【论文笔记】MDCSpell: A Multi-task Detector-Corrector Framework for Chinese Spelling Correction
文章目录
- 论文内容
- 论文思路
- 模型架构
- 损失函数
- 训练细节
- 实验结果
- 个人总结
论文复现 : https://blog.csdn.net/zhaohongfei_358/article/details/127035600
论文内容
论文地址: https://aclanthology.org/2022.findings-acl.98/
论文年份:2022
作者基于Transformer和BERT设计了一个多任务的网络来进行CSC(Chinese Spell Checking)任务(中文拼写纠错)。多任务分别是找出哪个字是错的和对错字进行纠正。
论文思路

作者对之前的模型进行了改进,其中(a), (b) 是之前的模型,(c)是作者提出的模型
(a): 直接使用一个"Correction Module"来进行错字修正,input为包含错字的token序列,output就是把所有的错字改成正确的,对于那些原本正确就重新输出即可。例如:input为基尼太美,output则为鸡你太美。典型的方法有BERT(b):对Input通过一个Detection Module来预测一下哪些是错字,然后对错字进行mask得到masked Input,然后再送给“Correction Module”进行预测。典型的方法有Softed-mask BERT。 例如:input为基尼太美,Masked Input为[MASK][MASK]太美,output为鸡你太美。(c):作者提出的方法。Input还是直接送给Correction Module,但另一方面Input还送给Detection Module,用Detection Module输出的向量和Correction Module输出的向量进行融合,然后再去做预测。(c)比(b)好的点主要有:①保留了错字的信息,这样可以让Correction Module更准确的预测。例如:input为哎呦,你干麻,如果使用(b),则masked input会变成哎呦,你干[MASK],此时就可能会修正成哎呦,你干啥,因为这也是语义通顺的。但如果给网络的麻这个错误信息,它就知道应该修正成哎呦,你干嘛了。 ② 在保留错字信息的同时,还能利用到Detection Module的信息。
模型架构
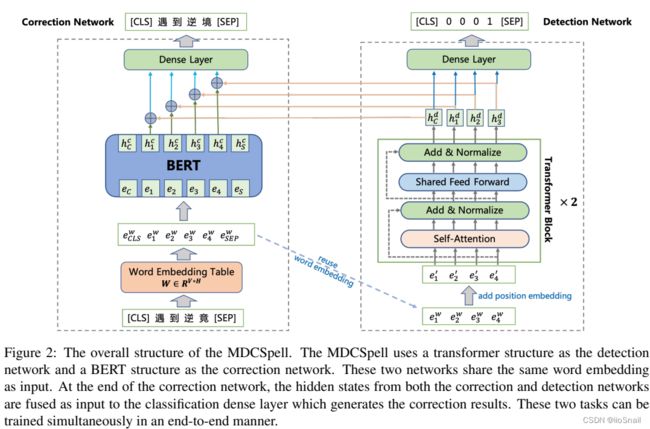
Correction Network 的数据流向如下:
1.将token序列 [CLS] 遇 到 逆 竟 [SEP] 送给Word Embedding模块进行embeddings,得到向量 { e C L S w , e 1 w , e 2 w , e 3 w , e 4 w , e S E P w } \{e_{CLS}^w, e_1^w, e_2^w, e_3^w, e_4^w,e_{SEP}^w\} {eCLSw,e1w,e2w,e3w,e4w,eSEPw}。
个人认为此时的embedding仅仅是Word Embeding,并不包含Position Embedding和Segment Embedding。
2.之后将 { e C L S w , e 1 w , e 2 w , e 3 w , e 4 w , e S E P w } \{e_{CLS}^w, e_1^w, e_2^w, e_3^w, e_4^w,e_{SEP}^w\} {eCLSw,e1w,e2w,e3w,e4w,eSEPw}向量送入BERT,增加Position Embedding和Segment Embedding,得到 { e C , e 1 , e 2 , e 3 , e 4 , e S } \{e_C, e_1, e_2, e_3, e_4, e_S\} {eC,e1,e2,e3,e4,eS}。
3.在BERT内部,会经历多层的TransformerEncoder,最终的得到输出向量 H c = { h C c , h 1 c , h 2 c , h 3 c , h 4 c , h S c } H^c=\{h_C^c, h_1^c, h_2^c, h_3^c, h_4^c, h_S^c\} Hc={hCc,h1c,h2c,h3c,h4c,hSc}.
4.将BERT的输出 H c H^c Hc 和 隔壁Detection Network输出的 H d H^d Hd 进行融合,得到 H = H d + H c H = H^d+H^c H=Hd+Hc
融合时并不对
[CLS]和[SEP]进行融合
5.将 H H H送给全连接层(Dense Layer)做最后的预测。
Correction Network模型细节:
- BERT:作者使用的是具有12层Transformer Block的BERT-base版。
- Dense Layer:Dense Layer的输入通道为词向量维度,输出通道为词典大小。例如:词向量维度为768,词典大小为20000,则Dense Layer则为
nn.Linear(768, 20000) - Dense Layer的初始化:Dense Layer的权重使用的是Word Embedding的参数。因为word Embedding是将词index转成词向量,所以其参数刚好是Dense Layer的转置,即Word Embedding是
nn.Linear(20000, 768),所以作者就是用Word Embedding的转置来初始化Dense Layer的参数。因为这样可以加速训练,且使模型变的稳定。
Detection Network的数据流向如下:
1.输入为使用BERT得到的word Embedding { e 1 w , e 2 w , e 3 w , e 4 w } \{e_1^w, e_2^w, e_3^w, e_4^w\} {e1w,e2w,e3w,e4w}。虽然图里并不包含[CLS]和[SEP]的词向量,但个人认为不需要对其特殊处理,因为最后的预测也用不到这两个token.
2.将 { e 1 w , e 2 w , e 3 w , e 4 w } \{e_1^w, e_2^w, e_3^w, e_4^w\} {e1w,e2w,e3w,e4w}增加Position Embedding信息,得到 { e 1 ′ , e 2 ′ , e 3 ′ , e 4 ′ } \{e_1', e_2', e_3', e_4'\} {e1′,e2′,e3′,e4′}
在论文中说Detection Network使用的是向量 { e 1 , e 2 , e 3 , e 4 } \{e_1, e_2, e_3, e_4\} {e1,e2,e3,e4},其是word embedding+position embedding+segment embedding。这与图上是矛盾的,这里以图为准了。
3.将 { e 1 ′ , e 2 ′ , e 3 ′ , e 4 ′ } \{e_1', e_2', e_3', e_4'\} {e1′,e2′,e3′,e4′}向量送入Transformer Block,得到输出向量 H d = { h 1 d , h 2 d , h 3 d , h 4 d } H^d=\{h_1^d, h_2^d, h_3^d, h_4^d\} Hd={h1d,h2d,h3d,h4d}
4.一方面,将输出向量 H d H^d Hd送给隔壁的Correction Network进行融合;另一方面,将 H d H^d Hd送给后续的全连接层(Dense Layer)来判断哪个token是错误的.
Detection Network的细节:
- Transformer Block:Transformer Block是2层的TransformerEncoder。
- Transformer Block参数初始化:Transformer Block参数初始化使用的是BERT的权重。
- Dense Layer:Dense Layer的输入通道为词向量大小,输出通道为1。使用Sigmoid来判别该token为错字的概率。
损失函数
Correction Network和Detection Network使用的都是Cross Entropy。之后进行相加即可:
L = λ L c + ( 1 − λ ) L d L = \lambda L^c + (1-\lambda) L^d L=λLc+(1−λ)Ld
其中 λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1] 。作者通过实验得出 λ = 0.85 \lambda=0.85 λ=0.85 时效果最好。
训练细节
第一步,首先使用 Wang271K(自己造的假数据) 数据集进行训练。batch size为32, learning rate为2e-5
第二步,使用SIGHAN训练集进行fine-tune。 batch size为32,learning rate为1e-5
作者并没有提到使用的是什么Optimizer,但看这个学习率,应该是Adam。
实验结果

个人总结
论文亮点:
- 纠错网络(Correction Network)的预测层加入了Detection Module的Hidden States,保留了原有错字信息的同时,增加了“是否是错字”的信息,让网络可以更好的预测出结果。
- 使用BERT的Word Embedding参数来初始化Correction Network的预测层(全连接层)的参数,使得模型可以更快更稳定的收敛。
- 使用BERT的Transfomer参数来初始化Detection Network的Transformer参数,让Detection Network可以更快更稳定的学习。
- 先使用大数据集对模型进行训练,然后再使用和测试集分布较为一致的训练集进行fine-tune,在fine-tune时,减小学习率。