MySQL(三):表的增删改查(进阶)
目录
- 一、数据库约束
-
- 1.1 约束类型
- 1.2 NULL约束
- 1.3 UNIQUE约束
- 1.4 DEFAULT 约束
- 1.5 PRIMARY KEY 主键约束
- 1.6 FOREIGN KEY 外键约束
- 1.7 CHECK 约束
- 二、表的设计
-
- 2.1 一对一
- 2.2 一对多
- 2.3 多对多
- 三、新增数据
- 四、查询
-
- 4.1 聚合查询
-
- 4.1.1 聚合函数
- 4.1.2 分组查询group by
- 4.1.4 where和having
- 4.2 联合查询
-
- 4.2.1 内连接
- 4.2.2 外连接
- 4.2.3 自连接
- 4.2.4 子查询
- 4.2.5 合并查询
一、数据库约束
数据库的约束就是,数据库可以让程序员定义一些对数据的限制规则,数据库会在插入/修改数据的时候按照这些规则对数据进行校验,如果校验不通过,就直接报错。
约束的本质是让我们即使发现数据中的错误,更好的保证数据的正确性
1.1 约束类型
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- DEFAULT - 规定没有给列赋值时的默认值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标 识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句
1.2 NULL约束
创建表时,可以指定某列不为空
【使用示例】:

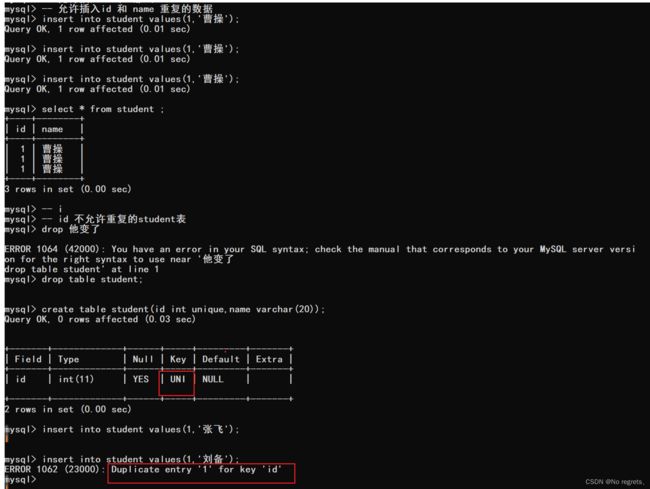
1.3 UNIQUE约束
指定id列是唯一的,不能重复
【使用示例】:
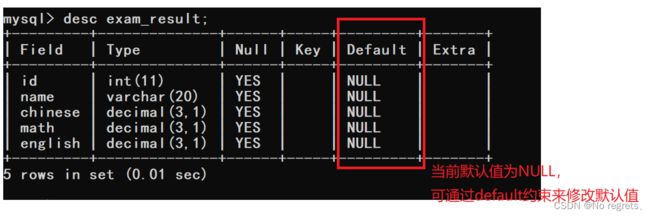
1.4 DEFAULT 约束
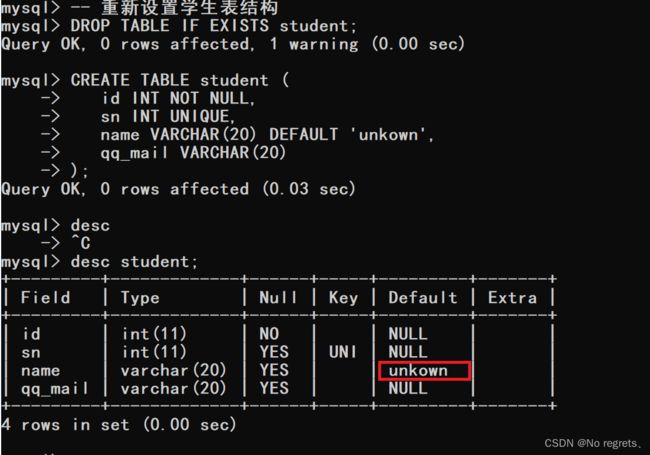
【使用示例】:指定插入数据时,name列为空,默认值unkown:
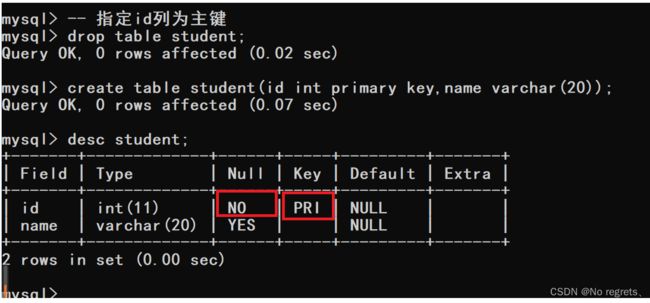
1.5 PRIMARY KEY 主键约束
主键表示一条记录的身份标识,用来区分这条记录和其他记录
主键约束:
- 不能为NULL,相当于NOT NULL
- 不能重复,相当于UNIQUE
- 一个表里只能有一个主键
【使用示例】
当我们在插入数据的时候,由于主键不能为NULL且不能重复,MySQL为了方便填写主键,内置了一个功能"自增主键",对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
【自增主键】
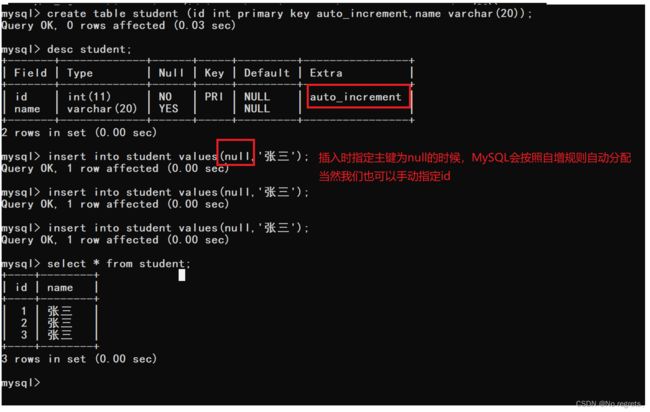
【面试问题】:自增主键,主要是用来生成一个唯一的id,来保证不重复,如果数据库是分布式部署该如何设计自增主键呢?
如果只有一个数据库服务器的话,服务器自己知道当前id 的最大值,也就容易生成下一个唯一的id,但当数据库分布式部署后,每个数据库只知道自己数据库中的id最大值,但并不知道其他数据库上的id最大值,这就无法保证所有数据库上的主键都是唯一的。对于分布式部署的主机自增主键的典型方法就是,唯一id=时间戳(ms)+机房编号/主机编号+随机因子
同一时间戳之内,进入数据库的数据是有限的,使用时间戳,就能区分出大部分的数据了,同一时间戳内进入数据库的数据,又会分摊到不同的主机上,如果同一时间戳进入又分摊到同一主机,可以通过随机因子再次进行区分
1.6 FOREIGN KEY 外键约束
foreign key描述了两张表之间的关联关系
【举例理解外键约束的作用】
现在有学生表和班级表,班级表中用来存储学生的信息,其中一列是班级编号,班级表中存储的是班级的具体信息,学生表中的每个同学的班级编号得在班级表中存在,如果不存在就属于是非法数据
此时,班级表是负责约束的一方,称为父表 学生表是被约束的一方,称为子表
【使用示例1】
- 创建班级表class,classId为主键

- 创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键,classesId为外键,关联班级表classId
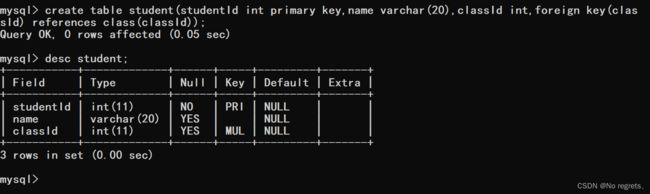
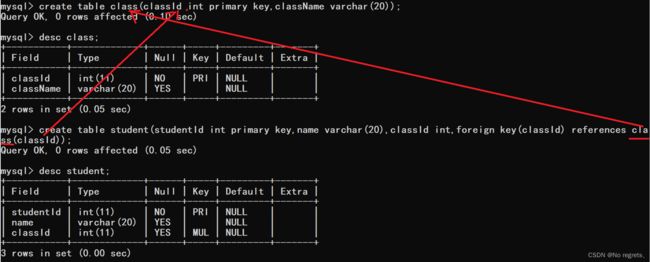
【使用示例2】

当父表为空时,直接尝试往子表插入,就会报错
【使用示例3】
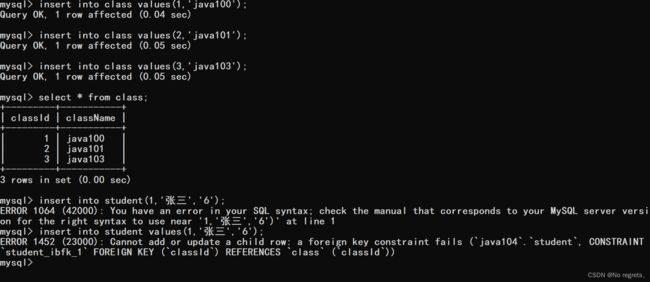
当插入子表的数据没在父表的classId中,同样也会报错
【使用示例4】
父表虽然对子表产生了限制,但是反过来子表也会对父表有限制,父表对子表的限制是不能随意的插入/修改,子表对于父表的限制就是不能随意修改/删除
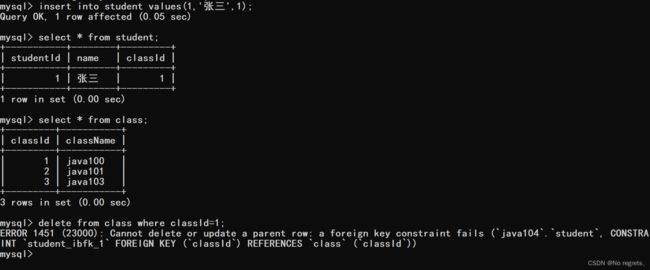
【注意】:
- 建立外键约束的时候,MySQL要求,引用的父表的列,必须是主键或者时UNIQUE
【延伸问题】:

1.7 CHECK 约束
可以直接对表中的值做出限制
【SQL语句】
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);
二、表的设计
三大范式:
2.1 一对一
学生和账户之间就是一对一的关系

- 对于学生和账户来说, 可以将学生和账户放到一张表里
student(id,name,account,password...)
- 把学生和账户各自放到一个表里,使用一个额外的id来关联
student(studentId,name,accountId)
account(accountId,password)
通过账户id和密码登陆成功之后,在通过accountId在学生表中查找对应的学生信息。
2.2 一对多
学生和班级之间是一对多的关系,一个同学只能属于一个班级,一个班级可以包含多个同学

class(classId,className)
student(student_id,name,classId)
2.3 多对多
学生和课程之间是多对多的关系,一个同学可以选择多门课程,一个课程可以被多个同学来选择
可以采用一个中间表,来表示多对多的关系
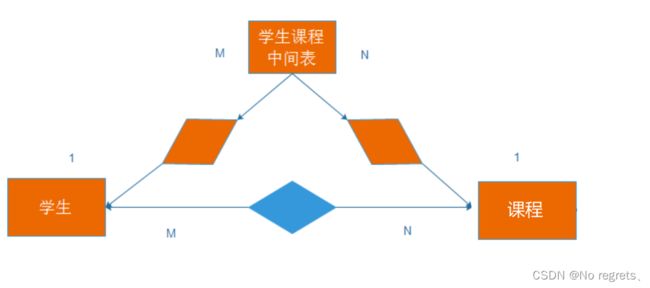
student(studentId,name)
course(courseId,courseName)
student_course(studentId,courseId)
【补充】:
- 当需求场景比较简单的时候,很容易就能梳理清其中的实体和关系
- 当需求场景比较复杂的时候,可能涉及很多的实体,很多组的关系,此时我们可以借助一个工具ER图(实体-关系图)
三、新增数据
将查询结果作为新增的数据
insert into 表名 select 列名 from 表名;
【使用示例】:创建一张用户表,设计有name姓名、email邮箱、sex性别、mobile手机号字段。需要把已有的学生数据复制进来,可以复制的字段为name、qq_mail
-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (
id INT primary key auto_increment,
name VARCHAR(20) comment '姓名',
age INT comment '年龄',
email VARCHAR(20) comment '邮箱',
sex varchar(1) comment '性别',
mobile varchar(20) comment '手机号'
);
-- 将学生表中的所有数据复制到用户表
insert into test_user(name, email) select name, qq_mail from student;
【注意】:
查询结果的临时表的列要和要插入表的列完全匹配
四、查询
4.1 聚合查询
通过聚合查询,进行行和行之间的运算
4.1.1 聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有
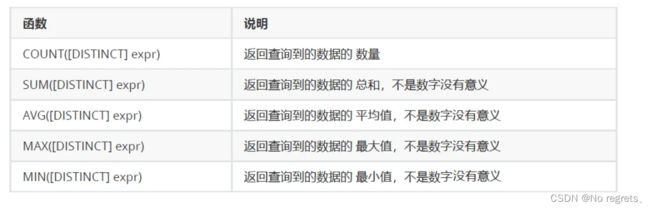
这些函数都是SQL内置的一些函数,SQL作为一个编程语言,也是内置了一些库函数供我们使用的
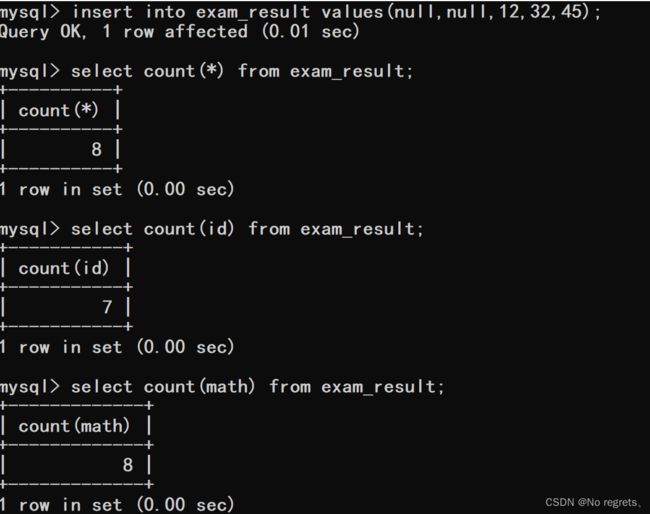
【使用示例1】:count
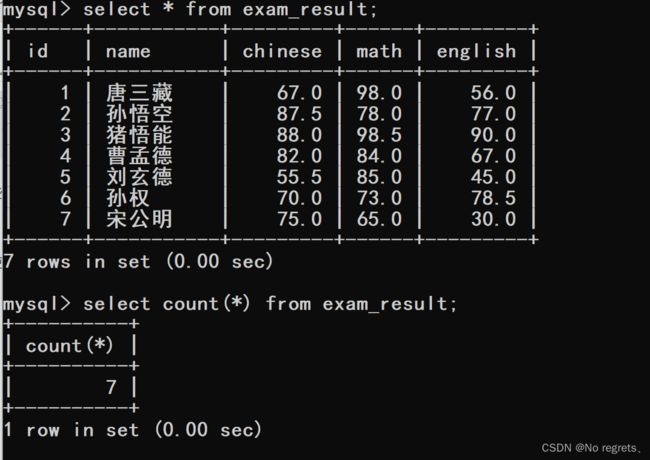
也可以写成selecr count(列名) from exam_result;但两种写法有一定的区别,count(*)会把空的记录算做结果的,而count(列名)不会将空的记录算做有效结果的
【使用示例2】:sum
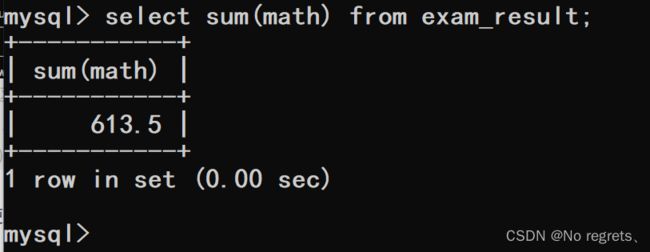
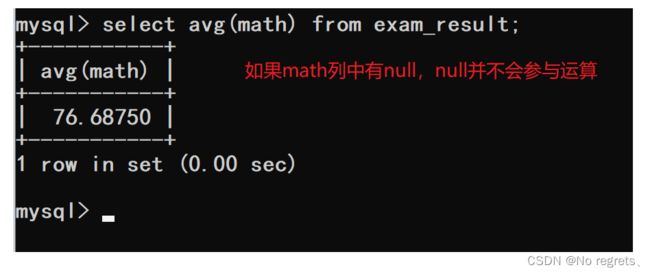
当记录中有NULL时,NULL并不会参与运算
【指定筛选条件】
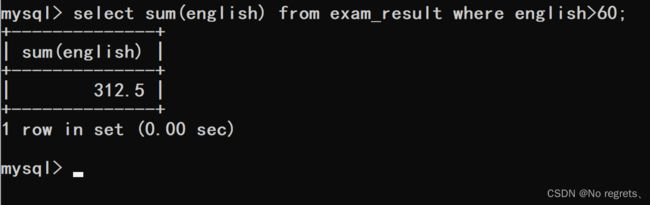
对于带有条件的聚合查询,会先按照条件进行筛选,将筛选后的结果在进行聚合
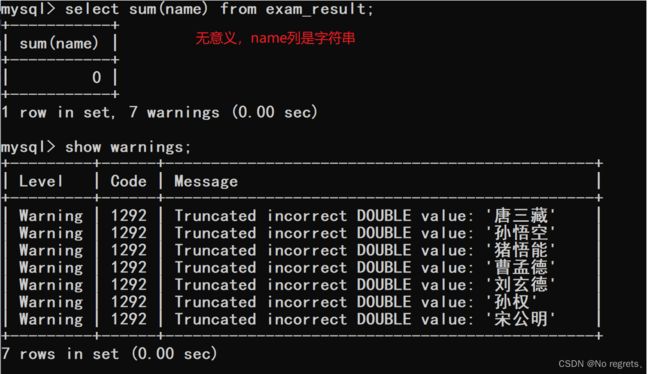
【使用示例3】:avg
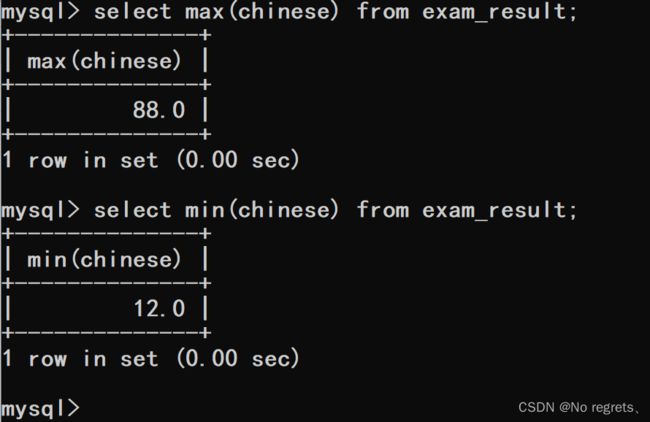
【使用示例4】:max和min
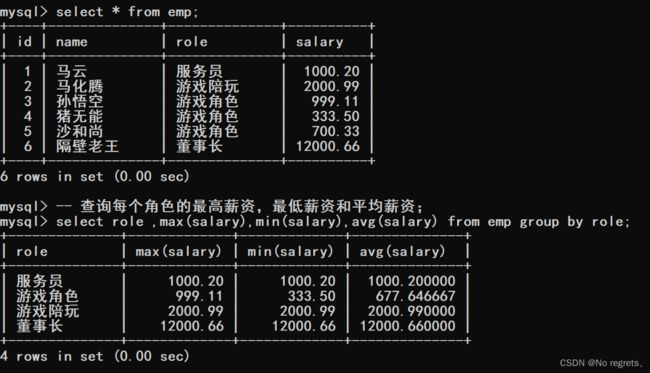
4.1.2 分组查询group by
把表中的若干行,分成几个组,指定某一列作为分组的依据,分组依据的列值相同,则被归为一组,分成多个组之后,还可以针对每个组,分别使用聚合函数
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
【使用示例】:
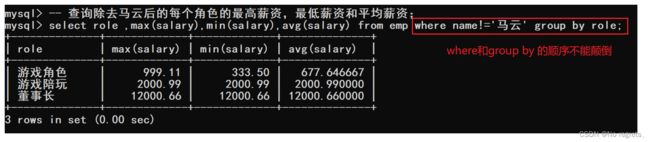
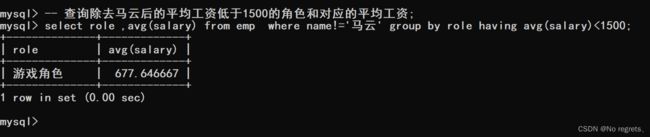
4.1.4 where和having
where和having都是在进行聚合查询时指定筛选条件的:
- 在聚合之前,进行筛选,针对筛选后的结果,在聚合,使用where子句
- GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
【使用示例】:where子句
【使用示例】:having子句

【使用示例】:同时使用where和having子句,也就是在聚合前后都进行筛选
4.2 联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:
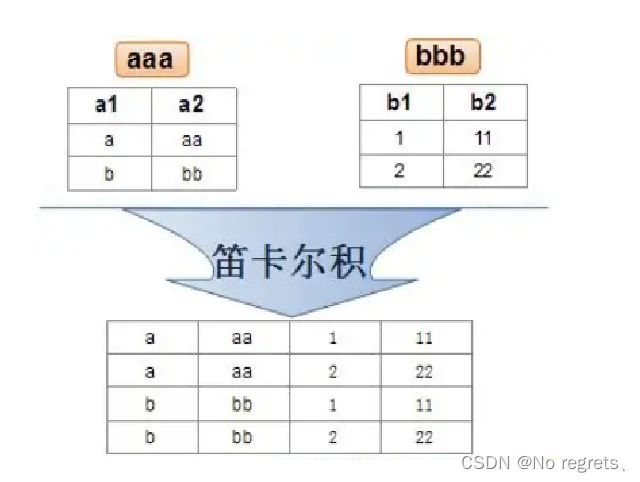
单纯的笛卡尔积,里面包含了大量的无效数据,指定了合理的过滤条件,把有效的数据筛选出来,就得到了一张有用的表,这个过程就是"联合查询"的过程。
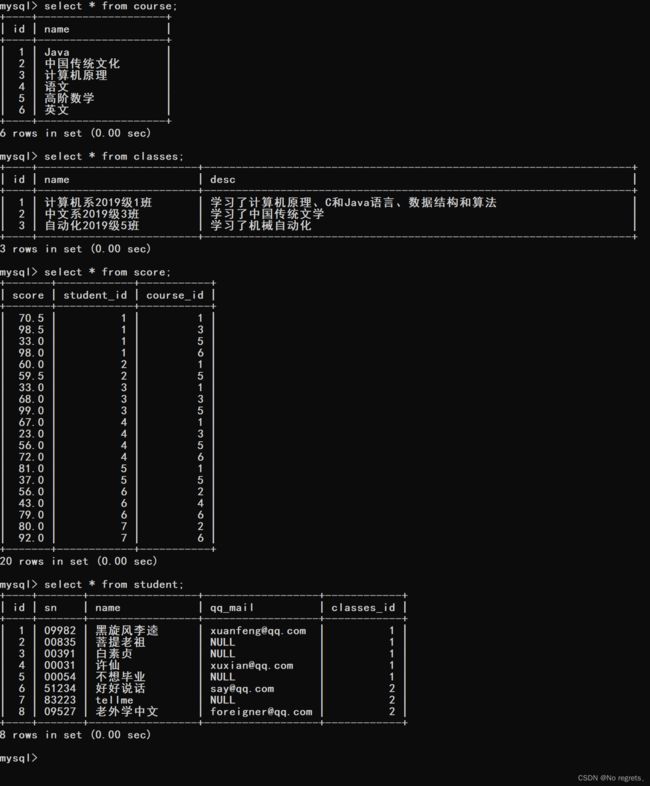
【构造数据】:有course,classes,student,score这四张表
4.2.1 内连接
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
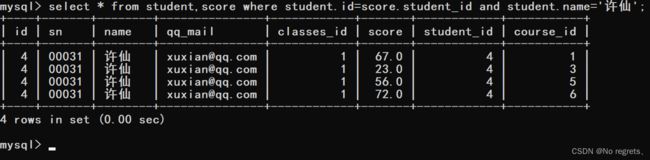
【使用示例1】:查询"许仙"同学的成绩
首先"许仙"是名字,在student表中,成绩在score表中,因此我们需要先将student表和score表进行笛卡尔积,在该表中符合条件student.id=score.id的数据是有意义的数据,因此student.id=score.id就是连接条件
(1)
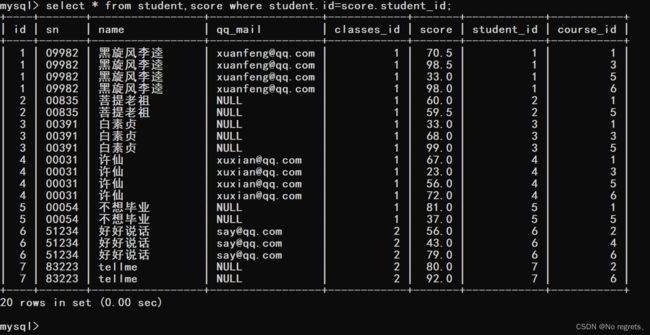
(2)
由于我们要查询的是许仙同学的成绩,因此使用name=‘许仙’,作为其他条件继续进行筛选
(3)
最后去掉一些不必要的列
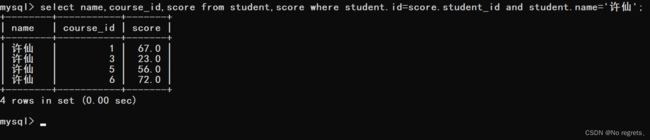
【等价写法】:

当使用join进行笛卡尔积时,后面使用的是on而不是where
【小结】:多表查询的一般步骤
- 先根据需求理清楚想要的数据在哪些表中
- 针对多个表进行笛卡尔积
- 根据连接条件,筛选出合法数据,过滤非法数据
- 进一步增加条件,根据需求做更精细的筛选
- 去掉不必要的列
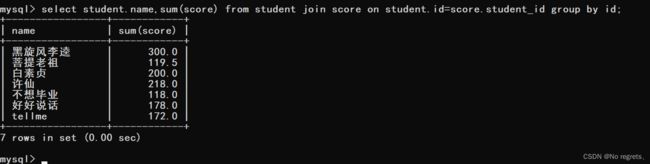
【使用示例2】:查询每个同学的总成绩
(1)先查询出每个同学的每门科目的成绩

(2)由于每个同学的各门科目的成绩处在不同的行中,因此想要查询总成绩需要进行聚合查询,使用id作为分组条件
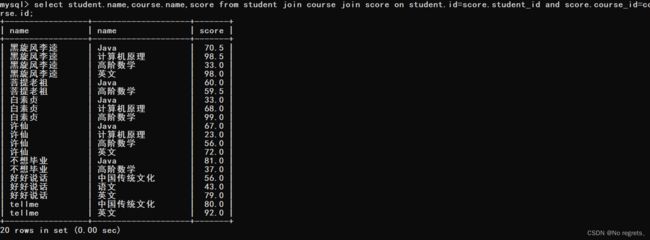
【使用示例3】:查询出每个同学的姓名,课程名和成绩
该需求中涉及到三张表,分别是student,course和score
通过score作为中间表,连接student和course
4.2.2 外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
【使用示例1】:左外连接,选取左侧的表作为驱动表
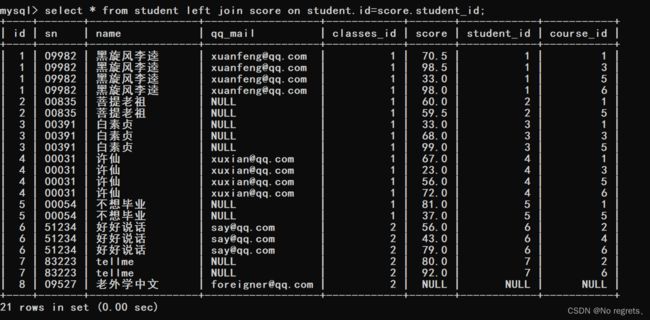
我们发现“老外学中文”同学 没有考试成绩,也显示出来了,这就是外连接的特点
【使用示例2】:右外连接,选取右侧的表作为驱动表
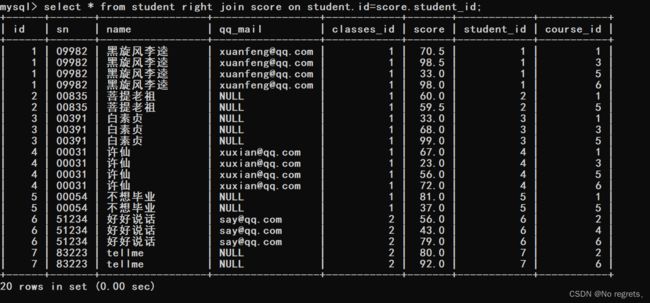
【小结】:内连接与外连接的区别
- 对于内连接的两个表,若驱动表中的记录在被驱动表中找不到匹配的记录,则该记录不会加入到最后的结果集
- 对于外连接的两个表,即使驱动表中的记录在被驱动表中没有匹配的记录,也仍然需要加入到结果集
4.2.3 自连接
自连接是指在同一张表连接自身进行查询。
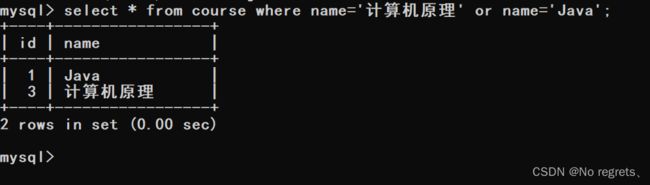
【使用示例】:显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
(1)首先在course表中找出"计算机原理"和"Java"所对应的id
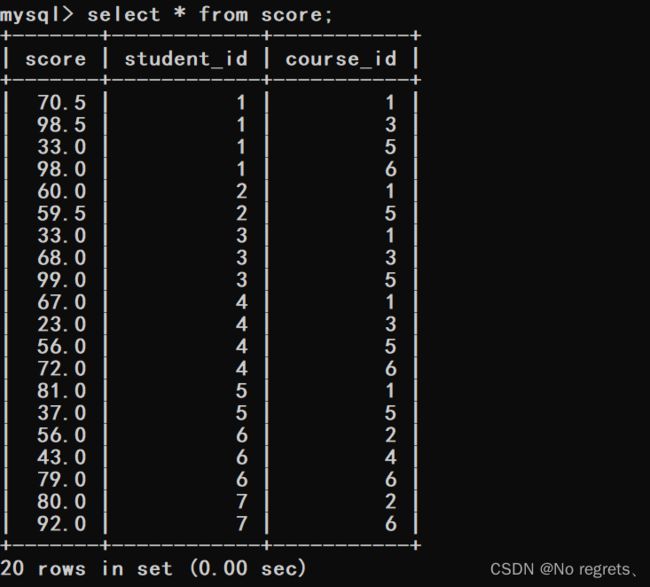
(2)查询score表我们发现,成绩之间都是以行的形式进行罗列的,然而在SQL中无法比较进行行与行之间的比较,因此我们需要通过自连接将行与行之间的比较转换成了列与列之间的比较
(3)自连接

(4)继续添加条件

4.2.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
- 单行子查询:返回一行记录的子查询
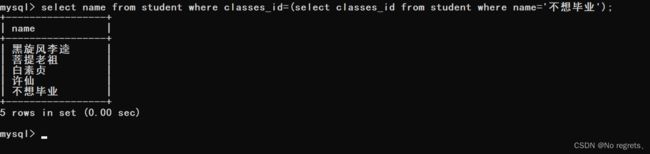
【使用示例】:查询与“不想毕业” 同学的同班同学
(1)先根据名字找到对应的班级id
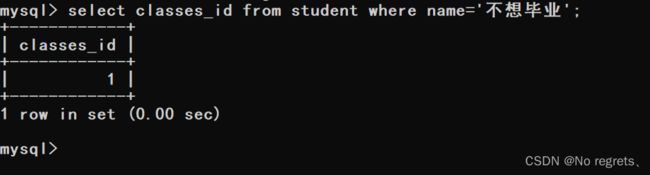
(2)根据"不想毕业"的班级id筛选出它的同班同学
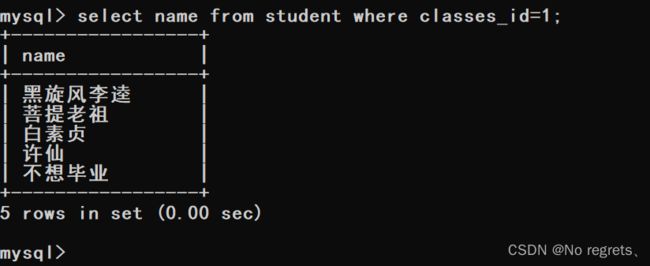
(3)将上述的(1)与(2)合并后就变成了一个子查询
- 多行子查询:返回多行记录的子查询
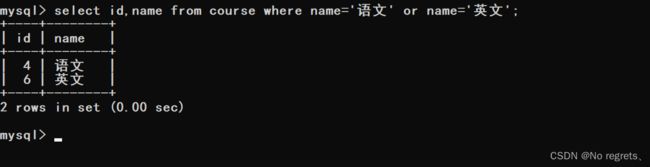
【使用示例】:查询“语文”或“英文”课程的成绩信息
(1)先根据课程名,找到对应课程的id
(2)根据课程id在分数表中查询对应的成绩信息

4.2.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
- union :该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
【使用示例】:查询id小于3,或者名字为“英文”的课程
此处使用or和union 都可以做到
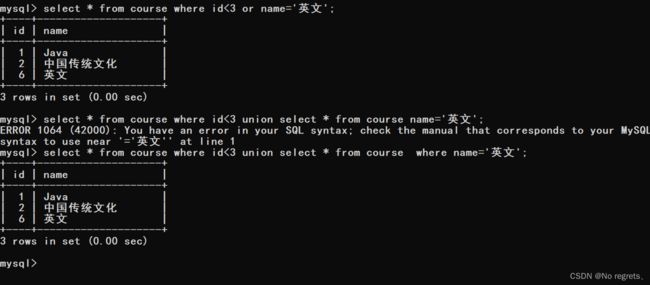
- union all:该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行
【使用示例】:查询id小于3,或者名字为“Java”的课程
