论文笔记:主干网络——ResNeXt
Aggregated Residual Transformations for Deep Neural Networks
深度神经网络中的残差聚合变换
文章目录
- Aggregated Residual Transformations for Deep Neural Networks
- 深度神经网络中的残差聚合变换
-
- 论文结构
- 一、摘要核心
- 二、Aggregated Transformations 聚合变换
-
- ① 一个神经元的操作(论文中的3.2)
- ② Block中的聚合变换(论文中的3.3)
- ③ Block的三种等效形式(论文中的3.3)
- ④ 分组卷积
- ⑤ 模型能力(论文中的3.4)
- 三 、ResNeXt
- 四、实验结果分析
-
- ① 实验1:研究cardinality与bottleneck width之间权衡关系
- ② 实验2:对比加宽、加深和加大cardinality
- ③实验3:各模型横向对比
- ④ 实验4:ImageNet-5K数据集
- ⑤ 实验5:CIFAR数据集
- 五、论文总结
-
- ① 关键点、创新点
- ② 备用参考文献知识点
- 六、VGG、ResNet、Inception系列与ResNeXt的回顾
论文结构
摘要: 提出聚合变换的操作,及cardinality(分组卷积的组数)指标用于衡量模型复杂度,提出的ResNeXt多个任务超越ResNet。
1. Introduction: 介绍VGG、ResNet、Inception的优点,本文将各优点结合得到ResNeXt。
2. Related Work: 简洁多分支、分组卷积、模型压缩(提升性能、参数量没有提升)及模型集成。
3. Method: Template引入基础Building Block,重新思考全连接操作,提出Aggregated Transforms。
4. Implement Details: 介绍实验各参数设置。
5. Experiments: 4个实验设置及结果分析。
一、摘要核心
① 全文概况:本文提出一个简洁且高度可调节的神经网络结构,该网络通过反复堆叠Building Block实现,Building Block则通过聚集简洁的卷积模块来实现。
② 本文优点:该网络具有相同的、多分支的结构,并且对应的超参数非常少。
③ 本文提出一个与网络宽度和深度类似作用的参数,用来衡量网络大小,称之为Cardinality(基数)——the size of the set of transformations.
④ 本文结论:ImageNet-1K数据集上,不增加模型复杂度,增加Cardinality可以提升网络性能,同时发现增加cardinality比增加网络深度和宽度可以更好的提升网络模型的性能。
⑤ 本文成果
二、Aggregated Transformations 聚合变换
① 一个神经元的操作(论文中的3.2)
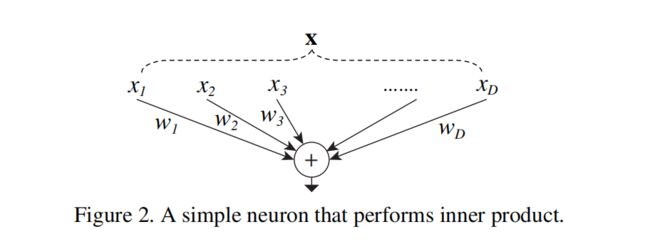
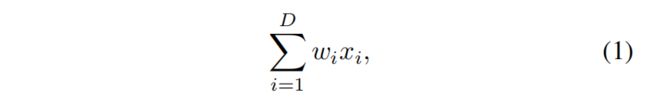
(1)
Splitting: x分解为D个元素,可以理解为低维嵌入。
Transforming:每个元素进行变换,乘wi进行缩放
Aggregating:对D个变换后的结果进行聚合(求和)
(2)Inception:split-transform-aggregate
Split:输入分支, 引入1×1卷积:参数量太复杂,做一个低维嵌入,让输入的数据变的简单化,容易操作
transform:每个分支相当于一个变换,对数据做了一系列操作,由网络层完成。
merge:逐通道拼接
② Block中的聚合变换(论文中的3.3)

Splitting:通过1×1卷积实现低维嵌入,256个通道变成4个通道,总共32个分支(cardinality = 32)
C=32,d=4
Transforming:每个分支进行变换(对网络层对数据操作)
Aggregating:对32个分支得到的变换结果——特征图,进行聚合(求和)
③ Block的三种等效形式(论文中的3.3)
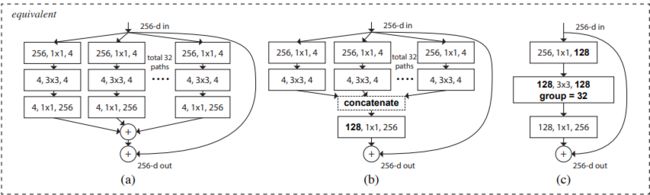
(a)split-transform-merge三阶段形式
(b)将各分支的最后一个1×1卷积融合成一个卷积
(c)将各分支的第一个1×1卷积融合成一个卷积,3×3卷积采用分组卷积的形式,分组数=cardinality(基数)
卷积参数等价:
(a)第三层 4×1×1×256×32=32768
(b)第三层 128×1×1×256 = 32768
(b)第一层 256×1×1×4×32=32768
第二层 4×3×3×4×32=4608
(c)第一层 256×1×1×128=32768
第二层 128/32×3×3×128 = 4608

④ 分组卷积
分组卷积使用更少的参数得到相同的特征图,参数量减少到 1/分组数
逐通道卷积是分组卷积的特例:分组数=通道数
分组卷积的好处:让网络学习到不同的特征,每组卷积学习到的特征不一样,获得更丰富的信息。
(AlexNet 两组卷积核学习两种不同的特征,一组学习纹理,另一组学习色彩)
⑤ 模型能力(论文中的3.4)
两个重要参数:Cardinality和Width
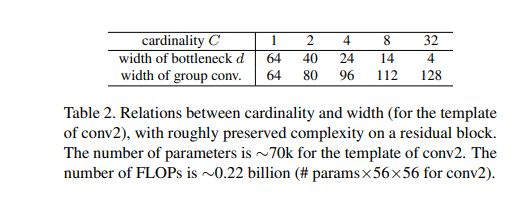
(1)C逐渐增大时,模型性能的变化;
(2)设计C和d,使得整体的参数量在70k左右。目的是对标resnet。
三 、ResNeXt
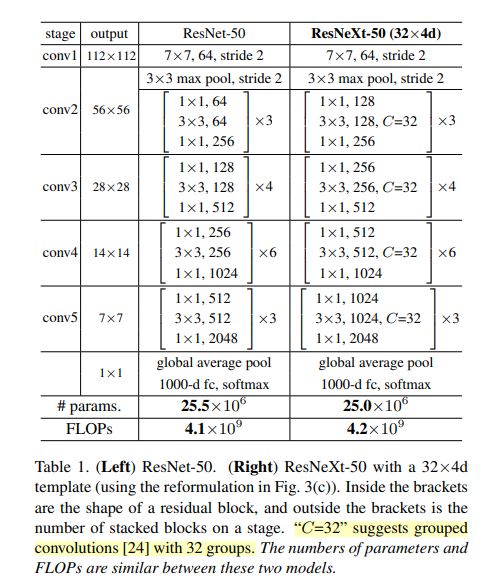
整体结构与ResNet一致,只有Building Block不同。
划分为6个stage
- 头部迅速降低分辨率
- 4阶段残差结构堆叠
- 池化+FC层
特点:加入了分组卷积,节省了参数量,因此可以用更多卷积核。
四、实验结果分析
① 实验1:研究cardinality与bottleneck width之间权衡关系
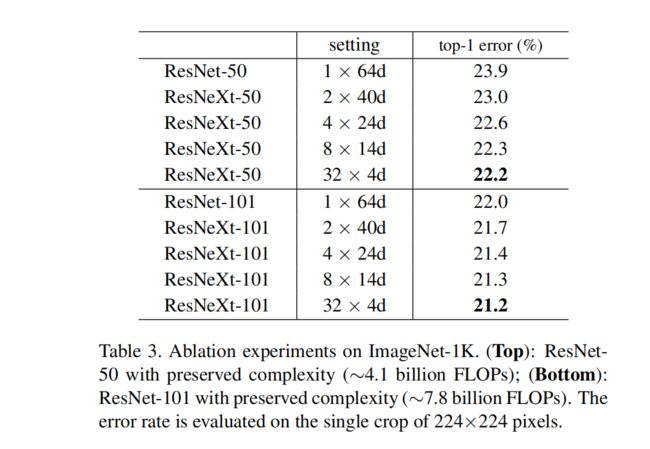
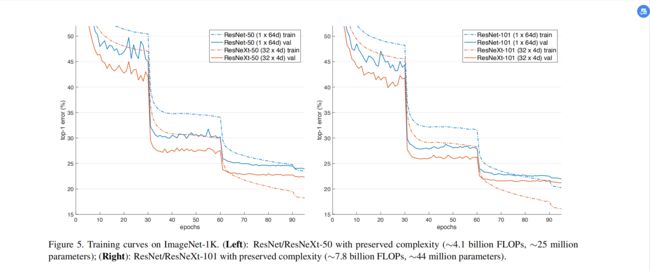
针对不同深度的模型设置了不同的cardinality和width,随着C的增大,性能提升,error下降,说明C是有效的参数。
结论:
4种方案中,32×4d精度最高;
精度随cardinality增加而提高
② 实验2:对比加宽、加深和加大cardinality
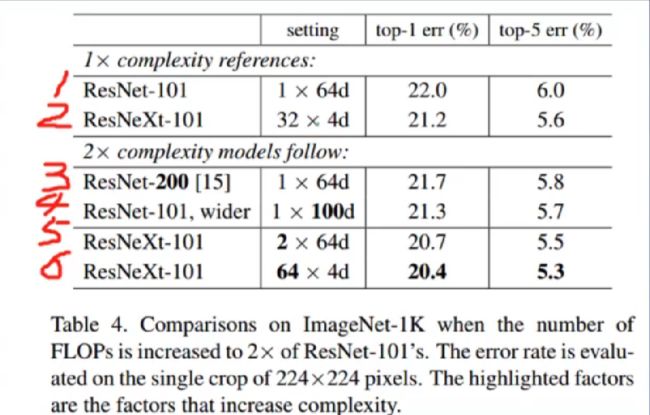
模型1和2是baseline;
模型3和4是ResNet的加深、加宽;
模型5和6是ResNeXt的加大cardinality版
结论:
加大cardinality比网络的宽度和深度更有效
③实验3:各模型横向对比
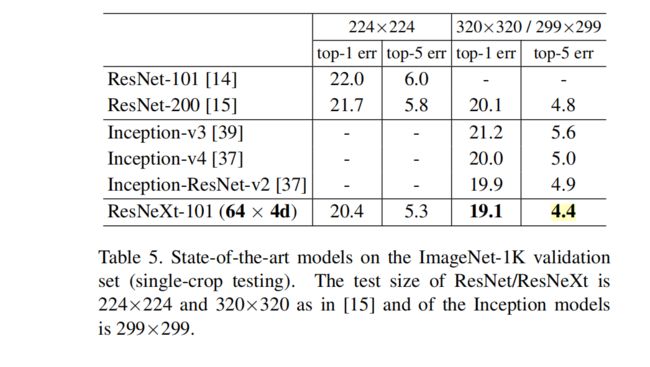
结论:
全面超越ResNet和加宽的ResNet
全面超越Inception系列
④ 实验4:ImageNet-5K数据集
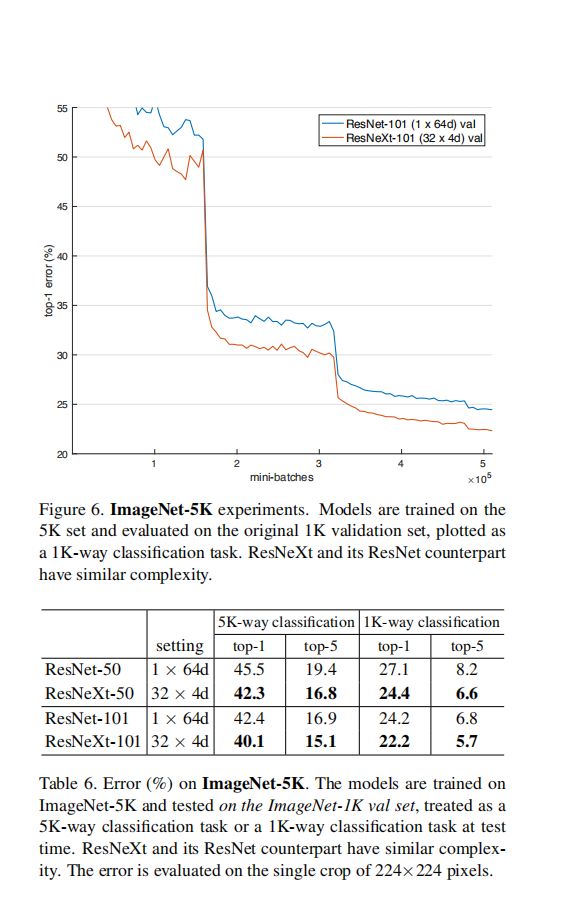
在1K的实验中发现,ResNeXt有很强的的表征能力,并且在ImageNet-1K数据集上未发挥出ResNeXt的性能,因为ResNeXt比ResNet有更高的方差,因而考虑更大数据集上训练。
解决高方差的一个思路:采用更多的数据
结论:
数据足够时,ResNeXt比ResNet有更强的学习能力
⑤ 实验5:CIFAR数据集
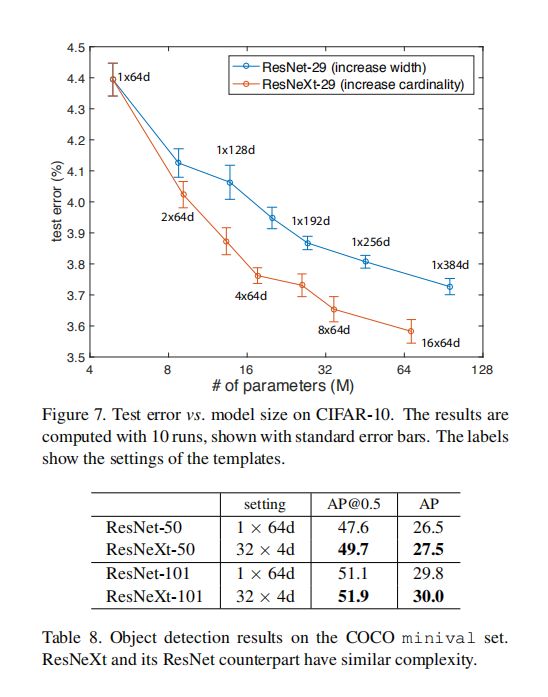
对比多种宽度ResNet与多种cardinality的ResNeXt
结论:
ResNeXt全面超越ResNet
五、论文总结
① 关键点、创新点
(1)提炼VGG、ResNet和Inception系列的优秀思想:
处理相同尺寸的特征图时,采用同样大小、数量的卷积核;
特征图分辨率长款降低2倍时,特征图通道数(卷积核数量)翻倍;
block中各分支采用相同结构,演化成分组卷积
(2)提出cardinality来衡量模型复杂度,实验表明cardinality比模型深度、宽度更高效
② 备用参考文献知识点
(1)相同架构的block进行堆叠,可以减少过度适应的风险,侧面反映出Inception系列模型泛化性能可能较差
…stacking building blocks of the same shape. we argue that the simplicity of this rule may reduce the risk of over-adapting the hyperparameters to a specific dataset.(论文1的第二段)
六、VGG、ResNet、Inception系列与ResNeXt的回顾
VGG:结构简洁(超参只关心深度和宽度),堆叠使用3×3卷积,广泛应用到各视觉任务中
ResNet:沿用VGG的简洁结构设计,同时堆叠的Building Block采用残差结构。模型去拟合的不是原来假设的H(x),而是H(x)- x。
可以加快模型训练,让梯度流通更顺畅,可以训练更深的网络。
Inception系列:采用多分支结构,采用inception-module。
采用多尺度的卷积核来对特征图进行特征提取。不同branch有不同的卷积核来对同一个特征图进行特征的提取和操作,将提取的多样性的特征拼接起来。
缺点:超参数过多,泛化性差
优点:Split-Transform-Merge思想
分支-变换(针对不同的卷积核,对数据做一系列的变换)-合并特征
ResNeXt 结构上采用多个Building Block堆叠,结构简洁,Building Block中采用残差结构,同时采用Aggregated Transform,即Split-Transform-Merge思想