机器学习之逻辑回归和支持向量机
逻辑回归 Logistic Regression
输出 Y=1 的对数几率是由输入 x 的线性函数表示的模型,这就是逻辑回归模型。
因此逻辑回归的思路是,先拟合决策边界(不局限于线性,还可以是多项式),再建立这个边界与分类的概率联系,从而得到了二分类情况下的概率。
从概率上讲,一件事发生的概率为 p p p的话,那么不发生的概率就是 1 − p 1-p 1−p,对于样本而言,属于第一类的概率符合这个理论,只不过这里的概率非0即1。我们定义这件事发生的几率,并给出表达
L o g i t ( p ) = p 1 − p Logit(p) = \frac{p}{1-p} Logit(p)=1−pp
ϕ ( z ) = 1 1 + e z \phi(z) = \frac{1}{1 + e^z} ϕ(z)=1+ez1
称之为 s i g m o i d sigmoid sigmoid函数
在线性感知器中,我们通过梯度下降算法来使得预测值与实际值的误差的平方和最小,来求得权重和阈值。而在逻辑斯蒂回归中所定义的代价函数就是使得该件事情发生的几率最大,也就是某个样本属于其真实标记样本的概率越大越好。这里我们使用梯度上升。
我们有最大似然函数
L ( ω ) = P ( y ∣ x ; ω ) = ∏ i = 1 n P ( y ( i ) ∣ x ( i ) ; ω ) = ( ϕ ( z ( i ) ) ) y ( i ) ( 1 − ϕ ( z ( i ) ) ) 1 − y ( i ) L(\omega) = P(y|x;\omega) = \prod_{i=1}^{n}P(y^{(i)}|x^{(i)};\omega) = (\phi(z^{(i)}))^{y^{(i)}}(1 - \phi(z^{(i)}))^{1-y^{(i)}} L(ω)=P(y∣x;ω)=i=1∏nP(y(i)∣x(i);ω)=(ϕ(z(i)))y(i)(1−ϕ(z(i)))1−y(i)
为了防止溢出取对数
l ( ω ) = L ( ω ) = P ( y ∣ x ; ω ) = ∑ i = 1 n ( y ( i ) l o g ( ϕ ( z ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − ϕ ( z ( i ) ) ) l(\omega) = L(\omega) = P(y|x;\omega) = \sum_{i=1}^{n}(y^{(i)}log(\phi(z^{(i)})) + (1-y^{(i)})log(1-\phi(z^{(i)})) l(ω)=L(ω)=P(y∣x;ω)=i=1∑n(y(i)log(ϕ(z(i)))+(1−y(i))log(1−ϕ(z(i)))
为了判断是否足够收敛,我们定义 l o s s loss loss
J ( ϕ ( z ) , y ; ω ) = { l o g ( ϕ ( z ) ) , y = 1 , l o g ( 1 − ϕ ( z ) ) , y = 0. J(\phi(z), y;\omega) = \left\{ \begin{array}{ll} log(\phi(z)), & y=1,\\ log(1-\phi(z)), & y=0. \\ \end{array} \right. J(ϕ(z),y;ω)={log(ϕ(z)),log(1−ϕ(z)),y=1,y=0.
式 ( 5 ) (5) (5)与式 ( 6 ) (6) (6)相等。
在进行了最初的计算之后我们需要对权重 W W W进行更新。
我们对似然函数求偏导数得到
∂ ∂ ω j l ( ω ) = ( y − ϕ ( z ) ) x j \frac{\partial}{\partial\omega_j}l(\omega) = (y - \phi(z))x_j ∂ωj∂l(ω)=(y−ϕ(z))xj
这便是梯度,更新后的 W W W为
W = W − 1 m ( D a t a T ⋅ ( R e s u l t − ϕ ( z ) ) ) W = W - \frac{1}{m}(Data^T \cdot (Result - \phi(z))) W=W−m1(DataT⋅(Result−ϕ(z)))
添加正则化惩罚之后变为
J ( ω ) = l ( ω ) + λ 2 m ∣ ∣ ω ∣ ∣ 2 2 W = W − 1 m ( D a t a T ⋅ ( R e s u l t − ϕ ( z ) ) ) − λ m W J(\omega) = l(\omega) + \frac{\lambda}{2m}||\omega||_2^2 \\ W = W - \frac{1}{m}(Data^T \cdot (Result - \phi(z))) - \frac{\lambda}{m}W J(ω)=l(ω)+2mλ∣∣ω∣∣22W=W−m1(DataT⋅(Result−ϕ(z)))−mλW
以上所有均适用于
z = X T ⋅ W z = X^T \cdot W z=XT⋅W
支持向量机 SVM
支持向量机(Support Vector Machine, SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
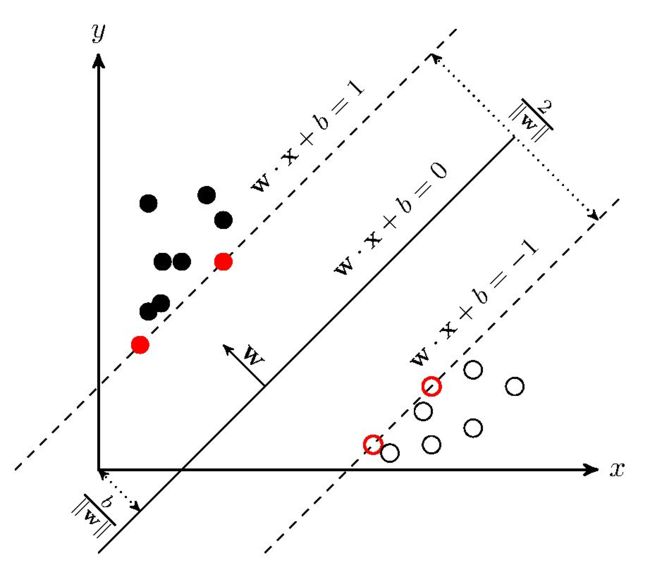
函数间隔 & 几何间隔
通过观察 ω T x + b \omega^Tx+b ωTx+b的符号与类标记y的符号是否一致可判断分类是否正确,即用 y ( ω T x + b ) y(\omega^Tx+b) y(ωTx+b)的正负性来判定或表示分类的正确性
定义函数间隔为 γ ^ = y ( ω T x + b ) = y f ( x ) \hat{\gamma}=y(\omega^Tx+b)=yf(x) γ^=y(ωTx+b)=yf(x)
事实上,我们可以对法向量w加些约束条件,从而引出真正定义点到超平面的距离:几何间隔
γ = ω T x + b ∣ ∣ ω ∣ ∣ \gamma = \frac{\omega^Tx+b}{||\omega||} γ=∣∣ω∣∣ωTx+b
最大间隔
令 γ \gamma γ最大,相当于最大化 1 ∣ ∣ ω ∣ ∣ \frac{1}{||\omega||} ∣∣ω∣∣1,相当于最小化 1 2 ∣ ∣ ω ∣ ∣ 2 \frac{1}{2}{||\omega||}^2 21∣∣ω∣∣2。
条件为 y i ( ω T x i + b ) ≥ 1 , ∀ i ∈ [ 1 , n ] y_i(\omega^Tx_i+b)\ge1, \forall i\in[1, n] yi(ωTxi+b)≥1,∀i∈[1,n],即标记为-1的点要在 ω T x + b = − 1 \omega^Tx+b=-1 ωTx+b=−1以外,反之标记为1的点要在 ω T x + b = 1 \omega^Tx+b=1 ωTx+b=1以外。
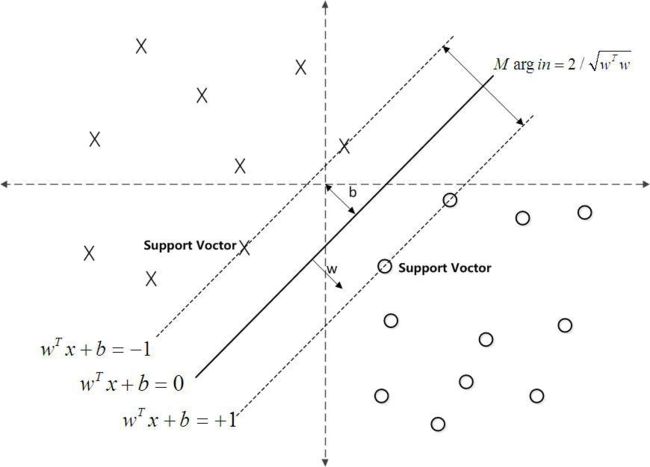
松弛变量
解决过拟合的办法是为SVM引入了松弛变量 ξ ξ ξ(slack variable),将SVM公式的约束条件改为:
y i ( ω T x i + b ) ≥ 1 − ξ i , ∀ i ∈ [ 1 , n ] y_i(\omega^Tx_i+b)\ge1-\xi_i, \forall i\in[1, n] yi(ωTxi+b)≥1−ξi,∀i∈[1,n]
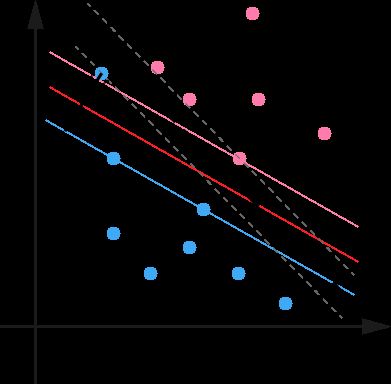
从图可以看到,引入松弛变量使SVM能够容忍异常点的存在。为什么?因为引入松弛变量后,所有点到超平面的距离约束不需要大于等于1了,而是大于0.8就行了(如果ξ=0.2的话),那么异常点就可以不是支持向量了,它就作为一个普通的点存在,我们的支持向量和超平面都不会受到它的影响。
如果我们运行 ξ i \xi_i ξi任意大的话,那任意的超平面都是符合条件的了。所以,我们在原来的目标函数后面加上一项,使得这些 ξ i \xi_i ξi的总和也要最小:
min ( 1 2 ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 n ξ i ) \min(\frac{1}{2}{||\omega||}^2+C\sum_{i=1}^n{\xi_i}) min(21∣∣ω∣∣2+Ci=1∑nξi)
其中 C C C是一个参数,用于控制目标函数中两项(“寻找 margin 最大的超平面”和“保证数据点偏差量最小”)之间的权重。注意,其中 ξ i \xi_i ξi是需要优化的变量(之一),而 C C C是一个事先确定好的常量。
核函数
特征空间的隐式映射:Kernel
在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。如图所示,一堆数据在二维空间无法划分,从而映射到三维空间里划分:
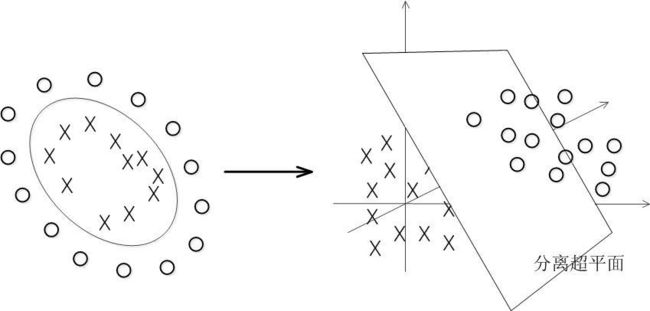
建立非线性学习器分为两步:
- 首先使用一个非线性映射将数据变换到一个特征空间F
- 然后在特征空间使用线性学习器分类
计算两个向量在隐式映射过后的空间中的内积的函数叫做核函数 (Kernel Function)
- 实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去
- 但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会太高
- 核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。