神经网络与深度学习(五)前馈神经网络(1)——二分类任务
神经网络是由神经元按照一定的连接结构组合而成的网络。神经网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射 。
前馈神经网络是最早发明的简单人工神经网络。整个网络中的信息单向传播,可以用一个有向无环路图表示,这种网络结构简单,易于实现。
目录
4.1 神经元
4.1.1 净活性值
4.1.2 激活函数
4.1.2.1 Sigmoid 型函数
4.1.2.2 ReLU型函数
4.2 基于前馈神经网络的二分类任务
4.2.1 数据集构建
4.2.2 模型构建
4.2.2.1 线性层算子
4.2.2.2 Logistic算子
4.2.2.3 层的串行组合
4.2.3 损失函数
4.2.4 模型优化
4.2.4.1 反向传播算法
4.2.4.2 损失函数
4.2.4.3 Logistic算子
4.2.4.4 线性层
4.2.4.5 整个网络
4.2.4.6 优化器
4.2.5 完善Runner类:RunnerV2_1
4.2.6 模型训练
4.2.7 性能评价
总结
参考资料
4.1 神经元
神经网络的基本组成单元为带有非线性激活函数的神经元。
在大脑中,神经网络由称为神经元的神经细胞组成,神经元的主要结构有细胞体、树突(用来接收信号)和轴突(用来传输信号)。一个神经元的轴突末梢和其他神经元的树突相接触,形成突触。神经元通过轴突和突触把产生的信号送到其他的神经元。信号就从树突上的突触进入本细胞,神经元利用一种未知的方法,把所有从树突突触上进来的信号进行相加,如果全部信号的总和超过某个阀值,就会激发神经元进入兴奋状态,产生神经冲动并传递给其他神经元。如果信号总和没有达到阀值,神经元就不会兴奋。图1展示的是一个生物神经元。
 图1-生物神经元
图1-生物神经元
人工神经元模拟但简化了生物神经元,是神经网络的基本信息处理单位,其基本要素包括突触、求和单元和激活函数,结构见图2
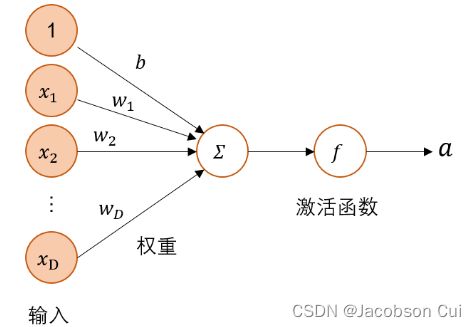 图2-典型的神经元结构
图2-典型的神经元结构
4.1.1 净活性值
假设一个神经元接收的输入为![]() ,其权重向量为
,其权重向量为![]() ,神经元所获得的输入信号,即净活性值
,神经元所获得的输入信号,即净活性值 的计算方法为:
的计算方法为:
![]()
其中 为偏置。
为偏置。
为了提高预测样本的效率,我们通常会将 个样本归为一组进行成批地预测:
个样本归为一组进行成批地预测:
![]()
其中![]() 为个样本的特征矩阵,
为个样本的特征矩阵,![]() 为个预测值组成的列向量。
为个预测值组成的列向量。
使用pytorch计算一组输入的净活性值。代码实现如下:
import torch
X = torch.rand([2, 5]) # 2个特征数为5的样本
w = torch.rand([5, 1]) # 含有5个参数的权重向量
b = torch.rand([1, 1]) # 偏置项
z = torch.matmul(X, w) + b # 使用'torch.matmul'实现矩阵相乘
print("input X:\n", X)
print("weight w:\n", w, "\nbias b:", b)
print("output z:\n", z)运行结果:

净活性值再经过一个非线性函数f(⋅)后,得到神经元的活性值 。
。
![]()
注: 在pytorch中,可以使用torch.nn.Linear(features_in, features_out, bias=False)完成输入张量的上述变换。
【思考题】加权求和与仿射变换之间有什么区别和联系?
加权求和可简单看成对输入的信息的线性变换 ,从几何上来看,在变换前后原点是不发生改变的。仿射变换在图形学中也叫仿射映射,是指一个向量空间经过一次线性变换,再经过一次平移,变换为另一个向量空间,因此仿射变换在几何上没有原点保持不变这一特点。只有当仿射变换的平移项 时,仿射变换才变为线性变换。
时,仿射变换才变为线性变换。
例如,平移就不是线性变换而是仿射变换。
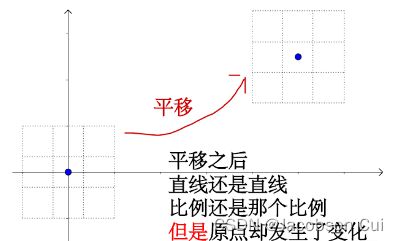
以下是仿射变换的具体定义描述:

借用老师所发资料的描述:
NNDL 实验五 前馈神经网络(1)二分类任务_HBU_David的博客-CSDN博客

4.1.2 激活函数
激活函数通常为非线性函数,可以增强神经网络的表示能力和学习能力。常用的激活函数有S型函数和ReLU函数。
4.1.2.1 Sigmoid 型函数
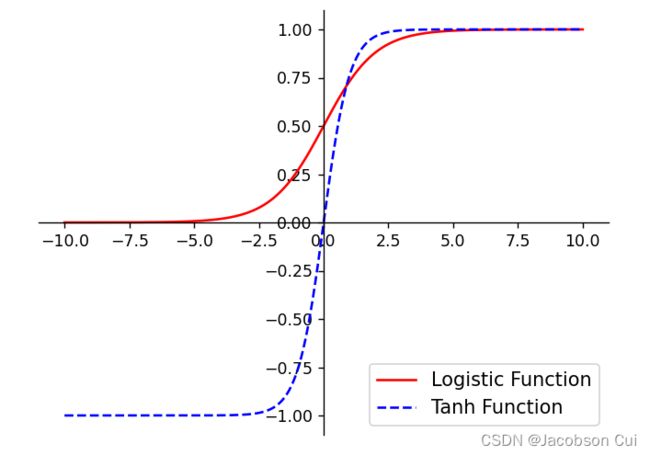
Sigmoid 型函数是指一类S型曲线函数,为两端饱和函数。常用的 Sigmoid 型函数有 Logistic 函数和 Tanh 函数,其数学表达式为
Logistic 函数:
![]()
Tanh 函数:
![]()
Logistic函数和Tanh函数的代码实现和可视化如下:
import matplotlib.pyplot as plt
# Logistic函数
def logistic(z):
return 1.0 / (1.0 + torch.exp(-z))
# Tanh函数
def tanh(z):
return (torch.exp(z) - torch.exp(-z)) / (torch.exp(z) + torch.exp(-z))
# 在[-10,10]的范围内生成10000个输入值,用于绘制函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), logistic(z).tolist(), color='red', label="Logistic Function")
plt.plot(z.tolist(), tanh(z).tolist(), color='blue', linestyle='--', label="Tanh Function")
ax = plt.gca() # 获取轴,默认有4个
# 隐藏两个轴,通过把颜色设置成none
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 调整坐标轴位置
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='lower right', fontsize='large')
plt.savefig('fw-logistic-tanh.pdf')
plt.show()运行结果:
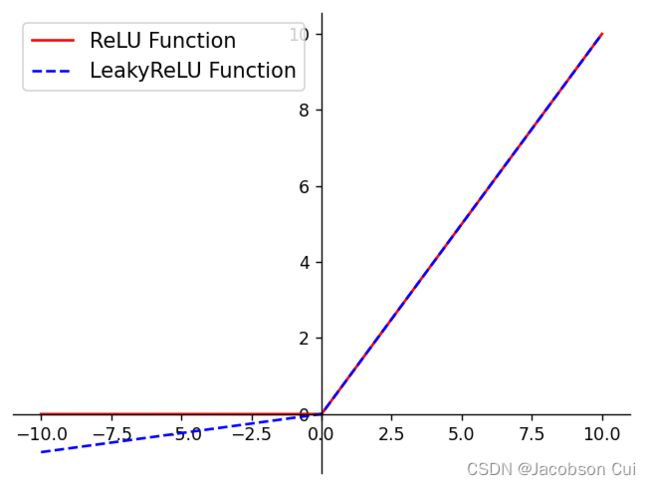
4.1.2.2 ReLU型函数
常见的ReLU函数有ReLU和带泄露的ReLU(Leaky ReLU),数学表达式分别为:
![]()
![]()
其中λ为超参数。
可视化ReLU和带泄露的ReLU的函数的代码实现和可视化如下:
# ReLU
def relu(z):
return torch.maximum(z, torch.tensor(0.))
# 带泄露的ReLU
def leaky_relu(z, negative_slope=0.1):
a1 = (torch.tensor((z > 0), dtype=torch.float32) * z)
a2 = (torch.tensor((z <= 0), dtype=torch.float32) * (negative_slope * z))
return a1 + a2
# 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), relu(z).tolist(), color="red", label="ReLU Function")
plt.plot(z.tolist(), leaky_relu(z).tolist(), color="blue", linestyle="--", label="LeakyReLU Function")
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
plt.legend(loc='upper left', fontsize='large')
plt.savefig('fw-relu-leakyrelu.pdf')
plt.show()运行结果:
《神经网络与深度学习》4.1节中提到的其他激活函数:
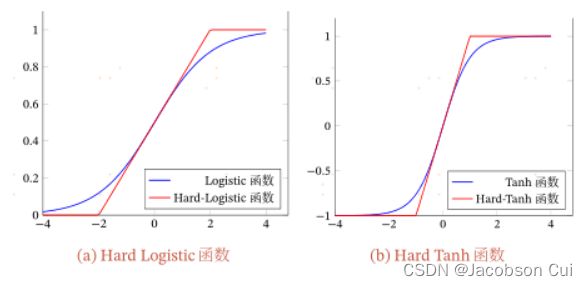
1.Hard-Logistic函数和Hard-Tanh函数
Logistic函数和Tanh函数都是Sigmoid型函数,具有饱和性,但是计算开销较大。Hard_Logistic和Hard_Tanh是前面两种Sigmoid函数的Hard版,解决了两端饱和性问题但依然没解决指数运算量大的问题。比前者们更易进行拟合,两端饱和部分被一阶泰勒展开函数进行线性化处理后在进行梯度计算的时候明显的收敛速度加快。而关于函数是否零中心化此二者与其非Hard版本保持一致,并且继承其前者的其他优点。
2.ELU
ELU(Exponential Linear Unit,指数线性单元)是一个近似的零中心化的非线性函数,其定义为
其中γ≥0是一个超参数,决定x≤0时的饱和曲线,并调整输出均值在0附近。
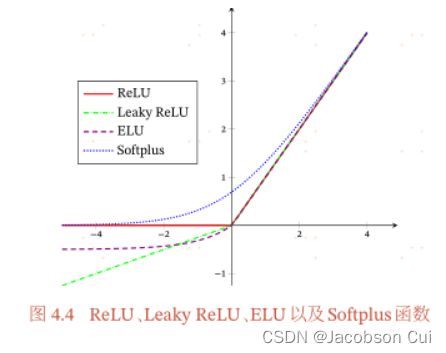
3.Softplus
Softplus函数可以看作Rectifier函数的平滑版本,其定义为:Softplus(x)=log(1+exp(x)). Softplus函数其导数刚好是Logistic函数.Softplus函数虽然也具有单侧抑制、宽兴奋边界的特性,却没有稀疏激活性。
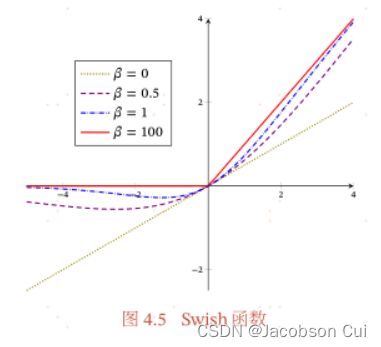
4.Swish函数
Swish函数
是一种自门控(Self-Gated)激活函数,定义为:
其中σ(⋅)为Logistic函数,β为可学习的参数或一个固定超参数.σ(⋅)∈(0,1)可以看作一种软性的门控机制.当σ(βx)接近于1时,门处于“开”状态,激活函数的输出近似于x本身;当σ(βx)接近于0时,门的状态为“关”,激活函数的输出近似于0.
当β=0时,Swish函数变成线性函数x/2;当β=1时,Swish函数在x>0时近似线性,在x<0时近似饱和,同时具有一定的非单调性;当β→+∞时,σ(βx)趋向于离散的0-1函数,Swish函数近似为ReLU函数.因此,Swish函数可以看作线性函数和ReLU函数之间的非线性插值函数,其程度由参数β控制.

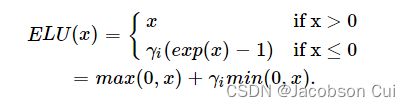
4.2 基于前馈神经网络的二分类任务
前馈神经网络的网络结构如图3所示。每一层获取前一层神经元的活性值,并重复上述计算得到该层的活性值,传入到下一层。整个网络中无反馈,信号从输入层向输出层逐层的单向传播,得到网络最后的输出![]() 。
。
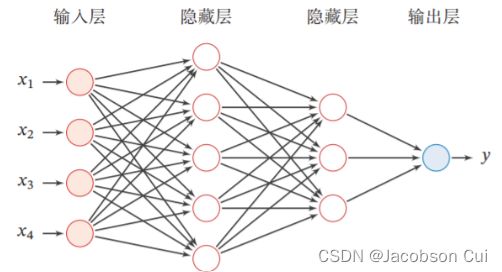 图3-前馈神经网络结构
图3-前馈神经网络结构
4.2.1 数据集构建
使用第3.1.1节中构建的二分类数据集:Moon1000数据集,其中训练集640条、验证集160条、测试集200条。该数据集的数据是从两个带噪音的弯月形状数据分布中采样得到,每个样本包含2个特征。
from nndl.dataset import make_moons
# 采样1000个样本
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1, 1])
y_dev = y_dev.reshape([-1, 1])
y_test = y_test.reshape([-1, 1])运行结果:

4.2.2 模型构建
为了更高效的构建前馈神经网络,我们先定义每一层的算子,然后再通过算子组合构建整个前馈神经网络。
假设网络的第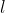 层的输入为第
层的输入为第![]() 层的神经元活性值
层的神经元活性值![]() ,经过一个仿射变换,得到该层神经元的净活性值,再输入到激活函数得到该层神经元的活性值。
,经过一个仿射变换,得到该层神经元的净活性值,再输入到激活函数得到该层神经元的活性值。
在实践中,为了提高模型的处理效率,通常将个样本归为一组进行成批地计算。假设网络第层的输入为![]() ,其中每一行为一个样本,则前馈网络中第层的计算公式为:
,其中每一行为一个样本,则前馈网络中第层的计算公式为:
![]()
![]()
其中![]() 为个样本第层神经元的净活性值,
为个样本第层神经元的净活性值,![]() 为个样本第层神经元的活性值
为个样本第层神经元的活性值![]() 为第层的权重矩阵,
为第层的权重矩阵,![]() 为第层的偏置。
为第层的偏置。
为了和代码的实现保存一致性,这里使用形状为(样本数量×特征维度)的张量来表示一组样本。样本的矩阵 是由个
是由个 的行向量组成。而邱锡鹏老师的《神经网络与深度学习》一书中为列向量,因此这里的权重矩阵
的行向量组成。而邱锡鹏老师的《神经网络与深度学习》一书中为列向量,因此这里的权重矩阵 和偏置与书中的表示刚好为转置关系。
和偏置与书中的表示刚好为转置关系。
为了使后续的模型搭建更加便捷,我们将神经层的计算都封装成算子,这些算子都继承op基类。
4.2.2.1 线性层算子
公式(4.8)对应一个线性层算子,权重参数采用默认的随机初始化,偏置采用默认的零初始化。代码实现如下:
from nndl.op import Op
# 实现线性层算子
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=torch.randn, bias_init=torch.zeros):
self.params = {}
# 初始化权重
self.params['W'] = weight_init([input_size, output_size])
# 初始化偏置
self.params['b'] = bias_init([1, output_size])
self.inputs = None
self.name = name
def forward(self, inputs):
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs4.2.2.2 Logistic算子
本节我们采用Logistic函数来作为公式(4.9)中的激活函数。这里也将Logistic函数实现一个算子,代码实现如下:
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
def forward(self, inputs):
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs4.2.2.3 层的串行组合
在定义了神经层的线性层算子和激活函数算子之后,我们可以不断交叉重复使用它们来构建一个多层的神经网络。
下面我们实现一个两层的用于二分类任务的前馈神经网络,选用Logistic作为激活函数,可以利用上面实现的线性层和激活函数算子来组装。代码实现如下:
# 实现一个两层前馈神经网络
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
self.fc1 = Linear(input_size, hidden_size, name="fc1")
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
def __call__(self, X):
return self.forward(X)
def forward(self, X):
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self.act_fn2(z2)
return a2测试一下
现在,我们实例化一个两层的前馈网络,令其输入层维度为5,隐藏层维度为10,输出层维度为1。并随机生成一条长度为5的数据输入两层神经网络,观察输出结果。
# 实例化模型
model = Model_MLP_L2(input_size=5, hidden_size=10, output_size=1)
# 随机生成1条长度为5的数据
X = torch.rand([1, 5])
result = model(X)
print("result: ", result)运行结果:

4.2.3 损失函数
二分类交叉熵损失函数详情见上一章内容中的3.2.3节:神经网络与深度学习(四)线性分类_Jacobson Cui的博客-CSDN博客
# 实现交叉熵损失函数
class BinaryCrossEntropyLoss(op.Op):
def __init__(self):
self.predicts = None
self.labels = None
self.num = None
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts)) + torch.matmul((1-self.labels.t()), torch.log(1-self.predicts)))
loss = torch.squeeze(loss, axis=1)
return loss4.2.4 模型优化
神经网络的参数主要是通过梯度下降法进行优化的,因此需要计算最终损失对每个参数的梯度。
由于神经网络的层数通常比较深,其梯度计算和上一章中的线性分类模型的不同的点在于:线性模型通常比较简单可以直接计算梯度,而神经网络相当于一个复合函数,需要利用链式法则进行反向传播来计算梯度。
4.2.4.1 反向传播算法
前馈神经网络的参数梯度通常使用误差反向传播算法来计算。使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:
- 前馈计算每一层的净活性值
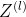 和激活值
和激活值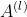 ,直到最后一层;
,直到最后一层; - 反向传播计算每一层的误差项
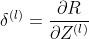 ;
; - 计算每一层参数的梯度,并更新参数。
在上面实现算子的基础上,来实现误差反向传播算法。在上面的三个步骤中,
- 第1步是前向计算,可以利用算子的
forward()方法来实现; - 第2步是反向计算梯度,可以利用算子的
backward()方法来实现; - 第3步中的计算参数梯度也放到
backward()中实现,更新参数放到另外的优化器中专门进行。
这样,在模型训练过程中,我们首先执行模型的forward(),再执行模型的backward(),就得到了所有参数的梯度,之后再利用优化器迭代更新参数。
以这我们这节中构建的两层全连接前馈神经网络Model_MLP_L2为例,下图给出了其前向和反向计算过程:
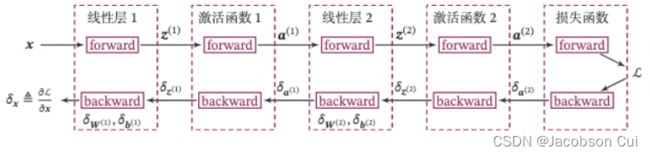
下面我们按照反向的梯度传播顺序,为每个算子添加backward()方法,并在其中实现每一层参数的梯度的计算。
4.2.4.2 损失函数
二分类交叉熵损失函数对神经网络的输出 的偏导数为:
的偏导数为:
![]()
![]()
其中![]() 表示以向量为对角元素的对角阵,
表示以向量为对角元素的对角阵,![]() 表示逐元素除,
表示逐元素除, 表示逐元素积。
表示逐元素积。
实现损失函数的backward(),代码实现如下:
# 实现交叉熵损失函数
class BinaryCrossEntropyLoss(Op):
def __init__(self, model):
self.predicts = None
self.labels = None
self.num = None
self.model = model
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts))
+ torch.matmul((1 - self.labels.t()), torch.log(1 - self.predicts)))
loss = torch.squeeze(loss, dim=1)
return loss
def backward(self):
# 计算损失函数对模型预测的导数
loss_grad_predicts = -1.0 * (self.labels / self.predicts -
(1 - self.labels) / (1 - self.predicts)) / self.num
# 梯度反向传播
self.model.backward(loss_grad_predicts)4.2.4.3 Logistic算子
在本节中,我们使用Logistic激活函数,所以这里为Logistic算子增加的反向函数。
Logistic算子的前向过程表示为![]() ,其中
,其中 为Logistic函数,
为Logistic函数,![]() 和
和![]() 的每一行表示一个样本。
的每一行表示一个样本。
为了简便起见,我们分别用向量![]() 和
和![]() 表示同一个样本在激活函数前后的表示,则对的偏导数为:
表示同一个样本在激活函数前后的表示,则对的偏导数为:
![]()
按照反向传播算法,令![]() 表示最终损失
表示最终损失 对Logistic算子的单个输出的梯度,则
对Logistic算子的单个输出的梯度,则
![]()
![]()
将上面公式利用批量数据表示的方式重写,令![]() 表示最终损失对Logistic算子输出
表示最终损失对Logistic算子输出 的梯度,损失函数对Logistic函数输入
的梯度,损失函数对Logistic函数输入 的导数为
的导数为
![]()
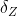 为Logistic算子反向传播的输出。
为Logistic算子反向传播的输出。
由于Logistic函数中没有参数,这里不需要在backward()方法中计算该算子参数的梯度。
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
self.params = None
def forward(self, inputs):
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
def backward(self, grads):
# 计算Logistic激活函数对输入的导数
outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))
return torch.multiply(grads, outputs_grad_inputs)4.2.4.4 线性层
线性层算子Linear的前向过程表示为![]() ,其中输入为
,其中输入为![]() ,输出为
,输出为![]() ,参数为权重矩阵
,参数为权重矩阵![]() 和偏置
和偏置![]() 。和
。和 中的每一行表示一个样本。
中的每一行表示一个样本。
为了简便起见,我们用向量![]() 和
和![]() 表示同一个样本在线性层算子中的输入和输出,则有
表示同一个样本在线性层算子中的输入和输出,则有![]() 。
。 对输入的偏导数为
对输入的偏导数为
![]()
线性层输入的梯度 按照反向传播算法,令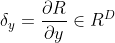 表示最终损失对线性层算子的单个输出的梯度,则
表示最终损失对线性层算子的单个输出的梯度,则
![]()
将上面公式利用批量数据表示的方式重写,令![]() 表示最终损失对线性层算子输出的梯度,公式可以重写为
表示最终损失对线性层算子输出的梯度,公式可以重写为
![]()
其中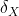 为线性层算子反向函数的输出。
为线性层算子反向函数的输出。
计算线性层参数的梯度 由于线性层算子中包含有可学习的参数和,因此backward()除了实现梯度反传外,还需要计算算子内部的参数的梯度。
令![]() 表示最终损失对线性层算子的单个输出的梯度,则
表示最终损失对线性层算子的单个输出的梯度,则
![]()
![]()
将上面公式利用批量数据表示的方式重写,令![]() 表示最终损失对线性层算子输出的梯度,则公式可以重写为
表示最终损失对线性层算子输出的梯度,则公式可以重写为
![]()
![]()
具体实现代码如下:
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=torch.randn, bias_init=torch.zeros):
self.params = {}
self.params['W'] = weight_init([input_size, output_size])
self.params['b'] = bias_init([1, output_size])
self.inputs = None
self.grads = {}
self.name = name
def forward(self, inputs):
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs
def backward(self, grads):
self.grads['W'] = torch.matmul(self.inputs.T, grads)
self.grads['b'] = torch.sum(grads, dim=0)
# 线性层输入的梯度
return torch.matmul(grads, self.params['W'].T)4.2.4.5 整个网络
实现完整的两层神经网络的前向和反向计算。代码实现如下:
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
# 线性层
self.fc1 = Linear(input_size, hidden_size, name="fc1")
# Logistic激活函数层
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
self.layers = [self.fc1, self.act_fn1, self.fc2, self.act_fn2]
def __call__(self, X):
return self.forward(X)
# 前向计算
def forward(self, X):
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self.act_fn2(z2)
return a2
# 反向计算
def backward(self, loss_grad_a2):
loss_grad_z2 = self.act_fn2.backward(loss_grad_a2)
loss_grad_a1 = self.fc2.backward(loss_grad_z2)
loss_grad_z1 = self.act_fn1.backward(loss_grad_a1)
loss_grad_inputs = self.fc1.backward(loss_grad_z1)4.2.4.6 优化器
在计算好神经网络参数的梯度之后,我们将梯度下降法中参数的更新过程实现在优化器中。
与第3章中实现的梯度下降优化器SimpleBatchGD不同的是,此处的优化器需要遍历每层,对每层的参数分别做更新。
from nndl.opitimizer import Optimizer
class BatchGD(Optimizer):
def __init__(self, init_lr, model):
super(BatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# 参数更新
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
for key in layer.params.keys():
layer.params[key] = layer.params[key] - self.init_lr * layer.grads[key]4.2.5 完善Runner类:RunnerV2_1
基于3.1.6实现的 RunnerV2 类主要针对比较简单的模型。而在本章中,模型由多个算子组合而成,通常比较复杂,因此本节继续完善并实现一个改进版: RunnerV2_1类,其主要加入的功能有:
- 支持自定义算子的梯度计算,在训练过程中调用
self.loss_fn.backward()从损失函数开始反向计算梯度; - 每层的模型保存和加载,将每一层的参数分别进行保存和加载。
import os
class RunnerV2_1(object):
def __init__(self, model, optimizer, metric, loss_fn, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
# 记录训练过程中的评估指标变化情况
self.train_scores = []
self.dev_scores = []
# 记录训练过程中的评价指标变化情况
self.train_loss = []
self.dev_loss = []
def train(self, train_set, dev_set, **kwargs):
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_epochs = kwargs.get("log_epochs", 100)
# 传入模型保存路径
save_dir = kwargs.get("save_dir", None)
# 记录全局最优指标
best_score = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
X, y = train_set
# 获取模型预测
logits = self.model(X)
# 计算交叉熵损失
trn_loss = self.loss_fn(logits, y) # return a tensor
self.train_loss.append(trn_loss.item())
# 计算评估指标
trn_score = self.metric(logits, y).item()
self.train_scores.append(trn_score)
self.loss_fn.backward()
# 参数更新
self.optimizer.step()
dev_score, dev_loss = self.evaluate(dev_set)
# 如果当前指标为最优指标,保存该模型
if dev_score > best_score:
print(f"[Evaluate] best accuracy performence has been updated: {best_score:.5f} --> {dev_score:.5f}")
best_score = dev_score
if save_dir:
self.save_model(save_dir)
if log_epochs and epoch % log_epochs == 0:
print(f"[Train] epoch: {epoch}/{num_epochs}, loss: {trn_loss.item()}")
def evaluate(self, data_set):
X, y = data_set
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
self.dev_loss.append(loss)
# 计算评估指标
score = self.metric(logits, y).item()
self.dev_scores.append(score)
return score, loss
def predict(self, X):
return self.model(X)
def save_model(self, save_dir):
# 对模型每层参数分别进行保存,保存文件名称与该层名称相同
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
torch.save(layer.params, os.path.join(save_dir, layer.name+".pdparams"))
def load_model(self, model_dir):
# 获取所有层参数名称和保存路径之间的对应关系
model_file_names = os.listdir(model_dir)
name_file_dict = {}
for file_name in model_file_names:
name = file_name.replace(".pdparams", "")
name_file_dict[name] = os.path.join(model_dir, file_name)
# 加载每层参数
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
name = layer.name
file_path = name_file_dict[name]
layer.params = torch.load(file_path)4.2.6 模型训练
基于RunnerV2_1,使用训练集和验证集进行模型训练,共训练2000个epoch。评价指标为第章介绍的accuracy。代码实现如下:
from nndl.metric import accuracy
torch.manual_seed(123)
epoch_num = 1000
model_saved_dir = "model"
# 输入层维度为2
input_size = 2
# 隐藏层维度为5
hidden_size = 5
# 输出层维度为1
output_size = 1
# 定义网络
model = Model_MLP_L2(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 损失函数
loss_fn = BinaryCrossEntropyLoss(model)
# 优化器
learning_rate = 0.2
optimizer = BatchGD(learning_rate, model)
# 评价方法
metric = accuracy
# 实例化RunnerV2_1类,并传入训练配置
runner = RunnerV2_1(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=epoch_num, log_epochs=50, save_dir=model_saved_dir)运行结果:
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.50000
[Train] epoch: 0/1000, loss: 0.7837428450584412
[Evaluate] best accuracy performence has been updated: 0.50000 --> 0.55625
[Evaluate] best accuracy performence has been updated: 0.55625 --> 0.66250
[Evaluate] best accuracy performence has been updated: 0.66250 --> 0.69375
[Evaluate] best accuracy performence has been updated: 0.69375 --> 0.70000
[Evaluate] best accuracy performence has been updated: 0.70000 --> 0.73750
[Evaluate] best accuracy performence has been updated: 0.73750 --> 0.74375
[Evaluate] best accuracy performence has been updated: 0.74375 --> 0.75625
[Evaluate] best accuracy performence has been updated: 0.75625 --> 0.76250
[Evaluate] best accuracy performence has been updated: 0.76250 --> 0.76875
[Evaluate] best accuracy performence has been updated: 0.76875 --> 0.77500
[Evaluate] best accuracy performence has been updated: 0.77500 --> 0.78750
[Evaluate] best accuracy performence has been updated: 0.78750 --> 0.79375
[Evaluate] best accuracy performence has been updated: 0.79375 --> 0.80000
[Train] epoch: 50/1000, loss: 0.6765806674957275
[Evaluate] best accuracy performence has been updated: 0.80000 --> 0.80625
[Train] epoch: 100/1000, loss: 0.6159222722053528
[Train] epoch: 150/1000, loss: 0.5496628880500793
[Train] epoch: 200/1000, loss: 0.5038267374038696
[Train] epoch: 250/1000, loss: 0.48039698600769043
[Train] epoch: 300/1000, loss: 0.4689186215400696
[Train] epoch: 350/1000, loss: 0.46293506026268005
[Train] epoch: 400/1000, loss: 0.45961514115333557
[Train] epoch: 450/1000, loss: 0.45769912004470825
[Train] epoch: 500/1000, loss: 0.45656299591064453
[Evaluate] best accuracy performence has been updated: 0.80625 --> 0.81250
[Train] epoch: 550/1000, loss: 0.4558698832988739
[Evaluate] best accuracy performence has been updated: 0.81250 --> 0.81875
[Train] epoch: 600/1000, loss: 0.4554292857646942
[Train] epoch: 650/1000, loss: 0.45513463020324707
[Train] epoch: 700/1000, loss: 0.4549262225627899
[Train] epoch: 750/1000, loss: 0.45476943254470825
[Train] epoch: 800/1000, loss: 0.4546455442905426
[Train] epoch: 850/1000, loss: 0.45454326272010803
[Train] epoch: 900/1000, loss: 0.45445701479911804
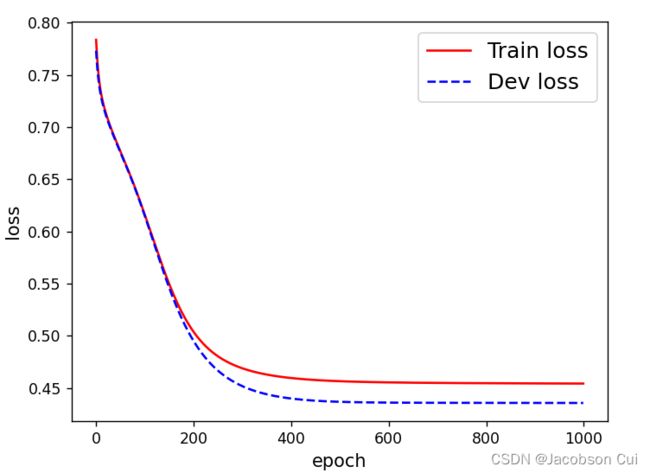
[Train] epoch: 950/1000, loss: 0.4543817639350891可视化观察训练集与验证集的损失函数变化情况。
# 打印训练集和验证集的损失
plt.figure()
plt.plot(range(epoch_num), runner.train_loss, color="red", label="Train loss")
plt.plot(range(epoch_num), runner.dev_loss, color="blue", linestyle='--', label="Dev loss")
plt.xlabel("epoch", fontsize='large')
plt.ylabel("loss", fontsize='large')
plt.legend(fontsize='x-large')
plt.savefig('fw-loss2.pdf')
plt.show()
#加载训练好的模型
runner.load_model(model_saved_dir)
# 在测试集上对模型进行评价
score, loss = runner.evaluate([X_test, y_test])运行结果:
4.2.7 性能评价
使用测试集对训练中的最优模型进行评价,观察模型的评价指标。代码实现如下:
# 加载训练好的模型
runner.load_model(model_saved_dir)
# 在测试集上对模型进行评价
score, loss = runner.evaluate([X_test, y_test])
print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))运行结果:
![]()
从结果来看,模型在测试集上取得了较高的准确率。
下面对结果进行可视化:
import math
x1, x2 = torch.meshgrid(torch.linspace(-math.pi, math.pi, 200), torch.linspace(-math.pi, math.pi, 200), indexing='ij')
x = torch.stack([torch.flatten(x1), torch.flatten(x2)], dim=1)
# 预测对应类别
y = runner.predict(x)
y = torch.squeeze((y >= 0.5).to(torch.float32), dim=-1)
# 绘制类别区域
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(x[:, 0].tolist(), x[:, 1].tolist(), c=y.tolist(), cmap=plt.cm.Spectral)
plt.scatter(X_train[:, 0].tolist(), X_train[:, 1].tolist(), marker='*', c=torch.squeeze(y_train, dim=-1).tolist())
plt.scatter(X_dev[:, 0].tolist(), X_dev[:, 1].tolist(), marker='*', c=torch.squeeze(y_dev, dim=-1).tolist())
plt.scatter(X_test[:, 0].tolist(), X_test[:, 1].tolist(), marker='*', c=torch.squeeze(y_test, dim=-1).tolist())
plt.show()运行结果:

【思考题】对比3.1 基于Logistic回归的二分类任务和 4.2 基于前馈神经网络的二分类任务谈谈自己的看法。
基于Logistic回归的二分类任务为线性模型,通常可直接计算出梯度,而神经网络在计算梯度时则相对比较复杂,需要使用反向传播来计算梯度。相较于基于Logistic回归的二分类任务,在大样本的情况下基于前馈神经网络的二分类任务的优势更大。基于Logistic回归的二分类任务的正确率受随机误差大小和变量个数的影响大,基于前馈神经网络的二分类任务的正确率受样本数量的影响大。
总结
本次实验在熟悉神经网络的同时,还了解了加权求和和仿射变换的区别以及Hard-Logistic、Hard-Tanh、ELU、Softplus、Swish等各种激活函数的特点。并基于前馈神经网络实现了二分类任务,其中在保存模型的时候,因为没有创建对应文件夹这种低级错误而出现了报错,在查阅网上教程后发现了问题并得到了解决。
参考资料
NNDL 实验4(上) - HBU_DAVID - 博客园
神经元与常用的激活函数 - wsg_blog - 博客园
FileNotFoundError: [Errno 2] No such file or directory: './download/js-tutorial.html' - 青春叛逆者 - 博客园