动手学数据分析Task4数据可视化
复习:回顾学习完第一章,我们对泰坦尼克号数据有了基本的了解,也学到了一些基本的统计方法,第二章中我们学习了数据的清理和重构,使得数据更加的易于理解;今天我们要学习的是第二章第三节:数据可视化,主要给大家介绍一下Python数据可视化库Matplotlib,在本章学习中,你也许会觉得数据很有趣。在打比赛的过程中,数据可视化可以让我们更好的看到每一个关键步骤的结果如何,可以用来优化方案,是一个很有用的技巧。
目录
第二章:数据可视化
2.7 如何让人一眼看懂你的数据?
2.7.1 任务一:跟着书本第九章,了解matplotlib,自己创建一个数据项,对其进行基本可视化
2.7.2 任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)
2.7.3 任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)
2.7.4 任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
2.7.5 任务五:可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
2.7.6 任务六:可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
2.7.7 任务七:可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
第二章:数据可视化
开始之前,导入numpy、pandas以及matplotlib包和数据:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
result = pd.read_csv('./result.csv')2.7 如何让人一眼看懂你的数据?
《Python for Data Analysis》第九章
2.7.1 任务一:跟着书本第九章,了解matplotlib,自己创建一个数据项,对其进行基本可视化
plt.plot([1, 2, 3, 4], [10, 20, 25, 30], color='lightblue', linewidth=3)
plt.xlim(0.5, 4.5)
plt.show()输出:

【思考】最基本的可视化图案有哪些?分别适用于那些场景?(比如折线图适合可视化某个属性值随时间变化的走势)
1. 可视化图:
- line折线图:可以看出数据随着某个变量的变化趋势,默认情况下参数 kind="line" 表示图的类型为折线图。
- hist直方图:用于概率分布,它显示了一组数值序列在给定的数值范围内出现的概率。
- bar柱状图:用于展示各个类别的频数和数据的对比,通过柱形的高低来表达数据的大小。
- box箱型图:可以展示出分位数,具体包括上四分位数、下四分位数、中位数以及上下5%的极值。如果想要画出箱线图,可以将参数 kind 设置为 box。
- scatter散点图:可以探索变量之间的关系。将参数 kind 设置为 scatter,同时需要指定 x 和 y。
- pie饼图:用于不同分类的数据占总体的比例情况。
- kde密度图:核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
- area面积图:面积图又称区域图,是将折线图与坐标轴之间的区域使用颜色填充,填充颜色可以很好地突出趋势信息,一般颜色带有透明度会更合适于观察不同序列之间的重叠关系。
来源:一文掌握Pandas可视化图表_简说Python的博客-CSDN博客
Seaborn入门:详解kdeplot和distplot_Python中文社区-CSDN博客
2. 中文显示问题
plt.rcParams["font.family"]="SimHei"加入代码后中文能正确显示,“SimHei”代表中文黑体。除了字体设置还有以下属性:
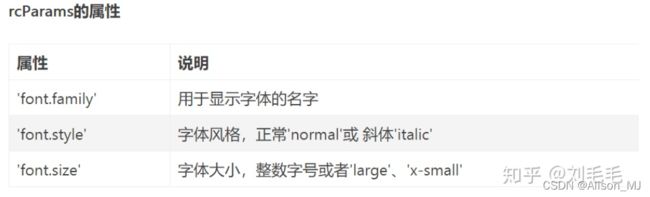
字体样式:
来源:matplotlib.pyplot的使用总结大全(入门加进阶) - 知乎
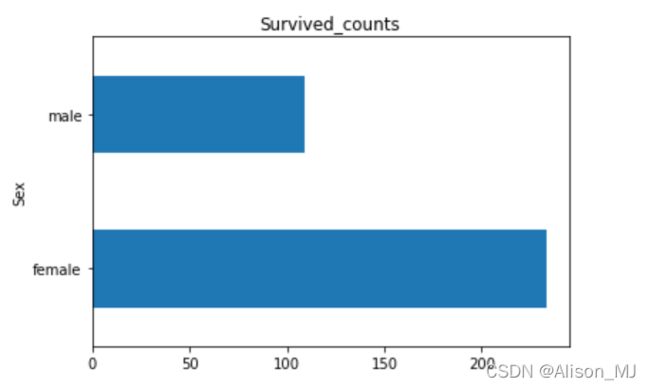
2.7.2 任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)
result['Survived'].groupby(result['Sex']).sum().plot(kind='barh')
plt.title('Survived_counts')
plt.show()输出:
2.7.3 任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)
先用groupby将sex分组为female和male、在female与male中分别再以survived为key分组为0和1,计算0与1各自的数量,用unstack将内部index转置为columns:
Sex = result.groupby(['Sex','Survived'])['Survived'].count().unstack()
Sex输出:

接着用plot选择bar图进行展示,设置y轴label和bar图的title:
Sex.plot(kind='bar',stacked=True)
plt.title('Sex_situation')
plt.ylabel('PassengerNum')
plt.show()输出:
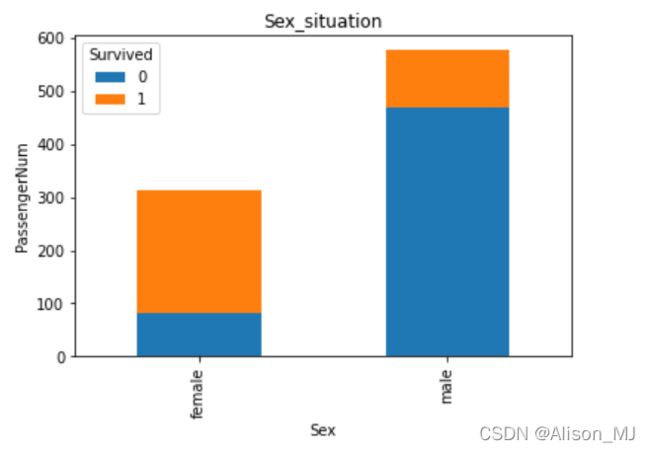
由此可看出女生存活人数比男生要多,且女性存活人数占女性总人数大部分,而男性存活人数占男性总人数不到1/4,说明性别可能影响存活率。
2.7.4 任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
折线图:fare属于连续数值型指标,考虑用折线图查看费用高低对幸存的影响,且用groupby分组、unstack转置后,发现有些fare的值只有一个幸存者而没有未存活者,因此存在NAN值,于是用fillna填补空值:
Fare = result.groupby(['Fare','Survived'])['Survived'].count().unstack().fillna(0)
Fare.plot(kind='line',figsize=(20,5))
plt.title('Fare_influence')
plt.ylabel('PassengerNum')
plt.show()输出:
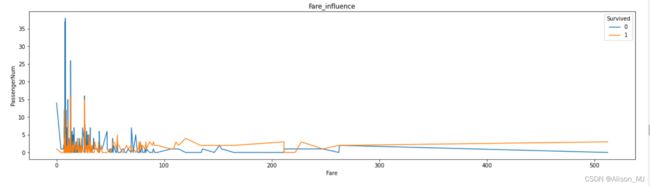
由结果可知,购买高价船票的乘客占少数,大多数乘客购买的船票价格集中在0-100中间,且由于fare数值差别大,考虑通过先用cut对fare进行分段后再可视化分析:
result['Fare_cut'] = pd.cut(result['Fare'],bins=[0,50,100,200,300,400],labels=[1,2,3,4,5])
FS = result['Survived'].groupby(result['Fare_cut']).sum()
FA = result['Survived'].groupby(result['Fare_cut']).count()
Fare_S_Ratio = FS/FA
Fare_influence = pd.concat([FS,FA,Fare_S_Ratio],axis=1)
Fare_influence.columns=['Survived','All','Ratio']
Fare_influence输出:
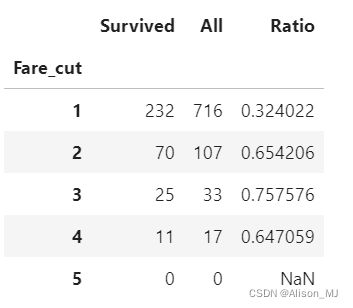
柱状图:分箱过后查看不同Fare区间的存活率进行比较:
fig,ax = plt.subplots()
ax.bar(Fare_influence.index,Fare_influence['Ratio'])
plt.title('Survived_Fare')
plt.ylabel('Survived_ratio')
plt.xlabel('Fare_cut')
plt.show()输出:

由结果可知,按照存活率来看,fare在[200:300]之间的存活率相对最高 。
2.7.5 任务五:可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
result.groupby('Pclass')['Survived'].value_counts().unstack().plot(kind='bar')
plt.title('Pclass_situation')
plt.ylabel('PassengerNum')
plt.show()可以看出Pclass越高存活率越高:
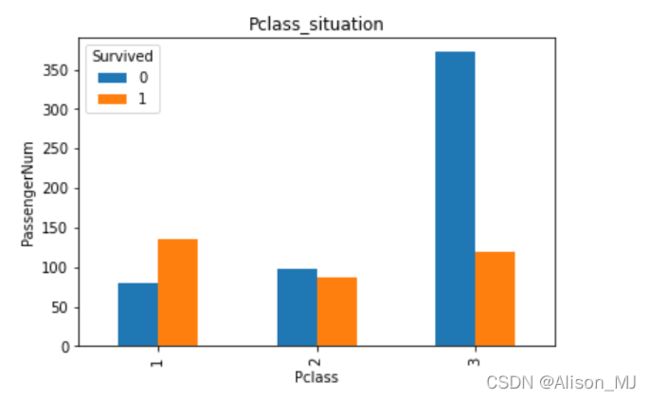
【思考】看到这个前面几个数据可视化,说说你的第一感受和你的总结
1. 可视化有多种实现方式,需要根据不同可视化图案的特点选择适合的场景进行使用;
2. 女性存活率比男性高;
3. Pclass越高,存活率越高;
4. 购买Fare[0,100]之间的乘客占大多数,Fare[200,300]之间存活率最高。
2.7.6 任务六:可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
折线图:
Age = result.groupby('Age')['Survived'].value_counts().unstack()
Age.plot()
plt.show()输出:
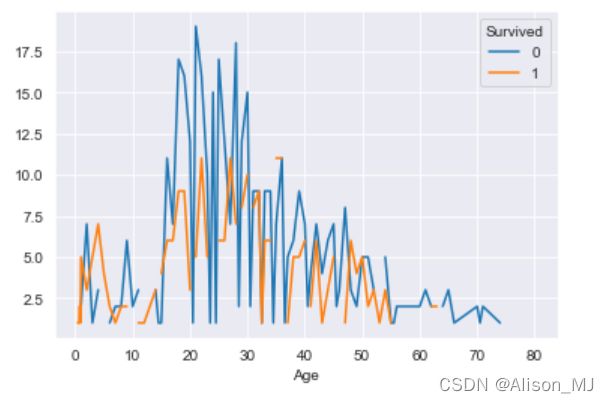
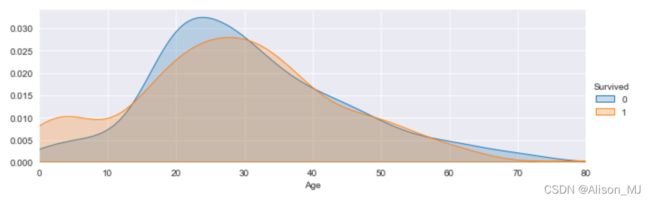
核密度估计图:
Age = sns.FacetGrid(result, hue="Survived",aspect=3)
Age.map(sns.kdeplot,'Age',shade= True)
Age.set(xlim=(0, result['Age'].max()))
Age.add_legend()
plt.show()输出:
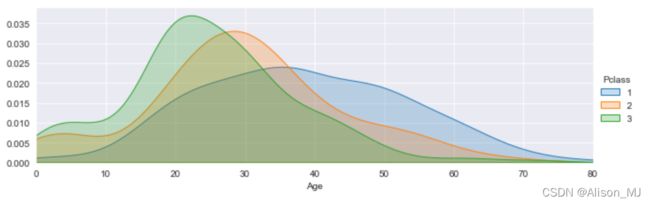
2.7.7 任务七:可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
核密度估计图:
Age_p = sns.FacetGrid(result, hue="Pclass",aspect=3)
Age_p.map(sns.kdeplot,'Age',shade= True)
Age_p.set(xlim=(0, result['Age'].max()))
Age_p.add_legend()
plt.show()输出:
总结:
通过Task4的学习,掌握了基础的柱状图,折线图等图形的可视化方法,了解了不同可视化图像所使用的场景。