大数据数仓项目实战
一、数仓项目需求及架构设计
数据仓库是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
数据仓库是出于分析报告和决策支持目的而创建的,为需要业务智能的企业,提供指导业务流程改进、监控时间、成本、质量以及控制。
1、项目需求分析
- 数据采集平台搭建;
- 实现数据仓库分层的搭建;
- 实现数据清洗、聚合、计算等操作;
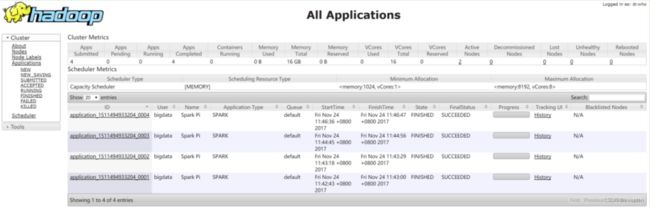
- 统计各指标,如统计通过各地址跳转注册的用户人数、统计各平台的用户人数、统计支付金额topN的用户;
2、项目框架
1)技术选型
- 数据存储:Hdfs
- 数据处理:Hive、Spark
- 任务调度:Azkaban
2)流程设计
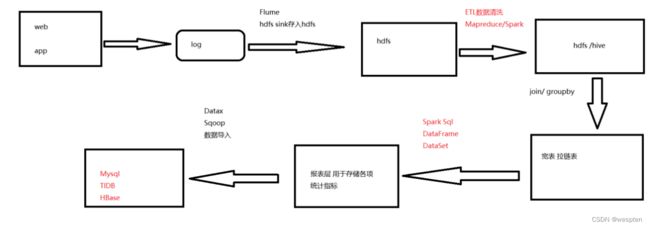
框架版本选型:
如何选择Apache/CDH/HDP版本?
Apache∶运维麻烦,组件间兼容性需要自己调研。(一般大厂使用,技术实力雄厚,有专业的运维人员)。
CDH∶国内使用最多的版本,但CM不开源,但其实对中、小公司使用来说没有影响(建议使用)。
HDP∶开源,可以进行二次开发,但是没有CDH稳定,国内使用较少。
二、用户注册模块需求
1、原始数据格式及字段含义
baseadlog 广告基础表原始json数据:
{
"adid": "0", //基础广告表广告id
"adname": "注册弹窗广告0", //广告详情名称
"dn": "webA" //网站分区
}basewebsitelog 网站基础表原始json数据:
{
"createtime": "2000-01-01",
"creator": "admin",
"delete": "0",
"dn": "webC", //网站分区
"siteid": "2", //网站id
"sitename": "114", //网站名称
"siteurl": "www.114.com/webC" //网站地址
}memberRegtype 用户跳转地址注册表:
{
"appkey": "-",
"appregurl": "http:www.webA.com/product/register/index.html", //注册时跳转地址
"bdp_uuid": "-",
"createtime": "2015-05-11",
"dt":"20190722", //日期分区
"dn": "webA", //网站分区
"domain": "-",
"isranreg": "-",
"regsource": "4", //所属平台 1.PC 2.MOBILE 3.APP 4.WECHAT
"uid": "0", //用户id
"websiteid": "0" //对应basewebsitelog 下的siteid网站
}pcentermempaymoneylog 用户支付金额表:
{
"dn": "webA", //网站分区
"paymoney": "162.54", //支付金额
"siteid": "1", //网站id对应 对应basewebsitelog 下的siteid网站
"dt":"20190722", //日期分区
"uid": "4376695", //用户id
"vip_id": "0" //对应pcentermemviplevellog vip_id
}pcentermemviplevellog用户vip等级基础表:
{
"discountval": "-",
"dn": "webA", //网站分区
"end_time": "2019-01-01", //vip结束时间
"last_modify_time": "2019-01-01",
"max_free": "-",
"min_free": "-",
"next_level": "-",
"operator": "update",
"start_time": "2015-02-07", //vip开始时间
"vip_id": "2", //vip id
"vip_level": "银卡" //vip级别名称
}memberlog 用户基本信息表:
{
"ad_id": "0", //广告id
"birthday": "1981-08-14", //出生日期
"dt":"20190722", //日期分区
"dn": "webA", //网站分区
"email": "[email protected]",
"fullname": "王69239", //用户姓名
"iconurl": "-",
"lastlogin": "-",
"mailaddr": "-",
"memberlevel": "6", //用户级别
"password": "123456", //密码
"paymoney": "-",
"phone": "13711235451", //手机号
"qq": "10000",
"register": "2016-08-15", //注册时间
"regupdatetime": "-",
"uid": "69239", //用户id
"unitname": "-",
"userip": "123.235.75.48", //ip地址
"zipcode": "-"
}其余字段为非统计项 直接使用默认值“-”存储即可。
2、数据分层
在hadoop集群上创建 ods目录:
hadoop dfs -mkdir -p /user/yyds/ods在hive里分别建立三个库,dwd、dws、ads 分别用于存储etl清洗后的数据、宽表和拉链表数据、各报表层统计指标数据。
create database dwd;
create database dws;
create database ads; 各层级:
- ods:存放原始数据
- dwd:结构与原始表结构保持一致,对ods层数据进行清洗
- dws:以dwd为基础进行轻度汇总
- ads:报表层,为各种统计报表提供数据
各层建表语句:
用户模块:
create external table `dwd`.`dwd_member`(
uid int,
ad_id int,
birthday string,
email string,
fullname string,
iconurl string,
lastlogin string,
mailaddr string,
memberlevel string,
password string,
paymoney string,
phone string,
qq string,
register string,
regupdatetime string,
unitname string,
userip string,
zipcode string)
partitioned by(
dt string,
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_member_regtype`(
uid int,
appkey string,
appregurl string,
bdp_uuid string,
createtime timestamp,
isranreg string,
regsource string,
regsourcename string,
websiteid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_base_ad`(
adid int,
adname string)
partitioned by (
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_base_website`(
siteid int,
sitename string,
siteurl string,
`delete` int,
createtime timestamp,
creator string)
partitioned by (
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_pcentermempaymoney`(
uid int,
paymoney string,
siteid int,
vip_id int
)
partitioned by(
dt string,
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_vip_level`(
vip_id int,
vip_level string,
start_time timestamp,
end_time timestamp,
last_modify_time timestamp,
max_free string,
min_free string,
next_level string,
operator string
)partitioned by(
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
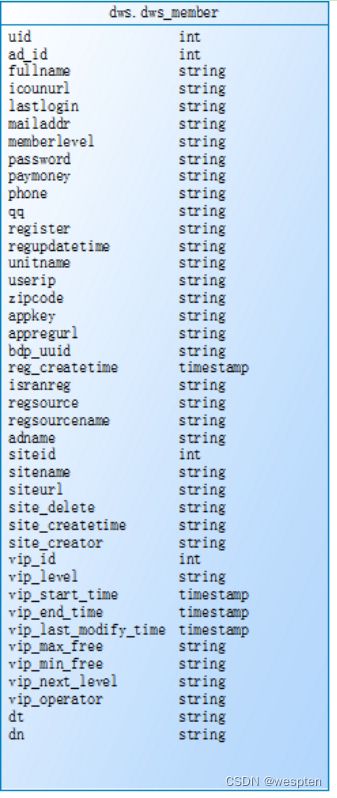
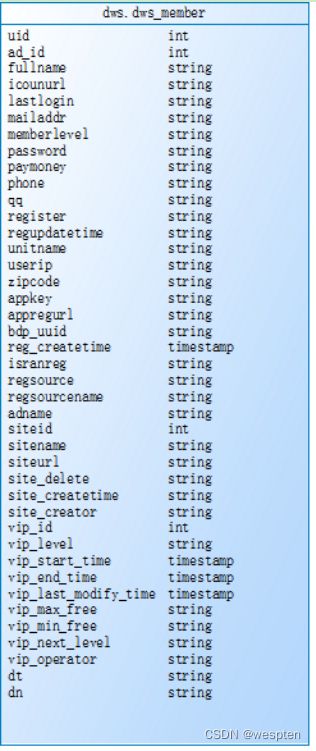
create external table `dws`.`dws_member`(
uid int,
ad_id int,
fullname string,
iconurl string,
lastlogin string,
mailaddr string,
memberlevel string,
password string,
paymoney string,
phone string,
qq string,
register string,
regupdatetime string,
unitname string,
userip string,
zipcode string,
appkey string,
appregurl string,
bdp_uuid string,
reg_createtime timestamp,
isranreg string,
regsource string,
regsourcename string,
adname string,
siteid int,
sitename string,
siteurl string,
site_delete string,
site_createtime string,
site_creator string,
vip_id int,
vip_level string,
vip_start_time timestamp,
vip_end_time timestamp,
vip_last_modify_time timestamp,
vip_max_free string,
vip_min_free string,
vip_next_level string,
vip_operator string
)partitioned by(
dt string,
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
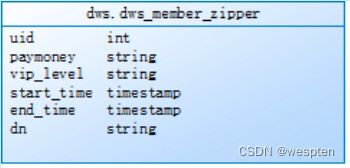
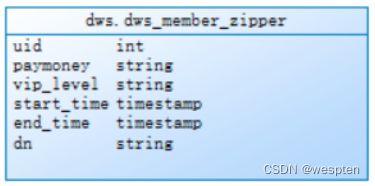
create external table `dws`.`dws_member_zipper`(
uid int,
paymoney string,
vip_level string,
start_time timestamp,
end_time timestamp
)partitioned by(
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `ads`.`ads_register_appregurlnum`(
appregurl string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_sitenamenum`(
sitename string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_regsourcenamenum`(
regsourcename string,
num int
)partitioned by(
dt string,
dn string
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_adnamenum`(
adname string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_memberlevelnum`(
memberlevel string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_viplevelnum`(
vip_level string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_top3memberpay`(
uid int,
memberlevel string,
register string,
appregurl string,
regsourcename string,
adname string,
sitename string,
vip_level string,
paymoney decimal(10,4),
rownum int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
dwd层 6张基础表:

dws层宽表和拉链表:
宽表:
拉链表:
报表层各统计表:

3、模拟数据采集上传数据
模拟数据采集 将日志文件数据直接上传到hadoop集群上:
hadoop dfs -put baseadlog.log /user/yyds/ods/
hadoop dfs -put memberRegtype.log /user/yyds/ods/
hadoop dfs -put baswewebsite.log /user/yyds/ods/
hadoop dfs -put pcentermempaymoney.log /user/yyds/ods/
hadoop dfs -put pcenterMemViplevel.log /user/yyds/ods/
hadoop dfs -put member.log /user/yyds/ods/
4、ETL数据清洗
需求1:必须使用Spark进行数据清洗,对用户名、手机号、密码进行脱敏处理,并使用Spark将数据导入到dwd层hive表中
清洗规则 用户名:王XX 手机号:137*****789 密码直接替换成******
5、基于dwd层表合成dws层的宽表
需求2:对dwd层的6张表进行合并,生成一张宽表,先使用Spark Sql实现。有时间的同学需要使用DataFrame api实现功能,并对join进行优化。
6、拉链表
需求3:针对dws层宽表的支付金额(paymoney)和vip等级(vip_level)这两个会变动的字段生成一张拉链表,需要一天进行一次更新。
7、报表层各指标统计
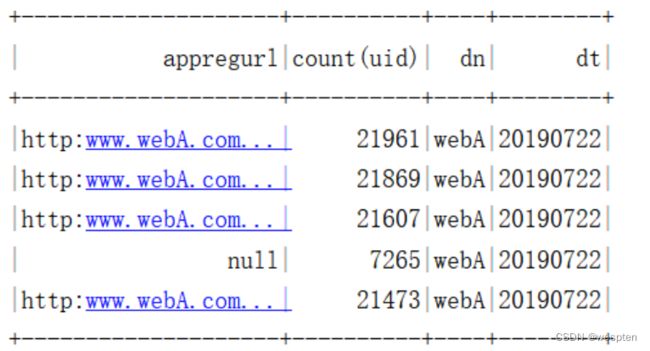
需求4:使用Spark DataFrame Api统计通过各注册跳转地址(appregurl)进行注册的用户数。
需求5:使用Spark DataFrame Api统计各所属网站(sitename)的用户数。

需求6:使用Spark DataFrame Api统计各所属平台的(regsourcename)用户数。

需求7:使用Spark DataFrame Api统计通过各广告跳转(adname)的用户数。
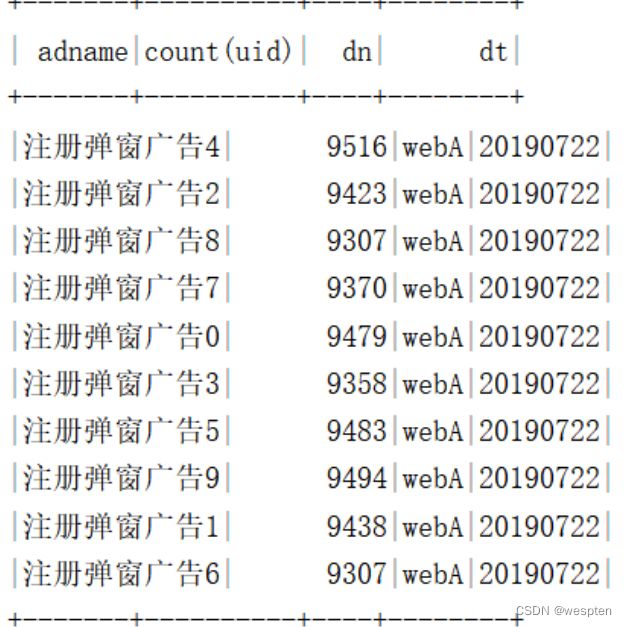
需求8:使用Spark DataFrame Api统计各用户级别(memberlevel)的用户数。
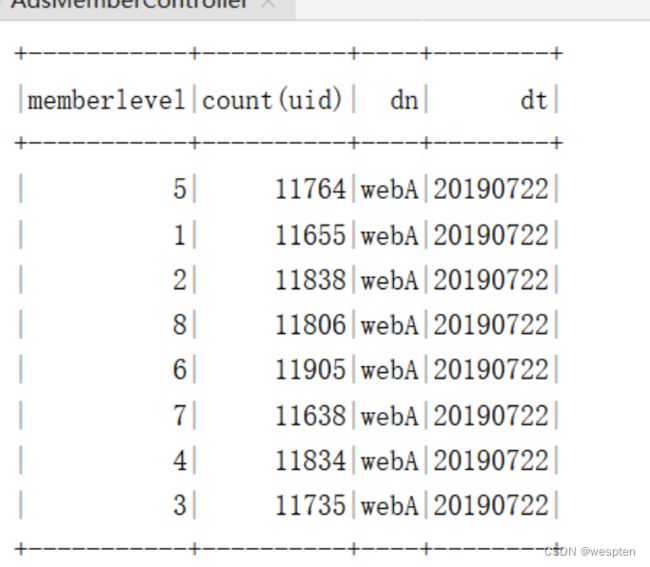
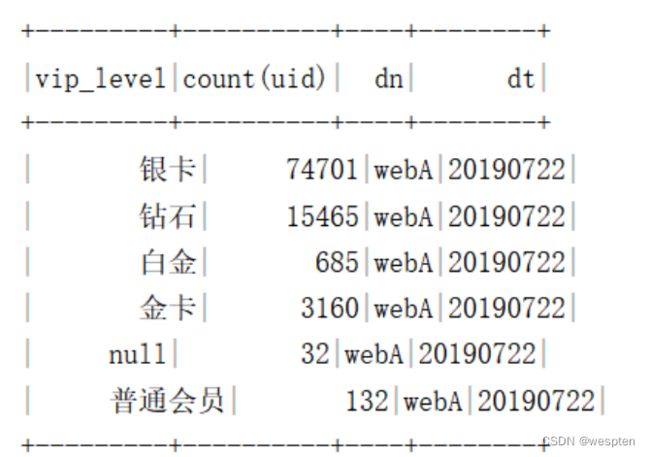
需求9:使用Spark DataFrame Api统计各vip等级人数。
需求10:使用Spark DataFrame Api统计各分区网站、用户级别下(website、memberlevel)的top3用户。

三、用户做题需求模块
1、原始数据格式及字段含义
QzWebsite.log 做题网站日志数据:
{
"createtime": "2019-07-22 11:47:18", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"domain": "-",
"dt": "20190722", //日期分区
"multicastgateway": "-",
"multicastport": "-",
"multicastserver": "-",
"sequence": "-",
"siteid": 0, //网站id
"sitename": "sitename0", //网站名称
"status": "-",
"templateserver": "-"
}QzSiteCourse.log 网站课程日志数据:
{
"boardid": 64, //课程模板id
"coursechapter": "-",
"courseid": 66, //课程id
"createtime": "2019-07-22 11:43:32", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"helpparperstatus": "-",
"sequence": "-",
"servertype": "-",
"showstatus": "-",
"sitecourseid": 2, //网站课程id
"sitecoursename": "sitecoursename2", //网站课程名称
"siteid": 77, //网站id
"status": "-"
}QzQuestionType.log 题目类型数据:
{
"createtime": "2019-07-22 10:42:47", //创建时间
"creator": "admin", //创建者
"description": "-",
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"papertypename": "-",
"questypeid": 0, //做题类型id
"quesviewtype": 0,
"remark": "-",
"sequence": "-",
"splitscoretype": "-",
"status": "-",
"viewtypename": "viewtypename0"
}QzQuestion.log 做题日志数据:
{
"analysis": "-",
"answer": "-",
"attanswer": "-",
"content": "-",
"createtime": "2019-07-22 11:33:46", //创建时间
"creator": "admin", //创建者
"difficulty": "-",
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"lecture": "-",
"limitminute": "-",
"modifystatus": "-",
"optnum": 8,
"parentid": 57,
"quesskill": "-",
"questag": "-",
"questionid": 0, //题id
"questypeid": 57, //题目类型id
"quesviewtype": 44,
"score": 24.124501582742543, //题的分数
"splitscore": 0.0,
"status": "-",
"vanalysisaddr": "-",
"vdeoaddr": "-"
}QzPointQuestion.log 做题知识点关联数据:
{
"createtime": "2019-07-22 09:16:46", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"pointid": 0, //知识点id
"questionid": 0, //题id
"questype": 0
}QzPoint.log 知识点数据日志:
{
"chapter": "-", //所属章节
"chapterid": 0, //章节id
"courseid": 0, //课程id
"createtime": "2019-07-22 09:08:52", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"excisenum": 73,
"modifystatus": "-",
"pointdescribe": "-",
"pointid": 0, //知识点id
"pointlevel": "9", //知识点级别
"pointlist": "-",
"pointlistid": 82, //知识点列表id
"pointname": "pointname0", //知识点名称
"pointnamelist": "-",
"pointyear": "2019", //知识点所属年份
"remid": "-",
"score": 83.86880766562163, //知识点分数
"sequece": "-",
"status": "-",
"thought": "-",
"typelist": "-"
}QzPaperView.log 试卷视图数据:
{
"contesttime": "2019-07-22 19:02:19",
"contesttimelimit": "-",
"createtime": "2019-07-22 19:02:19", //创建时间
"creator": "admin", //创建者
"dayiid": 94,
"description": "-",
"dn": "webA", //网站分区
"downurl": "-",
"dt": "20190722", //日期分区
"explainurl": "-",
"iscontest": "-",
"modifystatus": "-",
"openstatus": "-",
"paperdifficult": "-",
"paperid": 83, //试卷id
"paperparam": "-",
"papertype": "-",
"paperuse": "-",
"paperuseshow": "-",
"paperviewcatid": 1,
"paperviewid": 0, //试卷视图id
"paperviewname": "paperviewname0", //试卷视图名称
"testreport": "-"
}QzPaper.log 做题试卷日志数据:
{
"chapter": "-", //章节
"chapterid": 33, //章节id
"chapterlistid": 69, //所属章节列表id
"courseid": 72, //课程id
"createtime": "2019-07-22 19:14:27", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"papercatid": 92,
"paperid": 0, //试卷id
"papername": "papername0", //试卷名称
"paperyear": "2019", //试卷所属年份
"status": "-",
"suitnum": "-",
"totalscore": 93.16710017696484 //试卷总分
}QzMemberPaperQuestion.log 学员做题详情数据:
{
"chapterid": 33, //章节id
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"istrue": "-",
"lasttime": "2019-07-22 11:02:30",
"majorid": 77, //主修id
"opertype": "-",
"paperid": 91,//试卷id
"paperviewid": 37, //试卷视图id
"question_answer": 1, //做题结果(0错误 1正确)
"questionid": 94, //题id
"score": 76.6941793631127, //学员成绩分数
"sitecourseid": 1, //网站课程id
"spendtime": 4823, //所用时间单位(秒)
"useranswer": "-",
"userid": 0 //用户id
}QzMajor.log 主修数据:
{
"businessid": 41, //主修行业id
"columm_sitetype": "-",
"createtime": "2019-07-22 11:10:20", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"majorid": 1, //主修id
"majorname": "majorname1", //主修名称
"sequence": "-",
"shortname": "-",
"siteid": 24, //网站id
"status": "-"
}QzCourseEduSubject.log 课程辅导数据:
{
"courseeduid": 0, //课程辅导id
"courseid": 0, //课程id
"createtime": "2019-07-22 11:14:43", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"edusubjectid": 44, //辅导科目id
"majorid": 38 //主修id
}QzCourse.log 题库课程数据:
{
"chapterlistid": 45, //章节列表id
"courseid": 0, //课程id
"coursename": "coursename0", //课程名称
"createtime": "2019-07-22 11:08:15", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"isadvc": "-",
"majorid": 39, //主修id
"pointlistid": 92, //知识点列表id
"sequence": "8128f2c6-2430-42c7-9cb4-787e52da2d98",
"status": "-"
}QzChapterList.log 章节列表数据:
{
"chapterallnum": 0, //章节总个数
"chapterlistid": 0, //章节列表id
"chapterlistname": "chapterlistname0", //章节列表名称
"courseid": 71, //课程id
"createtime": "2019-07-22 16:22:19", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"status": "-"
}QzChapter.log 章节数据:
{
"chapterid": 0, //章节id
"chapterlistid": 0, //所属章节列表id
"chaptername": "chaptername0", //章节名称
"chapternum": 10, //章节个数
"courseid": 61, //课程id
"createtime": "2019-07-22 16:37:24", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"outchapterid": 0,
"sequence": "-",
"showstatus": "-",
"status": "-"
}QzCenterPaper.log 试卷主题关联数据:
{
"centerid": 55, //主题id
"createtime": "2019-07-22 10:48:30", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"openstatus": "-",
"paperviewid": 2, //视图id
"sequence": "-"
}QzCenter.log 主题数据:
{
"centerid": 0, //主题id
"centername": "centername0", //主题名称
"centerparam": "-",
"centertype": "3", //主题类型
"centerviewtype": "-",
"centeryear": "2019", //主题年份
"createtime": "2019-07-22 19:13:09", //创建时间
"creator": "-",
"description": "-",
"dn": "webA",
"dt": "20190722", //日期分区
"openstatus": "1",
"provideuser": "-",
"sequence": "-",
"stage": "-"
}
Centerid:主题id centername:主题名称 centertype:主题类型 centeryear:主题年份
createtime:创建时间 dn:网站分区 dt:日期分区 QzBusiness.log 所属行业数据:
{
"businessid": 0, //行业id
"businessname": "bsname0", //行业名称
"createtime": "2019-07-22 10:40:54", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"sequence": "-",
"siteid": 1, //所属网站id
"status": "-"
}2、模拟数据采集上传数据
日志上传命令:
hadoop dfs -put QzBusiness.log /user/yyds/ods/
hadoop dfs -put QzCenter.log /user/yyds/ods/
hadoop dfs -put QzCenterPaper.log /user/yyds/ods/
hadoop dfs -put QzChapter.log /user/yyds/ods/
hadoop dfs -put QzChapterList.log /user/yyds/ods/
hadoop dfs -put QzCourse.log /user/yyds/ods/
hadoop dfs -put QzCourseEduSubject.log /user/yyds/ods/
hadoop dfs -put QzMajor.log /user/yyds/ods/
hadoop dfs -put QzMemberPaperQuestion.log /user/yyds/ods/
hadoop dfs -put QzPaper.log /user/yyds/ods/
hadoop dfs -put QzPaperView.log /user/yyds/ods/
hadoop dfs -put QzPoint.log /user/yyds/ods/
hadoop dfs -put QzPointQuestion.log /user/yyds/ods/
hadoop dfs -put QzQuestion.log /user/yyds/ods/
hadoop dfs -put QzQuestionType.log /user/yyds/ods/
hadoop dfs -put QzSiteCourse.log /user/yyds/ods/
hadoop dfs -put QzWebsite.log /user/yyds/ods/
做题表建表语句:
create external table `dwd`.`dwd_qz_chapter`(
chapterid int ,
chapterlistid int ,
chaptername string ,
sequence string ,
showstatus string ,
creator string ,
createtime timestamp,
courseid int ,
chapternum int,
outchapterid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_chapter_list`(
chapterlistid int ,
chapterlistname string ,
courseid int ,
chapterallnum int ,
sequence string,
status string,
creator string ,
createtime timestamp
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_point`(
pointid int ,
courseid int ,
pointname string ,
pointyear string ,
chapter string ,
creator string,
createtme timestamp,
status string,
modifystatus string,
excisenum int,
pointlistid int ,
chapterid int ,
sequece string,
pointdescribe string,
pointlevel string ,
typelist string,
score decimal(4,1),
thought string,
remid string,
pointnamelist string,
typelistids string,
pointlist string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_point_question`(
pointid int,
questionid int ,
questype int ,
creator string,
createtime string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_site_course`(
sitecourseid int,
siteid int ,
courseid int ,
sitecoursename string ,
coursechapter string ,
sequence string,
status string,
creator string,
createtime timestamp,
helppaperstatus string,
servertype string,
boardid int,
showstatus string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_course`(
courseid int ,
majorid int ,
coursename string ,
coursechapter string ,
sequence string,
isadvc string,
creator string,
createtime timestamp,
status string,
chapterlistid int,
pointlistid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_course_edusubject`(
courseeduid int ,
edusubjectid int ,
courseid int ,
creator string,
createtime timestamp,
majorid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_website`(
siteid int ,
sitename string ,
domain string,
sequence string,
multicastserver string,
templateserver string,
status string,
creator string,
createtime timestamp,
multicastgateway string,
multicastport string
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_major`(
majorid int ,
businessid int ,
siteid int ,
majorname string ,
shortname string ,
status string,
sequence string,
creator string,
createtime timestamp,
column_sitetype string
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_business`(
businessid int ,
businessname string,
sequence string,
status string,
creator string,
createtime timestamp,
siteid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_paper_view`(
paperviewid int ,
paperid int ,
paperviewname string,
paperparam string ,
openstatus string,
explainurl string,
iscontest string ,
contesttime timestamp,
conteststarttime timestamp ,
contestendtime timestamp ,
contesttimelimit string ,
dayiid int,
status string,
creator string,
createtime timestamp,
paperviewcatid int,
modifystatus string,
description string,
papertype string ,
downurl string ,
paperuse string,
paperdifficult string ,
testreport string,
paperuseshow string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_center_paper`(
paperviewid int,
centerid int,
openstatus string,
sequence string,
creator string,
createtime timestamp)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_paper`(
paperid int,
papercatid int,
courseid int,
paperyear string,
chapter string,
suitnum string,
papername string,
status string,
creator string,
createtime timestamp,
totalscore decimal(4,1),
chapterid int,
chapterlistid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_center`(
centerid int,
centername string,
centeryear string,
centertype string,
openstatus string,
centerparam string,
description string,
creator string,
createtime timestamp,
sequence string,
provideuser string,
centerviewtype string,
stage string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_question`(
questionid int,
parentid int,
questypeid int,
quesviewtype int,
content string,
answer string,
analysis string,
limitminute string,
score decimal(4,1),
splitscore decimal(4,1),
status string,
optnum int,
lecture string,
creator string,
createtime string,
modifystatus string,
attanswer string,
questag string,
vanalysisaddr string,
difficulty string,
quesskill string,
vdeoaddr string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_question_type`(
quesviewtype int,
viewtypename string,
questypeid int,
description string,
status string,
creator string,
createtime timestamp,
papertypename string,
sequence string,
remark string,
splitscoretype string
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_member_paper_question`(
userid int,
paperviewid int,
chapterid int,
sitecourseid int,
questionid int,
majorid int,
useranswer string,
istrue string,
lasttime timestamp,
opertype string,
paperid int,
spendtime int,
score decimal(4,1),
question_answer int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_chapter`(
chapterid int,
chapterlistid int,
chaptername string,
sequence string,
showstatus string,
status string,
chapter_creator string,
chapter_createtime string,
chapter_courseid int,
chapternum int,
chapterallnum int,
outchapterid int,
chapterlistname string,
pointid int,
questionid int,
questype int,
pointname string,
pointyear string,
chapter string,
excisenum int,
pointlistid int,
pointdescribe string,
pointlevel string,
typelist string,
point_score decimal(4,1),
thought string,
remid string,
pointnamelist string,
typelistids string,
pointlist string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_course`(
sitecourseid int,
siteid int,
courseid int,
sitecoursename string,
coursechapter string,
sequence string,
status string,
sitecourse_creator string,
sitecourse_createtime string,
helppaperstatus string,
servertype string,
boardid int,
showstatus string,
majorid int,
coursename string,
isadvc string,
chapterlistid int,
pointlistid int,
courseeduid int,
edusubjectid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_major`(
majorid int,
businessid int,
siteid int,
majorname string,
shortname string,
status string,
sequence string,
major_creator string,
major_createtime timestamp,
businessname string,
sitename string,
domain string,
multicastserver string,
templateserver string,
multicastgateway string,
multicastport string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_paper`(
paperviewid int,
paperid int,
paperviewname string,
paperparam string,
openstatus string,
explainurl string,
iscontest string,
contesttime timestamp,
conteststarttime timestamp,
contestendtime timestamp,
contesttimelimit string,
dayiid int,
status string,
paper_view_creator string,
paper_view_createtime timestamp,
paperviewcatid int,
modifystatus string,
description string,
paperuse string,
paperdifficult string,
testreport string,
paperuseshow string,
centerid int,
sequence string,
centername string,
centeryear string,
centertype string,
provideuser string,
centerviewtype string,
stage string,
papercatid int,
courseid int,
paperyear string,
suitnum string,
papername string,
totalscore decimal(4,1),
chapterid int,
chapterlistid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_question`(
questionid int,
parentid int,
questypeid int,
quesviewtype int,
content string,
answer string,
analysis string,
limitminute string,
score decimal(4,1),
splitscore decimal(4,1),
status string,
optnum int,
lecture string,
creator string,
createtime timestamp,
modifystatus string,
attanswer string,
questag string,
vanalysisaddr string,
difficulty string,
quesskill string,
vdeoaddr string,
viewtypename string,
description string,
papertypename string,
splitscoretype string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create table `dws`.`dws_user_paper_detail`(
`userid` int,
`courseid` int,
`questionid` int,
`useranswer` string,
`istrue` string,
`lasttime` string,
`opertype` string,
`paperid` int,
`spendtime` int,
`chapterid` int,
`chaptername` string,
`chapternum` int,
`chapterallnum` int,
`outchapterid` int,
`chapterlistname` string,
`pointid` int,
`questype` int,
`pointyear` string,
`chapter` string,
`pointname` string,
`excisenum` int,
`pointdescribe` string,
`pointlevel` string,
`typelist` string,
`point_score` decimal(4,1),
`thought` string,
`remid` string,
`pointnamelist` string,
`typelistids` string,
`pointlist` string,
`sitecourseid` int,
`siteid` int,
`sitecoursename` string,
`coursechapter` string,
`course_sequence` string,
`course_stauts` string,
`course_creator` string,
`course_createtime` timestamp,
`servertype` string,
`helppaperstatus` string,
`boardid` int,
`showstatus` string,
`majorid` int,
`coursename` string,
`isadvc` string,
`chapterlistid` int,
`pointlistid` int,
`courseeduid` int,
`edusubjectid` int,
`businessid` int,
`majorname` string,
`shortname` string,
`major_status` string,
`major_sequence` string,
`major_creator` string,
`major_createtime` timestamp,
`businessname` string,
`sitename` string,
`domain` string,
`multicastserver` string,
`templateserver` string,
`multicastgatway` string,
`multicastport` string,
`paperviewid` int,
`paperviewname` string,
`paperparam` string,
`openstatus` string,
`explainurl` string,
`iscontest` string,
`contesttime` timestamp,
`conteststarttime` timestamp,
`contestendtime` timestamp,
`contesttimelimit` string,
`dayiid` int,
`paper_status` string,
`paper_view_creator` string,
`paper_view_createtime` timestamp,
`paperviewcatid` int,
`modifystatus` string,
`description` string,
`paperuse` string,
`testreport` string,
`centerid` int,
`paper_sequence` string,
`centername` string,
`centeryear` string,
`centertype` string,
`provideuser` string,
`centerviewtype` string,
`paper_stage` string,
`papercatid` int,
`paperyear` string,
`suitnum` string,
`papername` string,
`totalscore` decimal(4,1),
`question_parentid` int,
`questypeid` int,
`quesviewtype` int,
`question_content` string,
`question_answer` string,
`question_analysis` string,
`question_limitminute` string,
`score` decimal(4,1),
`splitscore` decimal(4,1),
`lecture` string,
`question_creator` string,
`question_createtime` timestamp,
`question_modifystatus` string,
`question_attanswer` string,
`question_questag` string,
`question_vanalysisaddr` string,
`question_difficulty` string,
`quesskill` string,
`vdeoaddr` string,
`question_description` string,
`question_splitscoretype` string,
`user_question_answer` int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table ads.ads_paper_avgtimeandscore(
paperviewid int,
paperviewname string,
avgscore decimal(4,1),
avgspendtime decimal(10,1))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_paper_maxdetail(
paperviewid int,
paperviewname string,
maxscore decimal(4,1),
minscore decimal(4,1))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_top3_userdetail(
userid int,
paperviewid int,
paperviewname string,
chaptername string,
pointname string,
sitecoursename string,
coursename string,
majorname string,
shortname string,
papername string,
score decimal(4,1),
rk int)
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_low3_userdetail(
userid int,
paperviewid int,
paperviewname string,
chaptername string,
pointname string,
sitecoursename string,
coursename string,
majorname string,
shortname string,
papername string,
score decimal(4,1),
rk int)
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_paper_scoresegment_user(
paperviewid int,
paperviewname string,
score_segment string,
userids string)
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_user_paper_detail(
paperviewid int,
paperviewname string,
unpasscount int,
passcount int,
rate decimal(4,2))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_user_question_detail(
questionid int,
errcount int,
rightcount int,
rate decimal(4,2))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';3、解析数据
需求1:使用spark解析ods层数据,将数据存入到对应的hive表中,要求对所有score 分数字段进行保留1位小数并且四舍五入。
4、维度退化
需求2:基于dwd层基础表数据,需要对表进行维度退化进行表聚合,聚合成dws.dws_qz_chapter(章节维度表),dws.dws_qz_course(课程维度表),dws.dws_qz_major(主修维度表),dws.dws_qz_paper(试卷维度表),dws.dws_qz_question(题目维度表),使用spark sql和dataframe api操作
dws.dws_qz_chapte : 4张表join dwd.dwd_qz_chapter inner join dwd.qz_chapter_list join条件:chapterlistid和dn ,inner join dwd.dwd_qz_point join条件:chapterid和dn, inner join dwd.dwd_qz_point_question join条件:pointid和dn
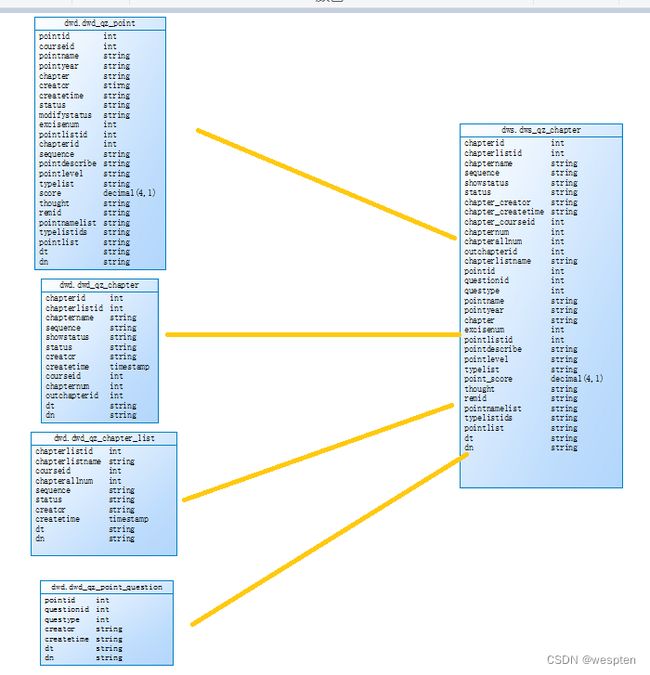
dws.dws_qz_course:3张表join dwd.dwd_qz_site_course inner join dwd.qz_course join条件:courseid和dn , inner join dwd.qz_course_edusubject join条件:courseid和dn
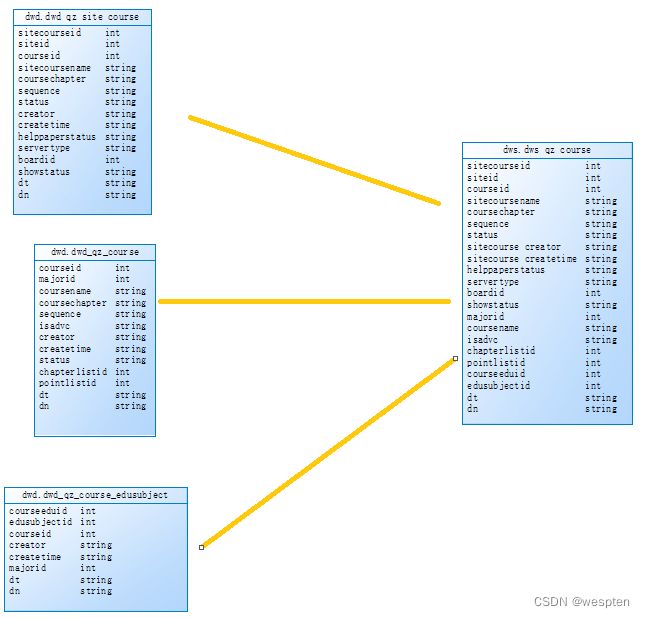
dws.dws_qz_major:3张表join dwd.dwd_qz_major inner join dwd.dwd_qz_website join条件:siteid和dn , inner join dwd.dwd_qz_business join条件:businessid和dn

dws.dws_qz_paper: 4张表join qz_paperview left join qz_center join 条件:paperviewid和dn,
left join qz_center join 条件:centerid和dn, inner join qz_paper join条件:paperid和dn
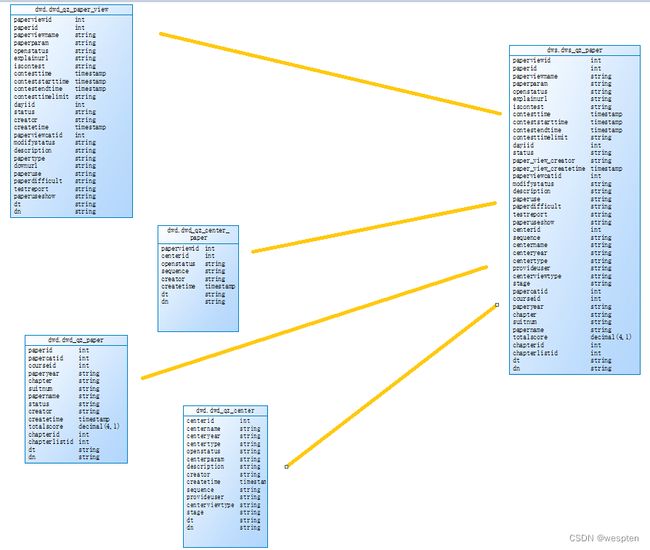
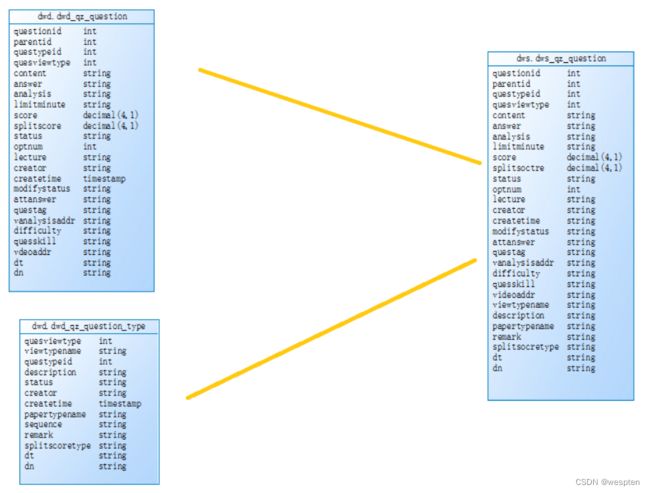
dws.dws_qz_question:2表join qz_quesiton inner join qz_questiontype join条件:
questypeid 和dn
5、宽表合成
需求3:基于dws.dws_qz_chapter、dws.dws_qz_course、dws.dws_qz_major、dws.dws_qz_paper、dws.dws_qz_question、dwd.dwd_qz_member_paper_question 合成宽表dw.user_paper_detail,使用spark sql和dataframe api操作
dws.user_paper_detail:dwd_qz_member_paper_question inner join dws_qz_chapter join条件:chapterid 和dn ,inner join dws_qz_course join条件:sitecourseid和dn , inner join dws_qz_major join条件majorid和dn, inner join dws_qz_paper 条件paperviewid和dn , inner join dws_qz_question 条件questionid和
6、报表层各指标统计
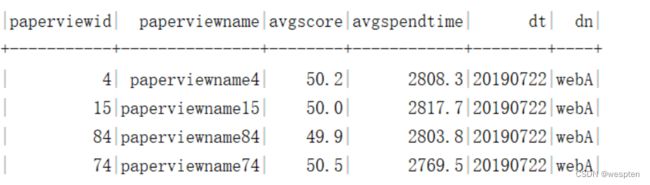
需求4:基于宽表统计各试卷平均耗时、平均分,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。
需求5:统计各试卷最高分、最低分,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。
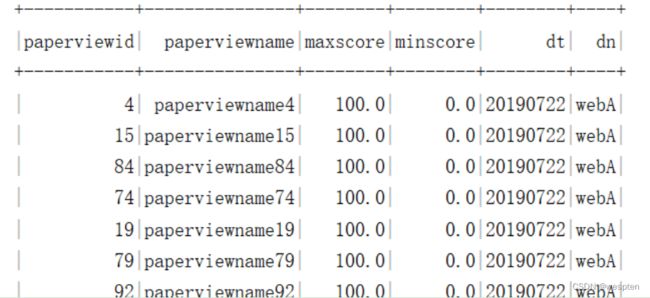
需求6:按试卷分组统计每份试卷的用Spa前三用户详情,先使rk Sql 完成指标统计,再使用Spark DataFrame Api。

需求7:按试卷分组统计每份试卷的倒数前三的用户详情,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。

需求8:统计各试卷各分段的用户id,分段有0-20,20-40,40-60,60-80,80-100。

需求9:统计试卷未及格的人数,及格的人数,试卷的及格率 及格分数60。
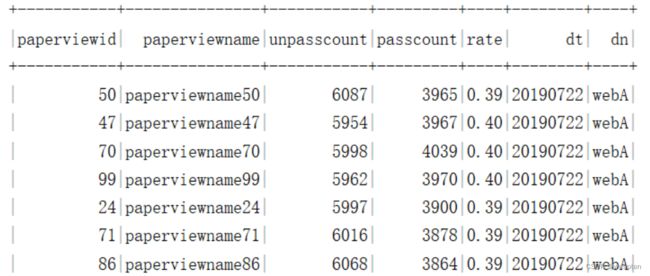
需求10:统计各题的错误数,正确数,错题率。
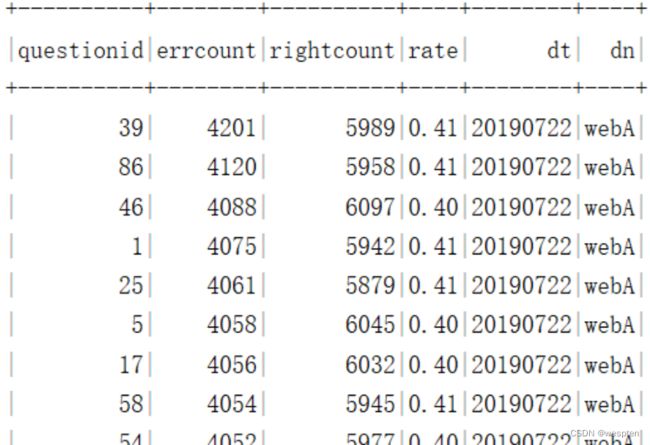
7、将数据导入mysql
需求11:统计指标数据导入到ads层后,通过datax将ads层数据导入到mysql中。
四、售课模块
1、原始数据格式及字段含义
salecourse.log 售课基本数据:
{
"chapterid": 2, //章节id
"chaptername": "chaptername2", //章节名称
"courseid": 0, //课程id
"coursemanager": "admin", //课程管理员
"coursename": "coursename0", //课程名称
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"edusubjectid": 7, //辅导科目id
"edusubjectname": "edusubjectname7", //辅导科目名称
"majorid": 9, //主修id
"majorname": "majorname9", //主修名称
"money": "100", //课程价格
"pointlistid": 9, //知识点列表id
"status": "-", //状态
"teacherid": 8, //老师id
"teachername": "teachername8" //老师名称
}courseshoppingcart.log 课程购物车信息:
{
"courseid": 9830, //课程id
"coursename": "coursename9830", //课程名称
"createtime": "2019-07-22 00:00:00", //创建时间
"discount": "8", //折扣
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"orderid": "odid-0", //订单id
"sellmoney": "80" //购物车金额
}coursepay.log 课程支付订单信息:
{
"createitme": "2019-07-22 00:00:00", //创建时间
"discount": "8", //支付折扣
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"orderid": "odid-0", //订单id
"paymoney": "80" //支付金额
}2、模拟数据采集上传数据
Hadoop dfs -put salecourse.log /user/yyds/ods
Hadoop dfs -put coursepay.log /user/yyds/ods
Hadoop dfs -put courseshoppingcart.log /user/yyds/ods3、解析数据导入到对应hive表中
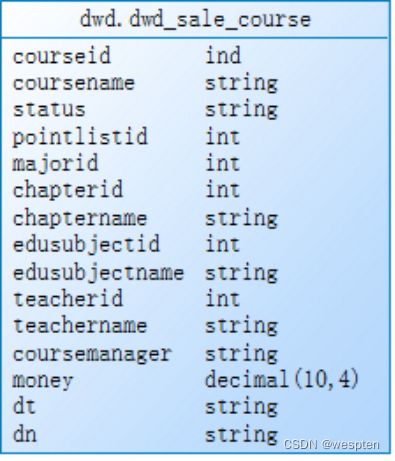
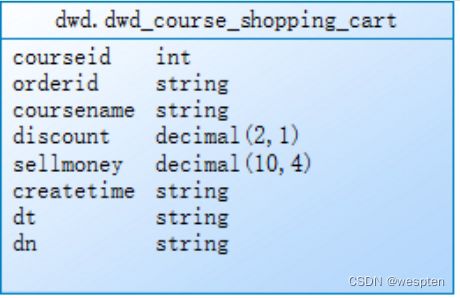

4、关联join聚合表
dwd.dwd_sale_course 与dwd.dwd_course_shopping_cart join条件:courseid、dn、dt
dwd.dwd_course_shopping_cart 与dwd.dwd_course_pay join条件:orderid、dn、dt
不允许丢数据,关联不上的字段为null,join之后导入dws层的表。
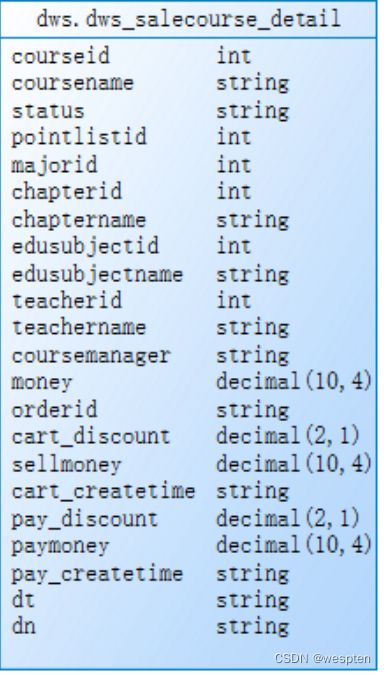
def etlBaseWebSiteLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/yyds/ods/baswewebsite.log").mapPartitions(partition => {
partition.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val siteid = jsonObject.getIntValue("siteid")
val sitename = jsonObject.getString("sitename")
val siteurl = jsonObject.getString("siteurl")
val delete = jsonObject.getIntValue("delete")
val createtime = jsonObject.getString("createtime")
val creator = jsonObject.getString("creator")
val dn = jsonObject.getString("dn")
(siteid, sitename, siteurl, delete, createtime, creator, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("dwd.dwd_base_website")
}五、数仓环境准备
1、为什么要分层

2、数仓命名规范
- ODS层命名为ods
- DWD层命名为dwd
- DWS层命名为dws
- ADS层命名为ads
- 临时表数据库命名为xxx_tmp
- 备份数据数据库命名为xxx_bak
3、Hive&MySQL安装
1)Hive安装部署
(1)把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt/software目录下
(2)解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
[yyds@hadoop102 software]$ tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/(3)修改apache-hive-1.2.1-bin.tar.gz的名称为hive
[yyds@hadoop102 module]$ mv apache-hive-1.2.1-bin/ hive(4)修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
[yyds@hadoop102 conf]$ mv hive-env.sh.template hive-env.sh(5)配置hive-env.sh文件
- 配置HADOOP_HOME路径
export HADOOP_HOME=/opt/module/hadoop-2.7.2- 配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/module/hive/conf2)Hadoop集群配置
(1)必须启动HDFS和YARN
[yyds@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[yyds@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh(2)在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
[yyds@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -mkdir /tmp
[yyds@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -mkdir -p /user/hive/warehouse
[yyds@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /tmp
[yyds@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /user/hive/warehouse3)Hive基本操作
(1)启动hive
[yyds@hadoop102 hive]$ bin/hive(2)查看数据库
hive> show databases;(3)打开默认数据库
hive> use default;(4)显示default数据库中的表
hive> show tables;(5)创建一张表
hive> create table student(id int, name string);(6)显示数据库中有几张表
hive> show tables;(7)查看表的结构
hive> desc student;(8)向表中插入数据
hive> insert into student values(1000,"ss");(9)查询表中数据
hive> select * from student;(10)退出hive
hive> quit;4)MySql安装包准备
查看mysql是否安装,如果安装了,卸载mysql:
(1)查看
[root@hadoop102 桌面]# rpm -qa|grep mysql
mysql-libs-5.1.73-7.el6.x86_64(2)卸载
[root@hadoop102 桌面]# rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64解压mysql-libs.zip文件到当前目录:
[root@hadoop102 software]# unzip mysql-libs.zip
[root@hadoop102 software]# ls
mysql-libs.zip
mysql-libs进入到mysql-libs文件夹下:
[root@hadoop102 mysql-libs]# ll
总用量 76048
-rw-r--r--. 1 root root 18509960 3月 26 2015 MySQL-client-5.6.24-1.el6.x86_64.rpm
-rw-r--r--. 1 root root 3575135 12月 1 2013 mysql-connector-java-5.1.27.tar.gz
-rw-r--r--. 1 root root 55782196 3月 26 2015 MySQL-server-5.6.24-1.el6.x86_64.rpm5)安装MySql服务器
安装mysql服务端:
[root@hadoop102 mysql-libs]# rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm查看产生的随机密码:
[root@hadoop102 mysql-libs]# cat /root/.mysql_secret
OEXaQuS8IWkG19Xs查看mysql状态:
[root@hadoop102 mysql-libs]# service mysql status启动mysql:
[root@hadoop102 mysql-libs]# service mysql start6)安装MySql客户端
安装mysql客户端:
[root@hadoop102 mysql-libs]# rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm链接mysql:
[root@hadoop102 mysql-libs]# mysql -uroot -pOEXaQuS8IWkG19Xs修改密码:
mysql>SET PASSWORD=PASSWORD('000000');退出mysql:
mysql>exit7)MySql中user表中主机配置
配置只要是root用户+密码,在任何主机上都能登录MySQL数据库。
进入mysql:
[root@hadoop102 mysql-libs]# mysql -uroot -p000000显示数据库:
mysql>show databases;使用mysql数据库:
mysql>use mysql;展示mysql数据库中的所有表:
mysql>show tables;展示user表的结构:
mysql>desc user;查询user表:
mysql>select User, Host, Password from user;修改user表,把Host表内容修改为%:
mysql>update user set host='%' where host='localhost';删除root用户的其他host:
mysql>
delete from user where Host='hadoop102';
delete from user where Host='127.0.0.1';
delete from user where Host='::1';刷新:
mysql>flush privileges;退出:
mysql>quit;4、Hive元数据配置到MySql
驱动拷贝:
在/opt/software/mysql-libs目录下解压mysql-connector-java-5.1.27.tar.gz驱动包。
[root@hadoop102 mysql-libs]# tar -zxvf mysql-connector-java-5.1.27.tar.gz拷贝/opt/software/mysql-libs/mysql-connector-java-5.1.27目录下的mysql-connector-java-5.1.27-bin.jar到/opt/module/hive/lib/:
[root@hadoop102 mysql-connector-java-5.1.27]# cp mysql-connector-java-5.1.27-bin.jar
/opt/module/hive/lib/配置Metastore到MySql:
在/opt/module/hive/conf目录下创建一个hive-site.xml。
[yyds@hadoop102 conf]$ vi hive-site.xml根据官方文档配置参数,拷贝数据到hive-site.xml文件中:
https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
000000
password to use against metastore database
配置完毕后,如果启动hive异常,可以重新启动虚拟机。(重启后,别忘了启动hadoop集群)。
5、Hive常见属性配置
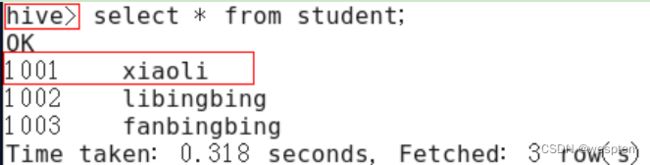
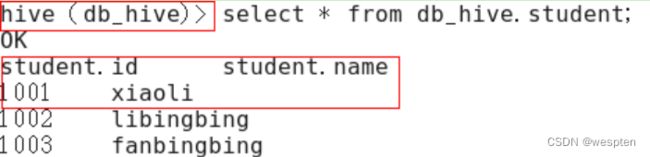
1)查询后信息显示配置
在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
hive.cli.print.header
true
hive.cli.print.current.db
true
重新启动hive,对比配置前后差异。
(1)配置前,如图所示:
配置后,如图所示:
2)Hive运行日志信息配置
1.Hive的log默认存放在/tmp/yyds/hive.log目录下(当前用户名下)
2.修改hive的log存放日志到/opt/module/hive/logs
(1)修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为
hive-log4j.properties:
[yyds@hadoop102 conf]$ pwd
/opt/module/hive/conf
[yyds@hadoop102 conf]$ mv hive-log4j.properties.template hive-log4j.properties在hive-log4j.properties文件中修改log存放位置:
hive.log.dir=/opt/module/hive/logs3)关闭元数据检查
[yyds@hadoop102 conf]$ pwd
/opt/module/hive/conf
[yyds@hadoop102 conf]$ vim hive-site.xml增加如下配置:
hive.metastore.schema.verification
false
6、Spark集群安装
机器准备:
准备三台Linux服务器,安装好JDK1.8。
下载Spark安装包:
上传解压安装包:
上传spark-2.1.1-bin-hadoop2.7.tgz安装包到Linux上。
解压安装包到指定位置:
tar -xf spark-2.1.1-bin-hadoop2.7.tgz -C /home/bigdata/Hadoop![]()
配置Spark【Yarn】:
修改Hadoop配置下的yarn-site.xml。
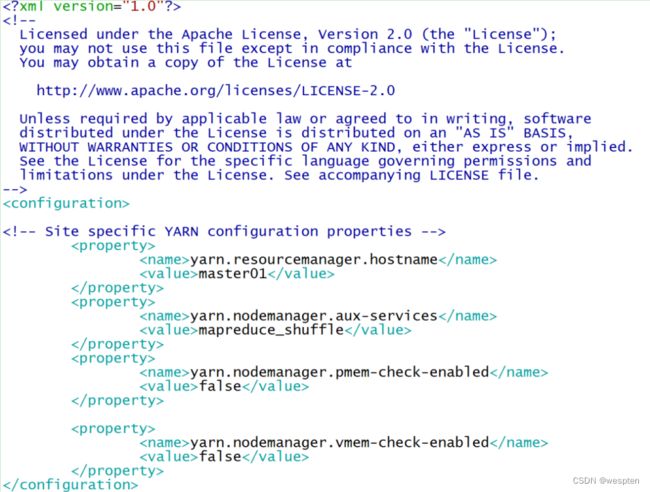
yarn.resourcemanager.hostname
master01
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
修改Spark-env.sh 添加:
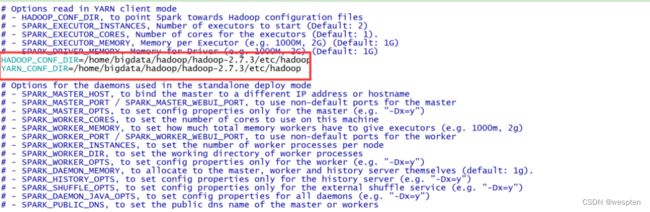
让Spark能够发现Hadoop配置文件:
HADOOP_CONF_DIR=/home/bigdata/hadoop/hadoop-2.7.3/etc/hadoop
YARN_CONF_DIR=/home/bigdata/hadoop/hadoop-2.7.3/etc/hadoop让Spark能够发现Hadoop配置文件。
启动spark history server:
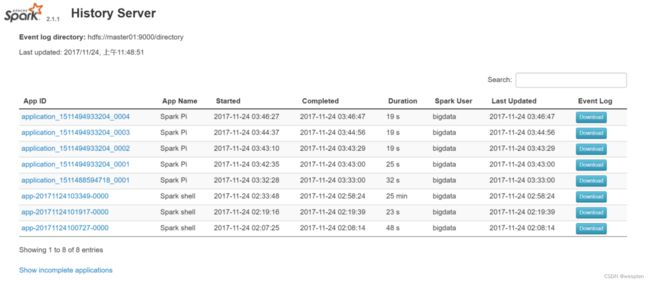
可以查看日志。
六、Maven项目创建
新建Maven项目:

创建子项目:
配置主目录pom.xml:
4.0.0
com.yyds
education-online
pom
1.0-SNAPSHOT
com_yyds_warehouse
2.1.1
2.11.8
1.2.17
1.7.22
org.slf4j
jcl-over-slf4j
${slf4j.version}
org.slf4j
slf4j-api
${slf4j.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
log4j
log4j
${log4j.version}
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-streaming_2.11
${spark.version}
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-hive_2.11
${spark.version}
org.apache.maven.plugins
maven-compiler-plugin
3.6.1
1.8
1.8
net.alchim31.maven
scala-maven-plugin
3.2.2
compile
testCompile
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
make-assembly
package
single
配置子项目pom.xml:
education-online
com.yyds
1.0-SNAPSHOT
4.0.0
com_yyds_warehouse
org.apache.spark
spark-core_2.11
${spark.version}
provided
org.apache.spark
spark-sql_2.11
${spark.version}
provided
org.apache.spark
spark-hive_2.11
${spark.version}
provided
org.scala-lang
scala-library
provided
com.alibaba
fastjson
1.2.47
org.scala-tools
maven-scala-plugin
2.15.1
compile-scala
add-source
compile
test-compile-scala
add-source
testCompile
org.apache.maven.plugins
maven-assembly-plugin
jar-with-dependencies
添加scala库支持:

Bean 目录下存放实体类;
Controller 目录下存放程序入口类;
Dao 目录下存放各表sql类;
Service 目录下存放各表业务类;
Util目录下存放工具类;
七、用户注册模块数仓设计与实现
1、用户注册模块数仓设计
1)原始数据格式及字段含义
baseadlog 广告基础表原始json数据:
{
"adid": "0", //基础广告表广告id
"adname": "注册弹窗广告0", //广告详情名称
"dn": "webA" //网站分区
}basewebsitelog 网站基础表原始json数据:
{
"createtime": "2000-01-01",
"creator": "admin",
"delete": "0",
"dn": "webC", //网站分区
"siteid": "2", //网站id
"sitename": "114", //网站名称
"siteurl": "www.114.com/webC" //网站地址
}memberRegtype 用户跳转地址注册表:
{
"appkey": "-",
"appregurl": "http:www.webA.com/product/register/index.html", //注册时跳转地址
"bdp_uuid": "-",
"createtime": "2015-05-11",
"dt":"20190722", //日期分区
"dn": "webA", //网站分区
"domain": "-",
"isranreg": "-",
"regsource": "4", //所属平台 1.PC 2.MOBILE 3.APP 4.WECHAT
"uid": "0", //用户id
"websiteid": "0" //对应basewebsitelog 下的siteid网站
}pcentermempaymoneylog 用户支付金额表:
{
"dn": "webA", //网站分区
"paymoney": "162.54", //支付金额
"siteid": "1", //网站id对应 对应basewebsitelog 下的siteid网站
"dt":"20190722", //日期分区
"uid": "4376695", //用户id
"vip_id": "0" //对应pcentermemviplevellog vip_id
}pcentermemviplevellog用户vip等级基础表:
{
"discountval": "-",
"dn": "webA", //网站分区
"end_time": "2019-01-01", //vip结束时间
"last_modify_time": "2019-01-01",
"max_free": "-",
"min_free": "-",
"next_level": "-",
"operator": "update",
"start_time": "2015-02-07", //vip开始时间
"vip_id": "2", //vip id
"vip_level": "银卡" //vip级别名称
}memberlog 用户基本信息表:
{
"ad_id": "0", //广告id
"birthday": "1981-08-14", //出生日期
"dt":"20190722", //日期分区
"dn": "webA", //网站分区
"email": "[email protected]",
"fullname": "王69239", //用户姓名
"iconurl": "-",
"lastlogin": "-",
"mailaddr": "-",
"memberlevel": "6", //用户级别
"password": "123456", //密码
"paymoney": "-",
"phone": "13711235451", //手机号
"qq": "10000",
"register": "2016-08-15", //注册时间
"regupdatetime": "-",
"uid": "69239", //用户id
"unitname": "-",
"userip": "123.235.75.48", //ip地址
"zipcode": "-"
}其余字段为非统计项 直接使用默认值“-”存储即可。
2)数据分层
在hadoop集群上创建 ods目录:
hadoop dfs -mkdir /user/yyds/ods在hive里分别建立三个库,dwd、dws、ads 分别用于存储etl清洗后的数据、宽表和拉链表数据、各报表层统计指标数据:
create database dwd;
create database dws;
create database ads;各层级:
- ods 存放原始数据
- dwd 结构与原始表结构保持一致,对ods层数据进行清洗
- dws 以dwd为基础进行轻度汇总
- ads 报表层,为各种统计报表提供数据
用户注册模块各层建表语句:
create external table `dwd`.`dwd_member`(
uid int,
ad_id int,
birthday string,
email string,
fullname string,
iconurl string,
lastlogin string,
mailaddr string,
memberlevel string,
password string,
paymoney string,
phone string,
qq string,
register string,
regupdatetime string,
unitname string,
userip string,
zipcode string)
partitioned by(
dt string,
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_member_regtype`(
uid int,
appkey string,
appregurl string,
bdp_uuid string,
createtime timestamp,
isranreg string,
regsource string,
regsourcename string,
websiteid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_base_ad`(
adid int,
adname string)
partitioned by (
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_base_website`(
siteid int,
sitename string,
siteurl string,
`delete` int,
createtime timestamp,
creator string)
partitioned by (
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_pcentermempaymoney`(
uid int,
paymoney string,
siteid int,
vip_id int
)
partitioned by(
dt string,
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_vip_level`(
vip_id int,
vip_level string,
start_time timestamp,
end_time timestamp,
last_modify_time timestamp,
max_free string,
min_free string,
next_level string,
operator string
)partitioned by(
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_member`(
uid int,
ad_id int,
fullname string,
iconurl string,
lastlogin string,
mailaddr string,
memberlevel string,
password string,
paymoney string,
phone string,
qq string,
register string,
regupdatetime string,
unitname string,
userip string,
zipcode string,
appkey string,
appregurl string,
bdp_uuid string,
reg_createtime timestamp,
isranreg string,
regsource string,
regsourcename string,
adname string,
siteid int,
sitename string,
siteurl string,
site_delete string,
site_createtime string,
site_creator string,
vip_id int,
vip_level string,
vip_start_time timestamp,
vip_end_time timestamp,
vip_last_modify_time timestamp,
vip_max_free string,
vip_min_free string,
vip_next_level string,
vip_operator string
)partitioned by(
dt string,
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_member_zipper`(
uid int,
paymoney string,
vip_level string,
start_time timestamp,
end_time timestamp
)partitioned by(
dn string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `ads`.`ads_register_appregurlnum`(
appregurl string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_sitenamenum`(
sitename string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_regsourcenamenum`(
regsourcename string,
num int
)partitioned by(
dt string,
dn string
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_adnamenum`(
adname string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_memberlevelnum`(
memberlevel string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_viplevelnum`(
vip_level string,
num int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
create external table `ads`.`ads_register_top3memberpay`(
uid int,
memberlevel string,
register string,
appregurl string,
regsourcename string,
adname string,
sitename string,
vip_level string,
paymoney decimal(10,4),
rownum int
)partitioned by(
dt string,
dn string
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
表模型:
dwd层 6张基础表。

dws层 宽表和拉链表:
宽表:
拉链表:
报表层各统计表:

3)模拟数据采集上传数据
模拟数据采集 将日志文件数据直接上传到hadoop集群上:
hadoop dfs -put baseadlog.log /user/yyds/ods/
hadoop dfs -put memberRegtype.log /user/yyds/ods/
hadoop dfs -put baswewebsite.log /user/yyds/ods/
hadoop dfs -put pcentermempaymoney.log /user/yyds/ods/
hadoop dfs -put pcenterMemViplevel.log /user/yyds/ods/
hadoop dfs -put member.log /user/yyds/ods/
4)ETL数据清洗
需求1:必须使用Spark进行数据清洗,对用户名、手机号、密码进行脱敏处理,并使用Spark将数据导入到dwd层hive表中
清洗规则 用户名:王XX 手机号:137*****789 密码直接替换成*****
5)基于dwd层表合成dws层的宽表
需求2:对dwd层的6张表进行合并,生成一张宽表,先使用Spark Sql实现。有时间的同学需要使用DataFrame api实现功能,并对join进行优化。
6)拉链表
需求3:针对dws层宽表的支付金额(paymoney)和vip等级(vip_level)这两个会变动的字段生成一张拉链表,需要一天进行一次更新。
7)报表层各指标统计
需求4:使用Spark DataFrame Api统计通过各注册跳转地址(appregurl)进行注册的用户数,有时间的再写Spark Sql;
需求5:使用Spark DataFrame Api统计各所属网站(sitename)的用户数,有时间的再写Spark Sql;
需求6:使用Spark DataFrame Api统计各所属平台的(regsourcename)用户数,有时间的再写Spark Sql;
需求7:使用Spark DataFrame Api统计通过各广告跳转(adname)的用户数,有时间的再写Spark Sql;
需求8:使用Spark DataFrame Api统计各用户级别(memberlevel)的用户数,有时间的再写Spark Sql;
需求9:使用Spark DataFrame Api统计各分区网站、用户级别下(dn、memberlevel)的top3用户,有时间的再写Spark Sql;
2、用户注册模块代码实现
1)准备样例类
package com.yyds.member.bean
case class MemberZipper(
uid: Int,
var paymoney: String,
vip_level: String,
start_time: String,
var end_time: String,
dn: String
)
case class MemberZipperResult(list: List[MemberZipper])
case class QueryResult(
uid: Int,
ad_id: Int,
memberlevel: String,
register: String,
appregurl: String, //注册来源url
regsource: String,
regsourcename: String,
adname: String,
siteid: String,
sitename: String,
vip_level: String,
paymoney: BigDecimal,
dt: String,
dn: String
)
case class DwsMember(
uid: Int,
ad_id: Int,
fullname: String,
iconurl: String,
lastlogin: String,
mailaddr: String,
memberlevel: String,
password: String,
paymoney: BigDecimal,
phone: String,
qq: String,
register: String,
regupdatetime: String,
unitname: String,
userip: String,
zipcode: String,
appkey: String,
appregurl: String,
bdp_uuid: String,
reg_createtime: String,
isranreg: String,
regsource: String,
regsourcename: String,
adname: String,
siteid: String,
sitename: String,
siteurl: String,
site_delete: String,
site_createtime: String,
site_creator: String,
vip_id: String,
vip_level: String,
vip_start_time: String,
vip_end_time: String,
vip_last_modify_time: String,
vip_max_free: String,
vip_min_free: String,
vip_next_level: String,
vip_operator: String,
dt: String,
dn: String
)
case class DwsMember_Result(
uid: Int,
ad_id: Int,
fullname: String,
icounurl: String,
lastlogin: String,
mailaddr: String,
memberlevel: String,
password: String,
paymoney: String,
phone: String,
qq: String,
register: String,
regupdatetime: String,
unitname: String,
userip: String,
zipcode: String,
appkey: String,
appregurl: String,
bdp_uuid: String,
reg_createtime: String,
isranreg: String,
regsource: String,
regsourcename: String,
adname: String,
siteid: String,
sitename: String,
siteurl: String,
site_delete: String,
site_createtime: String,
site_creator: String,
vip_id: String,
vip_level: String,
vip_start_time: String,
vip_end_time: String,
vip_last_modify_time: String,
vip_max_free: String,
vip_min_free: String,
vip_next_level: String,
vip_operator: String,
dt: String,
dn: String
)2)创建工具类
解析json使用fastjson,在util下创建ParseJosnData工具类:
package com.yyds.util;
import com.alibaba.fastjson.JSONObject;
public class ParseJsonData {
public static JSONObject getJsonData(String data) {
try {
return JSONObject.parseObject(data);
} catch (Exception e) {
return null;
}
}
}在util包下创建Hive工具HiveUtil类:
package com.yyds.util
import org.apache.spark.sql.SparkSession
object HiveUtil {
/**
* 调大最大分区个数
* @param spark
* @return
*/
def setMaxpartitions(spark: SparkSession)={
spark.sql("set hive.exec.dynamic.partition=true")
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict")
spark.sql("set hive.exec.max.dynamic.partitions=100000")
spark.sql("set hive.exec.max.dynamic.partitions.pernode=100000")
spark.sql("set hive.exec.max.created.files=100000")
}
/**
* 开启压缩
*
* @param spark
* @return
*/
def openCompression(spark: SparkSession) = {
spark.sql("set mapred.output.compress=true")
spark.sql("set hive.exec.compress.output=true")
}
/**
* 开启动态分区,非严格模式
*
* @param spark
*/
def openDynamicPartition(spark: SparkSession) = {
spark.sql("set hive.exec.dynamic.partition=true")
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict")
}
/**
* 使用lzo压缩
*
* @param spark
*/
def useLzoCompression(spark: SparkSession) = {
spark.sql("set io.compression.codec.lzo.class=com.hadoop.compression.lzo.LzoCodec")
spark.sql("set mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec")
}
/**
* 使用snappy压缩
* @param spark
*/
def useSnappyCompression(spark:SparkSession)={
spark.sql("set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec");
spark.sql("set mapreduce.output.fileoutputformat.compress=true")
spark.sql("set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec")
}
}3)对日志进行数据清洗导入
收集日志原始数据后 我们需要对日志原始数据进行清洗 将清洗后的数据存入dwd层表
创建EtlDatService清洗类,使用该类读取hdfs上的原始日志数据,对原始日志进行清洗处理,对敏感字段姓名、电话做脱敏处理。filter对不能正常转换json数据的日志数据进行过滤,mappartiton针对每个分区去做数据循环map操作组装成对应表需要的字段,重组完之后coalesce缩小分区(减少文件个数)刷新到目标表中。
package com.yyds.member.service
import com.alibaba.fastjson.JSONObject
import com.yyds.util.ParseJsonData
import org.apache.spark.SparkContext
import org.apache.spark.sql.{SaveMode, SparkSession}
object EtlDataService {
/**
* etl用户注册信息
*
* @param ssc
* @param sparkSession
*/
def etlMemberRegtypeLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/yyds/ods/memberRegtype.log")
.filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitoin => {
partitoin.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val appkey = jsonObject.getString("appkey")
val appregurl = jsonObject.getString("appregurl")
val bdp_uuid = jsonObject.getString("bdp_uuid")
val createtime = jsonObject.getString("createtime")
val isranreg = jsonObject.getString("isranreg")
val regsource = jsonObject.getString("regsource")
val regsourceName = regsource match {
case "1" => "PC"
case "2" => "Mobile"
case "3" => "App"
case "4" => "WeChat"
case _ => "other"
}
val uid = jsonObject.getIntValue("uid")
val websiteid = jsonObject.getIntValue("websiteid")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(uid, appkey, appregurl, bdp_uuid, createtime, isranreg, regsource, regsourceName, websiteid, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_member_regtype")
}
/**
* etl用户表数据
*
* @param ssc
* @param sparkSession
*/
def etlMemberLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/yyds/ods/member.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partition => {
partition.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val ad_id = jsonObject.getIntValue("ad_id")
val birthday = jsonObject.getString("birthday")
val email = jsonObject.getString("email")
val fullname = jsonObject.getString("fullname").substring(0, 1) + "xx"
val iconurl = jsonObject.getString("iconurl")
val lastlogin = jsonObject.getString("lastlogin")
val mailaddr = jsonObject.getString("mailaddr")
val memberlevel = jsonObject.getString("memberlevel")
val password = "******"
val paymoney = jsonObject.getString("paymoney")
val phone = jsonObject.getString("phone")
val newphone = phone.substring(0, 3) + "*****" + phone.substring(7, 11)
val qq = jsonObject.getString("qq")
val register = jsonObject.getString("register")
val regupdatetime = jsonObject.getString("regupdatetime")
val uid = jsonObject.getIntValue("uid")
val unitname = jsonObject.getString("unitname")
val userip = jsonObject.getString("userip")
val zipcode = jsonObject.getString("zipcode")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(uid, ad_id, birthday, email, fullname, iconurl, lastlogin, mailaddr, memberlevel, password, paymoney, newphone, qq,
register, regupdatetime, unitname, userip, zipcode, dt, dn)
})
}).toDF().coalesce(2).write.mode(SaveMode.Append).insertInto("dwd.dwd_member")
}
/**
* 导入广告表基础数据
*
* @param ssc
* @param sparkSession
*/
def etlBaseAdLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
val result = ssc.textFile("/user/yyds/ods/baseadlog.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partition => {
partition.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val adid = jsonObject.getIntValue("adid")
val adname = jsonObject.getString("adname")
val dn = jsonObject.getString("dn")
(adid, adname, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("dwd.dwd_base_ad")
}
/**
* 导入网站表基础数据
*
* @param ssc
* @param sparkSession
*/
def etlBaseWebSiteLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/yyds/ods/baswewebsite.log").filter(item => {
val obj = ParseJsonData.getJsonDat a(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partition => {
partition.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val siteid = jsonObject.getIntValue("siteid")
val sitename = jsonObject.getString("sitename")
val siteurl = jsonObject.getString("siteurl")
val delete = jsonObject.getIntValue("delete")
val createtime = jsonObject.getString("createtime")
val creator = jsonObject.getString("creator")
val dn = jsonObject.getString("dn")
(siteid, sitename, siteurl, delete, createtime, creator, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("dwd.dwd_base_website")
}
/**
* 导入用户付款信息
*
* @param ssc
* @param sparkSession
*/
def etlMemPayMoneyLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/yyds/ods/pcentermempaymoney.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partition => {
partition.map(item => {
val jSONObject = ParseJsonData.getJsonData(item)
val paymoney = jSONObject.getString("paymoney")
val uid = jSONObject.getIntValue("uid")
val vip_id = jSONObject.getIntValue("vip_id")
val site_id = jSONObject.getIntValue("siteid")
val dt = jSONObject.getString("dt")
val dn = jSONObject.getString("dn")
(uid, paymoney, site_id, vip_id, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_pcentermempaymoney")
}
/**
* 导入用户vip基础数据
*
* @param ssc
* @param sparkSession
*/
def etlMemVipLevelLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/yyds/ods/pcenterMemViplevel.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partition => {
partition.map(item => {
val jSONObject = ParseJsonData.getJsonData(item)
val discountval = jSONObject.getString("discountval")
val end_time = jSONObject.getString("end_time")
val last_modify_time = jSONObject.getString("last_modify_time")
val max_free = jSONObject.getString("max_free")
val min_free = jSONObject.getString("min_free")
val next_level = jSONObject.getString("next_level")
val operator = jSONObject.getString("operator")
val start_time = jSONObject.getString("start_time")
val vip_id = jSONObject.getIntValue("vip_id")
val vip_level = jSONObject.getString("vip_level")
val dn = jSONObject.getString("dn")
(vip_id, vip_level, start_time, end_time, last_modify_time, max_free, min_free, next_level, operator, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("dwd.dwd_vip_level")
}
}4)创建DwdMemberController
package com.yyds.member.controller
import com.yyds.member.service.EtlDataService
import com.yyds.util.HiveUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DwdMemberController {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "yyds")
val sparkConf = new SparkConf().setAppName("dwd_member_import").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
HiveUtil.openDynamicPartition(sparkSession) //开启动态分区
HiveUtil.openCompression(sparkSession) //开启压缩
HiveUtil.useSnappyCompression(sparkSession) //使用snappy压缩
//对用户原始数据进行数据清洗 存入bdl层表中
EtlDataService.etlBaseAdLog(ssc, sparkSession) //导入基础广告表数据
EtlDataService.etlBaseWebSiteLog(ssc, sparkSession) //导入基础网站表数据
EtlDataService.etlMemberLog(ssc, sparkSession) //清洗用户数据
EtlDataService.etlMemberRegtypeLog(ssc, sparkSession) //清洗用户注册数据
EtlDataService.etlMemPayMoneyLog(ssc, sparkSession) //导入用户支付情况记录
EtlDataService.etlMemVipLevelLog(ssc, sparkSession) //导入vip基础数据
}
}5)创建DwdMemberDao
package com.yyds.member.dao
import org.apache.spark.sql.SparkSession
object DwdMemberDao {
def getDwdMember(sparkSession: SparkSession) = {
sparkSession.sql("select uid,ad_id,email,fullname,iconurl,lastlogin,mailaddr,memberlevel," +
"password,phone,qq,register,regupdatetime,unitname,userip,zipcode,dt,dn from dwd.dwd_member")
}
def getDwdMemberRegType(sparkSession: SparkSession) = {
sparkSession.sql("select uid,appkey,appregurl,bdp_uuid,createtime as reg_createtime,domain,isranreg," +
"regsource,regsourcename,websiteid as siteid,dn from dwd.dwd_member_regtype ")
}
def getDwdBaseAd(sparkSession: SparkSession) = {
sparkSession.sql("select adid as ad_id,adname,dn from dwd.dwd_base_ad")
}
def getDwdBaseWebSite(sparkSession: SparkSession) = {
sparkSession.sql("select siteid,sitename,siteurl,delete as site_delete," +
"createtime as site_createtime,creator as site_creator,dn from dwd.dwd_base_website")
}
def getDwdVipLevel(sparkSession: SparkSession) = {
sparkSession.sql("select vip_id,vip_level,start_time as vip_start_time,end_time as vip_end_time," +
"last_modify_time as vip_last_modify_time,max_free as vip_max_free,min_free as vip_min_free," +
"next_level as vip_next_level,operator as vip_operator,dn from dwd.dwd_vip_level")
}
def getDwdPcentermemPayMoney(sparkSession: SparkSession) = {
sparkSession.sql("select uid,cast(paymoney as decimal(10,4)) as paymoney,vip_id,dn from dwd.dwd_pcentermempaymoney")
}
}6)基于dwd层表合成dws层的宽表和拉链表
宽表两种方式实现:
一种查询各单表基于单表dataframe使用 join算子得到结果,再使用groupbykey算子去重和取最大最小值等操作得到最终结果。
一种使用spark sql直接实现。
package com.yyds.member.service
import com.yyds.member.bean.{DwsMember, DwsMember_Result, MemberZipper, MemberZipperResult}
import com.yyds.member.dao.DwdMemberDao
import org.apache.spark.sql.{SaveMode, SparkSession}
object DwsMemberService {
def importMemberUseApi(sparkSession: SparkSession, dt: String) = {
import sparkSession.implicits._ //隐式转换
val dwdMember = DwdMemberDao.getDwdMember(sparkSession).where(s"dt='${dt}'") //主表用户表
val dwdMemberRegtype = DwdMemberDao.getDwdMemberRegType(sparkSession)
val dwdBaseAd = DwdMemberDao.getDwdBaseAd(sparkSession)
val dwdBaseWebsite = DwdMemberDao.getDwdBaseWebSite(sparkSession)
val dwdPcentermemPaymoney = DwdMemberDao.getDwdPcentermemPayMoney(sparkSession)
val dwdVipLevel = DwdMemberDao.getDwdVipLevel(sparkSession)
import org.apache.spark.sql.functions.broadcast
val result = dwdMember.join(dwdMemberRegtype, Seq("uid", "dn"), "left_outer")
.join(broadcast(dwdBaseAd), Seq("ad_id", "dn"), "left_outer")
.join(broadcast(dwdBaseWebsite), Seq("siteid", "dn"), "left_outer")
.join(broadcast(dwdPcentermemPaymoney), Seq("uid", "dn"), "left_outer")
.join(broadcast(dwdVipLevel), Seq("vip_id", "dn"), "left_outer")
.select("uid", "ad_id", "fullname", "iconurl", "lastlogin", "mailaddr", "memberlevel", "password"
, "paymoney", "phone", "qq", "register", "regupdatetime", "unitname", "userip", "zipcode", "appkey"
, "appregurl", "bdp_uuid", "reg_createtime", "domain", "isranreg", "regsource", "regsourcename", "adname"
, "siteid", "sitename", "siteurl", "site_delete", "site_createtime", "site_creator", "vip_id", "vip_level",
"vip_start_time", "vip_end_time", "vip_last_modify_time", "vip_max_free", "vip_min_free", "vip_next_level"
, "vip_operator", "dt", "dn").as[DwsMember]
result.groupByKey(item => item.uid + "_" + item.dn)
.mapGroups { case (key, iters) =>
val keys = key.split("_")
val uid = Integer.parseInt(keys(0))
val dn = keys(1)
val dwsMembers = iters.toList
val paymoney = dwsMembers.filter(_.paymoney != null).map(_.paymoney).reduceOption(_ + _).getOrElse(BigDecimal.apply(0.00)).toString
val ad_id = dwsMembers.map(_.ad_id).head
val fullname = dwsMembers.map(_.fullname).head
val icounurl = dwsMembers.map(_.iconurl).head
val lastlogin = dwsMembers.map(_.lastlogin).head
val mailaddr = dwsMembers.map(_.mailaddr).head
val memberlevel = dwsMembers.map(_.memberlevel).head
val password = dwsMembers.map(_.password).head
val phone = dwsMembers.map(_.phone).head
val qq = dwsMembers.map(_.qq).head
val register = dwsMembers.map(_.register).head
val regupdatetime = dwsMembers.map(_.regupdatetime).head
val unitname = dwsMembers.map(_.unitname).head
val userip = dwsMembers.map(_.userip).head
val zipcode = dwsMembers.map(_.zipcode).head
val appkey = dwsMembers.map(_.appkey).head
val appregurl = dwsMembers.map(_.appregurl).head
val bdp_uuid = dwsMembers.map(_.bdp_uuid).head
val reg_createtime = dwsMembers.map(_.reg_createtime).head
val domain = dwsMembers.map(_.domain).head
val isranreg = dwsMembers.map(_.isranreg).head
val regsource = dwsMembers.map(_.regsource).head
val regsourcename = dwsMembers.map(_.regsourcename).head
val adname = dwsMembers.map(_.adname).head
val siteid = dwsMembers.map(_.siteid).head
val sitename = dwsMembers.map(_.sitename).head
val siteurl = dwsMembers.map(_.siteurl).head
val site_delete = dwsMembers.map(_.site_delete).head
val site_createtime = dwsMembers.map(_.site_createtime).head
val site_creator = dwsMembers.map(_.site_creator).head
val vip_id = dwsMembers.map(_.vip_id).head
val vip_level = dwsMembers.map(_.vip_level).max
val vip_start_time = dwsMembers.map(_.vip_start_time).min
val vip_end_time = dwsMembers.map(_.vip_end_time).max
val vip_last_modify_time = dwsMembers.map(_.vip_last_modify_time).max
val vip_max_free = dwsMembers.map(_.vip_max_free).head
val vip_min_free = dwsMembers.map(_.vip_min_free).head
val vip_next_level = dwsMembers.map(_.vip_next_level).head
val vip_operator = dwsMembers.map(_.vip_operator).head
DwsMember_Result(uid, ad_id, fullname, icounurl, lastlogin, mailaddr, memberlevel, password, paymoney,
phone, qq, register, regupdatetime, unitname, userip, zipcode, appkey, appregurl,
bdp_uuid, reg_createtime, domain, isranreg, regsource, regsourcename, adname, siteid,
sitename, siteurl, site_delete, site_createtime, site_creator, vip_id, vip_level,
vip_start_time, vip_end_time, vip_last_modify_time, vip_max_free, vip_min_free,
vip_next_level, vip_operator, dt, dn)
}.show()
}
def importMember(sparkSession: SparkSession, time: String) = {
import sparkSession.implicits._ //隐式转换
//查询全量数据 刷新到宽表
sparkSession.sql("select uid,first(ad_id),first(fullname),first(iconurl),first(lastlogin)," +
"first(mailaddr),first(memberlevel),first(password),sum(cast(paymoney as decimal(10,4))),first(phone),first(qq)," +
"first(register),first(regupdatetime),first(unitname),first(userip),first(zipcode)," +
"first(appkey),first(appregurl),first(bdp_uuid),first(reg_createtime),first(domain)," +
"first(isranreg),first(regsource),first(regsourcename),first(adname),first(siteid),first(sitename)," +
"first(siteurl),first(site_delete),first(site_createtime),first(site_creator),first(vip_id),max(vip_level)," +
"min(vip_start_time),max(vip_end_time),max(vip_last_modify_time),first(vip_max_free),first(vip_min_free),max(vip_next_level)," +
"first(vip_operator),dt,dn from" +
"(select a.uid,a.ad_id,a.fullname,a.iconurl,a.lastlogin,a.mailaddr,a.memberlevel," +
"a.password,e.paymoney,a.phone,a.qq,a.register,a.regupdatetime,a.unitname,a.userip," +
"a.zipcode,a.dt,b.appkey,b.appregurl,b.bdp_uuid,b.createtime as reg_createtime,b.domain,b.isranreg,b.regsource," +
"b.regsourcename,c.adname,d.siteid,d.sitename,d.siteurl,d.delete as site_delete,d.createtime as site_createtime," +
"d.creator as site_creator,f.vip_id,f.vip_level,f.start_time as vip_start_time,f.end_time as vip_end_time," +
"f.last_modify_time as vip_last_modify_time,f.max_free as vip_max_free,f.min_free as vip_min_free," +
"f.next_level as vip_next_level,f.operator as vip_operator,a.dn " +
s"from dwd.dwd_member a left join dwd.dwd_member_regtype b on a.uid=b.uid " +
"and a.dn=b.dn left join dwd.dwd_base_ad c on a.ad_id=c.adid and a.dn=c.dn left join " +
" dwd.dwd_base_website d on b.websiteid=d.siteid and b.dn=d.dn left join dwd.dwd_pcentermempaymoney e" +
s" on a.uid=e.uid and a.dn=e.dn left join dwd.dwd_vip_level f on e.vip_id=f.vip_id and e.dn=f.dn where a.dt='${time}')r " +
"group by uid,dn,dt").coalesce(3).write.mode(SaveMode.Overwrite).insertInto("dws.dws_member")
//查询当天增量数据
val dayResult = sparkSession.sql(s"select a.uid,sum(cast(a.paymoney as decimal(10,4))) as paymoney,max(b.vip_level) as vip_level," +
s"from_unixtime(unix_timestamp('$time','yyyyMMdd'),'yyyy-MM-dd') as start_time,'9999-12-31' as end_time,first(a.dn) as dn " +
" from dwd.dwd_pcentermempaymoney a join " +
s"dwd.dwd_vip_level b on a.vip_id=b.vip_id and a.dn=b.dn where a.dt='$time' group by uid").as[MemberZipper]
//查询历史拉链表数据
val historyResult = sparkSession.sql("select *from dws.dws_member_zipper").as[MemberZipper]
//两份数据根据用户id进行聚合 对end_time进行重新修改
val reuslt = dayResult.union(historyResult).groupByKey(item => item.uid + "_" + item.dn)
.mapGroups { case (key, iters) =>
val keys = key.split("_")
val uid = keys(0)
val dn = keys(1)
val list = iters.toList.sortBy(item => item.start_time) //对开始时间进行排序
if (list.size > 1 && "9999-12-31".equals(list(list.size - 2).end_time)) {
//如果存在历史数据 需要对历史数据的end_time进行修改
//获取历史数据的最后一条数据
val oldLastModel = list(list.size - 2)
//获取当前时间最后一条数据
val lastModel = list(list.size - 1)
oldLastModel.end_time = lastModel.start_time
lastModel.paymoney = list.map(item => BigDecimal.apply(item.paymoney)).sum.toString
}
MemberZipperResult(list)
}.flatMap(_.list).coalesce(3).write.mode(SaveMode.Overwrite).insertInto("dws.dws_member_zipper") //重组对象打散 刷新拉链表
}
}7)创建DwsMemberController
package com.yyds.member.controller
import com.yyds.member.service.DwsMemberService
import com.yyds.util.HiveUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DwsMemberController {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "yyds")
val sparkConf = new SparkConf().setAppName("dws_member_import")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
HiveUtil.openDynamicPartition(sparkSession) //开启动态分区
HiveUtil.openCompression(sparkSession) //开启压缩
HiveUtil.useSnappyCompression(sparkSession) //使用snappy压缩
DwsMemberService.importMember(sparkSession, "20190722") //根据用户信息聚合用户表数据
// DwsMemberService.importMemberUseApi(sparkSession, "20190722")
}
}8)创建DwsMemberDao
package com.yyds.member.dao
import org.apache.spark.sql.SparkSession
object DwsMemberDao {
/**
* 查询用户宽表数据
*
* @param sparkSession
* @return
*/
def queryIdlMemberData(sparkSession: SparkSession) = {
sparkSession.sql("select uid,ad_id,memberlevel,register,appregurl,regsource,regsourcename,adname," +
"siteid,sitename,vip_level,cast(paymoney as decimal(10,4)) as paymoney,dt,dn from dws.dws_member ")
}
/**
* 统计注册来源url人数
*
* @param sparkSession
*/
def queryAppregurlCount(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select appregurl,count(uid),dn,dt from dws.dws_member where dt='${dt}' group by appregurl,dn,dt")
}
//统计所属网站人数
def querySiteNameCount(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select sitename,count(uid),dn,dt from dws.dws_member where dt='${dt}' group by sitename,dn,dt")
}
//统计所属来源人数
def queryRegsourceNameCount(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select regsourcename,count(uid),dn,dt from dws.dws_member where dt='${dt}' group by regsourcename,dn,dt ")
}
//统计通过各广告注册的人数
def queryAdNameCount(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select adname,count(uid),dn,dt from dws.dws_member where dt='${dt}' group by adname,dn,dt")
}
//统计各用户等级人数
def queryMemberLevelCount(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select memberlevel,count(uid),dn,dt from dws.dws_member where dt='${dt}' group by memberlevel,dn,dt")
}
//统计各用户vip等级人数
def queryVipLevelCount(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select vip_level,count(uid),dn,dt from dws.dws_member group where dt='${dt}' by vip_level,dn,dt")
}
//统计各memberlevel等级 支付金额前三的用户
def getTop3MemberLevelPayMoneyUser(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select *from(select uid,ad_id,memberlevel,register,appregurl,regsource" +
",regsourcename,adname,siteid,sitename,vip_level,cast(paymoney as decimal(10,4)),row_number() over" +
s" (partition by dn,memberlevel order by cast(paymoney as decimal(10,4)) desc) as rownum,dn from dws.dws_member where dt='${dt}') " +
" where rownum<4 order by memberlevel,rownum")
}
}9)报表层统计指标
package com.yyds.member.service
import com.yyds.member.bean.QueryResult
import com.yyds.member.dao.DwsMemberDao
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{SaveMode, SparkSession}
object AdsMemberService {
/**
* 统计各项指标 使用api
*
* @param sparkSession
*/
def queryDetailApi(sparkSession: SparkSession, dt: String) = {
import sparkSession.implicits._ //隐式转换
val result = DwsMemberDao.queryIdlMemberData(sparkSession).as[QueryResult].where(s"dt='${dt}'")
result.cache()
//统计注册来源url人数
val a = result.mapPartitions(partition => {
partition.map(item => (item.appregurl + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1)
.mapValues(item => item._2).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_")
val appregurl = keys(0)
val dn = keys(1)
val dt = keys(2)
(appregurl, item._2, dt, dn)
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_appregurlnum")
//统计所属网站人数
result.mapPartitions(partiton => {
partiton.map(item => (item.sitename + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1).mapValues((item => item._2)).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_")
val sitename = keys(0)
val dn = keys(1)
val dt = keys(2)
(sitename, item._2, dt, dn)
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_sitenamenum")
//统计所属来源人数 pc mobile wechat app
result.mapPartitions(partition => {
partition.map(item => (item.regsourcename + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1).mapValues(item => item._2).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_")
val regsourcename = keys(0)
val dn = keys(1)
val dt = keys(2)
(regsourcename, item._2, dt, dn)
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_regsourcenamenum")
//统计通过各广告进来的人数
result.mapPartitions(partition => {
partition.map(item => (item.adname + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1).mapValues(_._2).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_")
val adname = keys(0)
val dn = keys(1)
val dt = keys(2)
(adname, item._2, dt, dn)
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_adnamenum")
//统计各用户等级人数
result.mapPartitions(partition => {
partition.map(item => (item.memberlevel + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1).mapValues(_._2).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_")
val memberlevel = keys(0)
val dn = keys(1)
val dt = keys(2)
(memberlevel, item._2, dt, dn)
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_memberlevelnum")
//统计各用户vip等级人数
result.mapPartitions(partition => {
partition.map(item => (item.vip_level + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1).mapValues(_._2).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_")
val vip_level = keys(0)
val dn = keys(1)
val dt = keys(2)
(vip_level, item._2, dt, dn)
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_viplevelnum")
//统计各memberlevel等级 支付金额前三的用户
import org.apache.spark.sql.functions._
result.withColumn("rownum", row_number().over(Window.partitionBy("dn", "memberlevel").orderBy(desc("paymoney"))))
.where("rownum<4").orderBy("memberlevel", "rownum")
.select("uid", "memberlevel", "register", "appregurl", "regsourcename", "adname"
, "sitename", "vip_level", "paymoney", "rownum", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_top3memberpay")
}
/**
* 统计各项指标 使用sql
*
* @param sparkSession
*/
def queryDetailSql(sparkSession: SparkSession, dt: String) = {
val appregurlCount = DwsMemberDao.queryAppregurlCount(sparkSession, dt)
val siteNameCount = DwsMemberDao.querySiteNameCount(sparkSession, dt)
val regsourceNameCount = DwsMemberDao.queryRegsourceNameCount(sparkSession, dt)
val adNameCount = DwsMemberDao.queryAdNameCount(sparkSession, dt)
val memberLevelCount = DwsMemberDao.queryMemberLevelCount(sparkSession, dt)
val vipLevelCount = DwsMemberDao.queryMemberLevelCount(sparkSession, dt)
val top3MemberLevelPayMoneyUser = DwsMemberDao.getTop3MemberLevelPayMoneyUser(sparkSession, dt).show()
}
}10)创建AdsMemberController
package com.yyds.member.controller
import com.yyds.member.service.AdsMemberService
import com.yyds.util.HiveUtil
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object AdsMemberController {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "yyds")
val sparkConf = new SparkConf().setAppName("ads_member_controller").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
HiveUtil.openDynamicPartition(sparkSession) //开启动态分区
AdsMemberService.queryDetailApi(sparkSession, "20190722")
// AdsMemberService.queryDetailSql(sparkSession, "20190722")
}
}八、用户做题模块数仓设计与实现
1、用户做题模块数仓设计
1)原始数据格式及字段含义
QzWebsite.log 做题网站日志数据:
{
"createtime": "2019-07-22 11:47:18", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"domain": "-",
"dt": "20190722", //日期分区
"multicastgateway": "-",
"multicastport": "-",
"multicastserver": "-",
"sequence": "-",
"siteid": 0, //网站id
"sitename": "sitename0", //网站名称
"status": "-",
"templateserver": "-"
}QzSiteCourse.log 网站课程日志数据:
{
"boardid": 64, //课程模板id
"coursechapter": "-",
"courseid": 66, //课程id
"createtime": "2019-07-22 11:43:32", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"helpparperstatus": "-",
"sequence": "-",
"servertype": "-",
"showstatus": "-",
"sitecourseid": 2, //网站课程id
"sitecoursename": "sitecoursename2", //网站课程名称
"siteid": 77, //网站id
"status": "-"
}QzQuestionType.log 题目类型数据:
{
"createtime": "2019-07-22 10:42:47", //创建时间
"creator": "admin", //创建者
"description": "-",
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"papertypename": "-",
"questypeid": 0, //做题类型id
"quesviewtype": 0,
"remark": "-",
"sequence": "-",
"splitscoretype": "-",
"status": "-",
"viewtypename": "viewtypename0"
}QzQuestion.log 做题日志数据:
{
"analysis": "-",
"answer": "-",
"attanswer": "-",
"content": "-",
"createtime": "2019-07-22 11:33:46", //创建时间
"creator": "admin", //创建者
"difficulty": "-",
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"lecture": "-",
"limitminute": "-",
"modifystatus": "-",
"optnum": 8,
"parentid": 57,
"quesskill": "-",
"questag": "-",
"questionid": 0, //题id
"questypeid": 57, //题目类型id
"quesviewtype": 44,
"score": 24.124501582742543, //题的分数
"splitscore": 0.0,
"status": "-",
"vanalysisaddr": "-",
"vdeoaddr": "-"
}QzPointQuestion.log 做题知识点关联数据:
{
"createtime": "2019-07-22 09:16:46", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"pointid": 0, //知识点id
"questionid": 0, //题id
"questype": 0
}QzPoint.log 知识点数据日志:
{
"chapter": "-", //所属章节
"chapterid": 0, //章节id
"courseid": 0, //课程id
"createtime": "2019-07-22 09:08:52", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"excisenum": 73,
"modifystatus": "-",
"pointdescribe": "-",
"pointid": 0, //知识点id
"pointlevel": "9", //知识点级别
"pointlist": "-",
"pointlistid": 82, //知识点列表id
"pointname": "pointname0", //知识点名称
"pointnamelist": "-",
"pointyear": "2019", //知识点所属年份
"remid": "-",
"score": 83.86880766562163, //知识点分数
"sequece": "-",
"status": "-",
"thought": "-",
"typelist": "-"
}QzPaperView.log 试卷视图数据:
{
"contesttime": "2019-07-22 19:02:19",
"contesttimelimit": "-",
"createtime": "2019-07-22 19:02:19", //创建时间
"creator": "admin", //创建者
"dayiid": 94,
"description": "-",
"dn": "webA", //网站分区
"downurl": "-",
"dt": "20190722", //日期分区
"explainurl": "-",
"iscontest": "-",
"modifystatus": "-",
"openstatus": "-",
"paperdifficult": "-",
"paperid": 83, //试卷id
"paperparam": "-",
"papertype": "-",
"paperuse": "-",
"paperuseshow": "-",
"paperviewcatid": 1,
"paperviewid": 0, //试卷视图id
"paperviewname": "paperviewname0", //试卷视图名称
"testreport": "-"
}QzPaper.log 做题试卷日志数据:
{
"chapter": "-", //章节
"chapterid": 33, //章节id
"chapterlistid": 69, //所属章节列表id
"courseid": 72, //课程id
"createtime": "2019-07-22 19:14:27", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"papercatid": 92,
"paperid": 0, //试卷id
"papername": "papername0", //试卷名称
"paperyear": "2019", //试卷所属年份
"status": "-",
"suitnum": "-",
"totalscore": 93.16710017696484 //试卷总分
}QzMemberPaperQuestion.log 学员做题详情数据:
{
"chapterid": 33, //章节id
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"istrue": "-",
"lasttime": "2019-07-22 11:02:30",
"majorid": 77, //主修id
"opertype": "-",
"paperid": 91,//试卷id
"paperviewid": 37, //试卷视图id
"question_answer": 1, //做题结果(0错误 1正确)
"questionid": 94, //题id
"score": 76.6941793631127, //学员成绩分数
"sitecourseid": 1, //网站课程id
"spendtime": 4823, //所用时间单位(秒)
"useranswer": "-",
"userid": 0 //用户id
}QzMajor.log 主修数据:
{
"businessid": 41, //主修行业id
"columm_sitetype": "-",
"createtime": "2019-07-22 11:10:20", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"majorid": 1, //主修id
"majorname": "majorname1", //主修名称
"sequence": "-",
"shortname": "-",
"siteid": 24, //网站id
"status": "-"
}QzCourseEduSubject.log 课程辅导数据:
{
"courseeduid": 0, //课程辅导id
"courseid": 0, //课程id
"createtime": "2019-07-22 11:14:43", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"edusubjectid": 44, //辅导科目id
"majorid": 38 //主修id
}QzCourse.log 题库课程数据:
{
"chapterlistid": 45, //章节列表id
"courseid": 0, //课程id
"coursename": "coursename0", //课程名称
"createtime": "2019-07-22 11:08:15", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"isadvc": "-",
"majorid": 39, //主修id
"pointlistid": 92, //知识点列表id
"sequence": "8128f2c6-2430-42c7-9cb4-787e52da2d98",
"status": "-"
}QzChapterList.log 章节列表数据:
{
"chapterallnum": 0, //章节总个数
"chapterlistid": 0, //章节列表id
"chapterlistname": "chapterlistname0", //章节列表名称
"courseid": 71, //课程id
"createtime": "2019-07-22 16:22:19", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"status": "-"
}QzChapter.log 章节数据:
{
"chapterid": 0, //章节id
"chapterlistid": 0, //所属章节列表id
"chaptername": "chaptername0", //章节名称
"chapternum": 10, //章节个数
"courseid": 61, //课程id
"createtime": "2019-07-22 16:37:24", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"outchapterid": 0,
"sequence": "-",
"showstatus": "-",
"status": "-"
}QzCenterPaper.log 试卷主题关联数据:
{
"centerid": 55, //主题id
"createtime": "2019-07-22 10:48:30", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"openstatus": "-",
"paperviewid": 2, //视图id
"sequence": "-"
}QzCenter.log 主题数据:
{
"centerid": 0, //主题id
"centername": "centername0", //主题名称
"centerparam": "-",
"centertype": "3", //主题类型
"centerviewtype": "-",
"centeryear": "2019", //主题年份
"createtime": "2019-07-22 19:13:09", //创建时间
"creator": "-",
"description": "-",
"dn": "webA",
"dt": "20190722", //日期分区
"openstatus": "1",
"provideuser": "-",
"sequence": "-",
"stage": "-"
}
Centerid:主题id centername:主题名称 centertype:主题类型 centeryear:主题年份
createtime:创建时间 dn:网站分区 dt:日期分区
QzBusiness.log 所属行业数据:
{
"businessid": 0, //行业id
"businessname": "bsname0", //行业名称
"createtime": "2019-07-22 10:40:54", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"sequence": "-",
"siteid": 1, //所属网站id
"status": "-"
}2)模拟数据采集上传数据
日志上传命令:
hadoop dfs -put QzBusiness.log /user/yyds/ods/
hadoop dfs -put QzCenter.log /user/yyds/ods/
hadoop dfs -put QzCenterPaper.log /user/yyds/ods/
hadoop dfs -put QzChapter.log /user/yyds/ods/
hadoop dfs -put QzChapterList.log /user/yyds/ods/
hadoop dfs -put QzCourse.log /user/yyds/ods/
hadoop dfs -put QzCourseEduSubject.log /user/yyds/ods/
hadoop dfs -put QzMajor.log /user/yyds/ods/
hadoop dfs -put QzMemberPaperQuestion.log /user/yyds/ods/
hadoop dfs -put QzPaper.log /user/yyds/ods/
hadoop dfs -put QzPaperView.log /user/yyds/ods/
hadoop dfs -put QzPoint.log /user/yyds/ods/
hadoop dfs -put QzPointQuestion.log /user/yyds/ods/
hadoop dfs -put QzQuestion.log /user/yyds/ods/
hadoop dfs -put QzQuestionType.log /user/yyds/ods/
hadoop dfs -put QzSiteCourse.log /user/yyds/ods/
hadoop dfs -put QzWebsite.log /user/yyds/ods/
做题建表语句:
create external table `dwd`.`dwd_qz_chapter`(
chapterid int ,
chapterlistid int ,
chaptername string ,
sequence string ,
showstatus string ,
creator string ,
createtime timestamp,
courseid int ,
chapternum int,
outchapterid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_chapter_list`(
chapterlistid int ,
chapterlistname string ,
courseid int ,
chapterallnum int ,
sequence string,
status string,
creator string ,
createtime timestamp
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_point`(
pointid int ,
courseid int ,
pointname string ,
pointyear string ,
chapter string ,
creator string,
createtme timestamp,
status string,
modifystatus string,
excisenum int,
pointlistid int ,
chapterid int ,
sequece string,
pointdescribe string,
pointlevel string ,
typelist string,
score decimal(4,1) ,
thought string,
remid string,
pointnamelist string,
typelistids string,
pointlist string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_point_question`(
pointid int,
questionid int ,
questype int ,
creator string,
createtime string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_site_course`(
sitecourseid int,
siteid int ,
courseid int ,
sitecoursename string ,
coursechapter string ,
sequence string,
status string,
creator string,
createtime timestamp,
helppaperstatus string,
servertype string,
boardid int,
showstatus string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_course`(
courseid int ,
majorid int ,
coursename string ,
coursechapter string ,
sequence string,
isadvc string,
creator string,
createtime timestamp,
status string,
chapterlistid int,
pointlistid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_course_edusubject`(
courseeduid int ,
edusubjectid int ,
courseid int ,
creator string,
createtime timestamp,
majorid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_website`(
siteid int ,
sitename string ,
domain string,
sequence string,
multicastserver string,
templateserver string,
status string,
creator string,
createtime timestamp,
multicastgateway string,
multicastport string
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_major`(
majorid int ,
businessid int ,
siteid int ,
majorname string ,
shortname string ,
status string,
sequence string,
creator string,
createtime timestamp,
column_sitetype string
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_business`(
businessid int ,
businessname string,
sequence string,
status string,
creator string,
createtime timestamp,
siteid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_paper_view`(
paperviewid int ,
paperid int ,
paperviewname string,
paperparam string ,
openstatus string,
explainurl string,
iscontest string ,
contesttime timestamp,
conteststarttime timestamp ,
contestendtime timestamp ,
contesttimelimit string ,
dayiid int,
status string,
creator string,
createtime timestamp,
paperviewcatid int,
modifystatus string,
description string,
papertype string ,
downurl string ,
paperuse string,
paperdifficult string ,
testreport string,
paperuseshow string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_center_paper`(
paperviewid int,
centerid int,
openstatus string,
sequence string,
creator string,
createtime timestamp)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_paper`(
paperid int,
papercatid int,
courseid int,
paperyear string,
chapter string,
suitnum string,
papername string,
status string,
creator string,
createtime timestamp,
totalscore decimal(4,1),
chapterid int,
chapterlistid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_center`(
centerid int,
centername string,
centeryear string,
centertype string,
openstatus string,
centerparam string,
description string,
creator string,
createtime timestamp,
sequence string,
provideuser string,
centerviewtype string,
stage string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_question`(
questionid int,
parentid int,
questypeid int,
quesviewtype int,
content string,
answer string,
analysis string,
limitminute string,
score decimal(4,1),
splitscore decimal(4,1),
status string,
optnum int,
lecture string,
creator string,
createtime string,
modifystatus string,
attanswer string,
questag string,
vanalysisaddr string,
difficulty string,
quesskill string,
vdeoaddr string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_question_type`(
quesviewtype int,
viewtypename string,
questypeid int,
description string,
status string,
creator string,
createtime timestamp,
papertypename string,
sequence string,
remark string,
splitscoretype string
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dwd`.`dwd_qz_member_paper_question`(
userid int,
paperviewid int,
chapterid int,
sitecourseid int,
questionid int,
majorid int,
useranswer string,
istrue string,
lasttime timestamp,
opertype string,
paperid int,
spendtime int,
score decimal(4,1),
question_answer int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_chapter`(
chapterid int,
chapterlistid int,
chaptername string,
sequence string,
showstatus string,
status string,
chapter_creator string,
chapter_createtime string,
chapter_courseid int,
chapternum int,
chapterallnum int,
outchapterid int,
chapterlistname string,
pointid int,
questionid int,
questype int,
pointname string,
pointyear string,
chapter string,
excisenum int,
pointlistid int,
pointdescribe string,
pointlevel string,
typelist string,
point_score decimal(4,1),
thought string,
remid string,
pointnamelist string,
typelistids string,
pointlist string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_course`(
sitecourseid int,
siteid int,
courseid int,
sitecoursename string,
coursechapter string,
sequence string,
status string,
sitecourse_creator string,
sitecourse_createtime string,
helppaperstatus string,
servertype string,
boardid int,
showstatus string,
majorid int,
coursename string,
isadvc string,
chapterlistid int,
pointlistid int,
courseeduid int,
edusubjectid int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_major`(
majorid int,
businessid int,
siteid int,
majorname string,
shortname string,
status string,
sequence string,
major_creator string,
major_createtime timestamp,
businessname string,
sitename string,
domain string,
multicastserver string,
templateserver string,
multicastgateway string,
multicastport string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_paper`(
paperviewid int,
paperid int,
paperviewname string,
paperparam string,
openstatus string,
explainurl string,
iscontest string,
contesttime timestamp,
conteststarttime timestamp,
contestendtime timestamp,
contesttimelimit string,
dayiid int,
status string,
paper_view_creator string,
paper_view_createtime timestamp,
paperviewcatid int,
modifystatus string,
description string,
paperuse string,
paperdifficult string,
testreport string,
paperuseshow string,
centerid int,
sequence string,
centername string,
centeryear string,
centertype string,
provideuser string,
centerviewtype string,
stage string,
papercatid int,
courseid int,
paperyear string,
suitnum string,
papername string,
totalscore decimal(4,1),
chapterid int,
chapterlistid int)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table `dws`.`dws_qz_question`(
questionid int,
parentid int,
questypeid int,
quesviewtype int,
content string,
answer string,
analysis string,
limitminute string,
score decimal(4,1),
splitscore decimal(4,1),
status string,
optnum int,
lecture string,
creator string,
createtime timestamp,
modifystatus string,
attanswer string,
questag string,
vanalysisaddr string,
difficulty string,
quesskill string,
vdeoaddr string,
viewtypename string,
description string,
papertypename string,
splitscoretype string)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create table `dws`.`dws_user_paper_detail`(
`userid` int,
`courseid` int,
`questionid` int,
`useranswer` string,
`istrue` string,
`lasttime` string,
`opertype` string,
`paperid` int,
`spendtime` int,
`chapterid` int,
`chaptername` string,
`chapternum` int,
`chapterallnum` int,
`outchapterid` int,
`chapterlistname` string,
`pointid` int,
`questype` int,
`pointyear` string,
`chapter` string,
`pointname` string,
`excisenum` int,
`pointdescribe` string,
`pointlevel` string,
`typelist` string,
`point_score` decimal(4,1),
`thought` string,
`remid` string,
`pointnamelist` string,
`typelistids` string,
`pointlist` string,
`sitecourseid` int,
`siteid` int,
`sitecoursename` string,
`coursechapter` string,
`course_sequence` string,
`course_stauts` string,
`course_creator` string,
`course_createtime` timestamp,
`servertype` string,
`helppaperstatus` string,
`boardid` int,
`showstatus` string,
`majorid` int,
`coursename` string,
`isadvc` string,
`chapterlistid` int,
`pointlistid` int,
`courseeduid` int,
`edusubjectid` int,
`businessid` int,
`majorname` string,
`shortname` string,
`major_status` string,
`major_sequence` string,
`major_creator` string,
`major_createtime` timestamp,
`businessname` string,
`sitename` string,
`domain` string,
`multicastserver` string,
`templateserver` string,
`multicastgatway` string,
`multicastport` string,
`paperviewid` int,
`paperviewname` string,
`paperparam` string,
`openstatus` string,
`explainurl` string,
`iscontest` string,
`contesttime` timestamp,
`conteststarttime` timestamp,
`contestendtime` timestamp,
`contesttimelimit` string,
`dayiid` int,
`paper_status` string,
`paper_view_creator` string,
`paper_view_createtime` timestamp,
`paperviewcatid` int,
`modifystatus` string,
`description` string,
`paperuse` string,
`testreport` string,
`centerid` int,
`paper_sequence` string,
`centername` string,
`centeryear` string,
`centertype` string,
`provideuser` string,
`centerviewtype` string,
`paper_stage` string,
`papercatid` int,
`paperyear` string,
`suitnum` string,
`papername` string,
`totalscore` decimal(4,1),
`question_parentid` int,
`questypeid` int,
`quesviewtype` int,
`question_content` string,
`question_answer` string,
`question_analysis` string,
`question_limitminute` string,
`score` decimal(4,1),
`splitscore` decimal(4,1),
`lecture` string,
`question_creator` string,
`question_createtime` timestamp,
`question_modifystatus` string,
`question_attanswer` string,
`question_questag` string,
`question_vanalysisaddr` string,
`question_difficulty` string,
`quesskill` string,
`vdeoaddr` string,
`question_description` string,
`question_splitscoretype` string,
`user_question_answer` int
)
partitioned by(
dt string,
dn string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
create external table ads.ads_paper_avgtimeandscore(
paperviewid int,
paperviewname string,
avgscore decimal(4,1),
avgspendtime decimal(10,1))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_paper_maxdetail(
paperviewid int,
paperviewname string,
maxscore decimal(4,1),
minscore decimal(4,1))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_top3_userdetail(
userid int,
paperviewid int,
paperviewname string,
chaptername string,
pointname string,
sitecoursename string,
coursename string,
majorname string,
shortname string,
papername string,
score decimal(4,1),
rk int)
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_low3_userdetail(
userid int,
paperviewid int,
paperviewname string,
chaptername string,
pointname string,
sitecoursename string,
coursename string,
majorname string,
shortname string,
papername string,
score decimal(4,1),
rk int)
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_paper_scoresegment_user(
paperviewid int,
paperviewname string,
score_segment string,
userids string)
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_user_paper_detail(
paperviewid int,
paperviewname string,
unpasscount int,
passcount int,
rate decimal(4,2))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';
create external table ads.ads_user_question_detail(
questionid int,
errcount int,
rightcount int,
rate decimal(4,2))
partitioned by(
dt string,
dn string)
row format delimited fields terminated by '\t';3)解析数据
需求1:使用spark解析ods层数据,将数据存入到对应的hive表中,要求对所有score 分数字段进行保留两位1位小数并且四舍五入。
4)维度退化
需求2:基于dwd层基础表数据,需要对表进行维度退化进行表聚合,聚合成dws.dws_qz_chapter(章节维度表),dws.dws_qz_course(课程维度表),dws.dws_qz_major(主修维度表),dws.dws_qz_paper(试卷维度表),dws.dws_qz_question(题目维度表),使用spark sql和dataframe api操作
dws.dws_qz_chapte : 4张表join dwd.dwd_qz_chapter inner join dwd.qz_chapter_list join条件:chapterlistid和dn ,inner join dwd.dwd_qz_point join条件:chapterid和dn, inner join dwd.dwd_qz_point_question join条件:pointid和dn
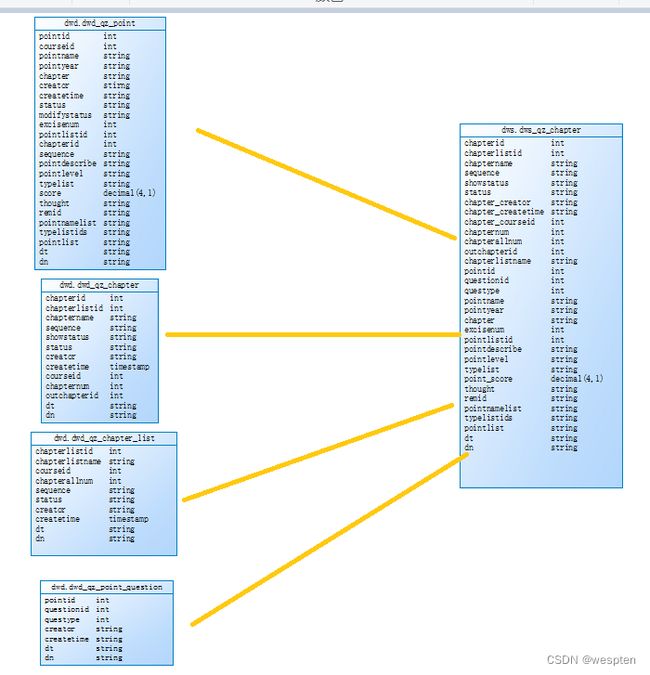
dws.dws_qz_course:3张表join dwd.dwd_qz_site_course inner join dwd.qz_course join条件:courseid和dn , inner join dwd.qz_course_edusubject join条件:courseid和dn
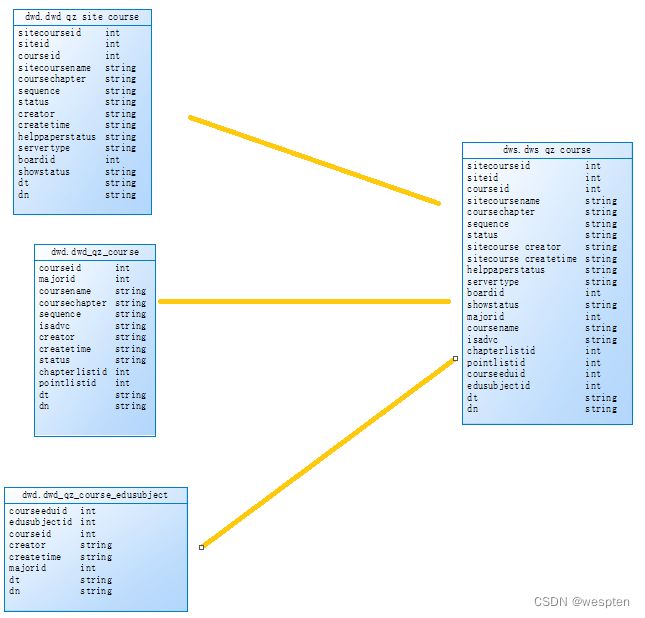
dws.dws_qz_major:3张表join dwd.dwd_qz_major inner join dwd.dwd_qz_website join条件:siteid和dn , inner join dwd.dwd_qz_business join条件:siteid和dn

dws.dws_qz_paper: 4张表join qz_paperview left join qz_center join 条件:paperviewid和dn,
left join qz_center join 条件:centerid和dn, inner join qz_paper join条件:paperid和dn
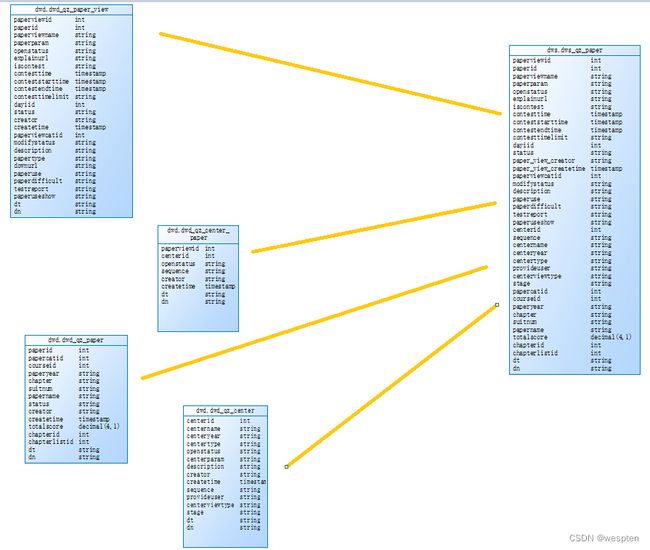
dws.dws_qz_question:2表join qz_quesiton inner join qz_questiontype join条件:
questypeid 和dn
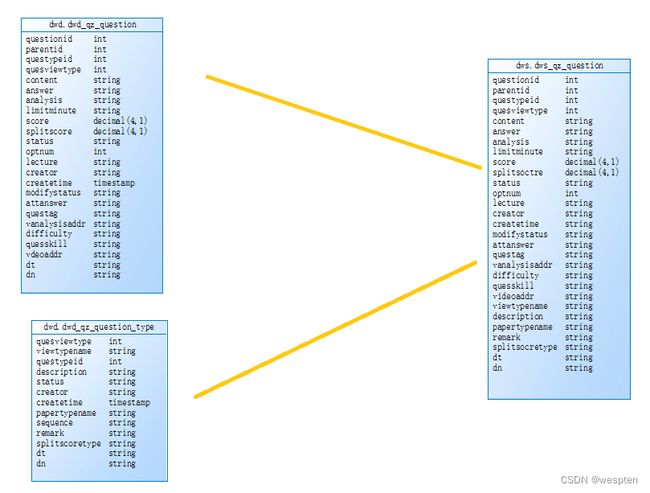
5)宽表合成
需求3:基于dws.dws_qz_chapter、dws.dws_qz_course、dws.dws_qz_major、dws.dws_qz_paper、dws.dws_qz_question、dwd.dwd_qz_member_paper_question 合成宽表dw.user_paper_detail,使用spark sql和dataframe api操作
dws.user_paper_detail:dwd_qz_member_paper_question inner join dws_qz_chapter join条件:chapterid 和dn ,inner join dws_qz_course join条件:sitecourseid和dn , inner join dws_qz_major join条件majorid和dn, inner join dws_qz_paper 条件paperviewid和dn , inner join dws_qz_question 条件questionid和dn
6)报表层各指标统计
需求4:基于宽表统计各试卷平均耗时、平均分,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。
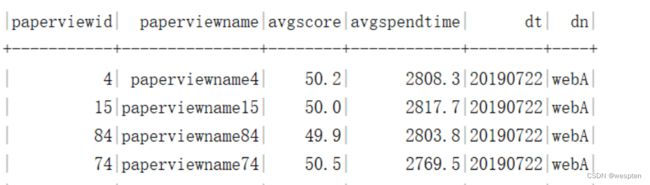
需求5:统计各试卷最高分、最低分,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。

需求6:按试卷分组统计每份试卷的前三用户详情,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。

需求7:按试卷分组统计每份试卷的倒数前三的用户详情,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。

需求8:统计各试卷各分段的用户id,分段有0-20,20-40,40-60,60-80,80-100

需求9:统计试卷未及格的人数,及格的人数,试卷的及格率 及格分数60
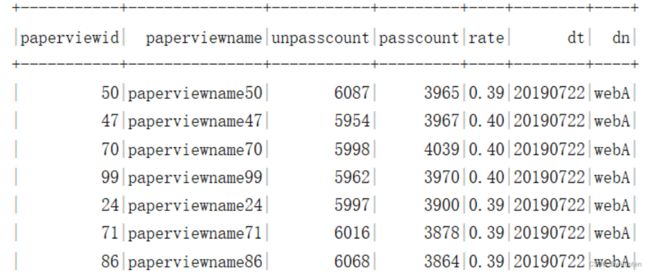
需求10:统计各题的错误数,正确数,错题率
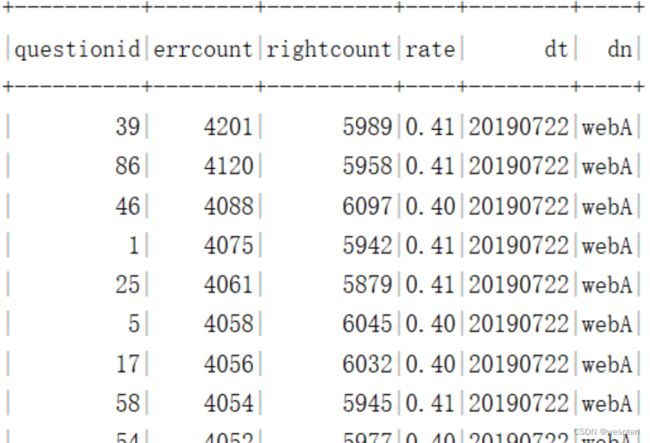
7)将数据导入mysql
需求11:统计指标数据导入到ads层后,通过datax将ads层数据导入到mysql中。
2、用户做题模块代码实现
1)准备样例类
package com.yyds.qz.bean
case class DwdQzPoint(pointid: Int, courseid: Int, pointname: String, pointyear: String, chapter: String,
creator: String, createtime: String, status: String, modifystatus: String, excisenum: Int,
pointlistid: Int, chapterid: Int, sequence: String, pointdescribe: String, pointlevel: String,
typelist: String, score: BigDecimal, thought: String, remid: String, pointnamelist: String,
typelistids: String, pointlist: String, dt: String, dn: String)
case class DwdQzPaperView(paperviewid: Int, paperid: Int, paperviewname: String, paperparam: String, openstatus: String,
explainurl: String, iscontest: String, contesttime: String, conteststarttime: String, contestendtime: String,
contesttimelimit: String, dayiid: Int, status: String, creator: String, createtime: String,
paperviewcatid: Int, modifystatus: String, description: String, papertype: String, downurl: String,
paperuse: String, paperdifficult: String, testreport: String, paperuseshow: String, dt: String, dn: String)
case class DwdQzQuestion(questionid: Int, parentid: Int, questypeid: Int, quesviewtype: Int, content: String, answer: String,
analysis: String, limitminute: String, scoe: BigDecimal, splitcore: BigDecimal, status: String,
optnum: Int, lecture: String, creator: String, createtime: String, modifystatus: String,
attanswer: String, questag: String, vanalysisaddr: String, difficulty: String, quesskill: String,
vdeoaddr: String, dt: String, dn: String)2)解析原始日志信息
package com.yyds.qz.service
import com.alibaba.fastjson.JSONObject
import com.yyds.qz.bean.{DwdQzPaperView, DwdQzPoint, DwdQzQuestion}
import com.yyds.util.ParseJsonData
import org.apache.spark.SparkContext
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* etl用户做题信息
*/
object EtlDataService {
/**
* 解析章节数据
*
* @param ssc
* @param sparkSession
* @return
*/
def etlQzChapter(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/yyds/ods/QzChapter.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val chapterid = jsonObject.getIntValue("chapterid")
val chapterlistid = jsonObject.getIntValue("chapterlistid")
val chaptername = jsonObject.getString("chaptername")
val sequence = jsonObject.getString("sequence")
val showstatus = jsonObject.getString("showstatus")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val courseid = jsonObject.getIntValue("courseid")
val chapternum = jsonObject.getIntValue("chapternum")
val outchapterid = jsonObject.getIntValue("outchapterid")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(chapterid, chapterlistid, chaptername, sequence, showstatus, status, creator, createtime,
courseid, chapternum, outchapterid, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_chapter")
}
/**
* 解析章节列表数据
*
* @param ssc
* @param sparkSession
*/
def etlQzChapterList(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzChapterList.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val chapterlistid = jsonObject.getIntValue("chapterlistid")
val chapterlistname = jsonObject.getString("chapterlistname")
val courseid = jsonObject.getIntValue("courseid")
val chapterallnum = jsonObject.getIntValue("chapterallnum")
val sequence = jsonObject.getString("sequence")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(chapterlistid, chapterlistname, courseid, chapterallnum, sequence, status, creator, createtime, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_chapter_list")
}
/**
* 解析做题数据
*
* @param ssc
* @param sparkSession
*/
def etlQzPoint(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzPoint.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val pointid = jsonObject.getIntValue("pointid")
val courseid = jsonObject.getIntValue("courseid")
val pointname = jsonObject.getString("pointname")
val pointyear = jsonObject.getString("pointyear")
val chapter = jsonObject.getString("chapter")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val status = jsonObject.getString("status")
val modifystatus = jsonObject.getString("modifystatus")
val excisenum = jsonObject.getIntValue("excisenum")
val pointlistid = jsonObject.getIntValue("pointlistid")
val chapterid = jsonObject.getIntValue("chapterid")
val sequence = jsonObject.getString("sequence")
val pointdescribe = jsonObject.getString("pointdescribe")
val pointlevel = jsonObject.getString("pointlevel")
val typeslist = jsonObject.getString("typelist")
val score = BigDecimal(jsonObject.getDouble("score")).setScale(1, BigDecimal.RoundingMode.HALF_UP) //保留1位小数 并四舍五入
val thought = jsonObject.getString("thought")
val remid = jsonObject.getString("remid")
val pointnamelist = jsonObject.getString("pointnamelist")
val typelistids = jsonObject.getString("typelistids")
val pointlist = jsonObject.getString("pointlist")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
DwdQzPoint(pointid, courseid, pointname, pointyear, chapter, creator, createtime, status, modifystatus, excisenum, pointlistid,
chapterid, sequence, pointdescribe, pointlevel, typeslist, score, thought, remid, pointnamelist, typelistids,
pointlist, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_point")
}
/**
* 解析知识点下的题数据
*
* @param ssc
* @param sparkSession
* @return
*/
def etlQzPointQuestion(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzPointQuestion.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val pointid = jsonObject.getIntValue("pointid")
val questionid = jsonObject.getIntValue("questionid")
val questtype = jsonObject.getIntValue("questtype")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(pointid, questionid, questtype, creator, createtime, dt, dn)
})
}).toDF().write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_point_question")
}
/**
* 解析网站课程
*
* @param ssc
* @param sparkSession
*/
def etlQzSiteCourse(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzSiteCourse.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val sitecourseid = jsonObject.getIntValue("sitecourseid")
val siteid = jsonObject.getIntValue("siteid")
val courseid = jsonObject.getIntValue("courseid")
val sitecoursename = jsonObject.getString("sitecoursename")
val coursechapter = jsonObject.getString("coursechapter")
val sequence = jsonObject.getString("sequence")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val helppaperstatus = jsonObject.getString("helppaperstatus")
val servertype = jsonObject.getString("servertype")
val boardid = jsonObject.getIntValue("boardid")
val showstatus = jsonObject.getString("showstatus")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(sitecourseid, siteid, courseid, sitecoursename, coursechapter, sequence, status, creator
, createtime, helppaperstatus, servertype, boardid, showstatus, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_site_course")
}
/**
* 解析课程数据
*
* @param ssc
* @param sparkSession
*/
def etlQzCourse(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzCourse.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val courseid = jsonObject.getIntValue("courseid")
val majorid = jsonObject.getIntValue("majorid")
val coursename = jsonObject.getString("coursename")
val coursechapter = jsonObject.getString("coursechapter")
val sequence = jsonObject.getString("sequnece")
val isadvc = jsonObject.getString("isadvc")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val status = jsonObject.getString("status")
val chapterlistid = jsonObject.getIntValue("chapterlistid")
val pointlistid = jsonObject.getIntValue("pointlistid")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(courseid, majorid, coursename, coursechapter, sequence, isadvc, creator, createtime, status
, chapterlistid, pointlistid, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_course")
}
/**
* 解析课程辅导数据
*
* @param ssc
* @param sparkSession
*/
def etlQzCourseEdusubject(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzCourseEduSubject.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val courseeduid = jsonObject.getIntValue("courseeduid")
val edusubjectid = jsonObject.getIntValue("edusubjectid")
val courseid = jsonObject.getIntValue("courseid")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val majorid = jsonObject.getIntValue("majorid")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(courseeduid, edusubjectid, courseid, creator, createtime, majorid, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_course_edusubject")
}
/**
* 解析课程网站
*
* @param ssc
* @param sparkSession
*/
def etlQzWebsite(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzWebsite.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val siteid = jsonObject.getIntValue("siteid")
val sitename = jsonObject.getString("sitename")
val domain = jsonObject.getString("domain")
val sequence = jsonObject.getString("sequence")
val multicastserver = jsonObject.getString("multicastserver")
val templateserver = jsonObject.getString("templateserver")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val multicastgateway = jsonObject.getString("multicastgateway")
val multicastport = jsonObject.getString("multicastport")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(siteid, sitename, domain, sequence, multicastserver, templateserver, status, creator, createtime,
multicastgateway, multicastport, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_website")
}
/**
* 解析主修数据
*
* @param ssc
* @param sparkSession
*/
def etlQzMajor(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzMajor.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val majorid = jsonObject.getIntValue("majorid")
val businessid = jsonObject.getIntValue("businessid")
val siteid = jsonObject.getIntValue("siteid")
val majorname = jsonObject.getString("majorname")
val shortname = jsonObject.getString("shortname")
val status = jsonObject.getString("status")
val sequence = jsonObject.getString("sequence")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val columm_sitetype = jsonObject.getString("columm_sitetype")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(majorid, businessid, siteid, majorname, shortname, status, sequence, creator, createtime, columm_sitetype, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_major")
}
/**
* 解析做题业务
*
* @param ssc
* @param sparkSession
*/
def etlQzBusiness(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzBusiness.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item);
val businessid = jsonObject.getIntValue("businessid")
val businessname = jsonObject.getString("businessname")
val sequence = jsonObject.getString("sequence")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val siteid = jsonObject.getIntValue("siteid")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(businessid, businessname, sequence, status, creator, createtime, siteid, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_business")
}
def etlQzPaperView(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzPaperView.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val paperviewid = jsonObject.getIntValue("paperviewid")
val paperid = jsonObject.getIntValue("paperid")
val paperviewname = jsonObject.getString("paperviewname")
val paperparam = jsonObject.getString("paperparam")
val openstatus = jsonObject.getString("openstatus")
val explainurl = jsonObject.getString("explainurl")
val iscontest = jsonObject.getString("iscontest")
val contesttime = jsonObject.getString("contesttime")
val conteststarttime = jsonObject.getString("conteststarttime")
val contestendtime = jsonObject.getString("contestendtime")
val contesttimelimit = jsonObject.getString("contesttimelimit")
val dayiid = jsonObject.getIntValue("dayiid")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val paperviewcatid = jsonObject.getIntValue("paperviewcatid")
val modifystatus = jsonObject.getString("modifystatus")
val description = jsonObject.getString("description")
val papertype = jsonObject.getString("papertype")
val downurl = jsonObject.getString("downurl")
val paperuse = jsonObject.getString("paperuse")
val paperdifficult = jsonObject.getString("paperdifficult")
val testreport = jsonObject.getString("testreport")
val paperuseshow = jsonObject.getString("paperuseshow")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
DwdQzPaperView(paperviewid, paperid, paperviewname, paperparam, openstatus, explainurl, iscontest, contesttime,
conteststarttime, contestendtime, contesttimelimit, dayiid, status, creator, createtime, paperviewcatid, modifystatus,
description, papertype, downurl, paperuse, paperdifficult, testreport, paperuseshow, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_paper_view")
}
def etlQzCenterPaper(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzCenterPaper.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val paperviewid = jsonObject.getIntValue("paperviewid")
val centerid = jsonObject.getIntValue("centerid")
val openstatus = jsonObject.getString("openstatus")
val sequence = jsonObject.getString("sequence")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(paperviewid, centerid, openstatus, sequence, creator, createtime, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_center_paper")
}
def etlQzPaper(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzPaper.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val paperid = jsonObject.getIntValue("paperid")
val papercatid = jsonObject.getIntValue("papercatid")
val courseid = jsonObject.getIntValue("courseid")
val paperyear = jsonObject.getString("paperyear")
val chapter = jsonObject.getString("chapter")
val suitnum = jsonObject.getString("suitnum")
val papername = jsonObject.getString("papername")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val craetetime = jsonObject.getString("createtime")
val totalscore = BigDecimal.apply(jsonObject.getString("totalscore")).setScale(1, BigDecimal.RoundingMode.HALF_UP)
val chapterid = jsonObject.getIntValue("chapterid")
val chapterlistid = jsonObject.getIntValue("chapterlistid")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(paperid, papercatid, courseid, paperyear, chapter, suitnum, papername, status, creator, craetetime, totalscore, chapterid,
chapterlistid, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_paper")
}
def etlQzCenter(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzCenter.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(parititons => {
parititons.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val centerid = jsonObject.getIntValue("centerid")
val centername = jsonObject.getString("centername")
val centeryear = jsonObject.getString("centeryear")
val centertype = jsonObject.getString("centertype")
val openstatus = jsonObject.getString("openstatus")
val centerparam = jsonObject.getString("centerparam")
val description = jsonObject.getString("description")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val sequence = jsonObject.getString("sequence")
val provideuser = jsonObject.getString("provideuser")
val centerviewtype = jsonObject.getString("centerviewtype")
val stage = jsonObject.getString("stage")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(centerid, centername, centeryear, centertype, openstatus, centerparam, description, creator, createtime,
sequence, provideuser, centerviewtype, stage, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_center")
}
def etlQzQuestion(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzQuestion.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val questionid = jsonObject.getIntValue("questionid")
val parentid = jsonObject.getIntValue("parentid")
val questypeid = jsonObject.getIntValue("questypeid")
val quesviewtype = jsonObject.getIntValue("quesviewtype")
val content = jsonObject.getString("content")
val answer = jsonObject.getString("answer")
val analysis = jsonObject.getString("analysis")
val limitminute = jsonObject.getString("limitminute")
val score = BigDecimal.apply(jsonObject.getDoubleValue("score")).setScale(1, BigDecimal.RoundingMode.HALF_UP)
val splitscore = BigDecimal.apply(jsonObject.getDoubleValue("splitscore")).setScale(1, BigDecimal.RoundingMode.HALF_UP)
val status = jsonObject.getString("status")
val optnum = jsonObject.getIntValue("optnum")
val lecture = jsonObject.getString("lecture")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val modifystatus = jsonObject.getString("modifystatus")
val attanswer = jsonObject.getString("attanswer")
val questag = jsonObject.getString("questag")
val vanalysisaddr = jsonObject.getString("vanalysisaddr")
val difficulty = jsonObject.getString("difficulty")
val quesskill = jsonObject.getString("quesskill")
val vdeoaddr = jsonObject.getString("vdeoaddr")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
DwdQzQuestion(questionid, parentid, questypeid, quesviewtype, content, answer, analysis, limitminute, score, splitscore,
status, optnum, lecture, creator, createtime, modifystatus, attanswer, questag, vanalysisaddr, difficulty, quesskill,
vdeoaddr, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_question")
}
def etlQzQuestionType(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzQuestionType.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val quesviewtype = jsonObject.getIntValue("quesviewtype")
val viewtypename = jsonObject.getString("viewtypename")
val questiontypeid = jsonObject.getIntValue("questypeid")
val description = jsonObject.getString("description")
val status = jsonObject.getString("status")
val creator = jsonObject.getString("creator")
val createtime = jsonObject.getString("createtime")
val papertypename = jsonObject.getString("papertypename")
val sequence = jsonObject.getString("sequence")
val remark = jsonObject.getString("remark")
val splitscoretype = jsonObject.getString("splitscoretype")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(quesviewtype, viewtypename, questiontypeid, description, status, creator, createtime, papertypename, sequence,
remark, splitscoretype, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_question_type")
}
/**
* 解析用户做题情况数据
*
* @param ssc
* @param sparkSession
*/
def etlQzMemberPaperQuestion(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._
ssc.textFile("/user/yyds/ods/QzMemberPaperQuestion.log").filter(item => {
val obj = ParseJsonData.getJsonData(item)
obj.isInstanceOf[JSONObject]
}).mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val userid = jsonObject.getIntValue("userid")
val paperviewid = jsonObject.getIntValue("paperviewid")
val chapterid = jsonObject.getIntValue("chapterid")
val sitecourseid = jsonObject.getIntValue("sitecourseid")
val questionid = jsonObject.getIntValue("questionid")
val majorid = jsonObject.getIntValue("majorid")
val useranswer = jsonObject.getString("useranswer")
val istrue = jsonObject.getString("istrue")
val lasttime = jsonObject.getString("lasttime")
val opertype = jsonObject.getString("opertype")
val paperid = jsonObject.getIntValue("paperid")
val spendtime = jsonObject.getIntValue("spendtime")
val score = BigDecimal.apply(jsonObject.getString("score")).setScale(1, BigDecimal.RoundingMode.HALF_UP)
val question_answer = jsonObject.getIntValue("question_answer")
val dt = jsonObject.getString("dt")
val dn = jsonObject.getString("dn")
(userid, paperviewid, chapterid, sitecourseid, questionid, majorid, useranswer, istrue, lasttime, opertype, paperid, spendtime, score,question_answer, dt, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Append).insertInto("dwd.dwd_qz_member_paper_question")
}
}3)创建DwdController
package com.yyds.qz.controller
import com.yyds.qz.service.EtlDataService
import com.yyds.util.HiveUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 解析做题数据导入dwd层
*/
object DwdController {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "yyds")
val sparkConf = new SparkConf().setAppName("dwd_qz_controller").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
HiveUtil.openDynamicPartition(sparkSession) //开启动态分区
HiveUtil.openCompression(sparkSession) //开启压缩
HiveUtil.useSnappyCompression(sparkSession) //使用snappy压缩
EtlDataService.etlQzChapter(ssc, sparkSession)
EtlDataService.etlQzChapterList(ssc, sparkSession)
EtlDataService.etlQzPoint(ssc, sparkSession)
EtlDataService.etlQzPointQuestion(ssc, sparkSession)
EtlDataService.etlQzSiteCourse(ssc, sparkSession)
EtlDataService.etlQzCourse(ssc, sparkSession)
EtlDataService.etlQzCourseEdusubject(ssc, sparkSession)
EtlDataService.etlQzWebsite(ssc, sparkSession)
EtlDataService.etlQzMajor(ssc, sparkSession)
EtlDataService.etlQzBusiness(ssc, sparkSession)
EtlDataService.etlQzPaperView(ssc, sparkSession)
EtlDataService.etlQzCenterPaper(ssc, sparkSession)
EtlDataService.etlQzPaper(ssc, sparkSession)
EtlDataService.etlQzCenter(ssc, sparkSession)
EtlDataService.etlQzQuestion(ssc, sparkSession)
EtlDataService.etlQzQuestionType(ssc, sparkSession)
EtlDataService.etlQzMemberPaperQuestion(ssc, sparkSession)
}
}4)创建QzChapterDao 章节表dao类
package com.yyds.qz.dao
import org.apache.spark.sql.SparkSession
object QzChapterDao {
/**
* 查询qz_chapter基础数据
*
* @param sparkSession
* @return
*/
def getDwdQzChapter(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select chapterid,chapterlistid,chaptername,sequence,showstatus,status,creator as " +
"chapter_creator,createtime as chapter_createtime,courseid as chapter_courseid,chapternum,outchapterid,dt,dn from dwd.dwd_qz_chapter where " +
s"dt='$dt'")
}
/**
* 查询qz_chapter_list基础数据
*
* @param sparkSession
* @param dt
*/
def getDwdQzChapterList(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select chapterlistid,chapterlistname,chapterallnum,dn from dwd.dwd_qz_chapter_list " +
s"where dt='$dt'")
}
/**
* 查询qz_point基础数据
*
* @param sparkSession
* @param dt
*/
def getDwdQzPoint(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select pointid,pointname,pointyear,chapter,excisenum,pointlistid,chapterid," +
"pointdescribe,pointlevel,typelist,score as point_score,thought,remid,pointnamelist,typelistids,pointlist,dn from " +
s"dwd.dwd_qz_point where dt='$dt'")
}
/**
* 查询qz_point_question基础数据
*
* @param sparkSession
* @param dt
*/
def getDwdQzPointQuestion(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select pointid,questionid,questype,dn from dwd.dwd_qz_point_question where dt='$dt'")
}
}5)创建QzCourseDao 课程表dao类
package com.yyds.qz.dao
import org.apache.spark.sql.SparkSession
object QzCourseDao {
def getDwdQzSiteCourse(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select sitecourseid,siteid,courseid,sitecoursename,coursechapter,sequence,status," +
"creator as sitecourse_creator,createtime as sitecourse_createtime,helppaperstatus,servertype,boardid,showstatus,dt,dn " +
s"from dwd.dwd_qz_site_course where dt='${dt}'")
}
def getDwdQzCourse(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select courseid,majorid,coursename,isadvc,chapterlistid,pointlistid,dn from " +
s"dwd.dwd_qz_course where dt='${dt}'")
}
def getDwdQzCourseEduSubject(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select courseeduid,edusubjectid,courseid,dn from dwd.dwd_qz_course_edusubject " +
s"where dt='${dt}'")
}
}6)创建QzMajorDao 主修表dao类
package com.yyds.qz.dao
import org.apache.spark.sql.SparkSession
object QzMajorDao {
def getQzMajor(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select majorid,businessid,siteid,majorname,shortname,status,sequence,creator as major_creator," +
s"createtime as major_createtime,dt,dn from dwd.dwd_qz_major where dt='$dt'")
}
def getQzWebsite(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select siteid,sitename,domain,multicastserver,templateserver,creator," +
s"createtime,multicastgateway,multicastport,dn from dwd.dwd_qz_website where dt='$dt'")
}
def getQzBusiness(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select businessid,businessname,dn from dwd.dwd_qz_business where dt='$dt'")
}
}7)创建QzPaperDao 试卷dao类
package com.yyds.qz.dao
import org.apache.spark.sql.SparkSession
object QzPaperDao {
def getDwdQzPaperView(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select paperviewid,paperid,paperviewname,paperparam,openstatus,explainurl,iscontest," +
"contesttime,conteststarttime,contestendtime,contesttimelimit,dayiid,status,creator as paper_view_creator," +
"createtime as paper_view_createtime,paperviewcatid,modifystatus,description,papertype,downurl,paperuse," +
s"paperdifficult,testreport,paperuseshow,dt,dn from dwd.dwd_qz_paper_view where dt='$dt'")
}
def getDwdQzCenterPaper(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select paperviewid,sequence,centerid,dn from dwd.dwd_qz_center_paper where dt='$dt'")
}
def getDwdQzPaper(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select paperid,papercatid,courseid,paperyear,chapter,suitnum,papername,totalscore,chapterid," +
s"chapterlistid,dn from dwd.dwd_qz_paper where dt='$dt'")
}
def getDwdQzCenter(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select centerid,centername,centeryear,centertype,centerparam,provideuser," +
s"centerviewtype,stage,dn from dwd.dwd_qz_center where dt='$dt'")
}
}8)创建QzQuestionDao 做题dao类
package com.yyds.qz.dao
import org.apache.spark.sql.SparkSession
object QzQuestionDao {
def getQzQuestion(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select questionid,parentid,questypeid,quesviewtype,content,answer,analysis,limitminute," +
"score,splitscore,status,optnum,lecture,creator,createtime,modifystatus,attanswer,questag,vanalysisaddr,difficulty," +
s"quesskill,vdeoaddr,dt,dn from dwd.dwd_qz_question where dt='$dt'")
}
def getQzQuestionType(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select questypeid,viewtypename,description,papertypename,remark,splitscoretype,dn from " +
s"dwd.dwd_qz_question_type where dt='$dt'")
}
}9)创建UserPaperDetailDao 宽表dao类
package com.yyds.qz.dao
import org.apache.spark.sql.SparkSession
object UserPaperDetailDao {
def getDwdQzMemberPaperQuestion(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select userid,paperviewid,chapterid,sitecourseid,questionid,majorid,useranswer,istrue,lasttime,opertype," +
s"paperid,spendtime,score,question_answer,dt,dn from dwd.dwd_qz_member_paper_question where dt='$dt'")
}
def getDwsQzChapter(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select chapterid,chapterlistid,chaptername,sequence as chapter_sequence,status as chapter_status," +
"chapter_courseid,chapternum,chapterallnum,outchapterid,chapterlistname,pointid,questype,pointname,pointyear" +
",chapter,excisenum,pointlistid,pointdescribe,pointlevel,typelist,point_score,thought,remid,pointnamelist," +
s"typelistids,pointlist,dn from dws.dws_qz_chapter where dt='$dt'")
}
def getDwsQzCourse(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select sitecourseid,siteid,courseid,sitecoursename,coursechapter,sequence as course_sequence," +
"status as course_status,sitecourse_creator,sitecourse_createtime,helppaperstatus,servertype,boardid,showstatus,majorid," +
s"coursename,isadvc,chapterlistid,pointlistid,courseeduid,edusubjectid,dn from dws.dws_qz_course where dt='$dt'")
}
def getDwsQzMajor(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select majorid,businessid,majorname,shortname,status as major_status,sequence as major_sequence," +
"major_creator,major_createtime,businessname,sitename,domain,multicastserver,templateserver,multicastgateway,multicastport," +
s"dn from dws.dws_qz_major where dt=$dt")
}
def getDwsQzPaper(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select paperviewid,paperid,paperviewname,paperparam,openstatus,explainurl,iscontest,contesttime," +
"conteststarttime,contestendtime,contesttimelimit,dayiid,status as paper_status,paper_view_creator,paper_view_createtime," +
"paperviewcatid,modifystatus,description,paperuse,testreport,centerid,sequence as paper_sequence,centername,centeryear," +
"centertype,provideuser,centerviewtype,stage as paper_stage,papercatid,courseid,paperyear,suitnum,papername,totalscore,dn" +
s" from dws.dws_qz_paper where dt=$dt")
}
def getDwsQzQuestion(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select questionid,parentid as question_parentid,questypeid,quesviewtype,content as question_content," +
"answer as question_answer,analysis as question_analysis,limitminute as question_limitminute,score as question_score," +
"splitscore,lecture,creator as question_creator,createtime as question_createtime,modifystatus as question_modifystatus," +
"attanswer as question_attanswer,questag as question_questag,vanalysisaddr as question_vanalysisaddr,difficulty as question_difficulty," +
"quesskill,vdeoaddr,description as question_description,splitscoretype as question_splitscoretype,dn " +
s" from dws.dws_qz_question where dt=$dt")
}
}10)维度退化、合成宽表 业务类
package com.yyds.qz.service
import com.yyds.qz.dao.{QzChapterDao, QzCourseDao, QzMajorDao, QzPaperDao, QzQuestionDao, UserPaperDetailDao}
import org.apache.spark.sql.{SaveMode, SparkSession}
object DwsQzService {
def saveDwsQzChapter(sparkSession: SparkSession, dt: String) = {
val dwdQzChapter = QzChapterDao.getDwdQzChapter(sparkSession, dt)
val dwdQzChapterlist = QzChapterDao.getDwdQzChapterList(sparkSession, dt)
val dwdQzPoint = QzChapterDao.getDwdQzPoint(sparkSession, dt)
val dwdQzPointQuestion = QzChapterDao.getDwdQzPointQuestion(sparkSession, dt)
val result = dwdQzChapter.join(dwdQzChapterlist, Seq("chapterlistid", "dn"))
.join(dwdQzPoint, Seq("chapterid", "dn"))
.join(dwdQzPointQuestion, Seq("pointid", "dn"))
result.select("chapterid", "chapterlistid", "chaptername", "sequence", "showstatus", "showstatus",
"chapter_creator", "chapter_createtime", "chapter_courseid", "chapternum", "chapterallnum", "outchapterid", "chapterlistname",
"pointid", "questionid", "questype", "pointname", "pointyear", "chapter", "excisenum", "pointlistid", "pointdescribe",
"pointlevel", "typelist", "point_score", "thought", "remid", "pointnamelist", "typelistids", "pointlist", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Append).insertInto("dws.dws_qz_chapter")
}
def saveDwsQzCourse(sparkSession: SparkSession, dt: String) = {
val dwdQzSiteCourse = QzCourseDao.getDwdQzSiteCourse(sparkSession, dt)
val dwdQzCourse = QzCourseDao.getDwdQzCourse(sparkSession, dt)
val dwdQzCourseEdusubject = QzCourseDao.getDwdQzCourseEduSubject(sparkSession, dt)
val result = dwdQzSiteCourse.join(dwdQzCourse, Seq("courseid", "dn"))
.join(dwdQzCourseEdusubject, Seq("courseid", "dn"))
.select("sitecourseid", "siteid", "courseid", "sitecoursename", "coursechapter",
"sequence", "status", "sitecourse_creator", "sitecourse_createtime", "helppaperstatus", "servertype", "boardid",
"showstatus", "majorid", "coursename", "isadvc", "chapterlistid", "pointlistid", "courseeduid", "edusubjectid"
, "dt", "dn")
result.coalesce(1).write.mode(SaveMode.Append).insertInto("dws.dws_qz_course")
}
def saveDwsQzMajor(sparkSession: SparkSession, dt: String) = {
val dwdQzMajor = QzMajorDao.getQzMajor(sparkSession, dt)
val dwdQzWebsite = QzMajorDao.getQzWebsite(sparkSession, dt)
val dwdQzBusiness = QzMajorDao.getQzBusiness(sparkSession, dt)
val result = dwdQzMajor.join(dwdQzWebsite, Seq("siteid", "dn"))
.join(dwdQzBusiness, Seq("businessid", "dn"))
.select("majorid", "businessid", "siteid", "majorname", "shortname", "status", "sequence",
"major_creator", "major_createtime", "businessname", "sitename", "domain", "multicastserver", "templateserver",
"multicastgateway", "multicastport", "dt", "dn")
result.coalesce(1).write.mode(SaveMode.Append).insertInto("dws.dws_qz_major")
}
def saveDwsQzPaper(sparkSession: SparkSession, dt: String) = {
val dwdQzPaperView = QzPaperDao.getDwdQzPaperView(sparkSession, dt)
val dwdQzCenterPaper = QzPaperDao.getDwdQzCenterPaper(sparkSession, dt)
val dwdQzCenter = QzPaperDao.getDwdQzCenter(sparkSession, dt)
val dwdQzPaper = QzPaperDao.getDwdQzPaper(sparkSession, dt)
val result = dwdQzPaperView.join(dwdQzCenterPaper, Seq("paperviewid", "dn"), "left")
.join(dwdQzCenter, Seq("centerid", "dn"), "left")
.join(dwdQzPaper, Seq("paperid", "dn"))
.select("paperviewid", "paperid", "paperviewname", "paperparam", "openstatus", "explainurl", "iscontest"
, "contesttime", "conteststarttime", "contestendtime", "contesttimelimit", "dayiid", "status", "paper_view_creator",
"paper_view_createtime", "paperviewcatid", "modifystatus", "description", "paperuse", "paperdifficult", "testreport",
"paperuseshow", "centerid", "sequence", "centername", "centeryear", "centertype", "provideuser", "centerviewtype",
"stage", "papercatid", "courseid", "paperyear", "suitnum", "papername", "totalscore", "chapterid", "chapterlistid",
"dt", "dn")
result.coalesce(1).write.mode(SaveMode.Append).insertInto("dws.dws_qz_paper")
}
def saveDwsQzQuestionTpe(sparkSession: SparkSession, dt: String) = {
val dwdQzQuestion = QzQuestionDao.getQzQuestion(sparkSession, dt)
val dwdQzQuestionType = QzQuestionDao.getQzQuestionType(sparkSession, dt)
val result = dwdQzQuestion.join(dwdQzQuestionType, Seq("questypeid", "dn"))
.select("questionid", "parentid", "questypeid", "quesviewtype", "content", "answer", "analysis"
, "limitminute", "score", "splitscore", "status", "optnum", "lecture", "creator", "createtime", "modifystatus"
, "attanswer", "questag", "vanalysisaddr", "difficulty", "quesskill", "vdeoaddr", "viewtypename", "papertypename",
"remark", "splitscoretype", "dt", "dn")
result.coalesce(1).write.mode(SaveMode.Append).insertInto("dws.dws_qz_question")
}
def saveDwsUserPaperDetail(sparkSession: SparkSession, dt: String) = {
val dwdQzMemberPaperQuestion = UserPaperDetailDao.getDwdQzMemberPaperQuestion(sparkSession, dt).drop("paperid")
.withColumnRenamed("question_answer", "user_question_answer")
val dwsQzChapter = UserPaperDetailDao.getDwsQzChapter(sparkSession, dt).drop("courseid")
val dwsQzCourse = UserPaperDetailDao.getDwsQzCourse(sparkSession, dt).withColumnRenamed("sitecourse_creator", "course_creator")
.withColumnRenamed("sitecourse_createtime", "course_createtime").drop("majorid")
.drop("chapterlistid").drop("pointlistid")
val dwsQzMajor = UserPaperDetailDao.getDwsQzMajor(sparkSession, dt)
val dwsQzPaper = UserPaperDetailDao.getDwsQzPaper(sparkSession, dt).drop("courseid")
val dwsQzQuestion = UserPaperDetailDao.getDwsQzQuestion(sparkSession, dt)
dwdQzMemberPaperQuestion.join(dwsQzCourse, Seq("sitecourseid", "dn")).
join(dwsQzChapter, Seq("chapterid", "dn")).join(dwsQzMajor, Seq("majorid", "dn"))
.join(dwsQzPaper, Seq("paperviewid", "dn")).join(dwsQzQuestion, Seq("questionid", "dn"))
.select("userid", "courseid", "questionid", "useranswer", "istrue", "lasttime", "opertype",
"paperid", "spendtime", "chapterid", "chaptername", "chapternum",
"chapterallnum", "outchapterid", "chapterlistname", "pointid", "questype", "pointyear", "chapter", "pointname"
, "excisenum", "pointdescribe", "pointlevel", "typelist", "point_score", "thought", "remid", "pointnamelist",
"typelistids", "pointlist", "sitecourseid", "siteid", "sitecoursename", "coursechapter", "course_sequence", "course_status"
, "course_creator", "course_createtime", "servertype", "helppaperstatus", "boardid", "showstatus", "majorid", "coursename",
"isadvc", "chapterlistid", "pointlistid", "courseeduid", "edusubjectid", "businessid", "majorname", "shortname",
"major_status", "major_sequence", "major_creator", "major_createtime", "businessname", "sitename",
"domain", "multicastserver", "templateserver", "multicastgateway", "multicastport", "paperviewid", "paperviewname", "paperparam",
"openstatus", "explainurl", "iscontest", "contesttime", "conteststarttime", "contestendtime", "contesttimelimit",
"dayiid", "paper_status", "paper_view_creator", "paper_view_createtime", "paperviewcatid", "modifystatus", "description", "paperuse",
"testreport", "centerid", "paper_sequence", "centername", "centeryear", "centertype", "provideuser", "centerviewtype",
"paper_stage", "papercatid", "paperyear", "suitnum", "papername", "totalscore", "question_parentid", "questypeid",
"quesviewtype", "question_content", "question_answer", "question_analysis", "question_limitminute", "score",
"splitscore", "lecture", "question_creator", "question_createtime", "question_modifystatus", "question_attanswer",
"question_questag", "question_vanalysisaddr", "question_difficulty", "quesskill", "vdeoaddr", "question_description",
"question_splitscoretype", "user_question_answer", "dt", "dn").coalesce(1)
.write.mode(SaveMode.Append).insertInto("dws.dws_user_paper_detail")
}
}11)创建DwsController
package com.yyds.qz.controller
import com.yyds.qz.service.DwsQzService
import com.yyds.util.HiveUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DwsController {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "yyds")
val sparkConf = new SparkConf().setAppName("dws_qz_controller").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
HiveUtil.openDynamicPartition(sparkSession) //开启动态分区
HiveUtil.openCompression(sparkSession) //开启压缩
HiveUtil.useSnappyCompression(sparkSession) //使用snappy压缩
val dt = "20190722"
DwsQzService.saveDwsQzChapter(sparkSession, dt)
DwsQzService.saveDwsQzCourse(sparkSession, dt)
DwsQzService.saveDwsQzMajor(sparkSession, dt)
DwsQzService.saveDwsQzPaper(sparkSession, dt)
DwsQzService.saveDwsQzQuestionTpe(sparkSession, dt)
DwsQzService.saveDwsUserPaperDetail(sparkSession, dt)
}
}12)报表层各指标统计(Spark Sql)
package com.yyds.qz.dao
import org.apache.spark.sql.SparkSession
object AdsQzDao {
/**
* 统计各试卷平均耗时 平均分
*
* @param sparkSession
* @param dt
* @return
*/
def getAvgSPendTimeAndScore(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select paperviewid,paperviewname,cast(avg(score) as decimal(4,1)) score,cast(avg(spendtime) as decimal(10,2))" +
s" spendtime,dt,dn from dws.dws_user_paper_detail where dt='$dt' group by " +
"paperviewid,paperviewname,dt,dn order by score desc,spendtime desc");
}
/**
* 统计试卷 最高分 最低分
*
* @param sparkSession
* @param dt
*/
def getTopScore(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select paperviewid,paperviewname,cast(max(score) as decimal(4,1)),cast(min(score) as decimal(4,1)) " +
s",dt,dn from dws.dws_user_paper_detail where dt=$dt group by paperviewid,paperviewname,dt,dn ")
}
/**
* 按试卷分组获取每份试卷的分数前三用户详情
*
* @param sparkSession
* @param dt
*/
def getTop3UserDetail(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select *from (select userid,paperviewname,chaptername,pointname,sitecoursename,coursename,majorname,shortname," +
"sitename,papername,score,dense_rank() over (partition by paperviewid order by score desc) as rk,dt,dn from dws.dws_user_paper_detail) " +
"where rk<4")
}
/**
* 按试卷分组获取每份试卷的分数倒数三的用户详情
*
* @param sparkSession
* @param dt
* @return
*/
def getLow3UserDetail(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select *from (select userid,paperviewname,chaptername,pointname,sitecoursename,coursename,majorname,shortname," +
s"sitename,papername,score,dense_rank() over (partition by paperviewid order by score asc) as rk,dt,dn from dws.dws_user_paper_detail where dt='$dt') where rk<4")
}
/**
* 统计各试卷 各分段学员名称
*/
def getPaperScoreSegmentUser(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select paperviewid,paperviewname,score_segment,concat_ws(',',collect_list(cast(userid as string))),dt,dn" +
" from (select paperviewid,paperviewname,userid," +
" case when score >=0 and score <=20 then '0-20'" +
" when score >20 and score <=40 then '20-40' " +
" when score >40 and score <=60 then '40-60' " +
" when score >60 and score <=80 then '60-80' " +
" when score >80 and score <=100 then '80-100' end as score_segment" +
s",dt,dn from dws.dws_user_paper_detail where dt='$dt') group by paperviewid,paperviewname,score_segment,dt,dn order by paperviewid,score_segment")
}
/**
* 统计各试卷未及格人数 及格人数 及格率
*
* @param sparkSession
* @param dt
*/
def getPaperPassDetail(sparkSession: SparkSession, dt: String) = {
sparkSession.sql("select t.*,cast(t.passcount/(t.passcount+t.countdetail) as decimal(4,2)) as rate,dt,dn" +
" from(select a.paperviewid,a.paperviewname,a.countdetail,a.dt,a.dn,b.passcount from " +
s"(select paperviewid,paperviewname,count(*) countdetail,dt,dn from dws.dws_user_paper_detail where dt='$dt' and score between 0 and 60 group by" +
s" paperviewid,paperviewname,dt,dn) a join (select paperviewid,count(*) passcount,dn from dws.dws_user_paper_detail where dt='$dt' and score >60 " +
"group by paperviewid,dn) b on a.paperviewid=b.paperviewid and a.dn=b.dn)t")
}
/**
* 统计各题 正确人数 错误人数 错题率 top3错误题数多的questionid
*
* @param sparkSession
* @param dt
*/
def getQuestionDetail(sparkSession: SparkSession, dt: String) = {
sparkSession.sql(s"select t.*,cast(t.errcount/(t.errcount+t.rightcount) as decimal(4,2))as rate" +
s" from((select questionid,count(*) errcount,dt,dn from dws.dws_user_paper_detail where dt='$dt' and user_question_answer='0' " +
s"group by questionid,dt,dn) a join(select questionid,count(*) rightcount,dt,dn from dws.dws_user_paper_detail where dt='$dt' and user_question_answer='1' " +
s"group by questionid,dt,dn) b on a.questionid=b.questionid and a.dn=b.dn)t order by errcount desc")
}
}13)报表层各指标统计(DataFrame Api)
package com.yyds.qz.service
import com.yyds.qz.dao.AdsQzDao
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{SaveMode, SparkSession}
object AdsQzService {
def getTarget(sparkSession: SparkSession, dt: String) = {
val avgDetail = AdsQzDao.getAvgSPendTimeAndScore(sparkSession, dt)
val topscore = AdsQzDao.getTopScore(sparkSession, dt)
val top3UserDetail = AdsQzDao.getTop3UserDetail(sparkSession, dt)
val low3UserDetail = AdsQzDao.getLow3UserDetail(sparkSession, dt)
val paperScore = AdsQzDao.getPaperScoreSegmentUser(sparkSession, dt)
val paperPassDetail = AdsQzDao.getPaperPassDetail(sparkSession, dt)
val questionDetail = AdsQzDao.getQuestionDetail(sparkSession, dt)
}
def getTargetApi(sparkSession: SparkSession, dt: String) = {
import org.apache.spark.sql.functions._
val avgDetail = sparkSession.sql("select paperviewid,paperviewname,score,spendtime,dt,dn from dws.dws_user_paper_detail ")
.where(s"dt=${dt}").groupBy("paperviewid", "paperviewname", "dt", "dn").
agg(avg("score").cast("decimal(4,1)").as("avgscore"),
avg("spendtime").cast("decimal(10,1)").as("avgspendtime"))
.select("paperviewid", "paperviewname", "avgscore", "avgspendtime", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Append).insertInto("ads.ads_paper_avgtimeandscore")
val topscore = sparkSession.sql("select paperviewid,paperviewname,score,dt,dn from dws.dws_user_paper_detail")
.where(s"dt=$dt").groupBy("paperviewid", "paperviewname", "dt", "dn")
.agg(max("score").as("maxscore"), min("score").as("minscore"))
.select("paperviewid", "paperviewname", "maxscore", "minscore", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Append).insertInto("ads.ads_paper_maxdetail")
val top3UserDetail = sparkSession.sql("select *from dws.dws_user_paper_detail")
.where(s"dt=$dt").select("userid", "paperviewid", "paperviewname", "chaptername", "pointname"
, "sitecoursename", "coursename", "majorname", "shortname", "papername", "score", "dt", "dn")
.withColumn("rk", dense_rank().over(Window.partitionBy("paperviewid").orderBy(desc("score"))))
.where("rk<4")
.select("userid", "paperviewid", "paperviewname", "chaptername", "pointname", "sitecoursename"
, "coursename", "majorname", "shortname", "papername", "score", "rk", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Append).insertInto("ads.ads_top3_userdetail")
val low3UserDetail = sparkSession.sql("select *from dws.dws_user_paper_detail")
.where(s"dt=$dt").select("userid", "paperviewid", "paperviewname", "chaptername", "pointname"
, "sitecoursename", "coursename", "majorname", "shortname", "papername", "score", "dt", "dn")
.withColumn("rk", dense_rank().over(Window.partitionBy("paperviewid").orderBy("score")))
.where("rk<4")
.select("userid", "paperviewid", "paperviewname", "chaptername", "pointname", "sitecoursename"
, "coursename", "majorname", "shortname", "papername", "score", "rk", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Append).insertInto("ads.ads_low3_userdetail")
val paperScore = sparkSession.sql("select *from dws.dws_user_paper_detail")
.where(s"dt=$dt")
.select("paperviewid", "paperviewname", "userid", "score", "dt", "dn")
.withColumn("score_segment",
when(col("score").between(0, 20), "0-20")
.when(col("score") > 20 && col("score") <= 40, "20-40")
.when(col("score") > 40 && col("score") <= 60, "40-60")
.when(col("score") > 60 && col("score") <= 80, "60-80")
.when(col("score") > 80 && col("score") <= 100, "80-100"))
.drop("score").groupBy("paperviewid", "paperviewname", "score_segment", "dt", "dn")
.agg(concat_ws(",", collect_list(col("userid").cast("string").as("userids"))).as("userids"))
.select("paperviewid", "paperviewname", "score_segment", "userids", "dt", "dn")
.orderBy("paperviewid", "score_segment")
.coalesce(1).write.mode(SaveMode.Append).insertInto("ads.ads_paper_scoresegment_user")
val paperPassDetail = sparkSession.sql("select * from dws.dws_user_paper_detail").cache()
val unPassDetail = paperPassDetail.select("paperviewid", "paperviewname", "dn", "dt")
.where(s"dt='$dt'").where("score between 0 and 60")
.groupBy("paperviewid", "paperviewname", "dn", "dt")
.agg(count("paperviewid").as("unpasscount"))
val passDetail = paperPassDetail.select("paperviewid", "dn")
.where(s"dt='$dt'").where("score >60")
.groupBy("paperviewid", "dn")
.agg(count("paperviewid").as("passcount"))
unPassDetail.join(passDetail, Seq("paperviewid", "dn")).
withColumn("rate", (col("passcount")./(col("passcount") + col("unpasscount")))
.cast("decimal(4,2)"))
.select("paperviewid", "paperviewname", "unpasscount", "passcount", "rate", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Append).insertInto("ads.ads_user_paper_detail")
paperPassDetail.unpersist()
val userQuestionDetail = sparkSession.sql("select * from dws.dws_user_paper_detail").cache()
val userQuestionError = userQuestionDetail.select("questionid", "dt", "dn", "user_question_answer")
.where(s"dt='$dt'").where("user_question_answer='0'").drop("user_question_answer")
.groupBy("questionid", "dt", "dn")
.agg(count("questionid").as("errcount"))
val userQuestionRight = userQuestionDetail.select("questionid", "dn", "user_question_answer")
.where(s"dt='$dt'").where("user_question_answer='1'").drop("user_question_answer")
.groupBy("questionid", "dn")
.agg(count("questionid").as("rightcount"))
userQuestionError.join(userQuestionRight, Seq("questionid", "dn"))
.withColumn("rate", (col("errcount") / (col("errcount") + col("rightcount"))).cast("decimal(4,2)"))
.orderBy(desc("errcount")).coalesce(1)
.select("questionid", "errcount", "rightcount", "rate", "dt", "dn")
.write.mode(SaveMode.Append).insertInto("ads.ads_user_question_detail")
}
}14)Datax将统计指标导入mysql中
创建各表对应json文件:
user_questiondetail.json:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/ads.db/ads_user_question_detail/dt=${dt}/dn=${dn}/*",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode30,namenode37",
"dfs.namenode.rpc-address.nameservice1.namenode30": "hadoop001:8020",
"dfs.namenode.rpc-address.nameservice1.namenode37": "hadoop002:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"defaultFS": "hdfs://nameservice1",
"column": [{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"value": "${dt}",
"type": "string"
},
{
"value": "${dn}",
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"questionid",
"errcount",
"rightcount",
"rate",
"dt",
"dn"
],
"preSql": [
"delete from user_question_detail where dt=${dt}"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop003:3306/qz_paper?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": [
"user_question_detail"
]
}]
}
}
}]
}
}
user_paperdetail.json:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/ads.db/ads_user_paper_detail/dt=${dt}/dn=${dn}/*",
"defaultFS": "hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode30,namenode37",
"dfs.namenode.rpc-address.nameservice1.namenode30": "hadoop001:8020",
"dfs.namenode.rpc-address.nameservice1.namenode37": "hadoop002:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"column": [{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type":"string"
},
{
"value": "${dt}",
"type": "string"
},
{
"value": "${dn}",
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"paperviewid",
"paperviewname",
"unpasscount",
"passcount",
"rate",
"dt",
"dn"
],
"preSql": [
"delete from user_paper_detail where dt=${dt}"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop003:3306/qz_paper?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": [
"user_paper_detail"
]
}]
}
}
}]
}
}
top3_userdetail.json:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/ads.db/ads_top3_userdetail/dt=${dt}/dn=${dn}/*",
"defaultFS": "hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode30,namenode37",
"dfs.namenode.rpc-address.nameservice1.namenode30": "hadoop001:8020",
"dfs.namenode.rpc-address.nameservice1.namenode37": "hadoop002:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"column": [{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
},
{
"index": 5,
"type": "string"
},
{
"index": 6,
"type": "string"
},
{
"index": 7,
"type": "string"
},
{
"index": 8,
"type": "string"
},
{
"index": 9,
"type": "string"
},
{
"index": 10,
"type": "string"
},
{
"index": 11,
"type": "string"
},
{
"value": "${dt}",
"type": "string"
},
{
"value": "${dn}",
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"userid",
"paperviewid",
"paperviewname",
"chaptername",
"pointname",
"sitecoursename",
"coursename",
"majorname",
"shortname",
"papername",
"score",
"rk",
"dt",
"dn"
],
"preSql": [
"delete from top3_userdetail where dt=${dt}"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop003:3306/qz_paper?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": [
"top3_userdetail"
]
}]
}
}
}]
}
}
paper_maxdetail.json:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/ads.db/ads_paper_maxdetail/dt=${dt}/dn=${dn}/*",
"defaultFS": "hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode30,namenode37",
"dfs.namenode.rpc-address.nameservice1.namenode30": "hadoop001:8020",
"dfs.namenode.rpc-address.nameservice1.namenode37": "hadoop002:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"column": [{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"value": "${dt}",
"type": "string"
},
{
"value": "${dn}",
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"paperviewid",
"paperviewname",
"maxscore",
"minscore",
"dt",
"dn"
],
"preSql": [
"delete from paper_maxdetail where dt=${dt}"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop003:3306/qz_paper?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": [
"paper_maxdetail"
]
}]
}
}
}]
}
}
low3_userdetail.json:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/ads.db/ads_low3_userdetail/dt=${dt}/dn=${dn}/*",
"defaultFS": "hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode30,namenode37",
"dfs.namenode.rpc-address.nameservice1.namenode30": "hadoop001:8020",
"dfs.namenode.rpc-address.nameservice1.namenode37": "hadoop002:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"column": [{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
},
{
"index": 5,
"type": "string"
},
{
"index": 6,
"type": "string"
},
{
"index": 7,
"type": "string"
},
{
"index": 8,
"type": "string"
},
{
"index": 9,
"type": "string"
},
{
"index": 10,
"type": "string"
},
{
"index": 11,
"type": "string"
},
{
"value": "${dt}",
"type": "string"
},
{
"value": "${dn}",
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"userid",
"paperviewid",
"paperviewname",
"chaptername",
"pointname",
"sitecoursename",
"coursename",
"majorname",
"shortname",
"papername",
"score",
"rk",
"dt",
"dn"
],
"preSql": [
"delete from low3_userdetail where dt=${dt}"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop003:3306/qz_paper?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": [
"low3_userdetail"
]
}]
}
}
}]
}
}
avgtimeandscore.json:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "hdfs://nameservice1/user/hive/warehouse/ads.db/ads_paper_avgtimeandscore/dt=${dt}/dn=${dn}/*",
"defaultFS": "hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode30,namenode37",
"dfs.namenode.rpc-address.nameservice1.namenode30": "hadoop001:8020",
"dfs.namenode.rpc-address.nameservice1.namenode37": "hadoop002:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"column": [{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"value": "${dt}",
"type": "string"
},
{
"value": "${dn}",
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"paperviewid",
"paperviewname",
"avgscore",
"avgspendtime",
"dt",
"dn"
],
"preSql": [
"delete from paper_avgtimeandscore where dt=${dt}"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop003:3306/qz_paper?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"table": [
"paper_avgtimeandscore"
]
}]
}
}
}]
}
}
下载datax:
执行pyton命令:
python /opt/module/datax/bin/datax.py avgtimeandscore.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py low3_userdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py paper_maxdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py paper_scoresegment.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py top3_userdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py user_paperdetail.json -p "-Ddt=20190722 -Ddn=webA"
python /opt/module/datax/bin/datax.py user_questiondetail.json -p "-Ddt=20190722 -Ddn=webA"九、项目调优
1、append和overwrite的区别
append 模式在原有分区上进行追加数据操作,overwrite在原有分区上进行全量刷新操作
2、coalesce和repartition
coalesce和repartiton都用于改变分区,coalesce用于缩小分区且不会进行shuffle,repartion用于增大分区(提供并行度)会进行shuffle,在spark中减少文件个数会使用coalesce来减少分区来到这个目的。但是如果数据量过大,分区数过少会出现OOM所以coalesce缩小分区个数也需合理
3、select方法
当业务需求只取DataFrame的某几列时可以使用select方法来获取其中几列
DataFrame.select(“字段1”,“字段2”,“字段3”) 方法返回值为Dataframe。
4、DataFrame join的两种方式
- DataFrameA.join(DataFrameB,DataFrameA(“字段名”)===DataFrameB(“字段名”))
- DataFrameA.join(DataFrameB,Seq(“字段名”,“字段名”))
两种方式区别在于 第一种不会去重,第二种会去重。
DataFrame join DataFrameB 默认使用inner join,如果需要改变join方式在join方法中第三个参数指定,left或right。
5、drop方法
DataFrame.drop(“colname”) 删除dataframe总的某列。
6、withColum方法
当需要对DataFrame新增列时可以使用withColum方法
DataFrame.withColumn(“新增列名”,Column) 第二个参数为列,需要使用表达式
如果需要新增一个固定值的列比如 在result DataFrame上新增姓名 “张三”
result.withColumn(“name”,lit(“张三”) ) 可以使用lit方法在增加固定值
如果需要新增像排序列类似的那么就需要编写相应的函数
7、排序与窗口函数
比如在上述的需求中需要新增一列排序列:
import org.apache.spark.sql.functions._
result.withColumn("rownum", row_number().over(Window.partitionBy("website", "memberlevel").orderBy(desc("paymoney"))))需要先导包:
import org.apache.spark.sql.functions._才能使用row_number方法,所有在functions类下的方法都需要这部操作。
调用窗口函数为:
Window.partitionBy() 方法内可以有多个列名,基于这些列去排序。
如果对结果需要排序再继续追加Order by方法,方法内可以有多个列名。
在Order by 中可以默认asc升序 可以使用desc(“列名”)来进行一个倒叙排序。
8、cache级别

分别是:
- DISK_ONLY:只缓存到磁盘没有副本
- DISK_ONLY_2:只缓存到磁盘有2份副本
- MEMORY_ONLY:只缓存到内存没有副本
- MEMORY_ONLY_2:只缓存到内存有2份副本
- MEMORY_ONLY_SER:只缓存到内存并且序列化没有副本
- MEMORY_ONLY_SER_2:只缓存到内存并且序列化有2份副本
- MEMORY_AND_DISK:缓存到内存和磁盘没有副本,如果内存放不下溢写到磁盘
- MEMORY_AND_DISK_2:缓存到内存和磁盘有2份副本,如果内存放不下溢写到磁盘
- MEMORY_AND_DISK_SER:缓存到内存和磁盘并且序列化,如果内存放不下溢写到磁盘
- MEMORY_ADN_DISK_SER_2:缓存到内存和磁盘并且序列化有2份副本,如果内存放不下溢写到磁盘
- OFF_HEAP:缓存到堆外内存
- 那么DataFrame的cache默认采用 MEMORY_AND_DISK 这和RDD 的默认方式不一样RDD cache 默认采用MEMORY_ONLY

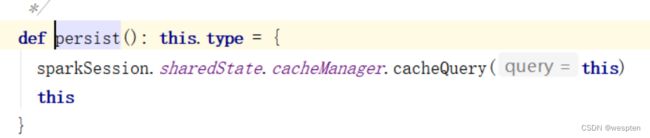
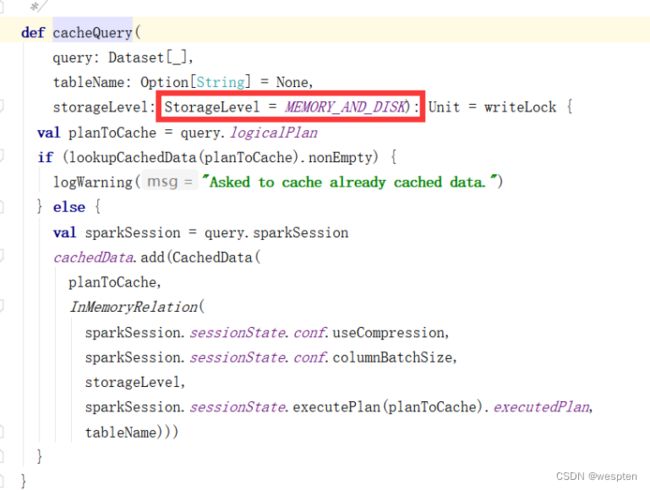
9、释放缓存与缓存方法
缓存:(1)dataFrame.cache (2)sparkSession.catalog.cacheTable(“tableName”)
释放缓存:(1)dataFrame.unpersist (2)sparkSession.catalog.uncacheTable(“tableName”)
10、Spark Sql默认并行度
Spark sql默认shuffle分区数为200 可对spark.sql.shuffle.partitions参数进行修改。
11、Kryo序列化

根据官网描述 kryo序列化比java序列化更快更紧凑,但spark默认的序列化是java序列化并不是spark序列化,因为spark并不支持所有序列化类型,而且每次使用都必须进行注册。
那么在使用kryo序列化后再使用序列化缓存能够非常大的减小内存所使用的大小。
所以对内存上的优化我们可以使用kryo来进行优化。
但是根据官网描述序列化缓存级别对cpu使用并不友好。
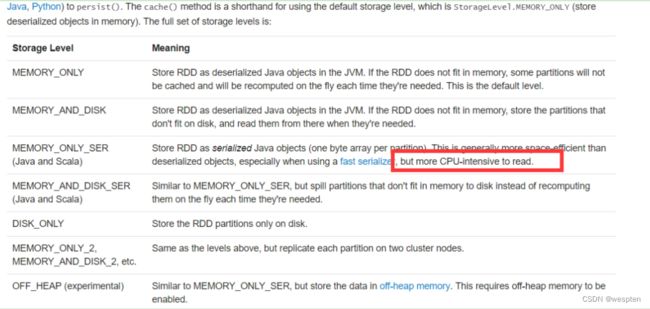
所以什么场景下使用cache,什么场景下使用序列化缓存?
在集群资源绝对充足的情况下推荐直接使用cache:

如何使用以上述需求为例:
![]()
result为DataSet[QueryResult],那么需要对QueryResult进行keyo注册。

注册完毕后进行缓存:
![]()
官方例子:
因为DataSet本身进行了优化 所以测试先用rdd测试:
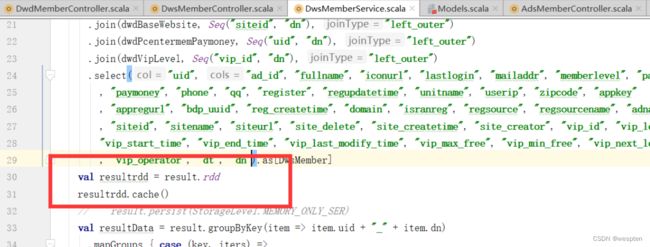
将DataSet转换为rdd先使用默认java序列化 并且cache方法 缓存大小为 696.MB并且没有缓存所有分区:

rdd中使用kryo序列化 使用persist(StorageLevel.MEMORY_ONLY_SER) 缓存大小优化减小为270.3Mb:

再使用DataSet来测试,无需序列化模式和注册类型,直接如图使用cache缓存 缓存大小为 37Mb:
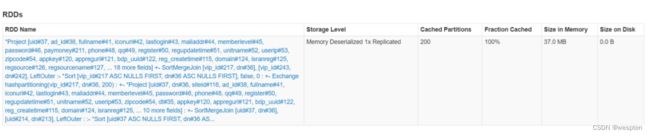
使用StorageLevel.MEMORY_ONLY_SER缓存 缓存大小为36.6MB。

12、dataframe的groupbykey
dataframe并没有reducebykey算子,只有reduce算子但是reduce算子并不符合业务需求,那么需要使用Spark2.0新增算子groupbykey,groupbykey后返回结果会转换成KeyValueGroupDataSet,开发者可以自定义key,groupbykey后数据集就变成了一个
(key,iterable[bean1,bean2,bean3]) bean为dataset所使用的实体类,groupbykey后,会将所有符合key规则的数据聚合成一个迭代器放在value处,那么如果我们需要对key和value进行重组就可以是用mapGroups算子,针对这一对key,value数据,可以对value集合内的数据进行求和处理重组一个返回对象,mapGroups的返回值是一个DataSeT,那么返回的就是你所重组的DataSet,操作类似于rdd groupbykey map。
如果需要保留key,只需要对value进行重构那么可以调用mapValues方法重构value,再进行reduceGroups对value内的各属性进行汇总.
代码样例:
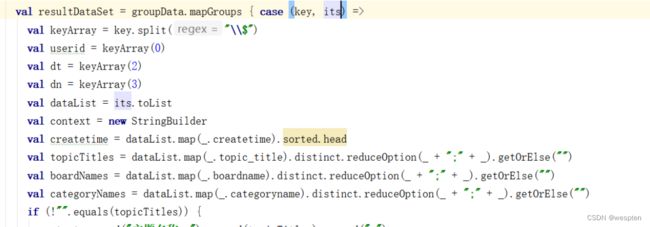
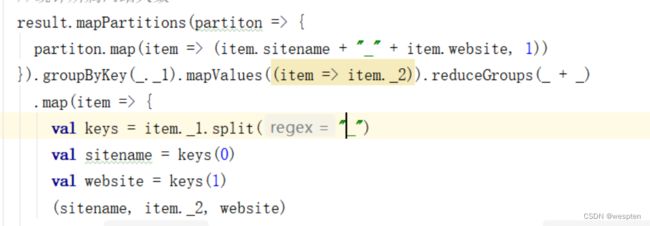
13、创建临时表和全局临时表
普通临时表只是针对于一个spark session,而全局临时表了引用于所有spark session
创建方法:
DataFrame.createTempView() 创建普通临时表
DataFrame.createGlobalTempView() DataFrame.createOrReplaceTempView() 创建全局临时表
14、BroadCast join
表与表之间进行join涉及到分区与分区之间的数据传输,会进行shuffle。在大表join小表的时候我们可以用广播join来进行优化避免shuffle,从而提高效率。广播join的实现原理为,将小表查出先聚合到driver端,再由driver广播到每个executor上。
代码实现:
import org.apache.spark.sql.functions.broadcast
broadcast(spark.table("src")).join(spark.table("records"), "key").show()广播join小表默认值 10MB。
可以通过spark.sql.autoBroadcastJoinThread 参数去设置。
并不是所有情况都适合使用broadcast join,当两张表数据量都非常大时如果使用broadcast join,那么从driver端传输到executor端的时间将会非常久,当网络传输时间大于shuffle时间的情况下就没有必要去使用broadcast join了。
不使用广播join stage和shuffle 如下:
使用广播join 将小表进行广播 减少了stage 和shuffle的数据量 达到优化效果:
15、控制Spark reduce缓冲 调优shuffle
spark.reducer.maxSizeInFilght 此参数为reduce task能够拉取多少数据量的一个参数默认48MB,当集群资源足够时,增大此参数可减少reduce拉取数据量的次数,从而达到优化shuffle的效果,一般调大为96MB,资源够大可继续往上跳。
spark.shuffle.file.buffer 此参数为每个shuffle文件输出流的内存缓冲区大小,调大此参数可以减少在创建shuffle文件时进行磁盘搜索和系统调用的次数,默认参数为32k 一般调大为64k。
16、注册udf函数
def spliceAttr(spark: SparkSession) = {
spark.udf.register("spliceAttr", (v1: String, v2: String) => {
"attr_name:" + v1 +" attr_value:" + v2
})
}
十、其他
1、项目打包
对com_yyds_warhouse打包上传到linux机上:
执行相应spark-submit命令:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.yyds.member.controller.DwdMemberController com_yyds_warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.yyds.member.controller.DwsMemberController com_yyds_warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.yyds.member.controller.AdsMemberController com_yyds_warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.yyds.qz.controller.DwdController com_yyds_warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.yyds.qz.controller.DwsController com_yyds_warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --class com.yyds.qz.controller.AdsController com_yyds_warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar2、本地Intelij idea连接集群环境操作
本机环境必须能ping通集群ip地址和 telnet通端口号。
获取hive-site.xml配置文件
从集群上获取到hive-site.xml,将hive-site.xml放到resources源码包下 这样就可以在本地Intelij idea上使用local模式直接进行操作。
3、debug调试
普通的debug调试这就不写了,本地调试的时候如何在海量数据中找出某一条想要的数据进行调试。
首先打个普通断点,断点位于你想要的调试处:
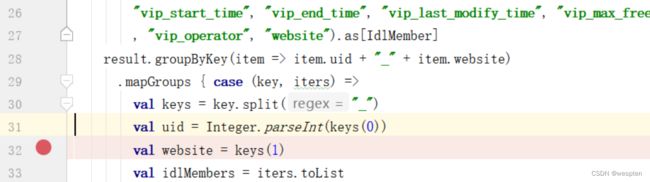
选中断点右键:
在condition处编写条件,比如我想调试uid为1001的用户。
编写完毕后点击done 然后启动debug模式运行代码,当uid为1001的数据到达此断点处则进入debug模式,其余数据则会过滤不进入debug模式。
4、Datax
下载地址:
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
针对需要读取数据库,和需要写入的数据 点击查看相应帮助。
如:本项目需要从hive导入到mysql那么就点击hive的读和mysql的写查看相应帮助。
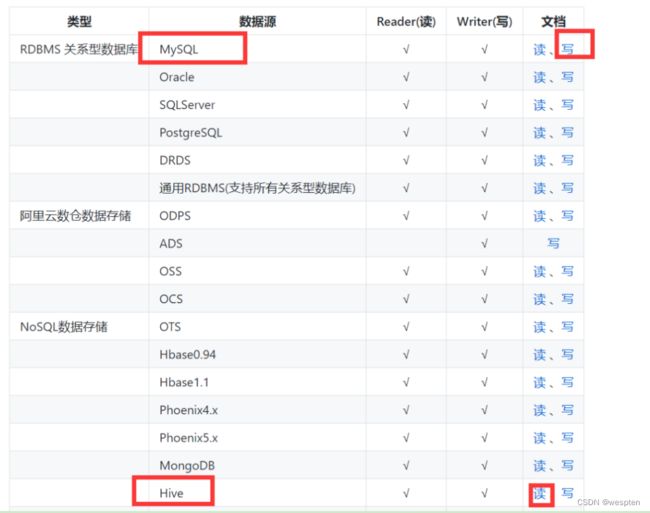
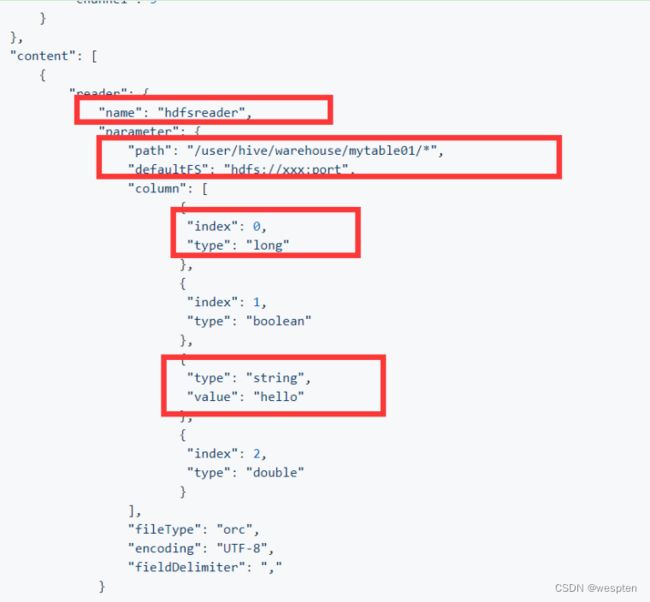 Name:指定相应reader针对 hive选择hdfsreader
Name:指定相应reader针对 hive选择hdfsreader
Path:需要读取的hdfs路径
defaultFs:对应 NameNode ip地址 和端口号
Index :hdfs文件下列下标
Type:列的类型,可以都写成string
Value:如果想在某一列中传固定值,那json的key值选value 不使用index
Filetype:指定文件存储类型

指定writername:为mysqlwriter,因为写入库为mysql。
Username:mysql账号。
Password:mysql密码。
preSql:执行Datax导入数据前需要执行的sql语句,如:导入数据前清除表中数据。
其他常用参数:
动态传参:
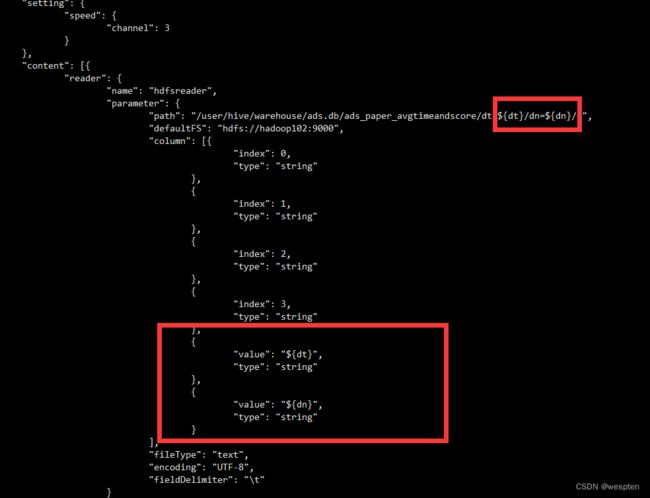
在实际应用当中,往往会需要动态传入分区字段,那么在json文件中,可以选择${参数值}来进行传参 相应的在执行命令上 使用-p “ -D参数值” 进行传参
jvm参数:
在datax 中导数据使用过程中往往会因为,目标数据过大导致datax oom,那么可以调大datax的jvm参数来防止oom,在python命令后,使用 -jvm=”-Xms5G -Xmx 5G”来调大
python datax.py --jvm="-Xms5G -Xmx5G" ../job/test.jsonwriteMode Insert ignore
当datax 导入mysql数据时,可能会因为有有数据报错,导致datax导数据会异常慢,那么可以修改mysqlwriter的writeMode模式 修改为Insert ignore 忽略报错,速度会显著提升。
java.io.IOException: Maximum column length of 100,000 exceeded in column...异常信息
如果报java.io.IOException: Maximum column length of 100,000 exceeded in column...异常信息,说明数据源column字段长度超过了100000字符。
需要在json的reader里增加如下配置:
"csvReaderConfig":{
"safetySwitch": false,
"skipEmptyRecords": false,
"useTextQualifier": false
}
safetySwitch = false;//单列长度不限制100000字符5、需要注意的点
(1)每次数据重组后 插入表之前需要缩小分区来减小文件个数,使用coalesce 算子(但数据量大 并行度小会造成OOM 所以需要合理缩小并行度) 缩小分区使用coalesce 增大分区使用repartition
(2)使用API写代码时需要注意Spark版本,groupByKey 是Spark2.0新增算子,调用后数据返回结果是KeyValueGroupedDataset。
(3)调用row_number、broadcast 需要导包
import org.apache.spark.sql.functions._但是,这个类的所有方法也只有在Spark2.0后能正常使用,在Spark 1.6中虽然有这个类,但是必须转换成hiveContext,才能使用类里的方法。需要记住广播join(broadcat join)触发的默认值(数据量小于等于10MB)