机器学习面试题——PCA与LDA
机器学习面试题——PCA与LDA
提示:不知道今后互联网大厂考还是不考,准备着
PCA介绍一下
PCA算法步骤
PCA原理
PCA降维之后的维度怎么确定
说说PCA的优缺点
推导一下PCA
降维方法有哪些?
LDA介绍一下
LDA的中心思想是什么
LDA的优缺点
说说LDA的步骤
推导一下LDA
PCA和LDA有什么区别
偏差与方差
SVD懂么
方差和协方差的理解
伯努利分布和二项分布的区别
PCA与LDA:《百面机器学习算法工程师带你面试》第四章——降维讲得很多
文章目录
- 机器学习面试题——PCA与LDA
-
- @[TOC](文章目录)
- PCA介绍一下
- PCA算法步骤
- PCA原理
- PCA降维之后的维度怎么确定
- 说说PCA的优缺点
-
- 优点
- 缺点
- 推导一下PCA
- 降维方法有哪些?
- LDA介绍一下
- LDA的中心思想是什么
- LDA的优缺点
-
- 优点:
- 缺点
- 说说LDA的步骤
- 推导一下LDA
- PCA和LDA有什么区别
-
- 相同点:
- 不同点:
- 偏差与方差
- SVD懂么
- 方差和协方差的理解
- 伯努利分布和二项分布的区别
- 总结
文章目录
- 机器学习面试题——PCA与LDA
-
- @[TOC](文章目录)
- PCA介绍一下
- PCA算法步骤
- PCA原理
- PCA降维之后的维度怎么确定
- 说说PCA的优缺点
-
- 优点
- 缺点
- 推导一下PCA
- 降维方法有哪些?
- LDA介绍一下
- LDA的中心思想是什么
- LDA的优缺点
-
- 优点:
- 缺点
- 说说LDA的步骤
- 推导一下LDA
- PCA和LDA有什么区别
-
- 相同点:
- 不同点:
- 偏差与方差
- SVD懂么
- 方差和协方差的理解
- 伯努利分布和二项分布的区别
- 总结
PCA介绍一下
主成分分析(Principal Component Analysis,PCA)是一种多变量统计方法,它是最常用的降维方法之一,无监督学习降维法。
通过正交变换将一组可能存在相关性的变量数据转换为一组线性不相关的变量,转换后的变量被称为主成分。
可以使用两种方法进行 PCA,分别是特征分解或奇异值分解(SVD)。
PCA旨在找到数据中的主成分, 并利用这些主成分表征原始数据, 从而达到降维的目的。
算法步骤:
(1)假设有m条n维数据。
(2)将原始数据按列组成n行m列矩阵X
(3)将X的每一行(代表一个属性字段)进行去均值化,即减去这一行的均值
(3)求出协方差矩阵
 (4)求出协方差矩阵的特征值以及对应的特征向量
(4)求出协方差矩阵的特征值以及对应的特征向量
(5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
(6)Y=PX即为降维到k维后的数据
要的就是前主要的k维数据表征
PCA是比较常见的线性降维方法,通过线性投影将高维数据映射到低维数据中,所期望的是在投影的维度上,新特征自身的方差尽量大,方差越大特征越有效,尽量使产生的新特征间的相关性越小。
PCA算法的具体操作为对所有的样本进行中心化操作,计算样本的协方差矩阵,然后对协方差矩阵做特征值分解,取最大的n个特征值对应的特征向量构造投影矩阵。
PCA算法步骤

PCA原理
PCA是比较常见的线性降维方法,
通过线性投影将高维数据映射到低维数据中,
所期望的是在投影的维度上,新特征自身的方差尽量大,
方差越大特征越有效,尽量使产生的新特征间的相关性越小。
PCA算法的具体操作为对所有的样本进行中心化操作,
计算样本的协方差矩阵,
然后对协方差矩阵做特征值分解,
取最大的n个特征值对应的特征向量构造投影矩阵。
然后后投影矩阵×X即Y
PCA降维之后的维度怎么确定
(1)可以利用交叉验证,再选择一个很简单的分类器,来选择比较好的 k 的值
(2)可以设置一个比重阈值 t,比如 95%,然后选择满足阈值的最小的 k:

说说PCA的优缺点
优点
(1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响
(2)各主成分之间正交,可消除原始数据成分间的相互影响的因素
(3)计算方法简单,主要运算是特征值分解,易于实现。
缺点
(1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强
(2)方差小的非主成分也可能含有对样本差异的重要信息,因此降维丢弃可能对后续数据处理有影响
(3)PCA属于有损压缩
推导一下PCA




降维方法有哪些?
PCA和LDA
LDA介绍一下
线性判别分析(Linear Discriminant Analysis, LDA)
是一种基于有监督学习的降维方式,
将数据集在低维度的空间进行投影,
要使得投影后的同类别的数据点间的距离尽可能的靠近,
而不同类别间的数据点的距离尽可能的远。
有点像聚类?
LDA的中心思想是什么
最大化类间距离
最小化类内距离。
有点像是特征元
LDA的优缺点
优点:
(1)在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
(2)LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
缺点
(1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
(2)LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
(3)LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
(4)LDA可能过度拟合数据。
说说LDA的步骤
类内散度
类间散度

推导一下LDA



PCA和LDA有什么区别
LDA用于降维,和PCA有很多相同,也有很多不同的地方,
因此值得好好的比较一下两者的降维异同点。
相同点:
(1)两者均可以对数据进行降维。
(2)两者在降维时均使用了矩阵特征分解的思想。
(3)两者都假设数据符合高斯分布。
不同点:
(1)LDA是有监督的降维方法,而PCA是无监督的降维方法
(2)LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
(3)LDA除了可以用于降维,还可以用于分类。 聚类
(4)LDA择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优。

当然,某些某些数据分布下PCA比LDA降维较优,如下图所示:

偏差与方差
(1)偏差(bias):偏差衡量了模型的预测值与实际值之间的偏离关系。
通常在深度学习中,我们每一次训练迭代出来的新模型,都会拿训练数据进行预测,偏差就反应在预测值与实际值匹配度上,
比如通常在keras运行中看到的准确度为96%,则说明是低偏差;
反之,如果准确度只有70%,则说明是高偏差。
(2)方差(variance):方差描述的是训练数据在不同迭代阶段的训练模型中,预测值的变化波动情况(或称之为离散情况)。
从数学角度看,可以理解为每个预测值与预测均值差的平方和的再求平均数。
通常在深度学习训练中,初始阶段模型复杂度不高,为低方差;
随着训练量加大,模型逐步拟合训练数据,复杂度开始变高,此时方差会逐渐变高。
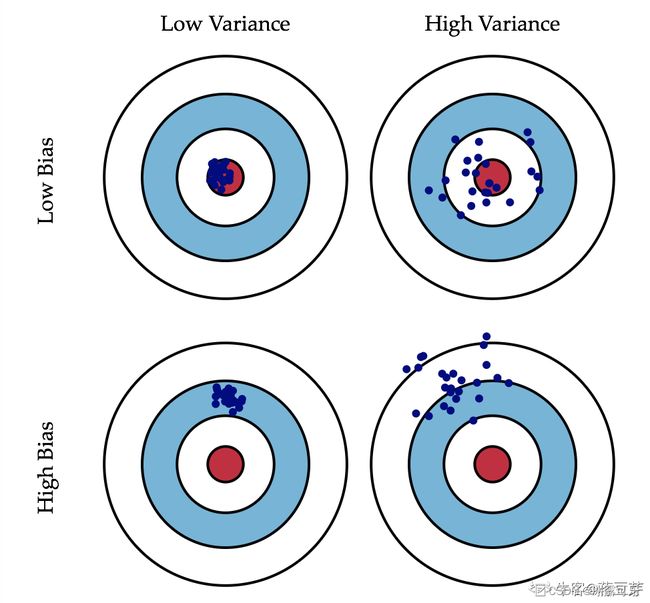
这是一张常见的靶心图。
可以想象红色靶心表示为实际值,蓝色点集为预测值。
在模型不断地训练迭代过程中,我们能碰到四种情况:
(1)低偏差,低方差:这是训练的理想模型,此时蓝色点集基本落在靶心范围内,且数据离散程度小,基本在靶心范围内;——这是狙击手最牛逼的地方!!!!连中10环
(2)低偏差,高方差:这是深度学习面临的最大问题,过拟合了。也就是模型太贴合训练数据了,导致其泛化(或通用)能力差,若遇到测试集,则准确度下降的厉害;
(3)高偏差,低方差:这往往是训练的初始阶段;
(4)高偏差,高方差:这是训练最糟糕的情况,准确度差,数据的离散程度也差。
SVD懂么
奇异值分解(Singular Value Decomposition,以下简称SVD)
是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,
还可以用于推荐系统,
以及自然语言处理等领域。

这个奇异值分解在研究生一年级的矩阵论里面学过的基础知识!!!
方差和协方差的理解

伯努利分布和二项分布的区别
(1)伯努利分布:
是假设一个事件只有发生或者不发生两种可能,
并且这两种可能是固定不变的。
那么,如果假设它发生的概率是p,
那么它不发生的概率就是1-p。
这就是伯努利分布。
(2)二项分布是多次伯努利分布实验的概率分布。
总结
提示:重要经验:
1)读过研究生的这点知识应该可以自己看懂
2)PAC和LDA都是降维算法,和t-SNE类似,在tensorboard中,可以将你的高威特征降维下来展示