MM2018/风格迁移-Style Separation and Synthesis via Generative Adversarial Networks通过生成性对抗网络进行风格分离和合成
Style Separation and Synthesis via Generative Adversarial Networks通过生成性对抗网络进行风格分离和合成
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.图像风格综合
- 2.2.生成式对抗网络
- 3.提出的方法
-
- 3.1.公式
- 3.2.架构
- 3.3.损失函数
-
- 3.3.1对抗性损失
- 3.3.2内容感知损失
- 3.3.3风格感知损失
- 3.3.4重建损失
- 3.3.5总变化损失
- 3.3.6全目标函数
- 4.实验
-
- 4.1.实验设置
-
- 4.1.1 CelebA数据集
- 4.1.2 UT Zappos 50K数据集
- 4.1.3实施细节
- 4.2.结果和比较
-
- 4.2.1内容和样式表示的可视化
- 4.2.2风格综合的结果
- 4.2.3多样性
- 4.2.4比较
- 4.3.讨论和分析
-
- 4.3.1目标函数的分析
- 4.3.2内容和风格分析
- 5.结论
- 参考文献
论文下载
0.摘要
近年来,风格综合引起了人们极大的兴趣,但很少有作品关注其双重问题“风格分离”。在本文中,我们提出了风格分离和合成生成对抗网络(S3-GAN),以同时实现特定类别的对象照片的风格分离和风格合成。基于目标照片位于流形上,且内容和样式独立的假设,我们使用S3-GAN在流形和潜在向量空间之间建立映射,以分离和合成内容和样式。S3-GAN由编码器网络、生成器网络和对抗网络组成。编码器网络通过将对象照片映射到潜在向量来执行样式分离。潜在向量的两半分别代表内容和风格。生成器网络通过将串联向量作为输入来执行样式合成。级联向量包含样式目标图像的样式半向量和内容目标图像的内容半向量。一旦从生成器网络获得图像,就会使用对抗网络生成更逼真的图像。在CelebA和UT Zappos 50K数据集上的实验表明,S3-GAN具有同时分离和合成风格的能力,并且可以在单个模型中捕获各种风格。
1.概述
风格合成[9],又称风格转移与肌理合成,近年来备受关注。样式合成的目标是从样式目标图像中迁移样式(如颜色、纹理),并维护内容目标图像的内容(如边缘、形状)的新图像。基于卷积神经网络(Convolutional Neural Networks, CNNs)[21,36]的方法[9,18]在风格合成方面取得了显著的成功,并产生了惊人的结果。这些作品大多着眼于艺术作品向摄影的过渡。但是,照片中的所有物体都有自己的风格,也可以迁移到其他照片上。此外,风格综合的成功也说明了一个形象的内容与风格是相互独立的。
因此,如何从给定的图像中学习内容和风格的个体表现形式是风格综合的双重问题。我们将这个问题命名为“风格分离”。目前,已有的作品多集中于风格合成,对风格分离的关注较少。例如,方法[18,38]可以用学习过的前馈网络表示样式,但它们不能同时表示图像内容。
在本工作中,我们的目标是同时实现对象照片的风格分离和风格合成。因此,我们提出了一种新的网络——风格分离与合成生成对抗网络(S3-GAN)。S3-GAN是针对特定类别的物体(如人脸、鞋子等)进行训练的,因为gan可以在特定领域生成逼真的图像。受[9]的启发,我们将对象的结构定义为“内容”(例如人脸的身份和姿势、鞋子的形状),将对象的颜色和纹理定义为“风格”(例如人脸的肤色和头发颜色、鞋子的颜色和图案)。基于目标照片位于高维流形上的假设,S3-GAN采用一对编码器和生成器构建流形与潜向量空间之间的映射,如图1所示。编码器用于样式分离。在编码器阶段,我们将一张给定的照片映射到潜在空间。由于内容和样式是独立的,我们强制潜向量的一半表示样式,另一半表示内容。发电机网络通过将连接的向量作为输入来进行样式综合。连接的向量包含样式目标图像的样式半向量和内容目标图像的内容半向量。由连接向量生成的对象照片具有与样式目标图像相似的风格,同时保留内容目标图像的内容。
本文提出的S3-GAN与现有的风格合成方法存在较大差异[8,9,18,23,38]。其中一些是迭代优化方法[8,9,23],可以生成高质量的图像,但计算成本较高。其他方法采用前馈网络生成接近给定风格目标图像的图像[18,38]。这些方法可以实时生成结果,但一次只能处理一个特定的样式。通过比较,本文提出的S3-GAN算法可以通过一个模型处理多种类型的对象,并通过拼接不同类型的半向量和处理正向传播,高效地合成不同类型的对象。
所提出的S3-GAN来源于gan,但与gan有一些不同。基于高斯的方法在图像生成和编辑方面取得了令人印象深刻的成功[17,19,48]。但是,它们中的大多数都为图像到图像的转换构建两个特定于应用程序的域之间的映射,这可以被视为两种样式之间的转换。与之不同的是,所提出的S3-GAN可以在各种类型之间构建传输。样式的半向量可以作为生成关联样式图像的条件。因此,任何两种不同样式之间的转换都可以通过替换样式半向量来简单地完成。
我们对两个特定类别的物体的照片执行了S3-GAN,分别是来自CelebA数据集[27]和来自UT Zappos50K数据集[42]的鞋子。实验结果表明,该方法能够有效地实现风格的分离与综合。我们工作的主要贡献可归纳如下
- 我们提出了一种用于风格分离和合成的新型S3-GAN框架。在人脸和鞋子的照片上进行的大量实验证明了S3-GAN的有效性。
- S3-GAN执行风格分离与编码器,建立对象照片流形和潜在向量空间之间的映射。对于给定的对象照片,其潜在向量的一半是样式表示,另一半是内容表示。
- S3-GAN用一个发生器进行风格合成。通过将风格目标图像的风格半向量与内容目标图像的内容半向量进行拼接,生成器将拼接后的向量映射回对象照片流形,生成风格合成结果。
2.相关工作
2.1.图像风格综合
风格合成可以看作是纹理合成的一种一般化。以往的纹理合成方法主要是利用低阶图像特征来生长纹理并保持图像结构[6,7,14]。
最近,基于cnn的方法产生了惊人的结果。这些方法利用从CNN特征中测量的感知损失来估计生成的图像与目标图像的风格和内容相似性。[8,9]直接通过迭代过程提出了基于优化的方法来最小化感知损失。[23]通过将神经补丁与马尔可夫随机场(mrf)匹配来扩展这些工作。基于优化的方法计算成本很高,因为合成结果的像素值是通过数百次向后传播逐步优化的。
为了加快风格综合的过程,提出了基于前馈网络的方法[18,24,38]。这些方法学习前馈网络,以最小化特定风格目标图像和任何内容目标图像的感知损失。因此,通过正向传播过程可以得到给定照片的程式化结果,节省了迭代的计算时间。然而,这些方法的一个模型只能表示单一的样式。对于一种新的方式,前馈网络必须重新训练。
直到最近,一些方法试图在一个单一的前馈网络中捕获多个样式,该网络表示具有多个过滤器组[2]、条件实例归一化[5]或二进制选择单元[25]的样式。也有一些方法试图通过学习通用映射[10]、自适应实例规范化[15]或特征转换[26]来在单个模型中表示任意样式。
在本文中,我们提出了S3-GAN来实现风格分离和风格综合。对象照片的内容和样式被表示为潜在向量。S3-GAN不仅可以通过正向传播过程进行风格合成,还可以在单个模型中捕获各种风格
2.2.生成式对抗网络
GAN是生成逼真图像最成功的生成模型之一。标准的GANs[12,32]从最小-最大值两方博弈中学习生成器和鉴别器。生成器从随机噪声中生成可信图像,而鉴别器将生成的图像与真实样本进行区分。原始gan的训练过程不稳定,因此提出了许多改进方法,如WGAN[1]、WGAN- gp[13]、EBGAN[47]、LS-GAN[31]等。
此外,基于条件gan (cgan)[29]的方法已成功应用于许多任务。这些方法在离散标签[29]、文本[33]和图像上条件gan。其中,以图像为条件的cga通过附加编码器实现图像到图像的转换[17],该编码器用于从输入图像中获取条件。这些框架被广泛用于解决许多具有挑战性的任务,如图像补绘[30,40]、超分辨率[22]、年龄进展和回归[46]、风格转移[49]、场景合成[39]、跨模态检索[3,41,43]和人脸属性处理[19,34,48]。此外,领域自适应方法[37,45]利用gan适应传统任务的特征并推进模型,如语义分割。其他一些方法[28,35]利用gan生成任意姿势的人体图像,有利于相关任务,如重新识别人。大多数这些方法都是通过构建两个特定于应用程序的域之间的映射来实现图像到图像的转换
在本文中,我们训练所提出的S3-GAN来表示由目标照片组成的域。这些域可以根据不同的样式划分为许多子域。S3-GAN可以在任意一对子域之间进行映射,实现任意的样式转换
3.提出的方法
在本节中,我们首先阐述潜向量空间,它被引入来解开内容和风格表示。然后我们演示了S3-GAN的流水线,并详细描述了每个组件。最后,我们给出了所有用于优化S3-GAN的个体损失函数。
3.1.公式
我们假设一个特定类别的目标照片位于摄影域中的高维流形M上。具有相同样式或相同内容的对象将被聚集到关联样式或内容的子域
由于在流形M中很难直接建模照片,我们在流形M和一个潜向量空间L∈R2d×k×k之间建立映射,其中d, k∈Z+表示L中向量的维数。考虑到内容和样式是独立的,我们试图将内容和样式的表示分解为潜在向量L∈ M中的不同维度, 它在L中的相关潜在向量是[cI,sI],其中cI∈ Rd×k×k和sI∈ Rd×k×k是分别代表其内容和风格的子向量。我们将内容和风格的子向量设置为等维,以便简化。因此,[·,sI](或[cI,·])可以表示包含所有显示不同内容(或样式)但与I相同样式(或内容)的对象的子域。对于任何样式子向量sˆ,[cI,sˆ]是样式ˆs的子域与子域[cI,·]的交集。因此,[cI,sˆ]可以代表将风格修改为sˆ的结果,同时保留I的内容
3.2.架构

图2:拟议的S3-GAN的体系结构由编码器、生成器、鉴别器和感知网络组成。编码器E通过将目标图像A和B映射到潜在向量[cA,sA]和[cB,sB]来获取样式分离的表示。生成器G从级联向量[cA,sB]生成样式合成的结果C。鉴别器D评估对手的损失,以帮助生成可信的图像。感知网络P用于获得感知损失,包括内容感知损失和风格感知损失。将重建损失和总变异损失添加到目标函数中进行补充(为了简化,图中省略了总变异损失)。
提出的S3-GAN采用GANs框架学习从流形M到潜在向量空间L的映射,并从L生成真实图像。S3-GAN的管道由四个组件组成,包括编码器、生成器、鉴别器和感知网络,如图2所示。在训练和测试阶段都使用编码器和生成器来进行风格分离和风格合成,而仅在训练阶段使用鉴别器和感知网络来优化目标函数。
我们学习编码器E:M→ L来构建从流形M到潜在向量空间L的映射。对于任何内容目标图像A和样式目标图像B,它们在L中对应的潜在向量表示为: .
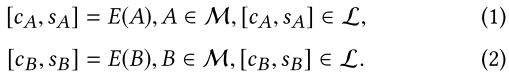
因此,风格分离可以通过E实现。cA(或cB)是内容的表示,sA(或sB)是对象照片A(或B)的风格表示。
相反,我们还学习了生成器G:L→ M构建从潜在向量空间L到流形M的映射:

其中A′(或B′)是具有与A(或B)相同内容和风格的重构。内容和风格目标图像的潜在子向量可以作为生成风格合成结果的条件。因此,生成器G可以通过将来自内容目标a的关联子向量cA和来自样式目标B的sB连接起来来生成合成照片C:
![]()
受GANs框架的启发,我们还引入了鉴别器D来分类图像是真是假(即,由生成器生成)。从训练集中随机抽取的合成结果C和真实照片被输入鉴别器D以获取对抗性损失。在min-max游戏的优化过程中,将生成无法区分的物体照片。
此外,我们还引入了感知网络P来评估和改进风格合成结果。P用于从合成结果C、内容目标A和风格目标B中提取特征,以评估感知损失,包括内容感知损失和风格感知损失。感知损失迫使C获得B的风格,同时保留A的内容。
3.3.损失函数
图2还显示了优化S3GAN的损失。目标函数是五种损失的加权和,包括对抗性损失、内容感知损失、风格感知损失、重建损失和总变异损失。下文将对其进行详细描述。
3.3.1对抗性损失
我们应用鉴别器D来评估对抗性损失LA。原始GAN[12]的对抗性损失是基于Kullback-Leibler(KL)散度。然而,当鉴别器快速训练到其最优性时,KL发散将导致一个常数,并导致消失梯度问题,这将限制生成器的更新。为了解决这个问题,我们利用了最近提出的WGAN[1]的对抗性损失,该WGAN[1]基于地球移动器(EM)距离。
我们将训练数据(即特定类别的对象照片)在流形M中的分布表示为pM。pM的随机抽样过程表示为I∼pM。因此,对抗性的损失是
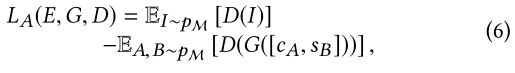
式中,G([cA,sB])是风格综合的生成结果,由式(1)、式(2)和式(5)表示。最小-最大目标函数用于优化对抗损失:
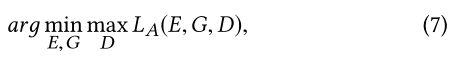
其中,E,G尝试最小化LA,以便生成看起来与训练集中的图像不可区分的图像G([cA,sB]),而D尝试最大化LA,以便对生成的图像G([cA,sB])和真实样本I进行分类。
对抗性损失确保生成的图像驻留在流形M中,并迫使它们与真实图像无法区分。因此,我们利用这个损失函数来生成真实的图像。模糊的图像看起来显然是假的,所以它们将被敌对的损失所阻止。
3.3.2内容感知损失
生成的图像C旨在在风格上与风格目标B相似,并保留内容目标A的内容。由于训练集中没有提供风格合成的基本事实,我们使用感知网络P,并利用特征表示来惩罚生成图像和目标图像之间的差异,通过结合风格综合的先验知识[9,18]。
生成的结果预计将与目标图像的特征响应相匹配。设Pl(I)为从感知网络P的层l和输入图像I中提取的特征映射∈ M.内容感知损失LC定义为特征响应之间的平方欧氏距离:

其中FC是用于评估内容感知损失的层。
考虑到神经网络的设计,高层捕捉语义级别的信息,包括形状和空间结构,但忽略低级信息,如颜色和纹理。因此,我们在P的更高层上计算LC(E,G),以便生成的图像C将保留内容目标A的内容。
3.3.3风格感知损失
假设输入I的l层的特征映射Pl(I)的形状为Cl×Hl×Wl。风格感知损失LS由Gram矩阵的Frobenius距离平方计算得出,表示为:

式中,FS是应用于样式感知损失的层。Gram矩阵ψl(I)是一个Cl×Cl矩阵,其灵感来源于特征映射Pl(I)沿通道维度的非中心协方差。其(c,c′)处的元素表示为:
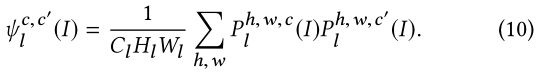
Gram矩阵侧重于从不同通道一起激活的特征,忽略了图像的空间信息。因此,基于Gram矩阵的风格感知损失LS(E,G)保持了风格目标B的风格,忽略了内容。与内容感知损失不同,LS(E,G)是在P的较低层上计算的,以关注低级信息,包括与风格相关的颜色和纹理。
3.3.4重建损失
我们还可以得到A和B的重构,如公式(3)和公式(4)所示。将从原始图像和重建图像计算出的重建损失LR添加到目标函数中进行补充,表示为:
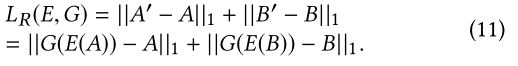
我们在LR中应用L1距离而不是L2,因为L1会减少模糊。
重构损耗确保编码器E和生成器G是彼此的一对逆映射。考虑到训练集中没有给出风格合成的基本事实,重构的实现还可以提供类似的基本事实输出,从而加快训练过程,提高逼真效果。此外,尽管重建损失可能过于平滑,导致图像模糊,但通过适当的减重和限制对抗性损失,可以避免严重的结果。
3.3.5总变化损失
另一个辅助损失函数是总变异损失LTV,它可以鼓励生成结果的空间平滑性,并减少尖峰伪影。它对合成产物和重建结果执行全变差正则化,公式如下:

3.3.6全目标函数
完整目标函数LO是上述所有损失的加权和,表示为:

其中λ1、λ2、λ3、λ4、λ5是控制目标函数中相对重要性的损失权重。优化过程旨在解决最小-最大问题:

4.实验
在本节中,我们对两个特定类别的物体照片进行实验,包括CelebA数据集[27]中的人脸和UT Zappo50k数据集[42]中的鞋子。
4.1.实验设置
4.1.1 CelebA数据集
CelebA数据集由超过20万张名人图片组成,共有10万个身份。我们在CelebA数据集中裁剪对齐人脸图像的128×128中心部分进行预处理。随机选取2K幅图像进行测试,其余图像作为训练样本。内容和风格目标图像对是随机选择的,而CelebA数据集中标注的40个人脸属性和5个关键点没有被利用。
4.1.2 UT Zappos 50K数据集
UT Zappos 50k数据集从在线购物网站Zappos收集。通用域名格式。该数据集包含50K个目录鞋图像,这些图像以相同方向拍摄,背景为空白。图像被缩放到128×128,然后被送入网络。我们将这些图像随机分成两部分,一部分包含2K图像用于测试,另一部分包含48K图像用于训练。我们还随机选择内容和风格目标图像对,忽略图像的元数据(例如鞋型、材质、性别等)。
4.1.3实施细节

编码器E、发生器G和鉴别器D的详细结构如表1所示。E和D使用“卷积、批量归一化、泄漏ReLU”模块,而G使用“反卷积、批量归一化、ReLU”模块。在卷积层和反卷积层中都使用2的步长对特征图进行下采样或上采样。特别地,G的输出层利用Tanh作为激活函数而不是ReLU。此外,在生成器输出层和鉴别器输入层中删除了批量归一化[16],因为直接对所有层应用批量归一化可能会导致采样振荡和模型不稳定。图像在输入到E或D之前被标准化为[0,1],G的输出被重新缩放为[0255]。对于给定的图像I,E(I)的输出1024×4×4潜在向量沿通道维度被分割为cI和sI,即,两个512×4×4向量的一半分别是内容和样式表示。
在培训过程中,采用了Adam优化器[20],该优化器具有16个样本的小批量。我们使用在ImageNet数据集[4]上预先训练的VGG-19网络[36]作为感知网络P。编码器E、生成器G和鉴别器D的权重由具有适当偏差的零中心高斯分布初始化[11]。30个时代的学习率固定在0.001。损失权重设置为λ1=1,λ2=10−6, λ3 = 5 × 10−5, λ4 = 30, λ5 = 1. 从实验中获得并选择了权损失的绝对值。感知损失的直接损失值远大于其他损失,因此我们将感知损失的损失权重设置为小于其他损失,以使加权损失的数量级相同。我们计算了relu4_2层的内容感知损失,以及relu1_1、relu2_1和relu3_1层的风格感知损失。我们通过在D上交替使用一个梯度下降步骤和在E和G上交替使用两个步骤来执行GANs的替代训练方法。我们的实验是在Tensorflow平台上实现的。我们所有的网络都在一个英伟达特斯拉K40 GPU上接受培训和测试。
4.2.结果和比较
4.2.1内容和样式表示的可视化
S3-GAN的编码器可以通过将图像编码为潜在向量来执行风格分离,其中一半代表风格,另一半代表内容。为了证明S3-GAN具有风格分离的能力,我们将编码器E生成的内容和风格表示可视化。为了可视化,我们保留内容或风格的一半向量,并简单地用零填充另一半向量。然后我们将新向量输入生成器G,并获得内容或样式的可视化。如图3和图4所示,内容表示的可视化保留了结构信息,但放弃了颜色信息,而样式表示保留了颜色信息,但忽略了结构信息。例如,内容表示法保留了图3中原始人脸的身份和姿势,以及图4中原始鞋子的形状和结构。相比之下,样式表示在图3中显示了样式目标面的肤色和头发颜色,在图4中显示了样式目标鞋的颜色和纹理。这些内容和样式表示对合成新图像非常有用。上述实验表明,内容和风格表示是互补的,可以从学习的编码器中捕获。

图3:CelebA数据集人脸图像上内容和样式表示的可视化。从上到下依次为:原始图像、内容表示和样式表示。

图4:UT Zappo50K数据集鞋子图像上内容和样式表示的可视化。从上到下依次为:原始图像、内容表示和样式表示。
4.2.2风格综合的结果
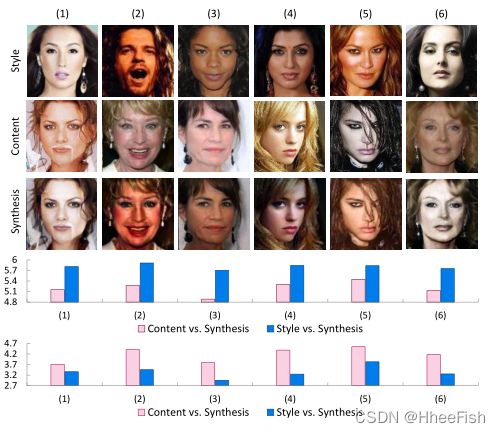
图5:CelebA数据集上的样式合成说明。自上而下:样式目标图像、内容目标图像、合成结果、内容距离和样式距离的对数。对于第四行和第五行,粉色条表示内容目标图像和合成结果之间的距离,而蓝色条表示样式目标图像和合成结果之间的距离。

图6:UT Zappo50K数据集上的样式合成说明。自上而下:样式目标图像、内容目标图像、合成结果、内容距离和样式距离的对数。对于第四行和第五行,粉色条表示内容目标图像和合成结果之间的距离,而蓝色条表示样式目标图像和合成结果之间的距离。
S3-GAN的生成器可以通过连接内容和风格半向量,从向量生成风格合成。CelebA和UT Zappo50K数据集合成结果的定性和定量评估如图5和图6所示。从这两幅图的前三行可以看出,合成图像代表了风格目标图像的明显风格,并保留了内容目标图像的内容。例如,图5第三行中的合成面表示样式目标面的肤色和头发颜色,同时保留内容目标面的身份、姿势和表情。类似地,图6第三行中的合成鞋显示了样式目标鞋的颜色以及内容目标鞋的结构和形状。此外,对于目标图像和合成图像,内容/样式感知距离(在等式(8)和等式(9)中)越低,内容/样式就越相似。如图5和图6第四行所示,合成图像与内容目标图像的内容感知距离低于样式目标图像。从图5和图6的第五行,我们可以观察到合成图像与风格目标图像的风格感知距离低于内容目标图像。我们得出结论,S3-GAN可以使风格合成具有以下两个优点:1)对于内容目标图像,它只捕获内容而放弃风格信息。2) 对于样式目标图像,它会保持样式,并忽略内容信息。
4.2.3多样性

图7:不同风格的风格合成示意图。第一行显示不同样式的目标图像,第二行显示内容目标图像和样式合成结果。

图8:不同内容的风格综合说明。第一行显示不同的内容目标图像,第二行显示样式目标图像和样式合成结果。
此外,我们从以下两个方面分析了S3GAN的多样性:1)在同一内容图像上应用不同风格的目标图像来生成合成图像。如图7所示,生成的图像与原始内容目标图像保持相似的结构,并根据不同风格的目标图像显示不同的颜色和纹理。2) 我们使用相同风格的目标图像和不同内容的目标图像来合成图像。如图8所示,生成的图像的颜色和纹理与样式目标图像相同,具有不同的形状和结构。以上结果显示了所提出的S3-GAN的多样性。换句话说,S3-GAN可以在一个模型中捕获各种样式和内容。
4.2.4比较

与四种流行风格合成方法[9]、[18]、[26]和[15]的比较结果。

表2:S3-GAN与四种流行风格合成方法[9]、[18]、[26]和[15]的置信度比较。信心:人脸检测的平均信心分数。内容:内容感知距离的平均对数。风格:风格感知距离的平均对数。
我们将所提出的方法与其他四种流行的风格综合方法[9]、[18]、[26]和[15]进行了比较。如图9所示,S3-GAN生成的图像在视觉上更逼真,因为它们包含可分辨的细节。相比之下,现有的四种方法生成的图像模糊且失真,并且丢失了目标图像内容的许多细节。受[39]和[26]的启发,我们还进行了定量实验。我们随机选择10幅图像作为风格目标图像,另外100幅图像作为内容目标图像。然后使用这五种方法生成1000幅合成图像。为了测量生成图像的真实感,我们使用流行的MTCNN[44]对生成的图像执行人脸检测。生成的图像越逼真,可信度越高。因此,我们使用人脸检测的置信度得分,即softmax概率来表示生成图像的质量。如表2所示,该方法的置信度高于四种方法,这意味着该方法生成的图像更真实。此外,我们使用等式(8)和等式(9)中内容/风格感知距离的平均对数来衡量合成结果和内容/风格目标图像的相似性。如表2所示,内容感知距离的平均对数低于四种比较方法的平均对数。同时,风格知觉距离的平均对数低于三种比较方法[18]、[26]和[15]。请注意,我们的方法的风格感知距离的平均对数略高于[9],因为它们[9]只关注传递风格信息。上述比较表明,所提出的方法生成的图像能够很好地代表目标图像的内容和风格。
4.3.讨论和分析
4.3.1目标函数的分析
在这项工作中,目标函数(等式(14))由几个损失函数组成,例如内容感知损失LC、风格感知损失LS、重建损失LR和对手损失LA。因此,我们分析了每个损失函数对图像的影响,相关结果如图10所示。从图10中,我们可以观察到,使用感知损失LP(LP=LC+LS)生成的图像模糊且失真,并且缺少许多重要细节。原因是,感知损失是一个全局约束,并且捕捉微妙信息的能力有限。通过将重建损失LR添加到感知损失LP,生成的图像仍然模糊,但更合理。另外,结合敌方损失LA和感知损失LP生成的图像更清晰、逼真,但与内容目标图像相比,丢失了许多重要的细节信息。例如,生成的图像和内容目标图像之间眼睛、眉毛和嘴巴的细微差异可能会改变原始人脸的身份。由于重建损失LR可以确保编码器和生成器是一对逆映射,因此它可以补偿对手损失LA导致的错误细节。因此,重建损失是对手损失的补充。如图10所示,融合重建损失LR、对手损失A和感知损失LP可以解决上述问题,并且生成的图像可以具有更清晰和校正的细节。

图10:不同目标函数的影响。LP=LC+LS是式(8)中内容感知损失和式(9)中风格感知损失的总和。LR是式(11)中的重建损失。LA是等式(6)中的对手损失。
4.3.2内容和风格分析
通过说明内容和风格插值的结果,我们分析了对象照片的流形M假设,如图11所示。左下角和右上角的图像是两个目标面的重建,而右下角和左上角的图像是交换内容和样式的合成结果。水平(或垂直)轴表示样式(或内容)的遍历,即每行(或列)中的图像是具有固定内容(或样式)的样式(或内容)插值结果。这些结果表明,流形M中的内容和风格与图像无关。此外,学习的编码器E和生成器G可以在流形M和潜在空间L之间建立映射,并成功地获得内容和风格的表示。

图11:学习到的人脸流形M的图示,以及内容和风格插值的分析。横轴表示样式的遍历,纵轴表示内容的遍历。
5.结论
在本文中,我们提出了S3-GAN来同时实现风格分离和风格合成。我们假设一个特定类别的物体照片位于一个流形上,并且一个物体的内容和风格是独立的。我们学习了一个编码器来构建从流形到潜在空间的映射,其中对象的内容和样式可以分别用其关联的潜在向量的两半来表示。因此,样式分离可以由编码器执行。我们还学习了一个用于逆映射的生成器,以便通过连接样式目标图像的样式半向量和内容目标图像的内容半向量来生成样式合成的结果。在CelebA和UT Zappos 50K数据集上的实验都证明了所提出的S3-GAN的令人满意的结果。
参考文献
[1] Martín Arjovsky, Soumith Chintala, and Léon Bottou. 2017. Wasserstein GAN. arXiv preprint arXiv:1701.07875 (2017).
[2] Dongdong Chen, Lu Yuan, Jing Liao, Nenghai Yu, and Gang Hua. 2017. StyleBank: An Explicit Representation for Neural Image Style Transfer. In IEEE Conference on Computer Vision and Pattern Recognition.
[3] Jingze Chi and Yuxin Peng. 2018. Dual Adversarial Networks for Zero-shot Cross-media Retrieval. In International Joint Conference on Artificial Intelligence.
[4] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Fei-Fei Li. 2009. ImageNet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition.
[5] Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur. 2016. A Learned Representation For Artistic Style. In International Conference on Learning Representations.
[6] Alexei A. Efros and William T. Freeman. 2001. Image quilting for texture synthesis and transfer. In Conference on Computer Graphics and Interactive Techniques, SIGGRAPH.
[7] Alexei A. Efros and Thomas K. Leung. 1999. Texture Synthesis by Non-parametric Sampling. In IEEE International Conference on Computer Vision.
[8] Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. 2015. Texture Synthesis Using Convolutional Neural Networks. In Advances in Neural Information Processing Systems.
[9] Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. 2016. Image Style Transfer Using Convolutional Neural Networks. In IEEE Conference on Computer Vision and Pattern Recognition.
[10] Golnaz Ghiasi, Honglak Lee, Manjunath Kudlur, Vincent Dumoulin, and Jonathon Shlens. 2017. Exploring the structure of a real-time, arbitrary neural artistic stylization network. In British Machine Vision Conference.
[11] Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. In International Conference on Artificial Intelligence and Statistics (AISTATS).
[12] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David WardeFarley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. In Advances in Neural Information Processing Systems.
[13] Ishaan Gulrajani, Faruk Ahmed, Martín Arjovsky, Vincent Dumoulin, and Aaron C. Courville. 2017. Improved Training of Wasserstein GANs. In Advances in Neural Information Processing Systems.
[14] Aaron Hertzmann, Charles E. Jacobs, Nuria Oliver, Brian Curless, and David Salesin. 2001. Image analogies. In Conference on Computer Graphics and Interactive Techniques, SIGGRAPH.
[15] Xun Huang and Serge J. Belongie. 2017. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In IEEE International Conference on Computer Vision.
[16] Sergey Ioffe and Christian Szegedy. 2015. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Internal Conference on Meachine Learning.
[17] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. 2017. Image-toImage Translation with Conditional Adversarial Networks. In IEEE Conference on Computer Vision and Pattern Recognition.
[18] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual Losses for RealTime Style Transfer and Super-Resolution. In European Conference on Computer Vision.
[19] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee, and Jiwon Kim. 2017. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. In Internal Conference on Meachine Learning.
[20] Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. International Conference on Learning Representations.
[21] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. 2012. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems.
[22] Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew P. Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. 2017. PhotoRealistic Single Image Super-Resolution Using a Generative Adversarial Network. In IEEE Conference on Computer Vision and Pattern Recognition.
[23] Chuan Li and Michael Wand. 2016. Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis. In IEEE Conference on Computer Vision and Pattern Recognition.
[24] Chuan Li and Michael Wand. 2016. Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks. In European Conference on Computer Vision.
[25] Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang. 2017. Diversified Texture Synthesis with Feed-Forward Networks. In IEEE Conference on Computer Vision and Pattern Recognition.
[26] Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang. 2017. Universal Style Transfer via Feature Transforms. In Advances in Neural Information Processing Systems.
[27] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2015. Deep Learning Face Attributes in the Wild. In IEEE International Conference on Computer Vision.
[28] Liqian Ma, Xu Jia, Qianru Sun, Bernt Schiele, Tinne Tuytelaars, and Luc Van Gool. 2017. Pose Guided Person Image Generation. In Advances in Neural Information Processing Systems.
[29] Mehdi Mirza and Simon Osindero. 2014. Conditional Generative Adversarial Nets. arXiv preprint arXiv:1411.1784 (2014).
[30] Deepak Pathak, Philipp Krähenbühl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros. 2016. Context Encoders: Feature Learning by Inpainting. In IEEE Conference on Computer Vision and Pattern Recognition.
[31] Guo-Jun Qi. 2017. Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities. arXiv preprint arXiv:1701.06264 (2017).
[32] Alec Radford, Luke Metz, and Soumith Chintala. 2016. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In International Conference on Learning Representations.
[33] Scott E. Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. 2016. Generative Adversarial Text to Image Synthesis. In Internal Conference on Meachine Learning.
[34] Wei Shen and Rujie Liu. 2017. Learning Residual Images for Face Attribute Manipulation. In IEEE Conference on Computer Vision and Pattern Recognition.
[35] Aliaksandr Siarohin, Enver Sangineto, Stéphane Lathuilière, and Nicu Sebe. 2018. Deformable GANs for Pose-based Human Image Generation. arXiv preprint arXiv:1801.00055 (2018).
[36] Karen Simonyan and Andrew Zisserman. 2014. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv preprint arXiv:1409.1556 (2014).
[37] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker. 2018. Learning to Adapt Structured Output Space for Semantic Segmentation. In IEEE Conference on Computer Vision and Pattern Recognition.
[38] Dmitry Ulyanov, Vadim Lebedev, Andrea Vedaldi, and Victor S. Lempitsky. 2016. Texture Networks: Feed-forward Synthesis of Textures and Stylized Images. In Internal Conference on Meachine Learning.
[39] Xiaolong Wang and Abhinav Gupta. 2016. Generative Image Modeling Using Style and Structure Adversarial Networks. In European Conference on Computer Vision.
[40] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li. 2017. High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis. In IEEE Conference on Computer Vision and Pattern Recognition.
[41] Hantao Yao, Shiliang Zhang, Yongdong Zhang, Jintao Li, and Qi Tian. 2017. One-Shot Fine-Grained Instance Retrieval. In ACM Multimedia Conference.
[42] Aron Yu and Kristen Grauman. 2014. Fine-Grained Visual Comparisons with Local Learning. In IEEE Conference on Computer Vision and Pattern Recognition.
[43] Jian Zhang, Yuxin Peng, and Mingkuan Yuan. 2018. Unsupervised Generative Adversarial Cross-Modal Hashing. In The Thirty-Second AAAI Conference on Artificial Intelligence.
[44] Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, and Yu Qiao. 2016. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. (2016).
[45] Yiheng Zhang, Zhaofan Qiu, Ting Yao, Dong Liu, and Tao Mei. 2018. Fully Convolutional Adaptation Networks for Semantic Segmentation. (2018).
[46] Zhifei Zhang, Yang Song, and Hairong Qi. 2017. Age Progression/Regression by Conditional Adversarial Autoencoder. In IEEE Conference on Computer Vision and Pattern Recognition.
[47] Junbo Jake Zhao, Michaël Mathieu, and Yann LeCun. 2016. Energy-based Generative Adversarial Network. arXiv preprint arXiv:1609.03126 (2016).
[48] Shuchang Zhou, Taihong Xiao, Yi Yang, Dieqiao Feng, Qinyao He, and Weiran He. 2017. GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data. arXiv preprint arXiv:1705.04932 (2017).
[49] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. 2017. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In IEEE International Conference on Computer Vision.