DTMF双音频信令检测,基于Goertzel(戈泽尔算法),FPGA实现
目录
1.引言
2.细节介绍
3.DTMF双音频信号的产生
4.DTMF双音频信号的检测
4.1(Goertzel)戈泽尔算法的使用
4.2戈泽尔算法的详细计算过程
4.3计算的优化
4.3.1时间复杂度方面
4.3.2空间复杂度方面
4.4算法的具体实现
4.4.1从串行思维入手
4.4.2如何减少资源的使用
4.5仿真
5.源码分享
6.后续展望
1.引言
双音频信令国际上采用697HZ,770HZ,852HZ,941HZ,1209HZ,1336HZ,1477HZ,1633HZ共8个频率,仔细观察不难发现,这8个频率中,有4个低于1000HZ的频率有4个高于1000HZ的频率,我们称低于1000HZ的4个频率为低频群,高于1000HZ的4个频率为高频群。
4个低频群和4个高频群交叉摆放,他们将会有16个交叉点,这16个交叉点也正是16个按键,每个按键对应一个信令。如下图所示:
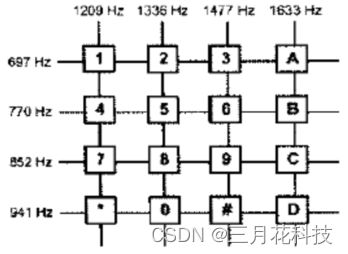
这个图很清晰得表现出了按键和音频频率的关系。虽然这个图长得非常像矩阵键盘,但是不要打同时按下两个按键的想法,毕竟双音频一次最多两个频率,按下两个按键至少有三个频率了,这样做是不讲武德的(手动狗头)。
2.细节介绍
第1章简要介绍了什么是DTMF,DTMF是用来做什么的。接下来详细介绍DTMF的具体的详细的规程。
DTMF信号的采样率为8KHZ。DTMF每秒可以发送10个信令,即每个信令的传输时间是100ms,数字音连续时间为45ms~55ms,其余时间均为静音。
3.DTMF双音频信号的产生
DTMF双音频信号虽然有4个低频,4个高频,但是在实际使用中同一时刻仅有2个频率,于是实际上仅需要两个DDS分别产生此时需要的一个高频和一个低频,然后叠加即可。
不过此处要注意一点,DDS产生的波形实质是以不同的速率来刷正弦表,起输出数据的更新频率是不同的,当然这个频率也显然和8KHZ 的采样时钟频率是不同的,所以使用两个DDS产生对应频率的波形后,一定要使用异步采样的方式,即使用8KHZ的时钟进行采样并相加。
DDS的实现本文不做介绍,DDS的代码资料如下(资源免费,如果需要收费请在评论区通知我):
DDS基于Verilog语言实现-嵌入式文档类资源-CSDN下载
4.DTMF双音频信号的检测
DTMF双音频信号是一高一低两种频率的正弦波叠加,那么最简单的思路当然是FFT变换,然后看不同频率的幅值进而判断传了什么信令按了什么键。
使用FFT的思路本是没有错的,但是略有杀鸡焉用宰牛刀。DTMF的检测中无需得知相位信息也无需计算所有的频点。因为DTMF的频率是已知的,直接针对已知的8种频率的频点进行计算即可。这就是戈泽尔算法(Goertzel)
4.1(Goertzel)戈泽尔算法的使用
首先,从感性角度和使用角度来看看戈泽尔算法。戈泽尔算法是仅对已知的个别频点进行幅值的计算。其“频点”的概念实质上和傅里叶变换中的频点意义是相同的,频率识别的分辨率及对应关系也是相同的。例如以1KHZ采样频率,采集持续1S的时间,即采集到1K个点,此时的频率分辨率为1HZ,此时若想要查看50HZ的幅值,只需要查看第51个频点的幅值即可(第1个频点是直流分量)。
综上内容稍加思索便可得知一个关键问题:采样点数和频点的确定。
既然我们已知4个低频和4个高频的频率,那么就确定采样点数,得到频率分辨率,并进而确定频点吧。
采样点越多,频率分辨率越高,但是也意味着更大量的计算和更高的延迟(采集数据的时间变长)因此,戈泽尔算法中常用的采样点数为205,其4个低频和4个高频对应的频点如下图所示。
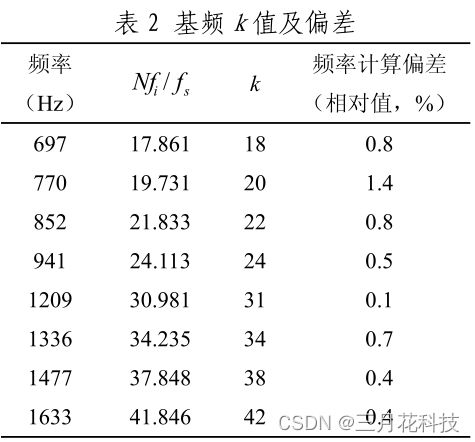
“频点”是整数,所以在取频点时会有一些误差,上图中频点是k,而误差正是最后一列所示。
4.2戈泽尔算法的详细计算过程
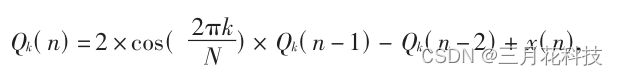
这是计算的第一步,式中N是采样点数即205,k是频点,x(n)是n时刻接收到的信号的量化值。
从式子中可以发现,此时计算的是Q在n时刻的值,但是需要用到Q在n-1时刻的值和n-2时刻的值,由此可见此算法是不停迭代计算的。
至此,眼尖的小伙伴一定发现了两个问题:1. n取值到多少时结束;2. 初始状态下即n=0时,Qk(n-1)和Qk(n-2)咋办。
![]()
这两个问题接着用第二个公式解答。第二个公式中,首先阐明了n=0时刻Qk(n-1)即Qk(-1)和Qk(n-2)即Qk(-2)的取值,两者初始值均为0。然后解释了n的取值范围 即0到N(采样点,205)。
顺延着计算,当得到Qk(N)的值后,就可以计算幅值了。幅值的计算公式如下:
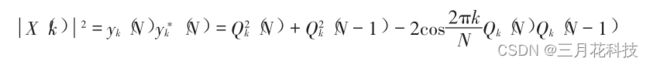
即Qk(N)的平方 + Qk(N-1)的平方 - 2cos(2*Π*频点/采样点数)*Qk(N)*Qk(N-1)
4.3计算的优化
4.3.1时间复杂度方面
仔细观察计算过程不难发现,2cos(2*Π*频点/采样点数)在每次的计算中都会用到,由于频点和采样点数固定了,所以此值是固定的,在实际的计算中,可以提前计算出来,并以常数的姿态参与计算。
4.3.2空间复杂度方面
其次,Q这个序列在结果的求解中实际只使用了Qk(N),Qk(N-1),Qk(N-2)三个值,所以大可不必在计算时使用与采样点数等长的序列。仅需要长度为3的序列即可。
在实际计算中,得到Qk(n)后,增加一步序列位置交换即可。
具体如下:
在此步骤的计算中,下一步的计算即n+1时刻的计算,将要使用Qk(n)和Qk(n-1)计算得到Qk(n+1)。而Qk(n-2)已经用不到了。所以增加一步,Qk(n-2) = Qk(n-1),Qk(n-1) = Qk(n),Qk(n)的内存空间即可留出Qk(n+1)。
4.4算法的具体实现
4.4.1从串行思维入手
前节提到的公式所示的计算过程均为从上到下依次计算的思路,进行实现。其思路类似于C语言,但是细节上与C语言是不同的。首先比较一下这两种思路,首先看看C语言实现戈泽尔算法并在单片机上运行的代码:
for(i=0;i<8;i++)
{
b[i][0]=0;
b[i][1]=0;
for(j=1;j<=205;j++)
{
b[i][2]=w[i]*b[i][1]-b[i][0]+dtmf[start+j-1];
b[i][0]=b[i][1];
b[i][1]=b[i][2];
}
result[i]=b[i][1]*b[i][1]+b[i][0]*b[i][0]-w[i]*b[i][1]*b[i][0]; //信号幅值的平方
}两层循环,其中内层循环计算的正式如下公式所示内容:
外层公式计算最终结果,如公式:
可见,从理解上而言,C语言实现与论文中所描述的公式计算流程一模一样,非常易懂。但是,使用这种实现方式有个前提,即计算使用的数据在计算开始时就已经全部采集完毕,例如此例子中205点数据全部采集完毕后才可以开始计算,这将耗费大量的存储空间,FPGA中如果使用寄存器存放所有等采样点将是不现实的做法。
FPGA中需要每采样一个点,就开始做对应的计算,按照这个要求,我们修改一下上面的C语言代码:
for(i=1; i<8; i++)
{
b[i][0] = 0;
b[i][1] = 0;
}
for(j=1; j<=205; j++)
{
for(i=0;i<8;i++)
{
b[i][2]=w[i]*b[i][1]-b[i][0]+dtmf[start+j-1];
b[i][0]=b[i][1];
b[i][1]=b[i][2];
}
}
result[i]=b[i][1]*b[i][1]+b[i][0]*b[i][0]-w[i]*b[i][1]*b[i][0]; //信号幅值的平方修改的精髓就在于,将两个for循环的位置互换,将205点的循环放在外面,这样就可以每来一个采样点单独对此采样点做计算工作了。
将此部分用Verilog语言重新编写后,核心代码为:
//放大7位
parameter coeff1 = 218;
parameter coeff2 = 209;
parameter coeff3 = 200;
parameter coeff4 = 190;
parameter coeff5 = 149;
parameter coeff6 = 129;
parameter coeff7 = 108;
parameter coeff8 = 72;
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
status <= 0;
end
else begin
case(status)
0: begin
status <= status + 1;
for(i=0; i<8; i=i+1) begin
b[i][0] <= 0;
b[i][1] <= 0;
b[i][2] <= 0;
end
result_697 <= result[0];
result_770 <= result[1];
result_852 <= result[2];
result_941 <= result[3];
result_1209 <= result[4];
result_1336 <= result[5];
result_1477 <= result[6];
result_1633 <= result[7];
// data_in <= $signed({{14{sample_data[11]}}, sample_data[10:0], 6'h00});
data_in <= $signed({{24{sample_data[11]}}, sample_data[10:4]});
end
206: begin
status <= 0;
result_697 <= (b[0][1]*b[0][1]+b[0][0]*b[0][0] - ((coeff1*b[0][0]*b[0][1])>>>7));//实际发现第三项还需要乘2,与除128对冲后,除64
result_770 <= (b[1][1]*b[1][1]+b[1][0]*b[1][0] - ((coeff2*b[1][0]*b[1][1])>>>7));
result_852 <= (b[2][1]*b[2][1]+b[2][0]*b[2][0] - ((coeff3*b[2][0]*b[2][1])>>>7));
result_941 <= (b[3][1]*b[3][1]+b[3][0]*b[3][0] - ((coeff4*b[3][0]*b[3][1])>>>7));
result_1209 <= (b[4][1]*b[4][1]+b[4][0]*b[4][0] - ((coeff5*b[4][0]*b[4][1])>>>7));
result_1336 <= (b[5][1]*b[5][1]+b[5][0]*b[5][0] - ((coeff6*b[5][0]*b[5][1])>>>7));
result_1477 <= (b[6][1]*b[6][1]+b[6][0]*b[6][0] - ((coeff7*b[6][0]*b[6][1])>>>7));
result_1633 <= (b[7][1]*b[7][1]+b[7][0]*b[7][0] - ((coeff8*b[7][0]*b[7][1])>>>7));
end
default: begin
status <= status + 1;
grz_calculate(data_in);
// data_in <= $signed({{14{sample_data[11]}}, sample_data[10:0], 6'h00});
data_in <= $signed({{24{sample_data[11]}}, sample_data[10:4]});
end
endcase
end
end
task grz_calculate(input integer grz_data_in);
b[0][2]=((coeff1*b[0][1])>>>7) - b[0][0] + grz_data_in;
b[0][0] = b[0][1];
b[0][1] = b[0][2];
b[1][2]=((coeff2*b[1][1])>>>7) - b[1][0] + grz_data_in;
b[1][0] = b[1][1];
b[1][1] = b[1][2];
b[2][2]=((coeff3*b[2][1])>>>7) - b[2][0] + grz_data_in;
b[2][0] = b[2][1];
b[2][1] = b[2][2];
b[3][2]=((coeff4*b[3][1])>>>7) - b[3][0] + grz_data_in;
b[3][0] = b[3][1];
b[3][1] = b[3][2];
b[4][2]=((coeff5*b[4][1])>>>7) - b[4][0] + grz_data_in;
b[4][0] = b[4][1];
b[4][1] = b[4][2];
b[5][2]=((coeff6*b[5][1])>>>7) - b[5][0] + grz_data_in;
b[5][0] = b[5][1];
b[5][1] = b[5][2];
b[6][2]=((coeff7*b[6][1])>>>7) - b[6][0] + grz_data_in;
b[6][0] = b[6][1];
b[6][1] = b[6][2];
b[7][2]=((coeff8*b[7][1])>>>7) - b[7][0] + grz_data_in;
b[7][0] = b[7][1];
b[7][1] = b[7][2];
endtask
其中,always正是前文所述的C语言代码中的两个for循环和结果计算。首先,第0个状态,对应C语言代码的对b数组清零的for循环;其次,第1个到第205个状态,对应C语言的循环205次的for循环,最后第206个状态对应C语言的求解result的代码。
这种实现方式仿真后可以得到正确答案,且可以综合,但是由于其中用到了太多的并行乘法运算,手头现有的FPGA没有足够的资源,其次,DTMF原本也不是什么要求很高的功能,使用太多的资源在实际项目中也是不切合实际的。
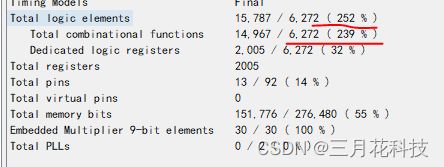
这是在EP4CE6E22C8N上综合的结果,需要这样两片半FPGA才能装下这个戈泽尔算法。然而此时的戈泽尔算法还没有加入2次谐波部分的计算,和多通道配合计算,因此,这种实现方式虽然很好理解,但是不切合实际。
4.4.2如何减少资源的使用
从上述代码中不难发现,每个乘法都是和固定数据绑定的,即无法复用乘法器,导致占用资源过多。因此,减少资源使用等方法很简单,即将需要做乘法的地方通过三个寄存器统一访问乘法器这样在综合时,就不会出现综合出来很多乘法器的情况了。其次,将算式拆分,没次只计算整个算式的一部分,多次计算最终得到结果。
例如计算:result[i]=b[i][1]*b[i][1]+b[i][0]*b[i][0]-w[i]*b[i][1]*b[i][0];
可以分为3步:
第一步:计算b[i][1]*b[i][1]和b[i][0]*b[i][0],共使用2个乘法器
第二步:计算第一步得到两个乘积的和,并计算w[i]*b[i][1]*b[i][0],共使用2个乘法器,复用第一步是使用的两个乘法器
第三步:将第二步求得的和与第二步求得的乘积相减,得到最终答案。
实际上,由于寄存器送数据会延迟一个时钟,此思路在FPGA上具体实现时需要4个时钟,代码如下:
1: begin res_mul_dataa <= b[0][0]; res_mul_datab <= b[0][0]; res_mul_datac <= b[0][1]; res_mul_datad <= b[0][1]; result_counter <= result_counter + 1; end
2: begin result_tempb <= mul_result + mul_resultb; res_mul_dataa <= coeff1; res_mul_datab <= (b[0][0]>>>3); res_mul_datad <= (b[0][1]>>>4); result_step <= 1; result_counter <= result_counter + 1;end
3: begin result_temp <= mul_resultb; result_step <= 0; result_counter <= result_counter + 1; end
4: begin result_697 <= result_tempb - result_temp; result_counter <= result_counter + 1; end
经过修改后,占用资源显著减少,可以在资源非常稀缺的FPGA,如EP4CE6E22C8N上配置。

这是增加2次谐波部分计算后外加PCM接收接口,G711编码解压扩等一系列操作后的资源占用情况。
4.5仿真
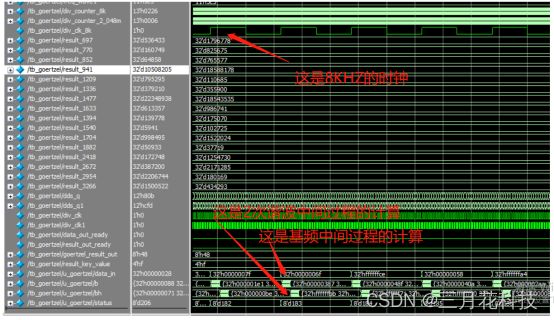
通过仿真图可以清晰明了得看到,在每个8KHZ的时钟内,进行中间变量的计算。依次计算基频部分和2次谐波部分。
一直到205点全部计算完毕后,即第206个状态时,开始计算结果。
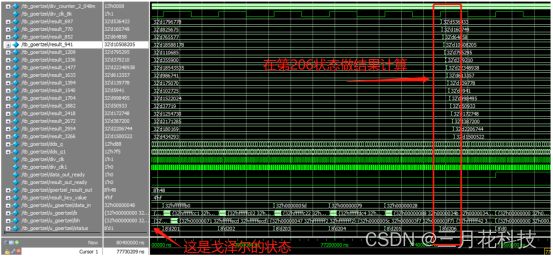
从结果以倾斜分布就可明了得看出,其是串行一个个计算出来的。
至此在不改变任何外界信号的条件下,仅使用两个乘法器完成了同样的功能。
5.源码分享
Goertzel算法,基于Verilog实现,可仿真,可综合-嵌入式文档类资源-CSDN下载
完整的分享,里面tb开头等文件是testbeench,可以直接在仿真软件上运行。其余所有.v和.sv文件均可综合。现在已经在EP4CE6E22C8N和EP4CE10F17C8N上成功综合并运行。
6.后续展望
戈泽尔算法在DTMF双音频检测中占有举足轻重的地位,功能稳定且资源占用少的戈泽尔算法实现为整个DTMF双音频检测奠定了坚实的基础。后续需要结合PCM的32个时隙以及协调A律13折线编解码功能实现对多个通道的音频进行检测。