【cvpr-论文笔记】《Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation》
目录
文章概述
符号解读
核心思路
Seeding loss with localization cues
Expansion loss with global weighted rank pooling
Constrain-to-boundary loss
训练与反向传播
研究相关
测试方法
实验方法
现有不足
本文记录弱监督语义分割领域论文笔记《Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation》
文章发布于 2016/03/16 ECCV2016
官方caffe代码 https://github.com/kolesman/SEC
非官方pytorch代码 https://github.com/halbielee/SEC_pytorch
文章概述
将弱监督应用到语义分割领域,即使用现有的分类或目标检测模型(拥有分类或检测的标注文件)实现语义分割任务,目的为节省昂贵的pixel-level像素级的标注成本。大多将弱监督应用到语义分割的流程为:利用现有的分类或检测的标注文件通过某种算法(如CAM)得到粗粒度即不精确的分割标注文件,也叫pseudo-label伪标签,直接使用伪标签训练分割网络,最后再通过某种算法(如CRF)对结果进行优化。也就是说大多的弱监督研究重点在于如何更好的生成伪标签,即更好的训练生成网络。
本文另辟蹊径,通过使用image-level图像级的分类模型,创新Loss损失函数,直接训练适用于弱监督的分割网络。这里分割网络使用DeepLab,分类模型是VGG,使用COCO和PASCAL VOC2012等数据集。
We introduce a new loss function for the weakly-supervised training of semantic image segmentation models based on three guiding principles: to seed with weak localization cues, to expand objects based on the information about which classes can occur in an image, and to constrain the segmentations to coincide with object boundaries.
研究的核心为探索由三部分结合的损失函数:Lseed,Lexpand,Lconstrain。
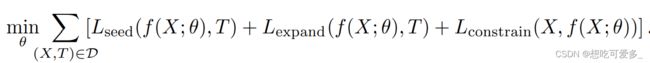
用形象的语言来解释各部分的作用
Lseed:在目标的核心位置种下一颗“种子”,保证分割时关注正确的位置
Lexpand:使分割从种子的位置开始向附近扩张,去接近目标的真实大小
Lconstrain:限制分割扩张,使其更好的拟合目标的真实轮廓
符号解读
现对文中使用的符号进行解读 ,并借此分析研究思路

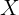 :图片输入
:图片输入
![]() :segmentation mask,即分割结果,由向量
:segmentation mask,即分割结果,由向量 ![]() 组成,代表图片的n个位置。类别集
组成,代表图片的n个位置。类别集 ![]() 由 目标类别的集合
由 目标类别的集合 ![]() 和 一个背景类
和 一个背景类 ![]() 组成,目标类也叫前景类。每个位置的输出是由每个类别对应的概率所组成的向量,哪个类概率最大该位置就会被归为哪一类。
组成,目标类也叫前景类。每个位置的输出是由每个类别对应的概率所组成的向量,哪个类概率最大该位置就会被归为哪一类。
这里表明:这里并没有对原图的每一个像素点都进行分类,而是分为n个区域,对每个区域的多个像素点进行统一分类。这是因为使用的DeepLab输出的segmentation maks的尺寸是41x41(即n=1681), 小于输入尺寸321x321。
而对于像UNet这种分割网络,输出尺寸经过上采样会恢复到输入尺寸,这时的分割则是对原图的每一个像素进行分类(n=原图像素)。
![]() :训练集容量为N,每张图片对应标注
:训练集容量为N,每张图片对应标注![]() ,
,![]() 是前景集合
是前景集合![]() 的子集,不包括背景。即标注是分类模型的标注,仅说明了一张图片出现了哪些前景,对应我们弱监督的应用场景。
的子集,不包括背景。即标注是分类模型的标注,仅说明了一张图片出现了哪些前景,对应我们弱监督的应用场景。
![]() :这是我们训练网路的目标函数。看等式左边,模型以X为输入,以θ为参数。再看等式右边,模型的输出是n个概率向量,第u个向量的第c个元素代表,当前模型按照当前输入时,第u个位置属于第c类(包括背景)的概率。
:这是我们训练网路的目标函数。看等式左边,模型以X为输入,以θ为参数。再看等式右边,模型的输出是n个概率向量,第u个向量的第c个元素代表,当前模型按照当前输入时,第u个位置属于第c类(包括背景)的概率。
核心思路
现在根据三种Loss值的公式进行详细分析
Seeding loss with localization cues
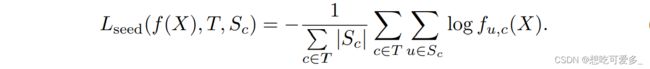
本文所提到的“种子”为作者利用week localization弱定位方法来获得分割目标核心特征的位置,![]() 便代表了弱定位集,集合内包含了第c类核心特征在图片中的位置。e.g.{S1={1,2,3,4,7,8,9,10}, S2={}, ..., Sn={101, 102, 103, 104}},有一点需要注意,定位集的每个元素≤n,即面向segmentation mask的每一个像素,而每个物体的“种子”通常是由多个像素点组成的。
便代表了弱定位集,集合内包含了第c类核心特征在图片中的位置。e.g.{S1={1,2,3,4,7,8,9,10}, S2={}, ..., Sn={101, 102, 103, 104}},有一点需要注意,定位集的每个元素≤n,即面向segmentation mask的每一个像素,而每个物体的“种子”通常是由多个像素点组成的。
看式子末尾累加内容:c是前景集合的第c个类别,u是第c类的弱定位集合的第u个位置。即把所有前景类的弱定位集中存在的位置的相应类别的概率取对数后相加。
![]() 表示集合长度。把整个式子除以,考虑所有前景类时弱定位的位置个数(也就是“种子的个数”)和,求平均(因为和个数无关)。
表示集合长度。把整个式子除以,考虑所有前景类时弱定位的位置个数(也就是“种子的个数”)和,求平均(因为和个数无关)。
训练趋势:因为式子有负号,随着梯度下降,Loss减小 ,会提高弱定位集相应位置相应类别整体的概率 。就好像在时刻地促使分割结果集中于“种子”,防止训练时分割位置错误的移动。
关于week localization弱定位:作者在文中没有明确提及使用何种算法进行定位,通过配图可以推断使用了CAM算法。

CAM:是一种可以使用在神经网络的每一层中(本文使用分类网络的最后一个非全连接层),利用例如梯度等信息生成热力图,观察当前神经元进行判断某物体时的关键依据(红色区域),该依据的位置就是我们想要的目标物体的关键特征,也就是“种子“的位置。
Expansion loss with global weighted rank pooling

第一步的种子区域显然只是目标物体的一部分。在全图中有些像素属于某一类,但是因为概率较小而没有成功分类,这一步就是为了提升他们的概率以至于可以纳入分割区域。这些区域通常围绕在种子周围,所以就好像从种子开始,向周边进行扩张蔓延。
这里提出了一种新的池化方法global weighted rank pooling (GWRP),来实现我们的目的。
Formally, let an index set
define the descending order of prediction scores for any class
i.e.
, and let
be a decay parameter for class
. Then we define the GWRP classification scores,
, for an image
, as following:
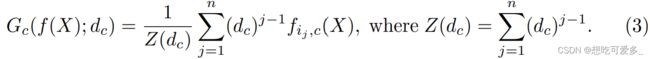
这里均是全局池化,池化的对象是每个位置输出为第c类的概率。
池化的目的是把当前的分割模型转换为多分类模型。为什么要这么做呢?首先分割作为pixel-level的模型,蕴含的信息是最为丰富的,通过观察一张图片是否有某类的分割,可以很轻易的直接得到这张图片属于哪一类,也就是从分割转换为分类。而我们拥有的标注文件正是分类标注,将生成的分类和标注的分类组合后便可以用来求损失反向传播来修正分割网络。但是刚才说的这种转换方法是不可微分的(梯度始终为0),也就是无法进行反向传播。
因此我们采用可以计算梯度的算法GWPR。在求某图的第c类的分类时(包括背景),我们把分割输出的segmentation mask所有位置对第c类的概率池化。如何池化呢?首先对n个位置按照c类的概率降序排序生成集合 ![]() ,看公式(3),对集合元素从前往后乘以衰减参数
,看公式(3),对集合元素从前往后乘以衰减参数 ![]() 的(j-1)次方后累加,然后除以
的(j-1)次方后累加,然后除以  做平均化。衰减参数
做平均化。衰减参数 ![]() 是一个小于1的数,j是某位置在
是一个小于1的数,j是某位置在![]() 的位置,在衰减参数不断求次方结果会越来越小。
的位置,在衰减参数不断求次方结果会越来越小。
通俗来讲,就是第c类在n个位置的概率加权后相加,相加后得到的这个值就是我们认为该图片属于第c类的得分,得分越高,图片越有可能属于第c类,这样便从分割转换成了分类。根绝衰减参数可以看出,这个权是越来越小的,衰减参数越小,减小的越快,也就是越有可能是第c类的位置,对第c类分类的贡献越大。
最后来看Loss函数,随着梯度下降,根据标注,若某些类存在于图片,这个类的池化值正向发展;若不存在,则负向发展;背景正向发展。随着训练,提高对标注中有的类和背景的分割能力,抑制对没有的类的的分割能力。
文中指出,衰减参数可以根据输入图片以及待分类的类别动态调整,但是这需要先验知识,这显然对弱监督来说是不可能的。
因此文中仅根据标注有的类、标注没有的类和背景三种各使用不同的衰减参数。
![]() :按照
:按照 ![]() 前10%的元素对分类贡献50%的原则设置(类比大学的加权成绩计算方法,10%的科目的学分和占总学分的50%)。可以设方程
前10%的元素对分类贡献50%的原则设置(类比大学的加权成绩计算方法,10%的科目的学分和占总学分的50%)。可以设方程 ![]() ,根据等比级数公式即可解得d+得近似值。
,根据等比级数公式即可解得d+得近似值。
![]() :按照
:按照 ![]() 前30%的元素对分类贡献50%的原则设置 。解法同上。
前30%的元素对分类贡献50%的原则设置 。解法同上。
![]() :观察发现,当衰减参数是0时,除了0的0次方是1,其余都是0,也就是说池化层累加的内容只有
:观察发现,当衰减参数是0时,除了0的0次方是1,其余都是0,也就是说池化层累加的内容只有 ![]() 的第一项,这是可以看成是全局最大值池化GMP;同时也有
的第一项,这是可以看成是全局最大值池化GMP;同时也有 ![]() = 1 的时候,衰减参数恒为1,相当于全局平均池化GAP。
= 1 的时候,衰减参数恒为1,相当于全局平均池化GAP。
文中指出,GMP和GAP在当前问题明显是很局限的池化方法,若使用GAP,会导致过度扩张;若使用GMP,会导致不充分扩张。其中很有意思的是,对于GMP,由于 ![]() 是降序排列的,若使用GMP进行训练需要增长的类别,那么只会导致最大值越来越大,完全起不到扩张 的作用,因此GMP仅能用于抑制训练,也就是对应文中的 d- = 0。
是降序排列的,若使用GMP进行训练需要增长的类别,那么只会导致最大值越来越大,完全起不到扩张 的作用,因此GMP仅能用于抑制训练,也就是对应文中的 d- = 0。
Constrain-to-boundary loss

分割的精细度是弱监督语义分割的难解问题,同样也是一般语义分割的一大缺陷,流行的做法是采用CRF条件随机场(或dense-CRF等)来平滑分割结果,使结果更加精细,更好的拟合物体的边缘。本文也不例外,使用dense-CRF算法优化前两步粗糙的分割结果,使物体边缘更精确。
这里仍是使用损失函数来吸收CRF的优点,怎么做呢?把当前的分割结果使用CRF处理后,结合未处理的分割结果求损失反向传播到分割网络。这里的巧妙之处在于直接把CRF的特性学习到分割模型中,从而不必在分割后再重新使用CRF。
具体做法。CRF产生平滑输出需要以原图和分割结果为输入,这是首先需要对原图进行downscale,因为segmentation mask的尺寸小于原图,必须使两者尺寸一样。
Loss函数是目的是使分割的输出尽可能的模仿经过CRF处理过的结果,也就是使两者的分布靠近。因此Loss的内容采用mean KL-divergence平均KL散度,KL散度是衡量两个分布的近距离。在训练时会不断减小两种分布的距离,增加两种分布的相似度。也就是分割网络学习到了CRF的特性。
本文基本使用原始的dense-CRF的超参数,其余被downscale影响的参数需重新设定,因为downscale改变了随机场内相邻变量的联系。
训练与反向传播
前面详解了三种损失函数的构成以及训练方式,但是如何在同一张网络中同时使用三种损失训练,现在用下面这张图解释参数的梯度是如何流动的。

这里的网络结构中三条路线训练时的梯度信息都会更新到分割网络,也就是直接训练一个具有弱监督分割能力的分割网络,不再额外附加算法,端到端地完成分割任务,除训练使用的分类模型和分类标签,其他中间内容不可见。
图中黑色箭头表示正向传播路径,灰色箭头表示反向传播路径。
首先中间的分割网络是主干,在生成原始分割图像后(训练开始时使用预训练模型,训练初期会是一个效果很差的mask),和上方通过在原图弱定位(在分类网络中使用CAM系列算法)生成的定位图计算Seeding Loss;
中间的线路代表原始分割图片通过GWPR池化后和分类标签计算Expansion Loss;
下面的线路代表原图downscale后和原始分割图像利用dense-CRF算法生成平滑的分割图像,然后平滑的分割图像和原始的分割图像计算Constrain-to-boundary Loss;
三种Loss求和后计算梯度(求和代表综合三者的功能),沿着灰色箭头更新参数,最重要的就是更新分割网络。最上方的弱定位参数不需要更新,因为他是现有的分类模型,是实验固定的前提条件。至于CRF的梯度传递,可以参考《Random field model for integration of local information and global information》。
研究相关
测试方法
测试时会计算mIou,这里是需要像素级的分割标注文件的。测试时会对分割结果再次使用dense-CRF,但是这次是要和分割标注文件计算mIou,所以尺寸要和原图一样,所以使用CRF时需要对segmentation mask做upscale。

实验方法
探索池化:在计算Expansion Loss时使用到了池化,文中对GAP、GMP和GWRP进行了实验对比,结果和统计分析契合。

消融实验:主要针对三种Loss结果的影响进行消融实验。由实验结果可以看出Seeding Loss种子的重要性,他对实验结果起决定性影响,考虑到物体的位置对于分割的重要性。seed+expand的结果差于seed本身,考虑到在扩大时没有constrain的限制。实验证明了只有同时使用三种损失函数才有更好的结果。

现有不足
在弱监督语义分割领域有两大共性问题。
1、弱监督分割的精细度不足。在这一点上大多就是采用CRF算法进行弥补,本文同样采用了训练学习的方式学习CRF更加平滑的分割能力。
2、前景和背景的耦合。e.g.如果要切割火车,而训练集中火车总是在铁轨上出现的,很显然在仅有分类模型的情况下,很有可能会把铁轨和火车当成一个整体整体,也就是把部分背景当成了前景的一部分,作者在另一篇论文中讨论了相关的解决方法:《Improving weakly-supervised object localization by micro-annotation》,其中也展示了作者在本文基础上进一步的研究。至于耦合的原因,抛开固有的缺陷,很有可能是分类网络的问题。前面提到CAM生成的热力图可以生成分类网络分类时关注的重点,进而获得弱定位位置。还用那个例子,如果分类火车时,是以铁轨为重要特征,那么就会造成弱定位位置偏向铁轨使铁轨成为分割对象。
而此研究也存在一个特有的问题:错误分类(发生概率很低)。前面提到种子的核心重要性,那么错误分类可以归结为“播种”时类别错误,导致后面步步错。究其原因,考虑到是DeepLab网络的大感受视野(实验证明小视野效果更差),以及物体间位置重叠、形状复杂特征多以及物体间共享特征。