数据分析实例-餐饮行业分析
本次数据分析案例共有8道题
开发工具:jupyter bootbook
话不多说,首先导入本次案例需要用到的包
# 导包
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示1. 读取“餐饮订单”表格数据命名为order,并查看第5行到第10行数据。
order = pd.read_excel('餐饮订单.xlsx')
order.head(11).tail(6)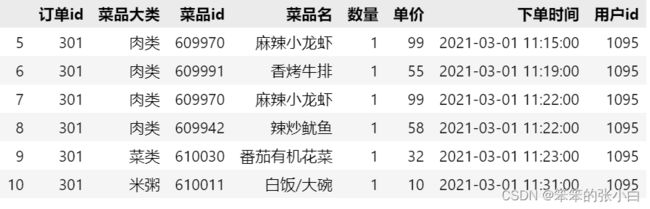
巧妙的利用head()和tail()来实现读取任意区间的数据
2. 读取”就餐人数”表格数据命名为customer,并按就餐人数进行升序排序,并查看第5行到第10行数据。
customer = pd.read_excel('就餐人数.xlsx')
customer.sort_values(by='就餐人数')
customer.head(11).tail(6)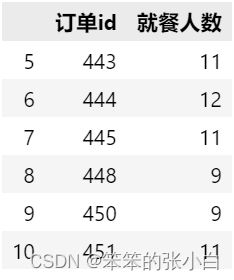
3.为order表增加一列“时间段”,将16点及之前的订单标记为午餐,16点后的订单标记为晚餐。并根据数量和单价计算出销售额。并查看前5行数据。
order['下单时间'] = order['下单时间'].astype(dtype='str')
order['时间段'] = order['下单时间'].apply(lambda x:'晚餐' if int(x.split()[-1][0:2]) > 16 else '午餐')
order['销售额'] = order['数量'] * order['单价']
order.head()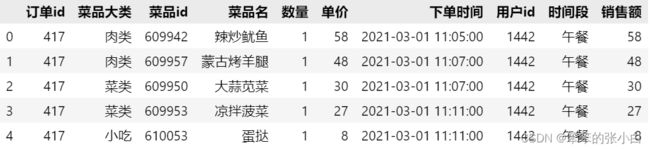
这里就需要利用字符串函数将下单时间提取出小时数,再跟16比较得出时间段
4.将order与customer表按照订单id合并,获得一张新表customer_order,表中包含“订单id”、“就餐人数”、“销售额”、“时间段”4个字段,查看前5行数据。(注意order表中,一个订单会有多条记录,销售额不能直接合并)
order1 = order[['订单id','时间段']]
order1.drop_duplicates(inplace=True)
data1 = order.groupby('订单id').sum()['销售额']
new_order = pd.merge(data1,order1,on='订单id')
customer_order = pd.merge(customer,new_order,on='订单id')
customer_order.head()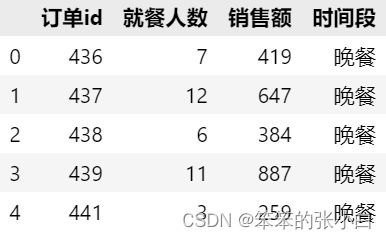
这个题就需要动脑筋思考一下了,巧妙利用删除重复值将order1中的数据唯一化再进行合并
5.占菜品销售额前80%的菜品是哪些?(除开酒水饮料和白饭,酒水饮料从菜品大类中找,白饭从菜品名中找)
num = len(order.groupby('菜品名').sum()['销售额'].sort_values(ascending=False))
all_list = order.groupby('菜品名').sum()['销售额'].sort_values(ascending=False).head(int(np.floor(num*0.8))).index.to_list()
table = order.pivot_table(index=['菜品大类','菜品名'])
except_list = [item[1] for item in table.index.to_list() if item[0] == '酒类' or item[0] == '饮料']
result = [x for x in all_list if x not in except_list and x[0:2] != '白饭']
result
这道题难度就又增大了一截,需要用到分组函数,交叉表,当然这里我为了简化代码,用到了三元列表推导式
6.使用order表画一个折线图,展示出1-15日每一天的订单数量,订单数量按降序排列,并在折线图上标记出对应的订单数。(注意order表中订单id有重复值)
order['日期'] = order['下单时间'].apply(lambda x:int(x.split()[0].split('-')[-1]))
data2 = order[['订单id','日期']]
data2.drop_duplicates(inplace=True)
data3 = data2.groupby('日期').count()['订单id']
data4 = data3[data3.index < 16]
plt.figure(figsize=(15,8))
plt.plot(data4.index,data4.values,color='blue')
for a,b in zip(data4.index,data4.values):
plt.text(a,b,'%d'%b,ha='center',va='bottom',fontsize=15)
plt.xticks()
plt.yticks(fontsize=15)
plt.xlabel('日期',fontsize=14)
plt.ylabel('订单数',fontsize=14)
plt.title('每日订单数',fontsize=14)
plt.show()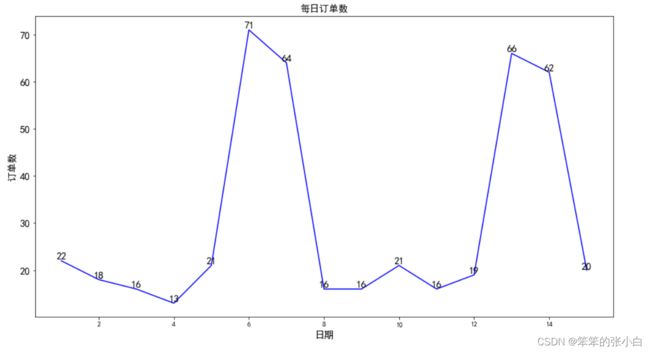
这个题就中规中矩,画个折线图并加上数值,当然前面你还得将1-15的数据提取出来
7. 通过order表计算出各个菜品大类的销量和销售额,命名为type_data。注意:白饭不属于任何菜品大类,需要在菜品中先剔除白饭再做计算.
order1 = order[order['菜品名'] != '白饭/大碗']
order2 = order1[order1['菜品名'] != '白饭/小碗']
type_data = order2.groupby('菜品大类').sum()[['数量','销售额']]
type_data
8.通过type_data采用子图方式画出食物和酒水的销量占比和销售额占比情况。饮料和酒类属于酒水,其他属于食物。
drink_data = type_data[(type_data.index == '饮料') | (type_data.index == '酒类')]
drink_num = drink_data['数量'].sum()
drink_sole = drink_data['销售额'].sum()
food_data = type_data[(type_data.index != '饮料') & (type_data.index != '酒类')]
food_num = food_data['数量'].sum()
food_sole = food_data['销售额'].sum()
food_num_perc = food_num/(food_num+drink_num)
drink_num_perc = drink_num/(food_num+drink_num)
food_sole_perc = food_sole/(food_sole+drink_sole)
drink_sole_perc = drink_sole/(food_sole+drink_sole)
plt.figure(figsize=(15,8))
plt.subplot(1,2,1)
paches,texts,autotexts = plt.pie([food_num_perc,drink_num_perc],autopct='%0.1f%%',labels=['食物占比','酒水饮料占比'])
plt.title('数售占比',fontsize=24)
#设置字体大小和颜色
for text in autotexts:
text.set_color('white')
text.set_fontsize(24)
for t in texts:
t.set_fontsize(24)
plt.subplot(1,2,2)
paches,texts,autotexts = plt.pie([food_sole_perc,drink_sole_perc],autopct='%0.2f%%',labels=['食物占比','酒水饮料占比'])
plt.title('销售额占比',fontsize=24)
#设置字体大小和颜色
for text in autotexts:
text.set_color('white')
text.set_fontsize(24)
for t in texts:
t.set_fontsize(24)
plt.show()