一个查询优化
有个查询,查猪(biz_pig)及猪在历史某个时刻所在批次(biz_pigbatch)。下面是经过简化的sql
一开始写的sql
SET @PigFarmID=2208151615480000076, @EnterpriseID=1805366,@strDate='2022-10-1';
select
p.PigID ,
pb.BatchID
from biz_pig p
left join ( select BatchID from (
SELECT BatchID FROM `biz_pigbatch`
where datadate<=@strDate order by datadate ) AA
group by AA.pigid) pb ON p.PigID = pb.PigID
where p.EnterpriseID = @EnterpriseID
逻辑大致讲一下。临时表AA,是查出某个时间之前的批次数据,并按时间降序,将后面的数据排在前面。
pb表 是AA表经过pigid分组,每组中取到第一行的BatchID。得到这个pigid在@strDate之前,最后一个批次。也就是pigid在@strDate时,所在的批次。
为什么要加一个临时表AA,是因为AA是经过排序的。如果不要这个临时表,直接在一个表上先排序,后分组是有语法问题的。
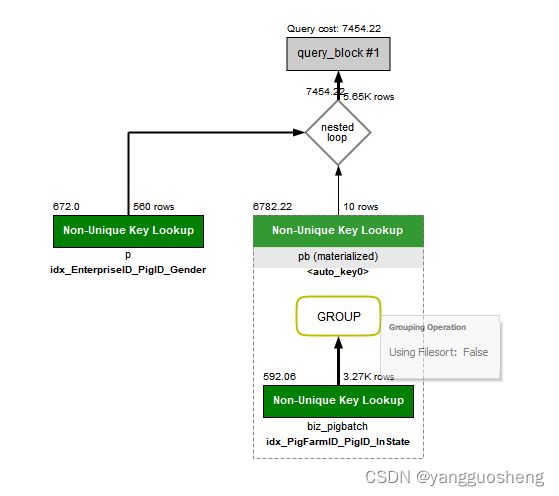
看执行分析,biz_pigbatch表会查出上千条数据(总共上万条),Non-Unique Key Lookup
同事改了一版
SET @PigFarmID=2208151615480000076, @EnterpriseID=1805366,@strDate='2022-10-1';
SELECT
p.PigID ,
pb.BatchID
FROM biz_pig P
LEFT JOIN biz_pigbatch PB ON PB.RecordID = (
SELECT PB_T.RecordID
FROM biz_pigbatch PB_T
WHERE PB_T.PigID = P.PigID AND PB_T.DataDate <= @strDate ORDER BY PB_T.DataDate DESC,PB_T.RecordID DESC LIMIT 1
)
where p.EnterpriseID = @EnterpriseID
如果用变量,查询直接超时,看执行分析biz_pigbatch PB表会full index scan。几乎查出所有数据。

但是如果把变量直接写死,查询就会很快。执行计划如下。
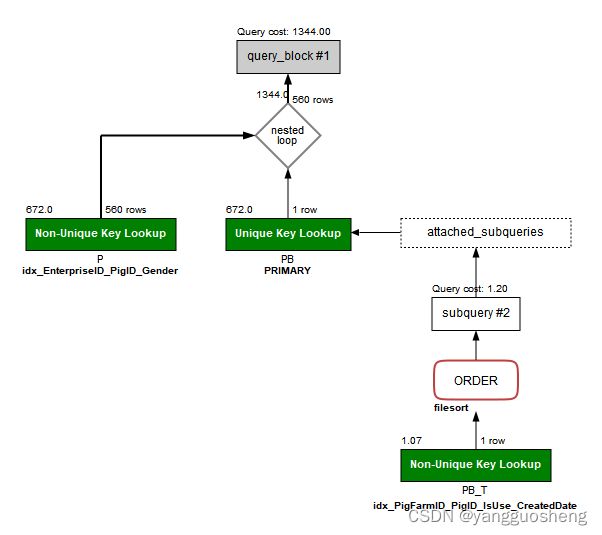
第一点:变量会导致执行计划不同。猜测是如果用常量,mysql会针对这个常量查询出来的数据优化执行计划。但是如果用变量,mysql认为这个值是会变化的,就不用根据当前值分析执行计划。而是考虑所有情况,给出最佳执行方案。
第二点:同事写的版本是我不知道的查询方式,left join的连接条件不再是主表的字段。而是一个子查询。这样就能将主表的 p.PigID条件直接作用在子查询上。而且子查询还是查要连接的表biz_pigbatch,直接定位到主键。biz_pigbatch 表就只需要查一条数据。之前因为多层嵌套,只能用在最外层,导致内部会查询出很多数据。
突破点是连接条件的一端可以是子查询。思路过程可能是这样的,我的第一版sql关联需要查出很多数据。那么怎么关联才能一对一呢,肯定无法直接拼关联条件。如果连接条件的一端是子查询,子查询能找到biz_pigbatch的主键RecordID就ok。
而且严谨,考虑到了biz_pigbatch表DataDate相同的情况。