论文笔记系列:主干网络(二)-- DenseNet
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
稠密连接卷积神经网络Densely Connected Concolutional Networks
论文链接: Densely Connected Convolutional Networks
前言: DenseNet(Densely connected convolutional networks) 模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。本篇文章首先介绍DenseNet的原理以及网路架构,然后讲解DenseNet在Pytorch上的实现。
对比Resnet设计理念:
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L LL 层的网络,DenseNet共包含 L ( L + 1 ) 2 \frac{L(L+1)}{2}2L(L+1)个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
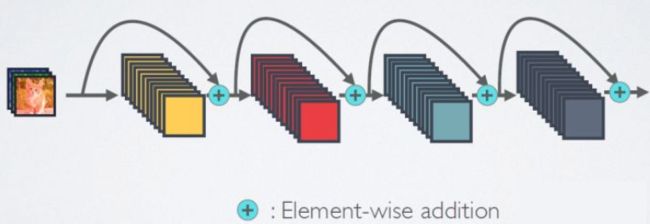
ResNet网络的短路连接机制(其中+代表的是元素级相加操作)

DenseNet网络的密集连接机制(其中c代表的是channel级连接操作)

论文结构
摘要: 捷径连接有效;本文提出激进的捷径连接FenseNet;在四个数据集获得SOTA
1. Introduction: CNN的发展,网络深度越来越深;网络深存在信息流通不畅问题;Short path广泛应用;DenseNet简介。
2. Related Work: 级联结构、捷径连接结构的网络模型简介;DenseNet简介。
3. DenseNets: Dense connectivity,pooling layer,Growth rate,bottleneck layer,compression等,网络细节
4. Experiments: 数据集介绍,训练超参介绍,4个数据的分类结果
5. Discussion: 实验结果分析探讨
6. Conclusion: 全文总结,总结本文工作,本文优点,将来可研究方向。
一、摘要核心
- 背景介绍:近年卷积神经网络中加入捷径连接之后,可训练更深、精度更高、更高效的网络
- 研究内容:本文提出DenseNet,其中的每一层会作为其后一层的输入层。对于L层的网络,传统方法有L层连接,而DenseNet有L×(L+1)/2个连接,所以叫DenseNet
- 本文优点:减轻梯度消失,增强特征传播,加强特征复用,减少权重参数
- 实验结果:各项指标超越ResNet
- 开源代码
二、DenseNet 结构
① Dense connectivity
稠密连接:在一个Block中,每一层输入来自于它前面所有层的特征图,每一层输出均会直接连接到它后面所有层的输入
L层block中,有L×(L+1)/2个连接
优点:
用较少参数获得更多特征,减少了参数;
低级特征得以复用,特征更丰富;
更强的梯度流动,跳层连接更多,梯度可更容易向前传播。
② Composite function
将BN层、ReLU层和3×3卷积层组成一组操作对特征进行提取 。
之前接触的操作:x->conv->BN->ReLU
DenseNet:[x0,x1,x2]->BN->ReLU->conv
模型接收的不同网络层的特征图的尺度可能会有很大的差异,再去做卷积不方便。所以在网络层之前做BN和ReLU。
③ Pooling layers
池化层用于降低特征图分辨率,DenseNet将各个block之间的特征图分辨率下降操作成为transition layer,由BN、1×1卷积、2×2池化构成。
transition layer用于dense block之间,Dense block内部要求特征图分辨率保持一致。
④ Growth rate
稠密连接的方式,使得特征图通道数随着网络层的加深不断增多,因此要控制特征图数量。所以引入Growth rate超参数k来衡量dense block中特征图的多少
Growth rate在代码中就是卷积层的卷积核个数,就像ResNeXt中的cardinality就是分组卷积的分组数而已
⑤ Bottleneck layers——DenseNet-B
瓶颈层来降低特征图通道数,减少后续卷积的计算量,当采用率以下形式进行特征提取,则网络会成为DenseNet-B
采用了1×1卷积来降低特征图分辨率,降到4k。k是growth rate增长率

【一个DenseNet中有多个(3个或4个)Dense Block】
【一个Dense Block中有多个Bottleneck layers】
【代码中,Bottleneck layers也称为Dense layers】
⑥ Compression
为进一步使DenseNet紧凑,在transition layer处采用较少的卷积核进行特征提取,从而压缩特征图通道数,压缩率用θ表示,典型值为0.5
当采用了Compression时,模型称为DenseNet-C
当同时采用Bottleneck layer和Compression时,称为DenseNet-BC
通常用的DenseNet指的DenseNet-BC
⑦ DenseNet 网络结构
整体分为三大块:头部卷积、Dense Block堆叠、全连接输出分类概率
头部卷积池化降低分辨率,
中间多个dense block+transition layer堆叠,
池化+全连接输出。
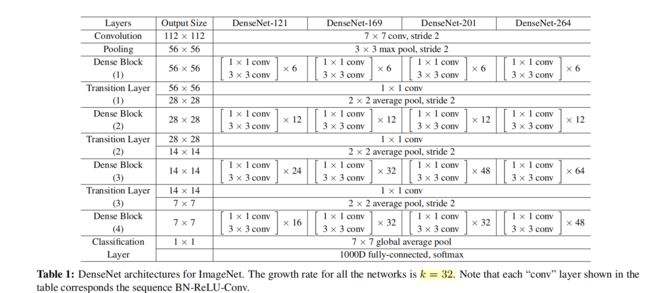
7×7的感受野比较大
进入一系列block堆叠的时候,都是56×56
三、实验结果及分析
① 在3个数据集(Cifar-10/100,SVHN数据)上进行对比实验
C10+表示基于数据增强
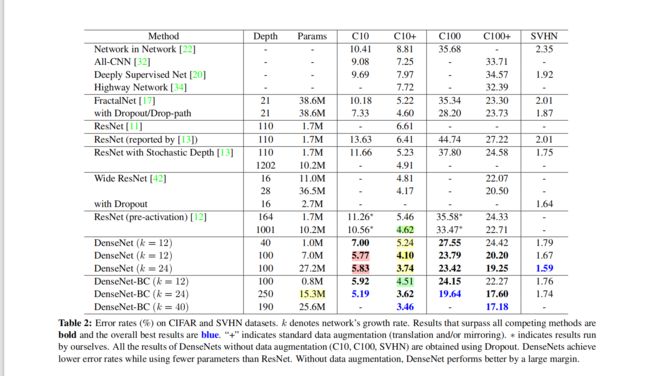
结论:
- DenseNet-BC-190获得最优成绩
- DenseNet性能随k和L增大而提升
- DenseNet-BC-250省参数,仅15.3M
- 粉色看出过拟合,可用数据增强
- 绿色看出省参数,十分之一不到
② 在Cifar-10数据集上分析DenseNet各种方案的结果

最左边的图:
DenseNet-C优于DenseNet
DenseNet-B优于DenseNet-C
DenseNet-BC优于DenseNet-B
右边两张图:对于ResNet
同样精度时,仅需ResNet的三分之一参数,
表明DenseNet更省参数,更高效
③ ImageNet-1K分类数据集

最左边的图:
结论:
- 10-crop均比single-crop精度高
- 网络越深、精度越高
右边两张图:
与ResNet对比精度与参数
3. 同参数,精度全面超越ResNet
4. 同精度,参数全面少于ResNet
④ 分析特征重要性

分析的是DenseNet-40,其中有三个Denseblock,
第一行表示DenseBlock前一层会传给后面所有层,
最后一列表示Transition layer与前面所有层的连接
结论:
- 网络层的权重,不仅关注上一层的特征图,还关注前面所有层的特征图。
- transition layer的权重均匀分布在各个layer的特征图。
- block2和3中,最上面那一行,对transition输出的特征的权重很低,DenseNet-BC正是压缩了这一部分(因为不太重要)
- block3中看到分类输出层对靠后的特征更关注,可能因为后面得到的是高级特征,更有分辨力。
四、论文总结
① 关键点、创新点
- 将捷径连接与特征复用思想结合,同时借鉴级联结构的思想,设计出稠密连接结构
- 针对稠密连接,提出DenseNet-BC形式,分别占block内部和transition部分采用1×1卷积进行参数量的控制,使模型紧凑
② 备用参考文献知识点
- 信息流通不顺畅时,普遍采用捷径连接来处理
as information about the input or gradient passes through many layers, it can vanish and “wash out” by the time it reaches the end (or beginning) of the network.
they create short paths from early layers to later layers.
(论文1的第二段)
-
采用捷径连接,便于信息流通,以及梯度传递,课可使模型便于训练
one big advantage of DenseNets is their improved flow of information and gradients throughout the network, which makes them easy to train.(论文1的第五段) -
稠密连接在小数据集上起到正则作用,减少过拟合。
we also observe that dense connections have a regularizing effect, which reduces over-fitting on tasks with smaller training set sizes.(论文1的第五段) -
ResNet的求和形式有缺点,会阻碍信息的流通。对要用拼接而不是求和时,可以引用这篇论文的这一点。
However, the identity function and the output of H` are combined by summation, which may impede the information flow in the network.(论文3的第二段)
五、研究思想
(1)short paths思想
深度神经网络中存在信息流通不畅问题——前向传播时输入数据消失、反向传播时梯度消失
应用 :
- Highway Net 带门控单元的short paths
- ResNet、随机深度的ResNet:在运算的部分,设置了一定的概率让它丢失掉,层数就减少了。
- FractalNet
(2)多级特征复用
当前的特征不仅会给下一层使用,还会给下下层……使用。
可以增强模型
应用:
- FCN: Fully Convolutional Networks
输出的score map由多级特征图共同生成 - 多尺度有向无环卷积神经网络:采用多个层的特征复用进行分类,提高分类精度
优点:不需要额外的计算量,可得到底层、中层和高层的特征来进行分类,使模型更鲁棒。
(3)结构类似的级联结构(第40篇参考文献)
前面神经元的输出会连到后面的所有神经元。类似于DenseNet的稠密连接。
资料推荐:详解DenseNet(密集连接的卷积网络)