目标检测打卡营下:YOLOv3、PP-YOLO、CornerNet、FCOS
文章目录
-
- 四、YOLO系列目标检测算法
- 五、世界冠军拆解CVPR2020赛题:如何打好AI比赛
-
- 5.1 AI比赛的本质
- 5.2 如何涨点
-
- 5.2.1 CrowdHuman吧比赛解析
- 5.2.2 铝压铸件检测问题解析
- 5.3 如何给解决方案排序?
- 5.4 冠军赛事分享:
- 六、PP-YOLO
-
- 6.1 PP-YOLO简介
- 6.2 PP-YOLO改进策略和效果
-
- 6.2.1 PaddleDetection YOLOv3优化策略
- 6.2.2 YOLOv3-ResNet50vd-DCN改进backbone
- 6.2.3 LB + EMA + DropBlock
- 6.2.4 IoU Loss&IoU Aware
- 6.2.4 grid sensitivity :消除grid网格敏感程度
- 6.2.5 Matrix NMS后处理
- 6.2.6 Coord Conv
- 6.2.7 SPP
- 6.2.8 更好的预训练权重&双倍迭代次数
- 6.2.9 总结
- 6.3 PP-YOLO工业案例分享
-
- 6.3.1 项目背景:输电线路环境检测
- 6.3.2 方案选择
- 6.4 答疑
- 七、 Anchor Free模型
-
- 7.1 Anchor Free简介
- 7.2 CornerNet
-
- 7.2.1 前言
- 7.2.2 CornerNet核心思想:Reduce penalty和corner pooling
- 7.2.3 CornerNet 网络结构和损失函数
- 7.2.4 CornerNet 检测效果
- 7.2.5 CornerNet-Lite
- 7.3 FCOS
- 7.4 CenterNet(待补充)
本文来自飞浆AI studio课程《目标检测7日打卡营》
四、YOLO系列目标检测算法
参考我的另一篇博文《YOLOv1——YOLOX系列及FCOS目标检测算法详解》
五、世界冠军拆解CVPR2020赛题:如何打好AI比赛
主讲人:电子羊
流程:比赛开始→构建baseline→调研数据集→可视化发现问题找到解决方案→按耗时尝试改进→上稳定收益的方案→提交最终结果结束比赛。
5.1 AI比赛的本质
AI比赛的本质是一个最大值搜素任务,如何在有限的时间内尝试更多的方法?如何找到更快的方法?答案是在baseline上迭代升级。即solution=Baseline+upgrede1+upgrede2+…
什么样的才是Baseline?目标检测中有一个通用的coco数据集,几乎所有的paper都在上面做过实验,超参数已经经过检验。下面是Faster-RCNN的baseline参数:

training schedule[8,11,12]表示训练12个epoch,在第8个epoch和第11个epoch时lr除以10,效果最好。
5.2 如何涨点
比赛中需要做什么?调研数据集、数据增强、调参、上trick这些都要做,但是怎么做,顺序很重要。推荐使用发现问题——>进行改进的思路。

如何发现问题?

没有检测到的目标、假阳性样本高分(目标认为这里有人其实没有)都会降低mAP。看一下baseline检测出的这两种情况的目标都是长啥样。
给错误分类后,调研paper可以上知乎等论坛搜索paper解析,或者github上搜detection paper,有的会总结一个paper list,大概50篇paper。摘要一般都会写发现了什么问题,如何解决的。这样找一找哪些paper有提到自己遇到的问题。比如《CVPR2020/2021行人检测重识别等论文,共33篇》、《CVPR2021 | CVPR2021最全整理,CVPR2021下载链接,CVPR2021全部论文代码》。
5.2.1 CrowdHuman吧比赛解析
以之前打的CrowdHuman为例,作者发现了8个问题,列出其中三种:
- 人体多姿态问题:

- 上图绿色框是TP,Ture Positive,这里确实有个人。
- 红色框是FP,比如右边这个FP,得分0.88还是挺高的。这里明明有个人,为啥是FP。因为他的左右手分别搭在两个人的肩膀上,所以他的真实框应该是很宽的,这样算,红色框的IoU肯定不到0.5了,就被认为不属于这个人,所以是FP。这也是人体姿态检测的难点,人体的一部分可能被遮挡住,就会给显露出的一部分很高的分。
- BBOX偏移:两个物体挨得很近的时候,预测框出现在中间。
比如下图红色框得分0.9,但是其实框住了两个人,这是因为预测时,这个框很难判断其属于左边还是右边,没办法对一个人进行回归,

- 严重的遮挡

上图蓝色代表miss掉的GTbox。比如上图最右侧的红色框,得分0.99。为啥这个框是这样的,估计是认为上面躺着的这个人的头和下面被遮挡的这个人的身体连起来是一个人。实际是躺着的这个人挡住了下面这个人的头。遮挡严重时会出现各种问题。
针对以上问题,有专门的paper可以解决。人体多姿态有篇论文是专门针对这个,用可变形的卷积实现,缓解这个问题。BBOX偏移问题,在行人检测中也有一篇著名的paper《Hierarchical Clustering With Hard-Batch Triplet Loss for Person Re-Identification》提出了一种loss,专门作用于这种两个人中间的anchor。其实只要稍微左或右偏移就可以轻松去掉(被nms掉)。
严重遮挡目前没有特别好的解决方案。但是CrowdHuman数据集中对这种遮挡物体提供了两种GT-BOX,一个是完整物体的边界框,一个是被遮住部分的边界框。两个框一起用,就知道有一部分是被遮住的。
5.2.2 铝压铸件检测问题解析
工业质检背景
铝压铸方式加工的产品统称铝压铸件,离变壳体就是铝压铸成型的,可用于发动机的机壳。离变壳内流动着汽油,所以其检测是汽车行业重中之重。如果壳体有缺陷,就可能造成发动机漏油事故。


铝压铸件视觉检测难点:

由检测框的面积来对缺陷大小进行评定。
铝压铸件视觉检测方案:
- 针对缺陷大小,采用精准标注,利用边界框的回归来实现缺陷大小的计量
- 多尺度问题:采用两阶段算法FasterR-CNN,利用ResNet101+FPN的方式,实现了对各个尺度缺陷的检测。
- 调整入网尺寸。本项目中,单张图像的图片大小为4096*3000,清晰度非常高。如果采用coco数据集的1333*800尺寸,小缺陷可能直接就没了。尺寸太大又增加计算量,最终入网尺寸为2048*1500,为原来的1/4。降低了resize缩放对小目标缺陷精度的影响。(工业上有时候就是这种很朴素的解决方案,效果非常好)
- 模型的训练和部署使用Tesla4显卡,最终被部署在一个windows环境下,采用c#调用C++预测程序(dll)方式实现,实现了高效的检测。
- 最终检测精度为95%,预测速度为200mS

5.3 如何给解决方案排序?
收益安排
- 方案的收益有稳定收益、难实现的收益、耗时短的收益
- 稳定收益就是做了一定会有的收益,比如更好的backbone网络(R50换成R101等),更深的模型更好的性能。但是这个大多数参赛者也会做,所以其实这部分稳定涨点的事情没有那么着急,可以放在后面做。
- 难实现的收益。作者打一个比赛中,有新的paper发表可以解决他的痛点,说是可以涨3个点,但是代码还没有开源。作者按照论文来复现,做了半个月但还是效果不理想。
- 耗时短的收益放在前面做。比赛本质是最大值搜素问题。搜的方案越多,成功可能性越大,所以耗时短的收益就放在前面做,把这些都试完。
调研数据集
有没有耗时短收益又高的方案?这就得先调研数据集。
- 入网尺寸:比如coco数据集的入网尺寸是1333*800,作者做的商超检查任务(就是检测商场货架上的货物,都堆得很密集)的图片,尺寸比这个大,可以将所有图片尺寸求平均来参考使用怎样的入网尺寸。入网尺寸还是很影响性能的,调整花不了多少时间,收益还很高
- anchor settings:比如行人检测,ratios=0.5表示这个框是横着的,就像是有人是躺着的,这种是很少的。如果去掉ratios=0.5的anchor,计算量减少1/3,准度也不会下降很多。而商超检测中,物品最小尺寸选择32、最大有512是否合理,需要调整?都是需要思考的。(感觉直接聚类选择anchor模板算了)
- training schedule、lr和bs:不建议调整,这些是试验很多次,得到效果最优下的参数值,不建议调整。
时间安排
跑更多的数据集、尝试更多的方案,都需要耗大量时间。所以需要: - 利用好空闲时间,比如晚上训练早上看结果。
- 并行做任务。跑idea的时候,做些其他的事情,比如baseline的可视化,看哪些框标注错误,是非常耗时间的。(作者说为了找出上面的8类错误,看了5万多张图,那三张截图还是局部放大的。)
5.4 冠军赛事分享:
- CrowdHuman竞赛冠军经验分享:https://zhuanlan.zhihu.com/p/68677880
- 商超检测冠军TechReport :https://trax-geometry.s3.amazonaws.com/cvpr_challenge/detection_challenge_technical_reports/1st A+Solution+for+Product+Detection+in+Densely+Packed+Scenes.pdf
- 商超检测亚军:TechReport :https://trax-geometry.s3.amazonaws.com/cvpr_challenge/detection_challenge_technical_reports/2nd_Working_with_scale_2nd_place_solution_to_Product_Detection_in_Densely

六、PP-YOLO
参考github官网文档《PP-YOLO 模型》
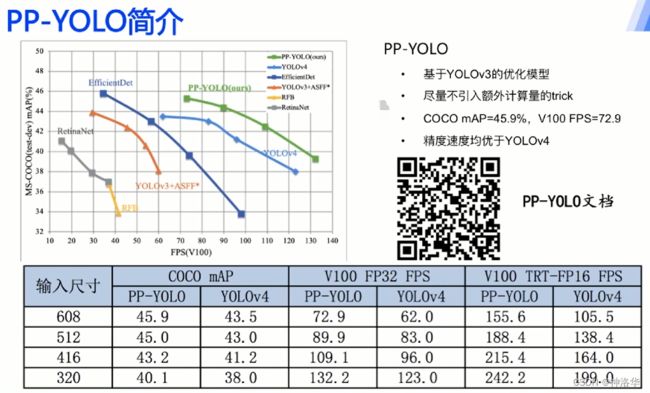
6.1 PP-YOLO简介
下图可见:PP-YOLO模型性能是由于YOLOv4模型的。


6.2 PP-YOLO改进策略和效果
下图总结了目标检测常用trick,标红的是PP-YOLO使用了的:

- 数据增强
- Image Mixup:两张图片混合为一张
- AutoAugment:预先定义好的图片增强方法池,会自动在里面选择合适的方法。
- Image Mosaic:YOLOV4用的方法,见《YOLOv1——YOLOX系列及FCOS目标检测算法详解》4.1。
- 数据采样
- OHEM:自动地选择 hard negative 来进行训练,不仅效率高而且性能好。可参考《OHEM 详解》
- Class aware Sampling:针对类别不平衡问题,调整不同数量类别检测物体的权重实现样本采样方法。
下面是PP-YOLO精度提升历程:

6.2.1 PaddleDetection YOLOv3优化策略
YOLOv3原作在coco数据集上精度为33, PaddleDetection上复现的基础版YOLOv3精度为38.9,推理速度不变。主要是做了如下优化:(参考Paper:Bag of FreebiesforTraining ObjectDetectionNeural Networks)

- Image Mixup:两种图片重叠起来混合为一张。比如下图样羊和路标互为空间扰动。
在PaddleDetection中只需要在预处理时加入Image Mixup算子就能实现此功能。PP-YOLO训练50w步,大概270epochs。一般是最后20个epoch不采用Mixup,前面的epoch都采用。
原论文中作者发现α=β=1.5时效果最好
- Label smooth:YOLOv3中,分类时使用sigmoid激活函数实现多分类。但是标签太硬(0或者1),sigmoid的输入的是-∞或者+∞才行,过于极限,容易导致过拟合。下图ε可以取1/class,比如1/80或者1/40。

- 卡间同步的批归一化:
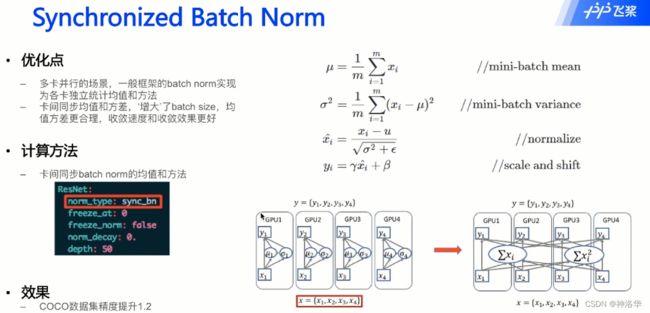
并行计算时,卡间同步的开销较大,为了简便,各张卡分配不同的数据后,只计算分配到部分数据的均值和方差,卡间数据相对独立。卡间同步BS,就是每次批归一化时,卡间同步均值和方差,这样多卡训练也相当于和单卡一样的批归一化处理,可以认为是增加了BS的batch size。
6.2.2 YOLOv3-ResNet50vd-DCN改进backbone
ResNet50vd:优化ResNet下采样信息丢失问题
ResNet出来之后,又出现了BCD三种改进。下图中:
ResNet下采样不合理:比如ResNet50经过五次下采样得到最后的输出,每次下采样如下图所示。原来的ResNet下采样时,右边会进行一个stride=2,卷积核1×1的卷积。这样每次只会计算1个格子的数据,步长为2则每次移动两格,这样就丢失了3/4的信息,是不合理的。

ResNet50-D中,左侧下采样是在第二个卷积层实现的,此时卷积核大小为3×3;右侧下采样是通过一个步长为2的池化层实现的。这样两边在下采样时都不会丢失信息,更加合理。PaddleDetection 中只需要把variant改为d就行。(支持ABCD四种版本)
DCN :可变形卷积
普通卷积的卷积核大小都是固定的,一般都是方块,这对于目标检测一定合适吗 ?是否可以在学习卷积核参数的时候也调整卷积核大小,这就是可变形卷积解决的问题。
比如下图,卷积核不仅学习到羊的权重,也学习到羊的形状。下图红色框表示,在ResNet50vd的第五个阶段使用可变形卷积。

FPS大幅提升是因为backbone从darknet53换成了resnet50vd。加入DCN又小幅下降了一点FPS,但还是比原来高。
6.2.3 LB + EMA + DropBlock
- 使用更大的bacth size,提升模型训练的稳定性

- DropBlock:目标检测任务,比如学习下面这只狗,就是学习检测蓝色部分的连通率。点级别的零散丢弃没有块级别的drop更适合目标检测任务。因为如果丢弃一些点,等于狗丢失了一些部分,比较奇怪。如果是丢弃一个块,丢掉这只狗,模型就只是是否检测出来的问题, 模型学习效果更好。

- EMA:指数滑动平均,平滑训练中的梯度,让其抖动不会太大,不会突然跑偏。


6.2.4 IoU Loss&IoU Aware
目标检测中GTBox和预测框各种loss原理及对比,可参考《YOLOv1——YOLOX系列及FCOS目标检测算法详解》4.3章节CIoU Loss。
IoU Loss

IoU Aware:NMS中预测框按照score倒序排列,下图中IoU值较小的预测框分值更高,反而会在NMS中过滤掉IoU值更大的预测框,反而输出低精度的预测框,这是因为最终计算预测框score时没有考虑IoU值。
改进方式:实时计算IoU表征定位精度,乘到score里,让定位精度高的预测框排在前面,避免被精度低的预测框过滤。

p i p_i pi表示第i个类别的概率,相当于IoU乘在classification里面
6.2.4 grid sensitivity :消除grid网格敏感程度
可参考《YOLOv1——YOLOX系列及FCOS目标检测算法详解》5.3.1 Eliminate grid sensitivity :消除grid网格敏感程度。
简单说就是真实框中心点刚好在或很接近网格上时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。

6.2.5 Matrix NMS后处理
soft nms:直接抑制->惩罚系数:比如下面两匹马是同一个类别,但不是同一个目标。可是由于两匹马挨得很近,分数高的那匹马生成的预测框可能会在NMS中滤除另一匹马的预测框,由此引入 soft nms。从之前判断是重复的预测框直接删除(可认为score *0),改为其score乘以一个惩罚系数。这样其排序会往后,但不会完全没有。
soft nms缺点:之前重复框直接删掉,计算复杂度会一直降低,而soft nms保留重复框,计算量会大幅增加。

Matrix NMS:为了提高计算速度,做了如下改进:
- 将soft nms顺序计算过程改为矩阵式并行计算过程。如下图,在矩阵中填入任意两个预测框的IoU。(矩阵中各元素独立,所以可以用GPU并行计算)

- 最终计算取近似

6.2.6 Coord Conv
Coord Conv:卷积时加入x、y坐标信息(不做反向传播),定位其全局信息,特征提取效率更高。最终少数层加入Coord Conv,预测速度小幅下降。

6.2.7 SPP
可参考《YOLOv1——YOLOX系列及FCOS目标检测算法详解》4.2 SPP(Spatial Pyramid Pooling)结构
SPP结构,简单讲就是输入特征图经过四个分支之后进行拼接得到。这四个分支是:
- 输入直接接到输出的分支,size为[16,16,512]
- 三个不同池化大小的最大池化层分支。k5表示卷积核大小为5,s1表示步幅为1,p2表示padding=2。所以这三个池化层是输入特征图进行padding之后再最大池化,池化后特征图尺寸大小、通道数都不变,都为[16,16,512]
- 四个分支进行concatenate拼接,size为[16,16,2048]。拼接后实现不同尺度特征融合。这个简单的结构对最终结果提升很大。
- SPP结构能一定程度上解决多尺度检测问题

最终在PP-YOLO的backbone输出预测特征图部分加入SPP结构。
6.2.8 更好的预训练权重&双倍迭代次数
YOLO模型中,backbone部分的权重都是采用在ImageNet上分类任务中训练好的模型权重,在目标检测中默认冻结,backbone部分不参与训练。
PP-YOLO采用更优的backbone预训练权重,最终模型效果更好。

预训练权重带ssld字段就是用ssld方法训练的更优的预训练权重
PP-YOLO有两种训练方式,一种是加载backboned的预训练权重,一种是加载整个模型在coco数据集上训练的权重,后一种相当于迁移学习了。
2x scheduler
之前模型都是迭代25w个steps,2x scheduler就是迭代50w个steps,效果更好。一般来说2x和3x精度会有提高,再加到4x就会过拟合了。
6.2.9 总结
PP-YOLO优化:
- 骨干网络:ResNet50vd-DCN
- 训练策略: Larger Batch Size + EMA + DropBlock
- 损失函数:loU Loss + loU Aware
- 后处理: Grid Sensitive + Matrix NMS
- 特征提取: SPP + Coord Conv
- 其他: SSLD pretrain + 2x scheduler
6.3 PP-YOLO工业案例分享
6.3.1 项目背景:输电线路环境检测
无人巡检应用场景:

项目背景:
6.3.2 方案选择
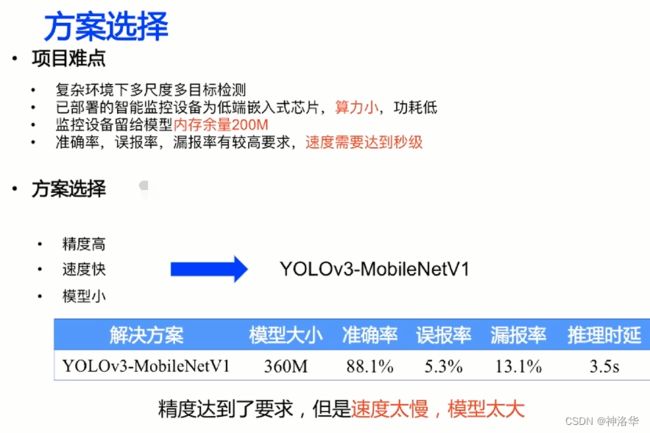
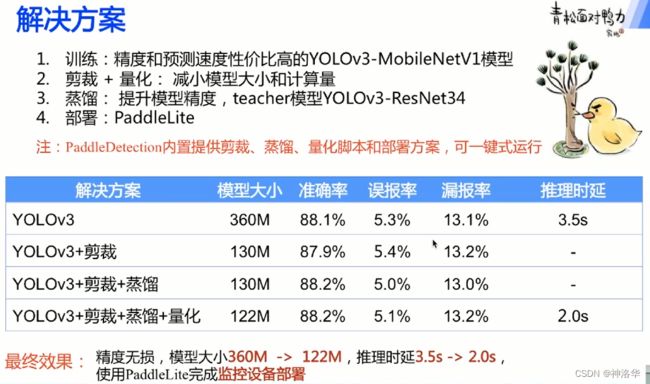
卷积通道剪裁:裁剪卷积中冗余的通道,减小模型大小和计算量。
量化:将float32的模型参数量化为int8的参数,减少计算量
最终效果:
6.4 答疑
- 为何使用PP-YOLO默认的bs会爆显存?
PP-YOLO是在32G的V100显卡上跑的,如果自己的显卡是16G,建议使用PP-YOLO master发布的12G显存的模型。(config/ppyolo-bs12) - PP-YOLO跑的时候CPU会占用很多吗?
是的,因为还用到了大量的图像增强,这些都是在CPU上做的。 - 用的的backbone预训练权重都在哪?
yaml配置文件的weight字段都有给出预训练权重地址,或者paddleclass里面找一找,都是采用ImageNet上训练的分类任务权重。 - 跑比赛时loss出现Nan,可以把lr调小一点(模型都是在8卡上跑的)
- PP-YOLO对输入图片尺寸有要求吗?
最好是在320到608 - 作业三印刷电路板(PCB)瑕疵检测,聚类anchor后精度更低了
理论上如果网络的Anchor大小适配当前数据集,可大幅提升mAP。如果实际反而降低了,可能是因为PCB数据集本身太小了,训练集只有593张图片吗,这样聚类出来的anchor可能不具有代表性。 - 训练时入网尺寸可以选800吗?
最好是选择320到608,如果改到800,可以在Reader.yaml部分修改resize尺寸(random shape定义的范围) - backbone上加入层,还能用原先的预训练权重吗?
如果加载网络后面可以,相当于前面层冻结使用训练好的权重就行,加载中间或者开头肯定不行,网络结构已经变了。 - 数据增强后效果反而不好
本身PCB数据集就很小,精度刷到acc 97%左右再往上提升意义不大了。 - 断点训练
指定-r 原先训练权重就行
七、 Anchor Free模型
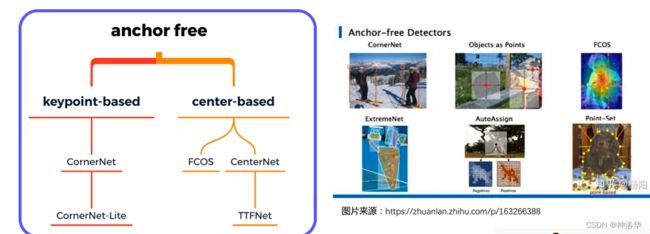
7.1 Anchor Free简介
-
基于Anchor的目标检测算法的弊端

anchor模板的尺寸、数量等等超参数很多,很难调。比如车牌检测中,anchor宽高比应该设计为5:1或7:1,人脸检测中,宽高比应该设计为1:1左右。 -
Anchor-Based方法中,通过Anchor模板和偏移量来表示检测框,那去掉anchor之后如何表示检测框呢?
主要有以下两种表示方法:

-
Anchor Free经典模型
7.2 CornerNet
参考《CornerNet论文阅读整理》
7.2.1 前言
CornerNet是发表在ECCV2018上的目标检测文章,借鉴了多人姿态估计思路。在人体姿态估计、图像分割中,底层逻辑都是给点打标签,通过点组合起来形成上层语义。受此启发,作者认为,目标检测中检测物体,就等于检测目标框的左上角和右下角两个点。两个点组合就是检测框,而且角点(corner)相对于中心点更容易训练。(角点只和两条边相关,而中心点和四条边相关)

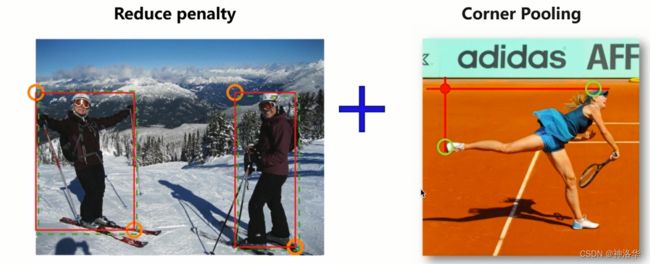
7.2.2 CornerNet核心思想:Reduce penalty和corner pooling

CornerNet通过backbone提取特征,然后分成两个检测器,分别检测目标的左上角点和右下角点。- 每个检测器又有Heatmaps和Emdeddings两个分支。
Heatmaps分支:负责找到角点的位置,并对角点进行分类。(这些角点会来自不同的检测物体)Emdeddings分支:将两个检测器中相同物体的点进行组合形成检测框。同时我们期望相同物体角点的embeddings相似,不同物体角点的embeddings距离较大,即Emdeddings分支负责找到匹配两个角点的方法。
- Heatmaps如何找到角点?Reduce penalty
- 扩大学习区域为角点半径=2内的区域,监督信息通过高斯分布产生 。
如果一张图片只有一个物体,正样本只会有两个点,即两个角点;其它点都是负样本,直接被舍弃的话,惩罚太大了,不利于训练,作者觉得需要把负样本的惩罚率设小一点。
所以对真实角点设置了一个半径=2的区域,区域内的点(不包括角点)虽然不是正样本,但也有学习价值,它们之间组成的检测框已经和真实框很接近了。这个区域的监督信息通过高斯分布产生,越接近圆心的部分,标签值越接近1。这样训练能帮我们更好的找到角点。 Corner Pooling:一种新型的池化层,可帮助卷积网络更好地定位边界框的corner
现实中,角点的位置很难直觉判断,比如下图找到莎拉波娃的左上角点,我们要不停判断其水平垂直线是否是其头和脚的边界。所以,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。
基于此,作者提出了Corner Pooling,它包含两个边界信息,角点水平边界信息(比如右下图左上角点对应的莎拉波娃的头),和垂直边界信息(莎拉波娃的脚)。Corner pooling的池化如果包含这两个信息,然后将两个池化结果相加,就容易预测出角点的信息了。
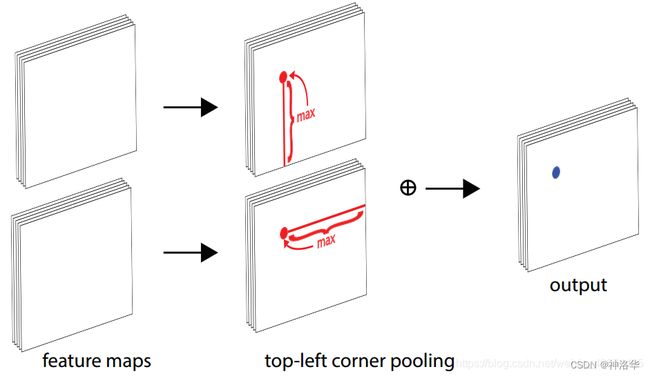
如下图所示,Corner pooling包含两个特征图; 对于每个channel,我们取两个方向(红线)的最大值(红点),然后把两个最大值相加(蓝点)。
- 扩大学习区域为角点半径=2内的区域,监督信息通过高斯分布产生 。
下面是针对左上角点做corner pooling的示意图,该图一共计算了4个点的corner pooling结果。左上角corner pooling层可以非常有效地实现。我们从右到左进行最大池化水平扫描(结果是一个递增序列),从下到上进行最大池化垂直扫描。然后把两个最大池化特征图相加

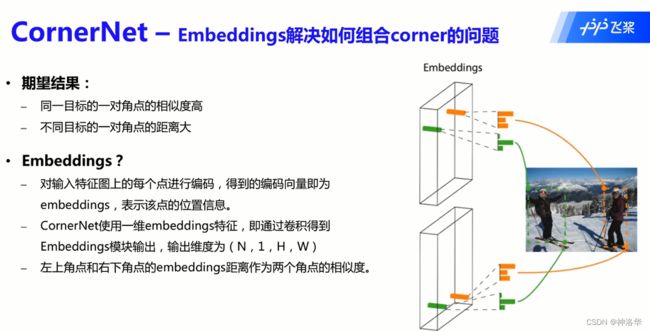
- 如何组合角点?
将特征图上每个点进行编码得到编码向量embeddings,其距离作为两个点的相似度
7.2.3 CornerNet 网络结构和损失函数
在CornerNet中,我们将目标检测转化为对边界框角点的检测。我们使用沙漏网络作为CornerNet的backbone网络。沙漏网络之后是两个预测模块。一个模块用于预测左上角,另一个模块用于预测右下角。
网络还预测每个检测到corner的嵌入向量,使得来自同一目标的两个corner的embedings之间的距离很小。
为了产生更紧密的边界框,网络还预测offsets以微调corers的位置。 利用预测模块,embeding和offset,我们用简单的后处理算法来获得最终的边界框。
与许多其他目标检测器不同,我们不使用来自不同尺度的特征来检测不同大小的目标(即没有采用FPN)。我们只将这两个模块应用于沙漏网络的输出。
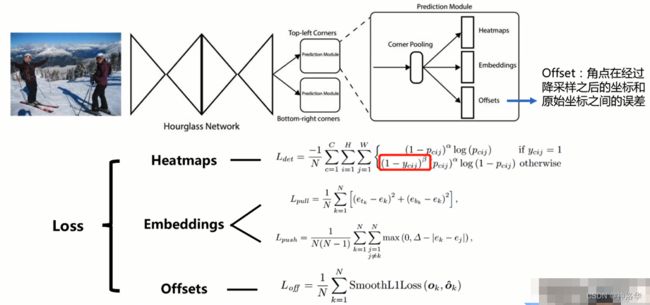
offset[N,2,H,W]是角点经过下采样后的坐标和原始坐标之间的x、y方向误差。卷积神经网络中,经常会使用下采样,这样就不可避免的会使一些点的坐标进行偏移。从原始图片到最终特征图上的输出,误差会累积起来,所以引入offdet来进行修正。
CornerNet损失函数如上图所示层,包括三个部分。
-
Heatmaps部分:
- 设 p c i j p_{cij} pcij为位置(i,j)处的预测模块中类别为c的得分, y c i j y_{cij} ycij为表示对应位置的ground truth。
- N是图像中目标的数量,α参数用来控制难易分类样本的损失权重,β参数控制 y c i j ! = 1 y_{cij}!=1 ycij!=1时,即点不是类别c的目标角点时的标签值。
这个标签值基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的 y c i j y_{cij} ycij值接近1,这部分通过β参数控制权重。在所有实验中我们将α设置为2,β设置为4。
- y c i j = 1 y_{cij}=1 ycij=1时,就是focal loss。
- CornerNet中将原始的focal loss的参数改为 ( 1 − y c i j ) β (1-y_{cij})^{\beta } (1−ycij)β。如果y比较小,loss就比较大,即如果这个点离真实角点很远的时候,其loss较大,就可以认为是一个困难样本,需要更多的训练。
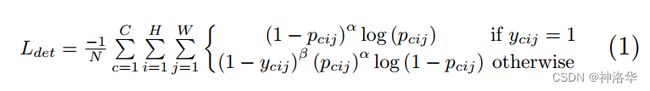
- embeddings
网络预测每个检测到的corner的嵌入向量(一维embeding),使得如果左上角和右下角属于同一个边界框,则它们的embedings之间的距离应该很小。 然后,我们可以根据左上角和右下角embedings之间的距离对corners进行分组。
embedings的实际值并不重要。 仅使用embedings之间的距离来对corners进行分组。具体的,我们使用“pull” loss来训练网络对各个corners的分组,使用“push” loss来分离各个corner:
( e t k e_{tk} etk和 e b k e_{bk} ebk分别表示左上角和右下角的embedding, e k e_{k} ek是这两个角点embedding的均值。我们在所有实验中将Δ设置为1。 与offset loss类似,我们仅在ground truth位置应用损失)

7.2.4 CornerNet 检测效果
下面是 CornerNet在coco数据集上的检测结果:

CornerNet容易把相同类别的不同物体的角点组合起来形成检测框,如上图右侧所示。模型将左上和右下两个人的两个角点(图中橘色点)组合起来形成了一个很大的检测框。
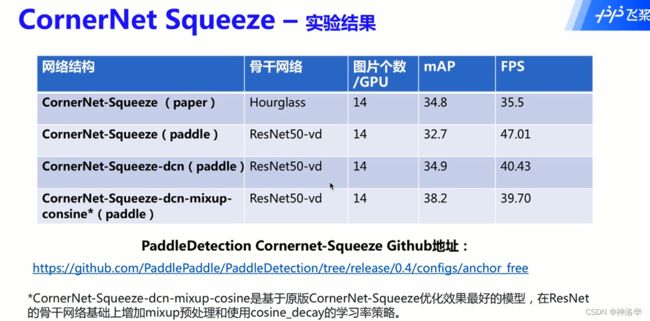
7.2.5 CornerNet-Lite
CornerNet-Lite发表在CVPR2019上,在速度(CornerNet-Squeeze)和精度((CornerNet-Saccade))两个方面都进行了改进。


- 将CornerNet的残差模块替换为CornerNet-Squeeze的Fire Module。
- 受MobileNet影响,将第二层的3×3普通卷积替换为3×3的深度可分卷积。(深度可分卷积可以参考我的帖子《图片分类网络ViT、MobileViT、Swin-Transformer、MobileNetV3、ConvNeXt、EfficientNetV2》中的4.2.1章节)
- 右图代码可见,Fire Module就是先经过
Conv 1×1,再分别经过Conv 1×1和Conv 3×3 Dwise,然后将二者结果拼接,得到最终输出结果。
7.3 FCOS
请参考我另一篇博客《YOLOv1——YOLOX系列及FCOS目标检测算法详解》
7.4 CenterNet(待补充)
参考《CenterNet算法详解》