高维数据降维(机器学习)
目录
一、实验内容
二、实验过程
1、算法思想
2、算法原理
3、算法分析
三、源程序代码
四、运行结果及分析
五、实验总结

一、实验内容
- 熟知高维数据降维的概念和基本算法思想;
- 掌握高维数据降维算法的算法原理;
- 掌握高维数据降维算法的设计及Python实现。
二、实验过程
1、算法思想
高维数据降维是指采用某种映射方法,降低随机变量的数量。例如将数据点从高维空间映射到低维空间中,从而实现维度减少。
降维分为:特征选择 和 特征提取
特征选择:是从含有冗余信息以及噪声信息的数据中找出主要变量;
特征提取:是去掉原来的数据,生成新的变量,可以寻找数据内部的本质结构特征。
2、算法原理
降维的过程是通过对输入的原始数据特征进行学习,得到一个映射函数,实现将输入样本映射后到低维空间中之后,原始数据特征并没有明显的损失。
通常情况下新空间的维度要小于原空间的维度。目前大部分降维算法是处理向量形式的数据。
3、算法分析
1.将原始数据进行标准化(一般是去均值化,如果特征在不同的数量级上,则还要将其除以标准差)
2.计算标准化数据集的协方差矩阵
3.计算协方差矩阵的特征值和特征向量
4.保留最重要(特征值最大)的前k个特征(k就表示降维后的维度)
5.找到这k个特征值对应的特征向量
6.将标准化数据集乘以该k个特征向量,得到降维后的结果
三、源程序代码
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
from matplotlib.patches import FancyArrowPatch
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
np.random.seed(1) # random seed for consistency
mu_vec1 = np.array([0,0,0])
cov_mat1 = np.array([[1,0,0],[0,1,0],[0,0,1]])
class1_sample = np.random.multivariate_normal(mu_vec1, cov_mat1, 20).T
mu_vec2 = np.array([1,1,1])
cov_mat2 = np.array([[1,0,0],[0,1,0],[0,0,1]])
class2_sample = np.random.multivariate_normal(mu_vec2, cov_mat2, 20).T
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111, projection='3d')
plt.rcParams['legend.fontsize'] = 10
ax.plot(class1_sample[0,:], class1_sample[1,:], class1_sample[2,:], 'o', markersize=8, color='blue', alpha=0.5, label='class1')
ax.plot(class2_sample[0,:], class2_sample[1,:], class2_sample[2,:], '^', markersize=8, alpha=0.5, color='red', label='class2')
plt.title('class1 and class2 ')
ax.legend(loc='upper right')
plt.show()
all_samples = np.concatenate((class1_sample, class2_sample), axis=1)
mean_x = np.mean(all_samples[0,:])
mean_y = np.mean(all_samples[1,:])
mean_z = np.mean(all_samples[2,:])
mean_vector = np.array([[mean_x],[mean_y],[mean_z]])
print('Mean Vector:\n', mean_vector)
scatter_matrix = np.zeros((3,3))
for i in range(all_samples.shape[1]):
scatter_matrix += (all_samples[:,i].reshape(3,1) - mean_vector).dot((all_samples[:,i].reshape(3,1) - mean_vector).T)
print('Scatter Matrix:\n', scatter_matrix)
sample_x =all_samples[0,:]
sample_y =all_samples[1,:]
sample_z =all_samples[2,:]
cov_mat = np.cov([sample_x,sample_y,sample_z])
print('Covariance Matrix:\n', cov_mat)
# eigenvectors and eigenvalues for the from the scatter matrix
eig_val_sc, eig_vec_sc = np.linalg.eig(scatter_matrix)
# eigenvectors and eigenvalues for the from the covariance matrix
eig_val_cov, eig_vec_cov = np.linalg.eig(cov_mat)
#print("eig_val_cov:",eig_val_cov)
print("eig_vec_sc:",eig_vec_sc)
print("eig_val_sc",eig_val_sc)
for i in range(len(eig_val_sc)):
eigvec_sc = eig_vec_sc[:,i].reshape(1,3).T
eigvec_cov = eig_vec_cov[:,i].reshape(1,3).T
assert eigvec_sc.all() == eigvec_cov.all(), 'Eigenvectors are not identical'
print('Eigenvector {}: \n{}'.format(i+1, eigvec_sc))
print('Eigenvalue {} from scatter matrix: {}'.format(i+1, eig_val_sc[i]))
print('Eigenvalue {} from covariance matrix: {}'.format(i+1, eig_val_cov[i]))
print('Scaling factor: ', eig_val_sc[i]/eig_val_cov[i])
print(40 * '-')
for i in range(len(eig_val_sc)):
eigv = eig_vec_sc[:,i].reshape(1,3).T
np.testing.assert_array_almost_equal(scatter_matrix.dot(eigv), eig_val_sc[i] * eigv,
decimal=6, err_msg='', verbose=True)
class Arrow3D(FancyArrowPatch):
def __init__(self, xs, ys, zs, *args, **kwargs):
FancyArrowPatch.__init__(self, (0,0), (0,0), *args, **kwargs)
self._verts3d = xs, ys, zs
def draw(self, renderer):
xs3d, ys3d, zs3d = self._verts3d
xs, ys, zs = proj3d.proj_transform(xs3d, ys3d, zs3d, renderer.M)
self.set_positions((xs[0],ys[0]),(xs[1],ys[1]))
FancyArrowPatch.draw(self, renderer)
fig = plt.figure(figsize=(7,7))
ax = fig.add_subplot(111, projection='3d')
ax.plot(class1_sample[0,:], class1_sample[1,:], class1_sample[2,:], 'o', markersize=8, color='blue', alpha=0.5, label='class1')
ax.plot(class2_sample[0,:], class2_sample[1,:], class2_sample[2,:], '^', markersize=8, alpha=0.5, color='red', label='class2')
print(mean_x)
ax.plot([mean_x], [mean_y], [mean_z], 'o', markersize=10, color='red', alpha=0.9)
# for v in eig_vec_sc.T:
# a = Arrow3D([mean_x, v[0]], [mean_y, v[1]], [mean_z, v[2]], mutation_scale=20, lw=3, arrowstyle="-|>", color="r")
# ax.add_artist(a)
ax.set_xlabel('x_values')
ax.set_ylabel('y_values')
ax.set_zlabel('z_values')
#plt.title("特征向量可视化")
plt.show()
eig_pairs = [(np.abs(eig_val_sc[i]), eig_vec_sc[:,i]) for i in range(len(eig_val_sc))]
print("eig_pairs:",eig_pairs)
# Sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs.sort(key=lambda x: x[0], reverse=True)
# Visually confirm that the list is correctly sorted by decreasing eigenvalues
for i in eig_pairs:
print(i[0])
matrix_w = np.hstack((eig_pairs[0][1].reshape(3,1), eig_pairs[1][1].reshape(3,1)))
print('Matrix W:\n', matrix_w)
transformed = matrix_w.T.dot(all_samples)
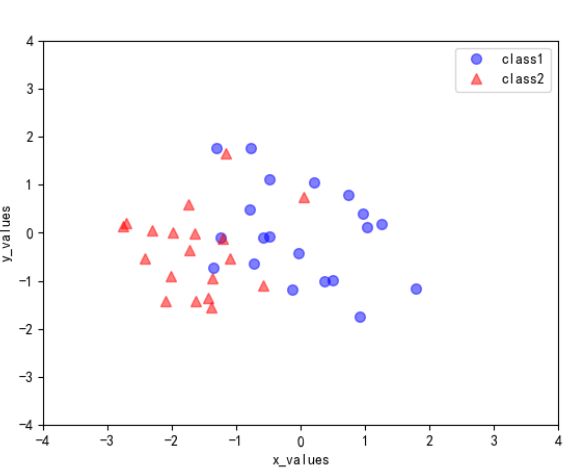
plt.plot(transformed[0,0:20], transformed[1,0:20], 'o', markersize=7, color='blue', alpha=0.5, label='class1')
plt.plot(transformed[0,20:40], transformed[1,20:40], '^', markersize=7, color='red', alpha=0.5, label='class2')
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.xlabel('x_values')
plt.ylabel('y_values')
plt.legend()
plt.show()
四、运行结果及分析

五、实验总结
数据降维可以降低模型的计算量并减少模型运行时间、降低噪音对于模型结果的影响、便于通过可视化方式展示归约后的维度信息并减少数据存储空间。因此,大多数情况下,当我们面临高维数据时,都需要对数据做降维处理。