YOLOV4 名词总结
YOLOV4论文
- 名词
-
- 隐藏层
- 批标准化 batch-normalization
- 残差网络 ResNet
- 残差连接 residual-connections
- 感受野
- one-stage 与 two-stage
- anchor
- Ground truth(真实值)
- FPN
- 数据预处理 one hot 编码
- Backbone、Neck和Head
- Bag of freebies
- Bag of specials
- SAT 自对抗
- Mosaic
名词
隐藏层
隐藏层的意义就是把输入数据的特征,抽象到另一个维度空间,来展现其更抽象化的特征,这些特征能更好的进行线性划分。
图像经过隐藏层加工,得出三个特征并将其可视化,就有了下面这张图
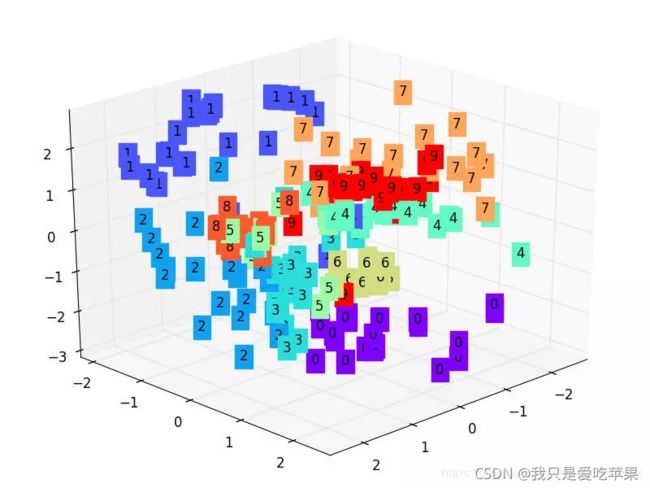
层数并不是越多越好
1.层数多了参数爆炸性增加
2.一味增加层数,分类的效果会越来越不明显,对于特征对划分没有什么影响
把一个神经元看作是一种线性划分方式,如果神经元数量很多,那么就会有很多个线性划分,决策边界就会越扭曲,基本就是过拟合了
批标准化 batch-normalization
将分散的数据统一,具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律.
进行normalization预处理,使输入的x值变化范围不太大,在激励函数的敏感部分
如果在输入层中,x可以方便的进行处理,但是换到了隐藏层中,就需要用batch-normalization进行处理。
添加位置
batch:批数据,在每一次前向传播的时候对每一层都进行normalization处理
计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递
没有normalization的数据经过 tanh 激活后,大部分都到了饱和阶段,(-1或者1),normalization之后,在中间的敏感部分还会有值存在。
除了normalization,batch-normalization还进行了反normalization操作,在验证前面的操作有没有起到优化后,如果没有,那么用gamma和belt来抵消一些normalization的效果
残差网络 ResNet
网络层数越多意味着能够提取到的不同级别的抽象特征更加丰富,越具有语义信息。
但是不能简单的增加网络层数,会导致退化问题。
由于深层网络结构更加复杂,所以梯度下降算法得到局部最优解的可能性最大,但不一定是全局最优解。
退化问题:随着网络层数的增加,在训练集上的准确率却饱和甚至下降了。
解决退化问题:
既保留深层网络的深度,又有浅层网络的优势去避免退化问题
任何单元l和L之间都具有残差特性
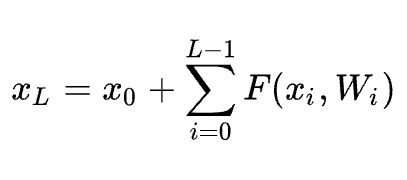
单元L的特征为之前所有的残差函数的输出的总和加上x0
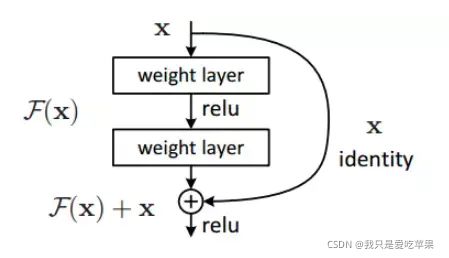
普通的平原网络与深度残差网络的最大区别在于,深度残差网络有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这些支路就叫做shortcut。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
残差连接 residual-connections
残差连接是resnet的基本层构造。
感受野
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。
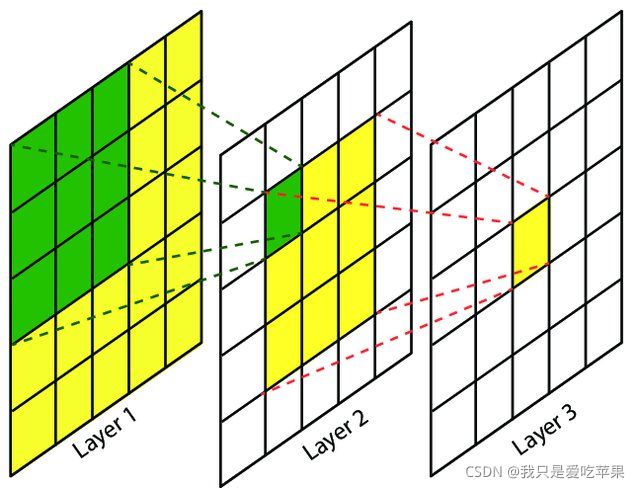
深层的神经元,看到的输入区域越大,如图,layer3一个神经元可以看到layer2的3x3大小的区域,这个区域又可以看到layer1上5x5大小的区域.
感受野的含义与计算
one-stage 与 two-stage
One-stage网络以yolo系列网络为代表的,
two-stage网络以faster-rcnn为代表的,
1.one-stage网络准确性比two-stage要低
我们来看rcnn,它是首先在原图上生成若干个候选区域,这个候选区域表示可能会是目标的候选区域,注意,这样的候选区域肯定不会特别多,假如我一张图像是100x100的,它可能会生成2000个候选框,然后再把这些候选框送到分类和回归网络中进行分类和回归,fast-rcnn其实差不多,只不过它不是最开始将原图的这些候选区域送到网络中,而是在最后一个feature map将这个候选区域提出来,进行分类和回归,它可能最终进行分类和回归的候选区域也只有2000多个并不多,再来看faster-rcnn,虽然faster-rcnn它最终一个feature map它是每个像素点产生9个anchor,那么100x100假如到最终的feature map变成了26x26了,那么生成的anchor就是26x26x9 = 6084个,虽然看似很多,但是其实它在rpn网络结束后,它会不断的筛选留下2000多个,然后再从2000多个中筛选留下300多个,然后再将这300多个候选区域送到最终的分类和回归网络中进行训练,所以不管是rcnn还是fast-rcnn还是faster-rcnn,它们最终进行训练的anchor其实并不多,几百到几千,不会存在特别严重的正负样本不均衡问题,但是我们再来看yolo系列网络,就拿yolo3来说吧,它有三种尺度,13x13,26x26,52x52,每种尺度的每个像素点生成三种anchor,那么它最终生成的anchor数目就是(13x13+26x26+52x52)*3 = 10647个anchor,而真正负责预测的可能每种尺度的就那么几个,假如一张图片有3个目标,那么每种尺度有三个anchor负责预测,那么10647个anchor中总共也只有9个anchor负责预测,也就是正样本,其余的10638个anchor都是背景anchor,这存在一个严重的正负样本失衡问题,虽然位置损失,类别损失,这10638个anchor不需要参与,但是目标置信度损失,背景anchor参与了,因为总的损失 = 位置损失 + 目标置信度损失 + 类别损失,所以背景anchor对总的损失有了很大的贡献,但是我们其实不希望这样的,我们更希望的是非背景的anchor对总的损失贡献大一些,这样不利于正常负责预测anchor的学习,而two-stage网络就不存在这样的问题,two-stage网络最终参与训练的或者计算损失的也只有2000个或者300个,它不会有多大的样本不均衡问题,不管是正样本还是负样本对损失的贡献几乎都差不多,所以网络会更有利于负责预测anchor的学习,所以它最终的准确性肯定要高些
2.one-stage网络速度要快很多
one-stage网络生成的anchor框只是一个逻辑结构,或者只是一个数据块,只需要对这个数据块进行分类和回归就可以,不会像two-stage网络那样,生成的 anchor框会映射到feature map的区域(rcnn除外),然后将该区域重新输入到全连接层进行分类和回归,每个anchor映射的区域都要进行这样的分类和回归,所以它非常耗时
two-stage算法需要先生成一个proposal(可能包含物体的预选框),然后进行细粒度的物体检测
one-stage会直接在网络中提取特征来预测物体的分类和位置
anchor
anchor机制由Faster-RCNN 提出,YOLOV2中引入anchor
为解决分而治之和ground truth box与ground truth box之间overlap太大导致ground truth box丢失的问题。
overlap:重叠
anchor机制可以减少金字塔层数
anchor-free 和 anchor-base区别
物体检测问题通常被建模成对候选区域进行分类和回归的问题
单阶段检测:候选区域是通过滑窗方式产生的anchor
两阶段检测:候选区域是RPN生成的proposal,RPN本身是对滑窗方式产生的anchor进行分类回归
anchor-free 分为两个子问题,确定物体中心和对四条边框的预测
在 anchor-based 的方法中,虽然每个位置可能只有一个 anchor,但预测的对象是基于这个 anchor 来匹配的,而在 anchor-free 的方法中,通常是基于这个点来匹配的。在anchor-free中,物体落到哪个网格,哪个网格就是正样本,其余都是负样本。anchor-base则计算每个anchor和gt的IoU,超过多少阈值就算正。
Ground truth(真实值)
表示框的真实值,x,y,w,h
FPN
数据预处理 one hot 编码
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
Backbone、Neck和Head
Backbone, 译作骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等
Head,译作检测头,主要用于预测目标的种类和位置(bounding boxes),预测类别信息和目标物体的边界框
在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层,通常称为Neck。
基于深度学习的目标检测模型的结构是这样的:输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出
对于head部分,通常分为两类:one-stage和two-stage的目标检测器。 .
通常,一个neck由多个bottom-up路径和top-down路径组成。使用这种机制的网络包括Feature Pyramid Network(特征金字塔网络、FPN),Path Aggregation Network(路径聚合网络、PAN),BiFPN和NAS-FPN。

Bag of freebies
我们将只改变训练策略或者只增加训练成本的方法称之为“bag of freebies"

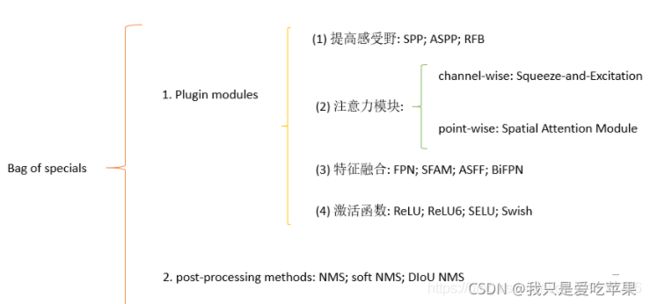
Bag of specials
对于那些插件模块和后处理方法,它们仅仅稍微的增加了推理成本,但是可以极大地提高目标检测的准确度,我们将其称之为“bag of specials”
SAT 自对抗
yolov4中提出的数据增强的新方法
自对抗训练(SAT)也代表了一种新的数据增强技术,它在两个前向后向阶段运行。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对其自身执行对抗性攻击,改变原始图像,以制造图像上没有所需对象的欺骗。在第二阶段,训练神经网络,以正常的方式在修改后的图像上检测目标。
Mosaic
Mosaic是一种新型的数据增广的方法
Mosaic是一种新型的数据增广的方法,它混合了四张训练图片。因此有四种不同的上下文进行融合,然而CutMix仅仅将两张图片进行融合。此外,batch normalization在每个网络层中计算四张不同图片的激活统计。这极大减少了一个大的mini-batch尺寸的需求。