学习汇报汇报
学习内容:
1、 DefectGAN: Weakly-Supervised Defect Detection using Generative Adversarial Network(GAN的半监督方法进行缺陷检测)
2、 Dual Attention Network for Scene Segmentation(一种引入时间注意力机制和空间注意力机制的实例分割方法)
3、 PGA-Net: Pyramid Feature Fusion and Global Context Attention Network for Automated Surface Defect Detection(在金字塔特征融合五种分辨率特征图的基础上,加上了注意力机制,进行特征融合,在NEU,MT,Road上进行测试)
4、 在之前的瓷砖数据集上,改进了评价指标,在之前Unet的基础上增加了注意力机制,AttU_Net,对于之前收敛速度慢的情况,可能是只训练了50epoch,显示收敛的慢,之前的U_Net也是在50epoch左右收敛。后面会增加一下,然后尝试一下,把RNN用在U_Net的skip融合上。
5、下载了DeepCrack数据集,由于数据集数量少,也是采用图像增强的技术扩展,模型采用ResU_Net 进行预测。
目录
- 学习内容:
- 一、DefectGAN: Weakly-Supervised Defect Detection using Generative Adversarial Network
-
- 1.1 Abstract
- 1.2 INTRODUCTION
- 1.3 METHOD
-
- 1.3.1 Negative-to-Positive Translation
- 1.3.2 Architecture
- 1.3.3 Loss Function
- 1.4 EXPERIMENTS
-
- 1.4.1 Evaluation Metrics
- 1.4.2 Results and Analysis
- 二、Dual Attention Network for Scene Segmentation
-
- 2.1 Abstract
- 2.2 Introduction
- 2.3 Dual Attention Network
-
- 2.3.1 Overiew
- 2.3.2 Position Attention Module
- 2.3.3 Channel Attention Module
- 2.3.4 Attention Module Embedding with Networks
- 2.4 Experiments
-
- 2.4.1 Datasets and Implementation Details
- 2.4.2 Results on Cityscapes Dataset
- 2.4.3 Results on PASCAL VOC 2012 Dataset
- 2.4.4 Results on PASCAL Context Dataset
- 2.5 Conclusion
- 3 PGA-Net: Pyramid Feature Fusion and Global Context Attention Network for Automated Surface Defect Detection
-
- 3.1 Abstract
- 3.2 INTRODUCTION
- 3.3 RELATED WORKS
- 3.4 METHODOLOGY AND DESIGN
-
- 3.4.1 System Overview
- 3.4.2 Multilevel Features Extraction Module
- 3.4.3 Pyramid Feature Fusion Module
- 3.4.4 Global Context Attention Module
- 3.4.5 Boundary Refinement Block
- 3.4.6 Deep Supervision
- 3.5 EXPERIMENTS AND RESULTS
-
- 3.5.1 Datasets
- 3.5.2 Evaluation Metrics
- 3.5 CONCLUSION
- 4 MT数据集的Att_Unet
- 5 DeepCrack数据集
提示:以下是本篇文章正文内容,下面案例可供参考
一、DefectGAN: Weakly-Supervised Defect Detection using Generative Adversarial Network
使用生成对抗网络的弱监督缺陷检测
1.1 Abstract
目前基于深度学习的一般对象分割方法需要大量的区域级人工标注。相反,我们提出了在弱监督学习中检测缺陷的DefectGAN,这需要很少的人工注释。在实际应用中,对训练数据集中的图像只进行了正面和负面的标注。尽管是在图像级别而不是区域级别的标签上进行训练,DefectGAN在定位缺陷区域方面有显著的能力。
1.2 INTRODUCTION
为了避免区域级人工标注的严重压力,提出了一些基于弱监督学习的人工标注方法。然而,GAN是用多个图像对进行训练的,因此需要人为地为每个阳性样本生成负图像。然后将生成的图像和对应的正样本标记为一对。使各种缺陷尽可能真实地生成是一种困难而耗时的生成算法,特别是后续研究的换向器气缸表面缺陷的生成。
我们提出了另一种弱监督的方法DefectGAN,它从收集到的图像中学习仅仅标记为两类,消极和积极的图像。我们避免生成成对的图像。主要工作如下:
- 能够通过学习图像级别而不是区域级别的注释来检测缺陷区域。DefectGAN通过训练标有这两个类的图像,学习将图像从NG域(负)转换为P域(正)。缺陷区域可以通过简单地比较由DefectGAN生成的阴性和阳性图像来定位。
- 与监督学习方法相比,有可比性和可能更好的性能。虽然该方法是弱监督的,但在CCSD-NL数据集上,其精度与SegNet方法相当,分别为81.05%和82.33%。此外,在DAGM 2007上,该方法的视觉效果优于SegNet方法。
- DefectGAN能够检测一些不在训练数据中的缺陷类型。这意味着它有可能检测到一些看不见的缺陷。
1.3 METHOD
1.3.1 Negative-to-Positive Translation
在训练阶段,我们提出的DefectGAN通过训练包含工业现场正、负样本的数据集来学习负图像和正图像之间的映射关系。然后在测试阶段,将负向图像输入训练良好的DefectGAN模型,生成相应的正向图像,然后进行简单的后处理,将被测试的负向图像与生成的正向图像进行灰度比较,定位缺陷区域。
我们使用CycleGAN[18]来学习这两个域NG(负)和P(正)给定的训练样本之间的映射
我们引入了两个从负到正的映射的生成器:G1:NG→P和一个逆映射:G2:P→NG,如下图:

另外,我们介绍了两种对抗性鉴别器 :(1)DNG,旨在区分{ng}和{G2§}和(2)DP,旨在区分{p}和{G1(NG)}。经过对抗性训练过程后,不仅G1(NG)中的图像分布与P的分布难以区分,而且DefectGAN还可以实现G2(G1(NG))≈NG,称为循环一致性。
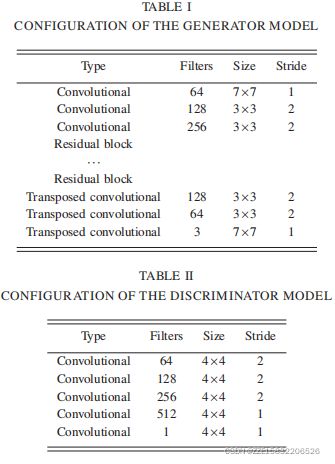
1.3.2 Architecture
下表分别显示了发生器和鉴别器的体系结构。生成器网络包含几个卷积层、几个残差块和几个转置的卷积层。我们对256块×256张训练图像使用了9个残余块。每个残差块包括两个相同的卷积层,具有3个×3内核,1个步幅和256个滤波器。在生成器中每个卷积层后,采用实例归一化和ReLU。
对于鉴别器网络,在最后一层后进行一次卷积,得到一维输出。在鉴别器中采用斜率为0.2的泄漏ReLU代替ReLU,避免了梯度消失的问题。
1.3.3 Loss Function
我们所采用的总损失由两种类型的损失组成:(1)对抗性损失和(2)周期一致性损失。
(1)对抗性损失计算了映射g1和g2的对抗性损失。对于从负g1到正的映射:NG→P及其鉴别器DP,对抗性损失表示为:
其中Ep∼§[logDP§]表示输入属于无缺陷域p数据(p)的无缺陷图像p)和Eng∼pdata(ng)[log(1−DP(G1(ng)))的鉴别器DP输出结果的平均值表示输入属于缺陷域p数据(ng)的缺陷图像ng的结果1减去鉴别器DNG输出的结果的平均值。生成器G1试图生成与域P的图像相似的图像,从而迫使DP(G1(ng))接近1并最小化LGAN(G1、Dp、NG、P)。同时,鉴别器DP试图区分生成的图像G1(ng)和真实图像p,这迫使DP(G1(ng))接近0,并最大化LGAN(G1、DP、NG、P)。这种优化被描述maxDPminG1LGAN(G1、DP、NG、P)。对于另一个映射G2:P→NG及其鉴别器DNG,对抗性损失与描述为maxDNGminG2LGAN(G2、Dng、P、NG)的优化相似。
(2)Cycle Consistency Loss
对于发电机G1和G2,我们希望将发电机G1产生的G1(ng)输入另一个发电机G2后,输出的G2(G1(ng)与ng相似,即ng→G1(ng)→G2(G1(ng))≈ng。同样,另一个周期应该实现相似性:p→G2§→G1(G2§)≈p。特别是,使用L1范数来衡量周期一致性损失,表示为:
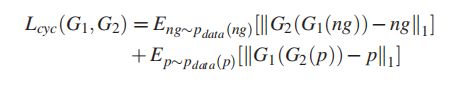
(3) The Total Loss
总损失包括两个gan的对抗性损失和循环一致性损失: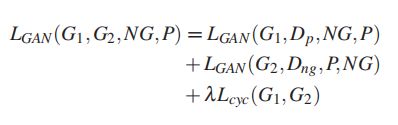
值得注意的是,通过循环一致性损失,将负图像和正图像的共同特征保存为。经过彻底的训练,使用从负到正的映射,即生成器G1在测试阶段生成正图像。由DefectGAN(G1)生成的检测到的负图像和相应的正图像的一些例子如图3、图4和图5所示。在比较配对图像后,我们发现视觉上的灰度、纹理和边缘特征只存在缺陷区域和边缘特征,其他区域几乎没有差异。在这里,我们通过简单地计算灰度水平上的每个像素的差值,输出一个相同大小的新图像。该值越小,与缺陷的关系就越小。因此,缺陷区域在输出图像中被突出显示。经过简单的去噪和膨胀处理后,缺陷的定位如图所示。


1.4 EXPERIMENTS
本文验证了DefectGAN对工件和纹理两种产品缺陷检测的有效性。前者来自数据集CCSDNL,后者来自数据集DAGM2007[21]。然后将我们的方法与基于监督和弱监督学习的SegNet[22]和CAM[23]两种方法进行了比较。
1.4.1 Evaluation Metrics
(1)mIoU
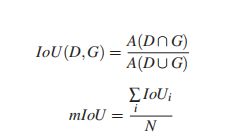
(2)ttest,ttest是评估模型时间成本的另一个重要指标。将图像i的测试时间表示为ti,然后计算整个测试集的平均测试时间为ttest:

1.4.2 Results and Analysis

二、Dual Attention Network for Scene Segmentation
2.1 Abstract
在本文中,我们通过捕获基于自注意机制的丰富的上下文依赖关系来解决场景分割任务。与以往通过多尺度特征融合来捕获上下文的工作不同,我们提出了一个双注意网络(DANet)来自适应地集成局部特征与其全局依赖性。具体来说,我们在扩展的FCN之上附加了两种类型的注意模块,它们分别模拟了空间维度和通道维度上的语义相互依赖关系。位置注意模块通过对所有位置的特征进行加权和,有选择性地聚合每个位置的特征。相似的特征将会相互关联,而不管它们之间的距离如何。同时,信道注意模块通过整合所有通道图之间的相关特征,选择性地强调相互依赖的通道图。我们总结了这两个注意模块的输出,以进一步改进特征表示,从而有助于更精确的分割结果。我们在三个具有挑战性的场景分割数据集上实现了新的分割性能,即 Cityscapes, PASCAL Context and COCO。
2.2 Introduction
场景分割是一个基本的、具有挑战性的问题,其目标是将场景图像分割和解析成与语义类别相关联的不同图像区域,包括东西(如天空、道路、草地)和离散物体(如人、汽车、自行车)。为了有效地完成场景分割的任务,我们需要区分一些令人混淆的类别,并考虑到不同外观的对象。例如,“田野”和“草”的区域往往难以区分,而“汽车”的物体可能经常受到鳞片、遮挡和照明的影响。因此,有必要提高特征表示对像素级识别的识别能力。
我们提出了一个新的框架,称为双注意网络(DANet),用于自然场景图像的分割,如图2.它引入了一种自我注意机制来分别捕获空间维度和通道维度中的特征依赖性。具体来说,我们在扩展的FCN上附加了两个平行的注意模块。一个是位置注意模块,另一个是通道注意模块。对于位置注意模块,我们引入了自我注意机制来捕捉特征图中任意两个位置之间的空间依赖关系。对于某一位置的特征,通过加权求和对所有位置的特征进行聚合来进行更新,其中权重由对应两个位置之间的特征相似性决定。也就是说,任何两个具有相似特征的位置都可以有相互的改进,而不管它们在空间维度上的距离如何。对于信道注意模块,我们使用类似的自注意机制来捕获任意两个通道映射之间的通道依赖关系,并使用所有通道的加权和更新每个通道映射。

需要注意的是,在处理复杂多样的场景时,我们的方法比以前的方法更有效和灵活。以图中的街景为例。首先,由于灯光和视野的原因,一些“人”和“红绿灯”和“红绿灯”是不显眼或不完整的物体。如果探索简单的上下文嵌入,来自占主导地位的突出对象(如汽车,建筑)的上下文将会损害这些不显眼的对象标签。相比之下,我们的注意力模型选择性地聚集了不明显物体的相似特征,以突出其特征表征,避免了显著物体的影响。第二,“车”和“人”的尺度是多样化的,识别这些不同的物体需要在不同的尺度上的上下文信息。在不同的尺度上,应该被平等地对待,以表示相同的语义。我们的注意机制模型只是为了从全局的角度自适应地整合任意尺度的相似特征,这可以在一定程度上解决上述问题。第三,我们明确地考虑了空间和通道关系,以便场景理解可以从长期依赖中获益。
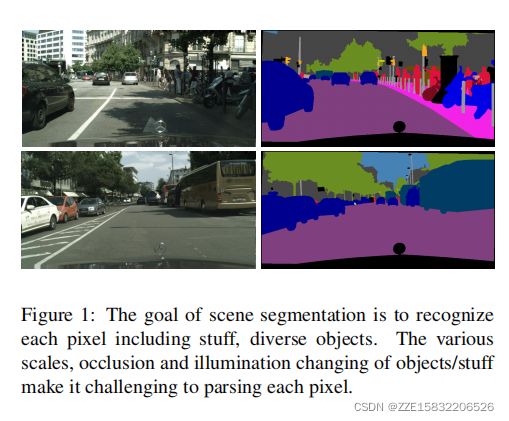
2.3 Dual Attention Network
2.3.1 Overiew
问题1:给定一个场景分割的图片,东西或物体,在尺度、照明和视图上都是不同的。由于卷积操作会导致一个局部的接受域,因此与具有相同标签的像素所对应的特征可能会有一些差异。
解决:为了解决这个问题,我们通过建立特征与关注之间的关联来探索全局上下文信息机制,该方法可以自适应地聚合随机化的上下文信息,从而提高了场景分割的特征表示能力。
我们设计了两种类型的注意模块,在扩张残差网络生成的局部特征上绘制全局上下文,从而获得更好的像素级预测的特征表示。我们采用了一个预先训练好的残余网络,以扩张策略作为骨干。需要注意的是,我们在后两个ResNet块中删除了降采样操作,并采用了扩展卷积,从而将动态特征图的大小扩大到输入图像的1/8。它保留了更多的细节,而不需要添加额外的参数。然后将扩张残差网络的特征输入两个平行的注意模块。以图的上部的空间注意模块为例,我们首先应用卷积层得到降维的特征。然后,我们将这些特征导入位置注意模块,并通过以下三个步骤生成空间远程上下文信息的新特征。第一步是生成一个空间注意矩阵,用来模拟特征的任意两个像素之间的空间关系。接下来,我们在注意矩阵和原始特征之间进行矩阵乘法。第三,我们对上述相乘法的结果矩阵和原始特征进行元素和运算,以获得反映上下文的最终表示。

2.3.2 Position Attention Module
我们首先将其输入一个卷积层,分别生成两个新的特征图B和C,其中{B,C}∈RC×H×W。然后我们将它们重塑为RC×N,其中N=H×W是像素数。然后,我们在C和B的之间进行矩阵乘法,并应用一个softmax层来计算空间注意图S∈RN×N:
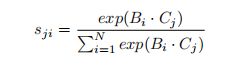
其中sji测量了第i个位置对第j个位置的影响。
同时,我们将特征A输入卷积层,生成一个新的特征图D∈RC×H×W,并将其重塑为RC×N。然后,我们在D和S的之间进行矩阵乘法,并将结果重塑为RC×H×W。最后,我们将其乘以尺度参数α,用特征a进行元素和运算,得到最终输出E∈RC×H×W如下:
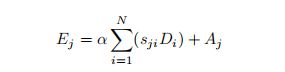
2.3.3 Channel Attention Module
通道注意模块的结构如图所示。与位置注意模块不同的是,我们从原始特征A∈RC×H×W直接计算出通道注意图X∈RC×C。具体来说,我们将A重塑为RC×N,然后在A和a的转座之间进行矩阵乘法。最后,我们应用softmax层获得通道注意图X∈RC×C:
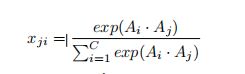
此外,我们在X和a的转座子之间进行矩阵乘法,并将它们的结果重塑为RC×H×W。然后我们将结果乘以一个尺度参数β,用a进行元素和运算,得到最终输出E∈RC×H×W:

我们在计算两个通道的关系处理之前不使用卷积层来嵌入特征,因为它可以保持不同通道映射之间的关系。此外,与最近通过全局池化或编码层来探索信道关系的工作不同,我们利用所有相应位置的空间信息来建模信道相关性。
2.3.4 Attention Module Embedding with Networks
为了充分利用长期上下文信息,我们聚合了这两个注意模块的特征。具体地说,我们将两个注意模块的输出转换为一个卷积层,并执行一个元素级和来完成特征融合。最后,按照卷积层生成最终的预测图。我们不采用级联操作,因为它需要更多的GPU内存。请注意,我们的注意力模块很简单,可以直接插入到现有的FCN管道中。它们不会增加太多的参数,但却有效地加强了特征表示。
2.4 Experiments
为了评价该方法,我们在 Cityscapes dataset、 PASCAL VOC2012、PASCAL Context dataset和COCO Stuff数据集上进行了综合实验。实验结果表明,DANet在三个数据集上都取得了最先进的性能.
2.4.1 Datasets and Implementation Details
Cityscapes:该数据集有从50个不同城市捕获的5000张图片。每幅图像有2048×1024像素,具有19个语义类的高质量像素级标签。训练集中有2979张图像,验证集有500张图像,测试集中有1525张图像。
PASCAL VOC 2012:该数据集有10,582张图像用于训练,1,449张图像用于验证,1,456张图像用于测试,其中涉及20个前景对象类和一个背景类。
PASCAL Context:该数据集为整个场景提供了详细的语义标签,其中包含4998张用于训练的图像和5105张用于测试的图像。我们用最常见的59个类和一个背景类别(总共60个类)来评估该方法。
2.4.2 Results on Cityscapes Dataset
与基于FCN(ResNet-50)的基本模型相比,使用位置注意模块在平均IoU中为75.74%,提高了5.71%。同时,单独使用通道上下文模块的性能比基线模块高出4.25%。当我们将这两个注意模块集成在一起时,性能进一步提高到76.34%。


位置注意模块(PAM)的效果如图4所示。使用位置注意模块,一些细节和对象边界更加清晰,如第一行的“极点”和第二行的“人行道”。对局部特征的选择性融合增强了对细节的识别能力。同时,图5表明,通过我们的频道注意模块(CAM),一些错误分类的类别现在被正确分类,如第一行和第三排的“公交车 ”。信道映射之间的选择性集成有助于捕获上下文信息。语义的一致性得到了明显的提高。
对于位置注意(PAM),整体自我注意图的大小为(H×W)×(H×W),这意味着对于图像中的每个特定点,都有一个对应的子注意图的大小为(H×W)。在图6,对于每个输入图像,我们选择两个点(标记为#1和#2),并分别在第2列和第3列中显示它们对应的子注意力图。我们观察到位置注意模块可以捕获清晰的语义相似性和随机关系。例如,在第一行中,红点#1被标记在一个建筑物上,它的注意力地图(在第2列中)突出显示了建筑物所在的大部分区域。此外,在子注意图中,边界是非常清晰的,即使其中一些边界是远离点#1。至于第二点,它的注意力地图集中在大多数被标记为“汽车”的位置上。在第二行中,全局特征内的“交通标志”和“人”也是如此,即使相应的像素数量更少。第三行是“植被”类和“人”类。特别是,第2点对附近的“骑手”类没有反应,但它对远处的“人”有反应。

2.4.3 Results on PASCAL VOC 2012 Dataset

2.4.4 Results on PASCAL Context Dataset
在本小节中,我们在帕斯卡上下文数据集上进行了实验,以进一步评估我们的方法的有效性。我们对pascalVOC2012数据集采用相同的训练和测试设置。帕斯卡尔上下文的定量结果如表6所示。 基本模型(简略的FCN-50)产生的平均IoU为44.3%。DANet-50将性能提高到50.1%。此外,通过深度预训练的网络ResNet101,我们的模型结果达到了平均IoU52.6%,大大优于以前的方法。

2.5 Conclusion
本文提出了一种用于场景分割的双注意网络(DANet),它利用自注意机制自适应地集成了局部语义特征。具体地说,我们引入了一个位置注意模块和一个通道注意模块来分别捕获空间维度和通道维度中的全局依赖性。消融实验表明,双注意模块能有效地捕获远程上下文信息,并得到更精确的分割结果。我们的注意力网络在四个场景分割数据集上取得了一致的出色表现,即城市景观、PascalVOC2012、Pascal上下文和COCO内容。
3 PGA-Net: Pyramid Feature Fusion and Global Context Attention Network for Automated Surface Defect Detection
3.1 Abstract
由于表面缺陷的复杂性,实现表面缺陷检测的全自动化仍然是一个挑战。虽然类间的缺陷包含相似的部分,但缺陷在外观上存在很大的差异。为了解决这些问题,本文提出了一种用于表面缺陷像素级检测的金字塔特征融合和全局上下文注意网络,称为PGA-Net。在该框架中,首先从主干网络中提取多尺度特征。然后利用金字塔特征融合模块,通过一些有效的密集跳跃连接,将这些特征融合成五种分辨率。最后,将全局上下文注意模块应用于相邻分辨率的融合特征图,使有效的信息从低分辨率融合特征图传播到高分辨率融合特征图。此外,在框架中加入边界细化块,细化缺陷的边界,改进预测结果。最终的预测是五种分辨率的融合特征图的融合。对4个真实缺陷数据集的评估结果表明,该方法在平均并集和平均像素精度上优于最新的方法(NEU-Seg:82.15%,DAGM2007:74.78%,MT_defect:71.31%,Road_defect:79.54%)。
3.2 INTRODUCTION
由于缺陷的复杂性,在自动缺陷检测任务中存在三个主要挑战:1)对比度较低:在工业生产中,灰尘的存在和光强的变化导致图像中缺陷与背景的对比度较低。图1(a)显示,红框中的缺陷几乎不可见,2)类内差异:与工业生产不同,其他应用中的缺陷形状不规则。如图1(b)所示,同类缺陷的多尺度差异很大;3)类间相似性:由于生产过程的不确定性,一些不同种类的缺陷差别不大。图1©显示了不同类型的缺陷(黄色和蓝色的方框),它们在纹理和灰度信息上非常相似。随着计算机视觉的快速发展,上述挑战在工业生产中正逐渐得到解决。

目前,基于CNN的检测方法在工业缺陷检测中得到了广泛的应用,它通过设计不同的网络模型来完成缺陷检测。对于低对比度,模型需要有效地利用对象的特征来区分对象和背景之间的区别。CNN不同层次的特征对物体有不同的敏感性。低级特征具有较高的分辨率,可以产生清晰而详细的边界,但上下文信息较少,而高级特征具有更抽象的语义信息,擅长进行类别分类,但形状和位置较弱。大多数的方法主要集中于从网络的深层中提取的高级特征。由于这些方法缺乏从浅层中提取的低层次特征(如边界、纹理和灰度信息),导致预测能力较差。
为了解决这些问题,本文提出了一个金字塔特征融合模块,该模块使用多尺度卷积(具有不同大小的内核)从最后一次卷积中对特征映射进行加权骨干网络每个阶段的层,以获得不同阶段的上下文信息,然后在每个阶段融合这些提取的相同分辨率的特征。这不仅避免了网格工件和信息的缺乏,而且充分提取了上下文信息。同时,使用与卷积核宽度相同大小的条不会带来大的计算。对于类间相似性,模型还需要实现对图像中不同类别对象(包括它们之间的连接和差异)的整体感知,实现每个像素需要分类在正确的位置。为了解决这一问题,我们在相邻的分辨率融合图中添加了全局上下文注意模块,从低分辨率融合图中提取全局上下文信息,然后对高分辨率融合图进行加权,以细化类别像素的空间位置。这不仅确保了信息的有效传播,而且也不会增加计算量。
本文五项主要贡献如下:
- 介绍了一种基于深度学习的表面缺陷检测方法,该方法在四种不同的表面缺陷数据集上取得了最先进的性能。
- 提出了一种基于像素级而不是图像级或区域级的表面缺陷检测方法。同时,该方法的目的是检测和区分不同类型的缺陷,而不仅仅是突出图像中的明显区域。
- 提供了一个金字塔特征融合模块,该模块将主干CNN各个阶段的多层次特征融合成多尺度分辨率,并分别学习这些分辨率。
- 设计了一个全局上下文注意模块,它嵌入到这些分辨率中,以确保从低分辨率到高分辨率的高效信息传输。
- 在该方法中加入了深度监督和边界细化技术来优化多分支网络,并在训练过程中加速收敛。最终的框架在四个缺陷数据集上取得了优异的性能。
3.3 RELATED WORKS
根据不同的表面缺陷检测任务,基于挖掘挖掘的方法可以分为图像级缺陷分类、区域级缺陷检测和像素级缺陷分割。
图像级缺陷分类:Masci等提出了一种用于钢缺陷分类的多尺度金字塔池化网络,但不要求所有图像的大小都相等。Natarajan等提出了一种通过迁移学习和支持向量机(SVM)分类器实现的灵活的多层深度特征提取方法,克服了小数据集导致的过拟合问题。He等人提出了一种用于特征提取的CNN半监督模型,并将表示特征输入到一个分类器中,用于钢表面缺陷的分类。然而,这些方法并不能给出缺陷的确切位置。同时,当图像中存在多种缺陷时,这些方法的精度也会降低。
区域级缺陷检查:He等提出了一种多层次特征融合网络,该网络将从骨干CNN中提取的多层次层次特征结合为一个分辨率,用于钢板缺陷检测。陈晓强等人提出了一种基于CNN的方法,通过CNN和朴素贝叶斯数据融合方案分析各个视频帧进行裂纹检测。周等人改进了一种深度卷积神经网络,并将一种新的锚定机制应用于为对象生成合适的候选框,并结合多层次特征构造超特征用于分裂销缺陷检查的鉴别。这些方法的缺点是只能通过一个或多个紧拟合的边界框提供一个粗糙的缺陷区域,而不能准确地描述缺陷的边界。
像素级缺陷分割:目前最有效的表面缺陷检测方法是基于全卷积网络。在[36]中提出了一种新的CNN,它以特征金字塔的方式从上到下集成上下文信息,用于路面裂缝检测。任等提出了一种基于深度学习的缺陷分类框架,然后通过训练后的分类器与原始图像进行卷积,获得像素级预测。杨等提出了一种基于多尺度特征聚类的全卷积的纹理表面缺陷检测方法。与基于图像级和区域级的方法相比,基于像素级的方法可以更准确地定位缺陷,准确地描述缺陷边界。然而,这些方法的结果也需要改进:1)这些方法大多集中于高级特征,而忽略了低级特征信息的重要性。同时,输出只有单边预测,检测结果较差。2)这些方法部分采用多侧预测,然后将这些预测直接融合输出最终预测,缺乏不同分辨率特征图的内在关系。相反,我们提出了一个金字塔特征融合模块来充分利用不同层的特征信息。我们将这些特性融合成不同的分辨率,并采用全局上下文注意模块来逐步融合它们。
3.4 METHODOLOGY AND DESIGN
3.4.1 System Overview
本文将表面缺陷检测视为一项像素化的任务。该方法的结构包括五个主要部分:1)多层特征提取网络;2)金字塔特征融合模块;3)全局上下文注意模块;4)边界细化块;5)深度监督,如图所示。
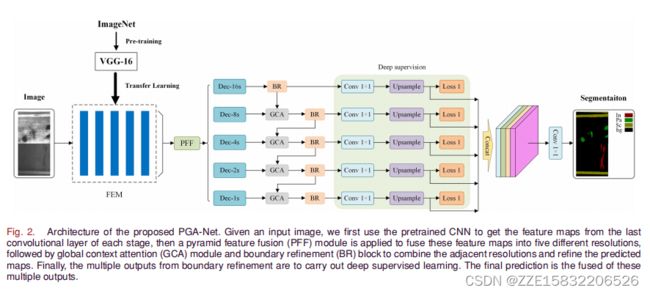
- 首先,将原始图像的批大小和相应的ground truth输入网络,通过卷积和池化操作的特征提取网络提取多层特征。该模型通过前向传播来学习训练样本各图像中的有效特征,并将这些特征逐一对应于ground truth,从而告知这些特征的属性。在前向传播过程中,利用输出特征映射和ground truth来计算损失。然后采用反向传播算法将损失最小化,实现了网络优化的目标。
- 接下来,将这些特征输入金字塔特征融合模块。通过卷积和反褶积(使用不同的内核和步幅)操作来调整维数,使融合后的特征映射具有相同的维数。通过一些密集的跳跃,同时连接并融合这些特性成5个分辨率。
- 然后,在这些分辨率中嵌入的全局上下文注意力机制,以允许有效的信息从低分辨率传播到高分辨率。每个全局上下文关注的输出之后都是边界细化。调整每个分辨率的尺寸大小,使其与原始图像相同,从而生成预测贴图。.
- 最后,将这些预测图进行融合,生成最终的预测。
3.4.2 Multilevel Features Extraction Module
本文在使用ImageNet数据集预训练的VGG-16模型上构建了深度特征提取模块(FEM),提取多层特征进行表面缺陷检测。有限元法包括五个块,这些块提取不同的外观信息,从浅细层(block_1和block_2)到深粗层(block_4和block_5)。每个块由卷积层、修正的线性单元激活函数(ReLU)、批归一化和除最后一个块外的最大池化层组成。有限元法的细节见表,所有这些层在反向传播过程中都通过随机梯度下降进行优化,以最小化预测和ground truth之间的差异。

3.4.3 Pyramid Feature Fusion Module
本文提出了金字塔特征融合(PFF)模块,如图所示,
 可分为三个步骤:第一,输入大小为W*H的图片,并通过FEM模块在不同的阶段生成多级特征PFF模块获得每个阶段的最后一层特征:conv1_2、conv2_2、conv3_3、conv4_3和conv5_3。为简单起见,这五个特征可以用特征集F:f=(f1、f2、f3、f4、f5)表示,其中f1表示conv1_2特征等等。第二,通过加权多尺度感受域生成多上下文信息,同时将该信息映射到5个不同分辨率的特征图:Tn=(W/2n,H/2n),其中n=(0,1,2,3,4)、W和H分别表示输入图像的宽度和高度。对于f1(分辨率R1=T0),该模块通过一堆卷积层将其缩小到5个分辨率,输出特征映射Yi1如下:
可分为三个步骤:第一,输入大小为W*H的图片,并通过FEM模块在不同的阶段生成多级特征PFF模块获得每个阶段的最后一层特征:conv1_2、conv2_2、conv3_3、conv4_3和conv5_3。为简单起见,这五个特征可以用特征集F:f=(f1、f2、f3、f4、f5)表示,其中f1表示conv1_2特征等等。第二,通过加权多尺度感受域生成多上下文信息,同时将该信息映射到5个不同分辨率的特征图:Tn=(W/2n,H/2n),其中n=(0,1,2,3,4)、W和H分别表示输入图像的宽度和高度。对于f1(分辨率R1=T0),该模块通过一堆卷积层将其缩小到5个分辨率,输出特征映射Yi1如下:

σ指ReLU激活,down-scale()表示通过Wk×k(核大小为k×k,步幅s=k)缩小特征图f1,b表示偏差,*表示卷积。
对于f5(分辨率R5=T4),模块将其上采样为5个分辨率下,输出特征映射Yi5如下:
![]() upsample()是指在训练过程中学习到的参数ψ进行反褶积。对于f2、f3和f4的分辨率在t0和t4之间,模型使用down-scale()和upsample()的组合将它们调整为5个分辨率,输出特征映射Yil如下:
upsample()是指在训练过程中学习到的参数ψ进行反褶积。对于f2、f3和f4的分辨率在t0和t4之间,模型使用down-scale()和upsample()的组合将它们调整为5个分辨率,输出特征映射Yil如下:![]()
最后,将输出中维度相同的特征融合,生成最后5个融合特征图。这五个融合的特征可以被定义为

在PFF中定义的所有卷积层之后都是ReLU激活和批处理归一化,这些参数都是可训练的,如表二所示。通过这种方法,该模型有效地从CNN的不同阶段获取多尺度上下文信息,实现了对对象的整体感知。

3.4.4 Global Context Attention Module
由PFF生成的不同分辨率的最终融合特征图包含了各种视觉上下文信息,其中的每一个都可以用来产生结果预测。一种方法是利用双线性上样本将这些融合的特征放大到与原始图像相同的维度,然后通过卷积层将它们的通道改变为类数来预测分割结果。然而,这些方法的缺点是:1)它们缺乏不同分辨率预测之间的内部关系信息,2)直接使用具有大核的双线性上样本可能会导致一些详细信息的缺失,且参数是不可训练的。其他U型模型,在解码过程中逐步将从低分辨率到高分辨率的相邻特征图结合起来。但是,这些方法也存在两个缺点:1)解码过程中相邻特征图的组合类型过于单一,缺乏多样化的表示,2)缺乏来自低分辨率(高级)的全局上下文信息,可以提高解码过程中的高分辨率(低级别)特征图。

为了解决上述问题,我们提出了一个全局上下文注意模块,该模块包括两个阶段:
第一阶段:采用3×3卷积法调整高分辨率和低分辨率融合特征图的信道尺寸,然后通过全局池化到低分辨率,获得全局上下文,然后与高分辨率特征图相乘。输出的fs1如下:
![]()
其中x和*分别表示元素向乘法和卷积,G(·)表示全局池化操作,σ表示ReLU激活,fh和fl表示高分辨率和低分辨率的融合特征图,W3×3表示可训练参数,b表示偏差。
第二阶段:将低分辨率的融合特征图以高分辨率上采样到相同的维度,然后加入fs1。第二阶段fs2的输出如下:
![]()
,其中上样本(;ψ)是指在训练过程中学习到的参数ψ的反褶积,⊕是指元素级加法。
3.4.5 Boundary Refinement Block
在本文中,我们添加了边界细化块,以进一步提高检测精度,如图4(b).所示边界细化视为残差结构,输出细化评分图S˜如下:
![]()
S和R(·)分别表示粗评分图和残差分支,*表示卷积,σ为ReLU激活,W1×1表示可训练参数,+为跨通道连接,b表示偏差。
3.4.6 Deep Supervision
虽然充分利用了多级特性,但参数的装载量也明显增加了,这可能会带来额外的优化难度。为了解决这一问题,我们在模型中加入了深度监督,旨在简化训练过程,加速网络模型的优化。由PFF模块在每个分辨率下生成的融合特征图可以单独进行裂纹预测。我们在上述5个分辨率融合的ground truth中添加一个每像素的损失(交叉熵)。

其中,Ti和Pi分别表示第i幅图像的ground truth和预测概率,N表示批处理大小,在测试阶段,将五个分支产生的预测结果进行融合,输出检测结果。
3.5 EXPERIMENTS AND RESULTS
3.5.1 Datasets
1)数据集描述:本文选取4个表面缺陷数据集,包括NEU-DET缺陷数据集、DAGM2007缺陷数据集、道路缺陷数据集来验证和评估该方法的适用性和通用性。
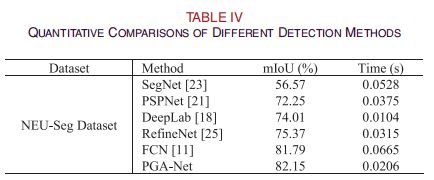
NEU-Seg数据集:NEU-Seg缺陷数据集是[51]收集的标准化高质量数据库,旨在解决热轧钢条的自动识别问题。该数据集包括来自带状钢板的六类表面缺陷,包括补片、裂纹、凹坑表面、包容、划痕和卷入比例。每个原始图像的分辨率为200×200,每个类包含300张带有紧密匹配的边界框注释的图像。然而,为了实现像素级表面缺陷检测任务,这种形式的注释并不满足CNN模型的训练。在这项工作中,我们选择了三个典型的缺陷(包含、补丁和划痕),并通过开放注释工具LabelMe进行像素级注释。这个数据集被命名为NEU-Seg数据集。由于热轧板情况的复杂性,类内缺陷的外观存在较大差异,而类间缺陷的部件相似,与背景的对比度较低。这些因素给热轧带钢表面缺陷的检测带来了巨大的挑战。图5为部分NEU-Seg原始图像的ground truth。

DAGM2007数据集:这个由人工生成的数据集[47]表示在纹理背景下的缺陷,非常接近现实世界。该数据集包含许多类别的缺陷,每个原始图像的分辨率为512×512。在DAGM2007的标签图像中,缺陷区域大致被椭圆覆盖。在本实验中,我们选择了六种类型的缺陷并重新定义了原始标签(我们没有改变原始缺陷区域的大小,只是改变了标签图像中的索引),新标签图像中的不同索引代表了不同的类别。图6为DAGM2007数据集的部分缺陷图像和相应的ground truth。

MT缺陷数据集:磁贴缺陷数据集,包含1344张缺陷图像,每个原始缺陷图像对应一个像素级标签。MT数据集包括五种类型的缺陷:不均匀、磨损、裂纹、吸孔和断裂,所有这些缺陷图像都具有不同的分辨率。这些缺陷图像大多包含一系列的噪声,如缺陷形状的多样性、纹理的复杂性和光照强度的变化等,所有这些因素都给检测带来了巨大的挑战。在本实验中,我们检测了磁性砖缺陷数据集的五种类型的缺陷(气孔、裂纹、断裂、断裂和不均匀)。图7显示了部分原始缺陷图像和相应的ground truth。

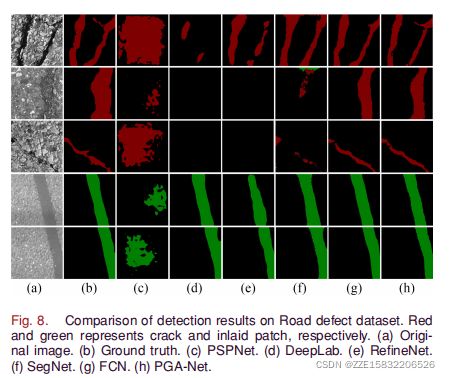
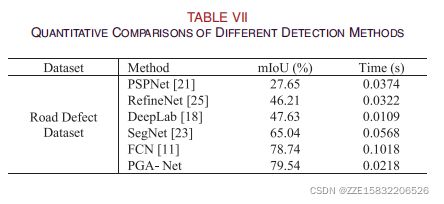
道路缺陷数据集:此数据集包含两个类(裂纹、嵌块)。破解图像的数量为500张,大小约为2000×1500像素,由[36]收集。我们通过CCD收集的嵌式贴片图像包含800张图像,大小约为3000×2000。每个缺陷图像对应于一个具有不同索引的像素级标签。
3.5.2 Evaluation Metrics
与其他分割方法相比,采用平均交叉过并集(mIoU)来进行预测结果的评价。其数学定义如[11]所示。我们还使用了在这个实验中处理每个图像的平均运行时间来显示该方法的实时性能。


3.5 CONCLUSION
本文提出了一种用于表面缺陷检测的自动缺陷检测网络。在该框架中,利用特征提取模块从缺陷图像中提取多层特征。引入了金字塔特征融合模块,将这些多层特征融合成不同的分辨率。全局上下文注意模块使有效的信息从低分辨率的融合特征图传播到高分辨率的融合特征图。在框架中添加了边界细化块来细化对象的边界预测。在框架中应用深度监督,加快网络优化过程。
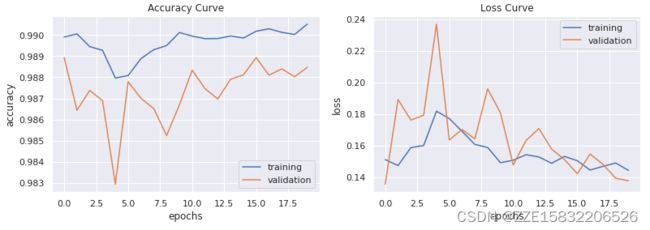
4 MT数据集的Att_Unet
训练图像:只有50epochs

用原始U-Net训练图像:

也是在50epoch左右收敛。

对于单个图片效果的话,对于类似缺陷的干扰识别不明显。
5 DeepCrack数据集
部分Crack图片的图片和Ground truth如下:

训练过程图像:
验证集的结果:

测试集的结果:
