动手学深度学习pytorch版练习解答-3.4softmax回归
这一节习题数学能力要求比较高,我的有限,如果有不同意见或者我哪里写错了欢迎讨论
练习
1.我们可以更深入地探讨指数族与softmax之间的联系。
(1)计算softmax交叉熵损失 l ( y , y ^ ) l(\mathbf{y},\hat{\mathbf{y}}) l(y,y^)的二阶导数
(2)计算softmax(o)给出的分布⽅差,并与上面计算的⼆阶导数匹配。
解:(1)由公式3.4.9和3.4.10:
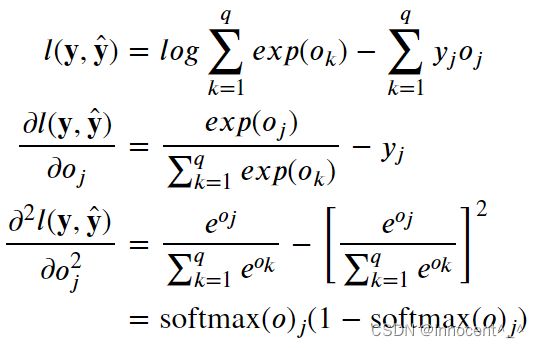
(2)由方差的计算公式,假设o一共有q个,第i个观察对象的softmax计算结果为 s i s_i si,他们的softmax计算值的平均结果为 s ˉ \bar s sˉ:
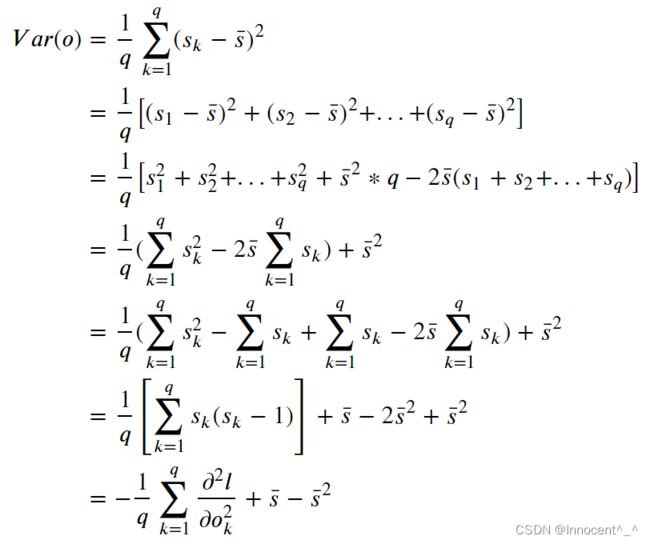
2.假设我们有三个类发⽣的概率相等,即概率向量是( 1 3 \frac{1}{3} 31, 1 3 \frac{1}{3} 31, 1 3 \frac{1}{3} 31)
(1)如果我们尝试为它设计⼆进制代码,有什么问题?
(2)你能设计⼀个更好的代码吗?提示:如果我们尝试编码两个独⽴的观察结果会发⽣什么?如果我们联合编码n个观测值怎么办?
解:(1)有三个类,如果要设置二进制代码至少需要2位。如果采用2位编码,有00、01、10、11四种组合,会出现某一个组合被浪费,而且想构造出题述概率向量非常困难,要根据组合,找新的表达形式,而且需要更改对应的损失函数参数,过程会非常繁琐困难
(2)采用one-hot独热编码。比如分别设置为001、010、100,三位数字中如果某一位是1则说明这个数据样例属于对应的类
3.softmax是对上⾯介绍的映射的误称(虽然深度学习领域中很多⼈都使⽤这个名字)。真正的softmax被定义为RealSoftMax(a, b) = log(exp(a) + exp(b))。
(1)证明:RealSoftMax(a, b) > max(a, b)
假设 a > b: l o g ( e a + e b ) > l o g e a = a log(e^a + e^b) > loge^a = a log(ea+eb)>logea=a,反之同理,得证
(2)证明:如果 λ > 0 \lambda > 0 λ>0,则 λ − 1 RealSoftMax ( λ a , λ b ) > m a x ( a , b ) \lambda^{-1}\text{RealSoftMax}(\lambda a, \lambda b) > max(a, b) λ−1RealSoftMax(λa,λb)>max(a,b)
假设 a > b: λ − 1 l o g ( e λ a + e λ b ) > λ − 1 l o g e λ a = a \lambda ^{-1}log(e^{\lambda a} + e^{\lambda b}) > \lambda ^{-1}loge^{\lambda a} = a λ−1log(eλa+eλb)>λ−1logeλa=a,反之同理,得证
(3)证明对于λ → ∞,有 λ − 1 \lambda^{-1} λ−1RealSoftMax(λa, λb) → max(a, b)。
直观理解:假设 a > b, λ \lambda λ→∞则有 λ a \lambda a λa >> λ b \lambda b λb,那么 l o g ( e λ a + e λ b ) log(e^{\lambda a} + e^{\lambda b}) log(eλa+eλb)中 e λ b e^{\lambda b} eλb可以忽略不计。
正常做法:使用夹逼定理

而 λ − 1 l o g 2 \lambda ^{-1}log2 λ−1log2在 λ \lambda λ趋于无穷时为0,根据夹逼定理得到原式极限为a,反之同理
4.soft-min会是什么样子
解:假设有q个观察结果,那么 softmin ( o ) i = e − i ∑ k = 1 q e − k \text{softmin}(o)_i = \frac{e^{-i}}{\sum^{q}_{k=1} \ e^{-k}} softmin(o)i=∑k=1q e−ke−i
5.将其扩展到两个以上的数字。
解:Realsoftmax(a,b,c,…)=log( e a + e b + e c + . . . e^a + e^b + e^c + ... ea+eb+ec+...)