[23-24 秋学期] NNDL-作业2 HBU
前言:
本文解决《神经网络与深度学习》-邱锡鹏 第二章课后题。
对于习题2-1,平方损失函数在机器学习课程中学习过,但是惭愧的讲,在完成这篇博客前我对均方误差和平方损失函数的概念还有些混淆。交叉熵损失函数我未曾了解过,只在决策树一节中学习过关于熵entropy的基本概念。借此机会弄清原理,并且尝试着学会应用它。
对于习题2-12,考察对混淆矩阵的理解程度和计算。其中宏平均和微平均是我未曾学习过的概念,借此机会弄清原理,并且尝试着学会应用它。
题目:
习题 2-1: 分析为什么平方损失函数不适用于分类问题,交叉熵损失函数不适用于回归问题。
习题 2-12 :对于一个三分类问题,数据集的真实标签和模型的预测标签如下:
![[23-24 秋学期] NNDL-作业2 HBU_第1张图片](http://img.e-com-net.com/image/info8/6f43f22db73345d6b4e42fb921eb9a60.jpg)
分别计算模型的精确率、召回率、F1值以及它们的宏平均和微平均。
习题 2-1
问题重述:分析 (1)为什么平方损失函数不适用于分类问题。
(2)为什么交叉熵损失函数不适用于回归问题。
首先,分类问题和回归问题的概念在机器学习课程中已经学习过,不再赘述。
(1) 那么何为平方损失函数? 损失函数是一个非负实数函数,用来量化模型预测和真是标签之间的差异。平方损失函数经常用于预测标签为实数值的任务之中。
给出平方损失函数公式, 为真实值,
为真实值,![]() 为预测值: (在公式前乘以1/2也正确)
为预测值: (在公式前乘以1/2也正确)
![]()
平方损失函数计算的是预测值和真实值距离的平方和,最终目的是缩小预测值和真实值之间的距离。而分类问题中的标签是没有“连续”这一概念的,分类问题的结果都是离散值,每个标签之间的“距离”是没有意义的,所以预测值和实际值这两个向量值之间的距离不能反映分类问题的优化程度。
例如,将西瓜的色泽属性 "浅白" "乌黑" "青绿" 分别标号为0,1,2。假设真实分类标签为0,那么预测为1,2标签的错误程度是一样的。 假设使用标签的“距离”差异来展示问题的优化程度,则会出现:预测值为1时,距离0的差异 和 预测值为2时,距离0的差异程度明显不同。这就导致了原本是同一程度的错误,却被定义了不同程度的值,这就对问题的优化产生了误导。
因此,平方损失函数不适用解决分类问题,而适合解决回归问题。
(2) 交叉熵是什么? 在机器学习中,我们已知熵entropy的公式为:
![]()
交叉熵损失函数(Cross Entropy Loss Function)的公式为:
![]()
其中,
M -- 表示类别数量。
![]() -- 表示0或1。若样本的真实类别等于c,则取1,否则取0。
-- 表示0或1。若样本的真实类别等于c,则取1,否则取0。
![]() -- 观测样本i属于类别c的预测概率。
-- 观测样本i属于类别c的预测概率。
回归问题的目标是预测连续变量,而分类问题的目标是预测离散变量。
在分类问题中,交叉熵损失函数计算的是预测的类别概率分布与真实的类别概率分布之间的差异。对于每个样本,交叉熵损失函数计算其预测类别概率与真实类别的对数似然损失。这种损失函数在分类问题中表现良好,因为它能够度量预测的概率分布与真实的概率分布之间的相似性。
交叉熵损失函数不适合解决回归问题的主要原因是它无法直接反映回归问题中预测值与真实值之间的差异。
习题2-12
本题中需要计算的评估指标有:
1. 精确率(查准率)--Precision
2. 召回率(查全率)--Recall
3.F1值
4.宏平均--Macro-averaging
5.微平均--
在混淆矩阵中,永远是真实值在前,预测值在后。下图为二分类混淆矩阵:
![[23-24 秋学期] NNDL-作业2 HBU_第2张图片](http://img.e-com-net.com/image/info8/ad90b7e887d94a2287f6f24a16ff5e9a.jpg)
二分类混淆矩阵(Confusion Matrix)的四种情况:
.TP – True Positive 实际为正,预测也为正 (机器判断正确)
.FN – False Negative 实际为正,预测为反 (机器判断错误)
.TN – True Negative 实际为反,判断为反 (机器判断正确)
.FP – False Positive 实际为反,判断为正 (机器判断错误)
区分机器判断与实际值:(图片来自文章)
![[23-24 秋学期] NNDL-作业2 HBU_第3张图片](http://img.e-com-net.com/image/info8/c7e39f59f1bd4f7cbc32dfc9a24818bb.jpg)
在多分类混淆矩阵中,
精确率是指对于一个多分类问题,模型预测正确的样本数占总样本数的比例。计算公式为:
![]()
召回率(查全率)是指对于一个多分类问题,模型正确预测的样本数占所有真实属于该类别的样本数的比例。计算公式为:
![]()
F1值是精确率和召回率的调和平均数,其中P表示精确率,R表示召回率。计算公式为:
![]()
宏平均:先对每一个类统计指标值,然后再对所有类求算术平均值。
微平均:对数据集中的每一个实例不分类进行统计建立全局混淆矩阵,然后计算相应指标。
根据公式,可以求得在三分类模型中的模型评价指标分别为:
精确率计算:
公式: ![]()
![]()
![]()
![]()
召回率(查全率)计算:
公式: ![]()
![]()
![]()
![]()
F1值计算:(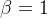 时为F1值)
时为F1值)
公式: ![]()
![]()
![]()
![]()
宏平均计算:
. 宏平均准确率:
![]()
.宏平均召回率:
![]()
.宏平均F1分数:
![]()
微平均计算:
.微平均精确率:
![]()
.微平均召回率:
![]()
.微平均F1分数:
![]()
思考:
宏平均和微平均的区别是什么?
宏平均的计算方法独立于不同类别,将每个类别的P、R、F值单独计算出来,然后将所有类别的度量值直接平均,因此它将各个类别平等对待。
微平均会结合不同类别的贡献大小来计算平均值。
所以在多分类问题中,如果存在数据不平衡问题,则使用微平均得到的效果更加可信。
本文所借鉴的优秀博客、文章,在此鸣谢:
https://www.cnblogs.com/robert-dlut/p/5276927.html
宏平均 / 微平均 - 知乎
分类问题不使用平方损失函数的原因_分类问题为什么不用平方误差_I AM A BIG SHARK的博客-CSDN博客
一文总结损失函数和评价指标 - 知乎 (zhihu.com)
为什么平方损失函数不适用于分类问题?_Refrain*的博客-CSDN博客
损失函数|交叉熵损失函数 (zhihu.com)
一文搞懂熵(Entropy),交叉熵(Cross-Entropy) - 知乎 (zhihu.com)