机器学习sklearn-随机森林
目录
1 集成学习
2 随机森林分类器
2.1 随机森林分类器函数及其参数
2.2 构建随机森林
2.3 在交叉验证下比较随机森林和决策树
2.4 绘制n_estimators的学习曲线
3 随机森林回归器
3.1 随机森林分类器函数及其参数
3.2 用随机森林回归填补缺失值
4 机器学习调参的基本思想
4.1 相关概念
4.2 实例
1 集成学习
集成学习通过构建并结合多个学习器来完成学习任务,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器 (base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。
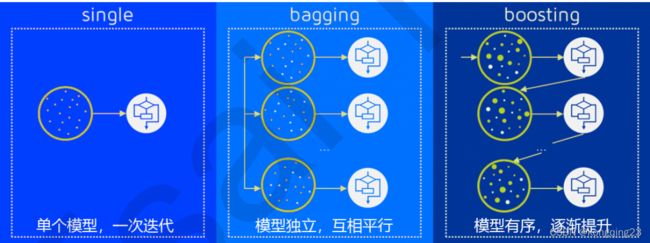
要获得好的集成,个体学习器应该“好而不同”,即个体学习器不仅要有一定的准确性,而且学习器之间应该具有差异。
2 随机森林分类器
2.1 随机森林分类器函数及其参数

随机森林分类器的参数有许多和决策树的参数一致。其中控制基评估器的参数如下。

其他相关参数:
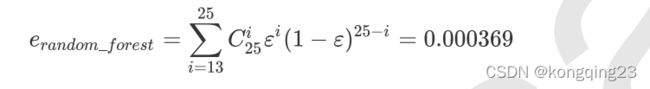
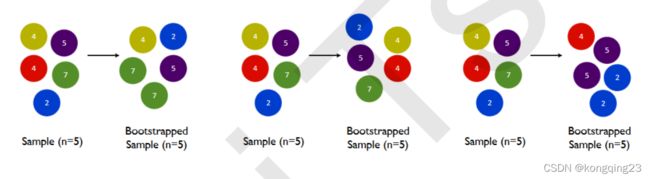
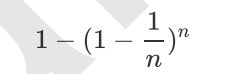
2.2 构建随机森林
在红酒数据集上,随机森林的效果比决策树更好。
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine
wine=load_wine()
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
#实例化
clf=DecisionTreeClassifier()
rfc=RandomForestClassifier()
clf=clf.fit(Xtrain,Ytrain)
rfc.fit(Xtrain,Ytrain)
score_c=clf.score(Xtest,Ytest)
score_r=rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c))
print("Random Forest:{}".format(score_r))
2.3 在交叉验证下比较随机森林和决策树
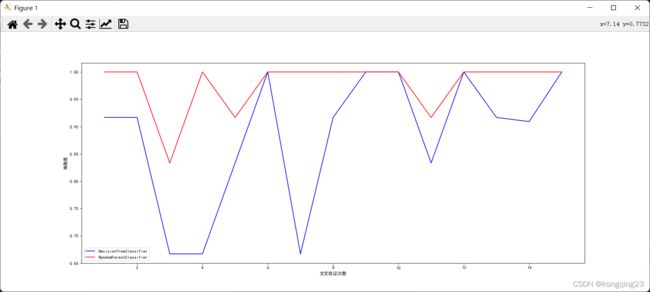
经过对比,可以发现随机森林的效果确实好于决策树,只有少部分情况下,两者的准确率相同,其他时刻,随机森林都优于决策树。
from matplotlib import colors
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_wine
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
wine=load_wine()
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
#实例化
rfc=RandomForestClassifier(n_estimators=20) #设定基评估器数量
clf=DecisionTreeClassifier()
#进行交叉验证
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=15)
clf_s=cross_val_score(clf,wine.data,wine.target,cv=15)
#绘图
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(1,16),clf_s,color='blue',label="DecisionTreeClassifier")
plt.plot(range(1,16),rfc_s,color='red',label="RandomForestClassifier")
plt.xlabel('交叉验证次数')
plt.ylabel('准确度')
plt.legend(loc='best')
plt.show()
2.4 绘制n_estimators的学习曲线
![]()
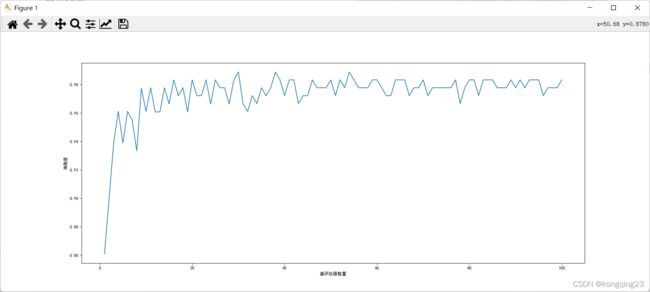
from matplotlib import colors
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_wine
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
wine=load_wine()
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
score=[]
for i in range(100):
rfc=RandomForestClassifier(n_estimators=i+1)
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
score.append(rfc_s)
print("最高准确率{} 对应次数{}".format(max(score),score.index(max(score))))
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(1,101),score)
plt.xlabel('基评估器数量')
plt.ylabel('准确度')
plt.show()
3 随机森林回归器
3.1 随机森林分类器函数及其参数

criterion:
3.2 用随机森林回归填补缺失值
对于一个有n个特征的数据来说,其中特征T有缺失值,我们就把特征T当作标签,其他的n-1个特征和原本的标签组成新的特征矩阵。那对于T来说,它没有缺失的部分,就是我们的Y_test,这部分数据既有标签也有特征,而它缺失的部分,只有特征没有标签,就是我们需要预测的部分。
特征T不缺失的值对应的其他n-1个特征 + 本来的标签:X_train
特征T不缺失的值:Y_train
特征T缺失的值对应的其他n-1个特征 + 本来的标签:X_test
特征T缺失的值:未知,我们需要预测的Y_test
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas.core.frame import DataFrame
from sklearn.datasets import load_boston
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
boston=load_boston()
# print(boston)
# print(boston.data.shape)
#存放完整的数据集,之后会对数据集进行缺失处理再填补,进而和原数据集作比较
x_full,y_full=boston.data,boston.target #存放原始数据及特征
n_samples=x_full.shape[0]#记录完整样本个数
n_features=x_full.shape[1]#记录完整特征个数
#为完整数据放入缺失值
#确定缺失值的比例,这里我们假设为50%
rng=np.random.RandomState(0)#确定一种随机模式
missing_rate=0.5
n_missing_samples=int(np.floor(n_samples*n_features*missing_rate))#向下取整,结果缺失数据总数
# print(n_missing_samples)
#生成的缺失值要分布在数据的各行各列中
miss_features=rng.randint(0,n_features,n_missing_samples) #3个参数依次为下限 上限 个数
miss_samples=rng.randint(0,n_samples,n_missing_samples)
#如果取出的随机数小于样本量 可以采用choice方法
#missing_samples = rng.choice(n_samples,n_missing_samples,replace=False) #从左到右参数为最大值 所需要随机取数的个数 不会重复 保证数据更加分散
#创造缺失的数据
#拷贝原始完整数据后进行操作
x_missing=x_full.copy()
y_missing=y_full.copy()
#将完整数据中一部分以缺失值替代
x_missing[miss_samples,miss_features]=np.nan
#转换为dataframe方便进行后续操作
x_missing=DataFrame(x_missing)
# print(x_missing)
#使用均值填补缺失值
imp_mean=SimpleImputer(missing_values=np.nan,strategy='mean')#实例化
x_missing_mean = imp_mean.fit_transform(x_missing) #fit_transform 训练+导出predict
#查看填补是否完成
# print(pd.DataFrame(x_missing_mean).isnull().sum())
#使用中值填补缺失值
imp_median=SimpleImputer(missing_values=np.nan,strategy='median')#实例化
x_missing_median = imp_median.fit_transform(x_missing) #fit_transform 训练+导出predict
#查看填补是否完成
# print(pd.DataFrame(x_missing_median).isnull().sum())
#使用0进行填补
imp_0 = SimpleImputer(missing_values=np.nan, strategy="constant",fill_value=0)
x_missing_0 = imp_0.fit_transform(x_missing)
#查看填补是否完成
# print(pd.DataFrame(x_missing_0).isnull().sum())
#使用随机森林填补缺失值
x_missing_reg=x_missing.copy()#复制需要利用回归填补缺失值的矩阵
#找出缺失值从小到大对应特征值排列的顺序 本质是找索引 从缺失最多的开始填充
sortindex=np.argsort(x_missing_reg.isnull().sum(axis=0)).values #argsort返回索引 利用values把数据取出
#遍历填充缺失值
for i in sortindex:
#构建新特征矩阵(没有被选中去填充的特征+原始标签)和新标签(被选中去填充的特征)
df=x_missing_reg
fillc=df.iloc[:,i]
#新的特征矩阵
df=pd.concat([df.iloc[:,df.columns!=i],pd.DataFrame(y_full)],axis=1) #左右连接
#在新特征矩阵中,对含有缺失值的列,进行0的填补
df_0 =SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df)
#找出训练集 测试集
Ytrain = fillc[fillc.notnull()] #被选中要填充的特征中的非空
Ytest = fillc[fillc.isnull()] #被选中要填充的特征中,不存在的那些值 我们需要的不是ytest的值,而是其索引
Xtrain = df_0[Ytrain.index,:] #在新特征矩阵上,被选出来的非空值所对应的记录
Xtest = df_0[Ytest.index,:] #在新特征矩阵上,被选出来的那个特征空值所对应的记录
#利用随机森林填补缺失值
rfc = RandomForestRegressor(n_estimators=100)
rfc = rfc.fit(Xtrain, Ytrain)
Ypredict = rfc.predict(Xtest)#得到预测结果
#将填好的特征填入原始特征矩阵
x_missing_reg.loc[x_missing_reg.iloc[:,i].isnull(),i]=Ypredict #先利用iloc找出为nan的行索引
# print(x_missing_reg.isnull().sum())
#对所有数据进行建模,取得MSE结果
X = [x_full,x_missing_0,x_missing_mean,x_missing_median,x_missing_reg]
mse = []
std = []
for x in X:
estimator = RandomForestRegressor()
scores = cross_val_score(estimator,x,y_full,scoring='neg_mean_squared_error', cv=5).mean()#使用负的均方误差打分
mse.append(scores * -1)#将结果转正
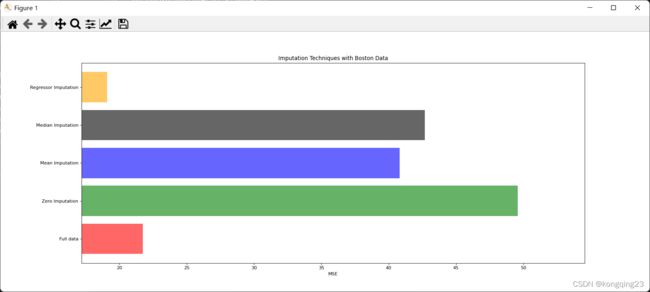
print(*zip(['x_full','x_missing_0','x_missing_mean','x_missing_median','x_missing_reg'],mse))#越小越好
#绘图
x_labels = ['Full data','Zero Imputation','Mean Imputation','Median Imputation','Regressor Imputation']
colors = ['r', 'g', 'b','black', 'orange']
plt.figure(figsize=(20, 8),dpi=80)
ax = plt.subplot(111) #添加子图 为后续函数化做准备
for i in np.arange(len(mse)):
ax.barh(i, mse[i],color=colors[i], alpha=0.6, align='center') #将条形图横过来 在中央绘制
ax.set_title('Imputation Techniques with Boston Data')
ax.set_xlim(left=np.min(mse) * 0.9,right=np.max(mse) * 1.1)#限定范围 x轴为mse取值
ax.set_yticks(np.arange(len(mse)))#设置y刻度
ax.set_xlabel('MSE')
ax.set_yticklabels(x_labels)#更改y的刻度
plt.show()4 机器学习调参的基本思想
4.1 相关概念
模型调参,第一步是要找准目标:我们要做什么?一般来说,这个目标是提升某个模型评估指标,比如对于随机森林来说,我们想要提升的是模型在未知数据上的准确率(由score或oob_score_来衡量)。找准了这个目标,我们就需要思考:模型在未知数据上的准确率受什么因素影响?在机器学习中,我们用来衡量模型在未知数据上的准确率的指标,叫做泛化误差(Genelization error)。
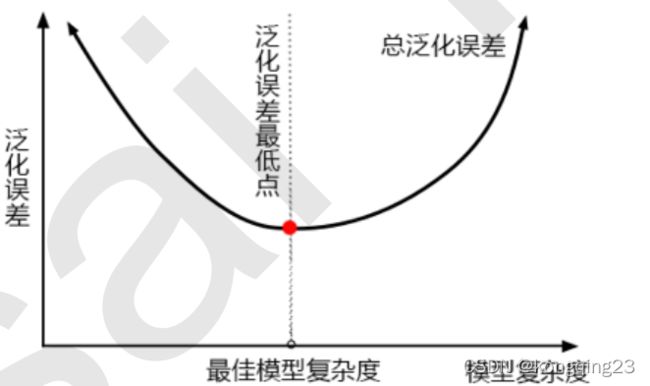

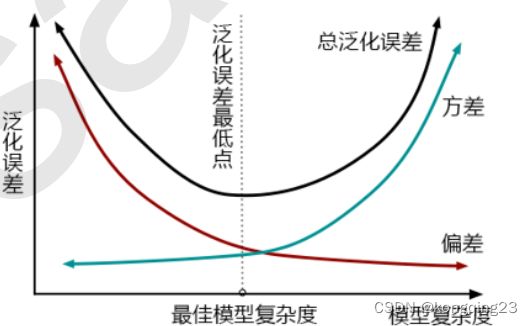

4.2 实例
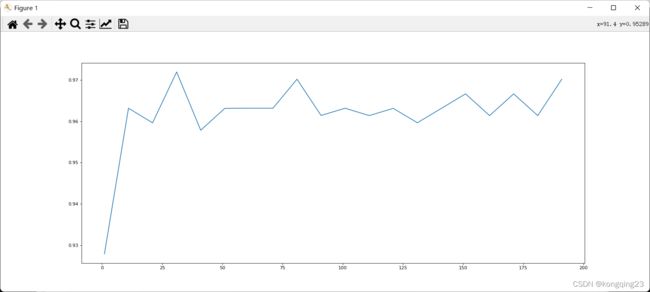
查看n_estimators的学习曲线。
![]()
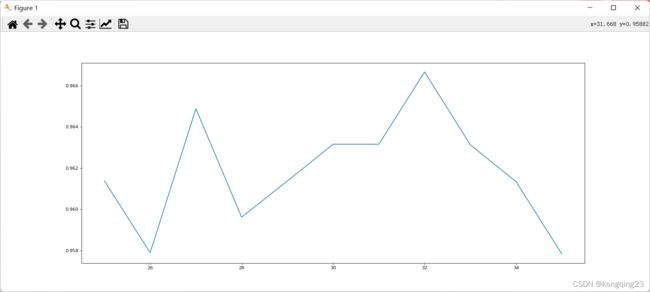
在确定好的范围,进一步细化学习曲线。
![]()
由于每一次训练集测试集划分的情况不同,所以可能出现细化后的表现不如之前,但是总体而言,细化后的曲线可以提供更为精确的参数选择范围 。确定了基评估器的数量后,进一步使用网格搜索查找其他合适参数。
在调制了max_depth后,模型精确度上升,所以模型在泛化复杂度右边。
此时min_samples_split反而让准确率下降,所以不设置改参数。
调整random_state
![]()
对准确率有所提升。
完整代码如下
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = load_breast_cancer()
#初步估计
# scorel = []
# for i in range(0,200,10):
# rfc=RandomForestClassifier(n_estimators=i+1)
# score=cross_val_score(rfc,data.data,data.target,cv=10).mean()
# scorel.append(score)
# print(max(scorel),(scorel.index(max(scorel))*10)+1)
# plt.figure(figsize=[20,8],dpi=80)
# plt.plot(range(1,201,10),scorel)
# plt.show()
#细化估计
# scorel = []
# for i in range(25,36):
# rfc=RandomForestClassifier(n_estimators=i+1)
# score=cross_val_score(rfc,data.data,data.target,cv=10).mean()
# scorel.append(score)
# print(max(scorel),([*range(25,36)][scorel.index(max(scorel))])) #在30-39范围内 取最大值对应的索引
# plt.figure(figsize=[20,8],dpi=80)
# plt.plot(range(25,36),scorel)
# plt.show()
#调整max_depth
# param_grid = {'max_depth':np.arange(1, 20, 1)}
# 一般根据数据的大小来进行一个试探,乳腺癌数据很小,所以可以采用1~10,或者1~20这样的试探
# 但对于像digit recognition那样的大型数据来说,我们应该尝试30~50层深度(或许还不足够
# 更应该画出学习曲线,来观察深度对模型的影响
# rfc = RandomForestClassifier(n_estimators=32)
# GS = GridSearchCV(rfc,param_grid,cv=10)
# GS.fit(data.data,data.target)
# print(GS.best_params_,GS.best_score_)
#调整max_features
#现在模型位于图像右侧 我们需要更低的复杂度
#max_features的默认最小值是sqrt(n_features),因此我们使用这个值的两倍作为调参范围的最大值。
# param_grid = {'max_features':np.arange(1,10,1)}
# rfc = RandomForestClassifier(n_estimators=32,max_depth=11)
# GS = GridSearchCV(rfc,param_grid,cv=10)
# GS.fit(data.data,data.target)
# print(GS.best_params_,GS.best_score_)
#调整min_samples_leaf
#对于min_samples_split和min_samples_leaf,一般是从他们的最小值开始向上增加10或20
#面对高维度高样本量数据,如果不放心,也可以直接+50,对于大型数据,可能需要200~300的范围
#如果调整的时候发现准确率无论如何都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
# param_grid={'min_samples_leaf':np.arange(1, 1+10, 1)}
# rfc = RandomForestClassifier(n_estimators=32,max_depth=11,max_features=7)
# GS = GridSearchCV(rfc,param_grid,cv=10)
# GS.fit(data.data,data.target)
# print(GS.best_params_,GS.best_score_)
#调整random_state
# param_grid={'random_state':np.arange(20,150)}
# rfc = RandomForestClassifier(n_estimators=32,max_depth=11,max_features=7)
# GS = GridSearchCV(rfc,param_grid,cv=10)
# GS.fit(data.data,data.target)
# print(GS.best_params_,GS.best_score_)
#确定最终参数
rfc = RandomForestClassifier(n_estimators=39,max_depth=11,max_features=7,random_state=66)
score = cross_val_score(rfc,data.data,data.target,cv=10)
print(score)