU阈值为0.5时的mAP值变化曲线
[email protected]:0.95:表示在IoU阈值以0.05的步长从0.5到0.95变化时的mAP值变化曲线,即IoU阈值取0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95时的平均mAP。
8. results.txt
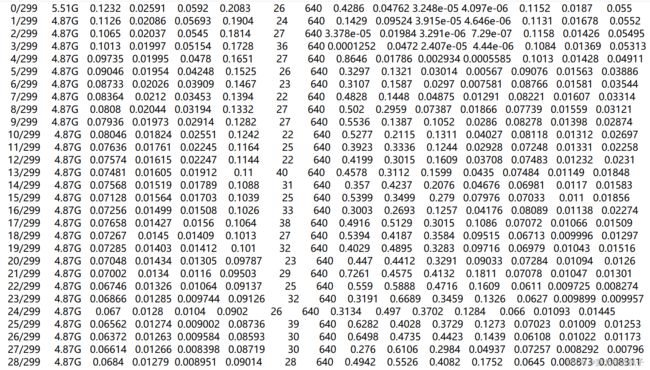
results.txt中最后三列是验证集结果,前面的是训练集结果,全部列分别是:
训练次数,GPU消耗,边界框损失,目标检测损失,分类损失,total,targets,图片大小,P,R,[email protected], [email protected]:.95, 验证集val Box, 验证集val obj, 验证集val cls
test_batch0_labels等图片是模型训练输出的可视化结果,不再赘述~