3-MySQL原理-InnoDB架构与数据一致性
专栏目录
- 1-MySQL原理-设计架构
- 2-MySQL原理-InnoDB架构与内存管理
- 3-MySQL原理-InnoDB架构与数据一致性
- 4-MySQL原理-SQL执行原理
- 5-MySQL原理-存储引擎与索引结构
- 6-MySQL原理-索引匹配原则
- 7-MySQL原理-事务底层实现
- 8-MySQL原理-MySQL回表与解决方案
- 9-MySQL原理-执行计划最全详解
- 10-MySQL原理-索引失效索引匹配最全详解
Checkpoint机制
InnoDB对于对于DML语句操作(如Update或Delete),事务提交时只需在缓冲池中完成操作,然后再通过Checkpoint将修改后的脏页数据刷新到磁盘。
InnoDB有两种Checkpoint
Sharp Checkpoint:数据库关闭时将所有脏页刷新回磁盘
Fuzzy Checkpoint:
- Master Thread Checkpoint
Master Thread每隔1秒或10秒按一定比例将缓存池的脏页列表刷新回磁盘 - FLUSH LRU LIST Checkpoint
Page Cleaner线程发现LRU列表中可用页数量少于innodb_lru_scan_depth(1024),就将LRU列表尾端移除,如果这些页中有脏页,就需要Checkpoint - Async/Sync Flush Checkpoint
重做日志文件空间不可以用时,将一部分脏页刷新到磁盘。 - Dirty Page too much Checkpoint:
脏页数量太多(超过比例innodb_max_dirty_pages_pct,默认75),执行Checkpoint。
重做日志
重做日志是为了保证事务的原子性,持久性。(防止宕机后不一致)InnoDB采用Write Ahread Log策略,事务提交时,先写重做日志,再修改页。
数据库宕机重启时通过执行重做日志恢复数据。
但由于Checkpoint机制,数据库宕机重启并不需要重做所有的日志,因为Checkpoint之前的页都刷新到磁盘了,只需执行最新一次Checkpoint后的重做日志进行恢复,这样可以缩短数据库的恢复时间。
InnoDB中重做日志文件是循环使用的。当页被Checkpoint刷新到磁盘后,对应的重做日志就不需要使用 ,其空间可以被覆盖重用。
如果待写入的重做日志文件空间不可用(脏页还没有刷新到磁盘),就需要强制产生Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。
InnoDB 1.2.x(MySql 5.6)后,FLUSH LRU LIST Checkpoint以及Async/Sync Flush Checkpoint操作放到Page Cleaner线程,以免阻塞用户线程。
关键特性
- 插入缓冲
- 两次写
- 自适应哈希索引
- 异步IO
- 刷新邻近页
插入缓冲
磁盘分为顺序IO和随机IO,例如要插入数据到磁盘的两个地方A和B
- 顺序IO是指A和B是磁盘中连续的,或者间隔较少的两个位置。这样磁盘通过寻址找到A位置后,可以快速地找到B位置。这样插入AB的位置的数据就会比较快,因为只需要1次寻址操作。
- 随机IO是指A和B两个位置没有关系。当磁盘找到A位置后,需要再次通过寻址操作来寻址B。所以就会比较慢,因为需要2次寻址操作。
数据存储
Mysql的数据存储是根据主键来顺序存储的。所以在插入数据的时候:
- 如果主键是顺序的,它们会存储在顺序的磁盘地址,这样就是顺序IO存储。例如主键是1和2
- 如果主键是不顺序的,Mysql需要存储在不同地方,这样就是随机IO。例如主键是abc和bcd
索引最好是有序的
索引存储
Mysql中主键本身也是索引,称为主索引(Primary index),其他索引称为辅助索引(secondary index)
如果一个表中有辅助索引,在插入数据的时候,除了存储数据,还需要建立索引。如果插入两条数据,主键是顺序的,但是有一个索引的数据是不顺序的,这样也会产生随机IO。(画磁盘扇区图)
Mysql的优化方法是加入插入缓冲:也就是先把索引放在缓冲池中,定期刷新到磁盘。这样可以减少随机IO的次数。例如插入两条数据,索引位置是相同的,如果分两次刷新到磁盘,就需要两次随机IO。如果合并为一次,只需要一次随机IO。
插入缓冲(Insert Buffer/Change Buffer):提升插入性能,change buffer是insert buffer的加强,insert buffer只针对insert有效,change buffering对insert、delete、update(delete+insert)、purge都有效。
Change buffer是作为buffer pool中的一部分存在。Innodb_change_buffering参数缓存所对应的操作:(update会被认为是delete+insert)
innodb_change_buffering,设置的值有:inserts、deletes、purges、changes(inserts和deletes)、all(默认)、none。
all: 默认值,缓存insert, delete, purges操作
none: 不缓存
inserts: 缓存insert操作
deletes: 缓存delete操作
changes: 缓存insert和delete操作
purges: 缓存后台执行的物理删除操作
可以通过参数控制其使用的大小:
innodb_change_buffer_max_size,默认是25%,即缓冲池的1/4。最大可设置为50%。*当MySQL实例中有大量的修改操作时,要考虑增大*innodb_change_buffer_max_size
只对于非聚集索引(非唯一)的插入和更新有效,对于每一次的插入不是写到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,如果在则直接插入;若不在,则先放到Insert Buffer 中,再按照一定的频率进行合并操作,再写回disk。这样通常能将多个插入合并到一个操作中,目的还是为了减少随机IO带来性能损耗。
插入缓冲需要条件:
- 索引是辅助索引
- 索引不是唯一的。因为如果是唯一的,插入的时候Mysql需要一次随机IO找到索引位置,看数据有没有重复。这样这次随机IO就肯定需要的,所以使用插入缓冲来优化就没有意义了。
可以通过engine status命令来查看插入缓冲的状态
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
- seg size 是插入缓冲的大小
- size 是已经合并的页数
- free list 是空闲的页数
- merged operations 被合并的操作
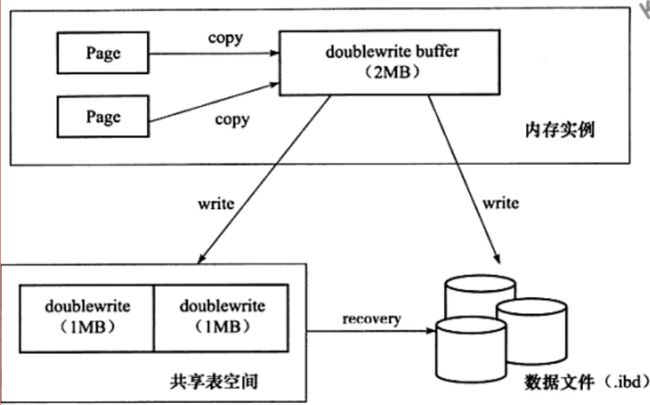
二次写(double write)
Double write缓存是位于系统表空间的存储区域,用来缓存InnoDB的数据页从innodb buffer pool中flush之后并写入到数据文件之前,所以当操作系统或者数据库进程在数据页写磁盘的过程中崩溃,Innodb可以在doublewrite缓存中找到数据页的备份而用来执行奔溃恢复。数据页写入到doublewrite缓存的动作所需要的IO消耗要小于写入到数据文件的消耗,因为此写入操作会以一次大的连续块的方式写入
在应用(apply)重做日志前,用户需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是double write
doublewrite组成:
内存中的doublewrite buffer,大小2M。
物理磁盘上共享表空间中连续的128个页,即2个区(extend),大小同样为2M。
写入buffer过程:
-
对缓冲池的脏页进行刷新时,不是直接写磁盘
-
而是会通过memcpy()函数将脏页先复制到内存中的doublewrite buffer,
-
之后通过doublewrite 再分两次,每次1M顺序地写入共享表空间的物理磁盘上
在这个过程中,因为doublewrite页是连续的,因此这个过程是顺序写的,开销并不是很大。
写入表空间
- 在完成doublewrite页的写入后,再将doublewrite buffer 中的页写入各个 表空间文件中,此时的写入则是离散的。
恢复
- 如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,innodb可以从共享表空间中的doublewrite中找到该页的一个副本,将其复制到表空间文件,再应用重做日志。