虚假新闻检测概述
几个概念
社交网络的新闻往往包括新闻内容,社交上下文内容,以及外部知识。其中新闻内容指的是文章中所包含的文本信息以及图片视频等多模态信息。社交上下文信息指的是新闻的发布者,新闻的传播网络,以及其他用户对新闻的评论和转发。外部知识指客观事实知识,通常由知识图谱表示外部知识。
虚假新闻检测的定义是给定新闻文章的新闻内容,社交上下文内容,以及外部知识,去判断新闻文章的真假。
分类(方法一)
根据Jointly embedding the local and global relations of heterogeneous graph for rumor detection论文来概述
相关工作
谣言检测的目标是根据社交媒体平台上发布的微博文本的相关信息(如文本内容、评论、传播方式、传播方式等)判断其是否为谣言。 相关作品可分为以下几类:
(1) 基于特征的分类方法
一些早期的研究侧重于基于手工制作的特征来检测谣言。 这些特征主要是从文本内容和用户的个人资料信息中提取的。Castillo等人在“Information credibility on twitter”利用各种类型的特征,即基于文本、基于用户、基于主题和基于传播的特征来研究 Twitter 上新闻的可信度,Yang等人在“Detect Rumors Using Time Series of Social Context Information on Microblogging Websites”中基于谣言生命周期的时间序列探索这些特征的时间特征,以融合各种社会背景信息
缺点:然而,社交媒体数据的规模和复杂性带来了许多技术挑战。 首先,社交媒体中使用的语言是高度非正式的、不合语法的和动态的,因此不能直接应用传统的自然语言处理技术。 其次,总是有一种或几种类型的手工制作的功能不可用、不充分或被操纵。
(2) 深度学习方法
近年来研究人员应用深度学习模型来自动学习用于谣言检测的有效特征。
16年由香港中文大学的马晶博士发表的“Detecting rumors from microblogs with recurrent neural networks“首次将深度学习技术应用到虚假新闻检测中。该方法将新闻的每个句子输入到循环神经网络RNN,LSTM或者GRU中,利用循环神经网络的隐层向量表示新闻信息,将隐藏层信息输入到分类器中,得到分类结果。
Yu等人在“A Convolutional Approach for Misinformation Identification”提出了一种基于卷积神经网络(CNN)的错误信息识别卷积方法,该方法可以捕获重要特征之间的高级交互。
缺点:然而,这些方法要么忽略传播模式,要么将传播路径建模为序列结构,不能充分利用微博的传播信息。 此外,这些方法很少关注谣言的早期发现。
(3) 传播树相关方法
与以往注重利用微博文本信息的方法不同,树相关方法的传播侧重于真假信息传播特性的差异。 Fang Jin等人在“Epidemiological modeling of news and rumors on Twitter”利用流行病学模型来描述 Twitter 上由真实新闻和虚假新闻产生的信息级联。 吴等人在“False rumors detection on sina weibo by propagation structures”提出了一个随机游走图内核来对消息的传播树进行建模,以改进谣言检测。Sampson等人在“Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection” 中在有关新闻故事的对话片段之间应用隐式联系来预测其真实性。 马等人在“Detect rumors in microblog posts using propagation structure via kernel learning”中 提出了一种基于内核的方法,通过传播树来捕获微博帖子传播的高阶模式,这为微博如何随时间传播和发展提供了有价值的线索。
缺点:然而,社交媒体上的消息传播本质上是以异构图的形式传播的。 在图表中,用户传递或转发消息以使其传播速度更快、范围更广。 这些基于传播树的方法只是探索了信息传输结构的差异,没有考虑不同传播树之间的关系。
分类(方法二):
根据这篇文章(点我)概述
一、基于文章信息的虚假新闻检测
(1) 基于文本的虚假新闻检测
基于文本的有监督虚假新闻检测方法将新闻的文本信息作为输入,对虚假新闻进行检测。
从19-20年共六篇突出性工作给虚假新闻检测带来了巨大影响。
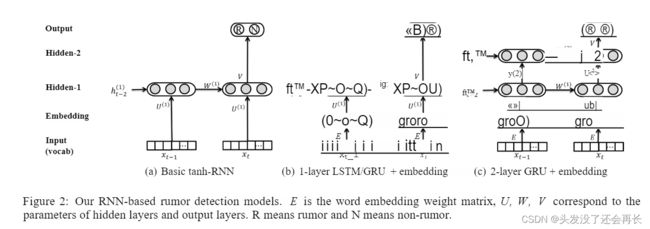
①IJCAI16年由香港中文大学的马晶博士发表的“Detecting rumors from microblogs with recurrent neural networks“首次将深度学习技术应用到虚假新闻检测中。
该方法将新闻的每个句子输入到循环神经网络RNN,LSTM或者GRU中,利用循环神经网络的隐层向量表示新闻信息,将隐藏层信息输入到分类器中,得到分类结果。
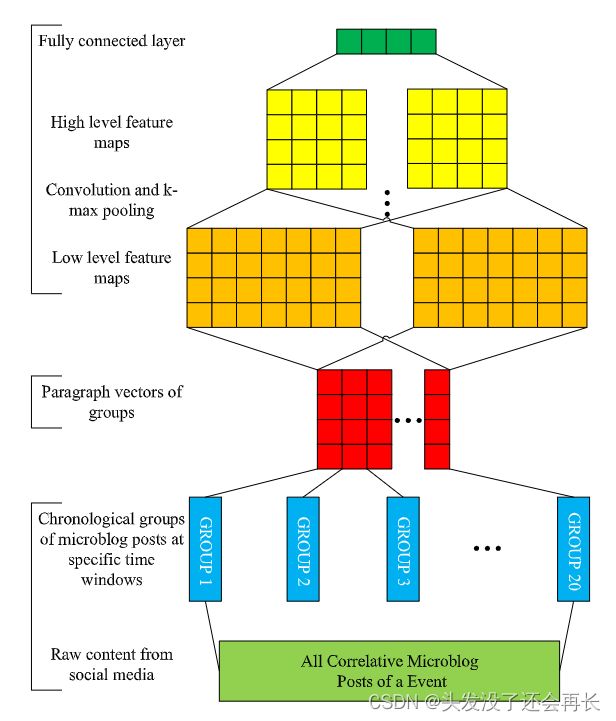
②IJCAI17年的文章“A Convolutional Approach for Misinformation Identification“首次利用卷积神经网络建模新闻文章。
该工作将新闻事件的各个post映射到向量空间,之后将各个post向量拼接形成一个矩阵,之后利用卷积神经网络提取文本特征,将得到的嵌入向量输入到分类器中,得到最后的分类结果。
③WWW18年香港中文大学马晶博士的文章“Detect rumor and stance jointly by neural multi-task learning “第一次将multi-task的思想应用到虚假新闻检测中。
该文章将虚假新闻检测任务和立场分类任务组合成一个多任务模型,利用RNN作为backbone,训练两个任务,取得了不错的结果。

④WWW19年香港中文大学马晶博士的文章“.Detect rumors on twitter by promoting information campaigns with generative adversarial learning”第一次将对抗训练的思想应用到虚假新闻检测中。
该文章利用生成器将谣言转化为非谣言,将谣言转化为非谣言,扩展了训练数据。之后将生成器生成的新闻和原始新闻输入到判别器中进行虚假新闻检测。利用对抗学习,对抗训练生成器和判别器,提升模型的鲁棒性和分类准确率。

⑤发表在EMNLP19的文章“Do Sentence Interactions Matter? Leveraging Sentence Level Representations for Fake News Classification”将新闻文章建模为一张以句子为节点,以句子间相似度为边的图。
将虚假新闻检测问题转化为图分类问题。利用GCN融合图中节点之间的信息,获得节点嵌入向量,将节点向量池化得到图嵌入,输入分类器中进行分类,取得了不错的效果。
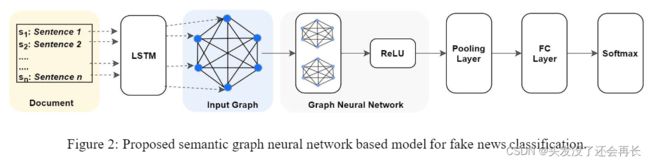
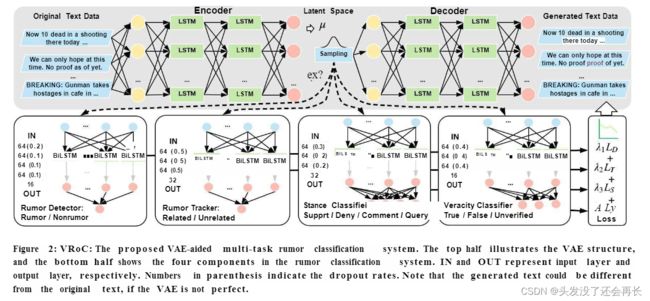
⑥发表在WWW20的文章“Vroc: Variational autoencoder-aided multi-task rumor classifier based on text”使用变分自动编码器VAE自编码文本信息的方式得到新闻文本的嵌入表示,并且将得到的新闻向量进行多任务学习,提升了模型的效果。
(2) 基于视觉信息的有监督虚假新闻检测
新闻中不仅包含文本信息,还包含图片,视频等视觉信息。
随着深度学习的兴起,大量的工作使用卷积神经网络VGG或者ResNet对图片进行特征抽取,利用抽取到的特征进行虚假新闻检测。但现有的图片造假技术可以更改图像的语义信息,传统基于CNN的模型只可以提取图片像素级信息,无法识别图片是否经过伪造。
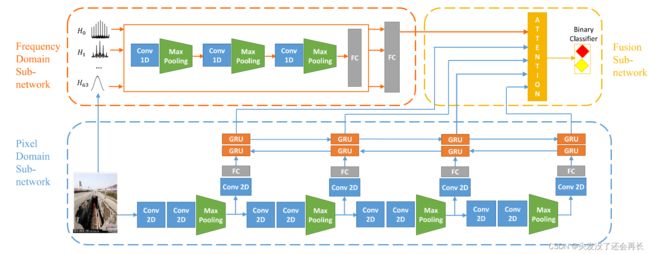
计算机视觉方面的研究表明,经过修图软件伪造得到的图片与原始图片在频域的特征会有很大的不同。基于此,中科院曹娟老师团队提出虚假图片判别器MVNN,该工作发表在ICDM19上。MVNN提取图片的空域特征和频域特征,利用频领特征判别图片是否经过修图软件进行伪造,利用空域特征识别图片的语义信息,将得到的空域embedding和频域embedding拼接到一起,输入到分类器重,得到分类结果。
(3) 基于多模态信息的有监督虚假新闻检测
以上研究表明文本信息和图片信息在虚假新闻检测任务是有效的。很直觉的想法是将文本信息和视觉信息结合起来进行虚假新闻检测。
现有的基于多模态信息进行虚假新闻检测方法大致可以分为三类:
①将多模态信息进行拼接融合:
随着深度神经网络和预训练模型的兴起,出现很多功能强大的特征提取器,比如文本特征提取器Bert,transformer等,视觉特征提取器VGG,Resnet等。很多学者利用视觉特征提取器提取视觉信息,利用文本特征提取器提取文本特征,之后将视觉信息和文本信息进行拼接融合,进行虚假新闻检测。
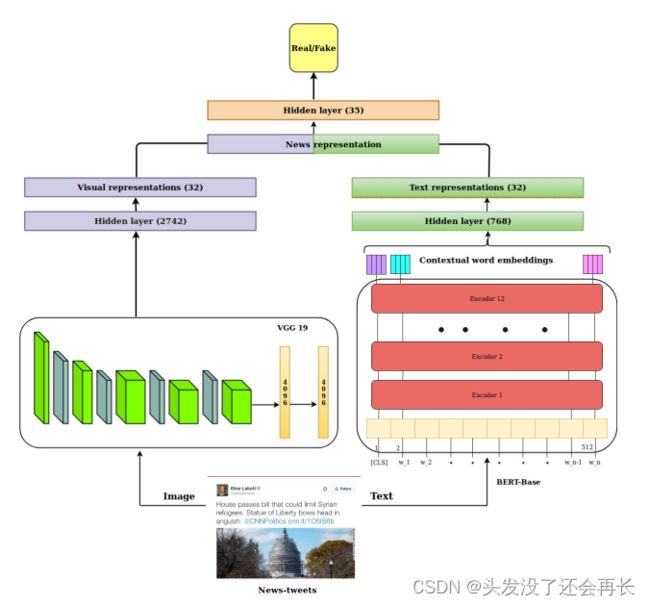
2019年发表在BIG MM的文章“Spotfake: A multi-modal framework for fake news detection “利用VGG19提取视觉信息,利用BERT提取文本信息,将视觉信息和文本信息拼接,输入到分类器中,对虚假新闻进行分类。
2020年发表在AAAI的“Spotfake+: A multimodal framework for fake news detection via transfer learning “利用VGG提取视觉特征,利用XLNET提取文本特征,将两者进行拼接输入到分类器中,对虚假新闻进行分类。
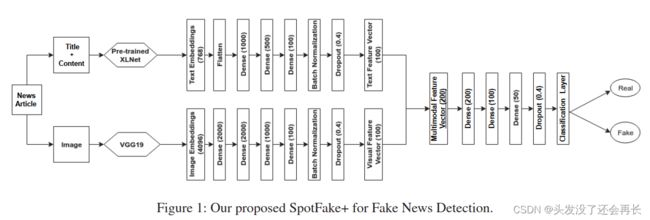
计算机研究与发展的文章“. MSRD: Multi-Modal Web Rumor Detection Method“考虑了新闻图片中包含的文本信息。使用LSTM建模文本信息以及图片中的文本信息,使用VGG建模视觉信息,最后将视觉信息,图片中的文本信息,新闻本身的文本信息拼接,得到最终的新闻表示,送入到分类器中,得到最终的分类结果。
但是直接将视觉信息和文本信息拼接的方法过于简单,无法充分利用多模态信息,很多学者设计一些辅助任务帮助模型更好的理解多模态信息。

发表在KDD18的“Eann: Event adversarial neural networks for multi-modal fake news detection “利用VGG提取视觉特征,利用Text-CNN提取视觉特征,将视觉信息和文本信息拼接得到新闻的表示。为了让模型更好的利用多模态信息,EANN设计了一个辅助任务,事件鉴别。事件鉴别器将拼接的多模态新闻信息作为输入,输出事件的类别。通过辅助任务更好的理解多模态信息,从而帮助虚假新闻检测。
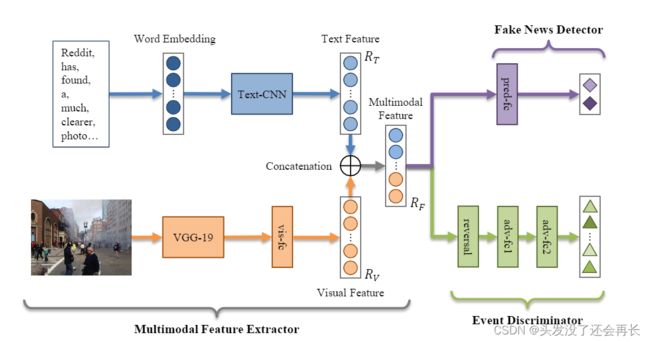
发表在WWW18的文章“Mvae: Multimodal variational autoencoder for fake news detection“利用VGG提取图像特征,利用双向的LSTM提取文本特征,将视觉特征和文本特征拼接得到新闻的表示。为了让模型更好的利用多模态信息,MVAE设计了一个辅助任务,新闻重构任务。通过encoder编码新闻的视觉信息和文本信息,通过decoder将视觉信息和文本信息进行重构,通过重构任务,更好的融合新闻的多模态信息。最后,将编码器得到的新闻embedding输入到分类器中,得到新闻的分类。
②利用模态之间的对比识别虚假新闻
大量学者认为如果新闻图片内容与文本内容不符,则说明新闻是虚假新闻。基于该假设,学者将新闻的图片信息与文本信息编码后,计算两者的相似度,如果相似度较高,则说明新闻的文本信息和视觉信息匹配,为真实新闻;如果相似度较低,则说明新闻的文本信息和视觉信息彼此不匹配,为虚假新闻。
KDD20年发表的文章“Similarity-Aware Multi-modal Fake News Detection[J]. Advances in Knowledge Discovery and Data Mining“是检测新闻图文相符性的代表工作。该工作利用image2text模型将视觉信息转化为文本信息,并通过全连接层将文本信息和视觉信息映射到同一向量空间中,之后对比视觉信息和文本信息之间的相似度。如果相似度较高,则图文相符,为真实新闻;如果相似度较低,则图文不符,为虚假新闻。
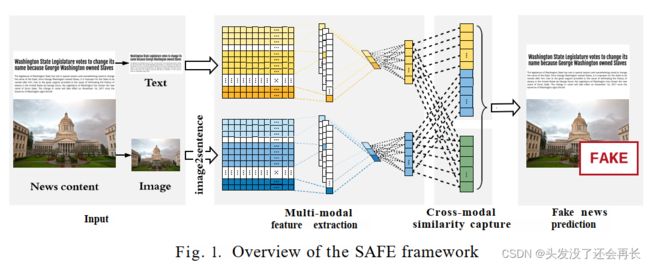
IPM21发表的文章“Detecting fake news by exploring the consistency of multimodal data“利用BERT建模文本信息,利用ResNet建模视觉信息,计算两者之间的相似度,判别图文是否相符。
③多模态信息增强
新闻往往即包含文字信息,又包含视觉信息,两种模态信息可以相互增强,视觉信息可以帮助模型更好的理解文本信息,文本信息也可以帮助模型更好的理解视觉信息。基于此,很多学者提出多模态之间的信息增强可以帮助模型更好的理解新闻内容,从而更好的分析新闻的真假。
中科院曹娟老师发表在ACM MM17的文章“Multimodal fusion with recurrent neural networks for rumor detection on microblogs“首次提出利用模态之间的注意力对模态之间的信息进行增强。该工作使用LSTM提取文本信息,使用VGG提取视觉信息,之后利用模态之间的注意力机制增强模态之间的信息理解,更好的对多模态信息进行理解,将融合的多模态信息输入到分类器中进行分类,取得不错的效果。
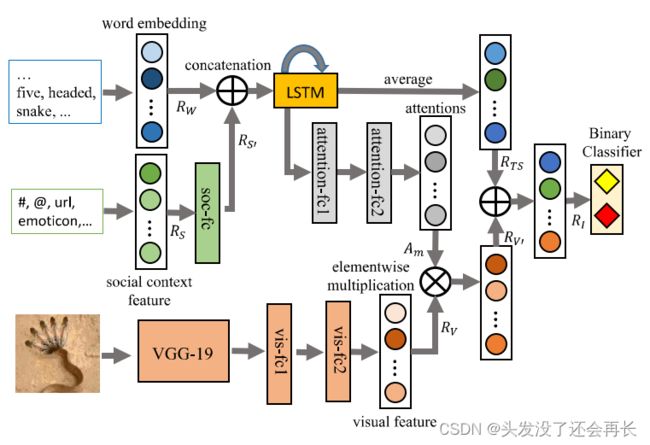
ACM MM19的文章“Multi-modal knowledge-aware event memory network for social media rumor detection“利用VGG提取视觉信息,利用双向GRU提取文本信息,利用注意力机制获得文本信息增强的视觉表示,更好的理解了多模态信息。
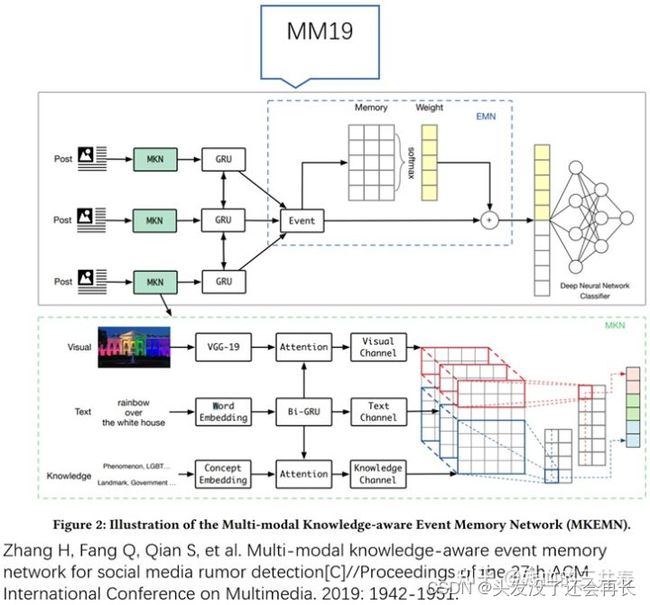
ACL21的文章“Multimodal Fusion with Co-Attention Networks for Fake News Detection “借鉴了人们阅读新闻时的习惯”人们通常是阅读一下文本,再看看图片,再阅读文本,再看看图片“,设计了双层的图片文本信息co-attention,从而更好的融合图片信息和文本信息。该工作认为图像的频域和空域信息对虚假新闻检测都是有必要的,因此作者使用VGG建模图片的空域信息,利用CNN建模图片的频域信息,使用co-attention将频域信息和空域信息进行融合,得到更好的图片表示。
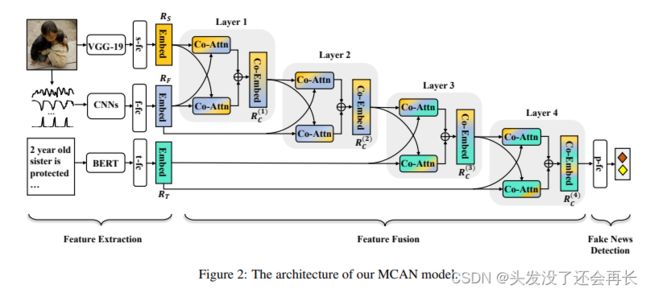
SIGIR21年的文章使用BERT建模文本信息,使用ResNet建模视觉信息,使用co-attention的方法利用文本信息对视觉信息进行增强,利用视觉信息对文本信息进行增强。该工作还注意到了分层的语义信息,认为每一层的语义信息都对虚假新闻的检测有所帮助,因此该工作将BERT每四层的信息输出与图片信息进行融合,很好的利用了分层的语义信息。

CIKM21的工作利用预训练的BERT建模文本信息,利用ResNet建模视觉信息,利用多头transformer对文本信息和视觉信息进行融合,从而获得更好的新闻表示。除此之外,该工作还利用有监督的对比学习方法学习真实新闻和虚假新闻的高阶特征,从而更好的区分真实新闻和虚假新闻。该工作选择话题相似,且真实性相同的新闻作为正样本,选择话题相似,且真实性不同的新闻作为负样本,利用有监督的对比学习拉近正例之间的距离,拉远正例与负例之间的距离,从而学习到真实新闻和虚假新闻的高阶特征,更好的区分真实新闻和虚假新闻。
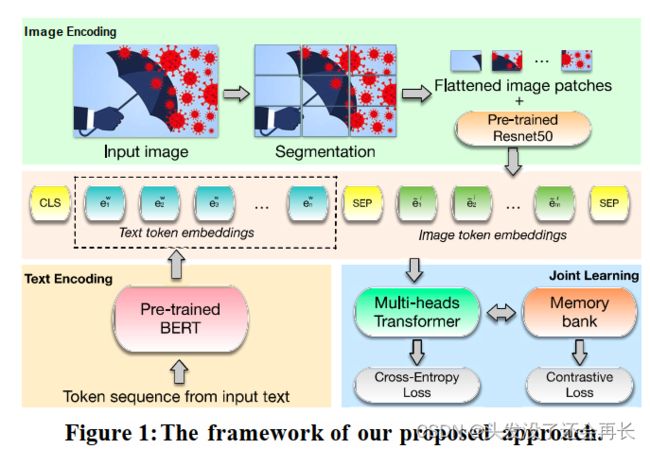
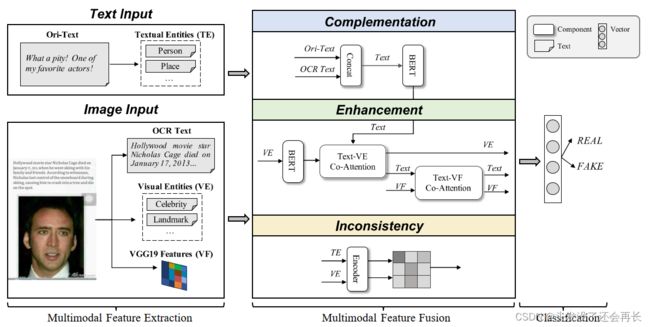
中科院曹娟老师团队发表在ACM MM21年的文章“Improving Fake News Detection by Using an Entity-enhanced Framework to Fuse Diverse Multimodal Clues”综合关注了多模态之间的互补信息,多模态的信息增强,以及多模态信息之间的对比。
该工作考虑了图片中的嵌入文字,图片实体,以及图片整体信息。
将图片中的嵌入文字作为文本信息的补充,利用BERT建模文本信息和图片中的嵌入文字。该工作利用VGG提取整张图片信息,利用目标识别算法提取图像实体。该工作将文本信息与图像整体信息利用co-attention进行融合从而实现多模态信息增强。该工作计算文本实体与视觉实体之间的相似度,从而计算文本信息与视觉信息的相关程度。