深度学习《InfoGAN模型》
一:网络介绍
普通的GAN网络的特点是无约束,对网络输入的噪声也不好解释,CGAN中我们通过给噪声合并一些类别数据,改变了输出形式,可以训练出我们指定类别的数据,这一点也是某种程度的解释,但是解释性不强。
InfoGAN 主要特点是对GAN进行了一些改动,成功地让网络学到了可解释的特征,网络训练完成之后,我们可以通过设定输入生成器的隐含编码来控制生成数据的特征。
InfoGAN将输入生成器的随机噪声分成了两部分:一部分是随机噪声Z, 另一部分是由若干隐变量拼接而成的latent code c。其中,c会有先验的概率分布,可以是离散数据,也可以是连续数据,用来代表生成数据的不同特征。例如:对于MNIST数据集,c既包含离散部分也包含了连续部分,离散部分取值为0~9的离散随机变量(表示数字的类别),连续部分有两个连续型随机变量(分别表示倾斜度和粗细度)。其网络结构如下图:

其中,真实数据Real_data只是用来跟生成的Fake_data混合在一起进行真假判断,并根据判断的结果更新生成器和判别器,从而使生成的数据与真实数据接近。生成数据既要参与真假判断,还需要和隐变量C_vector求互信息,并根据互信息更新生成器和判别器,从而使得生成图像中保留了更多隐变量C_vector的信息。
InfoGAN网络结构还可以看成是如下形式:
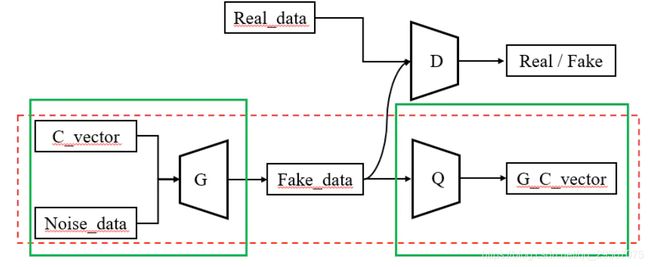
G网络相当于是encoder,Q网络相当于是decoder,整个红色框框就是一个编码器结构,生成数据Fake_data相当于对输入隐变量C_vector的编码,只不过将编码还要输出给D网络去判别。其中和关键的一点是,判别器D和Q共用所有卷积层,只是最后的全连接层不同。
二:详细分析各个网络:
G网络:除了噪声z,还需要增加latent code(有离散数据和连续数据)。
D网络:正常输入,和Q共享卷积层,输出有1维的向量,判断是fake or true,
Q网络:也就是D网络,只不过输出经过两个不同的FC层,维度和latent code维度一致。
这里直接用pytorch代码过程来分析了。
1:对D来说:
判别器D的输入为:(batch_size, channel, img_ size, img_size),判别器D的输出为:(batch_size, 1)
优化过程是:
optimizer_D.zero_grad() # 梯度清零
# Loss for real images
d_real_pred, _, _ = discriminator(real_imgs)
# Loss for fake images
gen_imgs = generator(z_noise, label_input, code_input).detach()
d_fake_pred, _, _ = discriminator(gen_imgs)
# Total discriminator loss
d_loss = discriminator_loss(d_real_pred, d_fake_pred) # 判别器的 loss
d_loss.backward()
optimizer_D.step()
其中discriminator_loss是:
def discriminator_loss(logits_real, logits_fake): # 判别器的 loss
size = logits_real.shape[0]
true_labels = Variable(torch.ones(size, 1)).float() # 和1作对比
size = logits_fake.shape[0]
false_labels = Variable(torch.zeros(size, 1)).float() # 和0作对比
loss = validity_loss(logits_real, true_labels) + validity_loss(logits_fake, false_labels)
return loss
2:对G来说:
生成器G的输入为:(batch_size, noise_dim + discrete_dim + continuous_dim),其中noise_dim为输入噪声的维度,discrete_dim为离散隐变量的维度,continuous_dim为连续隐变量的维度。生成器G的输出为(batch_size, channel, img_size, img_size)
优化过程是:
optimizer_G.zero_grad() # 梯度清零
# 假的图片去欺骗D,让D误认为是真的。
gen_imgs = generator(z_noise, label_input, code_input)
g_real_pred, _, _ = discriminator(gen_imgs)
g_loss = generator_loss(g_real_pred) # 生成网络的 loss
g_loss.backward()
optimizer_G.step()
其中generator_loss是:
def generator_loss(logits_fake): # 生成器的 loss
size = logits_fake.shape[0]
true_labels = Variable(torch.ones(size, 1)).float() #和1作对比
loss = validity_loss(logits_fake, true_labels)
return loss
3:对Q来说:
判别器Q的输入为:(batch_size, channel, img_size, img_size),Q的输出为:(batch_size, discrete_dim + continuous_dim)
optimizer_Q.zero_grad()
gen_imgs = generator(z_noise, label_input, code_input)
_, pred_label, pred_code = discriminator(gen_imgs)
info_loss = discrete_loss(pred_label, label_input) + continuous_loss(pred_code, code_input)
info_loss.backward()
optimizer_Q.step()
其中 optimizer_Q 是:
optimizer_Q = torch.optim.Adam(
itertools.chain(generator.parameters(), discriminator.parameters()), lr=opt.lr, betas=(opt.beta_1, opt.beta_2)
) # Q 就是多出来的那两个个FC网络,D和Q共用所有卷积层,只是最后的全连接层不同。
三:完整实例
种类还是用 MNIST数据集做测试,每一步骤都是有清晰的注释说明。
import argparse
import os
import numpy as np
import math
import itertools
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchvision.datasets import MNIST
# step ========================= 初始化参数 ===========
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=32, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--beta_1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--beta_2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--noise_dim", type=int, default=62, help="dimensionality of the latent space") # 原始噪声的维度
parser.add_argument("--code_discrete_dim", type=int, default=10, help="number of classes for dataset") # 离散变量维度,这里是使用数字的类别
parser.add_argument("--code_continuous_dim", type=int, default=2, help="latent code") # 连续变量的维度,假定是2维
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
# step ========================= 加载MNIST数据 ===========
train_set = MNIST('./data', train=True, transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]))
train_data = DataLoader(train_set, batch_size=opt.batch_size, shuffle=True)
def deprocess_img(img):
out = 0.5 * (img + 1)
out = out.clamp(0, 1)
out = out.view(-1, 1, 28, 28)
return out
# step ========================= 定义模型 ===========
# 初始化参数的函数
def weights_init_normal(m):
class_name = m.__class__.__name__
if class_name.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif class_name.find("BatchNorm") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
input_dim = opt.noise_dim + opt.code_continuous_dim + opt.code_discrete_dim
self.init_size = opt.img_size // 4 # Initial size before upsampling
self.l1 = nn.Sequential(nn.Linear(input_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise, labels, code):
z = np.concatenate((noise, labels, code), axis=1)
z = Variable(torch.from_numpy(z).float())
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_channels, out_channels, bn=True):
"""Returns layers of each discriminator block"""
block = [nn.Conv2d(in_channels, out_channels, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_channels, 0.8))
return block
# 共享卷积层
self.conv_blocks = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# Output layer,最后输出的FC 层是不同的。最后一层FC
self.valid_fc_layer = nn.Sequential(nn.Linear(512, 1))
self.discrete_fc_layer = nn.Sequential(nn.Linear(512, opt.code_discrete_dim), nn.Softmax())
self.continuous_fc_layer = nn.Sequential(nn.Linear(512, opt.code_continuous_dim))
def forward(self, img):
# 共享 Conv 层
out = self.conv_blocks(img)
out = out.view(out.shape[0], -1)
# FC 层,输入都是共享 Conv 层
validity_val = self.valid_fc_layer(out) # fake image? : 0 / real image? : 1
discrete_val = self.discrete_fc_layer(out) # 离散的输出
continuous_val = self.continuous_fc_layer(out) # 连续的输出
return validity_val, discrete_val, continuous_val
# 实例化 generator and discriminator
generator = Generator()
discriminator = Discriminator()
# 初始化各自模型的参数权重
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# step ========================= 定义损失函数和优化器 ===========
# Loss functions
validity_loss = torch.nn.MSELoss() # real or fake
discrete_loss = torch.nn.BCELoss() # 离散输入的输出的损失函数
continuous_loss = torch.nn.MSELoss() # 连续输入的输出的损失函数
def discriminator_loss(logits_real, logits_fake): # 判别器的 loss
size = logits_real.shape[0]
true_labels = Variable(torch.ones(size, 1)).float()
size = logits_fake.shape[0]
false_labels = Variable(torch.zeros(size, 1)).float()
loss = (validity_loss(logits_real, true_labels) + validity_loss(logits_fake, false_labels)) / 2
return loss
def generator_loss(logits_fake): # 生成器的 loss
size = logits_fake.shape[0]
true_labels = Variable(torch.ones(size, 1)).float()
loss = validity_loss(logits_fake, true_labels)
return loss
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.beta_1, opt.beta_2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.beta_1, opt.beta_2))
optimizer_Q = torch.optim.Adam(
itertools.chain(generator.parameters(), discriminator.parameters()), lr=opt.lr, betas=(opt.beta_1, opt.beta_2)
) # Q 就是多出来的那两个个FC网络,D和Q共用所有卷积层,只是最后的全连接层不同。
# step ========================= 开始训练 ===========
# 得到 one-hot 向量的函数
def get_onehot_vector(label, label_dim):
labels_onehot = np.zeros((label.shape[0], label_dim))
labels_onehot[np.arange(label.shape[0]), label.numpy()] = 1
return Variable(torch.FloatTensor(labels_onehot))
iter_count = 0
show_every = 50
# those is for test
os.makedirs("D:/software/Anaconda3/doc/3D_Img/inforgan/", exist_ok=True)
batch_size = 10
test_z_noise = Variable(torch.FloatTensor(np.random.normal(0, 1, (batch_size, opt.noise_dim))))
test_label_input = get_onehot_vector(torch.from_numpy(np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])), opt.code_discrete_dim)
test_code_input = Variable(torch.FloatTensor(np.zeros((batch_size, opt.code_continuous_dim))))
for epoch in range(opt.n_epochs):
for i, (real_imgs, labels) in enumerate(train_data):
# ---------------------------------------------------------------
# prepare data
# ---------------------------------------------------------------
batch_size = real_imgs.shape[0] # 获取 batch_size
# 生成随机噪声数据,正态分布随机采样
z_noise = Variable(torch.FloatTensor(np.random.normal(0, 1, (batch_size, opt.noise_dim))))
# 得到当前离散数据,用数字的类别作为离散数据输入
label_input = get_onehot_vector(labels, opt.code_discrete_dim)
# 离散数据输入,均值采样
code_input = Variable(torch.FloatTensor(np.random.uniform(-1, 1, (batch_size, opt.code_continuous_dim))))
# ---------------------------------------------------------------
# Train Discriminator
# ---------------------------------------------------------------
optimizer_D.zero_grad() # 梯度清零
# Loss for real images
d_real_pred, _, _ = discriminator(real_imgs)
# Loss for fake images
gen_imgs = generator(z_noise, label_input, code_input).detach()
d_fake_pred, _, _ = discriminator(gen_imgs)
# Total discriminator loss
d_loss = discriminator_loss(d_real_pred, d_fake_pred) # 判别器的 loss
d_loss.backward()
optimizer_D.step()
if i % 2 == 0 :
# ---------------------------------------------------------------
# Train Generator
# ---------------------------------------------------------------
optimizer_G.zero_grad() # 梯度清零
# 假的图片去欺骗D,让D误认为是真的。
gen_imgs = generator(z_noise, label_input, code_input)
g_real_pred, _, _ = discriminator(gen_imgs)
g_loss = generator_loss(g_real_pred) # 生成网络的 loss
g_loss.backward()
optimizer_G.step()
# ---------------------------------------------------------------
# Information Loss
# ---------------------------------------------------------------
optimizer_Q.zero_grad()
gen_imgs = generator(z_noise, label_input, code_input)
_, pred_label, pred_code = discriminator(gen_imgs)
info_loss = discrete_loss(pred_label, label_input) + 0.2 * continuous_loss(pred_code, code_input)
info_loss.backward()
optimizer_Q.step()
# ---------------------------------------------------------------
# test to output some images.
# To do another procession.
# ---------------------------------------------------------------
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [info loss: %f]"
% (epoch, opt.n_epochs, i, len(train_data), d_loss.item(), g_loss.item(), info_loss.item())
)
if (iter_count % show_every == 0):
fake_img = generator(test_z_noise, test_label_input, test_code_input) # 将向量放入生成网络G生成一张图片
#real_images = deprocess_img(fake_img.data)
save_image(fake_img.data, 'D:/software/Anaconda3/doc/3D_Img/inforgan/test_%d.png' % (iter_count))
iter_count += 1