2022大规模电商图上的风险商品检测
文章目录
- 前言
- 赛题数据
- 模型与方法介绍
-
- R-GCN
- R-GAT
- HAN
- GraphSAGE
- 模型评估与结果分析
-
- 模型评估方式
- 实验环境
- 模型参数设置与结果
-
- R-GCN
- GAT、R-GAT、HAN(图注意力网络)
- 小结
- 参考文献
前言
因为我用这个比赛来抵专业实践,现在成绩出来了,就发一发吧。
近年来,图计算尤其是图神经网络等技术获得了快速的发展以及广泛的应用。在电商平台上的风险商品检测场景中,黑灰产和风控系统之间存在着激烈的对抗,黑灰产为了躲避平台管控,会蓄意掩饰风险信息,通过引入场景中存在的图数据,可以缓解因黑灰产对抗带来的检测效果下降。
在实际应用中,图算法的效果往往和图结构的质量紧密相关,由于风险商品检测场景中对抗的存在,恶意用户会通过伪造设备、伪造地址等方式,伪造较为“干净”的关联关系。如何能够在这种存在着存在大量噪声的图结构数据中充分挖掘风险信息,是一个十分有挑战性的问题,另外该场景中还存在着黑白样本严重不均衡,图结构规模巨大且异构等多种挑战。
本次比赛阿里巴巴平台提供了来源于真实场景的风险商品检测数据,需要参赛者利用大规模的异构图结构以及比例不均衡的黑白样本,利用图算法,检测出风险商品。
赛题数据
首先,比赛提供的数据集的大致结构如图1.1所示,是一张拥有不同节点类型和边类型的异构图。图中各个节点特征为256维的向量表征,商品表征为预训练模型生成,其他类型节点表征使用关联商品的表征进行平均得到。
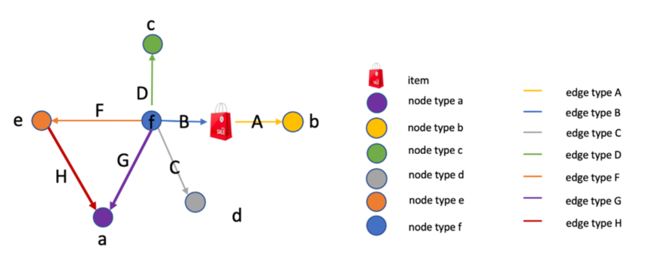
异构图拥有7种不同类型的节点和7种不同类型的边,节点数有13806619,边数有157814964,是一张比较大的异构图,并且可以看到,训练的节点样本中。存在正负样本不平衡的情况,并且赛题中指出图结构中存在大量噪声,即很多的边和标签之间并没有很强的关联。因此面对一个如此大的图、不平衡的训练数据集以及存在大量噪声的图结构,使得风险商品检测更具有挑战性。
模型与方法介绍
R-GCN
R-GCN[1]是由阿姆斯特丹大学的Micharl Schlichtkrull, Thomas N.Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, Max Welling 发表在 ESWC 2018年会议上的一篇文章提出的。R-GCN是对于GCN的一种改进,考虑了节点之间的关系,更加符合实际情况。其更新公式如公式2.1.1所示:


R-GAT



HAN
HAN[4]是一种专门为异构图提出的一种分层注意力网络,包括节点级注意力和语义级注意力,具体地说,节点地注意力机制旨在学习相同元路径的邻居之间的重要性,而语义级注意力机制旨在学习不同元路径的重要性。通过节点级和语义级两个层次上学习重要性,可以充分考虑节点和元路径的重要性。其中,节点级的多头注意力机制计算公式如公式2.3.1和公式2.3.2所示:
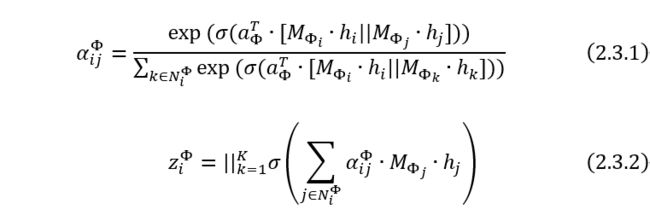

GraphSAGE
GraphSAGE[5]的核心思想是训练一个采样聚合器,由于不依赖原有的图结构,使得图神经网络模型能够扩展成为inductive模型,即面对模型未曾见过的图结构仍然能够进行预测,使得模型的泛化性更强。
如果需要进行大规模异构图的图神经网络训练,要是直接将整张图直接放入训练,很容易就超过一块GPU的现存了。因此可以使用GraphSAGE中邻居采样的思路,将一张大图分成若干minbatch进行训练,使得大图的训练变得方便可靠。
模型评估与结果分析
模型评估方式

具体可以参考我的博客:机器学习之分类模型评估指标及sklearn代码实现
实验环境
使用启智AI协作平台。实验配置:A100型号GPU:1、CPU数:8、内存(MB):65536、共享内存(MB):32768、Linux操作系统。
相关包依赖:torch=1.11.0、dgl=0.8.2post1、python=3.8.12。
模型参数设置与结果
实验设置模型最大训练epochs=500,early stopping epochs=20
R-GCN

基于Baseline的参数设置,我还对模型参数调整,由于正样本远少于负样本,对于正负样本不平衡的情况,采用欠采样的方式,即固定训练数据中的正样本,每轮训练再随机选取等量的负样本进行训练,模型使用AP衡量,结果如表3.2所示:

通过实验结果可以发现,网络层数并不是越深越好,当R-GCN网络达到3层时模型表现最好,因为当层数过多时,会导致节点特征过度平滑,使得每个节点的特征表示趋同,从而使得图神经网络失去原有的作用,导致表现不佳;由于原始数据并没有自连的边,当增加节点自连之后,使得更新特征时能够考虑到自身的特征,从而达到比较好的效果;对于正负样本不均衡,采用欠采样的方式进行调整,能够使得模型训练结果得到进一步的提升。
GAT、R-GAT、HAN(图注意力网络)


其中R-GAT中的关系使用14维的one-hot编码表示,用于计算关系注意力权重。
从实验结果可以看到,图注意网络中,欠采样的方式并没有明显提高模型的表现,究其原因,因为图注意力网络需要大量的训练数据才能够取得比较好的效果,欠采样的方式使得每次训练都只包含一小部分的数据集,从而使得注意力模型无法得到充分的训练,导致模型表现不佳;同时我们能够发现,图注意力网络中使用残差连接能够获得比较好的效果提升,因为图注意力网络中没有使用节点自连,而是使用残差连接来弥补自身特征传递的缺失。在已经尝试的图注意力网络模型中,HAN的表现最优,说明分层注意力机制的确能够对异构图有较好的表示能力。
小结
通过对比两类图神经网络模型以及不同参数的调整可以发现,R-GCN模型并不需要大量数据就能够训练出比较好的结果,而图注意力网络模型往往都需要大量的数据。再者,无论是R-GCN的节点自连还是注意力网络的残差连接,都是为了传递节点更新时自身的特征信息,实验效果都得到了提升,说明节点更新时自身特征的考虑是至关重要的。最后,图神经网络的层数并不能无限叠加,一般两到三层就是比较理想的层数,因为层数过多会导致节点特征过度平滑,使得节点之间的特征趋同,从而使得图神经网络的表现变得很差。
最终的结果是R-GCN的结果要优于已经尝试的图注意力网络,测试集AP为0.921276,比赛排名为109/223(2022/8/15 8:29)。因为赛题中给出的数据集存在较大的噪声,而图注意力模型对训练数据有较高的要求,从而受到数据噪声影响较大使得注意力模型表现不佳。
参考文献
[1] Schlichtkrull, Michael, et al. “Modeling relational data with graph convolutional networks.” European semantic web conference. Springer, Cham, 2018.
[2] Wang, Kai, et al. “Relational graph attention network for aspect-based sentiment analysis.” arXiv preprint arXiv:2004.12362 (2020).
[3] Veličković, Petar, et al. “Graph attention networks.” arXiv preprint arXiv:1710.10903 (2017). [4] Wang, Xiao, et al. “Heterogeneous graph attention network.” The world wide web conference. 2019.
[5] Hamilton, Will, Zhitao Ying, and Jure Leskovec. “Inductive representation learning on large graphs.” Advances in neural information processing systems 30 (2017).