图像风格化——感知损失(perceptual loss)(2016)
[paper]Perceptual Losses for Real-Time Style Transfer and Super-Resolution(2016)
Perceptual Losses for Real-Time Style Transfer and Super-Resolution:Supplementary Material
图像风格化
风格迁移简单的理解为,将一张图像在保存原图大致的纹理结构的同时,具有别的图像的风格。即对图像加了一个风格滤镜。



图像风格化(Neural Style Transfer)是将一张照片渲染成有艺术风格的画作。图像风格化算法的输入有二,分别是内容图和风格图,输出有一个,为风格迁移后的结果图。
图像风格化算法是一个图像渲染的过程。在图形学的非真实感图形学领域,图像艺术风格技术可以大体分为:
- 基于笔触渲染的方法(Stroke-based Rendering)
基于笔触渲染的方法,在算法设计之前首先会确定某一种风格,即每一个基于笔触渲染的方法一般只对应于一种风格,而不能简单的扩展到其他风格的迁移。 - 基于图像类比的方法(Image Analogy)
图像类比方法需要很多成对的原图和风格结果图作为训练集,然后对所有风格图像找到这些成对的数据貌似不太现实。 - 基于图像滤波的方法(Image Filtering)
通过图像滤波的方法速度快、效果稳定,可满足工业界落地的需求,但是基于图像滤波方法能模拟出来的风格种类很有限。
在基于统计学的计算机视觉领域,图像艺术风格渲染一般被认为是纹理合成的一个扩展问题。纹理合成是给定一个源纹理图,然后取合成更多类似的纹理结构,最终组成一个大的纹理图。风格迁移中的风格图可以看成是一种纹理,由此,假如我们在合成纹理图的时候去刻意保留一些语义信息,就是风格迁移。
纹理建模方法(Visual Texture Modelling),主要研究如何表示一种纹理,是纹理合成技术的核心。纹理合成方法可以分为两大类:
- 基于统计分布的参数化纹理建模方法(Parametric Texture Modelling with Summary Statistics)
基于统计分布的参数化方法主要将纹理建模为N阶统计量 - 基于MRF的非参数化纹理建模方法(Non-parametric Texture Modelling with MRFs)
基于MRF的方法是用patch相似度匹配进行逐点合成。
纹理建模方法解决了对风格图中的风格特征进行建模和提取。把风格图像中的风格提取之后,和内容混合还原成一个相应的风格化需要图像重建(Image Reconstruction)。
图像重建解决如何将给定的特征表达重建还原为一张图像。图像重建的输入是特征表达,输出是特征表达对应的图像。与通常的输入图像提取特征的过程相反,是把某个特征逆向重建为原来的图像,重建结果不唯一。图像重建算法分为:
- 基于在线图像优化的慢速图像重建方法(Slow Image Reconstruction based on Online Image Optimisation)
在图像像素空间做梯度下降来最小化目标函数。由随机噪声作为起始图,然后不断迭代改变图片的所有像素值来寻找一个目标结果图 x ′ x' x′,这个目标结果图的特征表达和作为重建目标的目标特征表达 Φ ( x ) \Phi(x) Φ(x)相似,即像素迭代的目标为 Φ ( x ′ ) ≈ Φ ( x ) \Phi(x') \approx \Phi(x) Φ(x′)≈Φ(x)。由于每个重建结果都需要在像素空间进行迭代优化很多次,这种方式是很耗时的(几百乘几百的图需要几分钟),尤其是当需要的重建结果是高清图的时候,占用的计算资源以及需要的时间开销很大。 - 基于离线模型优化的快速图像重建方法(Fast Image Reconstruction based on Offline Model Optimisation)
设计一个前向网络,用数据驱动的方式,喂给它很多训练数据去提前训练它,训练的目的是给定一个特征表达作为输入,这个训练好的网络只需要一次前向就能输出一张重建结果图像。如果再融入生成对抗网络的思想,会进一步提升效果。
以前的图像重建主要是用来理解某些特征表达的,图像重建提供了一个可以加深特征理解的途径。假如说给定一张猴子的某个图像分类特征,重建出来的不同结果中猴子的五官位置均正确保留,而其他的比如颜色等不同结果不太一样,那么可以理解成次分类网络在分类猴子这个类别的图像的时候,会参考五官的位置来与其它类别进行区分。
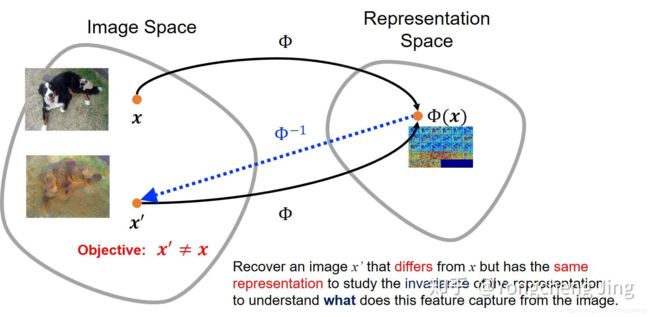
通过重建预训练的分类网络中的高层特征,发现重建结果保留了高层语义信息,而摒弃了低层的颜色等信息。加入在图像重建时加上保留给定风格信息的约束,就可以让重建出的结果既有想要的内容图的高层语义信息,又有给定风格图像中包含的风格信息。图像风格化迁移由此诞生。
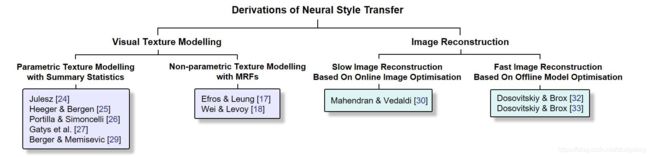
按照图像风格化迁移算法=图像重建算法+纹理建模算法,图像风格化可以分为基于在线优化的慢速图像风格迁移算法(Slow Neural Method Based On Online Image Optimisation)和基于离线模型优化的快速图像风格化迁移算法(Fast Neural Method Based On Offline Model Optimisation)的方法。
基于在线优化的慢速图像风格迁移算法(Slow Neural Method Based On Online Image Optimisation)
- 基于统计分布的参数化慢速风格化迁移算法(Parametric Slow Neural Method with Summary Statistics)
- 基于CNN的纹理建模方法(Texture Synthesis Using Convolutional Neural Networks)是在图像经过预训练的VGG网络时的特征表达(feature map)上计算Gram矩阵,利用得到的Gram矩阵来表示一种纹理。Gram矩阵的计算方式是先将预训练VGG某一层的特征表达 F l ( I ) F^l(I) Fl(I)由 R C × H × W R^{C \times H \times W} RC×H×Wreshape成 R C × ( H W ) R^{C \times (HW)} RC×(HW),然后用reshape后的特征表达和其转置矩阵相乘 [ F l ( I ) ] × [ F l ( I ) ] T [F^l(I)] \times [F^l(I)]^T [Fl(I)]×[Fl(I)]T,最后得到的Gram矩阵维度为 R C × C R^{C \times C} RC×C。这个Gram矩阵可以很好的表示大多数纹理。这个Gram矩阵的纹理表示方法其实是利用了二阶统计量来对纹理进行建模。用Gram矩阵来对图像中的风格进行建模和提取,再利用慢速图像重建方法,让重建后的图像以梯度下降的方式更新像素值,使其Gram矩阵接近风格图的Gram矩阵(即风格相似),然后其VGG网络的高层特征表达接近内容图的特征表达(即内容相似),实际应用时会再加个总分TV项来对结果进行平滑,最终重建出来的结果图就既拥有风格图的风格,又有内容图的内容了。
- Demystifying Neural Style Transfer从Domain Adaption的角度度风格化迁移进行解释和分析,Domain Adaption指的是当训练数据和测试数据属于不同的域时,通过某种手段利用源域有标签的训练数据训练得到的模型,去预测无标签的测试数据所在的目标域中的数据。Domain Adaption以最小化统计分布差异度量MMD,让目标域中的数据和源域中的数据建立起一种映射转换关系。最小化重建结果图和风格图的Gram统计量差异其实等价于最小化两个域统计分布之间的基于二阶核函数的MMD。即风格迁移的过程其实可以看做是让目标风格化结果图的特征表达二阶统计分布去尽可能的逼近风格图的特征表达二阶统计分布。既然是衡量统计分布差异,除了有二阶核函数的MMD外,其他的MMD核函数例如一阶线性核函数、高阶核函数、高斯核函数,也可能达到和Gram统计量类似的效果。这些计算风格特征的方式其实都是在特征表达(feature map)的所有channel上进行计算的。
- 用channel-wise的BN统计量取对风格进行建模的方法,利用VGG某些层的特征表达 F c l ∈ R H × W F^l_c \in R^{H \times W} Fcl∈RH×W的每一个channel的均值和方差(channel-wise)来表示风格。( F c l ∈ R H × W F^l_c \in R^{H \times W} Fcl∈RH×W表示VGG中第 l l l层的feature map的第 c c c个channel)。
- Laplacian-Steered Neural Style Transfer,提出在风格化迁移的过程中同时考虑像素空间和特征空间。因为之前的风格化算法在提取特征的时候都是在高层的CNN特征空间(feature map)中完成的,虽然这样做的效果在感知效果上(perceptually)优于利用传统的在像素空间(pixel space)计算的特征,但由于特征空间是对图像的一种抽象表达,会不可避免丢失一些低层次的如边缘等的图形信息,这会导致风格化结果图中有一些变形等。具体做法为在像素空间中将内容图的拉普拉斯算子的滤波结果和风格化重建结果之间的差异作为一个新的Loss,加到基于CNN的纹理建模方法(Texture Synthesis Using Convolutional Neural Networks)提出的损失函数上面,这样就弥补了抽象特征空间丢失低层次图像信息的缺点。
- 基于MRF的非参数化慢速风格化迁移算法(Non-parametric Slow Neural Method with MRFs)
- Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis提出了一个取代Gram损失的新的MRF损失。思路与传统的MRF非参数化纹理建模方法相似,即先将风格图和重建风格化结果图分成若干patch,然后对于每个重建结果图中的patch,去寻找并逼近与其最接近的风格patch。与传统MRF建模方法不同之处在于以上操作是在CNN特征空间中完成的。还需要加一个基于CNN的纹理建模方法(Texture Synthesis Using Convolutional Neural Networks)提出的内容损失来保证不丢失内容图中的高层语义信息。这种基于patch的风格建模方法相比较以往基于统计分布的方法的一个明显优势在于,当风格图不是一幅艺术画作,而是和内容图内容相近的一张摄影照片(Photorealistic Style),这种基于patch匹配(patch matching)的方式可以很好地保留图像中的局部结构等信息。
基于离线模型优化的快速图像风格化迁移算法(Fast Neural Method Based On Offline Model Optimisation)
基预先训练前向网络来解决计算量大、速度慢的问题。根据一个训练好的前向网络能够学习到多少个风格作为分类依据,我们将快速图像风格化迁移算法分为单模型单风格 (PSPM)、单模型多风格 (MSPM) 和 单模型任意风格 (ASPM) 的快速风格化迁移算法。
- 单模型单风格的快速风格化迁移算法(Per-Style-Per-Model Fast Neural Method)
主要想法是针对每一个风格图,我们去训练一个特定(style specific)的前向模型,这样当测试的时候,我们只需要向前向模型扔进去一张内容图,就可以前向出一个风格化结果了。 - 单模型多风格的快速风格化迁移算法(Multiple-Style-Per-Model Fast Neural Method)
发掘出不同风格网络之间共享的部分,然后对于新的风格只去改变其有差别的部分,共享的部分保持不变。 - 单模型任意风格的快速风格化迁移算法(Arbitrary-Style-Per-Model Fast Neural Method)
给定一个新风格不需要训练,我们就可以很快速地把风格化结果输出来。
按照运行速度,又有以下分类:
-
原始的 Optimization-based method
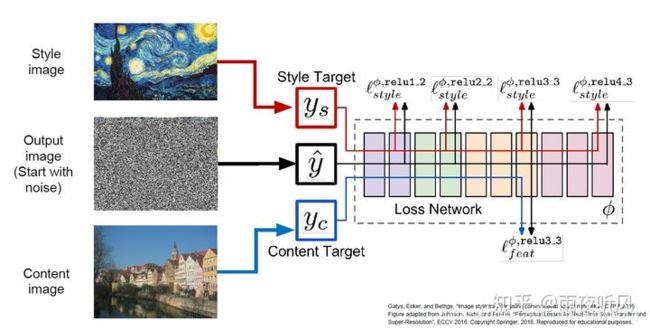
简单来说便是输入一张随机噪音构成的底图,通过计算Style Loss和Content Loss,迭代update底图,使其风格纹理上与Style Image相似,内容上与原照片相似。正常的训练过程是通过loss反向传播更新网络参数,这里则是用一个已经训练好的VGG16作为backbone,锁住参数,更新输入的底图。 -
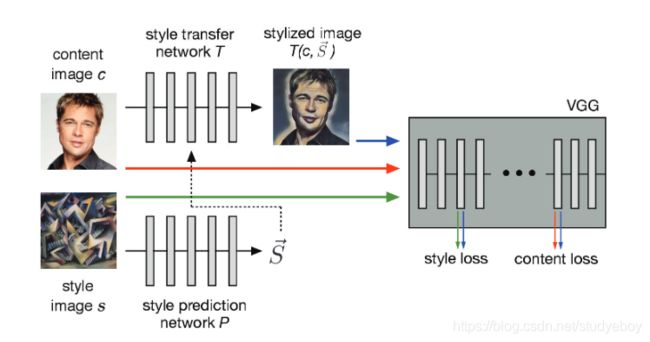
一次成型的Feedforward-based method
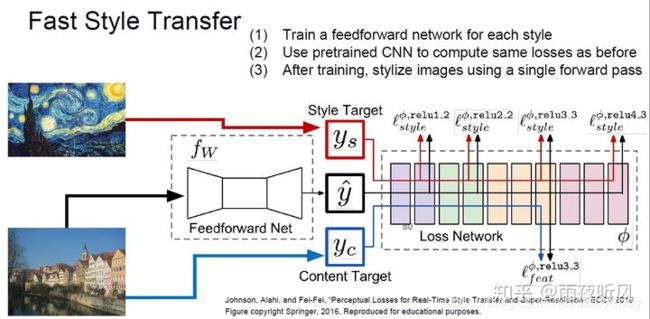
增加了一个Autoencoder形状的Feedforward Net 来拟合风格迁移的过程。仍然是之前的Content Loss+Style loss,用另一个网络来计算并统一在一起称之为 Perceptual Loss。 -
One network, multiple styles
微软亚研这篇的模型由三部分组成,Encoder E, StyleBank Layer K, Decoder D. 作者希望将content和style的生成分离,即 E+D负责重建Content, 不同的K 则控制不同style的风格,每个模型可以有多达50个不同的K。
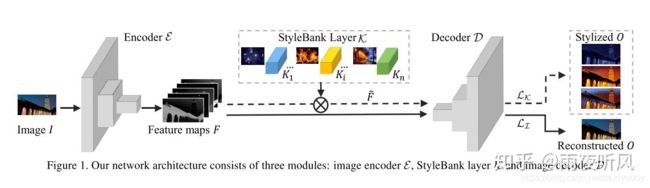
-
Arbitrary style in one model
做到Multi-style single model后又开始想怎么设计一个universal model,丢进去什么新的style都可以实时进行transfer,而无需重新训练。
作者argue到不同的style其实由feature的variance和mean决定,因此通过将Content image的feature 转换,使其与style image的feature有相同的variance和mean即可实现style transfer
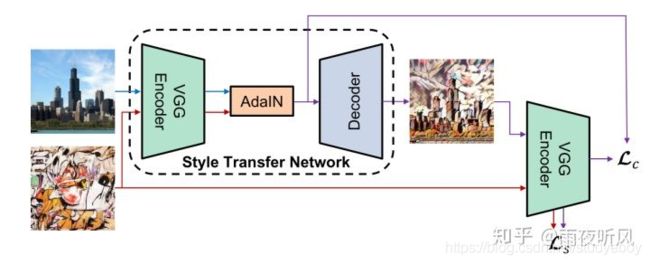
《Image Style Transfer Using Convolutional Neural Networks》
[paper] Image Style Transfer Using Convolutional Neural Networks


风格迁移任务,可以概括为把一张图像的纹理信息加到一张图像上,而保持该图像的语义内容不变。变换的难点在于如何明确的表征图像的语义信息,从而允许把图像的content与style二者分割开来。
风格迁移有时候可以认为是纹理迁移,而纹理迁移的目的是在目标图像上合成源图像中存在的纹理,同时保持目标图像的语义信息。该领域存在很多非参数的方法,通过采样源图像的纹理像素来实现。但是非参数的采样方法只利用了图像的低层特征,这造成了该类方法的局限。理想状态,风格迁移算法应该能够抽取图像的语义内容,再进行纹理合成。那么首要的任务就是如何独立的为图像的语义内容和纹理风格建模。
使用了经典的VGG19网络来提取图像的高层语义特征,它具有16个卷积层和5个池化层,未使用任何的全连接层。还对VGG的参数进行了不改变其输出的正则化,并且发现平均池化相比最大池化取得了稍微更好的结果。
在该风格迁移的过程中有三个框架和三张输入图片。a是风格图,p是内容图,x是随机生成的噪声图。该过程的总体思想是通过对噪声图像进行约束,使其不断的同时趋近于内容图也趋近于风格图。内容损失 L c o n t e n t L_{content} Lcontent是由内容图和随机噪声图经过卷积滤波后,在第四层分别的feature map的距离的平方和。风格损失 L s t y l e L_{style} Lstyle先对风格图和噪声图的每一层滤波feature map分别求gram矩阵,再求其距离的平方和,再将5层的结果加权求和,获得风格损失。最后将两种损失加权求和求得总的损失 L t o t a l L_{total} Ltotal,即产生对x噪声图的约束。利用反向传播算法,迭代更新权重和偏置参数,从而更新输入图像。
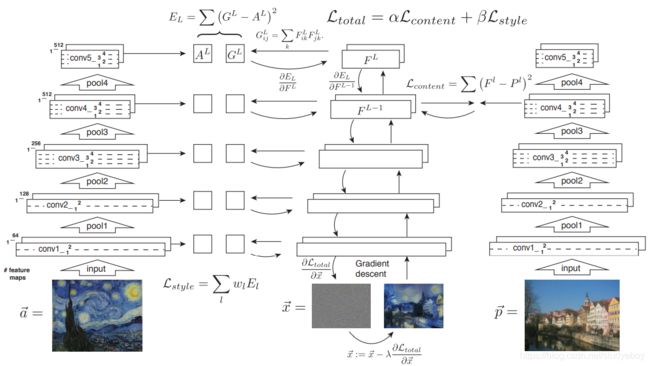


-
内容表示和内容损失
内容表示本质上就是图像输入到神经网络后,某一卷积层的输出特征图。当然采取不同的卷积层输出的特征图不一致,得到的内容表示也不一致。由生成图像提取出的内容表示和真实图像提取的内容表示的差异可以计算出内容损失,计算方法是对比生成图像在某一卷积层的输出特征图与真实图像在相同卷积层的输出特征图二者的逐像素差异,即内容损失实质上就是在生成图像和真实图像卷积得到的特征图上再计算逐像素损失。其计算公式表示如下:

经过卷积神经网络多层卷积后,可以得到更接近于图像真实内容的特征图,但和它原本的确切的外观可能会有所变化。因此,在网络中的更高层基于目标和他们的位置来捕捉高层内容,而不是关注于重建图像的像素值之间的差异。 -
风格表示和风格损失

-
风格迁移

实验结果


对实验结果的讨论
-
风格和内容的一些权衡
当然,很好地分离并不意味着我们可以完全将图像风格和内容进行分离。当合成一张图像其中带有一张图像的内容和另一张图像的风格时,通常不存在能同时匹配所有限制的图像。然而,因为我们在图像合成中优化的损失函数是一个风格损失和内容损失的线性组合,我们可以平滑地进行调节,将重点放在重建内容或是重建风格,下图展示了原始图像随着匹配内容与匹配风格的相对权重的变化而变化的结果,图上的比例10-3代表了内容损失项与风格权重项的权重相除(注意是损失项的权重相除,而不是损失值相除)的结果。因此从左往右,从上到下代表了内容损失项占的权重越来越大的结果。
由下图结果可以看出,重点强调风格(左上角)会导致图像过于匹配期望的风格信息,而重点强调内容则会生成一个仅有少量风格信息的图像。作者提出在实践中要在这两种极端之间进行平衡,最后取得视觉上吸引人的图像。

-
不同卷积层的生成效果
在图像合成过程中的另一个重要问题则是提取风格和内容表示的神经网络的卷积层的选择。作者发现以更高层提取的风格特征作为待匹配的风格特征,可以在风格迁移后的图像上取得更平滑和更连续的视觉体验。至于内容表示提取层的选择,在固定风格和权重超参的情况下,作者进行了对比如下图。
由下图可以看出,匹配网络中不同层提取的内容特征的影响。如图所示,如果匹配conv2_2的内容特征则可以保留原始图像更多细节结构与详细的像素信息。当匹配conv4_2层的内容特征时,内容特征和风格特征匹配地更深,输出图像的内容以风格图像的风格的形式被展示。


- 待转换图像初始化方法
无论是用内容图像、风格图像或是噪声图像进行初始化,最后取得的结果都差不多。

《Perceptual Loss for Real-Time Style Transfer and Super-Resolution》(2016)
[paper]Perceptual Losses for Real-Time Style Transfer
and Super-Resolution(2016)
[Supplementary Material]Perceptual Losses for Real-Time Style Transfer
and Super-Resolution: Supplementary Material
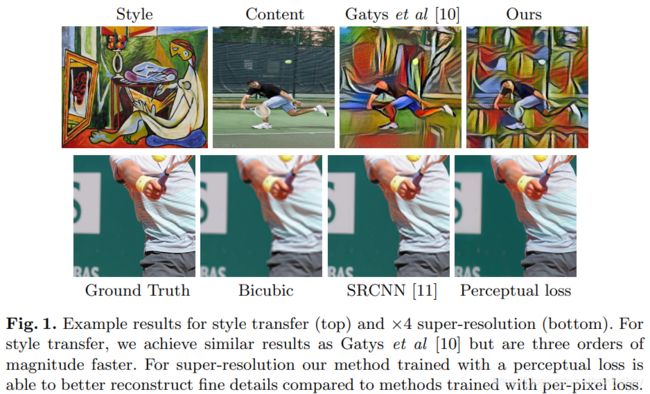
原始的风格迁移的速度是非常慢的。在GPU上,生成一张图片都需要10分钟左右,而如果只使用CPU而不使用GPU运行程序,甚至需要几个小时。这个时间还会随着图片尺寸的增大而迅速增大。这其中的原因在于,在原始的风格迁移过程中,把生成图片的过程当做一个“训练”的过程。每生成一张图片,都相当于要训练一次模型,这中间可能会迭代几百几千次。从头训练一个模型要比执行一个已经训练好的模型要费时太多。而这也正是原始的风格迁移速度缓慢的原因。
图像转换问题(image transformation tasks),输入一副图像转换成另一幅图像输出。现有方法来解决的图像转换问题,往往以监督训练的方式,训练一个前向传播的网络,利用的就是图像像素级之间的误差。这种方法在测试的时候非常有效,因为仅仅需要一次前向传播即可。但是,像素级的误差没有捕获输出和ground-truth图像之间的感知区别(perceptual differences)。
高质量的图像可以通过定义和优化perceptual loss函数来生成,该损失函数基于使用预训练好的网络提供的高层的特征。
将两者的优势进行结合,训练一个前向传播的网络进行图像转换的任务,但是不用 pixel-level loss function,而采用 perceptual loss function。在训练的过程中,感知误差衡量了图像之间的相似性,在测试的时可实时运行。
网络主要由两个部分构成:一个是 image transformation network 一个是 loss network 用来定义 loss function。

注:图中蓝线加黑线表示内容损失,作用在较低特征层上。红线和黑线表示风格损失,作用在从低到高所有特征层上。
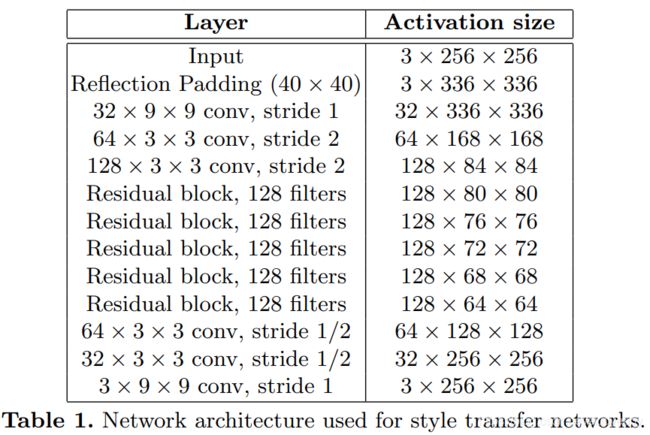

在使用过程中,Transform网络用来对图像进行转换,它的参数是变化的,而Loss网络,则保持参数不变,Transform的结果图、风格图和内容图都是通过Loss 网络得到每一层的feature激活值,并以之进行Loss计算。
风格是什么?对世界有着丰富而敏感的人,可以感受得到,但是用语言精确描述到可以量化的程度很难做到。无法精确的定量描述风格是什么,如何去教机器去理解什么是风格?取巧的方式是既然无法定义风格是什么,可以定义风格不是什么。
风格绝对不是内容,即同样一幅美术作品的内容,是可以用不同的风格来表达的,而具有同样风格的作品,可以具有完全不同的内容。更具体的说,风格是一种特征,这种特征具有位置不敏感性。
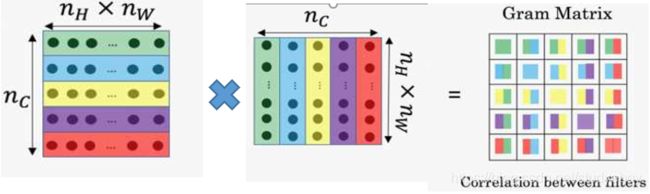
所以可以借用训练好的深度卷积网络,前向传播提取图片的特征图 F ∈ R C × H × W F \in R^{C \times H \times W} F∈RC×H×W后,对每个点的特征 F h , w ∈ R C F_{h,w} \in R^C Fh,w∈RC求其Gram矩阵得到 G h , w = F h , w F h , w T ∈ R C × C G_{h,w}=F_{h,w}F^T_{h,w} \in R^{C \times C} Gh,w=Fh,wFh,wT∈RC×C,然后将每个点的Gram矩阵相加 G = ∑ h , w G h , w = ∑ h , w F h , w F h , w T ∈ R C × C G=\sum _{h,w}G_{h,w}=\sum_{h,w}F_{h,w}F^T_{h,w} \in R^{C \times C} G=∑h,wGh,w=∑h,wFh,wFh,wT∈RC×C这个Gram矩阵最大的特点就是具有位置不敏感性,所以,可以将这个G当作衡量一张图片风格的量化描述,考虑到一个卷积佘宁网络中间有多层特征图,对于每层特征图都可以得到Gram矩阵,可以使用 { G 1 , G 2 , . . . G l } \{G_1, G_2, ...G_l\} {G1,G2,...Gl}来更为全面的描述一张图的风格,相应的损失函数为:
![]()

对图像的风格量化描述后,对图片的内容进行量化描述,直接用每一层的特征图来描述即可: { F 1 , F 2 , . . . F l } \{F_1, F_2,...F_l\} {F1,F2,...Fl},相应的损失函数为:
![]()


为了保持风格转换后的低层的特征,引入两个简单的Loss,MSE Loss和total variation loss。MSE Loss为:
![]()
total variation loss是为了提高图像的平滑度:


整体的loss为:
![]()

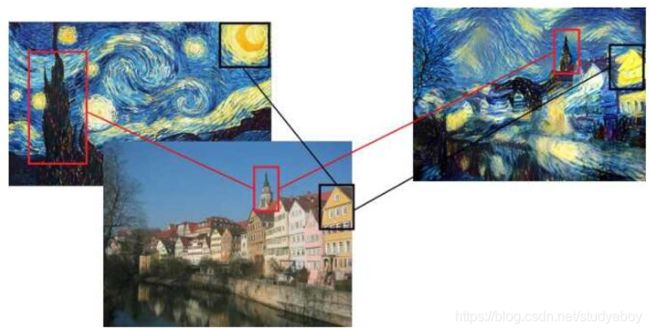
其中,Gram矩阵就是每一层滤波后的feature map,将其转置并相乘得到的矩阵,如下图说是。其实就是不同滤波器结果feature map两两之间的相关性。譬如说,某一层中有一个滤波器专门检测尖尖的塔顶这样的东西,另一个滤波器专门检测黑色。又有一个滤波器负责检测圆圆的东西,又有一个滤波器用来检测金黄色。对梵高的原图做Gram矩阵,谁的相关性会比较大呢?如下图所示,尖尖的和黑色总是一起出现的,它们的相关性比较高。而圆圆的和金黄色都是一起出现的,它们的相关性比较高。因此在风格转移的时候,其实也是在风景里取寻找这种匹配,将尖尖的渲染为黑色,将圆圆的渲染为金黄色。如果假设图像的艺术风格就是其基本形状与色彩的组合方式,那么Gram矩阵能够表征艺术风格就是理所当然的事情了。
实验结果
作用:
- 在超分辨率中,因为经常使用MSE损失函数,灰度熬制输出图片比较平滑(丢失了细节部分/高频部分),因此适当选择某个输出的特征输入感知损失函数是可以增强细节。
- 在风格转移中,用一个感知损失函数来训练图像转换网络能让输出非常接近目标图像,但并不是让他们做到完全匹配。
超分辨率
《Loss Functions for Image Restoration with Neural Networks》中对图像复原任务中的损失函数进行了比较,指出了L2损失的一些缺点:
- L2损失对大的error有强的惩罚,对小的error的惩罚低,忽略了图像内容本身的影响。实际上人眼视觉系统(HVS)对图像中的无纹理区域的亮度和颜色变化更敏感。而目前使用的感知损失,即Perceptual loss,在得到感知域内容的过程中,对图像的内容进行了一次提炼,因此在感知域空间中计算损失相当于结合图像内容的损失,会使得复原后的图像视觉效果上更好。
- L2损失的收敛性能比L1要差。理论上说,L2损失是刷高PSNR指标的理想损失函数,但是具体在应用的时候,复原的性能还是要取决于损失函数的收敛性能。文章对L2损失和L1损失进行了比较,在训练中交互损失函数,查看收敛情况,得出了收敛性能的对比图:
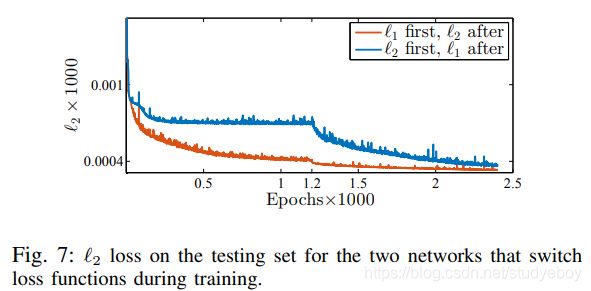
可以看到L1损失函数的收敛性能优于L2损失函数的。
此外,文章也对不同的损失函数指导的模型的测试进行了对比,在超分辨率下:
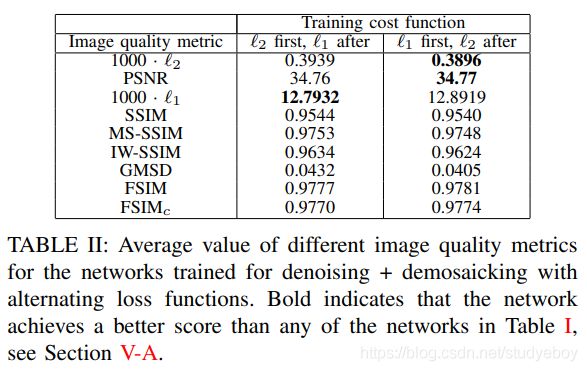
可以看出来使用L1损失函数优于使用L2损失函数。
MSE(Mean Squared Error),是图像空间的内容“相似”,而在图像上普遍存在区域,其属于某个类别(老虎皮、草、渔网等),如果出现纹理或者网格,那么优化MSE很容易将这个区域磨平,即平滑。
Perceptual Loss:是特征空间的类别/纹理“相似”,因为深度卷积网络拥有图像分类,利用的是物体的纹理差异。
多尺度(MS)-SSIM:图像空间的结构“相似”,MS-SSIM+L1的混合损失适合于图像复原。
参考资料
Loss Functions for Image Restoration with Neural Networks(2018)
在目前超分辨率的论文中不使用MSE,而使用L1或者Perceptual loss的原因是什么?
Perceptual Loss: 提速图像风格迁移1000倍
perceptual loss(感知loss)介绍
Perceptual Loss(感知损失)论文笔记
图像风格转换(Style Transfer | 风格迁移综述)
图像风格化算法综述三部曲之 (一) (Neural Style Transfer: A Review)
图像风格化算法综述三部曲之 (二) (Neural Style Transfer: A Review)
图像风格化算法综述三部曲之 (三) (Neural Style Transfer: A Review)
Image Style Transfer Using Convolutional Neural Networks
经典论文重读—风格迁移篇(一):Image Style Transfer Using Convolutional Neural Networks
Image Style Transfer Using Convolutional Neural Networks——风格迁移经典论文阅读
Image Style Transfer:多风格 TensorFlow 实现