【监督学习】套索回归与岭回归(含代码)
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
1、正则化
L1正则化
L1正则化的式子是这样的,原损失函数加上一个一阶范数:

这样根据上面L2正则化的推导思路就可以得到这样的一张图
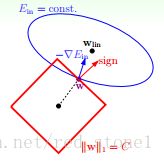
L2正则化
L2正则化就是在原来的损失函数的基础上加上权重的平方和:
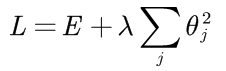
接下来解释为什么要这样做,正则化的目的是约束权重不能过多或过大,这样会使模型变的复杂,从而有可能导致过拟合。因此我们就在末尾加上了一个只与权重有关的多项式,这样再优化损失函数时,要原来的损失函数和权重都最小,相当于在最小化损失函数的同时加了一个条件,在满足这个条件下,对损失函数进行优化。
为什么要加平方和,而不是绝对值的和或者说三次方、四次方、n次方和?

L1,L2正则的区别与作用
L2正则化和L1正则化都可以减少过拟合,而L2正则化更多的作用是使参数大小更加均衡,防止出现某一个特征权重过大的情况,也就是说防止某个特征的权重过大、模型对某个特征过分敏感,这样即使数据集中有噪声,模型也不会对噪声特别敏感而发生过拟合。
L1正则化则可以使一些权重等于0,从而实现自动选择特征的效果,从而化简模型,防止模型过于复杂而过拟合。
为什么L1可以使部分权重等于0,而L2不可以呢?
看这两张图就可以理解了,L1正则化在优化的时候很容易取到角点,使一部分权重为0,从而实现自动选择特征,L2正则化中,正则项表示出来的图像是光滑的圆形,所以很难取到坐标轴上的点,很使部分特征权重为0。
2、岭回归
岭回归(英文名:ridge regression, Tikhonov regularization)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
1. 为什么损失精度和无偏性?
根据前面我介绍的无偏估计的概念,普通的线性回归是一种无偏估计,也就是这种估计的期望值是十分近似于总体数据的真实期望值的,而在这种估计方法之上加一个正则项,势必会改变估计的期望值,因此这种估计就变成了有偏估计。正则化的作用是防止过拟合(可以看这篇),相当于对目标函数的优化加上了一个约束条件,因此这样的优化效果一定会小于等于不加正则项的优惠效果,因此会损失精度。
2. 为什么对病态数据的拟合比普通的线性回归要强?
我对病态数据的理解就是,噪声过大、数据分布左偏或有偏、有较多离群值等等,这样的数据用普通的线性回归学习在学习样本的特征时也会过多的学习数据的噪声特征和离群特征,这样会导致模型过拟合,使模型的泛化能力(就是模型推广到不同数据集的表现)变差,因此可以加一些“约束”,也就是正则项,主动放弃一些模型在训练集上的精度,而使模型的泛化能力提升。
通线性回归的目标函数(看这里)是:
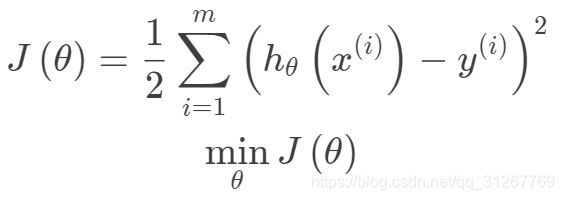
岭回归的目标函数是:
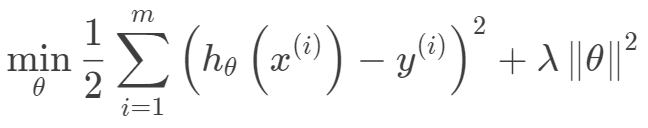
另外从最小二乘的角度来看,通过引入二范正则项,使得![]() 满秩,强制矩阵可逆。
满秩,强制矩阵可逆。
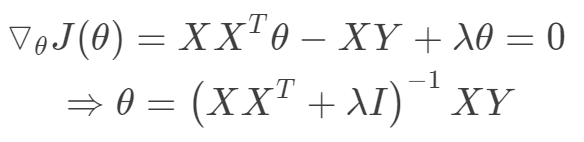
单位矩阵I的主对角线为1,像山岭一样,这就是岭回归的由来。
3、LASSO回归
Lasso回归和岭回归十分相似,不过是采用一范数来约束,就是加上了一个L1正则项。
Lasso回归的目标函数是:
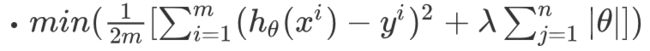
求导之后是MSE加上一个符号函数。
总结:岭回归很难剔除变量,而LASSO回归模型,将惩罚项由L2范数变为L1范数,可以将一些不重要的回归系数缩减为0,达到剔除变量的目的。
4、代码实现
岭回归代码(从零实现)
from __future__ import print_function, division
import numpy as npnp
import math
from mlfromscratch.utils import normalize, polynomial_features
class l1_regularization():
""" Regularization for Lasso Regression """
def __init__(self, alpha):
self.alpha = alpha
def __call__(self, w):
return self.alpha * np.linalg.norm(w)
def grad(self, w):
return self.alpha * np.sign(w)
class l2_regularization():
""" Regularization for Ridge Regression """
def __init__(self, alpha):
self.alpha = alpha
def __call__(self, w):
return self.alpha * 0.5 * w.T.dot(w)
def grad(self, w):
return self.alpha * w
class l1_l2_regularization():
""" Regularization for Elastic Net Regression """
def __init__(self, alpha, l1_ratio=0.5):
self.alpha = alpha
self.l1_ratio = l1_ratio
def __call__(self, w):
l1_contr = self.l1_ratio * np.linalg.norm(w)
l2_contr = (1 - self.l1_ratio) * 0.5 * w.T.dot(w)
return self.alpha * (l1_contr + l2_contr)
def grad(self, w):
l1_contr = self.l1_ratio * np.sign(w)
l2_contr = (1 - self.l1_ratio) * w
return self.alpha * (l1_contr + l2_contr)
class Regression(object):
""" Base regression model. Models the relationship between a scalar dependent variable y and the independent
variables X.
Parameters:
-----------
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, n_iterations, learning_rate):
self.n_iterations = n_iterations
self.learning_rate = learning_rate
def initialize_weights(self, n_features):
""" Initialize weights randomly [-1/N, 1/N] """
limit = 1 / math.sqrt(n_features)
self.w = np.random.uniform(-limit, limit, (n_features, ))
def fit(self, X, y):
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
self.training_errors = []
self.initialize_weights(n_features=X.shape[1])
# Do gradient descent for n_iterations
for i in range(self.n_iterations):
y_pred = X.dot(self.w)
# Calculate l2 loss
mse = np.mean(0.5 * (y - y_pred)**2 + self.regularization(self.w))
self.training_errors.append(mse)
# Gradient of l2 loss w.r.t w
grad_w = -(y - y_pred).dot(X) + self.regularization.grad(self.w)
# Update the weights
self.w -= self.learning_rate * grad_w
def predict(self, X):
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
y_pred = X.dot(self.w)
return y_pred
class LinearRegression(Regression):
"""Linear model.
Parameters:
-----------
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
gradient_descent: boolean
True or false depending if gradient descent should be used when training. If
false then we use batch optimization by least squares.
"""
def __init__(self, n_iterations=100, learning_rate=0.001, gradient_descent=True):
self.gradient_descent = gradient_descent
# No regularization
self.regularization = lambda x: 0
self.regularization.grad = lambda x: 0
super(LinearRegression, self).__init__(n_iterations=n_iterations,
learning_rate=learning_rate)
def fit(self, X, y):
# If not gradient descent => Least squares approximation of w
if not self.gradient_descent:
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
# Calculate weights by least squares (using Moore-Penrose pseudoinverse)
U, S, V = np.linalg.svd(X.T.dot(X))
S = np.diag(S)
X_sq_reg_inv = V.dot(np.linalg.pinv(S)).dot(U.T)
self.w = X_sq_reg_inv.dot(X.T).dot(y)
else:
super(LinearRegression, self).fit(X, y)
class LassoRegression(Regression):
"""Linear regression model with a regularization factor which does both variable selection
and regularization. Model that tries to balance the fit of the model with respect to the training
data and the complexity of the model. A large regularization factor with decreases the variance of
the model and do para.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree, reg_factor, n_iterations=3000, learning_rate=0.01):
self.degree = degree
self.regularization = l1_regularization(alpha=reg_factor)
super(LassoRegression, self).__init__(n_iterations,
learning_rate)
def fit(self, X, y):
X = normalize(polynomial_features(X, degree=self.degree))
super(LassoRegression, self).fit(X, y)
def predict(self, X):
X = normalize(polynomial_features(X, degree=self.degree))
return super(LassoRegression, self).predict(X)
class PolynomialRegression(Regression):
"""Performs a non-linear transformation of the data before fitting the model
and doing predictions which allows for doing non-linear regression.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree, n_iterations=3000, learning_rate=0.001):
self.degree = degree
# No regularization
self.regularization = lambda x: 0
self.regularization.grad = lambda x: 0
super(PolynomialRegression, self).__init__(n_iterations=n_iterations,
learning_rate=learning_rate)
def fit(self, X, y):
X = polynomial_features(X, degree=self.degree)
super(PolynomialRegression, self).fit(X, y)
def predict(self, X):
X = polynomial_features(X, degree=self.degree)
return super(PolynomialRegression, self).predict(X)
class RidgeRegression(Regression):
"""Also referred to as Tikhonov regularization. Linear regression model with a regularization factor.
Model that tries to balance the fit of the model with respect to the training data and the complexity
of the model. A large regularization factor with decreases the variance of the model.
Parameters:
-----------
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, reg_factor, n_iterations=1000, learning_rate=0.001):
self.regularization = l2_regularization(alpha=reg_factor)
super(RidgeRegression, self).__init__(n_iterations,
learning_rate)
class PolynomialRidgeRegression(Regression):
"""Similar to regular ridge regression except that the data is transformed to allow
for polynomial regression.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree, reg_factor, n_iterations=3000, learning_rate=0.01, gradient_descent=True):
self.degree = degree
self.regularization = l2_regularization(alpha=reg_factor)
super(PolynomialRidgeRegression, self).__init__(n_iterations,
learning_rate)
def fit(self, X, y):
X = normalize(polynomial_features(X, degree=self.degree))
super(PolynomialRidgeRegression, self).fit(X, y)
def predict(self, X):
X = normalize(polynomial_features(X, degree=self.degree))
return super(PolynomialRidgeRegression, self).predict(X)
class ElasticNet(Regression):
""" Regression where a combination of l1 and l2 regularization are used. The
ratio of their contributions are set with the 'l1_ratio' parameter.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
l1_ration: float
Weighs the contribution of l1 and l2 regularization.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree=1, reg_factor=0.05, l1_ratio=0.5, n_iterations=3000,
learning_rate=0.01):
self.degree = degree
self.regularization = l1_l2_regularization(alpha=reg_factor, l1_ratio=l1_ratio)
super(ElasticNet, self).__init__(n_iterations,
learning_rate)
def fit(self, X, y):
X = normalize(polynomial_features(X, degree=self.degree))
super(ElasticNet, self).fit(X, y)
def predict(self, X):
X = normalize(polynomial_features(X, degree=self.degree))
return super(ElasticNet, self).predict(X)套索回归代码(从零实现)
from __future__ import print_function, division
import numpy as np
import math
from mlfromscratch.utils import normalize, polynomial_features
class l1_regularization():
""" Regularization for Lasso Regression """
def __init__(self, alpha):
self.alpha = alpha
def __call__(self, w):
return self.alpha * np.linalg.norm(w)
def grad(self, w):
return self.alpha * np.sign(w)
class l2_regularization():
""" Regularization for Ridge Regression """
def __init__(self, alpha):
self.alpha = alpha
def __call__(self, w):
return self.alpha * 0.5 * w.T.dot(w)
def grad(self, w):
return self.alpha * w
class l1_l2_regularization():
""" Regularization for Elastic Net Regression """
def __init__(self, alpha, l1_ratio=0.5):
self.alpha = alpha
self.l1_ratio = l1_ratio
def __call__(self, w):
l1_contr = self.l1_ratio * np.linalg.norm(w)
l2_contr = (1 - self.l1_ratio) * 0.5 * w.T.dot(w)
return self.alpha * (l1_contr + l2_contr)
def grad(self, w):
l1_contr = self.l1_ratio * np.sign(w)
l2_contr = (1 - self.l1_ratio) * w
return self.alpha * (l1_contr + l2_contr)
class Regression(object):
""" Base regression model. Models the relationship between a scalar dependent variable y and the independent
variables X.
Parameters:
-----------
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, n_iterations, learning_rate):
self.n_iterations = n_iterations
self.learning_rate = learning_rate
def initialize_weights(self, n_features):
""" Initialize weights randomly [-1/N, 1/N] """
limit = 1 / math.sqrt(n_features)
self.w = np.random.uniform(-limit, limit, (n_features, ))
def fit(self, X, y):
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
self.training_errors = []
self.initialize_weights(n_features=X.shape[1])
# Do gradient descent for n_iterations
for i in range(self.n_iterations):
y_pred = X.dot(self.w)
# Calculate l2 loss
mse = np.mean(0.5 * (y - y_pred)**2 + self.regularization(self.w))
self.training_errors.append(mse)
# Gradient of l2 loss w.r.t w
grad_w = -(y - y_pred).dot(X) + self.regularization.grad(self.w)
# Update the weights
self.w -= self.learning_rate * grad_w
def predict(self, X):
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
y_pred = X.dot(self.w)
return y_pred
class LinearRegression(Regression):
"""Linear model.
Parameters:
-----------
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
gradient_descent: boolean
True or false depending if gradient descent should be used when training. If
false then we use batch optimization by least squares.
"""
def __init__(self, n_iterations=100, learning_rate=0.001, gradient_descent=True):
self.gradient_descent = gradient_descent
# No regularization
self.regularization = lambda x: 0
self.regularization.grad = lambda x: 0
super(LinearRegression, self).__init__(n_iterations=n_iterations,
learning_rate=learning_rate)
def fit(self, X, y):
# If not gradient descent => Least squares approximation of w
if not self.gradient_descent:
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
# Calculate weights by least squares (using Moore-Penrose pseudoinverse)
U, S, V = np.linalg.svd(X.T.dot(X))
S = np.diag(S)
X_sq_reg_inv = V.dot(np.linalg.pinv(S)).dot(U.T)
self.w = X_sq_reg_inv.dot(X.T).dot(y)
else:
super(LinearRegression, self).fit(X, y)
class LassoRegression(Regression):
"""Linear regression model with a regularization factor which does both variable selection
and regularization. Model that tries to balance the fit of the model with respect to the training
data and the complexity of the model. A large regularization factor with decreases the variance of
the model and do para.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree, reg_factor, n_iterations=3000, learning_rate=0.01):
self.degree = degree
self.regularization = l1_regularization(alpha=reg_factor)
super(LassoRegression, self).__init__(n_iterations,
learning_rate)
def fit(self, X, y):
X = normalize(polynomial_features(X, degree=self.degree))
super(LassoRegression, self).fit(X, y)
def predict(self, X):
X = normalize(polynomial_features(X, degree=self.degree))
return super(LassoRegression, self).predict(X)
class PolynomialRegression(Regression):
"""Performs a non-linear transformation of the data before fitting the model
and doing predictions which allows for doing non-linear regression.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree, n_iterations=3000, learning_rate=0.001):
self.degree = degree
# No regularization
self.regularization = lambda x: 0
self.regularization.grad = lambda x: 0
super(PolynomialRegression, self).__init__(n_iterations=n_iterations,
learning_rate=learning_rate)
def fit(self, X, y):
X = polynomial_features(X, degree=self.degree)
super(PolynomialRegression, self).fit(X, y)
def predict(self, X):
X = polynomial_features(X, degree=self.degree)
return super(PolynomialRegression, self).predict(X)
class RidgeRegression(Regression):
"""Also referred to as Tikhonov regularization. Linear regression model with a regularization factor.
Model that tries to balance the fit of the model with respect to the training data and the complexity
of the model. A large regularization factor with decreases the variance of the model.
Parameters:
-----------
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, reg_factor, n_iterations=1000, learning_rate=0.001):
self.regularization = l2_regularization(alpha=reg_factor)
super(RidgeRegression, self).__init__(n_iterations,
learning_rate)
class PolynomialRidgeRegression(Regression):
"""Similar to regular ridge regression except that the data is transformed to allow
for polynomial regression.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree, reg_factor, n_iterations=3000, learning_rate=0.01, gradient_descent=True):
self.degree = degree
self.regularization = l2_regularization(alpha=reg_factor)
super(PolynomialRidgeRegression, self).__init__(n_iterations,
learning_rate)
def fit(self, X, y):
X = normalize(polynomial_features(X, degree=self.degree))
super(PolynomialRidgeRegression, self).fit(X, y)
def predict(self, X):
X = normalize(polynomial_features(X, degree=self.degree))
return super(PolynomialRidgeRegression, self).predict(X)
class ElasticNet(Regression):
""" Regression where a combination of l1 and l2 regularization are used. The
ratio of their contributions are set with the 'l1_ratio' parameter.
Parameters:
-----------
degree: int
The degree of the polynomial that the independent variable X will be transformed to.
reg_factor: float
The factor that will determine the amount of regularization and feature
shrinkage.
l1_ration: float
Weighs the contribution of l1 and l2 regularization.
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, degree=1, reg_factor=0.05, l1_ratio=0.5, n_iterations=3000,
learning_rate=0.01):
self.degree = degree
self.regularization = l1_l2_regularization(alpha=reg_factor, l1_ratio=l1_ratio)
super(ElasticNet, self).__init__(n_iterations,
learning_rate)
def fit(self, X, y):
X = normalize(polynomial_features(X, degree=self.degree))
super(ElasticNet, self).fit(X, y)
def predict(self, X):
X = normalize(polynomial_features(X, degree=self.degree))
return super(ElasticNet, self).predict(X)